1、适用人群
- 这篇文章会介绍一些简单基本的 「数据结构」 ,相信大家也看过不少大佬的数据结构的文章,有着一些基础滴,但是本篇文章着重在于讲解与整理 基本数据结构 的框架,帮助小伙伴搭建一个数据结构的脑图,为学习 算法 打下坚实基础。
勤奋????的小伙伴可以去 码云 git 上传的 使用 Java 重写的基本数据结构哦!记得 Star 哦!
2、算法和数据结构
算法介绍
- 首先算法是什么东西?
- 它是一种方法,一种解决问题的方案。 举个例子,你现在要去上班,可以选择走路、跑步、坐公交、坐地铁、自己开车等等,这些都是解决方案。
- 但是它们都会有一些衡量指标,让你有一个权衡,最后选择你认为最优的策略去做。
- 而衡量的指标诸如:时间消耗、金钱消耗、是否需要转车、是否可达 等等。
时间消耗就对应了:时间复杂度
金钱消耗就对应了:空间复杂度
是否可达就对应了:算法可行性
数据结构
-
什么是数据结构呢?
-
让我们看看书上怎么解释滴:数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成的 。
-
而为什么需要引入这么多数据结构呢 ?
-
因为任何一种数据结构都不是完美的。每一种数据结构都有其处理的不了的应用场景,所以我们需要根据对应的场景,采用最适合的数据结构,而具体使用哪种数据结构,则需要不断地通过刷题、不断学习经验,才能总结出来。
-
对于实现某个算法,我们往往会用到一中或多种的 数据结构 来简化算法的实现。
-
因为我们处理一些问题的时候往往不能一次性将数据处理完,更多的时候需要先把它们放在一个容器或者说缓存里面,等到需要的时候再将它们拿出来处理和使用。
-
这其实是一种 「空间换时间」 思想的体现, 在适当的时候使用数据结构可以帮助我们高效地处理数据。
-
常用的一些数据结构如下:
| 数据结构 | 应用场景 |
|---|---|
| 数组 | 线性存储、元素为任意相同类型、随机访问 |
| 字符串 | 线性存储、元素为字符、结尾字符、随机访问 |
| 链表 | 链式存储、快速删除 |
| 栈 | 先进后出 |
| 队列 | 先进先出 |
| 哈希表 | 随机存储、快速增删改查 |
| 二叉树 | 对数时间增删改查,二叉查找树、线段树 |
| 多叉树 | B/B+树 硬盘树、字典树、字符串前缀匹配 |
| 树状数组 | 单点更新,成段求和 |
| 森林 | 并查集 快速合并数据 |
| 图 | 最短路径 |
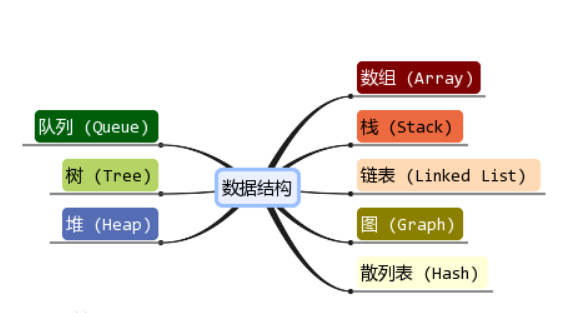
简单数据结构的掌握
1. 数组
数组是可以在内存中连续存储多个元素的结构,在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,并且数组下标从0开始。
优点:
1、按照索引查询元素速度快
2、按照索引遍历数组方便
缺点:
1、数组的大小固定后就无法扩容了 (根据程序语言不同,有的数组可以扩容)
2、数组只能存储一种类型的数据
3、添加,删除的操作慢,因为要移动其他的元素。
适用场景:
