1:主要以前用一个向量来表示用户,但是用户往往兴趣是多样的,所以这里会用多个向量来表示用户的多个兴趣,这个重点是设计了一个提取用户多兴趣向量层,主要是基于胶囊路由机制的方法。
2:特点是把用户历史行为聚类与提取用户不同的兴趣点。
3:DIN可以识别用户多兴趣,但是不适合做召回,因为计算量太多,适合做排序阶段。
整体架构如下:
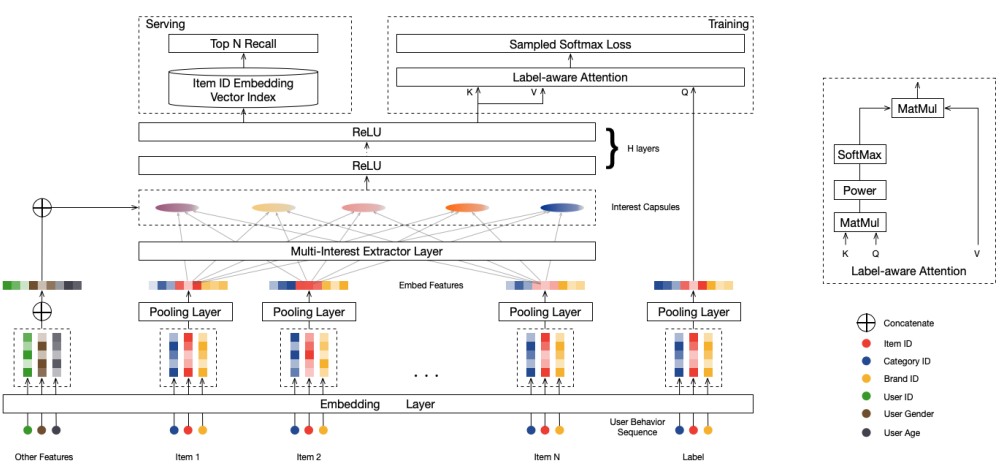
详细解释:
1:定义一个元组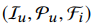 ,其中Iu是用户行为产生的一组商品,比如用户点击商品序列。 Pu是用户属性特征,比如年龄、男女等。Fi是目标商品的特征,比如目标商品的ID,品类ID等特征。
,其中Iu是用户行为产生的一组商品,比如用户点击商品序列。 Pu是用户属性特征,比如年龄、男女等。Fi是目标商品的特征,比如目标商品的ID,品类ID等特征。
表示用户:
我们的目标是什么?我们是想找到一个函数Fuser(),把用户点击的商品序列、用户的社会属性映射到一个用户向量,意思就是用用户的行为与用户的属性去表示用户。公式如下:
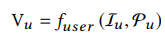 我们计算的Vu不是一个向量,这里有多个向量,因为我们这个主题就是基于多兴趣的召回。多个向量标示如下:
我们计算的Vu不是一个向量,这里有多个向量,因为我们这个主题就是基于多兴趣的召回。多个向量标示如下: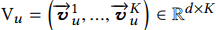 ,其中有K个向量,每个向量有d维。
,其中有K个向量,每个向量有d维。
表示目标商品:
目标商品i,我们知道它的特征Fi,那么我们可以用如下函数表示: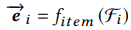 ,这个向量的范围:
,这个向量的范围: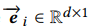 ,是一个向量,d维。
,是一个向量,d维。
商品召回:
我们已经知道了用户向量,目标商品向量,我们获取召回候选集,统计下面公式来计算用户与目标商品的相似度,来给用户与商品直接打分: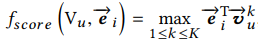 公式看,应该就是目标商品向量与用户向量计算点击,然后取最大的那个点击作为相似度分数。
公式看,应该就是目标商品向量与用户向量计算点击,然后取最大的那个点击作为相似度分数。
具体步骤:
一:embedding与池化层
我们从上图中,可以看到,用户也在大致分为3类,用户、行为、商品。每类里面都有很多id特征,这样的话,维度会非常高,这样需要大量的参数与计算。所以我们在开始需要针对他们做embedding,将高维向量压缩成低维稠密向量。
代表用户的向量 比如对于用户特征(性别,年龄等)特征,我们可以将他们对应的embedding后,在连接起来,就形成了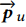 这个向量。
这个向量。
目标商品的embedding,首先我们用商品的ID,【品类id,品牌id,店铺id(等这些信息已经被证明在冷启动中非常有效)】,这些特征都是来自于Fi中的,我们将这些特征对应的embedding向量通过一个平均池化层形成目标商品的的embedding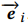 。
。
用户行为向量:用户的行为商品序列Iu,它里面有每个商品对应的embedding,把他们聚集起来形成用户行为embedding: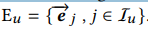
二:多兴趣提取层
1:为了学习到多个用户兴趣表示向量,我们利用聚类方式把用户历史行为分成好几个组。
2:多兴趣向量提取,采用的类似胶囊网络里面的动态路由方法。
