文章目录
- RuozeKafkaProducer.java
- 用checkpoint记录偏移量
- 用mysql记录偏移量
- MysqlOffsetApp
RuozeKafkaProducer.java
先写一个kafka制造数据的东东
package com.ruozedata.bigdata.kafka;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
import java.util.UUID;
//kafka数据发送,producer
public class RuozeKafkaProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("serializer.class","kafka.serializer.StringEncoder");
properties.put("metadata.broker.list","hadoop000:9092,hadoop000:9093,hadoop000:9094");
ProducerConfig producerConfig = new ProducerConfig(properties);
Producer<String,String> producer = new Producer<String, String>(producerConfig);
String topic ="ruozeg5sparkkafka";
for (int index=0; index<100;index++){
producer.send(new KeyedMessage<String, String>(topic,index+"",index+"ruozeshuju:"+ UUID.randomUUID()));
}
System.out.println("若泽数据Kafka生产者生产数据完毕...");
}
}
在消费者里可以看到数据
bin/kafka-console-consumer.sh
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka
--topic ruozeg5sparkkafka --from-beginning
用checkpoint记录偏移量
package com.ruozedata.bigdata.streaming05
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Duration, Seconds, StreamingContext}
object CheckpointOffsetApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("CheckpointOffsetApp")
//没有会自动创建
val checkpointPath = "hdfs://hadoop000:9000/offset_g5/checkpoint"
val topic="ruozeg5sparkkafka"
val interval =10
val kafkaParams = Map[String, String]("metadata.broker.list"->"hadoop000:9092","metadata.broker.list"->"hadoop000:9093","metadata.broker.list"->"hadoop000:9094","auto.offset.reset"->"smallest")
val topics = topic.split(",").toSet
def function2CreateStreamingContext()={
val ssc = new StreamingContext(conf,Seconds(10))
//[]里是[key class], [value class], [key decoder(解码) class], [value decoder class] ]
//(streamingContext, [map of Kafka parameters], [set of topics to consume])
val messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams, topics)
ssc.checkpoint(checkpointPath)
messages.checkpoint(Duration(8*10.toInt*1000))
messages.foreachRDD(rdd=>{
if (!rdd.isEmpty()){
println("------asd------"+rdd.count())
}
})
ssc
}
//如果检查点数据存在就根据检查点数据重建context,如果不存在就根据第二个参数构建context
val ssc =StreamingContext.getOrCreate(checkpointPath,function2CreateStreamingContext)
ssc.start()
ssc.awaitTermination()
}
}
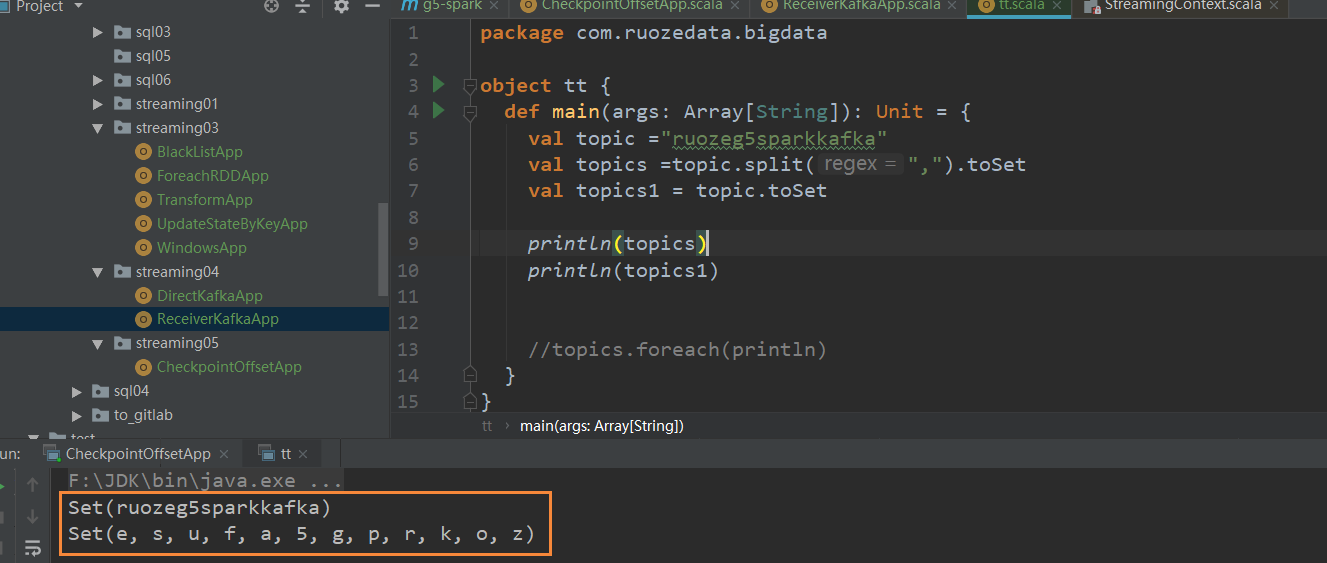
这里之所以要对topic做split,1是因为topic可以不止为1个,而且,就算只有一个不split结果会有问题。
At most once: Each record will be either processed once or not processed at all.