频繁查询,对存储空间要求不大,很少增加和删除的情况。
分类:
静态数组、动态数组
插入时间复杂度: O ( n ) O ( n ) O(n)
查找时间复杂度: O ( n ) O ( n ) O(n)
删除时间复杂度: O ( n ) O ( n ) O(n)
2. 字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符。一般记为 s=“a1a2···an”(n>=0)。
字符串(string)为符号或数值的一个连续序列,如符号串(一串字符)或二进制数字串(一串二进制数字),它的每一位单个元素都是能提取的。
特点:
内存空间连续,类似字符数组,一般编程语言会自带一些对字符串操作的库函数。
插入时间复杂度: O ( n ) O ( n ) O(n)
查找时间复杂度: O ( n ) O ( n ) O(n)
删除时间复杂度: O ( n ) O ( n ) O(n)
3. 链表
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现的。
每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。
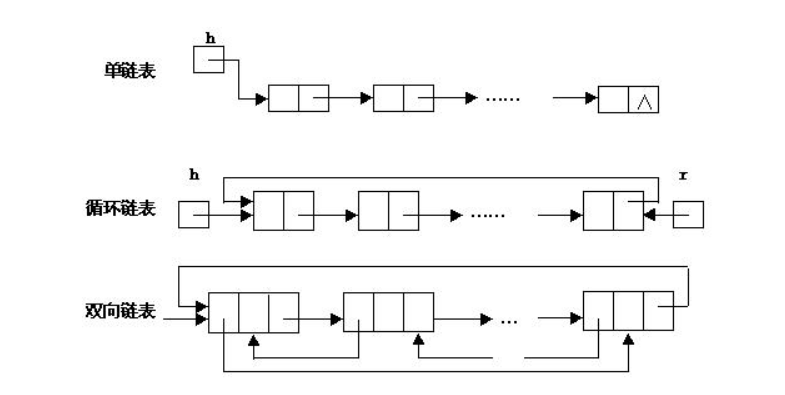
链表的优点:
链表是很常用的一种数据结构,不需要初始化容量,可以任意加减元素;
添加或者删除元素时只需要改变前后两个元素结点的指针域指向地址即可,所以添加,删除很快;
缺点:
因为含有大量的指针域,占用空间较大;
查找元素需要遍历链表来查找,非常耗时。
适用场景:
数据量较小,需要频繁增加,删除操作的场景
分类:
单链表,双向链表,循环链表,双向循环链表等等
插入时间复杂度: O ( 1 ) O ( 1 ) O(1)
查找时间复杂度: O ( n ) O ( n ) O(n)
删除时间复杂度: O ( 1 ) O ( 1 ) O(1)
4. 栈
栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出,或者说是后进先出,从栈顶放入元素的操作叫入栈,取出元素叫出栈。
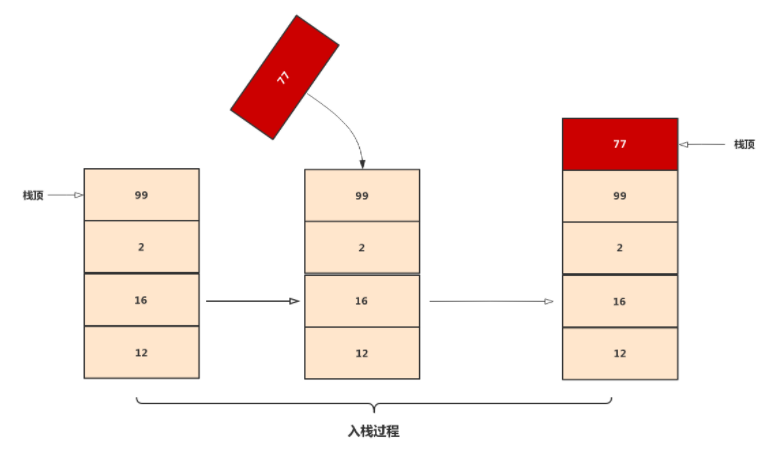
栈的结构就像一个集装箱,越先放进去的东西越晚才能拿出来,所以,栈常应用于实现递归功能方面的场景,例如斐波那契数列。
分类:
FILO、单调栈
特点:
不支持下标访问,即可以使用数组实现,也可以使用链表实现
插入时间复杂度: O ( 1 ) O ( 1 ) O(1)
查找时间复杂度:理论上不支持查找
删除时间复杂度: O ( 1 ) O ( 1 ) O(1)
5. 队列
列与栈一样,也是一种线性表,不同的是,队列可以在一端添加元素,在另一端取出元素,也就是:先进先出。
从一端放入元素的操作称为入队,取出元素为出队。
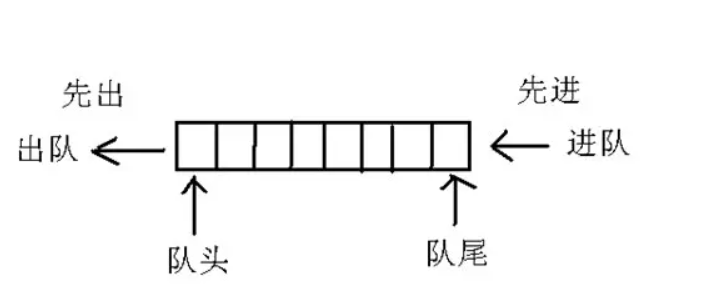
分类:
FIFO、单调队列、双端队列
特点:
不支持下标访问,即可以使用数组实现,也可以使用链表实现
