文章目录
- 第 1 章 题目分类
- 第 2 章 最易懂的贪心算法
- 2.1 算法解释
- 2.2 分配问题
- [455. 分发饼干]
- [135. 分发糖果]
- 2.3 区间问题
- [435. 无重叠区间]
- [803. 区间合并 - AcWing题库]
- 2.4 练习
- [605. 种花问题]
- [452. 用最少数量的箭引爆气球]
- [763. 划分字母区间]
- [122. 买卖股票的最佳时机 II]
- 找零钱问题*
- 第 3 章 玩转双指针
- 3.1 算法解释
- [167. 两数之和 II - 输入有序数组]
- 双指针 解法
- 双指针+哈希表 解法
- [88. 合并两个有序数组]
- 3.4 快慢指针
- [141. 环形链表]*
- [142. 环形链表 II]*
- 3.5 acwing双指针
- [799. 最长连续不重复子序列 - AcWing题库]*
- [800. 数组元素的目标和 - AcWing题库]*
- [2816. 判断子序列 - AcWing题库]*
- 3.6 滑动窗口
- [3. 无重复字符的最长子串]
- 3.6 练习
- [633. 平方数之和]
- [680. 验证回文串 II]
- [524. 通过删除字母匹配到字典里最长单词]
- 第 4 章 居合斩!二分查找
- 4.1 算法解释
- 4.2 求开方
- [69. x 的平方根 ]
- 4.3 查找区间
- [34. 在排序数组中查找元素的第一个和最后一个位置]
- 4.4 旋转数组查找数字
- [33. 搜索旋转排序数组]*
- 4.5 查找数字
- [789. 数的范围 - AcWing题库]*
- 第 5 章 千奇百怪的排序算法
- 5.1 常用排序算法
- 5.2 快速选择
- [785. 快速排序 - AcWing题库]*
- [786. 第k个数 - AcWing题库]*
- [215. 数组中的第K个最大元素]
- 5.3 桶排序
- [347. 前 K 个高频元素]
- 5.4 归并排序
- [787. 归并排序 - AcWing题库]*
- [788. 逆序对的数量 - AcWing题库]*
- 5.5 练习
- [451. 根据字符出现频率排序]
- 第 6 章 一切皆可搜索
- 6.1 算法解释
- 6.2 深度优先搜索
- [695. 岛屿的最大面积]
- [547. 省份数量]
- [417. 太平洋大西洋水流问题]
第 1 章 题目分类
-
第一个大分类是算法。本书先从最简单的贪心算法讲起,然后逐渐进阶到二分查找、排序算法和搜索算法,最后是难度比较高的动态规划和分治算法。
-
第二个大分类是数学,包括偏向纯数学的数学问题,和偏向计算机知识的位运算问题。这类问题通常用来测试你是否聪敏,在实际工作中并不常用,笔者建议可以优先把精力放在其它大类上。
-
第三个大分类是数据结构,包括 C++ STL 内包含的常见数据结构、字符串处理、链表、树和图。其中,链表、树、和图都是用指针表示的数据结构,且前者是后者的子集。最后我们也将介绍一些更加复杂的数据结构,比如经典的并查集和 LRU。
第 2 章 最易懂的贪心算法
2.1 算法解释
- 顾名思义,贪心算法或贪心思想采用贪心的策略,保证每次操作都是局部最优的,从而使最后得到的结果是全局最优的。举一个最简单的例子:小明和小王喜欢吃苹果,小明可以吃五个,小王可以吃三个。已知苹果园里有吃不完的苹果,求小明和小王一共最多吃多少个苹果。在这个例子中,我们可以选用的贪心策略为,每个人吃自己能吃的最多数量的苹果,这在每个人身上都是局部最优的。又因为全局结果是局部结果的简单求和,且局部结果互不相干,因此局部最优的策略也同样是全局最优的策略。
2.2 分配问题
[455. 分发饼干]
题目描述
- 有一群孩子和一堆饼干,每个孩子有一个饥饿度,每个饼干都有一个大小。每个孩子只能吃一个饼干,且只有饼干的大小不小于孩子的饥饿度时,这个孩子才能吃饱。求解最多有多少孩子可以吃饱。
输入输出样例
- 输入两个数组,分别代表孩子的饥饿度和饼干的大小。输出最多有多少孩子可以吃饱的数量。
Input: [1,2], [1,2,3] 前面数组是孩子,后面是饼干
Output: 2
在这个样例中,我们可以给两个孩子喂 [1,2]、[1,3]、[2,3] 这三种组合的任意一种。
题解
因为饥饿度最小的孩子最容易吃饱,所以我们先考虑这个孩子。为了尽量使得剩下的饼干可以满足饥饿度更大的孩子,所以我们应该把大于等于这个孩子饥饿度的、且大小最小的饼干给这个孩子。满足了这个孩子之后,我们采取同样的策略,考虑剩下孩子里饥饿度最小的孩子,直到没有满足条件的饼干存在。
简而言之,这里的贪心策略是,给剩余孩子里最小饥饿度的孩子分配最小的能饱腹的饼干,以此类推。
至于具体实现,因为我们需要获得大小关系,一个便捷的方法就是把孩子和饼干分别排序。这样我们就可以从饥饿度最小的孩子和大小最小的饼干出发,计算有多少个对子可以满足条件。
注意
对数组或字符串排序是常见的操作,方便之后的大小比较。
注意
在之后的讲解中,若我们谈论的是对连续空间的变量进行操作,我们并不会明确区分数组和字符串,因为他们本质上都是在连续空间上的有序变量集合。一个字符串“abc”可以被看作一个数组 [‘a’,‘b’,‘c’]。
class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s) {
sort(g.begin() , g.end());
sort(s.begin() , s.end());
int childen = 0;
int cookies = 0;
while(cookies < s.size() && childen < g.size() )
{
if(s[cookies] >= g[childen]) childen++;
cookies++;
}
return childen;
}
};
[135. 分发糖果]
题目描述
一群孩子站成一排,每一个孩子有自己的评分。现在需要给这些孩子发糖果,规则是如果一个孩子的评分比自己身旁的一个孩子要高,那么这个孩子就必须得到比身旁孩子更多的糖果;所有孩子至少要有一个糖果。求解最少需要多少个糖果。
输入输出样例
输入是一个数组,表示孩子的评分。输出是最少糖果的数量。
Input: [1,0,2]
Output: 5
在这个样例中,最少的糖果分法是 [2,1,2]。
题解
做完了题目 455,你会不会认为存在比较关系的贪心策略一定需要排序或是选择?
虽然这一道题也是运用贪心策略,但我们只需要简单的两次遍历即可:把所有孩子的糖果数初始化为 1;先从左往右遍历一遍,如果右边孩子的评分比左边的高,则右边孩子的糖果数更新为左边孩子的糖果数加 1;再从右往左遍历一遍,如果左边孩子的评分比右边的高,且左边孩子当前的糖果数不大于右边孩子的糖果数,则左边孩子的糖果数更新为右边孩子的糖果数加 1。
通过这两次遍历,分配的糖果就可以满足题目要求了。这里的贪心策略即为,在每次遍历中,只考虑并更新相邻一侧的大小关系。在样例中,我们初始化糖果分配为 [1,1,1],第一次遍历更新后的结果为 [1,1,2],第二次遍历更新后的结果为 [2,1,2]
class Solution {
public:
int candy(vector<int>& ratings) {
if(ratings.empty()) return 0;
int n = ratings.size();
vector<int> ans(n , 1);
for(int i = 0 ; i < n - 1; i++){
if(ratings[i + 1] > ratings[i])
ans[i + 1] = ans[i] + 1;
}
for(int i = n - 1 ; i >= 1 ; i--){
if(ratings[i - 1] > ratings[i])
ans[i - 1] = max(ans[i - 1] , ans[i] + 1);
}
int sum = 0;
for(auto ch : ans) sum += ch;
return sum;
}
};
2.3 区间问题
[435. 无重叠区间]
题目描述
- 给定多个区间,计算让这些区间互不重叠所需要移除区间的最少个数。起止相连不算重叠。
输入输出样例
输入是一个数组,数组由多个长度固定为 2 的数组组成,表示区间的开始和结尾。输出一个整数,表示需要移除的区间数量。
Input: [[1,2], [2,4], [1,3]]
