目录
一、背景
1.1、insert ignore
1.2、replace
1.3、查询除j,k外其他字段重复的语句
二、解决方案
一、背景
该部分进行了问题复盘和思路过程整理,如果想直接看解决思路,可选择目录,跳过背景部分。
1.1、insert ignore
先说业务场景,公司的某个业务是通过生成Excel然后读取Excel插入到数据库实现的,但是由于各种原因,Excel有些小问题,可能会手动修改一些字段,我必须把这部分数据也读进来。举个例子:

以上数据除了JK,其他都不会手动修改,我插入数据的方式就是定时读取Excel表,然后使用insert ignore into方式插入,把A-K全部设置了索引(因为数据高度相似,不得不这么做),这样当发现一样的数据时,就会忽略不插入。
读取代码如下(python3):
import openpyxl
import mysql.connector
def read_excel(file_name):
# 打开excel文件,获取工作簿对象
wb1 = openpyxl.load_workbook(file_name)
# 从工作薄中获取表单(sheet)对象
sheets = wb1.sheetnames
print('该Excel文件包含工作表如下:', sheets, type(sheets))
sheet1 = wb1.active
return sheet1
# 将Excel数据转化为元组列表
def excel_to_tuple_list(sheet1):
sheet1_max_row = sheet1.max_row
sheet1_max_column = sheet1.max_column
print("最大行:{}".format(sheet1_max_row))
print("最大列:{}".format(sheet1_max_column))
# 定义一个元组列表,用来存放Excel数据
# 一行就是一个元组,100行row就是100个元组,第一行不读,故-1
tuple_list_excel_data = [0 for i2 in range(sheet1_max_row - 1)]
# 首行表头忽略,从第二行开始读
for i1 in range(2, sheet1_max_row + 1):
# 将每行第一个数据放入元组
tuple1 = (sheet1.cell(i1, 1).value,)
# 从每行第二个数开始
for j1 in range(2, sheet1_max_column + 1):
# 之后每次添加一个元素,直到该行结束
tuple2 = (sheet1.cell(i1, j1).value,)
tuple1 = tuple1 + tuple2
# 处理完毕后将该元组放入列表,列表从0开始
tuple_list_excel_data[i1 - 2] = tuple1
# 检查列表数据是否完善
for tuple3 in tuple_list_excel_data:
print(tuple3)
return tuple_list_excel_data
def send_mysql(tuple_list):
# 连接到MySQL
db1 = mysql.connector.connect(
host="localhost",
user="root",
passwd="xxxxxx",
database='aaa_bbb_123'
)
cursor1 = db1.cursor()
cursor1.execute("SHOW TABLES")
for x in cursor1:
print('将插入MySQL表:', x)
sql = ("INSERT ignore INTO abcd (a,b,c,d,e,f,g,h,i,j,k) " +
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
val = tuple_list
cursor1.executemany(sql, val)
db1.commit() # 数据表内容有更新,必须使用到该语句
print(cursor1.rowcount, "记录插入成功。n")
send_mysql(excel_to_tuple_list(read_excel("./新建Excel.xlsx")))
(定时读取部分忽略,不是重点)
设置的索引如下:
alter table aaa_bbb_123.abcd add unique index abcd1(a,b,c,d,e,f,g,h,i,j,k);
插入效果如下:

数据都读到了,看起来不错。
1.2、replace
就这样运行一段时间以后,业务跟我说,手动修改的内容,数据库会多一条修改的数据,
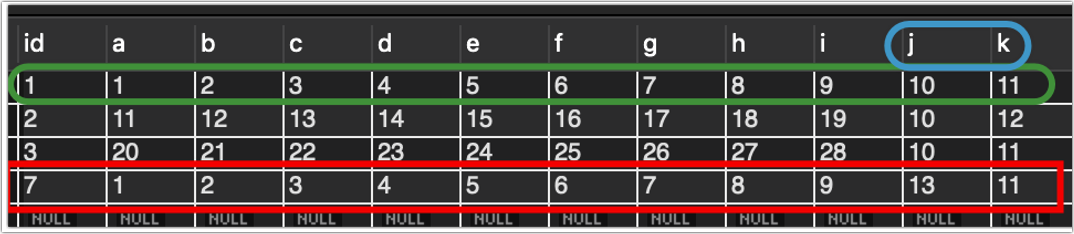
红色的数据,除了j为13,其他的和绿色的一模一样,业务说因为j和k是会手动修改的,但是明明Excel表已经没有j=10这条数了,数据库里却还有。