插入时间复杂度: O ( 1 ) O ( 1 ) O(1)
查找时间复杂度:理论上不支持查找
删除时间复杂度: O ( 1 ) O ( 1 ) O(1)
6. 哈希表 (散列表)
据关键码和值 (key和value) 直接进行访问的数据结构。
通过 key 和 value 来映射到集合中的一个位置,这样就会在 key 与 value 之间产生一个对应关系,称之为 关系 f,又称为散列函数、哈希(hash)函数。
散列表就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,这种存储空间可以充分利用数组的查找优势来查找元素,所以查找的速度很快。
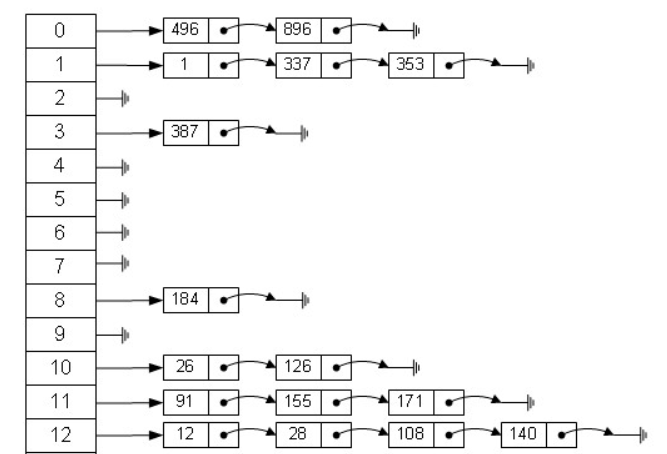
从图中可以看出,左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,这个链表可能为空,也可能有很多元素。
我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
哈希表的应用场景固然很多,但也有很多问题要考虑,比如哈希冲突的问题,如果处理的不好会浪费大量的时间,导致应用崩溃。
7. 树
树是也一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。
把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
- 每个节点有零个或多个子节点
- 没有父节点的节点称为根节点
- 每一个非根节点有且只有一个父节点
- 除了根节点外,每个子节点可以分为多个不相交的子树
而在日常的应用中,我们讨论和用的更多的是树的其中一种特殊的结构,就是二叉树
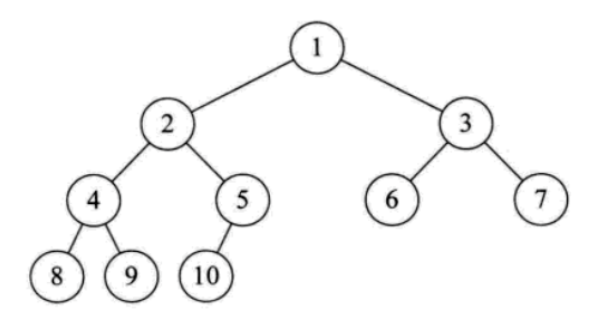
二叉树是树的特殊一种,具有如下特点:
1、每个结点最多有两颗子树,结点的度最大为2
2、左子树和右子树是有顺序的,次序不能颠倒
3、即使某结点只有一个子树,也要区分左右子树
二叉树是一种顺序查找的折中方案,它添加,删除元素都很快,并且在查找方面也有很多的优化算法。
分类:
平衡二叉树、红黑树、B+树
插入时间复杂度: O ( 1 ) O ( 1 ) O(1)
查找时间复杂度: O ( l o g 2 n ) O ( log2n ) O(log2n)
删除时间复杂度: O ( 1 ) O ( 1 ) O(1)
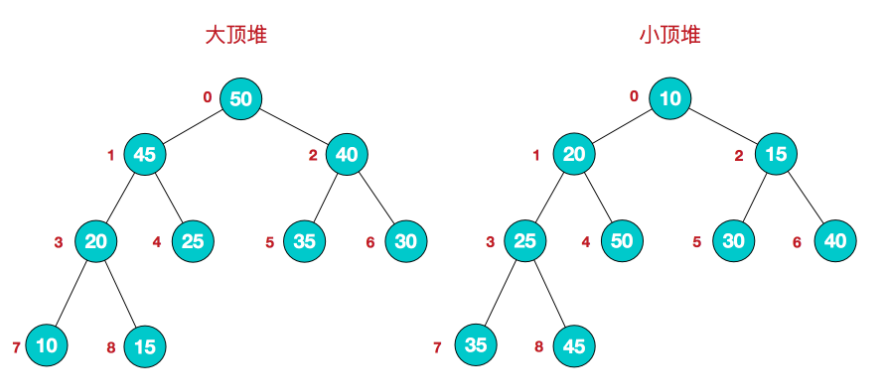
8. 堆
堆是一种比较特殊的数据结构,可以被看做一棵树的数组对象。
具有以下的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值
- 堆总是一棵完全二叉树
完全二叉树 : 叶子结点只出现在最下层和次下层,且最下层的叶子结点集中在树的左部。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
分类:
二叉堆、斐波那契堆、最大堆、最小堆等
最大堆的代码!
