Domain Adaptation
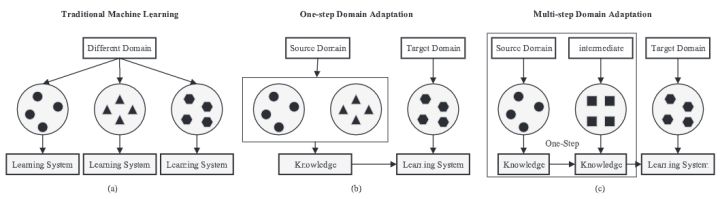
现有深度学习模型都不具有普适性,即在某个数据集上训练的结果只能在某个领域中有效,而很难迁移到其他的场景中,因此出现了迁移学习这一领域。其目标就是将原数据域(源域,source domain)尽可能好的迁移到目标域(target domain),Domain Adaptation任务中往往源域和目标域属于同一类任务,即源于为训练样本域(有标签),目标域为测集域,其测试集域无标签或只有少量标签,但是分布不同或数据差异大,具体根据这两点可以划分为:
- homogeneous 同质:target 与 source domain 特征空间相似,但数据分布存在 distribution shift
- heterogeneous 异构:target 与 source domain 特征空间不同
- non-equal:空间不同且数据偏移,这种就属于差异很大的情况了,可借助中间辅助data来bridge the gap,用multi-step / transitive DA来解决
这也是与Pretraning不一样的地方,现在流行的Pretraning技术也需要后期的很多数据才行。但由于DA的目标域是没有标签的,那么如何使在源于训练得到的模型也能够被目标域使用呢?很自然的想法是将源域和目标域映射到一个特征空间中,使其在该空间中的距离尽可能近。于是产生了三大类方法:
- 样本自适应,对源域样本进行加权重采样,使得重采样后的源域样本和目标域样本分布基本一致,然后在重采样的样本集合上重新学习分类器,即把源域和目标域相似的数据直接加权然后再训练。这种方法虽然简单但太过依赖于设计和经验。
- 特征层面自适应,将源域和目标域投影到公共特征子空间,在子空间中两者的数据分布一致。
- 模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。主要有两种方式,一是直接建模模型,但是在模型中加入“domain间距离近”的约束,二是采用迭代的方法,渐进的对目标域的样本进行分类,将信度高的样本加入训练集,并更新模型。
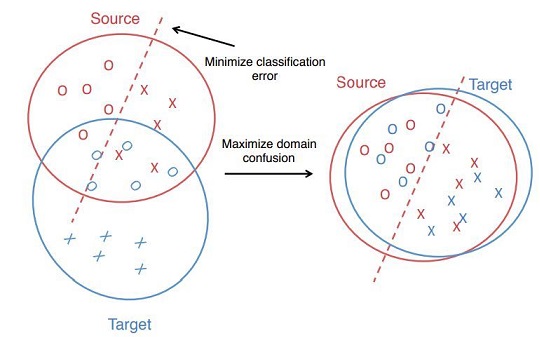
技术手段主要分为Discrepancy-based(空间距离近)和Adversarial-based(混淆空间)。接下来整理一些经典论文。
Discrepancy-based
这类方法会计算taget/source domain的距离,希望他们在空间上的距离尽可能的接近。
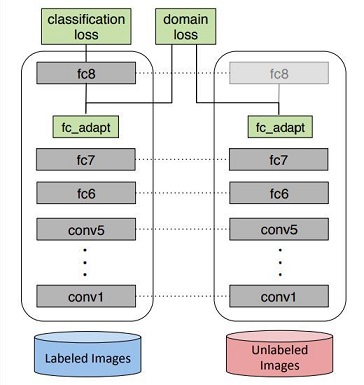
Deep Domain Confusion: Maximizing for Domain Invariance (MMD)
整体架构如上图,主要就是两个loss:classification loss与domain loss,domain loss以减小两个DNN学到的feature之间的距离(最大化域混淆),同时classification loss又能保证source domian分类器本身的性能(最小化分类误差),这样就可以同时学习具有判别性和域不变性的表示。
具体做法是在神经网络中额外加入一个适配层和域误差损失来自动的学习一些特征表达。最后的loss如下,第一项是优化监督分类器,第二项是缩小domain之间的差异。
L = L C ( X L , y ) + λ M M D 2 ( X S , X T ) L=L_C(X_L,y)+lambda MMD^2(X_S,X_T) L=LC(XL,y)+λMMD2(XS,XT)
超参数λ决定了想要的混淆域的强度,映射函数为ϕ ,domain loss使用的是最大均值差异(MMD)来计算,即
M
M
D
