文章目录
- 一. 简介
- 二. HELLO WORLD
- 2.1 引入依赖
- 2.2 Kafka配置
- 2.2.1 生产者
- 2.2.2 消费者
- 2.2.3 测试
- 三. 可视化工具Kafka Tool 2
- 源码地址
- 项目推荐
该篇博客实现最基本的Springboot整合kafka 发送消费消息
更多高级用法请看下篇博客
一. 简介
kafka概念相关的介绍请看官方文档和其他博文
官方中文文档
kafka入门介绍
二. HELLO WORLD
2.1 引入依赖
主要是spring-kafka依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<!--优化编码-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
application.properties 添加变量参数
设置配置参数,主题,topic等
kafka.bootstrap-servers=localhost:9092
kafka.topic.basic=test_topic
kafka.topic.json=json_topic
kafka.topic.batch=batch_topic
kafka.topic.manual=manual_topic
kafka.topic.transactional=transactional_topic
kafka.topic.reply=reply_topic
kafka.topic.reply.to=reply_to_topic
kafka.topic.filter=filter_topic
kafka.topic.error=error_topic
server.port=9093
2.2 Kafka配置
此处我们可以在application.properties中配置,也可以使用Java Config。我使用Java Config,看得更直观。
2.2.1 生产者
配置类 StringProducerConfig.java
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class StringProducerConfig {
@Value("${kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public KafkaTemplate<String, String> stringKafkaTemplate() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// -----------------------------额外配置,可选--------------------------
//重试,0为不启用重试机制
configProps.put(ProducerConfig.RETRIES_CONFIG, 1);
//控制批处理大小,单位为字节
configProps.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量
configProps.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//生产者可以使用的总内存字节来缓冲等待发送到服务器的记录
configProps.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024000);
return new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(configProps));
}
/**
* ----可选参数----
*
* configProps.put(ProducerConfig.ACKS_CONFIG, "1");
* 确认模式, 默认1
*
* acks=0那么生产者将根本不会等待来自服务器的任何确认。
* 记录将立即被添加到套接字缓冲区,并被认为已发送。在这种情况下,不能保证服务器已经收到了记录,
* 并且<code>重试</code>配置不会生效(因为客户端通常不会知道任何故障)。每个记录返回的偏移量总是设置为-1。
*
* acks=1这将意味着领导者将记录写入其本地日志,但不会等待所有追随者的全部确认。
* 在这种情况下,如果领导者在确认记录后立即失败,但在追随者复制之前,记录将会丢失。
*
* acks=all这些意味着leader将等待所有同步的副本确认记录。这保证了只要至少有一个同步副本仍然存在,
* 记录就不会丢失。这是最有力的保证。这相当于acks=-1的设置。
*
*
*
* configProps.put(ProducerConfig.RETRIES_CONFIG, "3");
* 设置一个大于零的值将导致客户端重新发送任何发送失败的记录,并可能出现暂时错误。
* 请注意,此重试与客户机在收到错误后重新发送记录没有什么不同。
* 如果不将max.in.flight.requests.per.connection 设置为1,则允许重试可能会更改记录的顺序,
* 因为如果将两个批发送到单个分区,而第一个批失败并重试,但第二个批成功,则第二批中的记录可能会首先出现。
* 注意:另外,如果delivery.timeout.ms 配置的超时在成功确认之前先过期,则在重试次数用完之前,生成请求将失败。
*
*
* 其他参数请参考:http://www.shixinke.com/java/kafka-configuration
* https://blog.csdn.net/xiaozhu_you/article/details/91493258
*/
}
注释已经很详细了,详细参数请参考:
http://www.shixinke.com/java/kafka-configuration
https://blog.csdn.net/xiaozhu_you/article/details/91493258
生产者 StringProducer.java
