
来源:本文由RT-Thread社区成员梦千年撰写,点击文末阅读原文可查看出处。
前言
GPU即图形处理器,是现代显卡的核心。在没有GPU的时代,所有图形的绘制都是由CPU来完成的,CPU需要计算图形的边界、颜色等数据,并且负责将数据写入显存。简单的图形还没有什么问题,但随着计算机的发展(尤其是游戏的发展),需要显示的图形图像越来越复杂,CPU也就越来越力不从心。所以后来GPU应运而生,将CPU从繁重的图形计算任务中拯救了出来,大大加速了图形的显示速度。
而单片机这边也有类似的发展历程。在早期的单片机使用场景中,极少有图形显示的需求。即使有,也只是简单的12864之类的显示设备,运算量不大,单片机的CPU可以很好的处理。但是随着嵌入式图形的发展,单片机需要承担的图形计算和显示任务越来越多,嵌入式系统的显示分辨率和色彩也一路飙升。慢慢地,单片机的CPU对这些计算就开始力不从心了。所以,自STM32F429开始,一个类似GPU的外设开始加入到STM32的单片机中,ST称之为Chrom-ART Accelerator,也叫DMA2D(本文将使用此名称)。DMA2D可以在很多2D绘图的场合提供加速,完美嵌合了现代显卡中“GPU”的功能。
虽然这个“GPU”只能提供2D加速,而且功能非常简单,与PC中的GPU不可同日而语。但是它已经可以满足大多数嵌入式开发中的图形显示加速需求,只要用好了DMA2D,我们在单片机上也可以做出流畅、华丽的UI效果。
本文将从实例出发,介绍DMA2D在嵌入式图形开发中的可以发挥的作用。目的是使读者能简单、快速地对DAM2D的建立最基本的概念并且学会最基本的用法。为了防止内容过于晦涩和难懂,本文不会对DMA2D的高级功能和特性进行深入地刨析(如详细介绍DMA2D的架构、全部的寄存器等等)。如果需要更加详细、专业地学习DAM2D,可以在阅读完本文后参考《STM32H743中文编程手册》。
阅读本文之前需要对STM32中的TFT液晶控制器(LTDC)和基本的图形知识(如帧缓冲framebuffer、像素、颜色格式等概念)有一定的了解。
另,除了ST之外,其他不少厂商生产的MCU中也存在类似功能的外设(如NXP在RT系列中设计的的PxP),不过这些不在本文的讨论范围内,有兴趣的朋友可以自行了解。
准备工作
硬件准备
可以使用任何的,带有DMA2D外设的STM32开发板来验证本文中的例子,如STM32F429,STM32F746,STM32H750等MCU的开发板。本文中使用的开发板是ART-Pi 。ART-Pi是由RT-Thread官方出品的开发板,采用了主频高达480MHz的STM32H750XB+32MB SDRAM的强悍配置。而且板载了调试器(ST-Link V2.1),使用起来非常方便,特别适合各种技术方案的验证,用来作为本文的硬件演示平台再合适不过了。
显示屏可以是任意的彩色TFT显示屏,推荐使用16位或24位颜色的RGB接口显示屏。本文中使用的是一块 3.5‘’ 的TFT液晶显示屏,接口为RGB666,分辨率为320x240(QVGA)。在LTDC中,配置使用的颜色格式为RGB565

开发环境准备
本文中介绍的内容和出现的代码可以在任何你喜欢的开发环境中使用,如RT-Thread Studio,MDK,IAR等。
开始本文的实验前你需要一个以framebuffer技术驱动LCD显示屏的基本工程。运行本文中所有的代码前都需要预先使能DMA2D。
使能DMA2D可以通过这个宏来实现(硬件初始化时使能一次即可):
1// 使用DMA2D之前一定要先使能DMA2D外设
2__HAL_RCC_DMA2D_CLK_ENABLE();
DMA2D的简介
我们先来看看ST是怎么描述DMA2D的

乍一看有点晦涩,但其实说白了就以下几个功能:
颜色填充(矩形区域)
图像(内存)复制
颜色格式转换(如YCbCr转RGB或RGB888转RGB565)
透明度混合(Alpha Blend)
前两种都是针对内存的操作,后两个则是运算加速操作。其中,透明度混合、颜色格式转换可以和图像复制一起进行,这样就带来了较大的灵活性。
可以看到,ST对DMA2D的定位就像它的名字一样,是一个针对图像处理功能强化过的DMA。而在实际开发的过程中,我们会发现DMA2D的使用方式也非常类似传统的DMA控制器。在某些非图形处理场合,DMA2D甚至也可以代替传统的DMA来发挥作用。
