MNIST是一个非常有名的手写数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门案例。
MNIST数据集是NIST数据集的一个子集,它包含了60000张图片作为训练数据,10000张图片作为测试数据。在MNIST数据集中的每一张图片都代表了0~9中的一个数字。图片的大小都为28x28,且数字都会出现在图片的正中间。
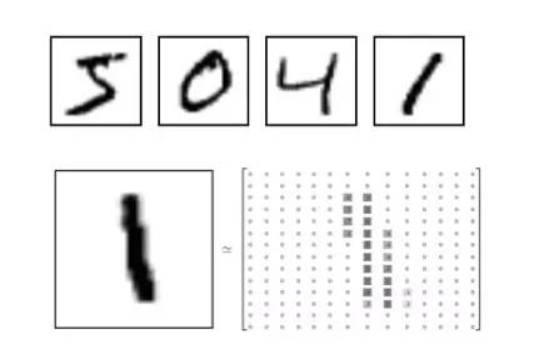
数字图片及其像素矩阵:(MNIST数据集中图片的像素大小为28x28,为了更清楚的展示,图中显示的是14x14矩阵)
MNIST提供了四个文件:
train-images-idx3-ubyte.gz (训练图像数据60000个)
train-labels-idx1-ubyte.gz (训练图像数据标签60000个)
t10k-images-idx3-ubyte.gz (测试图像数据10000个)
t10k-labels-idx1-ubyte.gz (测试图像数据标签10000个)
TensorFlow提供了一个类来处理MNIST数据,这个类会自动下载并转化MNIST数据的格式,将数据从原始数据包中解析成训练和测试神经网络时使用格式。
这个函数的示例:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入MNIST数据集,如果指定地址/path/to/MNIST_data下没有已经下载好的数据,那么TensorFlow会自动下载
mnist=input_data.read_data_sets("/path/to/MNIST_data",one_hot=True)
#打印Training data size:55000
print("Training data size:",mnist.train.num_examples)
#打印Validating data size:5000
print("Validating data size:",mnist.validation.num_examples)
#打印Testing data size:10000
print("Testing data size:",mnist.test.num_examples)
#打印Example training data
print("Example training data:",mnist.train.images[0])
这是下载到的数据集:
通过input_data.read_data_sets函数生成的类会自动将数据集划分为train、validation和test三个数据集,其中train这个集合内有55000张图片,validation集合内有5000张图片,这两个集合组成了MNIST本身提供的训练数据集。test集合内有10000张图片,这些图片都来自于MNIST提供的测试数据集。处理后的每一张图片是一个长度为784的一维数组,这个数组中的元素对应了图片像素矩阵中的每一个数字(28X28=784)。
为了方便使用随机梯度下降,input_data.read_data_sets函数生成的类还提供了mnist.train.next_batch函数,它可以从所有的训练数据中读取一小部分作为一个训练batch。
示例如下:
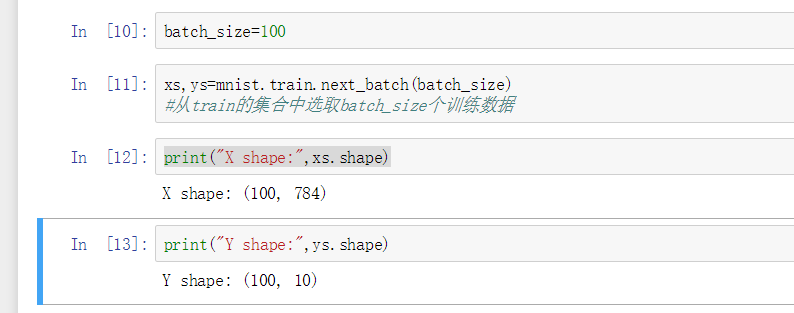
batch_size=100
xs,ys=mnist.train.next_batch(batch_size)
#从train的集合中选取batch_size个训练数据
print("X shape:",xs.shape)
print("Y shape:",ys.shape)
下面是 MNIST数据集分类简单版本.py
# coding: utf-8
#In[2]:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# In[3]:
#载入数据集
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)#从网上下载手写数据集
#每个批次的大小
batch_size = 100
#计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
#定义两个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