细心的你一定发现,id断层了,但是粗心的我此时还没有发现,对业务的问题,我略做思考,决定这么解决:
使用replace代替insert ignore,然后把索引设置为A-I,也就是说,我不管你JK的内容是什么,只要A-I是一样的,我就认为是同一条数据,然后直接replace替换掉。
这样做改动比较少,上面的代码不需要动,只需要改一个地方即可,也就是:
将函数send_mysql中的
sql = ("INSERT ignore INTO abcd (a,b,c,d,e,f,g,h,i,j,k) " +
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
改为
sql = ("replace INTO abcd (a,b,c,d,e,f,g,h,i,j,k) " +
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
是的,你没有看错,只是将insert ignore改成了replace,代码部分的修改就已经完成。接下来就是索引部分的修改,由于我不知道怎么删除已有索引中的部分字段,所以做法是直接删除原索引,并增加新索引:
删除原索引
DROP INDEX abcd1 ON aaa_bbb_123.abcd;
增加新索引
alter table aaa_bbb_123.abcd add unique index abcd2(a,b,c,d,e,f,g,h,i);
注意增加新索引时,MySQL提示我有重复数据,原因是之前插入的那两条数据在索引部分是完全相同的,这时需要删除重复数据,为了简便,我直接把整张表包括id全部清空(我只是测试,正式环境千万别这么做)
truncate table aaa_bbb_123.abcd;
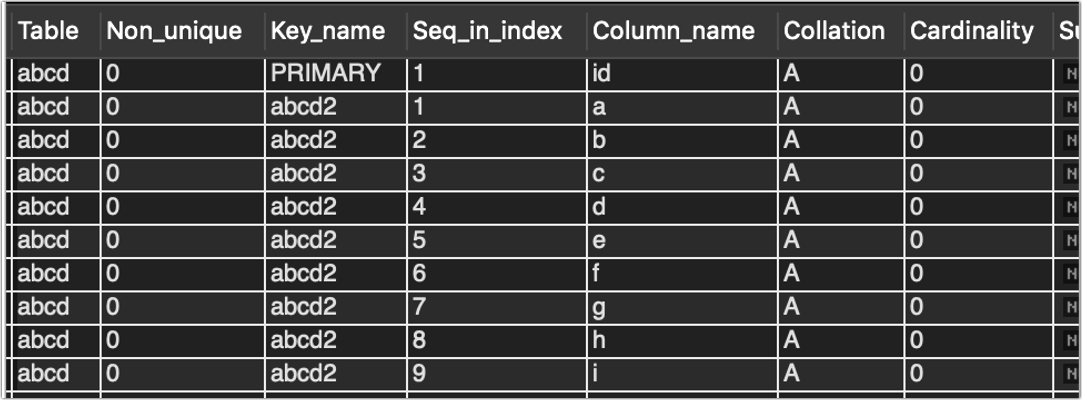
然后再执行添加索引操作即可成功,显示abcd表的索引如下
show index from aaa_bbb_123.abcd;
OK,都已经做完,来执行程序吧。
为了检验效果,我先把这张表读进去

然后把13改成14,再读一次

看看效果:

似乎不错,13那条数据不见了,取而代之的是14那条数据,效果也实现了,一切看起来都挺正常,但是角落那个奇怪的id,为什么会是4,5,6呢?
因为id不会影响业务,我也就没去管它,直到几个月后,业务跟我说,id已经增长到了2000w。。。
我查询了一下整个库的数据量,总共才40w条数据,id怎么会增长那么多?
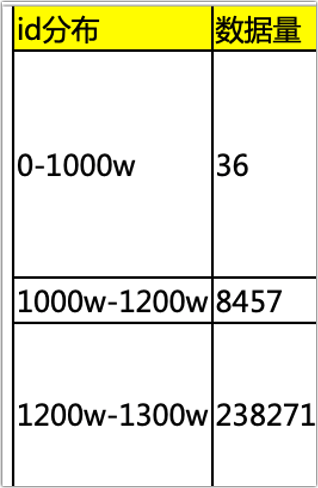
然后我统计了一下各个id段数据的分布情况,结果如下:
查询的语句:
select count(*) from xxx.xxx where id<10000000;
select count(*) from xxx.xxx where id>10000000 and id<12000000;
也就是说,0-1000w的id里面,只有36条数据,中间大部分都是空的,为什么呢?
因为replace的机制,当发现a-i字段完全相同的数据,它就删除原数据,然后在新的id下放这条数据,也就是说,每读取一次表格,都会增加几十甚至上百的id,加上前期测试,不断的全部读取,几百张表,也就是每一轮都会增加20w个id,读个几轮下来,轻轻松松上千万。
跟领导沟通了这个事情以后,觉得这么做,就是我还是用insert ignore,然后索引改回A-K,也就是全部索引,然后增加一个字段,filter_data,字段类型:tinyint(1) 默认值:0,当我插入数据的时候,无论有无修改,都添加进去,然后做一次select,当发现A-I字段内容完全相同的数据,我就把旧数据改成filter_data=1,这样业务查询的时候只查filter_data=0的数据即可,这样做还有一个好处,那就是当业务想看修改前的数据时,也可以看,不会丢失原始信息。
1.3、查询除j,k外其他字段重复的语句
在做这一步之前,需要把索引加回来,也就是j,k字段也要加入索引,否则不会有重复的数据。
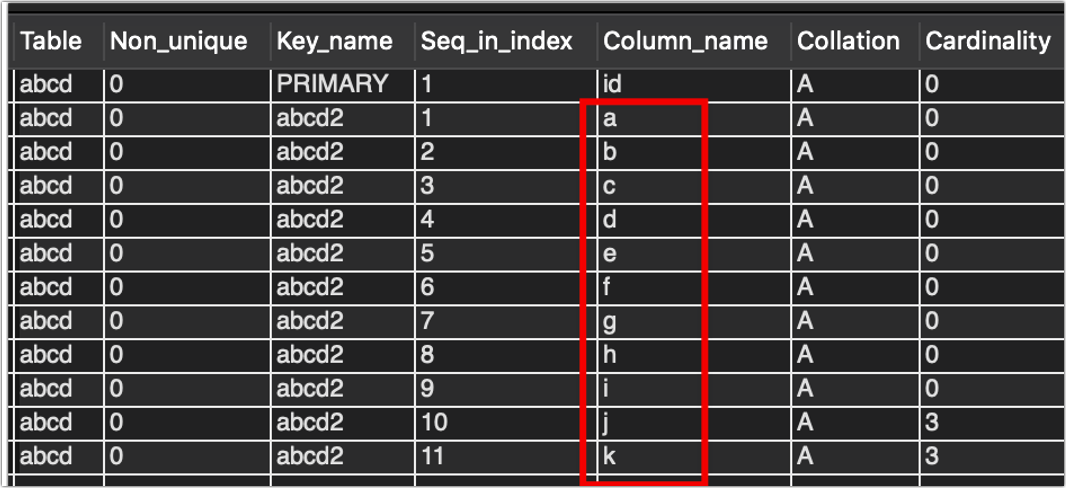
再把程序改回insert ignore,运行后结果如下:


好,现在数据库里有两条除了j以外完全相同的数据了,那就是id为4和id为7的两条数据,现在我要通过指令的方式找出它们:
select * from aaa_bbb_123.abcd where (a,b,c,d,e,f,g,h,i) in (
select a,b,c,d,e,f,g,h,i from aaa_bbb_123.abcd
group by a,b,c,d,e,f,g,h,i having count(*) > 1)
order by a;
结果如下:

这个语句看起来非常复杂,我们可以一步一步解构它,首先执行中间那个select,看看会发生什么
select a,b,c,d,e,f,g,h,i from aaa_bbb_123.abcd
group by a,b,c,d,e,f,g,h,i having count(*) > 1;
结果如下:

这个可能看的不是很清楚,我们增加一点数据

此时数据库有a为1和a为11的重复数据共4条,各2条。
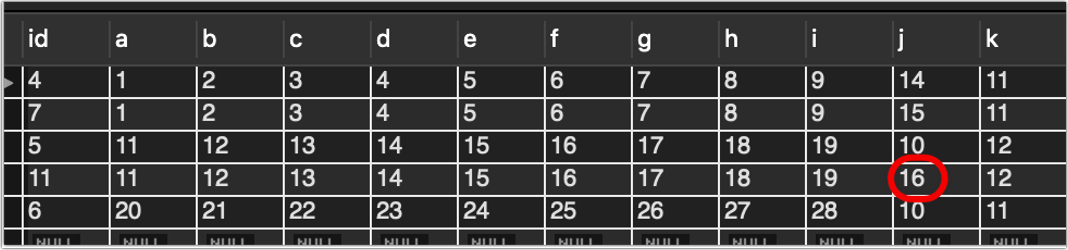
再次执行刚刚的语句:

看到了吗,刚刚的语句,是找出a-i中的完全相同的数据,前半句select a,b,c,d,e,f,g,h,i from aaa_bbb_123.abcd;就是普通的查询数据
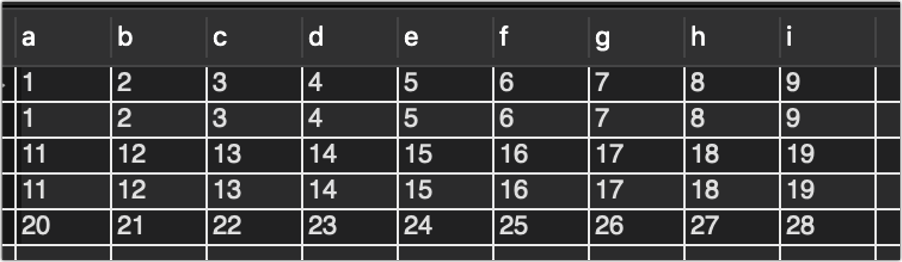
后半句group by a,b,c,d,e,f,g,h,i having count(*) > 1;意思是把数据按照a-i进行分组合并,并展示分组数大于1的数据。
理解了前半句,后半句就好理解了,
select * from aaa_bbb_123.abcd
where (a,b,c,d,e,f,g,h,i) in (分组结果) order by a;
查询数据,筛选条件就是上面的分组结果。

找到了查询语句,现在开始设计程序,思路很简单,首先通过上面的语句查询重复数据,会返回一个元祖列表,里面包含了上面的四行数据,然后我处理每一行的数据,通过这一行找到其他行,按照id排序,将除了最后一个id以外的其他数据的filter_data全部设置为1。
对了,别忘了先增加字段:
alter table aaa_bbb_123.abcd
add filter_data tinyint(1) NOT NULL DEFAULT 0 comment '筛选数据';