(
X
S
,
X
T
)
=
∣
∣
1
∣
X
S
∣
∑
ϕ
(
x
s
)
−
1
∣
X
T
∣
∑
ϕ
(
x
t
)
∣
∣
MMD(X_S,X_T)=||frac{1}{|X_S|}sum phi(x_s)-frac{1}{|X_T|}sum phi(x_t)||
MMD(XS,XT)=∣∣∣XS∣1∑ϕ(xs)−∣XT∣1∑ϕ(xt)∣∣
值得注意的是,MMD可以决定选择哪个特征层(“深度”)和适应层应该有多大(“宽度”),是整个目标的关键部分。即网络中的适配层是哪一层和维度都是可以任意选择的,选择方法就是算MMD哪个最小用哪个,如上图图中,作者最后选了放在fc7后面,并且维度也会根据MMD的计算结果来微调。
代码实现也相当容易:
import torch
def mmd_linear(f_of_X, f_of_Y): #mmd就是遍历所有算距离
delta = f_of_X - f_of_Y
loss = torch.mean(torch.mm(delta, torch.transpose(delta, 0, 1)))
return loss
def forward(self, source, target):
source = self.features(source)
source = source.view(source.size(0), -1)
source = self.classifier(source)#基础层
source = self.bottleneck(source)#适配层
mmd_loss = 0
if self.training:
target = self.features(target)
target = target.view(target.size(0), -1)
target = self.classifier(target)#基础层
target = self.bottleneck(target)#适配层
mmd_loss += mmd.mmd_linear(source, target)#算MMD
result = self.final_classifier(source)#这个是分类损失
return result, mmd_loss
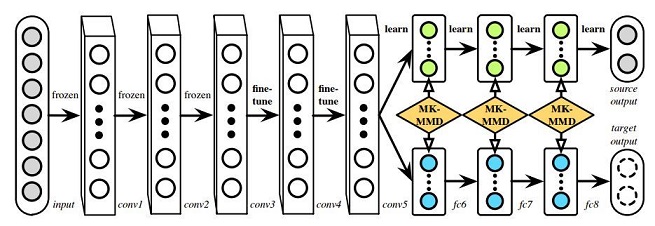
Deep Adaptation Networks(DAN)
有了开山之作之后,后面又有一些优化工作。这篇文章采用了两种改进方法:
- 一是在衡量两个分布差异时使用多核MMD,即MK-MMD。
- 二是不只选择一层网络来减少差异,而是选择多个全连接层。如上图,在alexnet的全连接层fc6、fc7、fc8上来自不同域的数据产生的特征都进行了一一对齐。
比较好的就是多核的无偏估计,能够将复杂度变成O ( n ) ,并且不再自己去增加一个适配层,而是直接用了正常网络中的所有全连接层。
然后还有把MMD升级成多阶的CORAL,将多个依赖domain特征层连乘概率分布的jointMMD的方法,不重点展开,他们都重点在于如何更进一步的缩小差距。
Adversarial-based
源自对抗的思路,如果生成器得到的特征能够混淆判别器的话,那说明学到的特征基本在同一个特征空间了。
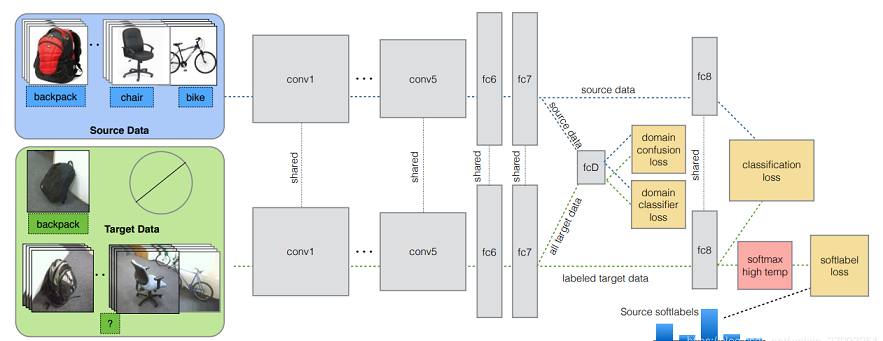
Simultaneous Deep Transfer Across Domains and Tasks
前面的部分和之前的工作基本一致,都是在Alexnet改的,然后在fc7之后进行操作,主要的贡献就是上图中的四块橙色部分的loss,classification loss+domain confusion loss+soft label correlation loss。
