文章目录
- 1.前言
- 2.详细过程
- 3.实验
- 4.总结
1.前言
数据增强一直都是 CV、NLP 领域广泛应用的技术,尤其是在数据资源极少的情况下。简单来说,就是扩充训练集的规模来缓解过拟合的问题,提高深度神经网络的鲁棒性。在 NLP 领域,数据增强的方法通常有: 1)对文本进行增删改;2)回译(翻译到一种语言再翻译回来);3)通过 dropout;4)mixup 技术等。本文主要介绍一篇 ACL 2022 来自中科院和快手的数据增强方法:Text Smoothing(文本平滑)。
论文:《Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks》
2.详细过程
在进入神经网络之前,一个 token 一般会转换成对应的 one-hot 表示,这是词汇表的离散分布。平滑表示是从预训练的掩码语言模型中获得的候选标记的概率,可以看作是对 one-hot 表示的信息更丰富的替代。
Text Smoothing的灵感来源于 mixup 技术,所以先简单说一下 mixup:
mixup(ICLR2018)是一种简单而有效的数据增强方法,该方法在图像(主要用于 CV)、文本、语音、推荐、GAN、对抗样本防御等多个领域都能显著提高效果。
mixup 对两个样本-标签数据对按比例相加后生成新的样本-标签数据:**
原 始 的 两 条 样 本 : ( x i , y i ) , ( x j , y j ) , 增 广 的 样 本 如 下 : x ~ = λ x i + ( 1 − λ ) x j , x 为 输 入 向 量 y ~ = λ y i + ( 1 − λ ) y j , y 为 标 签 的 o n e − h o t 编 码 λ ∈ [ 0 , 1 ] 是 概 率 值 , λ ∼ B e t a ( α , α ) , 即 λ 服 从 参 数 都 为 α 的 B e t a 分 布 small 原始的两条样本:(x_i,y_i),(x_j,y_j),增广的样本如下: \ tilde{x}=lambda x_i+(1-lambda)x_j,quad x为输入向量\ qquadqquadquadtilde{y}=lambda y_i+(1-lambda)y_j,quad y为标签的one-hot编码 \ scriptsize lambda in[0,1]是概率值,lambda sim Beta(alpha,alpha),即lambda服从参数都为alpha的Beta分布 原始的两条样本:(xi,yi),(xj,yj),增广的样本如下:x~=λxi+(1−λ)xj,x为输入向量y~=λyi+(1−λ)yj,y为标签的one−hot编码λ∈[0,1]是概率值,λ∼Beta(α,α),即λ服从参数都为α的Beta分布
Text Smoothing的架构图: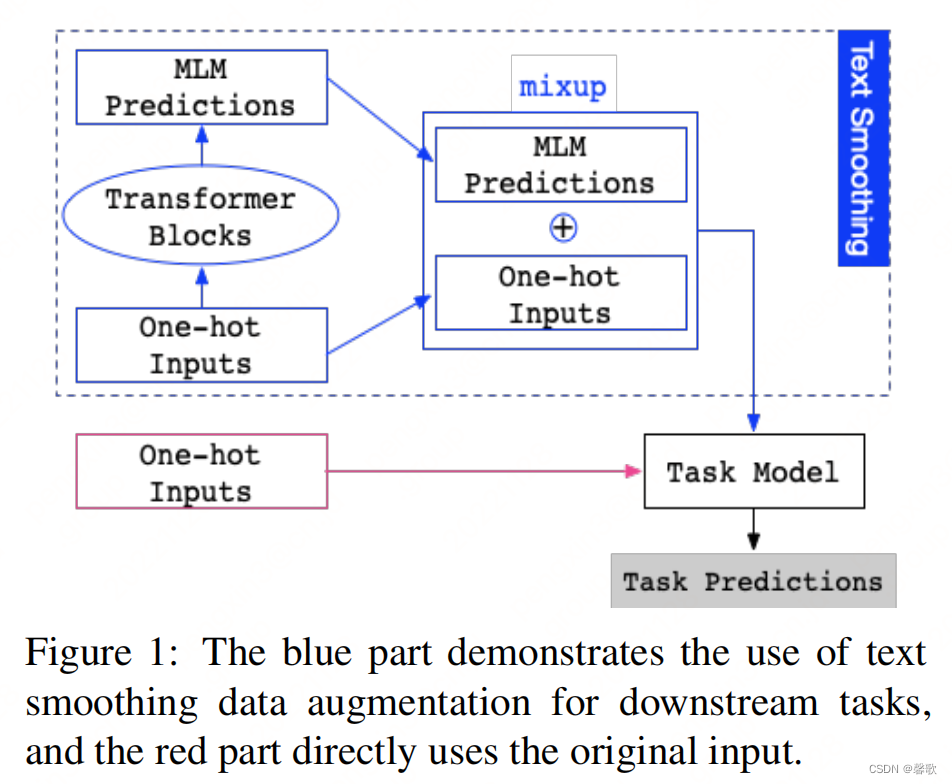
蓝色部分为使用文本平滑数据增强用于下游任务,可以看出主要分为两个部分,首先从 one-hot 输入开始,经过 MLM 得到 token 的概率分布,然后再和 one-hot 进行加权和,得到的结果来代替 one-hot。红色部分则为原来的输入。
使用文本平滑表示代替 one-hot 表示作为模型的输入,可以看作是一种有效的加权数据增强方法。为了在 MLM 中只用一个前向过程获得整个句子的所有标记的平滑表示,论文中没有显式地Mask输入。相反,则是打开 MLM 的 dropout,并在每一层动态随机丢弃一部分权重和隐藏状态。
假
设
用
BERT
作
为
MLM
,
下
游