需要注意的是,ST的不同产品线的DMA2D加速器是有微小区别的,比如STM32F4系列MCU的DMA2D就没有ARGB和AGBR颜色格式互转的功能,所以具体需要用到某个功能的时候,最好先查看编程手册看所需的功能是否被支持。
本文只介绍所有平台的DMA2D共有的功能。
DMA2D的工作模式
就像传统DMA有外设到外设,外设到存储器,存储器到外设三种工作模式一样,DMA2D作为一个DMA,也分为以下四种工作模式:
寄存器到存储器
存储器到存储器
存储器到存储器并执行像素颜色格式转换
存储器到存储器且支持像素颜色格式转换和透明度混合
可以看出,前两种模式起始就是简单的内存操作,而后面两种模式,则是在进行内存复制时,根据需要同时进行颜色格式转换或/和透明度混合。
DMA2D和HAL库
大多数情况下,使用HAL库可以简化代码编写,提高可移植性。但是在DMA2D的使用时则是个例外。因为HAL库存在的最大问题就是嵌套层数再加上各种安全检测过多效率不够高。在操作别的外设时,使用HAL库损失的效率并不会有多大的影响。但是对于DMA2D这种以计算和加速为目的的外设,考虑到相关的操作会在一个屏幕的绘制周期内被多次调用,此时再使用HAL库就会导致DAM2D的加速效率严重下降。
所以,我们大多时候都不会用HAL库中的相关函数来对DMA2D进行操作。为了效率,我们会直接操作寄存器,这样才能起到最大化的加速效果。
因为我们使用DMA2D的大多数场合都会频繁变更工作模式,所以CubeMX中对DMA2D的图形化配置也失去了意义。
DMA2D场景实例
1. 颜色填充
下图是一个简单的柱状图:

我们来思考一下如何把它绘制出来。
首先,我们需要使用白色来填充屏幕,作为图案的背景。这个过程是不能忽略的,否则屏幕上原来显示的图案会对我们的主体产生干扰。然后,柱状图其实是由4个蓝色的矩形方块和一条线段构成的,而线段也可以视作一个特殊的,高度为1的矩形。所以,这个图形的绘制可以分解为一系列“矩形填充”操作:
使用白色填充一个大小等于屏幕大小的的矩形
使用蓝色填充四个数据条
使用黑色填充一根高度为1的线段
在画布中实现任意位置绘制任意大小的矩形的本质就是将内存区域中对应像素位置的数据设定为指定的颜色。但是因为framebuffer在内存中的存储是线性的,所以除非矩形的宽度正好和显示区域的宽度重合,否看似连续的矩形的区域在内存中的地址是不连续的。
下图展示了典型的内存分布情况,其中的数字表示了frame buffer中每个像素的内存地址(相对首地址的偏移,这里忽略掉了一个像素占多个字节的情况),蓝色区域是我们要填充的矩形。可以看出矩形区域的内存地址是不连续的。

framebuffer的这种特性使得我们不能简单使用memset这类高效的操作来实现矩形区域的填充。通常情况下,我们会使用以下方式的双重循环来填充任意矩形,其中xs和ys是矩形左上角在屏幕上的坐标,width和height表示矩形的宽和高,color表示需要填充的颜色:
1for(int y = ys; y < ys + height; y++){
2 for(int x = xs; x < xs + width; x++){
3 framebuffer[y][x] = color;
4 }
5}
代码虽然简单,但实际执行时,大量的CPU周期浪费在了判断、寻址、自增等的操作,实际写内存的时间占比很少。这样一来,效率就会下降。
这时候DMA2D的寄存器到存储器工作模式就可以发挥用场了,DAM2D可以以极高的速度填充矩形的内存区域,即使这些区域在内存中实际是不连续的。
依然以这张图中演示的情况为例,我们来看它是如何实现的:

首先,因为我们只是进行内存填充,而不需要进行内存拷贝,所以我们要让DAM2D工作在寄存器到存储器模式。这通过设置DMA2D的CR寄存器的[17:16]位为11来实现,代码如下:
1DMA2D->CR = 0x00030000UL;然后,我们要告诉DAM2D要填充的矩形的属性,比如区域的起始地址在哪里,矩形的宽度有多少像素,矩形的高度有多少。
区域起始地址是矩形区域左上角第一个像素的内存地址(图中红色像素的地址),这个地址由DAM2D的OMAR寄存器管理。而矩形的宽度和高度都是以像素为单位的,分别由NLR寄存器的高16位(宽度)和低16位(高度)来进行管理,具体的代码如下:
1DMA2D->OMAR = (uint32_t)(&framebuffer[y][x]); // 设置填充区域的起始像素内存地址
