
这是 MIT Technology Review 12月11日的 Newsletter 的部分摘录,大概意思是,iPhone 上的 Siri 在听到我们个人说 "Hey Siri" 时有反应,但是对其他人说的都没有反应,按理来说,训练一个这种模型,会需要收集我们大量的声音数据,并且这些数据都会保存在苹果,但苹果并没有这么做,那它是怎么做到的呢?这就说到了今天的主角,联邦学习 (Federated Learning)。
什么是联邦学习?
联邦学习是一种训练数据去中心化的机器学习训练方式,最早在2016年由谷歌提出,目的是通过对保存在大量终端的分布式数据展开训练学习,最终汇总得到一个高质量的中心化机器学习模型。
在苹果 Siri 的例子上,每台手机都是一个终端设备,我们的音频信息都只保存在自己的手机上,苹果通过联邦学习的方式,用我们每个人的音频都训练得到了一个本地模型,然后再整合成一个统一的模型。通过这中方式,既能得到定制化的模型,又能保护用户数据隐私。
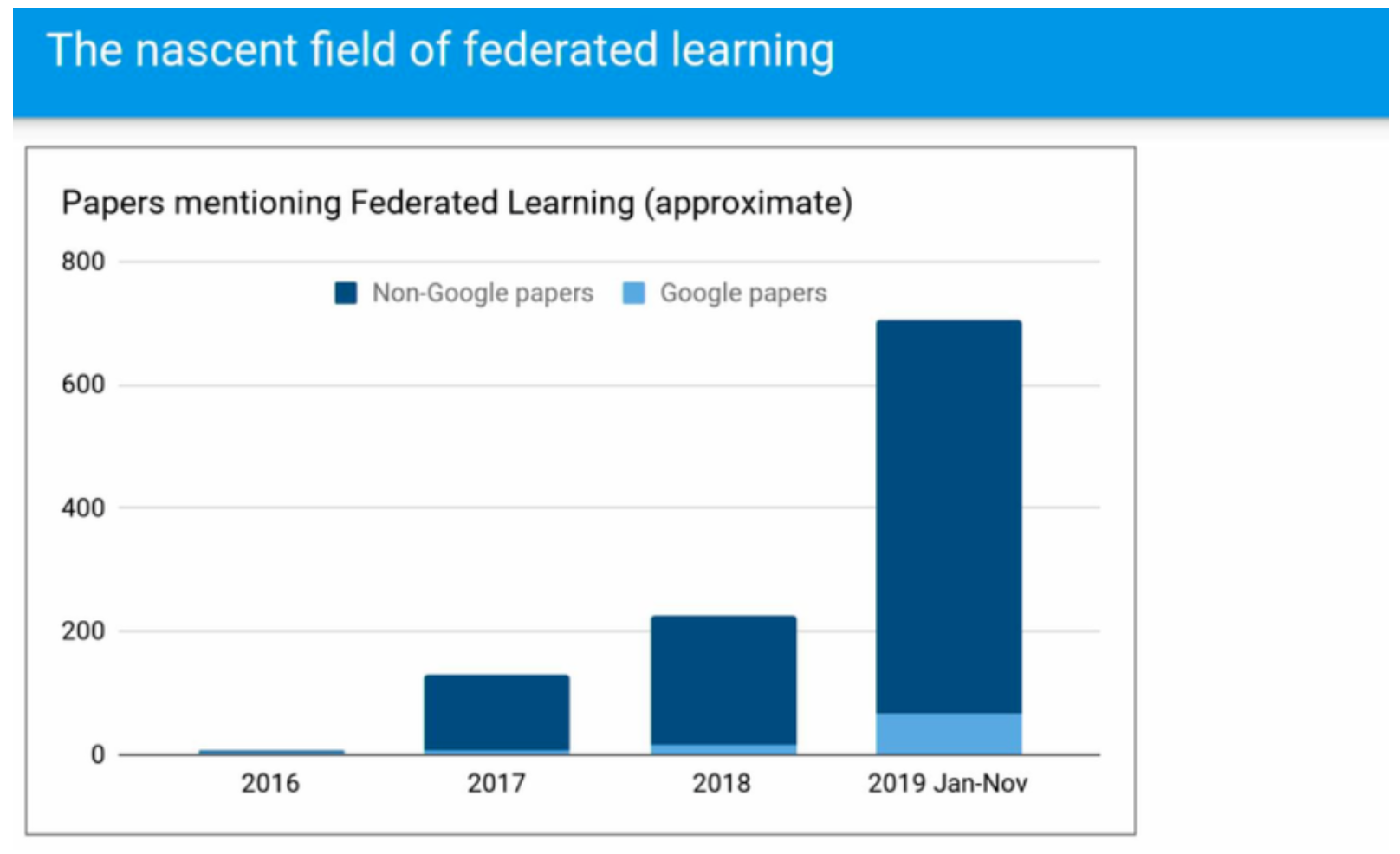
上面这个图是 NIPS 2019 workshop 上,Google 联邦学习的负责人在会上的讲义,这个领域相对较新,但在2019年的关注度有了跨越性的增长。联邦学习到底解决了什么问题呢?