Output: 1
在这个样例中,我们可以移除区间 [1,3],使得剩余的区间 [[1,2], [2,4]] 互不重叠。
题解
在选择要保留区间时,区间的结尾十分重要:选择的区间结尾越小,余留给其它区间的空间就越大,就越能保留更多的区间。因此,我们采取的贪心策略为,优先保留结尾小且不相交的区间。
具体实现方法为,先把区间按照结尾的大小进行增序排序,每次选择结尾最小且和前一个选择的区间不重叠的区间。我们这里使用 C++ 的 Lambda,结合 std::sort() 函数进行自定义排序。
在样例中,排序后的数组为 [[1,2], [1,3], [2,4]]。按照我们的贪心策略,首先初始化为区间[1,2];由于 [1,3] 与 [1,2] 相交,我们跳过该区间;由于 [2,4] 与 [1,2] 不相交,我们将其保留。因此最终保留的区间为 [[1,2], [2,4]]。
注意
需要根据实际情况判断按区间开头排序还是按区间结尾排序。
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if(intervals.size() == 1)return 0;
sort(intervals.begin() , intervals.end() , [](vector<int>& a , vector<int>& b){
return a[1] < b[1]; //按照区间第二个数来排序,越小排的越前面
});
int pre = intervals[0][1] , total = 0 ;
for(int i = 1 ; i < intervals.size() ; ++i)
{
//如果这两个有重叠,那么就略过这个元素往后继续找
if(pre > intervals[i][0]){
total++;
}
else{
//没有重叠的话就要更换pre
pre = intervals[i][1];
}
}
return total;
}
};
[803. 区间合并 - AcWing题库]

#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
void merge(vector<PII> &segs)
{
vector<PII> res;
//对组排序,默认根据第一个元素排序
sort(segs.begin(), segs.end());
int st = -2e9, ed = -2e9;
for(int i = 0 ; i < segs.size() ; i++){
if(ed < segs[i].first){
st = segs[i].first,ed = segs[i].second;
if(i != 0) //如果不是第一个元素
res.push_back({st,ed});
}
else{
ed = max(ed , segs[i].second);
}
}
//最后一次循环有两种结果:1,把最后第二个加入res 2,把最后两个合并成一个
//无论是上面那两种情况,最后都有一个没法加入res
if (st != -2e9) res.push_back({st, ed});
segs = res;
}
int main()
{
int n;
scanf("%d", &n);
vector<PII> segs;
for (int i = 0; i < n; i ++ )
{
int l, r;
scanf("%d%d", &l, &r);
segs.push_back({l, r});
}
merge(segs);
cout << segs.size() << endl;
return 0;
}
2.4 练习
[605. 种花问题]
题目描述
- 假设有一个很长的花坛,一部分地块种植了花,另一部分却没有,花不能种植在相邻的地块上,给你一个整数数组 flowerbed 表示花坛,由若干 0 和 1 组成,其中 0 表示没种植花,1 表示种植了花。另有一个数 n ,能否在不打破种植规则的情况下种入 n 朵花?能则返回 true ,不能则返回 false。
示例 1:
输入:flowerbed = [1,0,0,0,1], n = 1
输出:true
题解
判断每个位置是否可以种花,需要当前节点,前置节点,后置节点同时为0,
另外有两个特殊节点,就是如果是第一个节点则没有前置节点(置为 0),如果是最后一个节点,那么后置节点(置为 0)。
class Solution {
public:
bool canPlaceFlowers(vector<int>& flowerbed, int n) {
for(int i = 0; i< flowerbed.size() && n > 0 ; ++i)
{
if(flowerbed[i] == 1)continue;
//到达此处意味着,上一个点为0
//这里找出这个点两旁的元素是否为0,如果都为0那么可以插入
//这里考虑到两端,一个没有前驱,一个没有后继,所以用三元运算符
int pre = (i == 0 ? 0 : flowerbed[i - 1]);
int next = (i == flowerbed.size() - 1 ? 0 : flowerbed[i + 1]);
if(pre == 0 && next ==0){
n--;
flowerbed[i] = 1;
}
}
return n == 0;
}
};
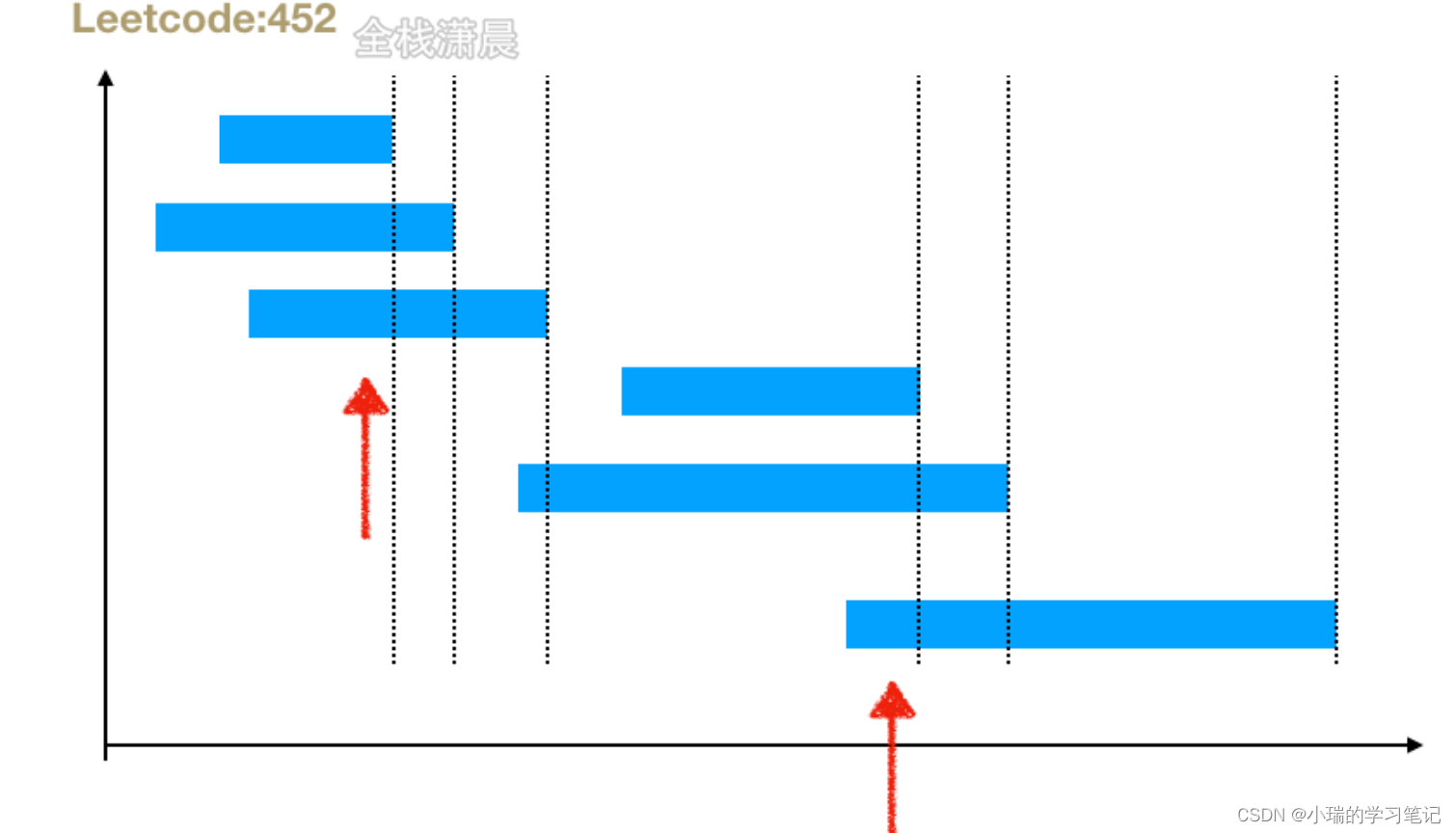
[452. 用最少数量的箭引爆气球]
题目描述
- 一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。给你一个数组 points ,返回引爆所有气球所必须射出的最小弓箭数 。
示例 1:
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:气球可以用2支箭来爆破:
在x = 6处射出箭,击破气球[2,8]和[1,6]。
在x = 11处发射箭,击破气球[10,16]和[7,12]。
示例 2:
输入:points = [[1,2],[3,4],[5,6],[7,8]]
输出:4
解释:每个气球需要射出一支箭,总共需要4支箭。
题解:
按照每个区间第二个数的大小排序,小的排在前面
那么就意味着,第二个区间的边界值一定大于等于小的边界值
class Solution {
public:
int findMinArrowShots(vector<vector<int>>& points) {
//这里必须要用引用,不然会报超时
sort(points.begin() , points.end() , [](vector<int>& v1 , vector<int>& v2){
return v1[1] < v2[1];//区间第二个数小的排前面,是便于后面找是否有重叠
});
int cur = points[0][1];
int count = 1;
for(int i =1 ; i < points.size() ; ++i)
{
if(cur >= points[i][0])continue;
//若气球没有重叠,则再加一只箭
cur = points[i][1];
count++;
}
return count;
}
};
[763. 划分字母区间]
题目描述
- 字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
输入:S = “ababcbacadefegdehijhklij”
输出:[9,7,8]解释:划分结果为 “ababcbaca”, “defegde”, “hijhklij”。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 的划分是错误的,因为划分的片段数较少。
题解:
分析题意:我们要找的切片片段中的字符串都是互不相交的,需要先找到S字符串中每一个字符最后一次出现的位置,并把它一一保存下来,后面再找到的划分后尽可能多的最大不相交的子区间,然后返回区间长度即可。
初始化每一个片段开始下标为start,结束下标为end,对于每一个访问到的字母S(i),得到当前字母的最后一次出现的下标位置end(i),此时我们调用max(end , end(i))进行比较,这样就能保证每次划分的最大子区间是局部最优解了。
这个主要是贪心结合双指针
注意 :
为了满足你的贪心策略,是否需要一些预处理?