import com.itcloud.itcloudkafka.springTemplate.basicString.listener.KafkaSendResultHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.ExecutionException;
@Component
public class StringProducer {
@Autowired
@Qualifier("stringKafkaTemplate")
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private KafkaSendResultHandler kafkaSendResultHandler;
@Value("${kafka.topic.basic}")
private String basicTopic;
public void send(String message) {
kafkaTemplate.send(basicTopic, message);
}
/**
* 异步发送
* @param message
*/
public void sendAsync(String message) {
kafkaTemplate.send(basicTopic, message);
}
/**
* 发送回调
* @param message
*/
public void sendAndCallback(String message) {
// 配置发送回调,可选
kafkaTemplate.setProducerListener(kafkaSendResultHandler);
kafkaTemplate.send(basicTopic, message);
}
/**
* 同步发送,默认异步
* @param message
*/
public void sendSync(String message) {
try {
kafkaTemplate.send(basicTopic, message).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
生产者回调 KafkaSendResultHandler.java
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.kafka.support.ProducerListener;
import org.springframework.stereotype.Component;
/**
* @author 司马缸砸缸了
* @date 2019/12/30 10:53
* @description 消息回调监听器
*/
@Component
@Slf4j
public class KafkaSendResultHandler implements ProducerListener {
@Override
public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata) {
log.info("Message send success : " + producerRecord.toString());
}
@Override
public void onError(ProducerRecord producerRecord, Exception exception) {
log.info("Message send error : " + exception);
}
/**
*
* @return true 代表成功也会调用onSuccess,默认为false
*/
@Override
public boolean isInterestedInSuccess() {
return false;
}
}
2.2.2 消费者
配置类 StringConsumerConfig.java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class StringConsumerConfig {
@Value("${kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${kafka.topic.transactional}")
private String topic;
/**
* 单线程-单条消费
* @return
*/
@Bean
public KafkaListenerContainerFactory<?> stringKafkaListenerContainerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, topic);
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(configProps));
return factory;
}
// 创建topic,3个分区,每个分区一个副本
// @Bean
// public NewTopic batchTopic() {
// return new NewTopic(topic, 3, (short) 1);
// }
}
消费者 StringConsumer.java
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
/**
* @KafkaListener多种使用方式
*/
@Component
@Slf4j
public class StringConsumer {
@KafkaListener(topics = "${kafka.topic.basic}", containerFactory = "stringKafkaListenerContainerFactory")
public void receiveString(String message) {
System.out.println(String.format("Message : %s", message));
