背景
- 端到端的语音识别需要大量成对的语音-文本数据,以获得更好的performance。然而目前来说成对的数据是相对较少的
- 相比于有标签的语音文本对,无标签的语音数据更多
- ASR模型的准确率依赖语言模型的rescoring,而大量的纯文本数据可以用于语言模型的构建
举例来说,LAS[1]的Decoder充当了传统方法的语言模型模块,而这一模型是在大约15 million个对话(audio-text pairs)的数据集(Google Voice Search)上训练的, 而当前最好的语言模型实在大约是在10亿个词或者更多的数据集上训练得到[2],这就是为什么LAS在结合额外的LM后,能获得大约5%的WER缩减[1]。
语言模型的引入帮助到语义信息的建模,可以显著地提升ASR模型的准确率表现。然而,额外语言模型的挂载,也带来了以下的问题。
- 额外的rescoring流程, 加大了整个pipeline的时延,无法满足某些识别实时性要求非常高的场景,如同声传译
- 参数冗余。对比来说,BERT-Base模型的参数量约为110 million,而GPT-2 的参数量则达到15 亿,虽然一般的ASR模型不会使用到如此巨大的LM,但是额外LM的融合,必将加大语音识别模型整体的参数量
- 由于声学模型与语言模型并不是同时训练的,其优化的目标也不一致,所以误差累积不可避免。
综上所述,为了使端到端的ASR模型能获得更好的准确率与性能表现,必须充分利用未标注的数据,包括纯语音与纯文本,在不依赖与额外的语言模型情况下,在模型结构上下功夫,将这一部分先验知识赋予模型本身。
无监督学习
使模型从无标签数据学习到数据特征抽取,表征,预测的能力,侧面达到数据增强的作用。
具体方法举例
1. 知识迁移 + 预训练文本嵌入[3]
利用text-to-intent数据在BERT上微调,预训练一个classifier,随后这个classfier与speech-to-intent模型共享最后一个classfication layer。在这个layer上,迫使声学嵌入匹配更好的文本嵌入。需要说明的是,text-to-intent类型的数据远多于speech-to-intent的数据量。
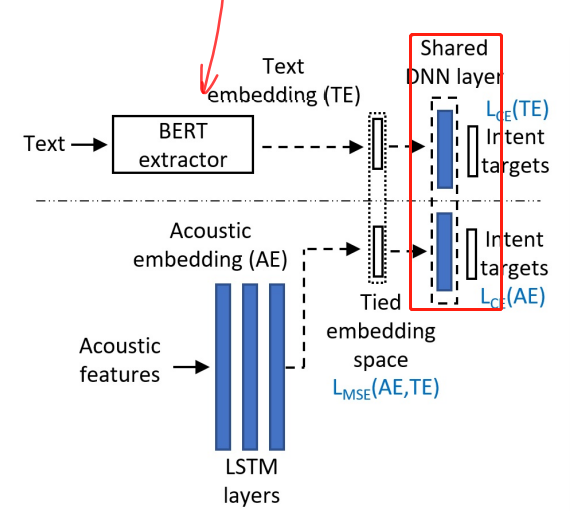
虽然原文的目的是训练一个speech-to-intent的模型,与一般的ASR模型有一定区别。但其提供以下几点思想依然值得学习。
- 是否可以预训练一个LM与ASR在最后几层共享参数,将LM的知识迁移到ASR模型本身。
- 对照speech-to-intent与text-to-intent的关系,是否可以比对延伸到text-text和speech-text的关系,预训练text-text(类似于机器翻译)分类器,再让ASR来学习其概率分布等知识。
值得注意的是,图中虚线上部,即text embedding部分仅在训练是需要,在测试阶段可以去除,达到精简模型参数的作用。
2. Mask + Reconstruction+Multi-task
借鉴BERT的Masked思想,以一定的几率随机mask掉纯文本或纯语音的部分tokens,在通过需要预训练的Encoder来重建(或者说预测)原本处理前的句子。
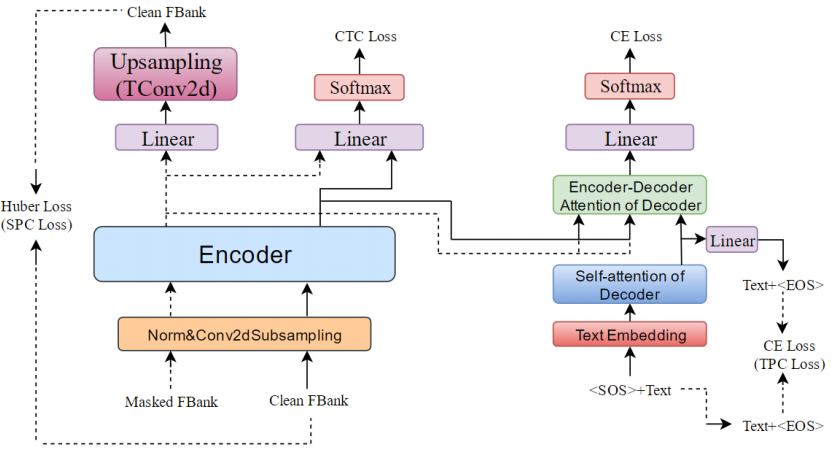