任
务
数
据
集
D
=
{
t
i
,
p
i
,
s
i
,
l
i
}
i
=
1
N
,
N
为
样
本
个
数
,
t
i
为
文
本
的
o
n
e
−
h
o
t
编
码
,
p
i
为
t
i
的
的
p
o
s
i
t
i
o
n
e
m
b
e
d
d
i
n
g
,
s
i
为
t
i
的
s
e
g
m
e
n
t
e
m
b
e
d
d
i
n
g
,
l
i
则
为
标
签
。
首
先
,
通
过
M
L
M
得
到
最
后
一
层
的
输
出
为
:
small假设用textbf{BERT}作为textbf{MLM},下游任务数据集D={t_i,p_i,s_i,l_i}_{i=1}^N,N为样本个数,t_i为文本的one-hot编码,p_i为t_i的的position,embedding,s_i为t_i的segment,embedding,l_i则为标签。\首先,通过MLM得到最后一层的输出为:
假设用BERT作为MLM,下游任务数据集D={ti,pi,si,li}i=1N,N为样本个数,ti为文本的one−hot编码,pi为ti的的positionembedding,si为ti的segmentembedding,li则为标签。首先,通过MLM得到最后一层的输出为:
t
i
→
=
B
E
R
T
(
t
i
,
p
i
,
s
i
)
smalloverrightarrow{t_i}=BERT(t_i,p_i,s_i)
ti=BERT(ti,pi,si)
t
i
→
的
维
度
为
[
s
e
q
_
l
e
n
,
e
m
b
_
s
i
z
e
]
,
词
嵌
入
矩
阵
W
的
维
度
为
[
v
o
c
a
b
_
s
i
z
e
,
e
m
b
e
d
_
s
i
z
e
]
,
则
M
L
M
的
预
测
结
果
为
:
smalloverrightarrow{t_i}的维度为[seq_len,emb_size],词嵌入矩阵W的维度为[vocab_size,embed_size],\则MLM的预测结果为:
ti的维度为[seq_len,emb_size],词嵌入矩阵W的维度为[vocab_size,embed_size],则MLM的预测结果为:
M
L
M
(
t
i
)
=
s
o
f
t
m
a
x
(
t
i
→
W
T
)
small MLM(t_i)=softmax(overrightarrow{t_i}W^T)
MLM(ti)=softmax(tiWT)
M
L
M
(
t
i
)
的
每
一
行
都
代
表
一
个
当
前
t
o
k
e
n
的
概
率
表
示
。
最
后
就
是
借
鉴
m
i
x
u
p
,
将
M
L
M
输
出
的
概
率
分
布
和
o
n
e
h
o
t
加
权
:
small MLM(t_i)的每一行都代表一个当前token的概率表示。\ small最后就是借鉴mixup,将MLM输出的概率分布和onehot加权:
MLM(ti)的每一行都代表一个当前token的概率表示。最后就是借鉴mixup,将MLM输出的概率分布和onehot加权:
t
i
→
=
λ
⋅
t
i
+
(
1
−
λ
)
⋅
M
L
M
(
t
i
)
smalloverrightarrow{t_i}=lambdacdot t_i+(1-lambda)cdot MLM(t_i)
ti=λ⋅ti+(1−λ)⋅MLM(ti)
整个文本平滑的数据增强流程就是如此了,下面 show the PyTorch code:
sentence = “My favorite fruit is pear.”