At least once: Each record will be processed one or more times. This is stronger than at-most once as it ensure that no data will be lost. But there may be duplicates.
Exactly once: Each record will be processed exactly once - no data will be lost and no data will be processed multiple times. This is obviously the strongest guarantee of the three.
之所以要split是因为
可以读多个topic,同时
smallest : 自动把offset设为最小的offset;
largest : 自动把offset设为最大的offset;
anything else: 抛出异常;
代码结果
跑100条,得到100条记录
再跑0条,得不到记录,说明偏移量起作用了,没有读所有的数据。
用mysql记录偏移量
scalalikeJDBC
写一个获得配置里参数的object用来读取application.conf的其他参数
package com.ruozedata.bigdata.streaming05
import com.typesafe.config.ConfigFactory
object ValueUtils {
//加载application.conf
val load=ConfigFactory.load()
def getStringValue(key:String,defaultValue:String="")={
load.getString(key)
}
def main(args: Array[String]): Unit = {
println(getStringValue("kafka.topics"))
}
}
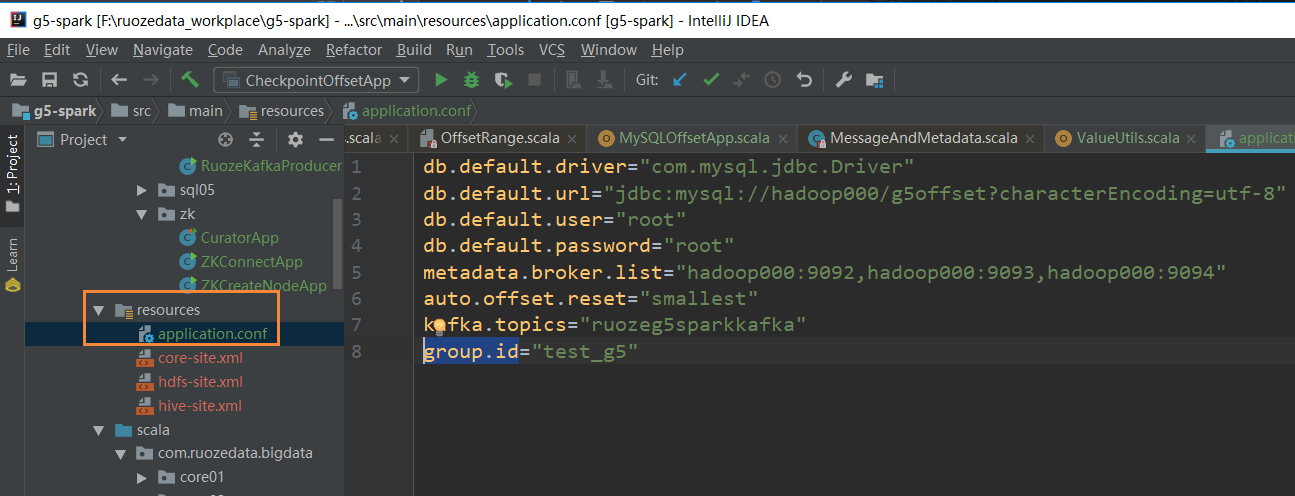
创建mysql表和权限
create table if not exists offsets_storage(
topic varchar(50),
groupid varchar(20),
partitions int,
offset bigint,
primary key(topic,groupid,partitions)
);
MysqlOffsetApp
package com.ruozedata.bigdata.streaming05
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scalikejdbc._
import scalikejdbc.config.DBs
object MySQLOffsetApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("MysqlOffsetApp")
//从application.conf加载配置信息
DBs.setup()
//用来构建stream的参数,详情看源码
val fromOffsets= DB.readOnly(implicit session =>{
sql"select * from offsets_storage".map(rs => {
(TopicAndPartition(rs.string("topic"), rs.int("partitions")), rs.long("offset"))
}).list().apply()
}).toMap
val topic = ValueUtils.getStringValue("kafka.topics")
val interval=10
val kafkaParams=Map(
"metadata.broker.list"->ValueUtils.getStringValue("metadata.broker.list"),
"auto.offset.reset"->ValueUtils.getStringValue("auto.offset.reset"),
"group.id"->ValueUtils.getStringValue("group.id")
)
val topics =topic.split(",").toSet
val ssc=new StreamingContext(conf,Seconds(10))
TODO... 去MySQL里面获取到topic对应的partition的offset
//没有offset从头消费
val messages=if(fromOffsets.size==0){
KafkaUtils.createDirectStream(ssc,kafkaParams,topics)
//有offset从指定位置消费
}else{
//把数据和元数据转换成需要的类型,模板
val messageHandler = (mm:MessageAndMetadata[String,String]) => (mm.key(),mm.message())
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder,(String,String)](ssc,kafkaParams,fromOffsets,messageHandler)
}
messages.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
println("---the count---"+rdd.count())
val offsetRanges=rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(x=>{
println(s"--${x.topic}---${x.partition}---${x.fromOffset}---${x.untilOffset}---")
//替换到mysql最新的offset
DB.autoCommit(implicit session =>{
sql"replace into offsets_storage(topic,groupid,partitions,offset) values(?,?,?,?)"