3:这里的实现方式跟图片还不太一样,我们知道胶囊网络当时提出的主要应用在图像上,以前每个神经元用一个具体的数值表示,而胶囊网络的神经元是用一个向量去表示,当时为了举例子,每个胶囊网络的神经元里包含了很多信息,比如方向,长度以及具体图像中的位置啊等一堆信息,我们需要用个转化矩阵要进行转化,比如图像中的眼睛,鼻子在转化过程中,需要的转化矩阵不同,这个转化矩阵可以适应梯度下降方法学习到。这个就是我们胶囊网络种的第一步,通过转化矩阵进行向量变换: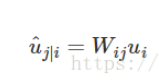 ,但是在这个paper里面,我们的商品embedding都是每个商品,这个每个商品都是一个行为胶囊,利用他们提取兴趣胶囊,商品不像图像,每个图像上的胶囊转化矩阵不同,但是商品的转化矩阵相同,他们可以共享同一个转化矩阵Wij,在论文中就是公式中的S,如下公式:
,但是在这个paper里面,我们的商品embedding都是每个商品,这个每个商品都是一个行为胶囊,利用他们提取兴趣胶囊,商品不像图像,每个图像上的胶囊转化矩阵不同,但是商品的转化矩阵相同,他们可以共享同一个转化矩阵Wij,在论文中就是公式中的S,如下公式: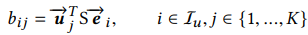 ,其中
,其中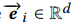 表示用户行为产生的商品的embedding。
表示用户行为产生的商品的embedding。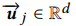 就是我们想获得的兴趣胶囊。bij就是我们动态路由里,用于计算低层胶囊到高层胶囊之间的动态权重。
就是我们想获得的兴趣胶囊。bij就是我们动态路由里,用于计算低层胶囊到高层胶囊之间的动态权重。
区别:
1:胶囊网络因为Wij不是共享的,所以初始化bij的时候可以初始化全是0,但是这个paper里,S(也就是Wij)是共享的,初始化如果全是0,那么他们得到的兴趣胶囊也是一样的,这样就陷入进去,没法计算了,所以我们用高斯分布去初始化bij。高斯分布: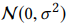
2:用户兴趣胶囊数量不是固定的,每个用户的兴趣不一样,所以兴趣胶囊数量也不一致。这样好处可以省计算,省空间。怎么确定用户兴趣数量,看下面公式: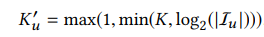 K是用户兴趣数。整个动态路由算法如下:
K是用户兴趣数。整个动态路由算法如下:
二: Label-aware 注意力层
1:由于用户兴趣很多,拥有很多兴趣胶囊,那具体使用那个兴趣胶囊呢?这里设计了 label-aware注意力层,基于点积的注意力机制,其实就是胶囊向量与目标商品向量点击,谁大用哪个兴趣胶囊。
2:对于目标商品,我们使用基于加权兴趣胶囊作为用户的向量表示。
3:每个兴趣胶囊的权重是由商品向量与胶囊向量点积决定的。
4:在这一层里,我们用目标商品向量做为Q,兴趣胶囊向量既是key也是value。我们输出用户u与相关的商品i向量计算公式如下:
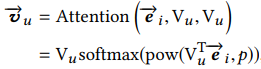 我们看到这里有个函数,pow,这是一个元素求幂的函数,就是每个向量与商品向量点积后求p次方,如果p趋近于0,那么所有兴趣胶囊的权重都一样,如果p大于1,p越大的话,那么点积越大,权重就越大。p越大的话,模型迭代收敛速度会更快。
我们看到这里有个函数,pow,这是一个元素求幂的函数,就是每个向量与商品向量点积后求p次方,如果p趋近于0,那么所有兴趣胶囊的权重都一样,如果p大于1,p越大的话,那么点积越大,权重就越大。p越大的话,模型迭代收敛速度会更快。
三:序列与预测
1:当用户向量与目标商品向量给出情况下,我们计算用户u对商品i的感兴趣概率,公式如下:Vu是用户向量,ei是目标商品向量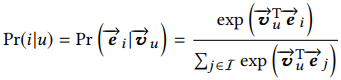 ,看分母,把用户兴趣向量与商品embedding做相似度,如果商品量很大,有几亿,这个计算是很大的,可以采用抽样的softmax方法。
,看分母,把用户兴趣向量与商品embedding做相似度,如果商品量很大,有几亿,这个计算是很大的,可以采用抽样的softmax方法。
