前言
并发编程是一项非常重要的技术,无论在面试,还是工作中出现的频率非常高。
并发编程说白了就是多线程编程,但多线程一定比单线程效率更高?
答:不一定,要看具体业务场景。
毕竟如果使用了多线程,那么线程之间的竞争和抢占cpu资源,线程的上下文切换,也是相对来说比较耗时的操作。
下面这几个问题在面试中,你必定遇到过:
你在哪来业务场景中使用过多线程?
怎么用的?
踩过哪些坑?
今天聊聊我之前在项目中用并发编程的12种业务场景,给有需要的朋友一个参考。

1. 简单定时任务
各位亲爱的朋友,你没看错,Thread类真的能做定时任务。如果你看过一些定时任务框架的源码,你最后会发现,它们的底层也会使用Thread类。
实现这种定时任务的具体代码如下:
public static void init() {
new Thread(() -> {
while (true) {
try {
System.out.println("下载文件");
Thread.sleep(1000 * 60 * 5);
} catch (Exception e) {
log.error(e);
}
}
}).start();
}使用Thread类可以做最简单的定时任务,在run方法中有个while的死循环(当然还有其他方式),执行我们自己的任务。有个需要特别注意的地方是,需要用try...catch捕获异常,否则如果出现异常,就直接退出循环,下次将无法继续执行了。
但这种方式做的定时任务,只能周期性执行,不能支持定时在某个时间点执行。
特别提醒一下,该线程建议定义成守护线程,可以通过setDaemon方法设置,让它在后台默默执行就好。
使用场景:比如项目中有时需要每隔5分钟去下载某个文件,或者每隔10分钟去读取模板文件生成静态html页面等等,一些简单的周期性任务场景。
使用Thread类做定时任务的优缺点:
优点:这种定时任务非常简单,学习成本低,容易入手,对于那些简单的周期性任务,是个不错的选择。
缺点:不支持指定某个时间点执行任务,不支持延迟执行等操作,功能过于单一,无法应对一些较为复杂的场景。
2.监听器
有时候,我们需要写个监听器,去监听某些数据的变化。
比如:我们在使用canal的时候,需要监听binlog的变化,能够及时把数据库中的数据,同步到另外一个业务数据库中。
 如果直接写一个监听器去监听数据就太没意思了,我们想实现这样一个功能:在配置中心有个开关,配置监听器是否开启,如果开启了使用单线程异步执行。
如果直接写一个监听器去监听数据就太没意思了,我们想实现这样一个功能:在配置中心有个开关,配置监听器是否开启,如果开启了使用单线程异步执行。
主要代码如下:
@Service
public CanalService {
private volatile boolean running = false;
private Thread thread;
@Autowired
private CanalConnector canalConnector;
public void handle() {
//连接canal
while(running) {
//业务处理
}
}
public void start() {
thread = new Thread(this::handle, "name");
running = true;
thread.start();
}
public void stop() {
if(!running) {
return;
}
running = false;
}
}在start方法中开启了一个线程,在该线程中异步执行handle方法的具体任务。然后通过调用stop方法,可以停止该线程。
其中,使用volatile关键字控制的running变量作为开关,它可以控制线程中的状态。
接下来,有个比较关键的点是:如何通过配置中心的配置,控制这个开关呢?
