训练决策树有三个关键问题:
1.对于分类树,大量的正常数据在其中之混杂着一个两个的异常数据,所以分类结果很可能认为出现的数据都是正常的。
为了避免这种情况的出现,我们设置先验概率(例如根据今天的天气,来预测明天的天气),异常出现的情况,我们人为进行增加,这样决策树就会被适当的增加。
设Qj为设置的第j个先验概率,Nj为该分类的样本数,则考虑了样本率并进行归一化处理的先验概率qj为:
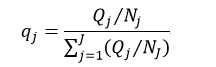
把先验概率带入到
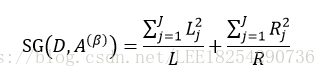
可以得到:
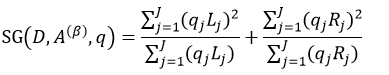
2.某些样本缺失某个特征属性,但该特征属性又是最佳分叉属性,如何对该样本进行分叉?
解决方法: 1.直接删掉该样本。
2.用各种算法估算该样本的缺失属性值。
3.用一个属性来代替最佳分叉属性(CART算法就是采用这种算法)
下面说一下第三种方法:
寻找替代分叉属性总的原则就是使其分叉的效果与最佳分叉属性相似,即分叉的误差最小。
根据特征属性是类还是数值的形式,把替代分叉属性的计算为分两种情况。
当特征属性是类的形式的时候,且当最佳分叉属性不是该特征属性时,会把该特征属性的每个种类分叉为不同的分支。这句话比较拗口,其意思是说:你在约妹子的时候,该特征属性是你想约妹子的决心,最佳分叉属性是你兜里有多少钱。这两种属性,一个是类,一个是数值。我们就把约妹子的决心分成不同分支,如十分想约的4个分成不同分支(3个属于左分支,1个属于右分支)。
但当最佳分叉属性是决心时,这种情况不会发生了。也就是说,十分想的这个分类,要么4个都在左分支,要么都在右分支。
因此我们把被最佳分叉属性分叉的特征属性种类的分支最大样本数量作为该种类的分叉值,计算该特征属性所有种类的这些分叉值,最终这些分叉值之和就作为该替代分叉属性的分叉值。
当特征属性是数值的形式的时候,样本被分割成了四个部分:LL、LR、RL和RR,前一个字母表示被最佳分叉属性分叉为左右分支,后一个字母表示被替代分叉属性分叉为左右分支,如LR表示被最佳分叉属性分叉为左分支,但被替代分叉属性分叉为右分支的样本,因此LL和RR表示的是被替代分叉属性分叉正确的样本,而LR和RL是被替代分叉属性分叉错误的样本,在该特征属性下,选取阈值对样本进行分割,使LL+RR或LR+RL达到最大值,则最终max{LL+RR,LR+RL}作为该特征属性的替代分叉属性的分叉值。按照该方法再计算其他特征属性是数值形式的替代分叉值,则替代性也由替代分叉值按从大到小进行排序。最终我们选取替代分叉值最大的那个特征属性作为该最佳分叉属性的替代分叉属性。
为了让替代分叉属性与最佳分叉属性相比较,我们还需要对替代分叉值进行规范化处理,如果替代分叉属性是类的形式,则替代分叉值需要乘以式12再除以最佳分叉属性中的种类数量,如果替代分叉属性是数值的形式,则替代分叉值需要乘以式19再除以所有样本的数量。规范化后的替代分叉属性如果就是最佳分叉属性时,两者的值是相等的。
3.过拟合
决策树的建立完全依赖于训练样本,因此该决策树对该样本能够产生完全一致的拟合效果。但这样的决策树对于预测样本来说过于复杂,对预测样本的分类效果也不够精确。这种现象被称为过拟合。
最后
以上就是虚幻火车最近收集整理的关于决策树详解(三)1.对于分类树,大量的正常数据在其中之混杂着一个两个的异常数据,所以分类结果很可能认为出现的数据都是正常的。2.某些样本缺失某个特征属性,但该特征属性又是最佳分叉属性,如何对该样本进行分叉?3.过拟合的全部内容,更多相关决策树详解(三)1.对于分类树,大量内容请搜索靠谱客的其他文章。








发表评论 取消回复