解决了什么问题?
数据隐私
用户个人的数据隐私越来越受重视,前有欧盟的 GDPR,在当时短时间内逼出一堆公司软件条款变更,最近一个月印度也爆出将要发布新的政策来保护印度公民的数据,初次之外,中国有网络安全法和数据管理办法,美国加州有 CCPA《加州消费者隐私法案》,所有这些法律的颁布,都指向了用户数据隐私保护,可以预见,在没有数据和隐私保护的情况下,使用用户的数据去做训练,难度会越来越大。
从另一个角度来说,一些用户的数据隐私保护的要求是更高的。比如说医疗数据,病人不愿意,医院也不改泄漏,没有数据,怎么把机器学习和深度学习这一套东西用到医疗行业里?
数据孤岛
在大数据时代,我们期待的是有大量的数据来完成模型的训练,但大数据往往只专属于几个巨头,多数的公司是没有足够的数据的,并且不同公司之间的数据共享基本是不可能的,法律不允许,公司政策不允许,公司利益不允许等,这导致了众多公司只拥有自己的一部分小数据,难以用来训练一个好的模型。
怎么解决?
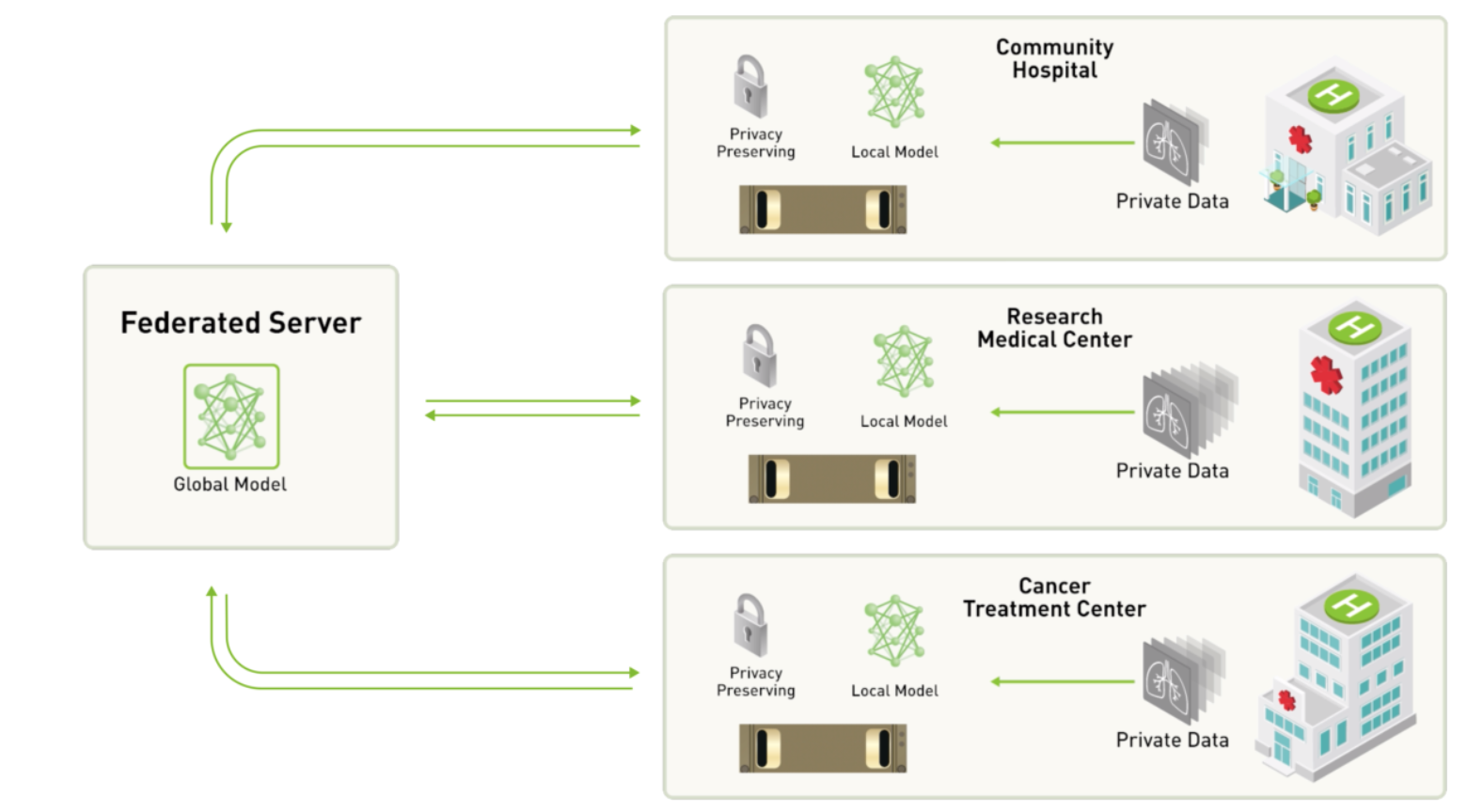
上图 Nvidia 和伦敦国王学院合作的项目,是联邦学习应用在医疗领域。每个医疗机构的用户数据是很敏感的,不能共享,但是一个医疗机构内的数据量太小,没法训练处好的模型,用联邦学习训练可以解决这个问题,训练流程是这样的:
- 云端服务器将一个统一模型下发给多个医疗机构端的服务器。
- 每个医疗机构用本地的数据进行几个 batch 的训练。
- 各个医疗机构把训练之后的模型参数上传到云端服务器。
- 云端服务器将从多个医疗机构那边得到的模型训参数进行整合、更新,一轮训练结束。
- 云端服务器将更新后的模型重新下发给多个医疗机构,开始下一轮训练。
