第五十一周学习笔记
论文阅读概述
Dynamic Routing Between Capsules:This article introduce a novel neural network architecture capsule net which uses group of neural called ‘capsule’ fed by vector input and output vector instead of scalar in traditional CNN and uses dynamic routing algorithm to weight its input vector as replacement of max-pooling, achieving better performance on MNIST.
Capsule Net 代码阅读笔记
代码参考自这里
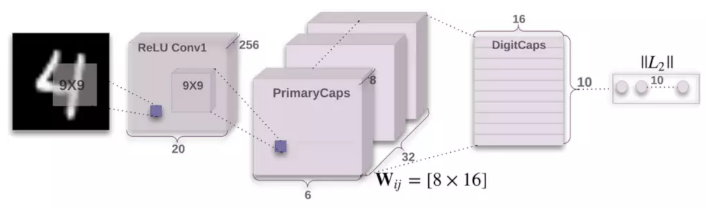
一个对MNIST分类的capsule net由三层组成,第一层是传统的卷积层,第二层是Primary Capsule层,第三层是Digit Capsule层
class CapsNet(nn.Module):
def __init__(self, routing_iterations, in_channels=1, n_classes=10):
super(CapsNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 256, kernel_size=9, stride=1)
self.primaryCaps = PrimaryCapsLayer(256, 32, 8, kernel_size=9, stride=2) # outputs 6*6
self.num_primaryCaps = 32 * 6 * 6
routing_module = AgreementRouting(self.num_primaryCaps, n_classes, routing_iterations)
self.digitCaps = CapsLayer(self.num_primaryCaps, 8, n_classes, 16, routing_module)
def forward(self, input):
x = self.conv1(input)
x = F.relu(x) # bs * 256 * 20 * 20
x = self.primaryCaps(x) # bs * 1152(32*6*6) * 8
x = self.digitCaps(x) # bs * 10 * 16
probs = x.pow(2).sum(dim=2).sqrt() # bs * 10
return x, probs
看过论文后可以了解到,Capsule Net和CNN的两大不同就是,capsule层接受向量输入,并输出向量,两层capsule之间的连接通过动态路由算法(dynamic routing algorithm)完成,那么,为了看懂网络的实际运行,只要依次回答以下几个问题即可
卷积层和Primary capsule如何相接
如上面的代码所示,卷积层经过非线性层后,直接输入到了Primary Capsule中,MNIST图片是28×28的,经过卷积和非线性层后,就变成了256×20×20
class PrimaryCapsLayer(nn.Module):
def __init__(self, input_channels, output_caps, output_dim, kernel_size, stride):
# output_caps 32
# output_dim 8
# kernel size 9
# stride 2
super(PrimaryCapsLayer, self).__init__()
self.conv = nn.Conv2d(input_channels, output_caps * output_dim, kernel_size=kernel_size, stride=stride)
self.input_channels = input_channels
self.output_caps = output_caps
self.output_dim = output_dim
def forward(self, input):
out = self.conv(input)
N, C, H, W = out.size()
# bs * 256(32*8) * 6 * 6
out = out.view(N, self.output_caps, self.output_dim, H, W)
# bs * 32 * 8 * 6 * 6
out = out.permute(0, 1, 3, 4, 2).contiguous()
# bs * 32 * 6 * 6 * 8
out = out.view(out.size(0), -1, out.size(4))
# bs * 1152(32*6*6) * 8
out = squash(out)
return out
在Primary Capsule接受的参数有:
- input channels 256,输入的特征图数
- output_caps 32, 输出的capsule组数
- output_dim 8, 输出的每个capsule的向量维数
- kernel size 9
- stride 2
primary capsule首先通过卷积将256×20×20的特征图卷积成256(output_caps×output_dim)×6×6的特征图,通过第一个view之后,这256×6×6的特征图,就被重排成了32组8×6×6的特征图,然后通过第二个view,重排成了32个6×6×8的tensor,最后,就得到1152(32×6×6)个8维输出向量,这个过程可以画图理解