在[4]中, SPC模型利用重建损失从掩盖的声学特征中预测干净的声学特征,这使SPC模型能够学习语音帧内的相互关系,例如中间语音帧与前后帧之间的关系。
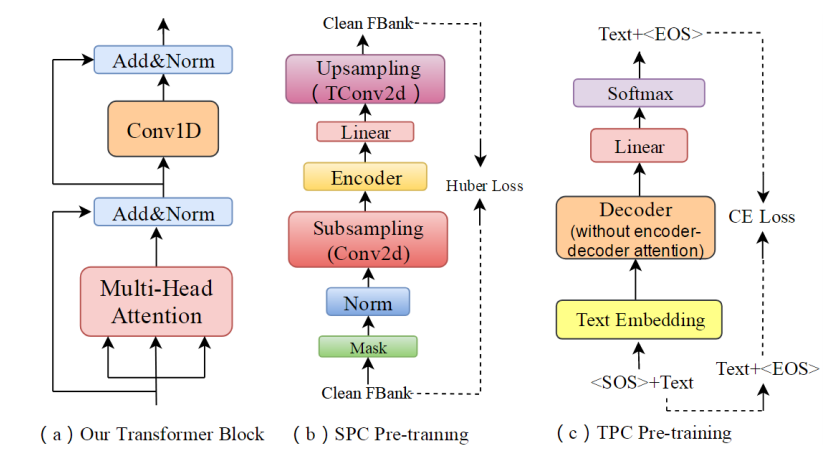
TPC的作用类似于SPC,SPC与TPC分别对应于预训练的Encoder和Decoder。通过多任务语义知识学习,Transformer在微调过程中继续学习声学和语言语义知识,防止微调阶段的训练忘记先前预训练得到的声学和语言语义知识。如下图:
3. Wav2Vec[5]
此方法是利用未标注的语音文件,将语音转化成更高级的向量表示。在大量未标记音频数据上训练wav2vec,相当于训练一个针对音频的embbeding,得到的表征结果可以用于下游任务,改进声学模型训练,实验表明,使用wav2vec转化的向量作为ASR的输入,在只有数个小时的ranscribed data 可用的情况下,相比于 log-mel filterbank baseline实现了36%的WER缩减。
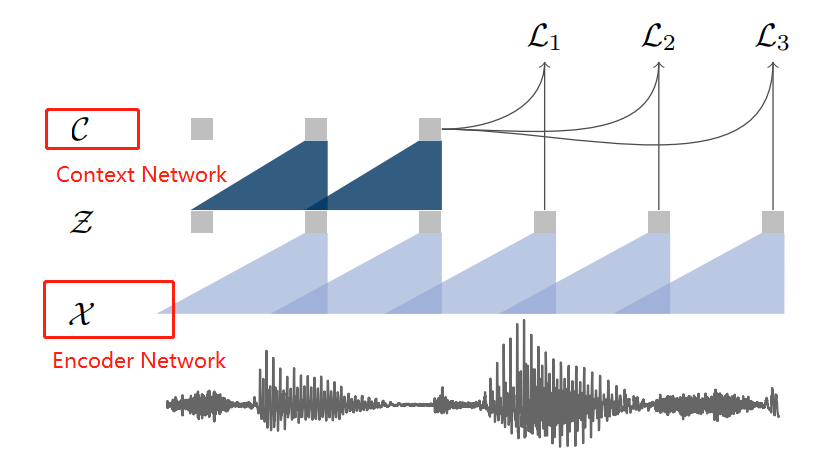
如图,encoder network将音频信号嵌入到一个潜在的空间中,而context network络结合编码器的多个时间步长来获得上下文化的表示。
实验结果表明,通过大量unlabeled audio数据学到的embbedings具有极强的特征表征能力,并能够捕捉音频上下文,从而有效提升下游任务的表现。
半监督学习
标签数据+无标签数据混合成的训练数据,侧面达到数据增强的作用。
具体方法
Self-Training
无标签的数据输入到训练好的模型得到预测的标签值,这样得到的一组新的有标注数据对(x,y),并将其作为训练集的一部分重新用于训练模型,不断重复此步骤。大致流程如下:

引自:https://blog.csdn.net/tyh70537/article/details/80244490
而将Self-training用于语音识别。[6]提供了思路。
- 在通过监督训练得到的模型上,输入无标签的audio得到伪标签(pseudo label), 组成一组新的伪成对数据
- 设计两个基于启发式的过滤函数,进一步与传统的基于置信度的过滤相结合,并将这两种过滤技术应用于sentence level,从而过滤掉不符合要求的伪数据
- 利用多个模型进行self-training,在推理过程中结合模型得分,生成一个质量更高的伪标记集
循环一致性(cycle consistency)
这种方法的基本思想是,如果一个模型将输入数据转换为输出数据,而另一个模型从输出数据重建输入数据,那么输入数据及其重建应该是相似的。
[7]通过结合ASR和TTS两种模型对纯文本和纯音频进行转换和重建,进而构造循环,并比较优化其一致性。
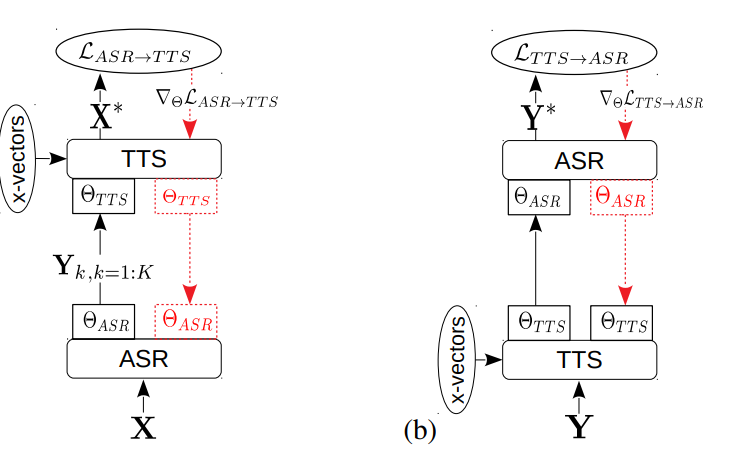
- 输入的未标注音频通过ASR-TTS得到输出的音频,两者之间通过目标函数 ℓ A S R − T T S ell_{ASR-TTS} ℓASR−TTS优化一致性
- 输入的未标注文本通过TTS-ASR得到输出的文本,两者之间通过目标函数 ℓ T T S − A S R ell_{TTS-ASR} ℓTTS−ASR优化一致性
