对于事件A和事件B同时出现的,一种信息论的描述方法就是互信息,计算方式如下

其意义:由于事件A发生与事件B发生相关联而提供的信息量。
在处理分类问题提取特征的时候就可以用互信息来衡量某个特征和特定类别的相关性,如果信息量越大,那么特征和这个类别的相关性越大。反之也是成立的。
以搜狗实验室的语料为例。选取金融,IT产品,体育,娱乐,股票这五个类别,通过互信息来选取词来建立空间向量模型。在选取之前需要做的一件事是把那些只在一个类别里的出现过的而且频次非常低的词需要去除,因为这些词注定和某个的互信息会很高而和其他类别的互信息会很低。如下:
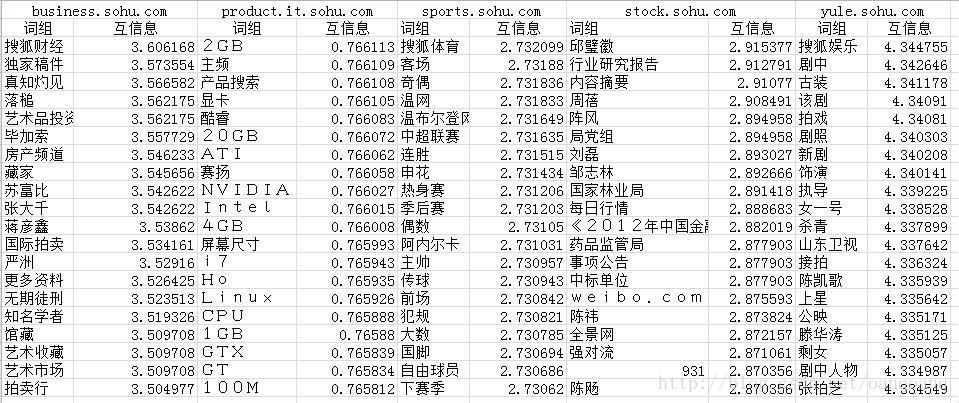
通过上表可以明显看出,仅仅用互信息来选词并不是那么理想,为什么呢?仔细分析可以发现,低词频对于互信息的影响还是蛮大的,一个词如果频次不够多,但是又主要出现在某个类别里,那么就会出现较高的互信息,从而给筛选带来噪音。所以为了避免出现这种情况可以采用先对词按照词频排序取然后按照互信息大小进行排序,然后再选择自己想要的词,这样就能比较好的解决找个问题。如下:
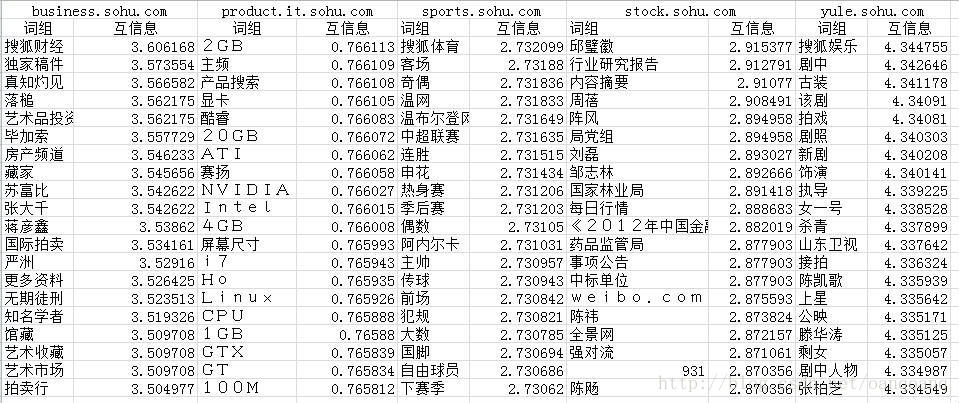
最后
以上就是可爱枕头最近收集整理的关于特征选择之互信息的全部内容,更多相关特征选择之互信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复