在处理数组前,统计一遍信息(如频率、个数、第一次出现位置、最后一次出现位置等)可以使题目难度大幅降低。
- 这里主要是描述了第二个片段

class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> ans;
if(s.empty()) return ans;
unordered_map<int , int> mm;
for(int i = 0 ; i < s.size() ; i++){
mm[s[i]] = i;
}
int start = 0 , end = 0;
for(int i = 0 ; i < s.size() ; i++){
end = max(end , mm[s[i]]);
// 若相等,则end这个下标是之前所有字母的最大下标
// 则在这个位置可以把之前所有字母都隔离
if(end == i){
ans.push_back(end - start + 1);
start = end + 1;
}
}
return ans;
}
};
[122. 买卖股票的最佳时机 II]
题目描述
-
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
-
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
-
返回你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
总利润为 4 + 3 = 7 。
题解:
首先我们是站在已经知道股票的涨幅,去卖股票的
所以可以转化为,只要股票第二天涨价,我前一天就买,第二天就卖,这样一定是赚取最多的办法
class Solution {
public:
int maxProfit(vector<int>& prices) {
int total = 0;
for(int i = 1 ; i < prices.size() ; i++){
if(prices[i] > prices[i - 1])
{
total+=(prices[i] - prices[i - 1]);
}
}
return total;
}
};
找零钱问题*
基本思路
其基本的解题思路为:
-
建立数学模型来描述问题
-
把求解的问题分成若干个子问题
-
对每一子问题求解,得到子问题的局部最优解
-
把子问题对应的局部最优解合成原来整个问题的一个近似最优解

- 这里钱的数组是按照金额从大到小排序的
#include<iostream>
using namespace std;
#define N 7
//钱的金额以及个数
int value[N] = { 100 , 50 , 20 , 10 , 5 , 2 , 1 };
int mcount[N] = { 10, 2, 3, 1 ,2 ,3 , 5 };
int getMomey(int momey)
{
if (momey <= 0)return -1;
int i = 0;
int sheetNum = 0;
while (1)
{
int m = momey / value[i];
int num = mcount[i] < m ? mcount[i] : m;
if (num == 0)
{
i++;
continue;
}
sheetNum += num;
momey -= value[i];
cout << value[i] << " " << num << endl;
i++;
if (momey == 0 )break;
if (i == N - 1)return -1;
}
return sheetNum;
}
int main()
{
int momey;
cout << "请输入钱数 :";
cin >> momey;
int sheetNum = getMomey(momey);
if (sheetNum == -1)
{
cout << "没有这么多钱" << endl;
}
else
{
cout << "一共用了" << sheetNum << "张钱" << endl;
}
system("pause");
}
第 3 章 玩转双指针
3.1 算法解释
双指针主要用于遍历数组,两个指针指向不同的元素,从而协同完成任务。也可以延伸到多个数组的多个指针。
若两个指针指向同一数组,遍历方向相同且不会相交,则也称为滑动窗口(两个指针包围的区域即为当前的窗口),经常用于区间搜索。
若两个指针指向同一数组,但是遍历方向相反,则可以用来进行搜索,待搜索的数组往往是排好序的。
[167. 两数之和 II - 输入有序数组]
题目描述
- 在一个增序的整数数组里找到两个数,使它们的和为给定值。已知有且只有一对解。
输入输出样例
输入是一个数组(numbers)和一个给定值(target)。输出是两个数的位置,从 1 开始计数。
Input: numbers = [2,7,11,15], target = 9
Output: [1,2]
题解
因为数组已经排好序,我们可以采用方向相反的双指针来寻找这两个数字,一个初始指向最小的元素,即数组最左边,向右遍历;一个初始指向最大的元素,即数组最右边,向左遍历。如果两个指针指向元素的和等于给定值,那么它们就是我们要的结果。
如果两个指针指向元素的和小于给定值,我们把左边的指针右移一位,使得当前的和增加一点。如果两个指针指向元素的和大于给定值,我们把右边的指针左移一位,使得当前的和减少一点。
双指针 解法
vector<int> twoSum(vector<int>& numbers, int target) {
int l = 0, r = numbers.size() - 1, sum;
while (l < r) {
sum = numbers[l] + numbers[r];
if (sum == target) break;
if (sum < target) ++l;
else --r;
}
return vector<int>{l + 1, r + 1};
}
双指针+哈希表 解法
class Solution {
public:
vector<int> twoSum(vector<int>& numbers, int target) {
unordered_map<int , int> mm;
vector<int> v;
for(int i = 0 ; i<numbers.size() ;++i)
{
int find = target - numbers[i];
if(mm.count(find)!=0){
v.push_back(mm[find] + 1);
v.push_back(i + 1);
return v;
}
else{
mm[numbers[i]] = i;
}
}
return v;
}
};
[88. 合并两个有序数组]
题目描述
- 给定两个有序数组,把两个数组合并为一个。
输入输出样例
输入是两个数组和它们分别的长度 m 和 n。其中第一个数组的长度被延长至 m + n,多出的n 位被 0 填补。题目要求把第二个数组归并到第一个数组上,不需要开辟额外空间。
Input: nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
Output: nums1 = [1,2,2,3,5,6]
题解
因为这两个数组已经排好序,我们可以把两个指针分别放在两个数组的末尾,即 nums1 的m − 1 位和 nums2 的 n − 1 位。每次将较大的那个数字复制到 nums1 的后边,然后向前移动一位。因为我们也要定位 nums1 的末尾,所以我们还需要第三个指针,以便复制。
在以下的代码里,我们直接利用 m 和 n 当作两个数组的指针,再额外创立一个 pos 指针,起始位置为 m +n−1。每次向前移动 m 或 n 的时候,也要向前移动 pos。这里需要注意,如果 nums1的数字已经复制完,不要忘记把 nums2 的数字继续复制;如果 nums2 的数字已经复制完,剩余nums1 的数字不需要改变,因为它们已经被排好序。
注意
这里我们使用了 ++ 和–的小技巧:a++ 和 ++a 都是将 a 加 1,但是 a++ 返回值为 a,而++a 返回值为 a+1。如果只是希望增加 a 的值,而不需要返回值,则推荐使用 ++a,其运行速度会略快一些
错误代码:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int pos = m-- + n-- - 1;
//在这里 while(m>=0 && n>=0),m条件必须在前面,如果n条件在前,
//有一种错误情况,m初始就为0,导致第一个while循环和第二个循环都运行不了;
while(n >= 0 && m >= 0){
nums1[pos--] = nums1[m]>nums2[n]?nums1[m--]:nums2[n--];
}
while(m>=0){
nums1[pos--] = nums1[m--];
}
}
};
正确代码:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
/*