- 由于目的是提高ASR模型的表现,在反向传播过程中,只有ASR的参数会得到更新
一致性训练(Consistency Regularization)
主要思想是:对于一个输入,即使受到微小干扰,其预测都应该是一致的。
- TODO
参考文献
[1] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, attend and spell,”CoRR, vol. abs/1508.01211, 2015.
[2] Kannan, A., Wu, Y., Nguyen, P., Sainath, T. N., Chen, Z., and Prabhavalkar, R., “An analysis of incorporating an external language model into a sequence-to-sequence model”, arXiv e-prints, 2017.
[3] Huang, Y., “Leveraging Unpaired Text Data for Training End-to-End Speech-to-Intent Systems”, arXiv e-prints, 2020.
[4] Li, S., Li, L., Hong, Q., Liu, L. (2020) Improving Transformer-Based Speech Recognition with Unsupervised Pre-Training and Multi-Task Semantic Knowledge Learning. Proc. Interspeech 2020, 5006-5010, DOI: 10.21437/Interspeech.2020-2007.
[5] Schneider, S., Baevski, A., Collobert, R., and Auli, M., “wav2vec: Unsupervised Pre-training for Speech Recognition”, arXiv e-prints, 2019.
[6] J. Kahn, A. Lee and A. Hannun, “Self-Training for End-to-End Speech Recognition,” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020, pp. 7084-7088, doi: 10.1109/ICASSP40776.2020.9054295.
[7] Baskar, M.K., Watanabe, S., Astudillo, R., Hori, T., Burget, L., Černocký, J. (2019) Semi-Supervised Sequence-to-Sequence ASR Using Unpaired Speech and Text. Proc. Interspeech 2019, 3790-3794, DOI: 10.21437/Interspeech.2019-3167.
最后
以上就是虚拟芒果最近收集整理的关于语音识别中半监督与无监督训练的全部内容,更多相关语音识别中半监督与无监督训练内容请搜索靠谱客的其他文章。








发表评论 取消回复