2DMA2D->NLR = (uint32_t)(width << 16) | (uint16_t)height; // 设置矩形区域的宽高接着,因为矩形在内存中的地址不连续,所以我们要告诉DMA2D在填充完一行的数据后,需要跳过多少个像素(即图中黄色区域的长度)。这个值由OOR寄存器管理。计算跳过的像素数量有一个简单的方法,即显示区域的宽度减去矩形的宽度即可。具体实现代码如下:
1DMA2D->OOR = screenWidthPx - width; // 设置行偏移,即跳过的像素最后,我们需要告知DAM2D,你将使用什么颜色来进行填充,颜色的格式是什么。这分别由OCOLR和OPFCCR寄存器来管理,其中颜色格式由LTDC_PIXEL_FORMAT_XXX宏来定义,具体代码如下:
1DMA2D->OCOLR = color; // 设置填充使用的颜色
2DMA2D->OPFCCR = pixelFormat; // 设置颜色格式,比如想设置成RGB565,就可以使用宏LTDC_PIXEL_FORMAT_RGB565
一切都设置完毕,DMA2D已经获取到了填充这个矩形所需要的全部信息,接下来,我们要开启DMA2D的传输,这通过将DMA2D的CR寄存器的第0位设置为1来实现:
1DMA2D->CR |= DMA2D_CR_START; // 开启DMA2D的数据传输,DMA2D_CR_START是一个宏,其值为0x01
等DMA2D传输开始后,我们只需要等待它传输完毕即可。DAM2D传输完成后,会自动把CR寄存器的第0位设置为0,所以我们可以通过以下代码来等待DAM2D传输完成:
1while (DMA2D->CR & DMA2D_CR_START) {} // 等待DMA2D传输完成tips0:如果你使用了OS,则可以使能DMA2D的传输完毕中断。然后我们可以创建一个信号量并且在开启传输后等待它,随后在DMA2D的传输完毕中断服务函数中释放该信号量。这样的话CPU就可以在DMA2D工作的时候去干点别的事儿而不是在此处傻等。
tips1:当然,由于实际执行时,DMA2D进行内存填充的速度实在是太快了,以至于OS切换任务的开销都比这个时间要长,所以即便使用了OS,我们还是会选择死等 :)。
为了函数的通用性考虑,起始传输地址和行偏移都在函数外计算完毕后传入,我们抽出的完整的函数代码如下:
1static inline void DMA2D_Fill( void * pDst, uint32_t width, uint32_t height, uint32_t lineOff, uint32_t pixelFormat, uint32_t color) {
2
3 /* DMA2D配置 */
4 DMA2D->CR = 0x00030000UL; // 配置为寄存器到储存器模式
5 DMA2D->OCOLR = color; // 设置填充使用的颜色,格式应该与设置的颜色格式相同
6 DMA2D->OMAR = (uint32_t)pDst; // 填充区域的起始内存地址
7 DMA2D->OOR = lineOff; // 行偏移,即跳过的像素,注意是以像素为单位
8 DMA2D->OPFCCR = pixelFormat; // 设置颜色格式
9 DMA2D->NLR = (uint32_t)(width << 16) | (uint16_t)height; // 设置填充区域的宽和高,单位是像素
10
11 /* 启动传输 */
12 DMA2D->CR |= DMA2D_CR_START;
13
14 /* 等待DMA2D传输完成 */
15 while (DMA2D->CR & DMA2D_CR_START) {}
16}为了方便编写代码,我们再包装一个针对所使用屏幕坐标系的矩形填充函数:
1void FillRect(uint16_t x, uint16_t y, uint16_t w, uint16_t h, uint16_t color){
2 void* pDist = &(((uint16_t*)framebuffer)[y*320 + x]);
3 DMA2D_Fill(pDist, w, h, 320 - w, LTDC_PIXEL_FORMAT_RGB565, color);
4}最后我们尝试用代码把本小节刚开始的示例图表画出来:
1 // 填充背景色
2 FillRect(0, 0, 320, 240, 0xFFFF);