#创建一个简单的神经网络
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x,W)+b)
#二次代价函数
loss = tf.reduce_mean(tf.square(y-prediction))
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#初始化变量
init = tf.global_variables_initializer()
#结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大的值所在的位置
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(acc))
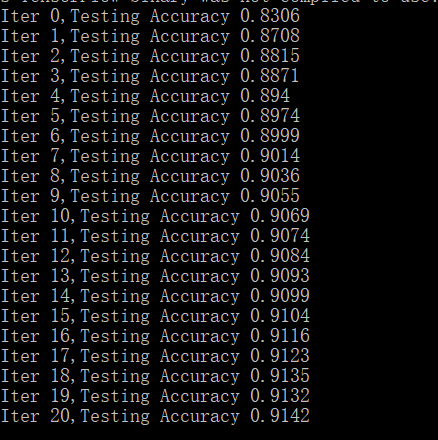
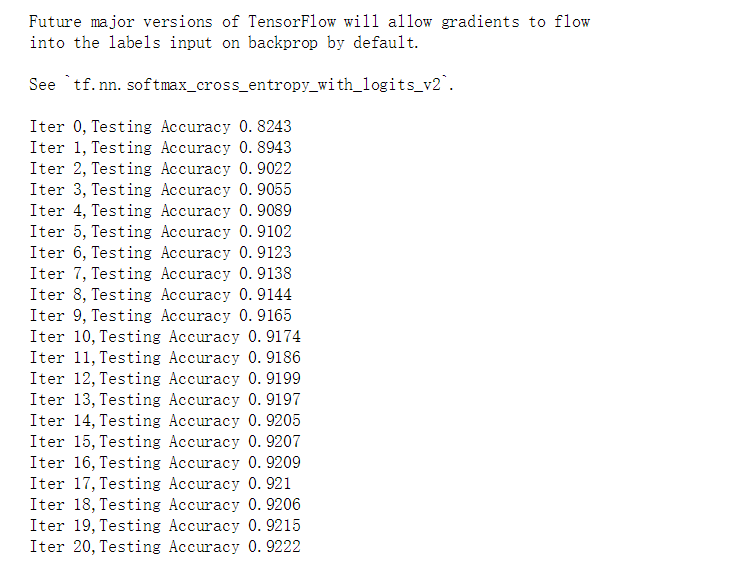
运行结果:
将第29行替换为loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))效果会更好一些。
下面给出一个更加完善的TensorFlow程序:(来源:TensorFlow实战Google深度学习框架)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from distributed.worker import weight
from tensorflow.contrib.nn.python.ops import cross_entropy
#MNIST数据集相关的常数
INPUT_NODE=784#输入层的节点数,对于MNIST数据集,这个就等于图片的像素
#输出层的节点数,这个等于类别的数。因为在MNIST数据集中需要区分的是0~9这10个数字,所以这里输出层的节点数为10
OUTPUT_NODE=10
# 配置神经网络的参数
LAYER1_NODE=500#隐藏层的节点数,这里使用只有一个隐藏层的网络结构作为样例,这个隐藏层有500个节点
BATCH_SIZE=100#一个训练batch中的训练数据个数。数字越小时,训练过程越接近随机梯度下降;数字越大时,训练越接近梯度下降
LEARNING_RATE_BASE=0.8#基础的学习率
LEARNING_RATE_DECAY=0.99#学习率的衰减率
REGULARIZATION_RATE=0.0001#描述模型复杂度的正则化项在损失函数中的系数
TRAINING_STEPS=30000#训练轮数
MOVING_AVERAGE_DECAY=0.99#滑动平均衰减率
"""
一个辅助函数,给定神经网络的输入和所有参数,计算神经网路的前向传播结果。在这里定义一个使用
RELU激活函数的三层全连接神经网络。通过加入隐藏层实现了多层网络结构,通过RELU激活函数实现了去线性化。
在这个函数中也支持传入用于计算参数平均值的类,这样方便在测试时使用滑动平均模型。
"""
def inference(input_tensor,avg_class,weights1,biases1,weights2,biases2):
#当没有提供滑动平均类时,直接使用参数当前的取值。
if avg_class==None:
#计算隐藏层的前向传播结果,这里使用RELU激活函数
layer1=tf.nn.relu(tf.matmul(input_tensor,weights1)+biases1)
'''
计算输出层的前向传播结果。因为在计算机损失函数时会一并计算softmax函数,
所以这里不需要加入激活函数。而且不加入softmax不会影响预测结果。因为
预测时使用的是不同类别对应节点输出值的相对大小,有没有softmax层对最后分类结果的
计算没有影响。于是在计算整个神经网络的前向传播时可以不加入最后的softmax层
'''
return tf.matmul(layer1,weights2)+biases2
else:
#首先使用avg_class.average函数来计算得出变量的滑动平均值
#然后再计算相应的神经网络的前向传播结果
layer1=tf.nn.relu(tf.matmul(input_tensor,avg_class.average(weights1))+avg_class.average(biases1))