这个方法,太好解了,可能不是面试官想要的解法
for(int i = 0 ; i <n ; i++){
nums1[m + i] = nums2[i];
}
sort(nums1.begin(),nums1.end());
*/
int pos = m-- + n-- - 1;//先取出最大下标,再--
while(m>=0 && n>=0){
nums1[pos--] = nums1[m] > nums2[n] ? nums1[m--] : nums2[n--];
}
while(n >= 0){
nums1[pos--] = nums2[n--];
}
}
};
3.4 快慢指针
[141. 环形链表]*
题目描述
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
题解
对于链表找环路的问题,有一个通用的解法——快慢指针(Floyd 判圈法)。给定两个指针,分别命名为 slow 和 fast,起始位置在链表的开头。每次 fast 前进两步,slow 前进一步。如果 fast可以走到尽头,那么说明没有环路;如果 fast 可以无限走下去,那么说明一定有环路,且一定存在一个时刻 slow 和 fast 相遇。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
if(head==NULL)return false;
ListNode * slow = head , * fast = head;
do
{
//因为快指针跑的快,如果有指针指向NULL代表不是环形链表
//如果有一个为NULL,后续走两步也会报错.
if(fast==NULL||fast->next==NULL)return false;
slow = slow->next;
fast = fast->next->next;
}while(slow != fast);
return true;
}
};
[142. 环形链表 II]*
题目描述
给定一个链表的头节点
head,返回链表开始入环的第一个节点。 如果链表无环,则返回null。
题解
当 slow 和 fast 第一次相遇时
我们将 fast 重新移动到链表开头,并让 slow 和 fast 每次都前进一步。
当 slow 和 fast 第二次相遇时,相遇的节点即为环路的开始点。
详解:
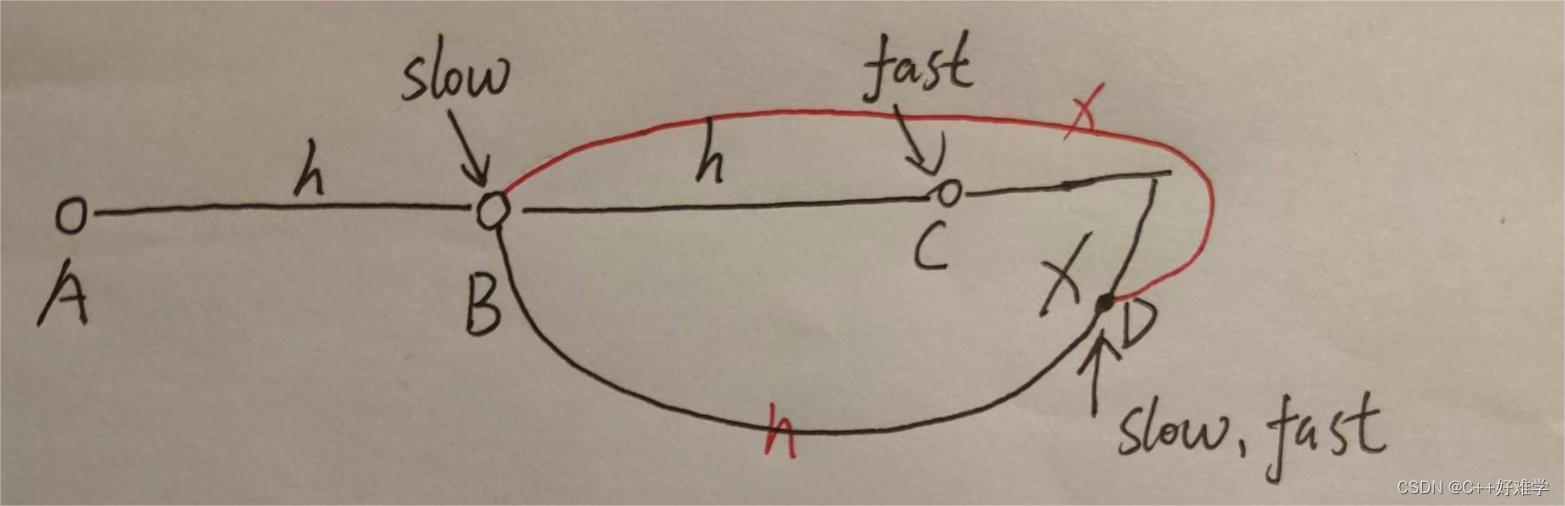
- A:起点 B:环路的初始点 C:slow到达B点的时候fast到达的点 D:第一次相聚的点
- slow移动h时候,到达B点,此时fast到达C点,在移动方向上fast离B点为x(C -> B点的距离)
- 此时两个点相距x,可以理解为fast追赶slow,当fast移动2x的时候,slow移动x,此时两个在D点第一次相聚
- slow移动x到D,所以B->D的距离为x,所以 D-> B的距离为h
- 所以AB的距离等于DB的距离
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode *slow = head, *fast = head;
// 判断是否存在环路
do {
if (!fast || !fast->next) return NULL;//如果不是环状则从这退出
fast = fast->next->next;
slow = slow->next;
} while (fast != slow);//如果是环状则从这退出循环
// 运行到这里就是存在环状,查找环路节点
fast = head;
while (fast != slow) {
slow = slow->next;
fast = fast->next;
}
return fast;
}
};
3.5 acwing双指针
对于形如
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
}
}
这一类的双层循环,可能可以使用双指针来进行优化,从而能够把时间复杂度从O(n2)降低到O(n)
模板
for (int i = 0, j = 0; i < n; i ++ )
{
while (j < i && check(i, j)) j ++ ;
// 具体问题的逻辑
}
常见问题分类:
(1) 对于一个序列,用两个指针维护一段区间
(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
[799. 最长连续不重复子序列 - AcWing题库]*
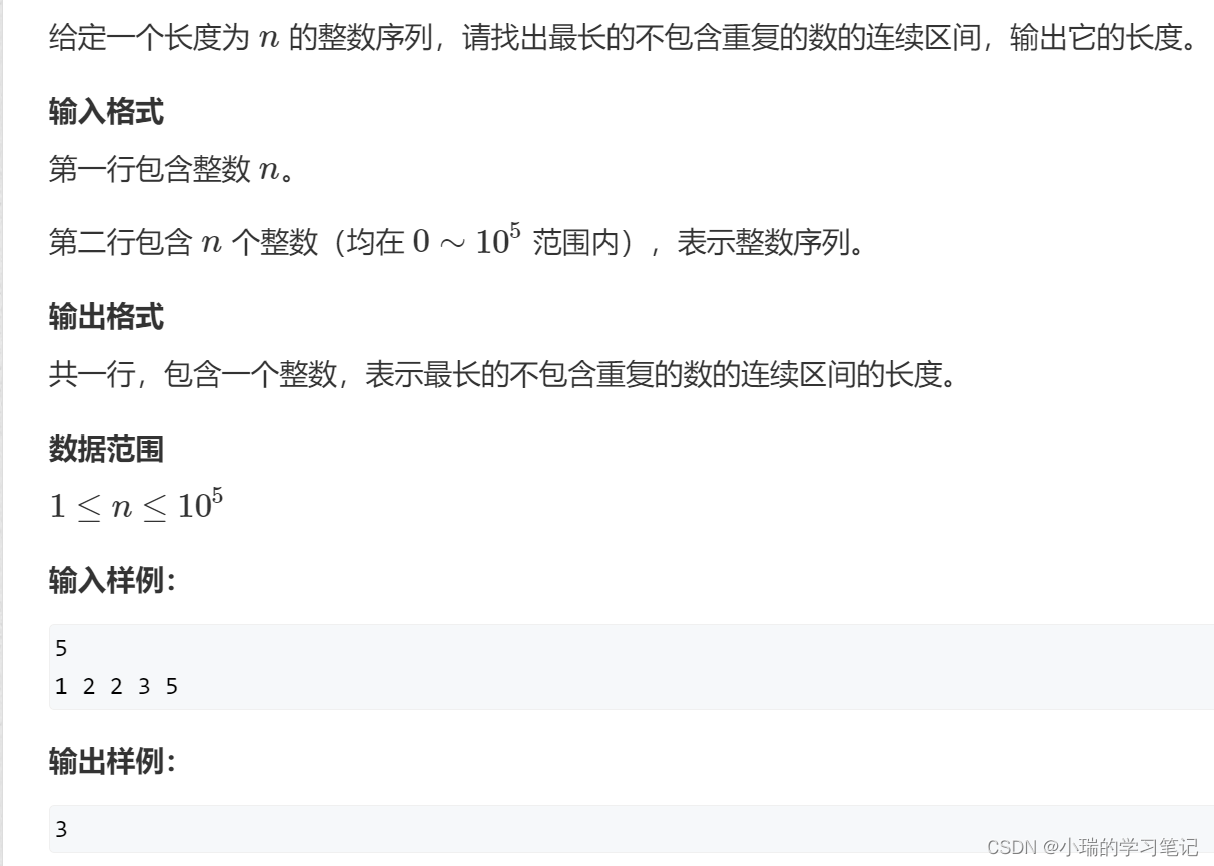
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int q[N], c[N]; // 这里对于判断重复, 采用了计数排序的思想, 若数的范围较大, 或者数不是整数, 可以考虑用哈希表
int main() {
scanf("%d", &n);
for(int i = 0; i < n; i++) scanf("%d", &q[i]);
int res = 0;
for(int i = 0, j = 0; i < n; i++) {
c[q[i]]++; // i往后移动一位, 计数加一, 将q[i]这个数纳入判重的集合
while(c[q[i]] > 1) { // 若在[j, i]区间内有重复元素的话, 只可能重复新加入的这个q[i], 只需判断q[i]的个数大于1
// 有重复, j 往右移动一位
c[q[j]]--; // 将j这个位置的数的计数减1, 即把q[j]从判重的集合中移除
j++;
}
res = max(res, i - j + 1); // 针对该i, 找到最远的左端点j
}
printf("%d", res);
return 0;
}
[800. 数组元素的目标和 - AcWing题库]*

#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int a[N], b[N];
int main() {
int n, m, x;
scanf("%d%d%d", &n, &m, &x);
for(int i = 0; i < n; i++) scanf("%d", &a[i]);
for(int i = 0; i < m; i++) scanf("%d", &b[i]);
int i = 0, j = m - 1;
while(i < n && j >= 0) {
int sum = a[i] + b[j];
if(sum < x) i++;
else if(sum > x) j--;
else break;
}
printf("%d %dn", i, j);
return 0;
}
[2816. 判断子序列 - AcWing题库]*

#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int a[N], b[N];
int main() {
int n, m;
scanf("%d%d", &n, &m);
for(int i = 0; i < n; i++) scanf("%d", &a[i]);
for(int i = 0; i < m; i++) scanf("%d", &b[i]);
int i = 0, j = 0;
while(i < n && j < m) {
if(a[i] == b[j]) {
i++;
j++;
} else j++;
}
if(i < n) printf("Non");
else printf("Yesn");
return 0;
}
小结
双指针算法,通常是适用于有两层循环的情况(循环变量分别为i,j)。首先是写一个暴力的解法,然后观察一下i和j之间是否存在单调性的关系(即i和j是否都往着同一个方向移动,不回头)。若i和j之间存在着这种单调性关系,则我们可以用双指针,来将时间复杂度从O(n2)降低到O(n)。
3.6 滑动窗口
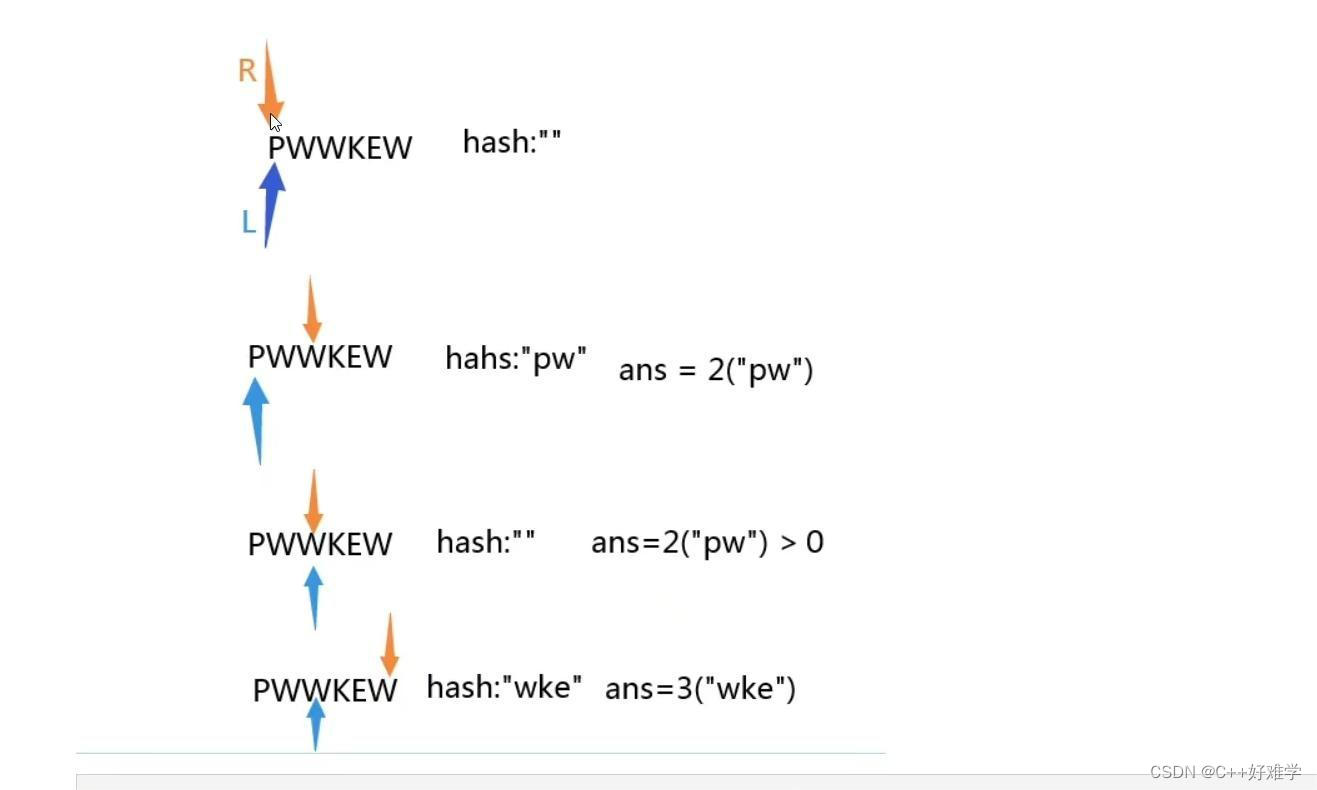
[3. 无重复字符的最长子串]
题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的最长子串的长度。
输入输出样例
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
题解
- 给定一个字符串
s,请你找出其中不含有重复字符的 最长子串 的长度。 - 这里运用了unordered_map容器主要的用处是保存两个指针之间的字母,还有就是判断两个指针之间有没有相同的字母
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int len = s.length();
int ret = 0;
//把这两个看成左指针右指针
int Lptr=0 ;
unordered_map<char,int> mm;
for(int Rptr = 0 ; Rptr < len ; Rptr++)
{
//把每一个元素都加入哈希表中
//就算有相同的元素,新加入的元素依然在会有自己的位置,
