“Generalizing to Unseen Domains via Adversarial Data Augmentation” 论文翻译 正文
- 论文题目:通过对抗数据增强泛化到未知域
- 1 .导入
- 相关工作
- 2.模型方法
- 3.理论思想
- 4.实验
- 5.结论
纯手打,相互学习,如有问题还望指正。
部分英文术语属于最新提出,会直接贴出英文,抱歉。
深度学习,文本分析等问题可以加QQ交流,相互学习。有好的论文也可推荐:QQ:1307629084
留学党有时差,回复不及时还请见谅。
论文归类:迁移学习
原文链接: link.
相关源码: link.
本篇论文作者:Riccardo Volpi, Hongseok Namkoong, Ozan Sener, John Duchi, Vittorio Murino, Silvio Savarese
论文发表时间:2018.11.6
论文题目:通过对抗数据增强泛化到未知域
1 .导入
在许多机器学习的现代应用中,我们希望学习一种能够在多个人群中均匀表现的系统。但由于数据采集成本高,所以数据集中的人口来源通常有限。在对数据集进行验证评估时表现良好的标准模型,通常从相同人群中的训练数据集中收集,所以一般对不同于训练数据集的人群表现不佳。在本文中,我们关注的是在我们无法访问来自未知目标分布的任何数据的环境中,对不同于训练分布的人群进行推广。例如,考虑一个自动驾驶汽车的模块,需要在整个天气条件和培训期间未开发的城市环境中进行泛化。
许多作者在设置中提出了自适应领域的方法,其中可以获得完全标记的源数据集和来自固定目标分布的未标记(或部分标记)的一组示例数据集。虽然这样的算法可以成功地学习在已知目标分布上表现良好的模型,但是在实际场景中先验固定目标分布的假设可能是限制性的。例如,考虑机器人使用的语义分割算法:每个任务,机器人,环境和摄像机配置将产生不同的目标分布,并且只有在训练和部署模型之后才能识别这些不同的场景,这使得他们收集样本变得困难。
在这项工作中,我们开发的方法可以更好地学习推广到新的未知领域。我们考虑了限制性设置,其中训练数据仅来自单个源领域。受到分布式强大优化和对抗性训练的最新发展的启发,我们考虑围绕源分布(训练)P0的以下最坏情况问题
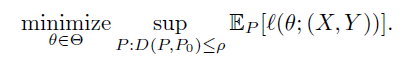 (1)
(1)
这里,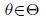 是模型,
是模型,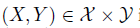 是一个带有标签的源数据点,
是一个带有标签的源数据点,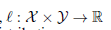 是损失函数,D(P,Q)是概率分布空间上的距离度量。
是损失函数,D(P,Q)是概率分布空间上的距离度量。
最坏情况问题的解决方案(1)保证了针对远离源域P0的距离ρ的数据分布的良好性能。 为了允许对源P0具有不同支持的数据分布,我们使用Wasserstein距离作为我们的度量D。我们的距离将在语义空间3上定义,因此满足D(P,P0)小于等于 ρ 的目标群体P代表真实的协变量 保留源的相同语义表示的移位(例如,向灰度图像添加颜色)。 在这方面,我们期望解决最坏情况问题(1) - 我们希望学习的模型在语义空间中的协变量变化中具有良好的性能。
我们提出了一个迭代过程,旨在解决问题(1)一次得到一个小的 ρ 值,并对模型 θ 进行关于这些虚构的最坏情况目标分布的随机梯度更新(第2节)。 我们方法的每次迭代都使用小的ρ 值,我们提供了许多方法的理论解释。 首先,我们证明了我们的迭代算法是一种自适应数据增强方法,我们在当前模型中将对侧扰动样本添加到数据集(第3节)。 更准确地说,我们的对手生成的样本大致对应于Tikhonov正则化Newton-steps 关于语义空间中的损失。 此外,我们表明,对于softmax损失,我们方法的每次迭代都可以被认为是一种依赖于数据的正则化方案,其中我们向与真实标签相对应的参数向量进行正则化,而不是像经典正则化器那样向零正则化,例如ridge 或者lasso。
从实际的角度来看,应用最坏情况公式(1)的关键难点在于协变量偏移ρ的大小是先验未知的。 我们提出学习一组对应于不同距离ρ的模型。 换句话说,我们的迭代方法生成一组数据集,每个数据集对应一个不同的数据集间距离水平ρ,我们为每个数据集学习一个模型。 在测试时,我们使用启发式方法从集合中选择合适的模型。
我们在简单的数字识别任务上测试我们的方法,并在不同的季节和天气条件下测试更现实的语义分割任务。 在这两种设置中,我们观察到我们的方法允许学习能够改善与原始源域具有不同距离的先验未知目标分布的性能的模型。
相关工作
关于对抗性训练的文献[10,34,20,12]与我们的工作密切相关,因为主要目标是设计训练程序,学习对输入波动具有鲁棒性的模型。与对抗性训练中考虑的难以察觉的攻击不同,我们的目标是学习抵抗较大扰动的模型,即分布式样本。 Sinha等。 [34]提出了一种原则性的对抗性训练程序,其中生成最大化某些风险的新图像,并且针对那些对抗性图像优化模型参数。设计用于防御难以察觉的对抗性攻击,新的图像是在损失的情况下学习的,这种损失会惩罚原始图像和新图像之间的差异。在这项工作中,我们依赖于类似于Sinha等人提出的极小极大游戏。 在[34]中,是我们在语义空间中强加了约束,以便允许来自虚拟分布的对抗样本在像素级别上不同,同时共享相同的语义。
关于领域适应的大量工作[15,3,32,9,39,36,26,40]旨在更好地推广到在训练时标识未知的先验固定目标领域。这种设置与我们的不同之处在于这些算法需要在训练期间从目标分布访问样本。领域概括方法[28,22,27,33,24]提出了更好地推广到未知领域的不同方法,这也与我们的工作有关。这些算法要求从不同的域中提取训练样本(同时在训练期间可以访问域标签),而不是单个源,这是我们的方法没有的限制。从这个意义上讲,人们可以将我们的问题设置解释为无监督域概括。托宾等人。 [37]提出了域随机化,它适用于模拟数据并使用模拟器创建各种随机渲染,希望现实世界将被解释为其中之一。我们的目标是相同的,因为我们的目标是获得更类似于现实世界的数据分布,但我们通过实际学习新数据点来实现它,从而使我们的方法适用于任何数据源而无需模拟器。
Hendrycks和Gimpel [13]认为,检测测试样本是否超出给定模型的分布的一种好的经验方法是评估softmax输出的统计数据。我们在我们的设置中调整这个想法,学习用我们的方法训练的模型的集合,并在测试时选择具有最大最大softmax值的模型。
2.模型方法
3.理论思想
4.实验
5.结论
更新中。。。
最后
以上就是尊敬乌龟最近收集整理的关于Generalizing to Unseen Domains via Adversarial Data Augmentation 正文的全部内容,更多相关Generalizing内容请搜索靠谱客的其他文章。








发表评论 取消回复