程序如下:
import mysql.connector
db1 = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="aaa_bbb_123"
)
cursor1 = db1.cursor()
def find_duplicate_all(date1):
# 查询除j,k外其他字段重复的语句
duplicate_data_field = 'a,b,c,d,e,f,g,h,i'
sql = ('select * from abcd where (' + duplicate_data_field
+ ') in (select ' + duplicate_data_field
+ ' from abcd group by ' + duplicate_data_field
+ ' having count(*) > 1) and a="' + date1
+ '";')
print('sql=', sql)
cursor1.execute(sql)
return cursor1.fetchall()
def change_filter_data(data, i):
# 修改单条标记
# 这里必须把条件写全了,因为有部分数据除了a外完全一致,
# 而a不是修改字段,所以实际上它们是两条数据
sql1 = ('select * from abcd where ' +
'a = "' + str(data[i][1]) + '" and ' +
'b = "' + str(data[i][2]) + '" and ' +
'c = "' + str(data[i][3]) + '" and ' +
'd = "' + str(data[i][4]) + '" and ' +
'e = "' + str(data[i][5]) + '" and ' +
'f = "' + str(data[i][6]) + '" and ' +
'g = "' + str(data[i][7]) + '" and ' +
'h = "' + str(data[i][8]) + '" and ' +
'i = "' + str(data[i][9]) + '"order by id;')
# print('sql1=', sql1, 'n')
cursor1.execute(sql1)
data1 = cursor1.fetchall()
for i in range(len(data1)):
print(i, '与上面相同的数据:', data1[i])
# 由于按id排序,可以逐个改filter_data,最后一个id不管
if i != len(data1) - 1:
# filter_data改为1
sql2 = "update abcd set filter_data=1 where id=" + str(data1[i][0]) + ";"
print('不是最后一个id,修改filter_data:', sql2)
cursor1.execute(sql2)
db1.commit()
else:
print('是最后一个id,不修改filter_data')
print('n')
def change_filter_data_all(date1):
# 修改全部标记
data = find_duplicate_all(date1)
# 这是一个元祖列表
for i in range(len(data)):
print('n', i, '**存在重复的数据:', data[i], 'n')
# 通过这一条找出与这条数据相同的,修改单条标记
change_filter_data(data, i)
change_filter_data_all('1')
执行结果如下:
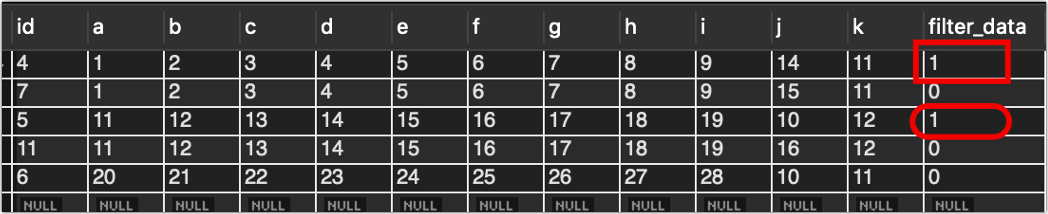
可以看到id较低的数据重复数据,筛选字段已经被改为1。
你可能看到我上面加了一个筛选条件a=1,因为在实际业务中a是日期,所以每次调用change_filter_data_all方法时只需要指定要查询和修改的日期即可,不用全表查询,没必要,一旦Excel表被修改,我就读修改的那个日期。
我本以为这样可以万无一失,但是经过我这样一顿操作以后,我发现,即使我不做任何修改,多运行几次insert ignore,然后一旦有新的数据进来,id还是会莫名的增长!!
比如我现在id最大是11,Excel表不做修改,运行几次那个插入的程序,然后改一个数据,再运行一次。结果如下:

