1 常用内建模块
1.1 math
math库是Python的标准库,提供了诸多的数学函数,可以使用整数和浮点数的数学运算。
| 函数 | 含义 |
| math.sqrt() | 计算平方根,返回的数据为浮点型数据 |
| math.log(x,y) | 计算对数,其中x为真数,y为底数 |
| math.ceil() | 向上取整操作 |
| math.floor() | 向下取整操作 |
| math.pow(底数,指数) | 计算一个数值的N次方 |
| math.fabs() | 计算一个数值的绝对值 |
| math.pi | 圆周率 |
| math.e | 自然常数e |
| math.trunc(x) | 返回x的整数部分 |
| math.modf(x) | 返回x的小数和整数 |
| math.fmod(x,y) | 取余 |
| math.fsum([x,y,·····]) | 返回序列中各元素之和 |
| math.factorial(x) | 返回x的阶乘 |
| math.gcd(x,y) | 返回整数x和y的最大公约数 |
| math.isnan(x) | 若x不是数字,返回True,否则返回False |
| math.sin(x) | 返回x(弧度)的三角正弦值 |
| math.asin(x) | 返回x的反三角正弦值 |
| math.cos(x) | 返回x(弧度)的三角余弦值 |
| math.acos(x) | 返回x的反三角余弦值 |
| math.tan(x) | 返回x(弧度)的三角正切值 |
| math.atan(x) | 返回x的反三角正切值 |
学习该库更多的相关用法,可以阅读官方文档,math库
1.2 random
随机数是随机产生的数据(比如抛硬币),但时计算机是不可能产生随机值,真正的随机数也是在特定条件下产生的确定值,计算机不能产生真正的随机数,那么伪随机数也就被称为随机数。
python中用于生成伪随机数的函数库是random。因为是标准库,使用时候只需要import random
| 函数 | 含义 |
|---|---|
| random.seed(a=None) | Python中产生随机数使用随机数种子来产生(只要种子相同,产生的随机序列,无论是每一个数,还是数与数之间的关系都是确定的,所以随机数种子确定了随机序列的产生) |
| random.random() | 生成一个[0.0,1.0)之间的随机小数 |
| random.randint(a,b) | 生成一个[a,b]之间的随机整数 |
| random.randrange(m,n[,k]) | 生成一个[m,n)之间以k(默认为1)为步长的随机整数 |
| random.uniform(a,b) | 生成一个[a,b]之间的随机小数 |
| random.choice(seq) | 从序列中随机选择一个元素 |
| random.shuffle(seq) | 将序列seq中元素随机排列,返回打乱后的序列 |
学习该库更多的相关用法,可以阅读官方文档,random库
1.3 time & datetime
Python中内置了一些与时间处理相关的库,如time、datatime和calendar库。其中time库是Python中处理时间的标准库,是最基础的时间处理库。time库的功能如下:
(1)计算机时间的表达
(2)提供获取系统时间并格式化输出功能
(3)提供系统级精确计时功能,用于程序性能分析
| 函数 | 含义 |
|---|---|
| time.asctime([tupletime]) | 接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串 |
| time.localtime([secs]) | 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时) |
| time.gmtime([sec]) | 将时间戳类型的时间转换为UTC中的struct_time,其中dst标志始终为零 |
| time.mktime(t) | 将struct_time类型的时间转换为时间戳类型 |
| time.sleep() | 推迟调用线程的运行,secs指秒数 |
| time.strftime(fmt[,tupletime]) | 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定 |
| time.strptime(str,fmt=‘%a %b %d %H:%M:%S %Y’) | 根据fmt的格式把一个时间字符串解析为时间元组 |
| time.time( ) | 返回当前时间的时间戳(1970纪元后经过的浮点秒数) |
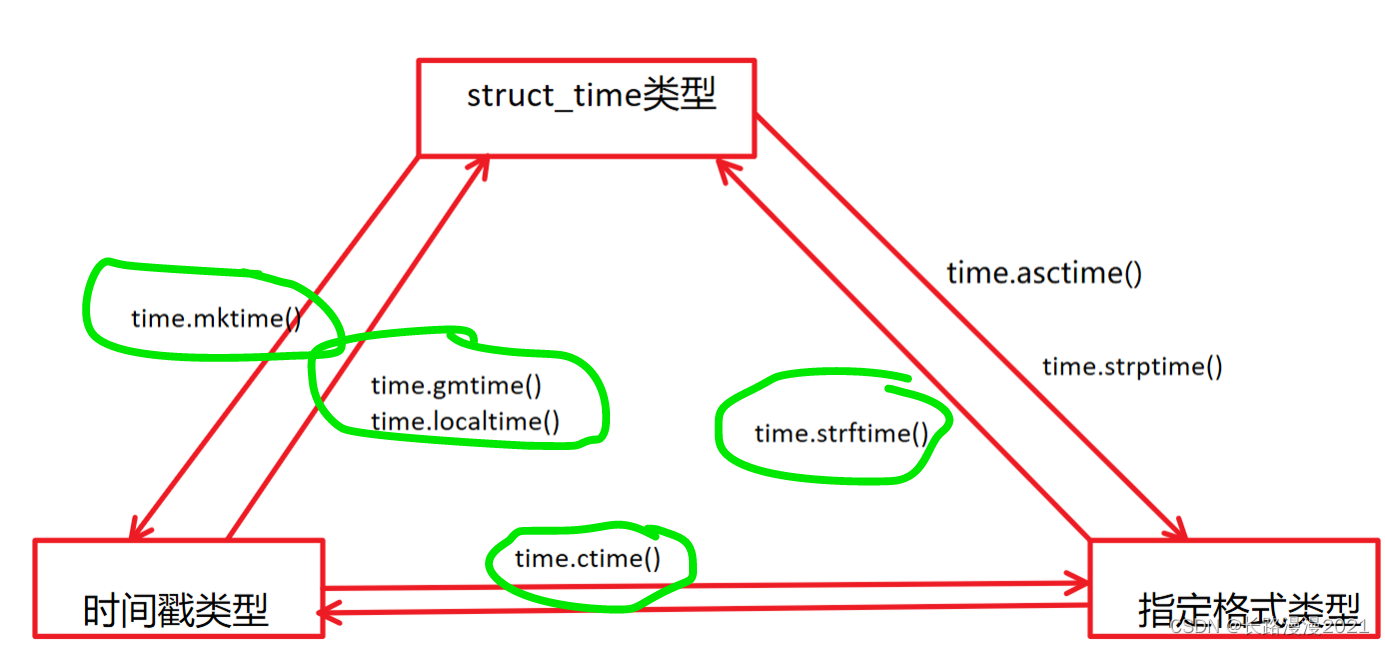