return tf.matmul(layer1,avg_class.average(weights2))+avg_class.average(biases2)
#训练模型的过程
def train(mnist):
x=tf.placeholder(tf.float32,[None,INPUT_NODE],name='X-input')
y_= tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='Y-input')
#生成隐藏层的参数
weights1=tf.Variable(tf.truncated_normal([INPUT_NODE,LAYER1_NODE],stddev=0.1))
biases1=tf.Variable(tf.constant(0.1,shape=[LAYER1_NODE]))
#生成输出层的参数
weights2=tf.Variable(tf.truncated_normal([LAYER1_NODE,OUTPUT_NODE],stddev=0.1))
biases2=tf.Variable(tf.constant(0.1,shape=[OUTPUT_NODE]))
#计算在当前参数下神经网络的前向传播结果,给出的用于计算滑动平均类为None,所以函数不会使用参数的滑动平均值
y=inference(x,None,weights1,biases1,weights2,biases2)
'''
定义存储训练轮数的变量,这个变量不需要计算滑动平均值,所以这里指定这个变量为不可训练的变量(trainable=False)
在使用TensorFlow训练神经网络时,一般会将代表训练的轮数的变量指定为不可训练的参数
'''
global_step=tf.Variable(0,trainable=False)
'''
给定滑动平均衰减率和训练轮数 的变量,初始化滑动平均类,给定训练轮数的变量可以加快训练
早期变量的更新速度
'''
variable_averages=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
#在所有代表神经网络参数的变量上使用滑动平均
variables_averages_op=variable_averages.apply(tf.trainable_variables())
"""
计算使用了滑动平均之后的前向传播结果,滑动平均不会改变变量本身的取值,而是会
维护一个影子变量来维护滑动平均取值。所以当使用这个滑动平均值时,需要明确调用average函数
"""
average_y=inference(x,variable_averages,weights1,biases1,weights2,biases2)
"""
计算交叉熵作为刻画预测值与真实值之间的损失函数。这里使用了TensorFlow中提供的sparse_softmax_cross_entropy_with_logits
函数来计算交叉熵。当分类问题只有一个正确答案时,可以使用这个函数来加速交叉熵的计算。MNIST问题的图片中
只包含了0~9中的一个数字,所以可以使用这个函数来计算交叉熵损失。这个函数 的第一个参数是神经网络不包括softmax层
的前向传播结果,第二个是训练数据的正确答案,因为标准答案是一个长度为10的一维数组,而该函数需要提供的是
一个正确答案的数字,所以需要使用tf.argmax函数来得到正确答案对应的类别编号。
"""
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
#计算在当前batch中所有样例的交叉熵平均值
cross_entropy_mean=tf.reduce_mean(cross_entropy)
#计算L2正则化损失函数
regularizer=tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
#计算模型的正则化损失。一般只计算神经网络边上权重的正则化损失,而不使用偏置项。
regularizeration=regularizer(weights1)+regularizer(weights2)
#总损失等于交叉熵损失和正则化损失的和
loss=cross_entropy_mean+regularizeration
#设置指数衰减的学习率
learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples/BATCH_SIZE,LEARNING_RATE_DECAY)