在整个训练过程中,各个医疗机构的数据没有共享,用户隐私得到保护,同时又能共享训练处一个不错的模型可以共用。
不过,上述的这个过程并不是完全保密的,比如云端服务器是可能可以从每个医疗机构传上来的模型参数反推出一些用户数据,有挺多加密的方法可以加入到机器学习和深度学习的过程中,来确保全链条的隐私安全,可以用的一些方法有同态加密,差分隐私,安全多方计算等。
展望
联邦学习从提出到现在就三年多的时间,还有挺多问题没有被解决,或者没有被完全解决,比如终端数据的异构性、联邦学习整套框架的工程化、云端模型整合的方式等,还是有不少可以做研究的方向。
针对联邦学习,整理了一个 Github,由浅入深,包括了一些博文、论文、视频、教程等,将这些内容划分了主题,有兴趣的朋友可以进一步了解一下,欢迎 加星、提PR。
Github: https://github.com/weimingwill/awesome-federated-learning
References
- WeBank AI Group. Federated learning white paper v1.0. 2018.
- https://blogs.nvidia.com/blog/2019/10/13/what-is-federated-learning/
- https://slideslive.com/38921900/workshop-on-federated-learning-for-data-privacy-and-confidentiality-3
最后
以上就是缥缈薯片最近收集整理的关于你的Siri收集了你的个人数据?联邦学习介绍的全部内容,更多相关你内容请搜索靠谱客的其他文章。








发表评论 取消回复