- classification loss。这个就不说了,由分类器中的softmax层得到预测类别再与真实类别做交叉熵。
- domain confusion loss。如果分类器无法分辨出输入是来自源域还是来自来自目标域的时候,就认为二者已经达到域对齐了。所以固定住特征提取器,使得domain分类器得到的结果尽可能接近真实值。然后固定住domain分类器,优化特征提取器,使得分类器不能分辨图片来自哪个domain,两者交替对抗训练。
- soft label correlation loss。对于拥有相同标签的源域/目标域数据,希望他们输出的label的分布尽可能相同。但是由于目标域是没有label的,所以此时需要soft label,即用源域的类别信息来做为soft label,将源分类器对源域中类别k的样本的softmax结果取均值即可。
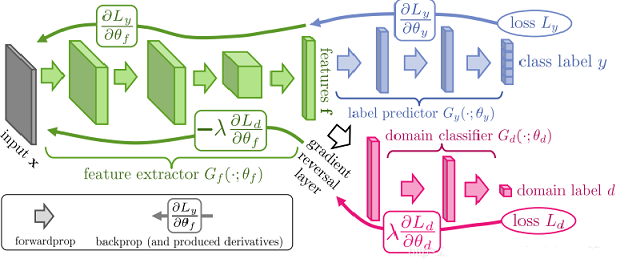
Domain Adversarial Training of NN(DANN)
同样的,基于对抗的方法也有一些突出的发展。模型结构如上图,由三部分组成:特征映射网络Gf(绿色),标签分类网络Gy(蓝色)和域判别网络Gd(红色)。
- 特征映射网络Gf:将数据映射到feature space,使 Gy 能分辨出source domain数据的label,Gd 分辨不出数据来自source domain还是target domain。
- 标签分类网络Gy :对feature space的source domain数据进行分类,尽可能分出正确的label。
- 域判别网络Gd:对feature space的数据进行领域分类,尽量分辨出数据来自于哪一个domain。
同时值得注意的是,它使用了gradient reversal layer避免了一般GAN模型分步训练的情况,即不需要固定一个去训练另一个。
但是如何保证投影之后的特征包含了足够的信息?如果这个特征通过重构能够变成原先的水平,那说明确实已经学习到了足够的信息。所以后来某些模型也加入了重构损失(直接算相似度)。
接下来简单的填坑几篇20’的新工作。
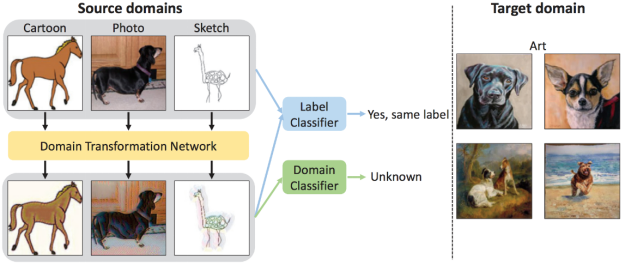
Deep Domain-Adversarial Image Generation for Domain Generalisation
出自AAAI 20,基于基于深度域对抗式图像生成。由于合成图像有助于提高模型泛化性的假设,作者提出一种更统一的方式:generator、extractor、semantic classifier 和 domain discriminator全部都协同训练 ,让 generator 动态地根据后面组件的loss进行调整,提高在未知领域数据上的泛化性。
即通过学习目标函数来确保生成的数据可以被标签分类器正确分类,而同时能欺骗域分类器。通过生成的未知域的数据,可对源域扩展,而使标签分类器对未知域更具鲁棒性。例如上图,源域只有卡通、自然图像、草图三类数据,通过域转换网络得到类标签不变但域标签已经改变的合成数据,合成数据对源数据扩充后再训练分类器,可以泛化到未知域的正确分类。
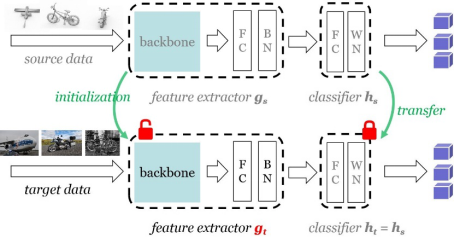
Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation
出自ICML 20,如题是我们真的需要访问源数据吗?用于无监督域自适应的源假设转移。提出了一种新颖的自监督伪标签方法增强目标域的表示学习,学习正确的符合源假设的特征表示。所以整体上是基于“分类器参数是可以在源域和目标域共享”的假设,并且提出两阶段训练方式:
- 首先在源域上使用标签来训练特征提取器(backbone为LeNet)和分类器,如上图的上半部分。