以apollo配置为例,我们在配置中心的后台,修改配置之后,自动获取最新配置的核心代码如下:
public class CanalConfig {
@Autowired
private CanalService canalService;
@ApolloConfigChangeListener
public void change(ConfigChangeEvent event) {
String value = event.getChange("test.canal.enable").getNewValue();
if(BooleanUtils.toBoolean(value)) {
canalService.start();
} else {
canalService.stop();
}
}
}通过apollo的ApolloConfigChangeListener注解,可以监听配置参数的变化。
如果test.canal.enable开关配置的true,则调用canalService类的start方法开启canal数据同步功能。如果开关配置的false,则调用canalService类的stop方法,自动停止canal数据同步功能。
3.收集日志
在某些高并发的场景中,我们需要收集部分用户的日志(比如:用户登录的日志),写到数据库中,以便于做分析。
但由于项目中,还没有引入消息中间件,比如:kafka、rocketmq等。
如果直接将日志同步写入数据库,可能会影响接口性能。
所以,大家很自然想到了异步处理。
实现这个需求最简单的做法是,开启一个线程,异步写入数据到数据库即可。
这样做,可以是可以。
但如果用户登录操作的耗时,比异步写入数据库的时间要少得多。这样导致的结果是:生产日志的速度,比消费日志的速度要快得多,最终的性能瓶颈在消费端。
其实,还有更优雅的处理方式,虽说没有使用消息中间件,但借用了它的思想。
这套记录登录日志的功能,分为:日志生产端、日志存储端和日志消费端。
如下图所示:
先定义了一个阻塞队列。
@Component
public class LoginLogQueue {
private static final int QUEUE_MAX_SIZE = 1000;
private BlockingQueueblockingQueue queue = new LinkedBlockingQueue<>(QUEUE_MAX_SIZE);
//生成消息
public boolean push(LoginLog loginLog) {
return this.queue.add(loginLog);
}
//消费消息
public LoginLog poll() {
LoginLog loginLog = null;
try {
loginLog = this.queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
return result;
}
}然后定义了一个日志的生产者。
@Service
public class LoginSerivce {
@Autowired
private LoginLogQueue loginLogQueue;
public int login(UserInfo userInfo) {
//业务处理
LoginLog loginLog = convert(userInfo);
loginLogQueue.push(loginLog);
}
}接下来,定义了日志的消费者。
@Service
public class LoginInfoConsumer {
@Autowired
private LoginLogQueue queue;
@PostConstruct
public voit init {
new Thread(() -> {
while (true) {
LoginLog loginLog = queue.take();
//写入数据库
}
}).start();
}
}当然,这个例子中使用单线程接收登录日志,为了提升性能,也可以使用线程池来处理业务逻辑(比如:写入数据库)等。
4.excel导入
我们可能会经常收到运营同学提过来的excel数据导入需求,比如:将某一大类下的所有子类一次性导入系统,或者导入一批新的供应商数据等等。
我们以导入供应商数据为例,它所涉及的业务流程很长,比如:
调用天眼查接口校验企业名称和统一社会信用代码。
写入供应商基本表
写入组织表
给供应商自动创建一个用户
给该用户分配权限
自定义域名
发站内通知
等等。
如果在程序中,解析完excel,读取了所有数据之后。用单线程一条条处理业务逻辑,可能耗时会非常长。
为了提升excel数据导入效率,非常有必要使用多线程来处理。
当然在java中实现多线程的手段有很多种,下面重点聊聊java8中最简单的实现方式:parallelStream。
伪代码如下:
supplierList.parallelStream().forEach(x -> importSupplier(x));parallelStream是一个并行执行的流,它默认通过ForkJoinPool实现的,能提高你的多线程任务的速度。
ForkJoinPool处理的过程会分而治之,它的核心思想是:将一个大任务切分成多个小任务。每个小任务都能单独执行,最后它会把所用任务的执行结果进行汇总。
下面用一张图简单介绍一下ForkJoinPool的原理:
当然除了excel导入之外,还有类似的读取文本文件,也可以用类似的方法处理。
温馨的提醒一下,如果一次性导入的数据非常多,用多线程处理,可能会使系统的cpu使用率飙升,需要特别关注。
5.查询接口
很多时候,我们需要在某个查询接口中,调用其他服务的接口,组合数据之后,一起返回。
比如有这样的业务场景:
在用户信息查询接口中需要返回:用户名称、性别、等级、头像、积分、成长值等信息。
而用户名称、性别、等级、头像在用户服务中,积分在积分服务中,成长值在成长值服务中。为了汇总这些数据统一返回,需要另外提供一个对外接口服务。
于是,用户信息查询接口需要调用用户查询接口、积分查询接口 和 成长值查询接口,然后汇总数据统一返回。
调用过程如下图所示:
调用远程接口总耗时 530ms = 200ms + 150ms + 180ms
显然这种串行调用远程接口性能是非常不好的,调用远程接口总的耗时为所有的远程接口耗时之和。
那么如何优化远程接口性能呢?