3 // 绘制数据条
4 FillRect(80, 80, 20, 120, 0x001f);
5 FillRect(120, 100, 20, 100, 0x001f);
6 FillRect(160, 40, 20, 160, 0x001f);
7 FillRect(200, 60, 20, 140, 0x001f);
8 // 绘制X轴
9 FillRect(40, 200, 240, 1, 0x0000);代码运行效果:

2.图片显示(内存复制)
假设我们现在要开发一个游戏,然后想在屏幕上显示一团跳动的火焰。一般是由美工先把火焰的每一帧都画出来,然后放到同一张图片素材里面,如下图所示:

然后我们以一定的间隔轮流显示每一帧图像,就可以在屏幕上实现“跳动的火焰”这个效果了。
我们现在略过素材文件加载到内存的过程,假设这张素材图片已经在内存中了。然后我们来考虑如何将其中的一帧图片显示到屏幕上。通常情况下,我们会这样实现:先计算得出每一帧的数据在内存中的地址,然后将这一帧图片的数据复制到framebuffer中相应的位置即可。代码类似于这样:
1/**
2 * 将素材中的一帧画面复制到framebuffer中的对应位置
3 * index为画面在帧序列中的索引
4 */
5static void General_DisplayFrameAt(uint16_t index) {
6 // 宏说明
7 // #define FRAME_COUNTS 25 // 帧数量
8 // #define TILE_WIDTH_PIXEL 96 // 每一帧画面的宽度(等于高度)
9 // #define TILE_COUNT_ROW 5 // 素材中每一行有多少帧
10
11 // 计算帧起始地址
12 uint16_t *pStart = (uint16_t *) img_fireSequenceFrame;
13 pStart += (index / TILE_COUNT_ROW) * (TILE_WIDTH_PIXEL * TILE_WIDTH_PIXEL * TILE_COUNT_ROW);
14 pStart += (index % TILE_COUNT_ROW) * TILE_WIDTH_PIXEL;
15
16 // 计算素材地址偏移
17 uint32_t offlineSrc = (TILE_COUNT_ROW - 1) * TILE_WIDTH_PIXEL;
18 // 计算framebuffer地址偏移(320是屏幕宽度)
19 uint32_t offlineDist = 320 - TILE_WIDTH_PIXEL;
20
21 // 将数据复制到framebuffer
22 uint16_t* pFb = (uint16_t*) framebuffer;
23 for (int y = 0; y < TILE_WIDTH_PIXEL; y++) {
24 memcpy(pFb, pStart, TILE_WIDTH_PIXEL * sizeof(uint16_t));
25 pStart += offlineSrc + TILE_WIDTH_PIXEL;
26 pFb += offlineDist + TILE_WIDTH_PIXEL;
27 }
28}
可见要实现这个效果需要大量的内存复制操作。在嵌入式系统中,需要大量数据复制的时候,硬件DMA的效率是最高的。但是硬件DMA只能搬运地址连续的数据,而这里,需要复制的数据在源图片和frambuffer中的地址都是不连续的,这引来了额外的开销(与第一小节中出现的问题相同),也导致我们无法使用硬件DMA来进行高效的数据复制。
所以,虽然我们实现了目标,但是效率不高(或者说没有达到最高)。
为了以最快的速度把素材图片中的某一块数据搬运到帧缓冲中,我们来看如何使用DMA2D来实现。
首先,因为这次是要在存储器中进行数据复制,所以我们要把DMA2D的工作模式设定为“存储器到存储器模式”,这通过设置DMA2D的CR寄存器的[17:16]位为00来实现,代码如下:
1DMA2D->CR = 0x00000000UL;然后我们要分别设置源和目标的内存地址,与第一节中不同,因为数据源也存在内存偏移,所以我们要同时设定源和目标位置的数据偏移
1DMA2D->FGMAR = (uint32_t)pSrc; // 源地址
