词向量转换回文本-以CMU-MOSI为例
需求:在进行深度学习的时候,我们使用glove将文本转换为词向量,使得神经网络可以更好的理解文本。但是,当我们得到一个已经经过预处理的数据集,我们想要逆推导得到该向量的文本。
这个时候我们应该怎么办?我们这里以多模态情感分析数据集CMU-MOSI为例子进行介绍。
步骤
- 下载所使用的embedding版本。我这里是glove.840B.300d。由于可能需要翻墙,提供一下百度云盘,需要可以自取
链接:https://pan.baidu.com/s/1SFK93RpL5YJfEmV2jgWDIw
提取码:op2g
复制这段内容后打开百度网盘手机App,操作更方便哦
- 使用下载的glove,构建两个在转换中需要的数据结构,分别是id2word的字典以及embedding的列表
def contruct_twoFile():
id2word = {}
embedding = []
with open(r'F:pcodedatasetglove.840B.300d.txt', 'r', encoding='utf-8')as f:
row = 0
for line in f.readlines():
if row == 0:
row = 1
continue
row += 1
if row % 10000 == 0:
print(row)
word = line.strip().split(' ')[0]
try:
vec = np.array([float(item) for item in line.strip().split()[1:]])
except:
continue
# print()
if (vec.shape[0] == 300):
id2word[len(embedding)] = word
embedding.append(vec)
# exit(0)
glove_embedding = np.array(embedding)
- 载入MOSI数据集中文本的部分
dataset = pickle.load(open(path, 'rb'))
train_text_embed = torch.tensor(dataset['train']['text'].astype(np.float32)).cpu().detach()
- 然后就可以根据如下代码进行转换了
total_text_context = []
for x in train_text_embed:
text = [] # 50, 300
for xx in x: # 在这50个里面找
dataset_embed = xx[:300]
if np.sum(dataset_embed) != 0:
dataset_embed = np.reshape(dataset_embed, [1, 300])
scores = np.sum(np.abs(dataset_embed - glove_embedding), axis=-1)
id = scores.argmin()
score = scores[id]
text.append(id2word[id])
if score < 0.1:
print(id2word[id] + ':' + str(score))
text.append(id2word[id])
total_text_context.append(text)
- 结果如图所示
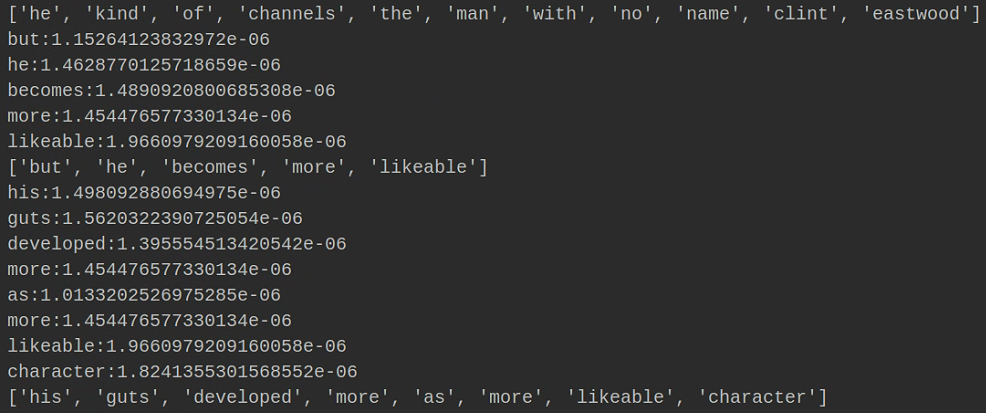
最后
以上就是迷路汽车最近收集整理的关于词向量转换回文本-以CMU-MOSI为例的全部内容,更多相关词向量转换回文本-以CMU-MOSI为例内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![[语音识别] kaldi -- aidatatang_200zh脚本解析:词典准备](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)
发表评论 取消回复