我的需求:复现convnext网络模型(convnext+upernet),部署到自己的框架代码中,用于语义分割任务(vaihingen数据集)。
前提:根据mmsegmentation框架中的手册安装mmseg、mmcv等库。
- 进入convnext源码网站:https://github.com/facebookresearch/ConvNeXt
- 进入
semantic_segmantation/文件下 - convnext代码在
backbone/convnext.py中,
其中需要修改的地方:
(1)我的代码中from mmcv_custom import load_checkpoint总是报错mmcv_custom模块找不到,因此将此段代码注释掉,换成from mmcv.runner import _load_checkpoint,这里是参考了mmsegmentation中poolformer代码的处理方法。
(2)修改代码中使用了load_checkpoint的部分(在ConvNeXt类中)
def init_weights(self, pretrained=None):
"""Initialize the weights in backbone.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
def _init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
if isinstance(pretrained, str):
self.apply(_init_weights)
logger = get_root_logger()
load_checkpoint(self, pretrained, strict=False, logger=logger)
elif pretrained is None:
self.apply(_init_weights)
else:
raise TypeError('pretrained must be a str or None')
修改为:
def init_weights(self, pretrained='这里填预训练权重的路径或链接'):
"""Initialize the weights in backbone.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
def _init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
if isinstance(pretrained, str):
self.apply(_init_weights)
logger = get_root_logger()
ckpt_path = pretrained
ckpt = _load_checkpoint(
ckpt_path, logger=logger, map_location='cpu')
if 'state_dict' in ckpt:
_state_dict = ckpt['state_dict']
elif 'model' in ckpt:
_state_dict = ckpt['model']
else:
_state_dict = ckpt
state_dict = _state_dict
missing_keys, unexpected_keys =
self.load_state_dict(state_dict, False)
elif pretrained is None:
self.apply(_init_weights)
else:
raise TypeError('pretrained must be a str or None')
其中,预训练权重在ConvNeXt/semantic_segmentation/文件中的readme.md的表格中,如图:
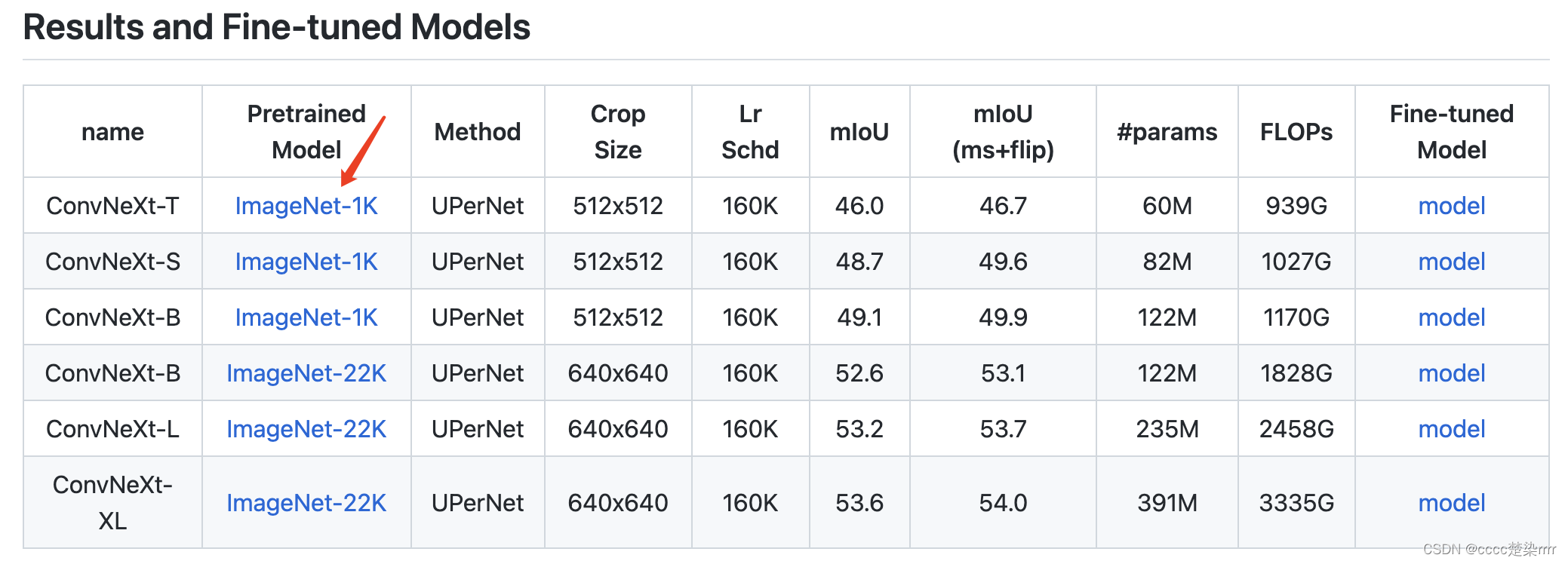
这里我使用的是tiny类型,因此选第一个,可以点击下载放到项目中,也可以复制其链接(鼠标右击复制链接)
(3)官方代码中使用了self.apply(self._init_weights)调用了_init_weights,这里要修改为self.init_weights(),调用修改后的初始化权重函数。
4. Upernet参考博客中的内容。
5. 按照论文中的一些参数设定对参数进行设置,比如学习率、优化策略等。(参考configs/convnext/upernet_convnext_tiny_512_160k_ade20k_ms.py)
结束。
最后
以上就是优秀小天鹅最近收集整理的关于【实验】ConvNeXt+UperNet的全部内容,更多相关【实验】ConvNeXt+UperNet内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复