2DMA2D->OMAR = (uint32_t)pDst; // 目标地址
3DMA2D->FGOR = OffLineSrc; // 源数据偏移(像素)
4DMA2D->OOR = OffLineDst; // 目标地址偏移(像素)然后依然是设置要复制的图像的宽和高,以及颜色格式,这点与第一小节中的相同
1DMA2D->FGPFCCR = pixelFormat;
2DMA2D->NLR = (uint32_t)(xSize << 16) | (uint16_t)ySize;同样的方式,我们开启DMA2D的传输,并等待传输完成:
1/* 启动传输 */
2DMA2D->CR |= DMA2D_CR_START;
3
4/* 等待DMA2D传输完成 */
5while (DMA2D->CR & DMA2D_CR_START) {}最终我们抽出的函数如下:
1static void DMA2D_MemCopy(uint32_t pixelFormat, void * pSrc, void * pDst, int xSize, int ySize, int OffLineSrc, int OffLineDst)
2{
3 /* DMA2D配置 */
4 DMA2D->CR = 0x00000000UL;
5 DMA2D->FGMAR = (uint32_t)pSrc;
6 DMA2D->OMAR = (uint32_t)pDst;
7 DMA2D->FGOR = OffLineSrc;
8 DMA2D->OOR = OffLineDst;
9 DMA2D->FGPFCCR = pixelFormat;
10 DMA2D->NLR = (uint32_t)(xSize << 16) | (uint16_t)ySize;
11
12 /* 启动传输 */
13 DMA2D->CR |= DMA2D_CR_START;
14
15 /* 等待DMA2D传输完成 */
16 while (DMA2D->CR & DMA2D_CR_START) {}
17}为了方便,我们包装一个调用它的函数:
1static void DMA2D_DisplayFrameAt(uint16_t index){
2
3 uint16_t *pStart = (uint16_t *)img_fireSequenceFrame;
4 pStart += (index / TILE_COUNT_ROW) * (TILE_WIDTH_PIXEL * TILE_WIDTH_PIXEL * TILE_COUNT_ROW);
5 pStart += (index % TILE_COUNT_ROW) * TILE_WIDTH_PIXEL;
6 uint32_t offlineSrc = (TILE_COUNT_ROW - 1) * TILE_WIDTH_PIXEL;
7
8
9 DMA2D_MemCopy(LTDC_PIXEL_FORMAT_RGB565, (void*) pStart, pDist, TILE_WIDTH_PIXEL, TILE_WIDTH_PIXEL, offlineSrc, offlineDist);
10}然后轮流播放每一帧图片,这里设置的帧间隔是50毫秒,并且将目标地址定义到了frambuffer的中央:
1while(1){
2 for(int i = 0; i < FRAME_COUNTS; i++){
3 DMA2D_DisplayFrameAt(i);
4 HAL_Delay(FRAME_TIME_INTERVAL);
5 }
6}最终运行的效果:

3.图片渐变切换
假设我们要开发一个看图应用,在两张图片进行切换时,直接进行切换会显得比较生硬,所以我们要加入切换时的动态效果,而渐变切换(淡入淡出)是一个很经常使用的,而且看起来还不错的效果。
就用这两张图片好了:

这里我们需要先了解一下透明度混合(Alpha Blend)的基本概念。首先透明度混合需要有一个前景,一个背景。而混合的结果就相当于透过前景看背景时的效果。如果前景完全不透明,那么就完全看不到背景,反之如果前景完全透明,那么就只能看到背景。而如果前景是半透明的,则结果就是两者根据前景色的透明度按照一定的规则进行混合。
如果1表示完全透明,0表示不透明,则透明度的混合公式如下,其中A是背景色,B是前景色:
