我是靠谱客的博主 雪白红牛,这篇文章主要介绍ElasticSearch最佳入门实践(十二)Elasticsearch容错机制:master选举,replica容错,数据恢复,现在分享给大家,希望可以做个参考。
(1)9 shard,3 node

(2)master node宕机,自动master选举,cluster status为red

容错第一步:master选举,自动选举其中一个node成为新的master,承担master的责任
(3)replica容错:新master将replica提升为primary shard,cluster status为yellow

容错第二步:新master会将丢失的primary shard对应的某个replica shard提升为primary shard,此时cluster status变为了yellow,因为虽然primary shard全都变成active,但是R22这个replica shard还是非active的
(4)重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,cluster status为green
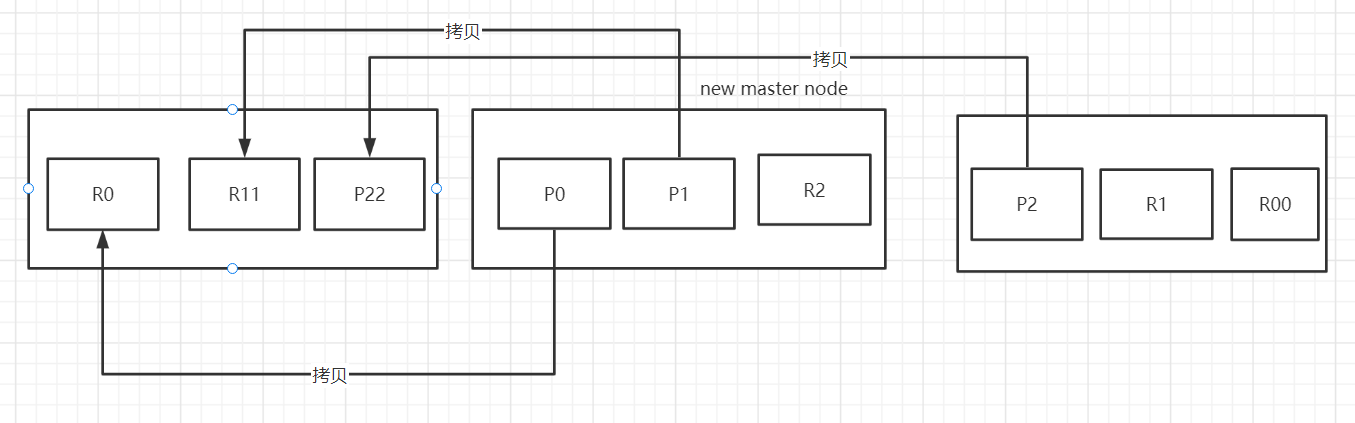
容错第三步:重启发生故障的node,新选举的master会将确实的副本都copy一份到重启的node上,而重启的node会使用之前已经存在的shard数据,只需要同步一下宕机之后修改的数据就可以了,此时cluster status为green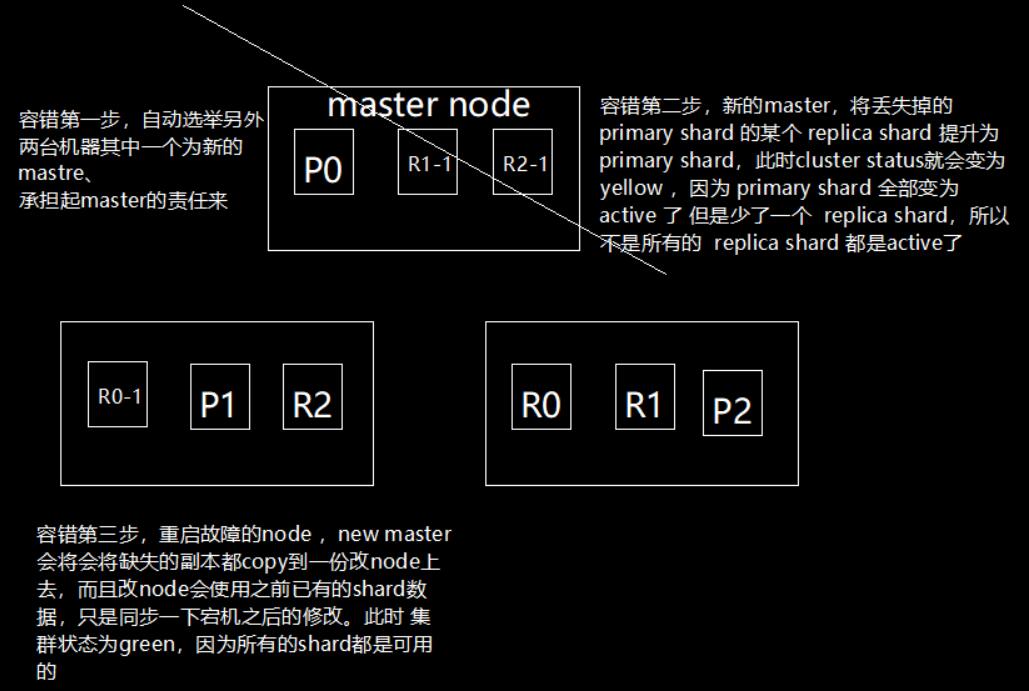
最后
以上就是雪白红牛最近收集整理的关于ElasticSearch最佳入门实践(十二)Elasticsearch容错机制:master选举,replica容错,数据恢复的全部内容,更多相关ElasticSearch最佳入门实践(十二)Elasticsearch容错机制:master选举内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复