#使用tf.train.GradentDescentOptimizer优化算法来优化损失函数,注意,这里损失函数包含了交叉熵损失和L2正则化损失。
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
#在训练神经网络模型时,每过一遍数据即需要通过反向传播来更新神经网络中的参数,又要
#更新每一个参数的滑动平均值。为了一次完成多个操作,TensorFlow提供了
#tf.control_dependencies和tf.group两种机制
with tf.control_dependencies([train_step,variables_averages_op]):
train_op=tf.no_op(name='train')
"""
检验使用了滑动平均模型的神经网络前向传播结果是否正确。tf.argmax(average_y,1)
计算每一个样例的预测答案。其中average_y是一个batch_size*10的二维数组,每一行表示一个样例的前向传播结果
tf.argmax的第二个参数"1"表示选取最大值的操作仅在第一个维度进行,也就是说,只在每一行选取最大值对应的下标。
于是得到的结果是一个长度为batch的一维数组,这个一维数组的值就表示了每一个样例对应的数字识别结果。
tf.equal判断两个张量的每一维是否相等,如果 相等返回True,否则返回false。
"""
correct_prediction=tf.equal(tf.argmax(average_y,1),tf.argmax(y_,1))
#这个运算首先将一个布尔型的数值转化为实数型,然后计算平均值。这个平均值就是模型在这一组数据上的正确率。
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#初始化会话并开始训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
#准备验证数据。一般在神经网络的训练过程中会通过验证数据来大致判断停止的条件和评判训练的效果
validate_feed={x:mnist.validation.images,y_:mnist.validation.labels}
#准备测试数据。在真实的应用中,这部分数据在训练时是不可见的,这个数据只是作为模型优劣的最后评价标准
test_feed={x:mnist.test.images,y_:mnist.test.labels}
#迭代的训练神经网络
for i in range(TRAINING_STEPS):
#每1000轮输出一次在验证数据集上的测试结果
if i % 1000 == 0:
#计算滑动平均模型在验证数据上的结果,因为MNIST数据集比较小,所以一次可以处理所有验证数据。
#为了计算方便,样例数据没有将验证数据划分为更小的batch。当神经网络模型比较复杂或者验证数比较大时,
#太大的batch会导致计算时间过长甚至发生内存溢出的错误。
validate_acc=sess.run(accuracy,feed_dict=validate_feed)
print("After %d training step(s),validation accuracy""using average model is %g"%(i,validate_acc))
#产生这一轮使用的一个batch的训练数据,并运行训练过程
xs,ys=mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op,feed_dict={x:xs,y_:ys})
#在训练结束后,在测试数据上检测神经网络模型的最终正确率
test_acc=sess.run(accuracy,feed_dict=test_feed)
print("After %d training step(s),test accuraty using average""model is %g"%(TRAINING_STEPS,test_acc))
#主程序入口
def main(argv=None):
#声明处理MNIST数据集的类,这个类在初始化时会自动下载数据
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
train(mnist)