学习该库更多的相关用法,可以阅读官方文档,time库
在实际应用中datetime库也比较常用,datetime模块包含可用于处理日期和时间值的方法。要使用这个模块,我们得先通过以下import语句将其导入:
import datetime
可以使用time类表示时间值。时间类的属性包括小时、分钟、秒和微秒。time类的参数是可选的。尽管不指定任何参数,你将获得0的时间(对象),但这大多数时候不太可能是你需要的。
例如,要初始化值为 9小时、36分种、45秒、25微秒的时间对象,我们可以运行以下命令:
t = datetime.time(9, 36, 45, 25) # 09:36:45.000025
print(t)
print('hour:', t.hour) # hour: 9
print('Minutes:', t.minute) # Minutes: 36
print('Seconds:', t.second) # Seconds: 45
print('Microsecond:', t.microsecond) # Microsecond: 25
日历日期指可以通过date类表示。示例具有的属性有年、月和日。让我们来调用today方法来查看今天的日期:
today = datetime.date.today()
print(today) # 2022-09-22
调用ctime方法以另一种格式打印日期:
print('ctime:', today.ctime()) # ctime: Thu Sep 22 00:00:00 2022
ctime方法会使用比我们之前看到的示例更长的日期时间格式。此方法主要用于将 Unix 时间(从 1970 年 1 月 1 日以来的秒数)转换为字符串格式。
以下是我们如何使用date类显示年份,月份和日期:
print('Year:', today.year) # Year: 2022
print('Month:', today.month) # Month: 9
print('Day:', today.day) # Day: 22
我们将使用strftime方法。这个方法可以帮助我们将日期对象转换为可读字符串。它需要两个参数,语法如下所示:
time.strftime(format, t)
第一个参数是格式字符串(以何种格式显示时间日期),第二个参数是格式化的时间,可选值。
t = datetime.datetime(2022, 9, 22)
print(t.strftime("%b %d %Y %H:%M:%S")) # Sep 22 2022 00:00:00
完整的字符代码列表
除了上面给出的字符串外,strftime方法还使用了其他几个指令来格式化日期值:
%a: 返回工作日的前三个字符,例如 Wed。%A: 返回返回工作日的全名,例如 Wednesday。%b: 当地月份的缩写,例如 Feb。%B: 返回月份的全名,例如 September。%w: 返回工作日作为数字,从 0 到 6,周日为 0。%m: 将月份作为数字返回,从 01 到 12。%p: 返回 AM/PM 标识。%y: 返回两位数格式的年份,例如,”18“ 而不是 ”2018“。%f: 返回从 000000 到 999999 的微秒。%Z: 返回时区。%z: 返回 UTC 偏移量。%j: 返回当年的日期编号,从 001 到 366。%W: 返回年份的周数,从 00 到 53。星期一被记为一周第一天。%U: 返回年份的周数,从 00 到 53。星期日被记为一周第一天。%c: 返回本地日期和时间版本。%x: 返回本地日期版本。%X: 返回本地时间版本。
strftime方法帮助我们将日期对象转换为可读的字符串,strptime恰恰相反。它作用于字符串,并将它们转换成 Python可以理解的日期对象。语法格式如下:
datetime.strptime(string, format)
string参数是我们转换成日期格式的字符串值。format参数是指定转换后日期采用的格式的指令。
例如,如果我们需要将字符串 “9/15/18” 转换成datetime对象。
我们可以用字符串形式定义日期:
str = '9/22/22'
在将字符串转换为实际的datetime对象之前,Python 无法将上述字符串理解为日期时间。我们可以通过调用strptime方法成功完成:
str = '9/22/22'
date_object = datetime.datetime.strptime(str, '%m/%d/%y')
print(date_object) # 2022-09-22 00:00:00
学习该库更多的相关用法,可以阅读官方文档,datetime库
1.4 collections
collections的常用类型有:
- 计数器(Counter)
- 双向队列(deque)
- 默认字典(defaultdict)
- 有序字典(OrderedDict)