既然串行调用多个远程接口性能很差,为什么不改成并行呢?
如下图所示: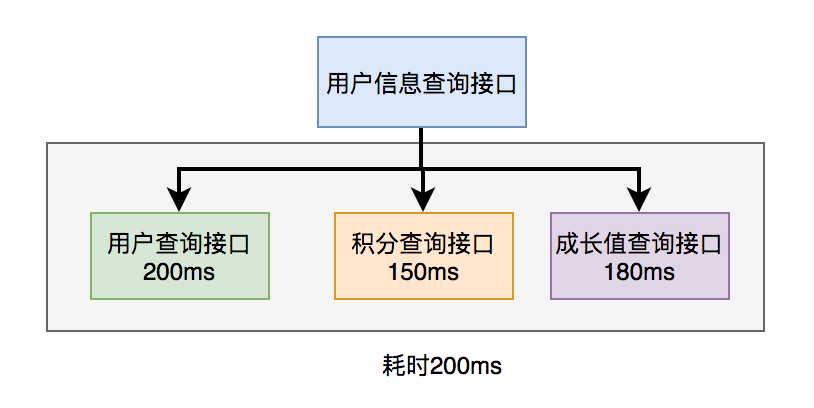
调用远程接口总耗时 200ms = 200ms(即耗时最长的那次远程接口调用)
在java8之前可以通过实现Callable接口,获取线程返回结果。
java8以后通过CompleteFuture类实现该功能。我们这里以CompleteFuture为例:
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}温馨提醒一下,这两种方式别忘了使用线程池。示例中我用到了executor,表示自定义的线程池,为了防止高并发场景下,出现线程过多的问题。
6.获取用户上下文
不知道你在项目开发时,有没有遇到过这样的需求:用户登录之后,在所有的请求接口中,通过某个公共方法,就能获取到当前登录用户的信息?
获取的用户上下文,我们以CurrentUser为例。
CurrentUser内部包含了一个ThreadLocal对象,它负责保存当前线程的用户上下文信息。当然为了保证在线程池中,也能从用户上下文中获取到正确的用户信息,这里用了阿里的TransmittableThreadLocal。伪代码如下:
@Data
public class CurrentUser {
private static final TransmittableThreadLocal<CurrentUser> THREA_LOCAL = new TransmittableThreadLocal<>();
private String id;
private String userName;
private String password;
private String phone;
...
public statis void set(CurrentUser user) {
THREA_LOCAL.set(user);
}
public static void getCurrent() {
return THREA_LOCAL.get();
}
}这里为什么用了阿里的TransmittableThreadLocal,而不是普通的ThreadLocal呢?在线程池中,由于线程会被多次复用,导致从普通的ThreadLocal中无法获取正确的用户信息。父线程中的参数,没法传递给子线程,而TransmittableThreadLocal很好解决了这个问题。
然后在项目中定义一个全局的spring mvc拦截器,专门设置用户上下文到ThreadLocal中。伪代码如下:
public class UserInterceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
CurrentUser user = getUser(request);
if(Objects.nonNull(user)) {
CurrentUser.set(user);
}
}
}用户在请求我们接口时,会先触发该拦截器,它会根据用户cookie中的token,调用调用接口获取redis中的用户信息。如果能获取到,说明用户已经登录,则把用户信息设置到CurrentUser类的ThreadLocal中。
接下来,在api服务的下层,即business层的方法中,就能轻松通过CurrentUser.getCurrent();方法获取到想要的用户上下文信息了。
这套用户体系的想法是很good的,但深入使用后,发现了一个小插曲:
api服务和mq消费者服务都引用了business层,business层中的方法两个服务都能直接调用。
我们都知道在api服务中用户是需要登录的,而mq消费者服务则不需要登录。
如果business中的某个方法刚开始是给api开发的,在方法深处使用了CurrentUser.getCurrent();获取用户上下文。但后来,某位新来的帅哥在mq消费者中也调用了那个方法,并未发觉这个小机关,就会中招,出现找不到用户上下文的问题。
所以我当时的第一个想法是:代码没做兼容处理,因为之前这类问题偶尔会发生一次。
想要解决这个问题,其实也很简单。只需先判断一下能否从CurrentUser中获取用户信息,如果不能,则取配置的系统用户信息。伪代码如下:
@Autowired
private BusinessConfig businessConfig;
CurrentUser user = CurrentUser.getCurrent();
if(Objects.nonNull(user)) {
entity.setUserId(user.getUserId());
entity.setUserName(user.getUserName());
} else {
entity.setUserId(businessConfig.getDefaultUserId());
entity.setUserName(businessConfig.getDefaultUserName());
}这种简单无公害的代码,如果只是在一两个地方加还OK。
此外,众所周知,SimpleDateFormat在java8以前,是用来处理时间的工具类,它是非线程安全的。也就是说,用该方法解析日期会有线程安全问题。