//哈希表中元素和字符串中元素排列相同
mm[s[Rptr]]++;
//这里运用循环很关键,可以参图片来考虑
while(mm[s[Rptr]] == 2)
{
//此时,把左指针向右移动,
//那么窗口中就少了一个元素,所以要-- , 此时符合情况
mm[s[Lptr]]--;
Lptr++;
}
ret = max(ret , Rptr - Lptr + 1);
}
return ret;
}
};
3.6 练习
[633. 平方数之和]
题目描述
给定一个非负整数
c,你要判断是否存在两个整数a和b,使得a2 + b2 = c。
示例 1:
输入:c = 5
输出:true
解释:1 * 1 + 2 * 2 = 5
示例 2:
输入:c = 3
输出:false
题解
本题利用双指针,左指针指向0,右指针指向c的算数平方根,
class Solution {
public:
bool judgeSquareSum(int c) {
long left = 0;
long right = (int)sqrt(c);
while (left <= right) {
long sum = left * left + right * right;
if (sum == c) {
return true;
} else if (sum > c) {
right--;
} else {
left++;
}
}
return false;
}
};
[680. 验证回文串 II]
题目描述
给你一个字符串
s,最多 可以从中删除一个字符。请你判断
s是否能成为回文字符串:如果能,返回true;否则,返回false。
示例 1:
输入:s = “abca”
输出:true
解释:你可以删除字符 ‘c’ 。
示例 2:
输入:s = “abc”
输出:false
题解
题目所给函数 validPalindrome 先判断是否有不一样的元素,如果有那么就删除一个字母(这里是跳过一个字母)
尝试把左指针+1,或者右指针-1,然后调用函数isNo()判断调整后的是否是回文字符串,两种方式成功一个就可。
class Solution {
public:
bool isNo(string s , int L , int R){
while(L<R){
if(s[L]!=s[R]) return false;
L++;
R--;
}
return true;
}
bool validPalindrome(string s) {
for(int L = 0 , R = s.size() - 1 ; L < R ; L++,R--){
if(s[L]!=s[R]){
return isNo(s,L+1,R)||isNo(s,L,R-1);
}
}
return true;
}
};
[524. 通过删除字母匹配到字典里最长单词]
题目描述
给你一个字符串
s和一个字符串数组dictionary,找出并返回dictionary中最长的字符串,该字符串可以通过删除s中的某些字符得到。如果答案不止一个,返回长度最长且字母序最小的字符串。如果答案不存在,则返回空字符串。
示例 1:
输入:s = “abpcplea”, dictionary = [“ale”,“apple”,“monkey”,“plea”]
输出:“apple”
示例 2:
输入:s = “abpcplea”, dictionary = [“a”,“b”,“c”]
输出:“a”
题解
ans保存答案,dstr保存容器中的需要测试是否相等的字符串
通过第一层循环,把每一个容器中的每一个字符串拿出来,进行测试
通过第二层循环,判断是否包含全部字符,
若包含则与之前保存的字符串进行对比,若长度大于之前的 或者 长度相等但字符序较小的 则重新赋值
注意
compare():在不同的编译器下返回值不同
- 当相等的时候返回0,不相等的时候返回 -1 ,1
- 当相等的时候返回0,不相等的时候返回 ascii 的差值
class Solution {
public:
string findLongestWord(string s, vector<string>& dictionary) {
string ans = "" , dstr = "";
for(int m = 0 ; m < dictionary.size() ; m++){
dstr = dictionary[m];
for(int i = 0 , j = 0 ; i < s.size() && j < dstr.size() ; i++){
if(s[i] == dstr[j])j++;
if(j == dstr.size()){
if(dstr.size() > ans.size() ||
(dstr.size() == ans.size() && ans.compare(dstr) > 0))
ans = dstr;
}
}
}
return ans;
}
};
第 4 章 居合斩!二分查找
4.1 算法解释
二分查找也常被称为二分法或者折半查找,每次查找时通过将待查找区间分成两部分并只取一部分继续查找,将查找的复杂度大大减少。对于一个长度为 O(n) 的数组,二分查找的时间复杂度为 O(log n)。
举例来说,给定一个排好序的数组 {3,4,5,6,7},我们希望查找 4 在不在这个数组内。第一次折半时考虑中位数 5,因为 5 大于 4, 所以如果 4 存在于这个数组,那么其必定存在于 5 左边这一半。于是我们的查找区间变成了 {3,4,5}。(注意,根据具体情况和您的刷题习惯,这里的 5 可以保留也可以不保留,并不影响时间复杂度的级别。)第二次折半时考虑新的中位数 4,正好是我们需要查找的数字。于是我们发现,对于一个长度为 5 的数组,我们只进行了 2 次查找。如果是遍历数组,最坏的情况则需要查找 5 次。
我们也可以用更加数学的方式定义二分查找。给定一个在 [a, b] 区间内的单调函数 f (x),若f (a) 和 f (b) 正负性相反,那么必定存在一个解 c,使得 f (c) = 0。在上个例子中,f (x) 是离散函数f (x) = x +2,查找 4 是否存在等价于求 f (x) −4 = 0 是否有离散解。因为 f (1) −4 = 3−4 = −1 < 0、f (5) − 4 = 7 − 4 = 3 > 0,且函数在区间内单调递增,因此我们可以利用二分查找求解。如果最后二分到了不能再分的情况,如只剩一个数字,且剩余区间里不存在满足条件的解,则说明不存在离散解,即 4 不在这个数组内。
具体到代码上,二分查找时区间的左右端取开区间还是闭区间在绝大多数时候都可以,因此有些初学者会容易搞不清楚如何定义区间开闭性。这里我提供两个小诀窍,第一是尝试熟练使用一种写法,比如左闭右开(满足 C++、Python 等语言的习惯)或左闭右闭(便于处理边界条件),尽量只保持这一种写法;第二是在刷题时思考如果最后区间只剩下一个数或者两个数,自己的写法是否会陷入死循环,如果某种写法无法跳出死循环,则考虑尝试另一种写法。
二分查找也可以看作双指针的一种特殊情况,但我们一般会将二者区分。双指针类型的题,指针通常是一步一步移动的,而在二分查找里,指针每次移动半个区间长度。
二分法知识点
左闭右闭&左闭右开----讲解视频
手把手带你撕出正确的二分法 | 二分查找法 | 二分搜索法 | LeetCode:704. 二分查找_哔哩哔哩_bilibili
4.2 求开方
[69. x 的平方根 ]
题目描述
给定一个非负整数,求它的开方,向下取整。
输入输出样例
输入一个整数,输出一个整数。
Input: 8
Output: 2
8 的开方结果是 2.82842…,向下取整即是 2。
题解
- 为了防止 int 溢出所以用long
- 使用了左闭右闭的写法,所以L <= R
class Solution {
public:
int mySqrt(int x) {
if(x == 0) return 0;
int l = 0 , r = x;
int ans = 0;
while(r > l){
long mid = ((long)r + (long)l + 1) / 2;
long a = mid * mid;
if(a <= x){
l = mid;
ans = mid;
}else{
r = mid - 1;
}
}
return ans;
}
};
4.3 查找区间
[34. 在排序数组中查找元素的第一个和最后一个位置]
题目描述
给定一个增序的整数数组和一个值,查找该值第一次和最后一次出现的位置。
输入输出样例
输入是一个数组和一个值,输出为该值第一次出现的位置和最后一次出现的位置(从 0 开始);如果不存在该值,则两个返回值都设为-1。
Input: nums = [5,7,7,8,8,10], target = 8
Output: [3,4]
数字 8 在第 3 位第一次出现,在第 4 位最后一次出现。
题解
写出两个辅助函数,利于解题。
class Solution {
public:
//主函数
vector<int> searchRange(vector<int>& nums, int target) {
int L = start(nums , target);
int R = end(nums , target);
