我是靠谱客的博主 动听板凳,这篇文章主要介绍[2022]李宏毅深度学习与机器学习第十一讲(必修)-Domain Adaptation做笔记的目的Domain ShiftDomain Adaptation,现在分享给大家,希望可以做个参考。
[2022]李宏毅深度学习与机器学习第十一讲(必修)-Domain Adaptation
- 做笔记的目的
- Domain Shift
- Domain Adaptation
- Little but labeled
- Large amount of unlabeled data
- little and Unlabeled
做笔记的目的
1、监督自己把50多个小时的视频看下去,所以每看一部分内容做一下笔记,我认为这是比较有意义的一件事情。
2、路漫漫其修远兮,学习是不断重复和积累的过程。怕自己看完视频不及时做笔记,学习效果不好,因此想着做笔记,提高学习效果。
3、因为刚刚入门深度学习,听课的过程中,理解难免有偏差,也希望各位大佬指正。
Domain Shift
主要有以下三种可能:
- train和test的输入不一样
- train和test的输出不一样
- train和test的标签不一样
这里主要放在第一种上面,这个也更加常见。

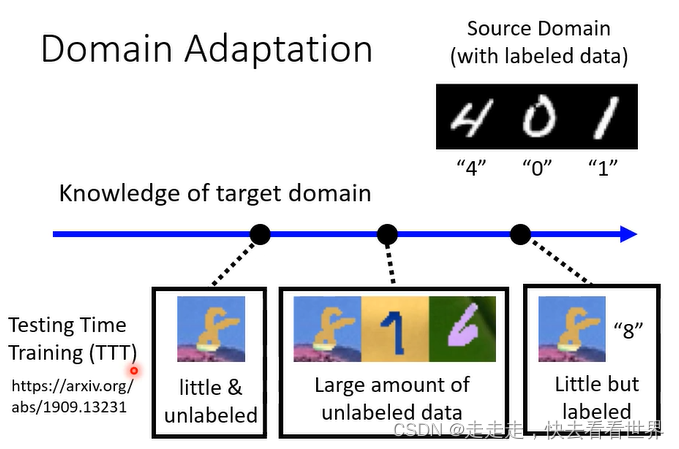
Domain Adaptation
根据知道的target domain的信息多少策略不同。
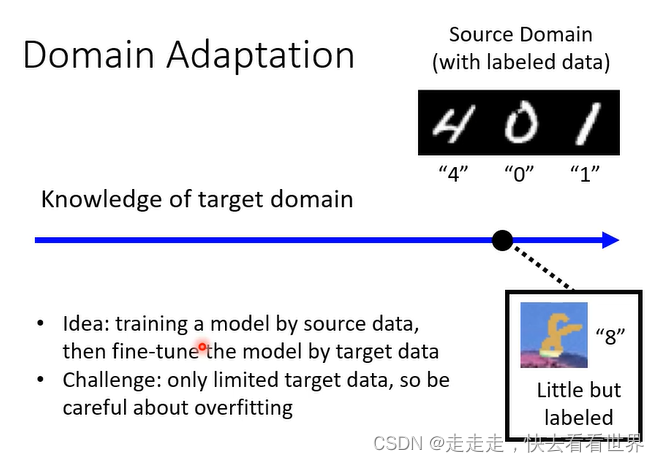
Little but labeled
可以进行fine-tune,但是要防止Overfitting,所以不要跑太多的次数,可以设置小一点的学习率。
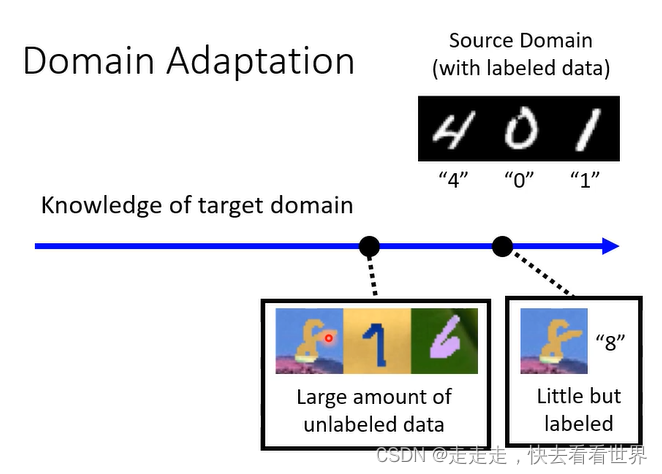
Large amount of unlabeled data
在目标数据集上有很多资料但是没有标签
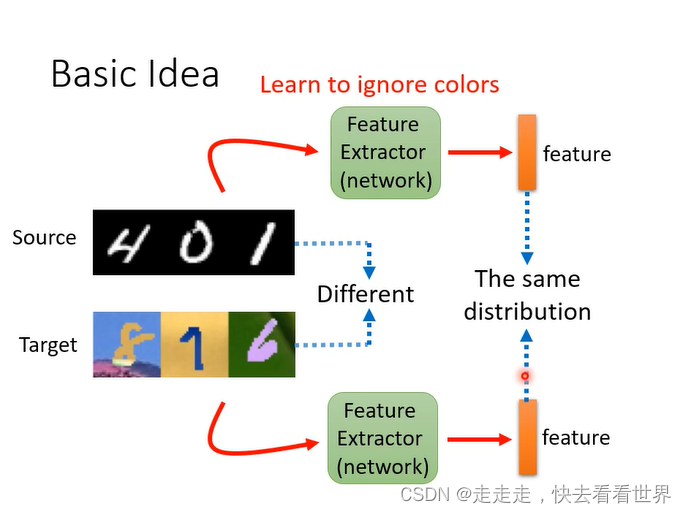
找出Feature Extractor,source data 和target data 的分布差不多,要训练一个Domain分类器,想办法骗过Domain分类器,这个非常像是GAN。
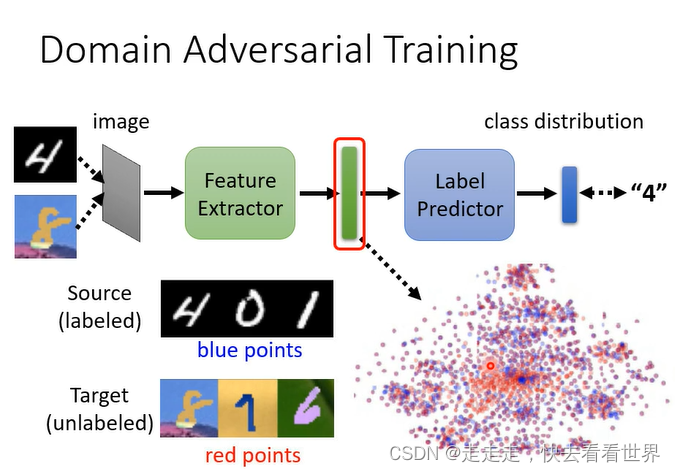
可以看到下图,不会发生模型坍塌,因为Feature Extractor的损失是
L
−
L
d
L-L_d
L−Ld.