lambd = 0.1 #interpolation hyperparameter
mlm.train() #enable dropout, dynamically mask
tensor_input = tokenizer(sentence, return_tensors="pt")
onehot_repr = convert_to_onehot(**tensor_input)
smoothed_repr = softmax(mlm(**tensor_input).logits[0])
interpolated_repr = lambd * onehot_repr + (1-lambd) * smoothed_repr
我们知道,在预训练期间,某些 token 在相似上下文中出现的频率高于其他 token,这将导致模型对这些 token 产生偏好,这对细粒度的情感分类等下游任务来说是不利的。虽然有研究者提出通过训练 label embedding 来约束 MLM 预测标签兼容其他 token,但是,在资源匮乏的情况下,想要有足够的标签数据来提供监督并不容易。
上面只是理论框架,下面举个实际的????来看一下文本平滑怎么解决上述问题:
给定句子 “The quality of this shirt is average .” 可以看出 “average” 这个 token 跟标签是最相关的。通过 MLM 在 “average” 位置得到的平滑表示如下:
虽然 “average” 得到的概率最高,但余下的挺多概率集中分布在几个与任务标签冲突的 token 上,如 “high”、“good” 和 “poor”等。这种平滑的表示对于下游任务来说不是一个很好的增强输入。Text Smoothing 用原始的 one-hot 表示对平滑表示进行插值。通过插值,可以放大原始 token 的概率,概率仍然大多分布在上下文兼容词上。