vector<int> v{L , R};
return v;
}
//取出下标最小的目标值
int start(vector<int>& nums, int target) {
//- 1 是为了取出第一个有用的值
int L = 0 , R = nums.size() - 1 , ans = -1;
while(R >= L){
int mid = L + (R - L)/2;
//一开始因为>所以移动,后来因为=移动找到最左边符合的值
if(nums[mid] >= target){
ans = mid;
R = mid - 1;
}else{
L = mid +1;
}
}
if(ans == -1 || nums[ans] != target) return -1;
return ans;
}
//取出下标最大的目标值
int end(vector<int>& nums, int target) {
int L = 0 , R = nums.size() - 1, ans = -1;
while(R >= L){
int mid = L + (R - L)/2;
//一开始因为<所以移动,后来因为=移动找到最右边符合的值
if(nums[mid] <= target){
ans = mid;
L = mid +1;
}else{
R = mid - 1;
}
}
if(ans == -1 || nums[ans] != target) return -1;
return ans;
}
};
4.4 旋转数组查找数字
[33. 搜索旋转排序数组]*
整数数组
nums按升序排列,数组中的值 互不相同 。在传递给函数之前,
nums在预先未知的某个下标k(0 <= k < nums.length)上进行了 旋转,例如,[0,1,2,4,5,6,7]在下标3处经旋转后可能变为[4,5,6,7,0,1,2]。给你 旋转后 的数组
nums和一个整数target,如果nums中存在这个目标值target,则返回它的下标,否则返回-1。你必须设计一个时间复杂度为
O(log n)的算法解决此问题。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
题解
先通过第一个元素的值和中间值比较,若小于中间值,则前面有序,反之后面有序.然后判断元素是否在有序一侧,反复循环缩小范围,
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (right >= left) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)return mid;
//[1,2,3,4,5] 但左指针和右指针分别指向1,2 查找元素2 在if有=的情况下,执行 右边界有序的else
//在第一个没有=的情况下,执行 左边界有序else 则right = -1越界,出错
//所以在两个数字的情况下,若要分成两部分则,第一个数一部分,第二个数一部分
//所以if一个有=
if (nums[mid] >= nums[left]) { //= 是为了接受两个元素情况下的中间元素
//在左边有序的情况下,判断元素是否在左半侧
if (target < nums[mid] && target >= nums[left]) {
right = mid - 1;
}
else {
left = mid + 1;
}
}
else {
if (target > nums[mid] && target <= nums[right]) {
left = mid + 1;
}
else {
right = mid - 1;
}
}
}
return -1;
}
};
4.5 查找数字
算法思想:
- 首先对数组进行排序。
- 将要查找值x与数组中间值mid相比较;
- 如果
x=mid,则找到x,退出程序; - 如果
x<mid,则将边界设为[left,mid]; - 如果
x>mid,则将边界设为[mid+1,right]; - 循环执行4,5两步骤,若直到数组长度为1,还没找打x,则数组中不存在x
整数二分查找模板
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l;
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
[789. 数的范围 - AcWing题库]*
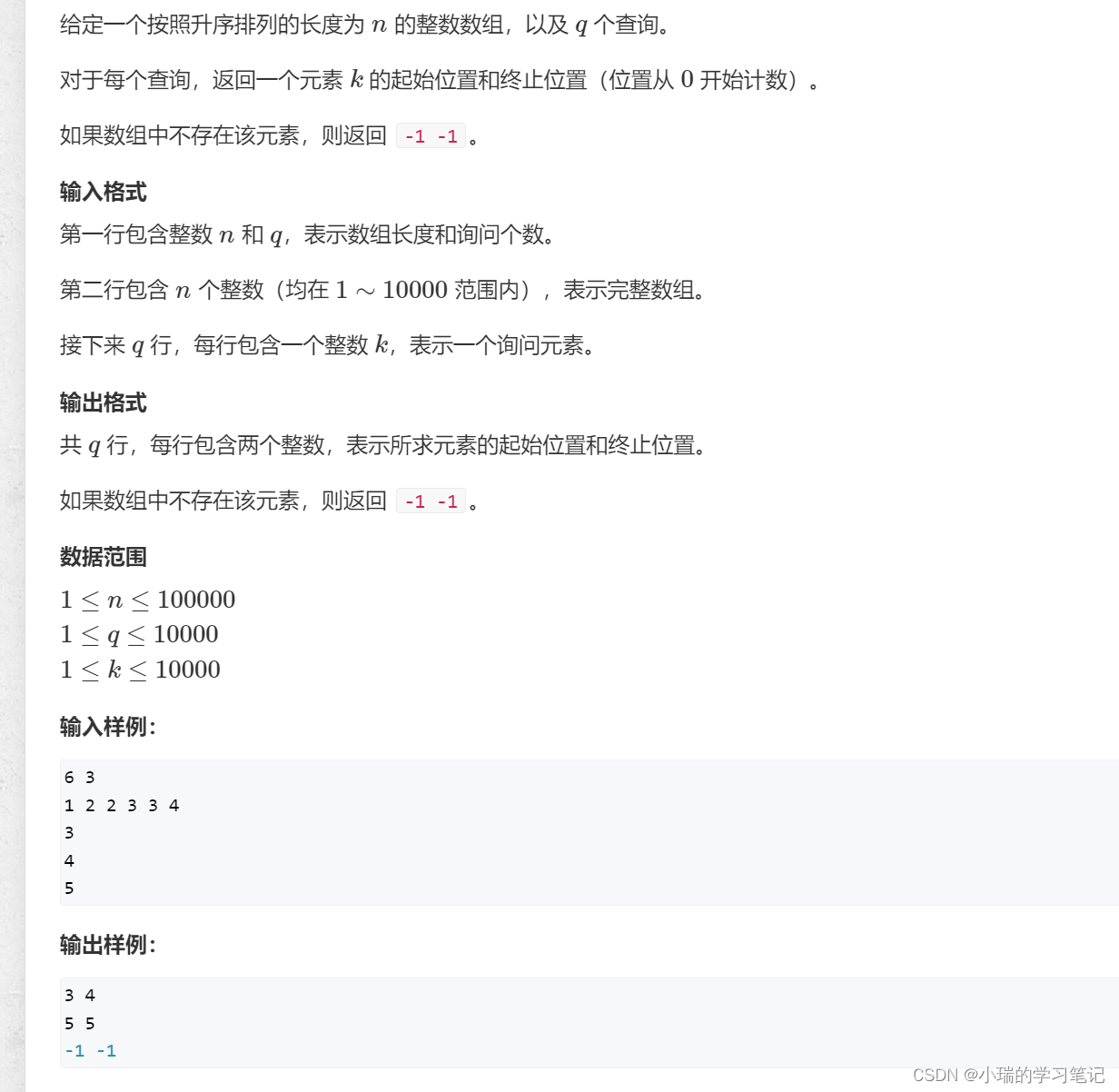
代码
//整数二分查找
#include <iostream>
#include <stdio.h>
using namespace std;
const int N = 1e6 + 10;
int q[N];
int n, m;
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i++)
scanf("%d", &q[i]);
while (m--)
{
int x;
scanf("%d", &x);
int l = 0, r = n - 1;
//取第一个等于x的数,右边界等于mid
while (l < r)
{
int mid = l + r >> 1;
if (x <= q[mid])
r = mid;
else
l = mid + 1;
}
if (q[l] != x)
cout << "-1 -1" << endl;
else
{
cout << l << " ";
int l = 0, r = n - 1;
//取最后一个等于x的数,左边界等于mid
while (l < r)
{
int mid = l + r + 1 >> 1;
if (x >= q[mid])
l = mid;
else
r = mid - 1;
}
cout << l << endl;
}
}
return 0;
}
第 5 章 千奇百怪的排序算法
5.1 常用排序算法
以下是一些最基本的排序算法。虽然在 C++ 里可以通过 std::sort() 快速排序,而且刷题时很少需要自己手写排序算法,但是熟习各种排序算法可以加深自己对算法的基本理解,以及解出由这些排序算法引申出来的题目。
5.2 快速选择
算法思想: 分治思想
时间复杂度:平均时间复杂度:
O ( nlog2 n )。
- 如果
left>=right,则退出; - 在数组中随即确定一个分界点x,假设
x=q[l]; - 设指针i,j,分别指向left,right;
- 当
i<j时,循环执行5,6,7步; - 如果i指针所指向的数小于x,则
i++;否则,跳出循环; - 如果j指针所指向的数大于x,则
j--;否则,跳出循环; - 如果
i<j,则swap(arr[i],arr[j]); - 调整区间,递归处理左右两段,
quick_sort(arr,left,i);quick_sort(arr,i+1,right);
模板
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}
[785. 快速排序 - AcWing题库]*

代码
#include <iostream>
#include <stdio.h>
using namespace std;
const int N = 1e6 + 10;
int n;
int q[N];
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int x = q[l], i = l - 1, j = r + 1;
while (i < j)
{
//如果12 12不先进行++,--操作的话,会造成死循环
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
//会一直存在(0,i)区间,死循环
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
int main()
{
//数组元素个数n
scanf("%d", &n);
//接收数组元素
for (int i = 0; i < n; i++)
scanf("%d", &q[i]);
quick_sort(q, 0, n - 1);
for (int i = 0; i < n; i++)
printf("%d ", q[i]);
return 0;
}
[786. 第k个数 - AcWing题库]*

#include<iostream>
using namespace std;
const int N = 1e5 +10;
int n, k;
int q[N];
// 选取[l, r]区间内数组q第k小的数
int quick_select(int q[], int l, int r, int k) {
if(l == r) return q[l]; // 找到答案
int x = q[l + r >> 1], i = l - 1, j = r + 1;
while(i < j) {
while(q[++i] < x);
while(q[--j] > x);
if(i < j) swap(q[i], q[j]);