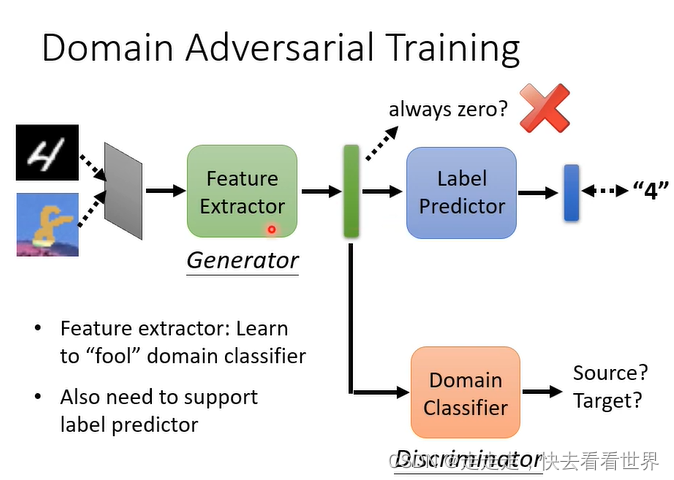
这个方法是有用的如下图,括号里面是提高的精度。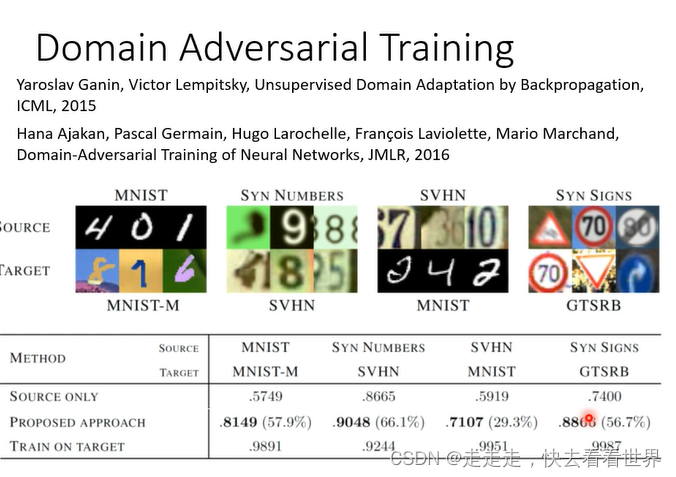
第二个方法明显更加好,我们应该让模型远离分界点
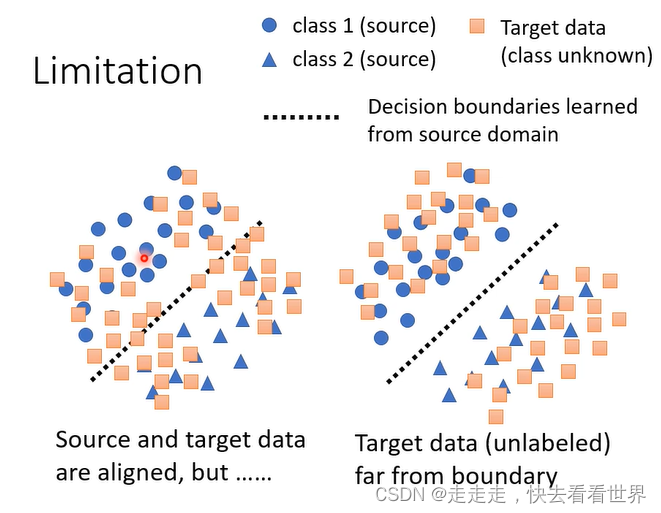
所以有论文进行了改进,让结果更加集中。
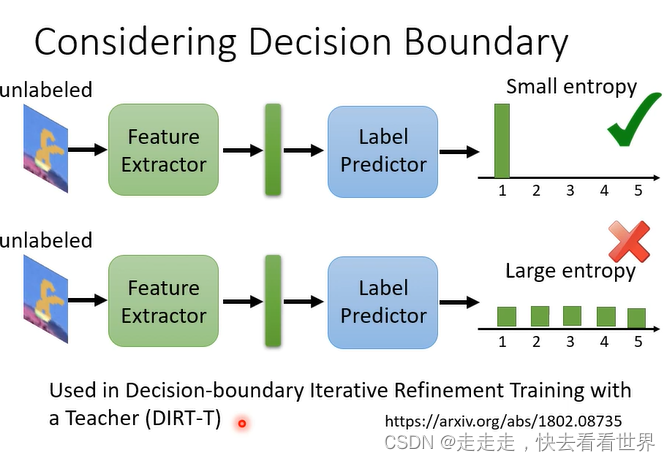
little and Unlabeled
没有标签同时资料很少,可用TTT的方法,其实我感觉像是zero-shot问题。
最后
以上就是动听板凳最近收集整理的关于[2022]李宏毅深度学习与机器学习第十一讲(必修)-Domain Adaptation做笔记的目的Domain ShiftDomain Adaptation的全部内容,更多相关[2022]李宏毅深度学习与机器学习第十一讲(必修)-Domain内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。




![[2022]李宏毅深度学习与机器学习第十一讲(必修)-Domain Adaptation做笔记的目的Domain ShiftDomain Adaptation](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)



发表评论 取消回复