public class MaxHeap<E extends Comparable<E>> {
private Array<E> data;
public MaxHeap(int capacity){
data = new Array<E>(capacity);
}
public MaxHeap(){
data = new Array<E>();
}
//堆化构造函数
public MaxHeap(E[] arr){
data = new Array<>(arr);
for(int i = parent(arr.length - 1) ; i >= 0; i--)
siftDown(i);
}
public int size(){
return data.getSize();
}
public boolean isEmpty(){
return data.isEmpty();
}
//返回index结点的父亲结点的索引
private int parent(int index){
if(index == 0)
throw new IllegalArgumentException("index-0 does't have parent!");
return (index -1) / 2;
}
//返回完全二叉树的数组表示中,一个索引的元素的左孩子结点的索引
private int leftChild(int index){
return index * 2 + 1;
}
//返回完全二叉树的数组表示中,一个索引的元素的右孩子结点的索引
private int rightChild(int index){
return index * 2 + 2;
}
//
public void add(E e){
data.addLast(e);
siftUp(data.getSize() - 1);
}
private void siftUp(int k ){
while(k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0){
data.swap(k, parent(k));
k = parent(k);
//循环直到满足堆的条件
}
}
//返回堆中的最大元素
public E findMax(){
if(data.getSize() == 0)
throw new IllegalArgumentException("Can not findMax when heap is empty!");
return data.get(0);
}
//取出堆中最大的元素
public E extractMax(){
E ret = findMax();
data.swap(0, data.getSize() - 1);
data.removeLast();
siftDown(0);
return ret;
}
private void siftDown(int k){
while(leftChild(k) < data.getSize()){ //左孩子的索引大于所有的元素数,结束
int j = leftChild(k);
if(j + 1 < data.getSize() && data.get(j + 1).compareTo(data.get(j)) > 0)
//j + 1 表示k的右孩子, 左右孩子比较
j = rightChild(k);
//将右孩子给j,即可了解data[j] 是k的俩孩子里最大的
if(data.get(k).compareTo(data.get(j)) >= 0)
break;
//若k的值比最大的还大,返回
data.swap(k, j);
k = j;
}
}
//取出堆中的最大元素, 并且替换成元素e
public E replace(E e){
E ret = findMax();
data.set(0, e);
siftDown(0);
return ret;
}
public void heapSort(E arr[]){
MaxHeap<E> maxHeap = new MaxHeap<>(arr);
for(int i = arr.length - 1; i >= 0; i --)
arr[i] = maxHeap.extractMax();
}
}
9. 图
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
图的结构构成
- 顶点(vertex):图中的数据元素
- 边(edge):图中连接这些顶点的线
树可以说是图的特例
分类:无向图和有向图
特点:
图是一种比较复杂的数据结构,在存储数据上有着许多比较复杂和高效的算法,例如邻接矩阵 、邻接表、十字链表、邻接多重表、边集数组等存储结构。
最后
以上就是敏感面包最近收集整理的关于数据结构 : 简单数据结构总结1、适用人群2、算法和数据结构简单数据结构的掌握的全部内容,更多相关数据结构内容请搜索靠谱客的其他文章。








发表评论 取消回复