为了避免线程安全问题的出现,我们可以把SimpleDateFormat对象定义成局部变量。但如果你一定要把它定义成静态变量,可以使用ThreadLocal保存日期,也能解决线程安全问题。
8. 传递参数
之前见过有些同事写代码时,一个非常有趣的用法,即:使用MDC传递参数。
MDC是什么?
MDC是org.slf4j包下的一个类,它的全称是Mapped Diagnostic Context,我们可以认为它是一个线程安全的存放诊断日志的容器。
MDC的底层是用了ThreadLocal来保存数据的。
例如现在有这样一种场景:我们使用RestTemplate调用远程接口时,有时需要在header中传递信息,比如:traceId,source等,便于在查询日志时能够串联一次完整的请求链路,快速定位问题。
这种业务场景就能通过ClientHttpRequestInterceptor接口实现,具体做法如下:
第一步,定义一个LogFilter拦截所有接口请求,在MDC中设置traceId:
public class LogFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
MdcUtil.add(UUID.randomUUID().toString());
System.out.println("记录请求日志");
chain.doFilter(request, response);
System.out.println("记录响应日志");
}
@Override
public void destroy() {
}
}第二步,实现ClientHttpRequestInterceptor接口,MDC中获取当前请求的traceId,然后设置到header中:
public class RestTemplateInterceptor implements ClientHttpRequestInterceptor {
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
request.getHeaders().set("traceId", MdcUtil.get());
return execution.execute(request, body);
}
}第三步,定义配置类,配置上面定义的RestTemplateInterceptor类:
@Configuration
public class RestTemplateConfiguration {
@Bean
public RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setInterceptors(Collections.singletonList(restTemplateInterceptor()));
return restTemplate;
}
@Bean
public RestTemplateInterceptor restTemplateInterceptor() {
return new RestTemplateInterceptor();
}
}其中MdcUtil其实是利用MDC工具在ThreadLocal中存储和获取traceId
public class MdcUtil {
private static final String TRACE_ID = "TRACE_ID";
public static String get() {
return MDC.get(TRACE_ID);
}
public static void add(String value) {
MDC.put(TRACE_ID, value);
}
}当然,这个例子中没有演示MdcUtil类的add方法具体调的地方,我们可以在filter中执行接口方法之前,生成traceId,调用MdcUtil类的add方法添加到MDC中,然后在同一个请求的其他地方就能通过MdcUtil类的get方法获取到该traceId。
能使用MDC保存traceId等参数的根本原因是,用户请求到应用服务器,Tomcat会从线程池中分配一个线程去处理该请求。
那么该请求的整个过程中,保存到MDC的ThreadLocal中的参数,也是该线程独享的,所以不会有线程安全问题。
9. 模拟高并发
有时候我们写的接口,在低并发的场景下,一点问题都没有。
但如果一旦出现高并发调用,该接口可能会出现一些意想不到的问题。
为了防止类似的事情发生,一般在项目上线前,我们非常有必要对接口做一下压力测试。
当然,现在已经有比较成熟的压力测试工具,比如:Jmeter、LoadRunner等。
如果你觉得下载压测工具比较麻烦,也可以手写一个简单的模拟并发操作的工具,用CountDownLatch就能实现,例如:
public static void concurrenceTest() {
/**
* 模拟高并发情况代码
*/
final AtomicInteger atomicInteger = new AtomicInteger(0);
final CountDownLatch countDownLatch = new CountDownLatch(1000); // 相当于计数器,当所有都准备好了,再一起执行,模仿多并发,保证并发量
final CountDownLatch countDownLatch2 = new CountDownLatch(1000); // 保证所有线程执行完了再打印atomicInteger的值