#Tensorflow提供的一个主程序入口,tf.app.run会调用上面定义的main函数
if __name__=='__main__':
tf.app.run()
运行结果:
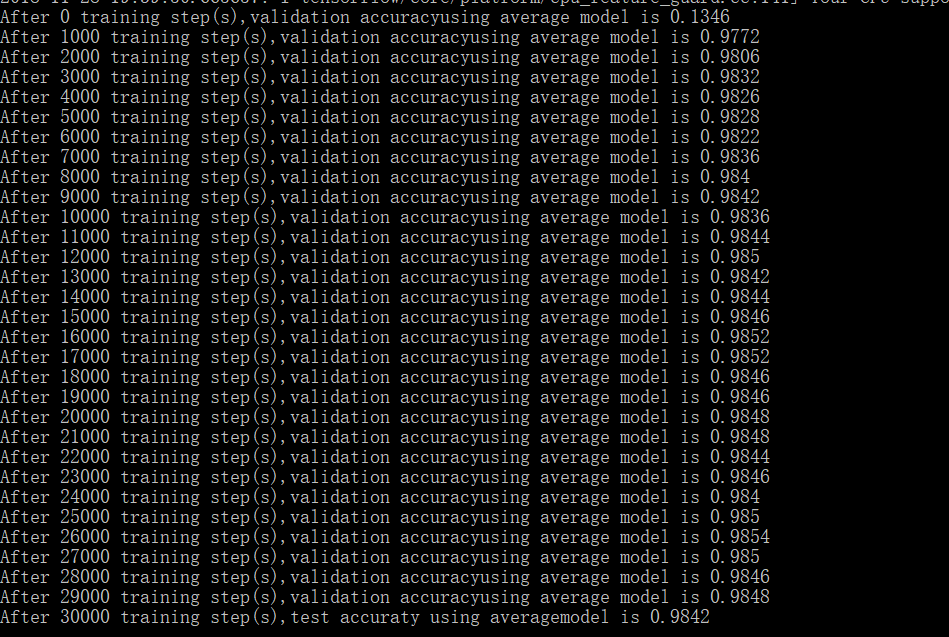
随着训练的进行,模型在验证数据集的表现越来越好。从第6000轮开始,模型在数据集上的表现开始波动,这说明模型已经接近极小值了,所以迭代也就可以结束了。
TensorFlow解决 MNIST问题的最佳实践样例程序
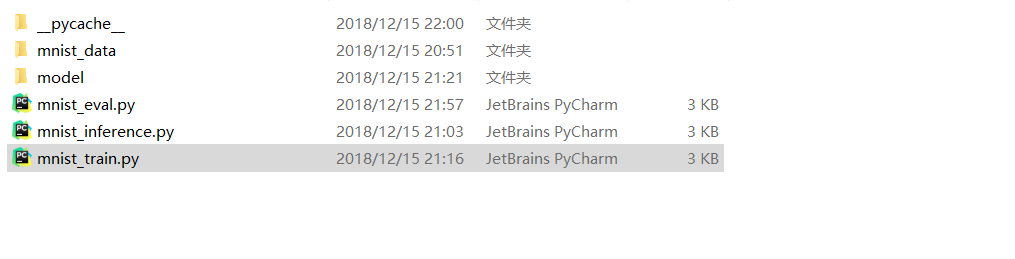
代码会拆成3个程序:
mnist_inference.py 它定义了前向传播的过程及神经网络中的参数
mnist_train.py 它定义了神经网络的训练过程
mnist_eval.py 它定义了测试过程
mnist_inference.py
import tensorflow as tf
from statsmodels.sandbox.nonparametric.tests.ex_smoothers import weights
#定义神经网络结构相关的参数
INPUT_NODE=784
OUTPUT_NODE=10
LAYER1_NODE=500
#通过tf.get_variables函数来获取变量。在训练神经网络时会创建这些变量:在测试时会通过保存的模型
#加载这些变量的取值。而且更加方便的是,因为可以在变量加载时将滑动平均变量重命名,所以可以
#直接通过同样的名字在训练时使用变量自身,而在测试时使用变量滑动平均值,这个函数中也会将变量的
#正则化损失加入损失集合
def get_weight_variable(shape,regularizer):
weights=tf.get_variable("weights",shape,initializer=tf.truncated_normal_initializer(stddev=0.1))
#当给出了正则化生成函数时,将当前变量的正则化损失加入名字为losses的集合。在这里使用了
#add_to_collection函数将一个张量加入一个集合,而这个集合的名称为losses。
#这是自定义的集合,不在TensorFlow自动管理的集合列表
if regularizer !=None:
tf.add_to_collection('losses',regularizer(weights))
return weights
#定义神经网络的前向传播过程
def inference(input_tensor,regularizer):
#声明第一层神经网络的变量并完成前行传播过程
with tf.variable_scope('layer1'):
#这里通过tf.get_variable或tf.Variable没有本质区别,因为在训练或是测试中
#没有在同一个程序中多次调用这个函数。如果在同一个程序中多次调用,在第一次调用
#后需要将reuse参数设置为True
weights=get_weight_variable([INPUT_NODE,LAYER1_NODE],regularizer)
biases=tf.get_variable("biases",[LAYER1_NODE],initializer=tf.constant_initializer(0.0))
layer1=tf.nn.relu(tf.matmul(input_tensor,weights)+biases)
#类似的声明第二层神经网络的变量并完成前向传播过程
with tf.variable_scope('layer2'):
weights=get_weight_variable([LAYER1_NODE,OUTPUT_NODE],regularizer)
biases=tf.get_variable("biases",[OUTPUT_NODE],initializer=tf.constant_initializer(0.0))
layer2=tf.matmul(layer1,weights)+biases
#返回最后前向传播的结果
return layer2
mnist_train.py
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#加载mnist_inference.py中定义的常量和前向传播的函数
import mnist_inference