- 可命名元组(namedtuple)
1. Counter
Counter 作为字典(dict)的一个子类用来进行hashtable计数,将元素进行数量统计、计数后返回一个字典,键值为元素:值为元素个数。
| 函数 | 含义 |
|---|---|
| Counter() | 获取各元素的个数,返回字典 |
| most_common(int) | 按照元素出现的次数进行从高到低的排序,返回前int个元素的字典 |
| elements() | 返回经过计数器Counter后的元素,返回的是一个迭代器 |
| update() | 和set集合的update一样,对集合进行并集更新 |
| substract() | 和update类似,只是update是做加法,substract做减法,从另一个集合中减去本集合的元素 |
| iteritems | 与字典dict的items类似,返回由Counter生成的字典的所有item,只是在Counter中此方法返回的是一个迭代器,而不是列表 |
| iterkeys | 与字典dict的keys方法类似,返回由Counter生成的字典的所有key,只是在Counter中此方法返回的是一个迭代器,而不是列表 |
| itervalues | 与字典dict的values方法类似,返回由Counter生成的字典的所有value,只是在Counter中此方法返回的是一个迭代器,而不是列表 |
from collections import *
s = 'abcbcaccbbad'
l = ['a', 'b', 'c', 'c', 'a', 'b', 'b']
d = {'2': 3, '3': 2, '17': 2}
# Counter 获取各元素的个数,返回字典
print(Counter(s)) # Counter({'b': 4, 'c': 4, 'a': 3, 'd': 1})
print(Counter(l)) # Counter({'b': 3, 'a': 2, 'c': 2})
print(Counter(d)) # Counter({'2': 3, '3': 2, '17': 2})
# most_common(int) 按照元素出现的次数从高到低的排序,返回前int个元素的字典
m1 = Counter(s)
print(m1) # Counter({'b': 4, 'c': 4, 'a': 3, 'd': 1})
print(m1.most_common(3)) # [('b', 4), ('c', 4), ('a', 3)]
e1 = Counter(s)
print(''.join(sorted(e1.elements()))) # aaabbbbccccd
e2 = Counter(d)
print(sorted(e2.elements())) # ['17', '17', '2', '2', '2', '3', '3']
u1 = Counter(s)
u1.update('123a')
print(u1) # Counter({'a': 4, 'b': 4, 'c': 4, 'd': 1, '1': 1, '2': 1, '3': 1})
sub1 = 'which'
sub2 = 'whatw'
subset = Counter(sub1)
print(subset) # Counter({'h': 2, 'w': 1, 'i': 1, 'c': 1})
subset.subtract(Counter(sub2))
print(subset) # Counter({'h': 1, 'i': 1, 'c': 1, 'w': -1, 'a': -1, 't': -1})
2. deque
deque 包含在文件_collections.py中,属于高性能的数据结构(High performance data structures)之一。可以从两端添加和删除元素,常用的结构是它的简化版。
| 函数 | 含义 |
|---|---|
| append() | 队列右边添加元素 |
| appendleft() | 队列左边添加元素 |
| clear() | 清空队列中的所有元素 |
| count() | 返回队列中包含value的个数,结果类型为 integer |
| extend() | 队列右边扩展,可以是列表、元组或字典,如果是字典则将字典的key加入到deque |
| extendleft() | 同extend, 在左边扩展 |
| pop() | 移除并且返回队列右边的元素 |
| popleft() | 移除并且返回队列左边的元素 |
| remove() | 移除队列第一个出现的元素(从左往右开始的第一次出现的元素value) |
| reverse() | 队列的所有元素进行反转 |