ExecutorService executorService = Executors.newFixedThreadPool(10);
try {
for (int i = 0; i < 1000; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
try {
countDownLatch.await(); //一直阻塞当前线程,直到计时器的值为0,保证同时并发
} catch (InterruptedException e) {
log.error(e.getMessage(),e);
}
//每个线程增加1000次,每次加1
for (int j = 0; j < 1000; j++) {
atomicInteger.incrementAndGet();
}
countDownLatch2.countDown();
}
});
countDownLatch.countDown();
}
countDownLatch2.await();// 保证所有线程执行完
executorService.shutdown();
} catch (Exception e){
log.error(e.getMessage(),e);
}
}10. 处理mq消息
在高并发的场景中,消息积压问题,可以说如影随形,真的没办法从根本上解决。表面上看,已经解决了,但后面不知道什么时候,就会冒出一次,比如这次:
有天下午,产品过来说:有几个商户投诉过来了,他们说菜品有延迟,快查一下原因。
这次问题出现得有点奇怪。
为什么这么说?
首先这个时间点就有点奇怪,平常出问题,不都是中午或者晚上用餐高峰期吗?怎么这次问题出现在下午?
根据以往积累的经验,我直接看了kafka的topic的数据,果然上面消息有积压,但这次每个partition都积压了十几万的消息没有消费,比以往加压的消息数量增加了几百倍。这次消息积压得极不寻常。
我赶紧查服务监控看看消费者挂了没,还好没挂。又查服务日志没有发现异常。这时我有点迷茫,碰运气问了问订单组下午发生了什么事情没?他们说下午有个促销活动,跑了一个JOB批量更新过有些商户的订单信息。
这时,我一下子如梦初醒,是他们在JOB中批量发消息导致的问题。怎么没有通知我们呢?实在太坑了。
虽说知道问题的原因了,倒是眼前积压的这十几万的消息该如何处理呢?
此时,如果直接调大partition数量是不行的,历史消息已经存储到4个固定的partition,只有新增的消息才会到新的partition。我们重点需要处理的是已有的partition。
直接加服务节点也不行,因为kafka允许同组的多个partition被一个consumer消费,但不允许一个partition被同组的多个consumer消费,可能会造成资源浪费。
看来只有用多线程处理了。
为了紧急解决问题,我改成了用线程池处理消息,核心线程和最大线程数都配置成了50。
大致用法如下:
先定义一个线程池:
@Configuration
public class ThreadPoolConfig {
@Value("${thread.pool.corePoolSize:5}")
private int corePoolSize;
@Value("${thread.pool.maxPoolSize:10}")
private int maxPoolSize;
@Value("${thread.pool.queueCapacity:200}")
private int queueCapacity;
@Value("${thread.pool.keepAliveSeconds:30}")
private int keepAliveSeconds;
@Value("${thread.pool.threadNamePrefix:ASYNC_}")
private String threadNamePrefix;
@Bean("messageExecutor")
public Executor messageExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setThreadNamePrefix(threadNamePrefix);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}再定义一个消息的consumer:
@Service
public class MyConsumerService {
@Autowired
private Executor messageExecutor;
@KafkaListener(id="test",topics={"topic-test"})
public void listen(String message){
System.out.println("收到消息:" + message);
messageExecutor.submit(new MyWork(message);
}
}在定义的Runable实现类中处理业务逻辑:
public class MyWork implements Runnable {
private String message;
public MyWork(String message) {