}
int left = j - l + 1;
if(k <= left) return quick_select(q, l, j, k);
else return quick_select(q, j + 1, r, k - left);
}
int main() {
scanf("%d%d", &n, &k);
for(int i = 0; i < n; i++) scanf("%d", &q[i]);
printf("%d", quick_select(q, 0, n - 1, k));
return 0;
}
[215. 数组中的第K个最大元素]
题目描述
在一个未排序的数组中,找到第 k 大的数字。
输入输出样例
输入一个数组和一个目标值 k,输出第 k 大的数字。题目默认一定有解。
Input: [3,2,1,5,6,4] and k = 2
Output: 5
题解
将所有元素放入优先队列,优先队列的顶端就是当前最大的数
然后弹出k - 1次最大的顶端数字,最后剩下的顶端就是我们需要的答案
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
priority_queue<int , vector<int> , less<int>> q;
for(int i = 0 ; i < nums.size() ; i++){
q.push(nums[i]);
}
for(int i = 0 ; i < k - 1; i++){
q.pop();
}
return q.top();
}
};
5.3 桶排序
[347. 前 K 个高频元素]
题目描述
给定一个数组,求前 k 个最频繁的数字。
输入输出样例
输入是一个数组和一个目标值 k。输出是一个长度为 k 的数组。
Input: nums = [1,1,1,1,2,2,3,4], k = 2
Output: [1,2]
在这个样例中,最频繁的两个数是 1 和 2。
题解
把元素出现的次数计数 first保存值 second保存出现次数
使用优先队列,把出现次数多的排在前面
小结
- 遍历容器的话,感觉还是新特性好用一些,以后都用新特性,别忘了用引用,返回的是值不是指针
- 使用vector来说虽然麻烦了一点,但是相对优先队列来说他可以用下标访问,更加方便,功能更多
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int , int> mm;
for(auto & num : nums) mm[num]++;
vector<pair<int , int>> vv;
for(auto & it : mm) vv.push_back(it);
sort(vv.begin() , vv.end() , [](pair<int , int> pa1 , pair<int , int> pa2){
return pa1.second > pa2.second;
});
vector<int> ans;
for(auto & a : vv){
ans.push_back(a.first);
if(ans.size() == k) return ans;
}
return ans;
}
};
- 使用优先队列,每次访问元素都要出队,有点麻烦
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int , int> mm;
for(int x : nums) mm[x]++;
priority_queue<pair<int , int>> pq;
for(auto& p : mm)pq.push({p.second , p.first});
vector<int> ans(k);
for(int i = 0 ; i < k ; i++){
ans[i] = pq.top().second;
pq.pop();
}
return ans;
}
};
5.4 归并排序
算法思想:
时间复杂度:O(nlog2n)。
- 取数组的中间值作为分界点mid;
- 将mid左边的序列,右边的序列分别排好序;
- 对左右序列进行合并。
模板
void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
[787. 归并排序 - AcWing题库]*

代码
#include <iostream>
#include <stdio.h>
using namespace std;
const int N = 1e6 + 10;
int q[N], tmp[N];
int n;
void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid), merge_sort(q, mid + 1, r);
//记录左右两边的起点
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j])
tmp[k++] = q[i++];
else
tmp[k++] = q[j++];
while (i <= mid)
tmp[k++] = q[i++];
while (j <= mid)
tmp[k++] = q[j++];
//排好序的写回原来的数组
for (i = l, j = 0; i <= r; i++, j++)
q[i] = tmp[j];
}
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i++)
scanf("%d", &q[i]);
merge_sort(q, 0, n - 1);
for (int i = 0; i < n; i++)
printf("%d ", q[i]);
return 0;
}
[788. 逆序对的数量 - AcWing题库]*
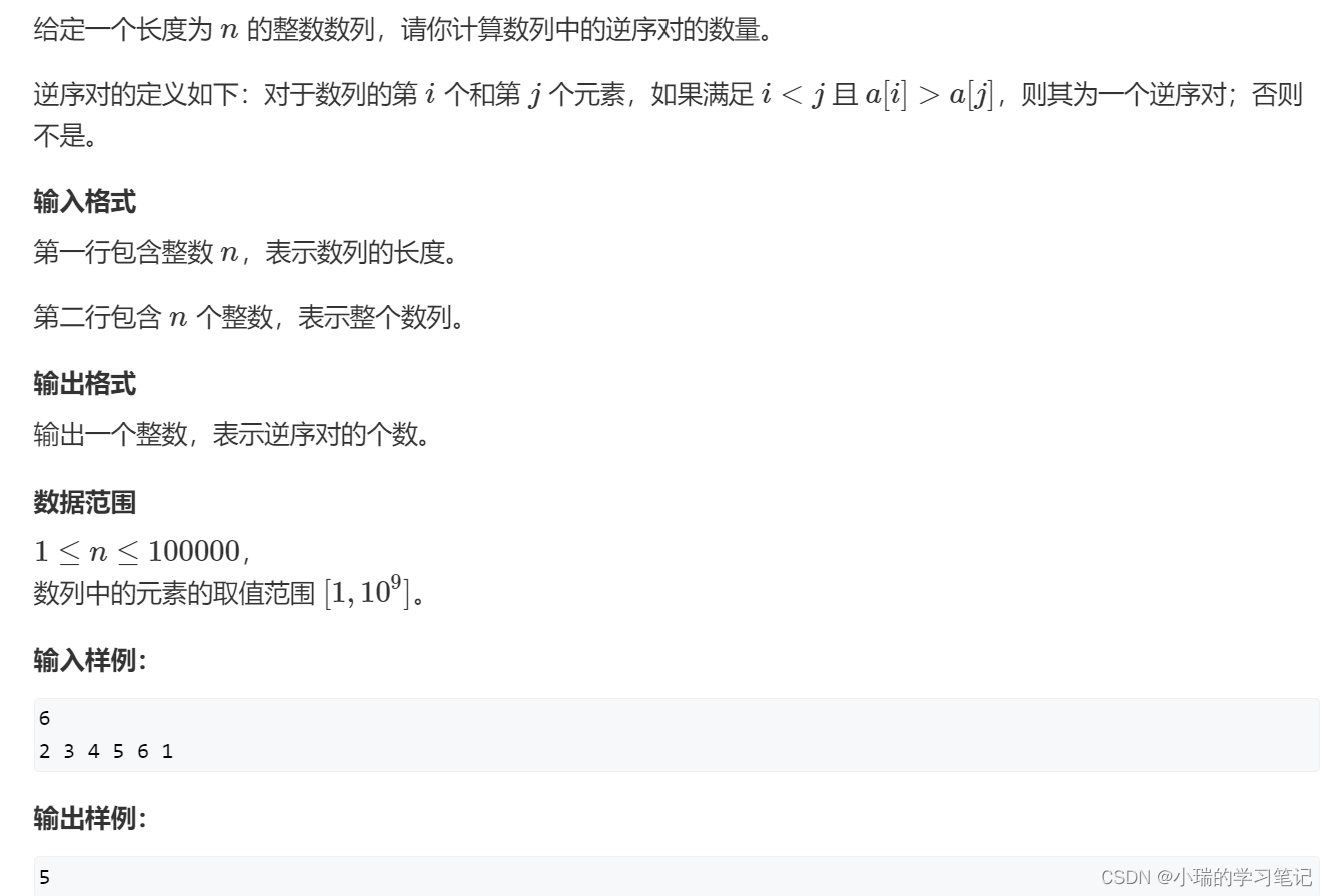
#include<iostream>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n;
int q[N], tmp[N];
// 返回区间[l, r]中的逆序对的数量
LL merge_sort(int q[], int l, int r) {
if(l >= r) return 0;
int mid = l + r >> 1;
LL cnt = merge_sort(q, l, mid) + merge_sort(q, mid + 1, r); // 计算左右区间内各自的逆序对数量
// 合并时, 计算左右两个区间中的数组成的逆序对
int i = l, j = mid + 1, k = 0;
while(i <= mid && j <= r) {
if(q[i] <= q[j]) tmp[k++] = q[i++];
else {
cnt += mid - i + 1;
tmp[k++] = q[j++];
}
}
while(i <= mid) tmp[k++] = q[i++];
while(j <= r) tmp[k++] = q[j++];
for(int i = l, k = 0; i <= r; i++, k++) q[i] = tmp[k];
return cnt;
}
int main() {
scanf("%d", &n);
for(int i = 0; i < n; i++) scanf("%d", &q[i]);
LL cnt = merge_sort(q, 0, n - 1);
printf("%lld", cnt);
return 0;
}
5.5 练习
[451. 根据字符出现频率排序]
题目描述:
给定一个字符串
s,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。返回 已排序的字符串 。如果有多个答案,返回其中任何一个。
示例 1:
输入: s = "tree"
输出: "eert"
解释: 'e'出现两次,'r'和't'都只出现一次。
因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。
题解:
- 先用unordered_map计算出每个元素出现的频率
- 用vector保存元素及其他出现的频率,然后排序让频率高的放在前面
- 用string保存排好序的元素,返回字符串
class Solution {
public:
string frequencySort(string s) {
unordered_map<char , int> mm;
for(char & ch : s) mm[ch]++;
vector<pair<char , int>> v;
for(auto pa : mm) v.push_back(pa);
sort(v.begin() , v.end() , [](pair<char , int> p1 , pair<char , int> p2){
return p1.second > p2.second;
});
string ss = "";
for(auto pa : v){
for(int i = 0 ; i < pa.second ; i++){
