0.机器学习中分类与预测算法的评价指标
1)准确率
2)速度
3)强壮性(算法稳定)
4)可规模性(适应于不同规模)
5)可解释性(容易解释结果)
1.基本流程
1)定义:决策树是一个类似于流程图的树结构;其中,每个内部节点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶节点代表类或类分布。树的最顶层是根结点;
2)地位:决策树归纳是一类最简单也是最成功的机器学习方法;
3)表示法:决策树表示一个函数,以属性值向量作为输入,返回一个简单的决策结果(当输入值和输出值为二值时,输入被分为正例和反例);
4)表达能力:布尔决策树逻辑上等价于断言:目标属性为真,当且仅当输入属性满足一条通向带true值叶结点的路径;
2.划分选择(选择测试属性)
1) 属性选择思想(策略即最小化最终树的深度)
贪婪"分化-征服"策略,优先选择最重要属性 (最重要属性:对于样例分类具有最大差异的属性)
2)熵:随机变量的不确定性度量,信息的获取对应与熵的减少,它刻画了任意样例集的纯度(purity);
一般的,设随机变量V具有值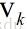 ,
,的概率为
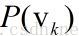
熵的定义为:
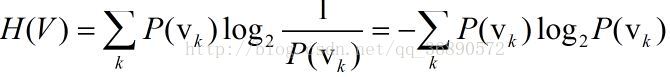
3)信息增益:
剩余的期望熵:
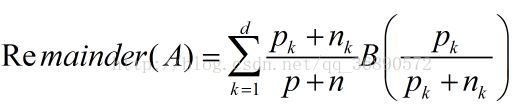
信息收益:
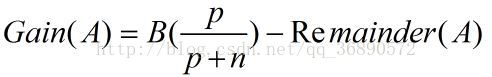
3.剪枝处理(泛化与过度拟合)
1)泛化:学习得到的模型能够指导一般情况下实例的能力;
2)过度拟合:模型过于注重训练样本的细节特征,而失去了一般情况下的预测能力;
3)决策树剪枝处理:减轻过度拟合,通过删除不明显相关的结点来实现剪枝(不相关属性通过信息收益去发现)
4.连续与缺省值
5.多变量决策树
6.应用
1)丢失数据
2)多值属性
3)连续和整型值输入属性
4)连续值输出属性
7.决策树优缺点
1)优点
直观、便于理解、小规模数据集有效
2)缺点
a.处理连续变量效果不好;b.类别较多时,错误增加的比较快;c.可规模新一般
最后
以上就是落后流沙最近收集整理的关于决策树(理论)的全部内容,更多相关决策树(理论)内容请搜索靠谱客的其他文章。








发表评论 取消回复