- 接着固定分类器参数,在目标域数据上使用 pseudo-label loss 来优化特征提取器,提高模型在目标域上的分类性能。
以前的方法都是共享源域和目标域的特征提取部分,而这个方法是共享源域和目标域的分类器部分。
code:https://github.com/tim-learn/SHOT/
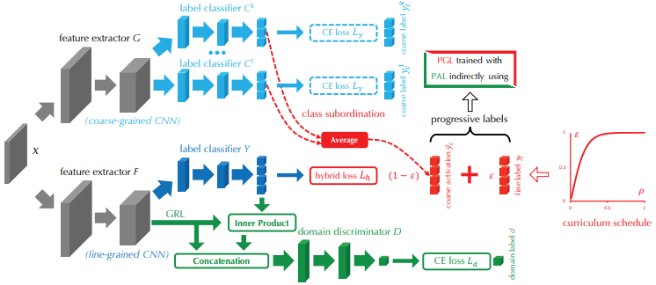
Progressive Adversarial Networks for Fine-grained Domain Adaptation
CVPR 20,首次探索面向精细分类场景的领域自适应方法,并提出一个 CUB-200-Paintings 数据集。精细分类即具有树状结构的特征,所以做法也比较直观,由易到难学吧!所以文章提出Progressive Adversarial Network(PAN):对抗学习+课程学习来学习。
模型架构如上,分两个分支,粗分支和精分支。
- 蓝色。先在一级标签类别上做领域自适应,计算预测值 与 coarse label 的CE loss。
- 红色。计算预测值 与 progressive labels 的 hybrid loss。这个progressive labels 由真实值和预测值组成,由epsilon来平衡。这里就是文章提到的课程学习。
- 再在二级细粒度标签上做进一步领域自适应。
code:https://github.com/thuml/PAN
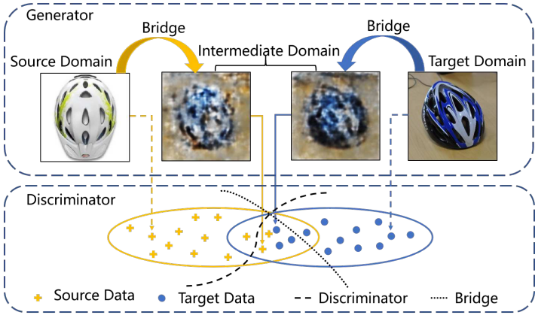
Gradually Vanishing Bridge for Adversarial Domain Adaptation
CVPR20,渐进式领域适应,如上图的“渐进”。论文一种新的渐进式领域自适应方法(考虑到源域和目标域数据分布的差异和实际数据的复杂程度,摒弃一步到位的想法,采取一步一步地特征对齐思路):基于特征任务的相似性、不同领域数据的独立性、以及学习到最后特征空间的收敛性,提出了一种新的启发式领域自适应方法。
所以作者尝试提出一种桥梁的机制,应用在生成器和判别器中。在生成器上桥梁建模领域专属特性,并将源域和目标域特征连接到中间域,用来降低总体迁移难度。具体实现是在源和目标域都多做一个分支,然后融合得到新的loss对抗约束空间。
另外我们可以同时看该作者做的另一篇渐进的工作:
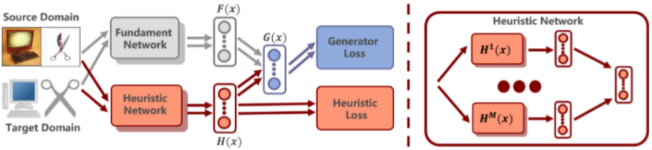
Heuristic Domain Adaptation(NeurIPS 20)
这篇采取的技术方案借鉴于经典的启发式搜索,强调在识别具体物体的过程中,额外对环境场景等无关因素进行建模。所以heuristic就是做的这个事情,尝试构建多种不同的路径去施加约束(初始态和收敛态)。最后的loss=源于分类loss-源域与目标域对齐loss+中间态约束loss。
code:https://github.com/cuishuhao/HDA
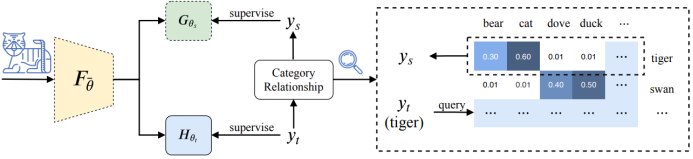
Co-Tuning for Transfer Learning
NeurIPS 20,由于人脑在学习新的概念时,往往会借助已有的、相似的概念来帮助提升新概念的学习。所以让模型同时学习新概念和旧概念,并且共享他们的特征提取器吧。
所以架构如上图有两个分支建模新知识和旧知识,同时为了在学习过程中灵活地、有效地更新旧概念的类别,需要借助category relationship来同时监督,以此提高新概念的学习效率。具体细节请详细参考论文,博主过段时间再填坑。
最后
以上就是从容海燕最近收集整理的关于Domain Adaptation(领域自适应,MMD,DANN)的全部内容,更多相关Domain内容请搜索靠谱客的其他文章。








发表评论 取消回复