1X(C)=(1-alpha)*X(B) + alpha*X(A)因为颜色有RGB三个通道,所以我们需要对三通道都进行计算,计算完成后在进行组合:
1R(C)=(1-alpha)*R(B) + alpha*R(A)
2G(C)=(1-alpha)*G(B) + alpha*G(A)
3B(C)=(1-alpha)*B(B) + alpha*B(A)
而在程序中为了效率起见(CPU对于浮点的运算速度很慢),我们并不用0~1这个范围的值。通常情况下我们一般会使用一个8bit的数值来表示透明度,范围从0~255。需要注意的是,这个数值越大表示越不透明,也就是说255是完全不透明,而0表示完全透明(所以也叫不透明度),然后我们可以得到最终的公式:
1outColor = ((int) (fgColor * alpha) + (int) (bgColor) * (256 - alpha)) >> 8;实现RGB565颜色格式像素的透明度混合代码:
1typedef struct{
2 uint16_t r:5;
3 uint16_t g:6;
4 uint16_t b:5;
5}RGB565Struct;
6
7static inline uint16_t AlphaBlend_RGB565_8BPP(uint16_t fg, uint16_t bg, uint8_t alpha) {
8 RGB565Struct *fgColor = (RGB565Struct*) (&fg);
9 RGB565Struct *bgColor = (RGB565Struct*) (&bg);
10 RGB565Struct outColor;
11
12 outColor.r = ((int) (fgColor->r * alpha) + (int) (bgColor->r) * (256 - alpha)) >> 8;
13 outColor.g = ((int) (fgColor->g * alpha) + (int) (bgColor->g) * (256 - alpha)) >> 8;
14 outColor.b = ((int) (fgColor->b * alpha) + (int) (bgColor->b) * (256 - alpha)) >> 8;
15
16
17 return *((uint16_t*)&outColor);
18}
了解了透明度混合的概念,也实现了单个像素的透明度混合后,我们来看如何实现图片的渐变切换。
假设整个渐变在30帧内完成,我们需要在内存中开辟一块儿大小等于图片的缓冲区。然后我们以第一张图片(当前显示的图片)为背景,第二张图片(接下来显示的图片)为前景,然后为前景设置一个透明度,对每个像素进行透明度混合,并且将混合结果暂存至缓冲区中。待混合结束后,将缓冲区中的数据复制到framebuffer中即完成了一帧的显示。接下来继续进行第二帧、第三帧……逐渐增大前景的不透明度,直到前景色的变为不透明,即完成了图片的渐变切换。
因为每一帧都需要对两张图片中的每一个像素都进行混合运算,这带了来巨大的运算量。交给CPU实现是很不明智的行为,所以我们还是把这些工作交给DMA2D来实现吧。
这次用到了DMA2D的混合功能,所以我们要使能DAM2D的带颜色混合的存储器到存储器模式,对应CR寄存器[17:16]位的值为10,即:
1DMA2D->CR = 0x00020000UL; // 设置工作模式为存储器到存储器并带颜色混合然后分别设置前景、背景和输出数据的内存地址和数据传输偏移、传输图像的宽和高:
1DMA2D->FGMAR = (uint32_t)pFg; // 设置前景数据内存地址
2DMA2D->BGMAR = (uint32_t)pBg; // 设置背景数据内存地址
3DMA2D->OMAR = (uint32_t)pDst; // 设置数据输出内存地址
4
5DMA2D->FGOR = offlineFg; // 设置前景数据传输偏移
6DMA2D->BGOR = offlineBg; // 设置背景数据传输偏移
7DMA2D->OOR = offlineDist; // 设置数据输出传输偏移
8
9DMA2D->NLR = (uint32_t)(xSize << 16) | (uint16_t)ySize; // 设置图像数据宽高(像素)设置颜色格式。这里设置前景色的颜色格式时需要注意,因为如果使用的是ARGB这样的颜色格式,那么我们进行透明度混合时,颜色数据中本身的alpha通道就会对混合结果产生影响,所以我们这里要设定在进行混合操作时,忽略前景色自身的alpha通道。并强制设定混合时的透明度。