this.message = message;
}
@Override
public void run() {
System.out.println(message);
}
}果然,调整之后消息积压数量确实下降的非常快,大约半小时后,积压的消息就非常顺利的处理完了。
但此时有个更严重的问题出现:我收到了报警邮件,有两个订单系统的节点down机了。。。
更详细内容,请看看我的另一篇文章《我用kafka两年踩过的一些非比寻常的坑》
11. 统计数量
在多线程的场景中,有时候需要统计数量,比如:用多线程导入供应商数据时,统计导入成功的供应商数有多少。
如果这时候用count++统计次数,最终的结果可能会不准。因为count++并非原子操作,如果多个线程同时执行该操作,则统计的次数,可能会出现异常。
为了解决这个问题,就需要使用concurent的atomic包下面的类,比如:AtomicInteger、AtomicLong等。
@Servcie
public class ImportSupplierService {
private static AtomicInteger count = new AtomicInteger(0);
public int importSupplier(List<SupplierInfo> supplierList) {
if(CollectionUtils.isEmpty(supplierList)) {
return 0;
}
supplierList.parallelStream().forEach(x -> {
try {
importSupplier(x);
count.addAndGet(1);
} catch(Exception e) {
log.error(e.getMessage(),e);
}
);
return count.get();
}
}AtomicInteger的底层说白了使用自旋锁+CAS。
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}自旋锁说白了就是一个死循环。
而CAS是比较和交换的意思。
它的实现逻辑是:将内存位置处的旧值与预期值进行比较,若相等,则将内存位置处的值替换为新值。若不相等,则不做任何操作。
12. 延迟定时任务
我们经常有延迟处理数据的需求,比如:如果用户下单后,超过30分钟还未完成支付,则系统自动将该订单取消。
这里需求就可以使用延迟定时任务实现。
ScheduledExecutorService是JDK1.5+版本引进的定时任务,该类位于java.util.concurrent并发包下。
ScheduledExecutorService是基于多线程的,设计的初衷是为了解决Timer单线程执行,多个任务之间会互相影响的问题。
它主要包含4个方法:
schedule(Runnable command,long delay,TimeUnit unit),带延迟时间的调度,只执行一次,调度之后可通过Future.get()阻塞直至任务执行完毕。
schedule(Callablecallable,long delay,TimeUnit unit),带延迟时间的调度,只执行一次,调度之后可通过Future.get()阻塞直至任务执行完毕,并且可以获取执行结果。
scheduleAtFixedRate,表示以固定频率执行的任务,如果当前任务耗时较多,超过定时周期period,则当前任务结束后会立即执行。
scheduleWithFixedDelay,表示以固定延时执行任务,延时是相对当前任务结束为起点计算开始时间。
实现这种定时任务的具体代码如下:
public class ScheduleExecutorTest {
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
scheduledExecutorService.scheduleAtFixedRate(() -> {
System.out.println("doSomething");
},1000,1000, TimeUnit.MILLISECONDS);
}
}调用ScheduledExecutorService类的scheduleAtFixedRate方法实现周期性任务,每隔1秒钟执行一次,每次延迟1秒再执行。
这种定时任务是阿里巴巴开发者规范中用来替代Timer类的方案,对于多线程执行周期性任务,是个不错的选择。
使用ScheduledExecutorService类做延迟定时任务的优缺点:
优点:基于多线程的定时任务,多个任务之间不会相关影响,支持周期性的执行任务,并且带延迟功能。
缺点:不支持一些较复杂的定时规则。
当然,你也可以使用分布式定时任务,比如:xxl-job或者elastic-job等等。
其实,在实际工作中我使用多线程的场景远远不只这12种,在这里只是抛砖引玉,介绍了一些我认为比较常见的业务场景。

往期推荐
Spring Boot 中实现跨域的 5 种方式,你一定要知道!

实战!阿里神器 Seata 实现 TCC 模式解决分布式事务

volatile 关键字的作用

最后
以上就是知性金针菇最近收集整理的关于聊聊并发编程的12种业务场景的全部内容,更多相关聊聊并发编程内容请搜索靠谱客的其他文章。








发表评论 取消回复