from keras_preprocessing.text import one_hot
#配置神经网络的参数
BATCH_SIZE=100
LEARNING_RATE_BASE=0.8
LEARNING_RATE_DECAY=0.99
REGULARAZTION_RATE=0.0001
TRAINING_STEPS=30000
MOVING_AVERAGE_DECAY=0.9
#模拟保存的路径和文件名
MODEL_SAVE_PATH='model'
MODEL_NAME="model.ckpt"
def train(mnist):
#定义输入输出placeholder
x=tf.placeholder(tf.float32,[None,mnist_inference.INPUT_NODE],name='x-input')
y_=tf.placeholder(tf.float32,[None,mnist_inference.OUTPUT_NODE],name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
#直接使用mnist_inference.py中定义的前向传播过程
y=mnist_inference.inference(x,regularizer)
global_step=tf.Variable(0,trainable=False)
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_average_op=variable_averages.apply(tf.trainable_variables())
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cross_entropy_mean=tf.reduce_mean(cross_entropy)
loss=cross_entropy_mean+tf.add_n(tf.get_collection('losses'))
learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples/BATCH_SIZE,LEARNING_RATE_DECAY)
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
with tf.control_dependencies([train_step,variable_average_op]):
train_op=tf.no_op(name='train')
#初始化TensorFlow持久化类
saver=tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
#在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成
for i in range(TRAINING_STEPS):
xs,ys=mnist.train.next_batch(BATCH_SIZE)
_,loss_value,step=sess.run([train_op,loss,global_step],feed_dict={x:xs,y_:ys})
#每1000轮保存一次模型
if i%1000==0:
#输出当前的训练情况。这里只输出了模型在当前训练batch上的损失函数大小.
#通过损失函数的大小可以大概了解训练的情况。在验证数据集上的正确率信息会
#有一个单独的程序来生成
print("After %d training step(s),loss on training ""batch is %g."%(step,loss_value))
#保存当前的模型,注意这里给出了global_step参数,这样可以让每个被保存模型的文件名末尾加上训练的轮数
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
def main(argv=None):
mnist=input_data.read_data_sets("mnist_data",one_hot=True)
train(mnist)
if __name__ == "__main__":
tf.app.run()
运行结果:
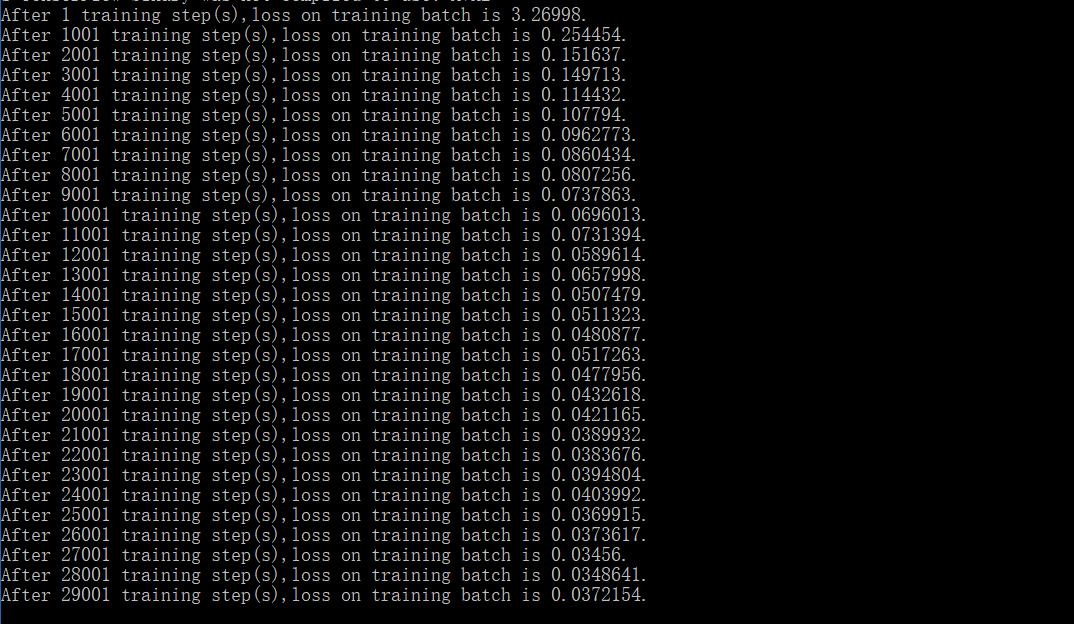
mnist_eval.py