输出颜色格式和背景颜色格式
1DMA2D->FGPFCCR = pixelFormat // 设置前景色颜色格式
2 | (1UL << 16) // 忽略前景颜色数据中的Alpha通道
3 | ((uint32_t)opa << 24); // 设置前景色不透明度
4
5DMA2D->BGPFCCR = pixelFormat; // 设置背景颜色格式
6DMA2D->OPFCCR = pixelFormat; // 设置输出颜色格式tips0:有时我们会遇到一张带有透明通道的图片与背景叠加显示的情况,此时就不应该禁用颜色本身的alpha通道
tips1:这个模式下,我们不仅可以进行颜色混合,还可以同时转换颜色格式,可以根据需要设置前景和背景以及输出的颜色格式
最后,启动传输即可:
1/* 启动传输 */
2DMA2D->CR |= DMA2D_CR_START;
3
4/* 等待DMA2D传输完成 */
5while (DMA2D->CR & DMA2D_CR_START) {}
完整代码如下:
1void _DMA2D_MixColors(void* pFg, void* pBg, void* pDst,
2 uint32_t offlineFg, uint32_t offlineBg, uint32_t offlineDist,
3 uint16_t xSize, uint16_t ySize,
4 uint32_t pixelFormat, uint8_t opa) {
5
6 DMA2D->CR = 0x00020000UL; // 设置工作模式为存储器到存储器并带颜色混合
7
8 DMA2D->FGMAR = (uint32_t)pFg; // 设置前景数据内存地址
9 DMA2D->BGMAR = (uint32_t)pBg; // 设置背景数据内存地址
10 DMA2D->OMAR = (uint32_t)pDst; // 设置数据输出内存地址
11
12 DMA2D->FGOR = offlineFg; // 设置前景数据传输偏移
13 DMA2D->BGOR = offlineBg; // 设置背景数据传输偏移
14 DMA2D->OOR = offlineDist; // 设置数据输出传输偏移
15
16 DMA2D->NLR = (uint32_t)(xSize << 16) | (uint16_t)ySize; // 设置图像数据宽高(像素)
17
18 DMA2D->FGPFCCR = pixelFormat // 设置前景色颜色格式
19 | (1UL << 16) // 忽略前景颜色数据中的Alpha通道
20 | ((uint32_t)opa << 24); // 设置前景色不透明度
21
22 DMA2D->BGPFCCR = pixelFormat; // 设置背景颜色格式
23 DMA2D->OPFCCR = pixelFormat; // 设置输出颜色格式
24
25 /* 启动传输 */
26 DMA2D->CR |= DMA2D_CR_START;
27
28 /* 等待DMA2D传输完成 */
29 while (DMA2D->CR & DMA2D_CR_START) {}
30}
编写测试代码,这次不需要二次包装函数了:
1void DMA2D_AlphaBlendDemo(){
2
3 const uint16_t lcdXSize = 320, lcdYSize = 240;
4 const uint8_t cnvFrames = 60; // 60帧完成切换
5 const uint32_t interval = 33; // 每秒30帧
6 uint32_t time = 0;
7
8 // 计算输出位置的内存地址
9 uint16_t distX = (lcdXSize - DEMO_IMG_WIDTH) / 2;
10 uint16_t distY = (lcdYSize - DEMO_IMG_HEIGHT) / 2;
11 uint16_t* pFb = (uint16_t*) framebuffer;
12 uint16_t* pDist = pFb + distX + distY * lcdYSize;