1152个8维向量就是primary capsule的输出,不过在这之前,还要对向量进行归一化,即squash
def squash(x):
lengths2 = x.pow(2).sum(dim=2)
lengths = lengths2.sqrt()
x = x * (lengths2 / (1 + lengths2) / lengths).view(x.size(0), x.size(1), 1)
return x
就是论文中的
v
j
=
∣
∣
s
j
∣
∣
2
1
+
∣
∣
s
j
∣
∣
2
s
j
∣
∣
s
j
∣
∣
v_j=dfrac{||s_j||^2}{1+||s_j||^2}dfrac{s_j}{||s_j||}
vj=1+∣∣sj∣∣2∣∣sj∣∣2∣∣sj∣∣sj
Primary Capsule如何与digit Capsule相接
此时输入流进入digit Capsule中,是一个规范了的1152×8的向量
class CapsLayer(nn.Module):
def __init__(self, input_caps, input_dim, output_caps, output_dim, routing_module):
# input_caps 32 * 6 * 6
# input_dim 8
# output_caps 10
# output_dim 16
super(CapsLayer, self).__init__()
self.input_dim = input_dim
self.input_caps = input_caps
self.output_dim = output_dim
self.output_caps = output_caps
self.weights = nn.Parameter(torch.Tensor(input_caps, input_dim, output_caps * output_dim))
self.routing_module = routing_module
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.input_caps)
self.weights.data.uniform_(-stdv, stdv)
def forward(self, caps_output):
# caps_output bs * 1152 * 8
caps_output = caps_output.unsqueeze(2) # bs * 1152 * 1 * 8
# self.weights 1152(32*6*6) * 8 * 160
u_predict = caps_output.matmul(self.weights) # bs * 1152 * 1 * 160
u_predict = u_predict.view(u_predict.size(0), self.input_caps, self.output_caps, self.output_dim)
# bs * 1152(32*6*6) * 10 * 16
v = self.routing_module(u_predict)
return v
从参数设定可知,digit capsule接受1152个8维向量作为输入,输出10个16维向量
digit capsule首先将1152个8维向量映射成1152个160维向量,然后重排成1152×10×16的tensor,为了得到最后的输出,即10×16,digit capsule会分别在10组1152个16维的tensor上进行加权,这个过程就通过动态路由完成
class AgreementRouting(nn.Module):
def __init__(self, input_caps, output_caps, n_iterations):
# input_caps 1152(32*6*6)
# output_caps 10
# n_iterations 3
super(AgreementRouting, self).__init__()
self.n_iterations = n_iterations
self.b = nn.Parameter(torch.zeros((input_caps, output_caps)))
def forward(self, u_predict):
batch_size, input_caps, output_caps, output_dim = u_predict.size()
# bs * 1152 * 10 * 16
# b:1152,10
c = F.softmax(self.b, dim=1) # 1152 * 10
s = (c.unsqueeze(2) * u_predict).sum(dim=1) # bs * 10 * 16
v = squash(s)
# if n iteration = 0, means average the feature
if self.n_iterations > 0:
b_batch = self.b.expand((batch_size, input_caps, output_caps))
# bs * 1152 * 10, 在每个capsule(10)上有一组权值(1152),针对16维向量的加权
for r in range(self.n_iterations):
v = v.unsqueeze(1) # bs * 1 * 10 * 16
# u_predict:bs * 1152 * 10 * 16
b_batch = b_batch + (u_predict * v).sum(-1) # bs * 1152 * 10
# c = F.softmax(b_batch.view(-1, output_caps), dim=1).view(-1, input_caps, output_caps, 1)
# 改成下面这样好像并无影响
c = F.softmax(b_batch, dim=2).view(-1, input_caps, output_caps, 1)
# bs * 1152 * 10 * 1
s = (c * u_predict).sum(dim=1)
# bs * 10 * 16
v = squash(s)
return v
Agreement routing接受一个1152×10×16的输入,返回一个10×16的输出,这个过程其实就是论文上一模一样的算法

用每个向量与加权结果的点积更新加权系数,反复多次(这里设定为3次),就得到最后的结果10个16维向量
digit capsule如何连接输出
回忆10个向量是规范化的,因此每个向量的模长不大于1,所以它们的模长就解释为是某类的概率,从10个向量中选择模长最大的,作为预测结果(0~9)
损失函数
损失函数定义为margin loss
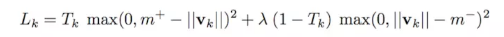
Reconstruction
为了让10个16维向量更好地捕捉图片的信息,在分类的同时,作者增加了额外的任务,使用这些向量重建原来的图片,重建方法就是,比如当前的label是1,那就用1所对应的那个16维向量通过MLP来重建28×28的MNIST图片,并且计算重建误差
运行结果
运行结果在MNIST上的没有重建是99.51%,有重建是99.58%
本周小结
上周任务完成情况
- 读完17ICCV 18年ECCV的image captioning论文 ×
- 整理近年来的SoTA image captioning model ×
- 整理先前阅读的论文 ~
- 整理论文的书写方法 ~
- 整理重要的引用文献 ~
- 研究策略梯度、CIDEr optimization和top-down model的细节 ×
- 完成基本模型的运行任务,比对其原论文详细分析结果 ×
本周主要在做学长安排的任务,别的事情暂未考虑
下周目标
在没有其他任务的情况下
- 读完17ICCV 18年ECCV的image captioning论文
- 整理近年来的SoTA image captioning model
- 整理先前阅读的论文
- 整理论文的书写方法
- 整理重要的引用文献
- 研究策略梯度、CIDEr optimization和top-down model的细节
- 完成基本模型的运行任务,比对其原论文详细分析结果
若有其他任务,目标更改至达到原目标的1/3完成度
最后
以上就是默默灰狼最近收集整理的关于第五十一周学习笔记第五十一周学习笔记的全部内容,更多相关第五十一周学习笔记第五十一周学习笔记内容请搜索靠谱客的其他文章。







![[经典论文分享]CommNet 多智能体通讯网络模型](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)
发表评论 取消回复