那么MIND总体的目标函数是: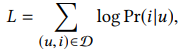 通过上面的训练,我们可以得到MIND模型,在这个模型里,我们把lable-aware层去了,我们通过输入用户的profile特征,用户浏览商品特征,通过网络可以输出用户的多个兴趣向量,然后我们通过用户兴趣向量计算与用户向量相似的TOPN商品作为推荐召回的候选集。当用户的行为发生改变了,用户点击商品序列变化,那么输入模型的入参就变了,会产生新的用户兴趣向量。所以这个模型可以做实时召回。
通过上面的训练,我们可以得到MIND模型,在这个模型里,我们把lable-aware层去了,我们通过输入用户的profile特征,用户浏览商品特征,通过网络可以输出用户的多个兴趣向量,然后我们通过用户兴趣向量计算与用户向量相似的TOPN商品作为推荐召回的候选集。当用户的行为发生改变了,用户点击商品序列变化,那么输入模型的入参就变了,会产生新的用户兴趣向量。所以这个模型可以做实时召回。
四:选取数据集技巧
1:像亚马逊的选取样本,选的商品都是要求有10条评论以上,选的用户呢?都是要再最近浏览超过10个商品的用户。天猫如何选取的呢?就是基于UV级别,过滤掉低于600次点击的商品(这里是到UV级别)。训练集与验证集比例19:1
2:这里的大致思路是,基于用户的浏览的商品,我们随机选择一个商品作为目标召回商品,这个商品之前的商品就作为行为商品。我们需要考虑模型的召回性能,这里的召回性能就是召回率:定义如下: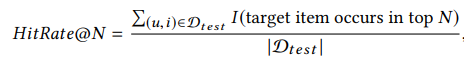 其中
其中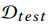 是测试集中,用户与目标商品组成的(u,i)对的数量,分子是我们召回的TOPN中有多少个是属于这个集合的数量。这里对比了其他几种算法:WALS youTUbe DNN MaxMF (这个方法应该相对还是不错的,他是基于MF的,将MF的线性能力扩展到非线性能力上,可以刻画用户多个兴趣向量)
是测试集中,用户与目标商品组成的(u,i)对的数量,分子是我们召回的TOPN中有多少个是属于这个集合的数量。这里对比了其他几种算法:WALS youTUbe DNN MaxMF (这个方法应该相对还是不错的,他是基于MF的,将MF的线性能力扩展到非线性能力上,可以刻画用户多个兴趣向量)
五:调参
1:我们知道,bij刚开始我们可以都初始化为0,不过这里我们采用高斯分布去初始化的: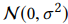 ,这里主要实验了不同的 σ,会导致不同的收敛速度。
,这里主要实验了不同的 σ,会导致不同的收敛速度。
2:天猫这里选择的是 σ=1,收敛速度更好,更稳健。
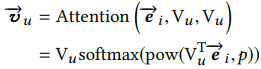 参数p,我们知道P是控制组合的兴趣表示
参数p,我们知道P是控制组合的兴趣表示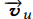 中,来自下层Vu多兴趣向量的比例。结果表示,P非常大的时候,模型的收敛速度会更好,性能更优。这个也说明了,与目标商品更匹配的那个兴趣比加权组合后的
中,来自下层Vu多兴趣向量的比例。结果表示,P非常大的时候,模型的收敛速度会更好,性能更优。这个也说明了,与目标商品更匹配的那个兴趣比加权组合后的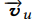 是要好的。
是要好的。
对比各种方法,其实DNN不一定比based-CF好,因为based-CF长期优化过。天猫的多兴趣向量是5-7个,说明天猫用户兴趣平均在5-7个。这个我们可以使用到苏宁易购里面,比如我们定义兴趣点,我们可以保持TOP5-7个。
总结:
这个算法增加兴趣数量并不能提升CTR。目前XX召回1000个候选集,再排序。按照天级别更新。
作者:李春生,搜索、推荐的兴趣爱好者,如有兴趣,大家可以一起交流,相互学习,一起助力中国AI的应用。
最后
以上就是端庄小懒虫最近收集整理的关于Multi-Interest Network with Dynamic Routing for Recommendation at Tmall-MIND多兴趣动态路由推荐的全部内容,更多相关Multi-Interest内容请搜索靠谱客的其他文章。








发表评论 取消回复