.bind(x.topic,ValueUtils.getStringValue("group.id"),x.partition,x.untilOffset)
.update().apply()
})
})
}
})
ssc.start()
ssc.awaitTermination()
}
}
根据TopicAndPartition写fromoffsets
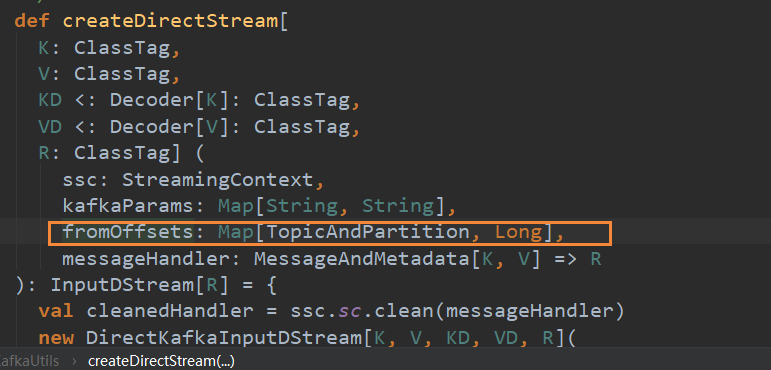
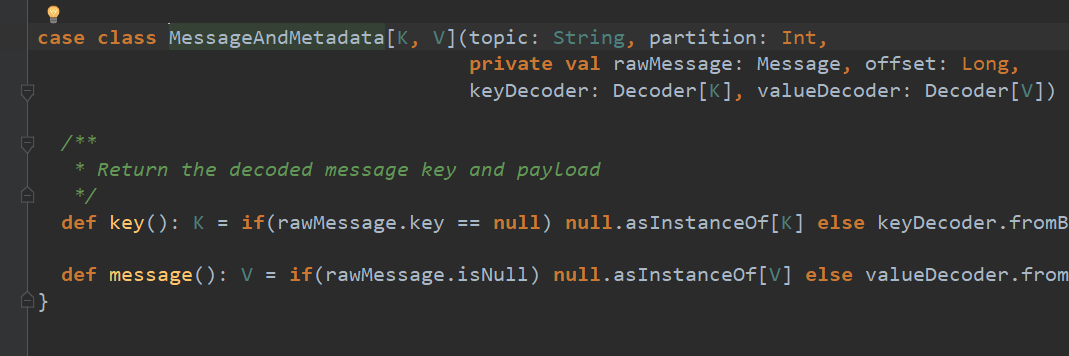
可以通过offsetRange拿到Dstream的offset之类的
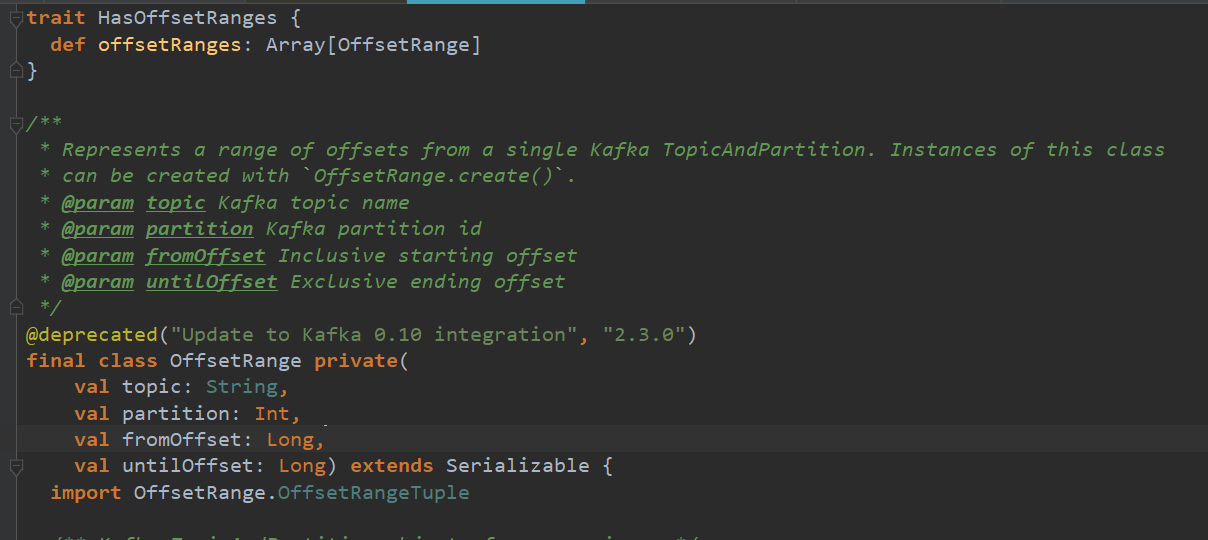
查看mysql结果

最后
以上就是怡然洋葱最近收集整理的关于kafka-streaming偏移量管理的全部内容,更多相关kafka-streaming偏移量管理内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复