ss.push_back(pa.first);
}
}
return ss;
}
};
第 6 章 一切皆可搜索
6.1 算法解释
深度优先搜索和广度优先搜索是两种最常见的优先搜索方法,它们被广泛地运用在图和树等结构中进行搜索。
6.2 深度优先搜索
深度优先搜索(depth-fifirst seach,DFS)在搜索到一个新的节点时,立即对该新节点进行遍
历;因此遍历需要用先入后出的栈来实现,也可以通过与栈等价的递归来实现。对于树结构而言,
由于总是对新节点调用遍历,因此看起来是向着“深”的方向前进。
有时我们可能会需要对已经搜索过的节点进行标记,以防止在遍历时重复搜索某个节点,这
种做法叫做状态记录或记忆化(memoization)。
[695. 岛屿的最大面积]
题目描述
给定一个二维的 0-1 矩阵,其中 0 表示海洋,1 表示陆地。单独的或相邻的陆地可以形成岛屿,每个格子只与其上下左右四个格子相邻。求最大的岛屿面积。
输入输出样例
输入是一个二维数组,输出是一个整数,表示最大的岛屿面积。
Input:
[[1,0,1,1,0,1,0,1],
[1,0,1,1,0,1,1,1],
[0,0,0,0,0,0,0,1]]
Output: 6
最大的岛屿面积为 6,位于最右侧。
题解
- 此题是十分标准的搜索题,我们可以拿来练手深度优先搜索。一般来说,深度优先搜索类型的题可以分为主函数和辅函数,主函数用于遍历所有的搜索位置,判断是否可以开始搜索,如果可以即在辅函数进行搜索。
- 辅函数则负责深度优先搜索的递归调用。
class Solution {
public:
int dir[5] = {1 , 0 , -1 , 0 , 1};
int dfs(int x , int y , vector<vector<int>>& grid){
int ans = 1;
grid[x][y] = 0;//标记这个点不可再被访问
for(int i = 0 ; i < 4 ; ++i){
int nx = x + dir[i];
int ny = y + dir[i+1];
if(nx >= 0 && nx < grid.size() && ny >= 0 && ny < grid[0].size() && grid[nx][ny] == 1){
ans = ans + dfs(nx , ny , grid);
}
}
return ans;
}
int maxAreaOfIsland(vector<vector<int>>& grid) {
int ans = 0;
for(int i = 0 ; i < grid.size() ; ++i){
for(int j = 0 ; j < grid[0].size() ; ++j){
if(grid[i][j] == 1){
ans = max(ans , dfs(i , j , grid));
}
}
}
return ans;
}
};
[547. 省份数量]
题目描述
有
n个城市,其中一些彼此相连,另一些没有相连。如果城市a与城市b直接相连,且城市b与城市c直接相连,那么城市a与城市c间接相连。若 i 城市和 j 城市相连则
isConnected[i][j] = 1,isConnected[j][i] = 1反之都等于1省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。所以二维数组是一个根据对角线重叠的数组
给你一个
n x n的矩阵isConnected,其中isConnected[i][j] = 1表示第i个城市和第j个城市直接相连,而isConnected[i][j] = 0表示二者不直接相连。
输入输出样例
输入:
| 城市1 | 城市2 | 城市3 | 城市4 | |
|---|---|---|---|---|
| 城市1 | 1 | 0 | 0 | 1 |
| 城市2 | 0 | 1 | 1 | 0 |
| 城市3 | 0 | 1 | 1 | 1 |
| 城市4 | 1 | 0 | 1 | 1 |
输出: 1
题解
看到这个格式实属让我想起了哈希表
- 先把四个城市设为false设为没有被遍历过,当遍历后设为true
- 首先从城市1开始找相连城市:
- 上述流程图就是一个遍历的过程,其实当走到城市4的时候,还应该遍历一下城市2,但是因为这是深度优先遍历,所以被城市3先访问了
- 所以上述只有一个省份
//辅助函数
void dfs(int index, vector<vector<int>>& isConnected, vector<bool> & v) {
v[index] = true;//这个节点已经被访问了
for (int i = 0; i < isConnected.size(); ++i) {
if (isConnected[index][i] == 1 && v[i] == false) {
dfs(i, isConnected, v);
}
}
}
//主函数
int findCircleNum(vector<vector<int>>& isConnected) {
int size = isConnected.size(), ans = 0;
vector<bool> v(size, false);//先设为都没有被访问过
for (int i = 0; i < size; ++i) {
if (v[i] == false) {
//不需要返回任何值,只需要遍历与当前节点相连的节点,并设为true
dfs(i, isConnected, v);
ans++;
}
}
return ans;
}
[417. 太平洋大西洋水流问题]
题目描述
给定一个二维的非负整数矩阵,每个位置的值表示海拔高度。假设左边和上边是太平洋,右边和下边是大西洋,求从哪些位置向下流水,可以流到太平洋和大西洋。水只能从海拔高的位置流到海拔低或相同的位置。
输入输出样例
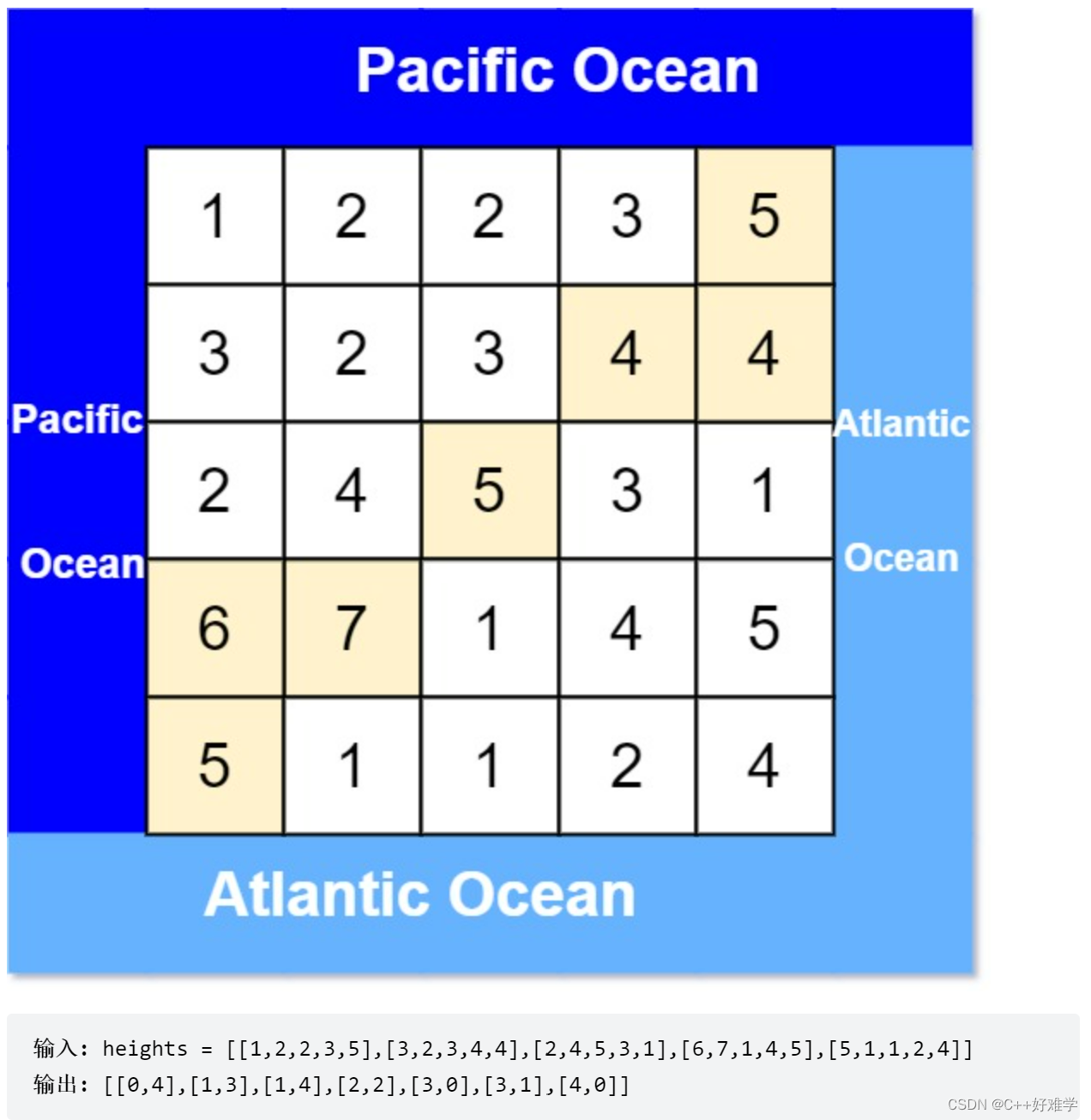
题解
- 首先分别求出那些点可以流到大西洋和太平洋,然后返回可以流到两个洋的点
- 所有点位是否可以流到大洋,用两个bool类型的数组分别保存
- 靠近大洋的点位一定可以流进大洋,所以我们只要找到可以流进旁边点的点位就可以了,所以遍历四周点位
- 最后用数组保存两个洋都可以流入的点位,并且返回
int row = 0, col = 0;
int dir[5] = { 1 , 0 , -1 , 0 , 1 };
void dfs(int x, int y, vector<vector<bool>> & vb, vector<vector<int>>& heights) {
vb[x][y] = true;
for (int i = 0; i < 4; ++i) {
int nx = x + dir[i];
int ny = y + dir[i + 1];
if (nx >= 0 && nx < row && ny >= 0 && ny < col
&& heights[nx][ny] >= heights[x][y] && vb[nx][ny] == false) {
dfs(nx, ny, vb, heights);
}
}
}
vector<vector<int>> pacificAtlantic(vector<vector<int>>& heights) {
row = heights.size(); //行数
col = heights[0].size();//列数
vector<vector<bool>> P(row, vector<bool>(col, false)), A(row, vector<bool>(col, false));
for (int i = 0; i < row; ++i) {
dfs(i, 0, P, heights);//遍历最左边的那列,即靠近太平洋
dfs(i, col - 1, A, heights);//遍历最右边的那一列,即靠近大西洋
}
for (int j = 0; j < col; ++j) {
dfs(0, j, P, heights);//遍历最上面那一行,即靠近太平洋
dfs(row - 1, j, A, heights);//遍历最下面那一行,即靠近大西洋
}
vector<vector<int>> v;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
if (P[i][j] && A[i][j]) v.push_back({ i , j });
}
}
return v;
}
最后
以上就是魁梧酸奶最近收集整理的关于LeetCode 101:和你一起你轻松刷题(C++)总篇章正在陆续更新第 1 章 题目分类第 2 章 最易懂的贪心算法第 3 章 玩转双指针第 4 章 居合斩!二分查找第 5 章 千奇百怪的排序算法第 6 章 一切皆可搜索的全部内容,更多相关LeetCode内容请搜索靠谱客的其他文章。

![[剑指Offer]-和为S的连续正数序列](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)






发表评论 取消回复