3.实验
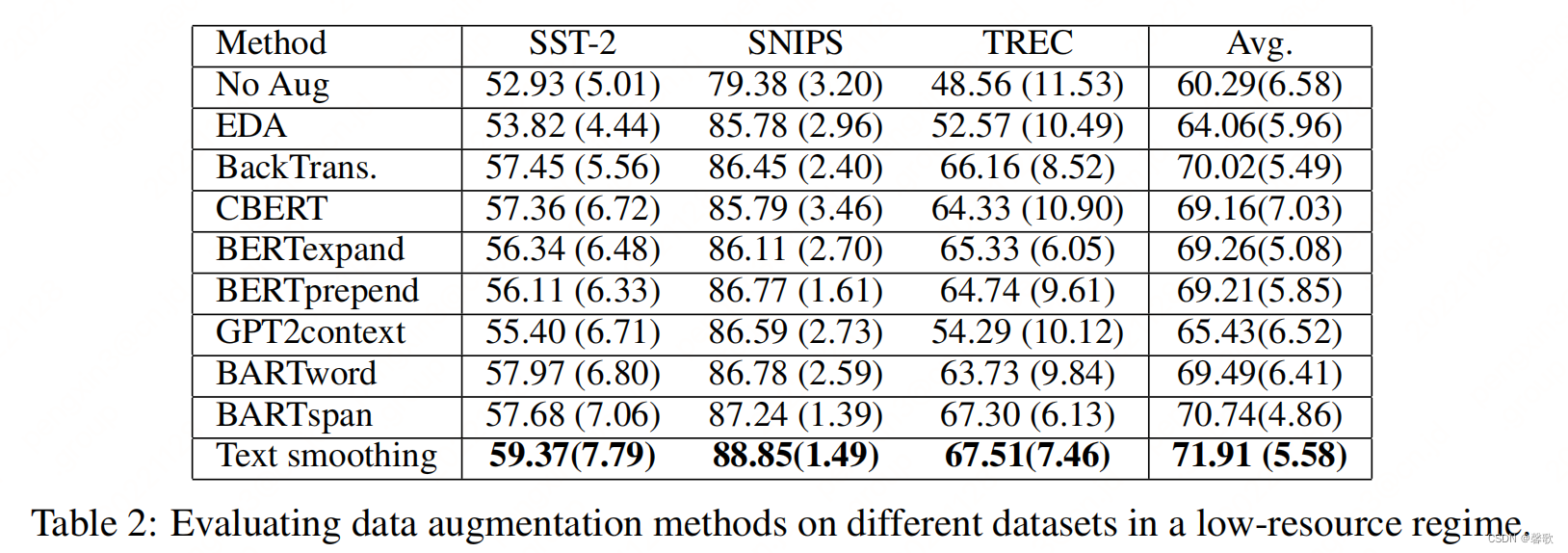
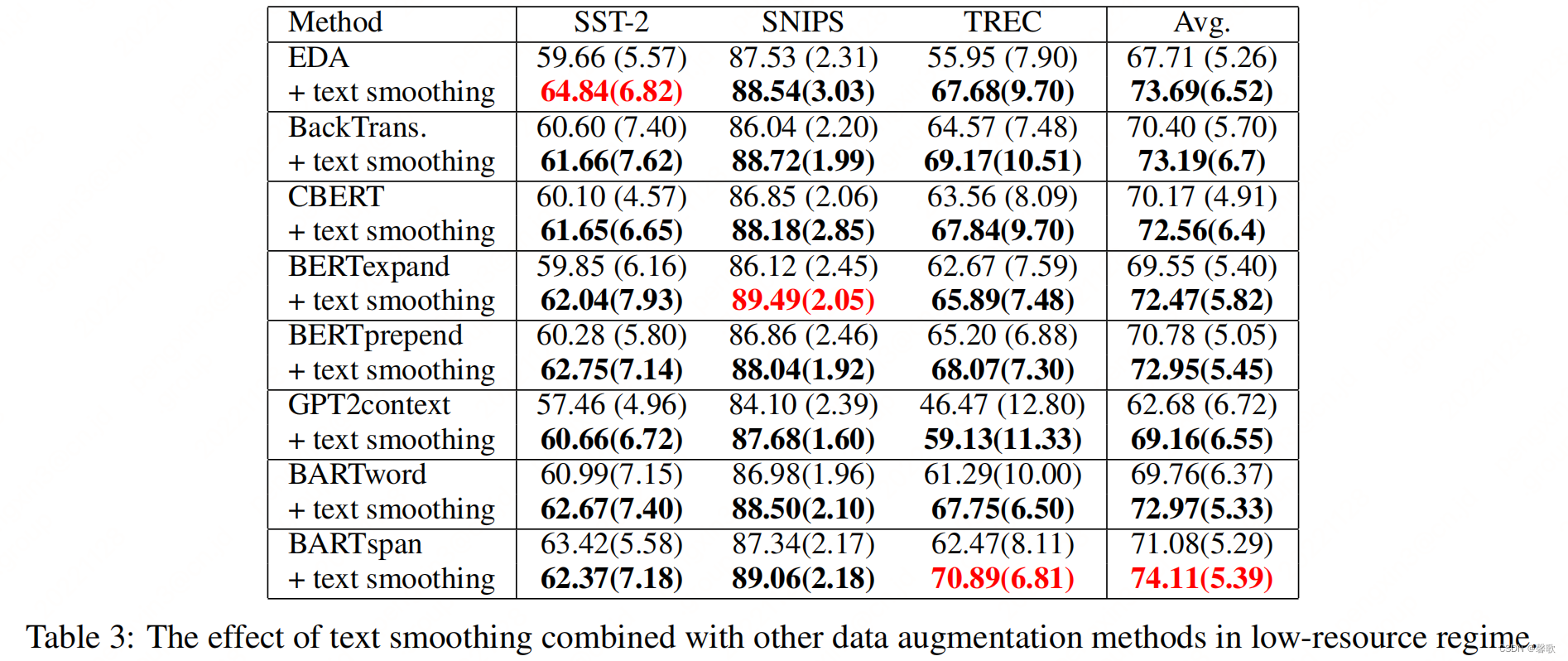
事实胜于雄辩,同时,作者为了评估文本平滑和其他数据增强方法(EDA、Back translation、CBERT、BERTexpand、BERTprepend、GPT2context、BARTword、BARTspan)的效果对比,专门在三个分类基准上使用低资源设置进行实验。在所有实验中,文本平滑都比其他数据增强方法取得了更好的性能。此外,还发现文本平滑可以与其他数据增强方法相结合,以进一步改进任务。
“To the best of our knowledge, this is the first method to improve a variety of mainstream data augmentation methods.”(猴赛雷!此处应有掌声!)
4.总结
数据增强省时省力,如果能够模拟出接近真实样本的分布,确实不失为一种好方法。Text Smoothing 虽说针对文本分类任务,但对于各种有监督任务,也提供了一种数据增强的思路,尤其对一些预测标签概率较为分散的问题。而且还有后发优势,省的去学习前面列的那么多文本增强的方法????????????。
最后
以上就是多情自行车最近收集整理的关于【ACL 2022】Text Smoothing:针对文本分类任务的数据增强方法的全部内容,更多相关【ACL内容请搜索靠谱客的其他文章。








发表评论 取消回复