| rotate(n) | 对队列的数进行移动,若n<0,则往左移动即将左边的第一个移动到最后,移动n次,n>0 往右移动 |
str1 = 'abc123cd'
dq = deque(str1)
print(dq) # deque(['a', 'b', 'c', '1', '2', '3', 'c', 'd'])
dq = deque('abc123')
dq.extend({1:10, 2:20})
dq.extendleft('L')
print(dq) # deque(['L', 'a', 'b', 'c', '1', '2', '3', 1, 2])
dq = deque([1, 2, 3, 4, 5])
dq.rotate(-1)
print(dq) # deque([2, 3, 4, 5, 1])
3. defaultdict
默认字典,是字典的一个子类,继承有字典的方法和属性,默认字典在进行定义初始化的时候可以指定字典值的默认类型:
dic = defaultdict(dict)
dic['k1'].update({'k2': 'aaa'})
print(dic) # defaultdict(<class 'dict'>, {'k1': {'k2': 'aaa'}})
看上面的例子,字典dic在定义的时候就定义好了值为字典类型,虽然现在字典中还没有键值 k1,但仍然可以执行字典的update方法。这种操作方式在传统的字典类型中是无法实现的,必须赋值以后才能进行值得更新操作,否则会报错。看一下传统的字典类型:
b = dict()
b['k1'].append('2')
# TypeError: 'type' object is not iterable
4. OrderedDict
OrderDict 叫做有序字典,也是字典类型(dict)的一个子类,是对字典的一个补充。 前面我们说过,字典类型是一个无序的集合,如果要想将一个传统的字典类型进行排序一般会怎么做了,我们可能会将字典的键值取出来做排序后在根据键值来进行有序的输出,看下面的一个例子:
dic1 = dict()
dic1['a'] = '123'
dic1['b'] = 'jjj'
dic1['c'] = '394'
dic1['d'] = '999'
print(dic1) # {'a': '123', 'b': 'jjj', 'c': '394', 'd': '999'}
# 方法一
dic1_key_list = []
for k in dic1.keys():
dic1_key_list.append(k)
dic1_key_list.sort()
for key in dic1_key_list:
print('dic1字典排序结果 %s:%s'%(key, dic1[key]))
# 方法二
dic1_list = list(dic1.items())
dic1_list.sort(key = lambda item: item[0])
for i in range(len(dic1_list)):
print("dic1排序结果 %s: %s" % (dic1_list[i][0], dic1_list[i][1]))
以上为定义传统字典类型时的一个简单排序过程。 如果我们定义一个有序字典时,将不用再如此麻烦,字典顺序将按照录入顺序进行排序且不会改变。
dic2 = OrderedDict()
dic2['a'] = '123'
dic2['b'] = 'jjj'
dic2['c'] = '394'
dic2['d'] = '999'
for k, v in dic2.items():
print("有序字典:%s:%s" % (k, v))
5. nametuple
标准的tuple类型使用数字索引来访问元素,
bob = ('Bob', 30, 'male')
print("Representation:", bob) # Representation: ('Bob', 30, 'male')
jane = ('Jane', 29, 'female')
print('nField by index:', jane[0])
print('nFields by index:')
for p in [bob, jane]:
print('%s is a %d year old %s' % p)
这种对于标准的元组访问,我们需要知道元素对应下标索引值,但当元组的元素很多时,我们可能无法知道每个元素的具体索引值,这个时候就是可命名元组登场的时候了。
nametuple 的创建是由自己的类工厂nametuple()进行创建,而不是由标准的元组来进行实例化,通过nametuple()创建类的参数包括类名称和一个包含元素名称的字符串
P = namedtuple('Person', 'name, age, gender')
print('Type of Person:', type(P)) # Type of Person: <class 'type'>