}
/**
* 注解方式获取消息头及消息体
*
* @Payload:获取的是消息的消息体,也就是发送内容
* @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY):获取发送消息的key
* @Header(KafkaHeaders.RECEIVED_PARTITION_ID):获取当前消息是从哪个分区中监听到的
* @Header(KafkaHeaders.RECEIVED_TOPIC):获取监听的TopicName
* @Header(KafkaHeaders.RECEIVED_TIMESTAMP):获取时间戳
*
*/
// @KafkaListener(topics = "${kafka.topic.basic}", containerFactory = "stringKafkaListenerContainerFactory")
public void receive(@Payload String message,
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) Integer key,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long ts) {
System.out.println(String.format("From partition %d : %s", partition, message));
}
/**
* 指定消费分区和初始偏移量
*
* @TopicPartition:topic--需要监听的Topic的名称,partitions --需要监听Topic的分区id,partitionOffsets --可以设置从某个偏移量开始监听
* @PartitionOffset:partition --分区Id,非数组,initialOffset --初始偏移量
*
*/
// @KafkaListener(
// containerFactory = "stringKafkaListenerContainerFactory",
// topicPartitions = @TopicPartition(
// topic = "${kafka.topic.basic}",
// partitionOffsets = @PartitionOffset(
// partition = "0" ,
// initialOffset = "0")))
public void receiveFromBegin(@Payload String payload,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
System.out.println(String.format("Read all message from partition %d : %s", partition, payload));
}
/**
* ConsumerRecord 接收
*
* @param record
*/
// @KafkaListener(topics = "${kafka.topic.basic}", containerFactory = "stringKafkaListenerContainerFactory")
public void receive(ConsumerRecord<?, ?> record) {
System.out.println("Message is :" + record.toString());
}
}
消费者中使用多种方式@KafkaListener进行消费,注释已经很详细了。
参考博客:https://www.jianshu.com/p/a64defb44a23
2.2.3 测试
运行
@Autowired
private StringProducer producer;
@Test
public void stringProducer() {
for (int i = 0; i < 5; i++) {
producer.send("Message【" + i + "】:my name is simagangzagangl");
}
try {
Thread.sleep(1000 * 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
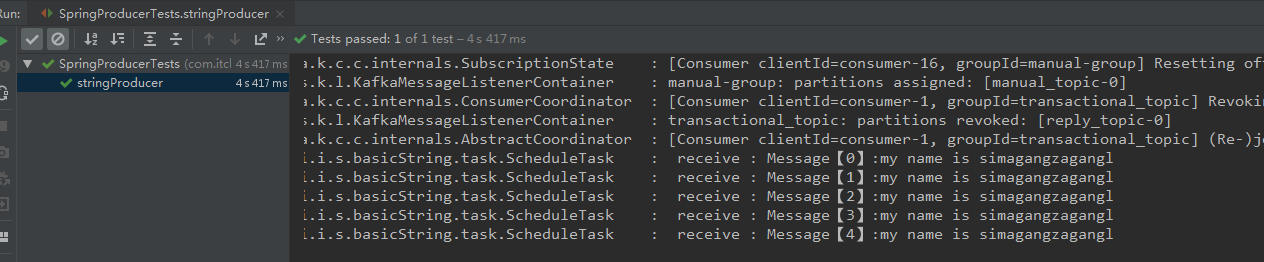
结果
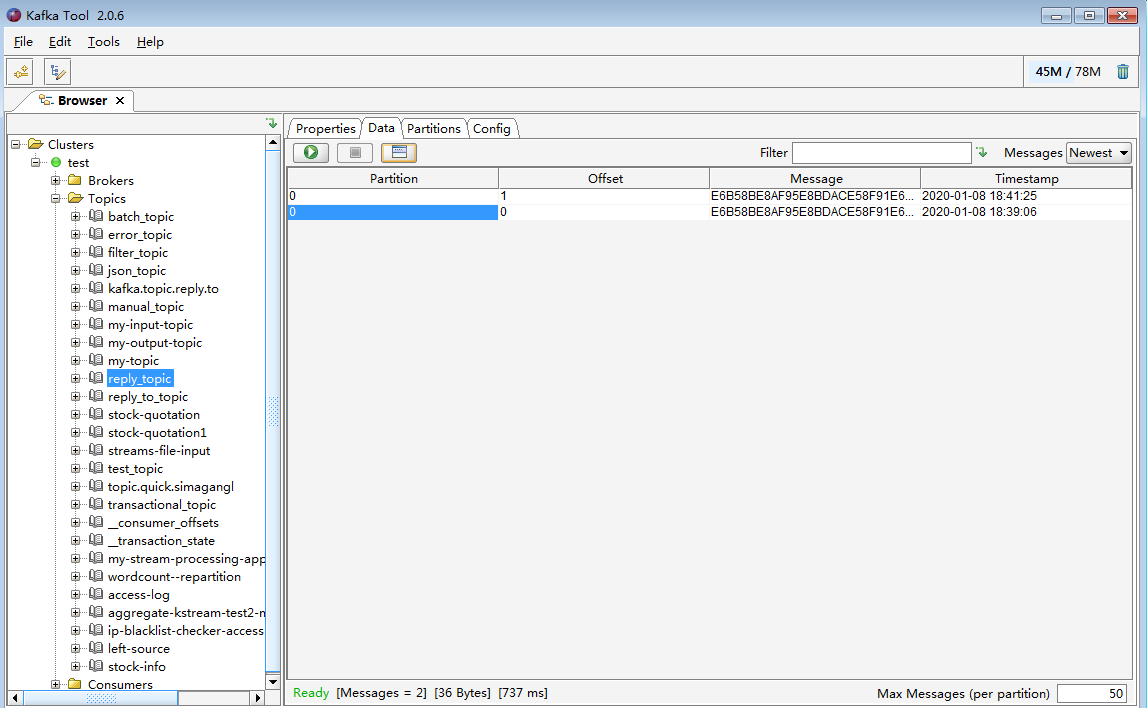
三. 可视化工具Kafka Tool 2
Kafka Tool 2是一款Kafka的可视化客户端工具,可以非常方便的查看Topic的队列信息以及消费者信息以及kafka节点信息。
下载地址:http://www.kafkatool.com/download.html
推荐使用它进行测试验证
源码地址
IT-CLOUD-KAFKA :spring整合kafka教程源码。博文在本CSDN kafka系列中。
项目推荐
IT-CLOUD :IT服务管理平台,集成基础服务,中间件服务,监控告警服务等。
IT-CLOUD-ACTIVITI6 :Activiti教程源码。博文在本CSDN Activiti系列中。
IT-CLOUD-ELASTICSEARCH :elasticsearch教程源码。博文在本CSDN elasticsearch系列中。
IT-CLOUD-KAFKA :spring整合kafka教程源码。博文在本CSDN kafka系列中。
IT-CLOUD-KAFKA-CLIENT :kafka client教程源码。博文在本CSDN kafka系列中。开源项目,持续更新中,喜欢请 Star~
最后
以上就是多情自行车最近收集整理的关于【弄nèng - Kafka】应用篇(一) —— Springboot整合Kafka(基本用法)的全部内容,更多相关【弄nèng内容请搜索靠谱客的其他文章。








发表评论 取消回复