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#加载mnist_inference.py 和 mnist_train.py中定义的常量和函数
import mnist_inference
import mnist_train
from astropy.coordinates.tests import accuracy
from distributed import variable
#每10秒加载一次最新的模型,并在测试数据上测试最新模型的正确率
EVAL_INTERVAL_SECS=10
def evaluate(mnist):
with tf.Graph().as_default() as g:
#定义输入输出的格式
x=tf.placeholder(tf.float32,[None,mnist_inference.INPUT_NODE],name='x-input')
y_=tf.placeholder(tf.float32,[None,mnist_inference.OUTPUT_NODE],name='y-input')
validate_feed={x:mnist.validation.images,y_:mnist.validation.labels}
#直接通过调用封装好的函数来计算前向传播结果,因为测试时不关注正则化损失的值,
#所以这里用于计算正则化损失的函数被设置为None
y=mnist_inference.inference(x,None)
#使用前向传播的结果计算正确率。如果需要对未知的样例进行分类,那么使用
#tf.argmax(y,1)就可以得到输入样例的预测类别了。
corrent_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(corrent_prediction,tf.float32))
#通过变量重命名的方式来加载模型,这样在前向传播的过程中就不需要调用求滑动平均
#的函数来获取平均值了。这样就可以完全共用mnist_inference.py中定义的
#前向传播过程
variable_averages=tf.train.ExponentialMovingAverage(mnist_train.MOVING_AVERAGE_DECAY)
variables_to_restore=variable_averages.variables_to_restore()
saver=tf.train.Saver(variables_to_restore)
#每隔EVAL_INTERVAL_SECS秒调用一次计算正确率的过程以检测训练过程中正确率的变化
while True:
with tf.Session() as sess:
#tf.train.get_checkpoint_state函数会通过checkpoint文件自动找到目录
#中最新模型的文件名
ckpt=tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
#加载模型
saver.restore(sess,ckpt.model_checkpoint_path)
#通过文件名得到模型保存时迭代的轮数
global_step=ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score=sess.run(accuracy,feed_dict=validate_feed)
print("After %s training step(s),validation""accuracy=%g"%(global_step,accuracy_score))
else:
print('No cheeckpoint file found')
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
mnist=input_data.read_data_sets("mnist_data",one_hot=True)
evaluate(mnist)
if __name__ == "__main__":
tf.app.run()
最后
以上就是呆萌糖豆最近收集整理的关于TensorFlow——MNIST数字识别问题的全部内容,更多相关TensorFlow——MNIST数字识别问题内容请搜索靠谱客的其他文章。








发表评论 取消回复