bob = P(name='Bob', age=30, gender='male')
print('nRepresentation:', bob) # Representation: Person(name='Bob', age=30, gender='male')
jane = P(name='Jane', age=29, gender='female')
print('nField by name:', jane.name) # Field by name: Jane
print('nFields by index:')
for p in [bob, jane]:
print('%s is a %d year old %s' % p)
# Fields by index:
# Bob is a 30 year old male
# Jane is a 29 year old female
通过上面的实例可以看出,我们通过nametuple()创建了一个Person的类,并复制给P变量,Person的类成员包括name,age,gender,并且顺序已经定了,在实例化zhangsan这个对象的时候,对张三的属性进行了定义。这样我们在访问zhangsan这个元组的时候就可以通过张三的属性来复制(zhangsan.name、zhangsan.age等)。这样就算这个元组有1000个元素我们都能通过元素的名称来访问而不用考虑元素的下标索引值。
学习该库更多的相关用法,可以阅读官方文档,collections库
1.5 itertools
Python内建模块itertools提供了非常有用的用于操作迭代对象的函数。
首先,看看itertools提供的几个‘无限’迭代器:
>>> import itertools
>>> natuals = itertools.count(1)
>>> for n in natuals:
... print(n)
...
1
2
3
...
count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出。
cycle()会把传入的一个序列无限重复下去:
>>> import itertools
>>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
>>> for c in cs:
... print(c)
...
'A'
'B'
'C'
'A'
'B'
'C'
...
repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
>>> ns = itertools.repeat('A', 3)
>>> for n in ns:
... print(n)
...
A
A
A
...
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
>>> for c in itertools.chain('ABC', 'XYZ'):
... print(c)
# 迭代效果:'A' 'B' 'C' 'X' 'Y' 'Z'
groupby()把迭代器中相邻的重复元素挑出来放在一起:
>>> for key, group in itertools.groupby('AAABBBCCAAA'):
... print(key, list(group))
...
A ['A', 'A', 'A']
B ['B', 'B', 'B']
C ['C', 'C']
A ['A', 'A', 'A']
import itertools
# 产生ABCD的全排列
itertools.permutations('ABCD')
# 产生ABCDE的五选三组合
itertools.combinations('ABCDE', 3)
# 产生ABCD和123的笛卡尔积
itertools.product('ABCD', '123')
# 产生ABC的无限循环序列
itertools.cycle(('A', 'B', 'C'))
学习该库更多的相关用法,可以阅读官方文档,itertools库
参考
- Python常用模块:https://www.liaoxuefeng.com/wiki/1016959663602400/1017642838127488
- 日期和时间:https://www.runoob.com/python3/python3-date-time.html
- collections库:https://www.cnblogs.com/Ironboy/p/8745874.html
最后
以上就是想人陪小丸子最近收集整理的关于Python基础篇(十二)-- 常用模块的全部内容,更多相关Python基础篇(十二)--内容请搜索靠谱客的其他文章。








发表评论 取消回复