13 uint16_t offlineDist = lcdXSize - DEMO_IMG_WIDTH;
14
15 uint8_t nextImg = 1;
16 uint16_t opa = 0;
17 void* pFg = 0;
18 void* pBg = 0;
19 while(1){
20 // 切换前景/背景图片
21 if(nextImg){
22 pFg = (void*)img_cat;
23 pBg = (void*)img_fox;
24 }
25 else{
26 pFg = (void*)img_fox;
27 pBg = (void*)img_cat;
28 }
29
30 // 完成切换
31 for(int i = 0; i < cnvFrames; i++){
32 time = HAL_GetTick();
33 opa = 255 * i / (cnvFrames-1);
34 _DMA2D_MixColors(pFg, pBg, pDist,
35 0,0,offlineDist,
36 DEMO_IMG_WIDTH, DEMO_IMG_HEIGHT,
37 LTDC_PIXEL_FORMAT_RGB565, opa);
38 time = HAL_GetTick() - time;
39 if(time < interval){
40 HAL_Delay(interval - time);
41 }
42 }
43 nextImg = !nextImg;
44 HAL_Delay(5000);
45 }
46}
最终效果:

性能对比
前面介绍了三种嵌入式图形开发种的实例,并对分别介绍了通过传统和DMA2D实现的方法。这时候肯定有朋友会问,DMA2D实现,比起传统方法实现,到底能快多少呢?我们来实际测试一下。
共同的测试条件如下:
framebuffer放置在SDRAM中,320x240,RGB565
SDRAM工作频率100MHz,CL2,16位带宽。
MCU为STM32H750XB,主频400MHz,开启I-Cache和D-Cache
代码和资源在内部Flash上,64位AXI总线,速度为200MHz。
GCC编译器(版本:arm-atollic-eabi-gcc-6.3.1)
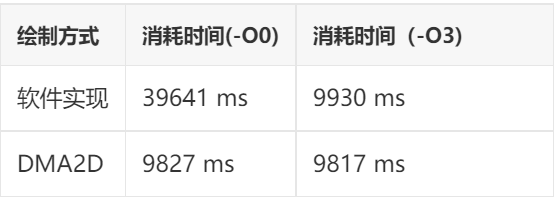
测试项目:矩形填充
绘制上一章第1节中的图表,绘制10000次,统计结果
测试结果:
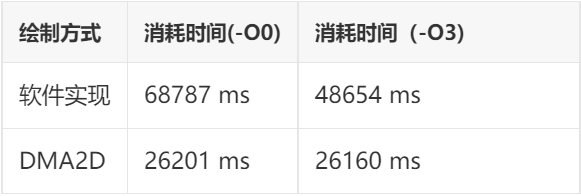
测试项目:内存复制
绘制上一章第2节中的序列帧10000帧,统计结果
测试结果:
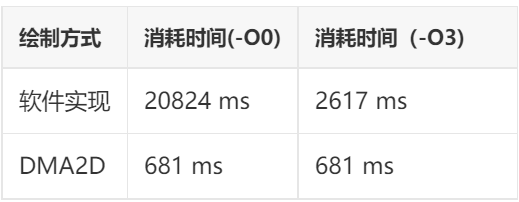
测试项目:透明度混合
渐变切换上一章第3小节中的两张图片100次,每次30帧完成,共计3000帧
混合结果直接输出到framebuffer,不再通过缓冲区缓冲
测试结果:
性能测试总结
由上面的测试结果可以看出,DAM2D至少有2个优势:
一是速度更快:在部分项目中,DMA2D实现的速度相比纯软件实现最高可以达到30倍的差距!这还是在主频高达400MHz还带L1-Cache的STM32H750平台上测试的结果,如果是在无cache且主频较低的STM32F4平台上进行测试,差距会进一步拉大。
二是性能更加稳定:由测试结果可以看出,DMA2D实现的方式受编译器优化等级的影响非常小,几乎可以忽略不计,这意味着,无论你使用IAR,GCC或是MDK,使用DMA2D都可以达到相同的性能表现。不会出现同一段代码移植后性能相差很大的情况。
除这两个直观的结果外,其实还有第三点优势,那就是代码编写更加简单。DMA2D的寄存器不多,而且比较直观。在某些场合,使用起来要比软件实现方便的多。
结语
本文中的三个实例,都是我本人在嵌入式图形开发中经常遇到的情况。实际上,DMA2D的用法还有很多,有兴趣的话可以参考《STM32H743中文编程手册》中的相关内容,相信有了本文的基础,在阅读里面的内容时一定会事半功倍。
受限于作者的技术,文章中的内容无法做到100%的正确,如果存在错误,请大家指出,谢谢。

最后
以上就是友好楼房最近收集整理的关于STM32的“GPU”——DMA2D实例详解的全部内容,更多相关STM32内容请搜索靠谱客的其他文章。








发表评论 取消回复