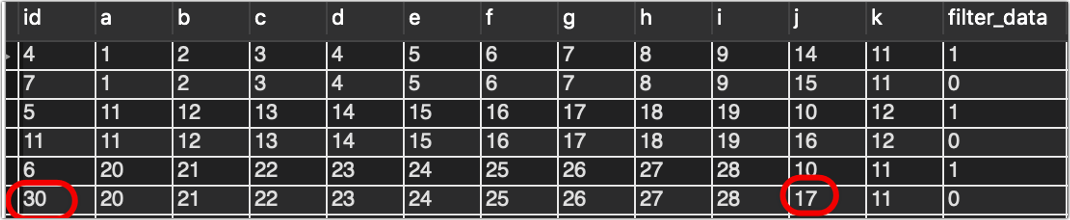
id还是增长到了30,这就非常离谱,说明上面的努力全都白费了,insert ignore也会增加id,只不过机制不是替换,而是忽略,并在id上自动增加一个数。
二、解决方案
在前面的部分中,我介绍了业务场景和探索过程,主要是:
Excel表部分字段会被手动修改,比如a-k中,j和k会被修改,而我必须把手动修改的值也读到,一开始我使用replace+非修改字段索引的方式插入,结果会导致id异常,然后我新增了一个filter_data字段用于筛选旧数据,使用insert ignore+全字段索引,旧数据filter_data=1 ,正常数据filter_data=0,结果发现insert ignore也会导致id异常增长,现在我必须找到一个方法,能保留所有数据,同时不能导致id异常增长。
经过各种查询,找到了一个看起来比较低效却很实用的方法:
每次插入数据之前,查询一遍该数据是否存在,考虑到还要识别和保留旧数据,所以要加两层筛选,第一遍匹配非修改字段,就是上面的a-i,如果这部分也没有,说明是新数据,直接insert即可。
如果有a-i,继续查询所有字段匹配,就是a-k,如果没有,说明该条数据被修改过(因为a-i是相同的,所以j,k不同),那么在插入之前把符合该数据的filter_data=1 ,再插入新的数据。
如果a-k有,说明是完全一致的数据,直接忽略,不做任何操作。
代码如下:
import openpyxl
import mysql.connector
def read_excel(file_name):
# 打开excel文件,获取工作簿对象
wb1 = openpyxl.load_workbook(file_name)
# 从工作薄中获取表单(sheet)对象
sheets = wb1.sheetnames
print('该Excel文件包含工作表如下:', sheets, type(sheets))
sheet1 = wb1.active
return sheet1
# 将Excel数据转化为元组列表
def excel_to_tuple_list(sheet1):
sheet1_max_row = sheet1.max_row
sheet1_max_column = sheet1.max_column
print("最大行:{}".format(sheet1_max_row))
print("最大列:{}".format(sheet1_max_column))
# 定义一个元组列表,用来存放Excel数据
# 一行就是一个元组,100行row就是100个元组,第一行不读,故-1
tuple_list_excel_data = [0 for i2 in range(sheet1_max_row - 1)]
# 首行表头忽略,从第二行开始读
for i1 in range(2, sheet1_max_row + 1):
# 将每行第一个数据放入元组
tuple1 = (sheet1.cell(i1, 1).value,)
# 从每行第二个数开始
for j1 in range(2, sheet1_max_column + 1):
# 之后每次添加一个元素,直到该行结束
tuple2 = (sheet1.cell(i1, j1).value,)
tuple1 = tuple1 + tuple2
# 处理完毕后将该元组放入列表,列表从0开始
tuple_list_excel_data[i1 - 2] = tuple1
# 检查列表数据是否完善
for tuple3 in tuple_list_excel_data:
print(tuple3)
return tuple_list_excel_data
def send_mysql(tuple_list):
# 连接到MySQL
db1 = mysql.connector.connect(
host="localhost",
user="root",
passwd="xxxxxx",
database='aaa_bbb_123'
)
cursor1 = db1.cursor()
cursor1.execute("SHOW TABLES")
for x in cursor1:
print('将插入MySQL表:', x)
sql = ("insert INTO abcd (a,b,c,d,e,f,g,h,i,j,k) " +
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
for one_row in tuple_list:
a(sql, one_row, cursor1)
db1.commit() # 数据表内容有更新,必须使用到该语句
print(cursor1.rowcount, "记录插入成功。n")
def a(sql, one_row, cursor1):
select_count = "SELECT count(1) FROM abcd "
# 9个非修改字段
product_9 = ("a = '" + str(one_row[0])
+ "' and b = '" + str(one_row[1])
+ "' and c= '" + str(one_row[2])
+ "' and d='" + str(one_row[3])
+ "' and e='" + str(one_row[4])
+ "' and f='" + str(one_row[5])
+ "' and g='" + str(one_row[6])
+ "' and h='" + str(one_row[7])
+ "' and i='" + str(one_row[8])
+ "'")
# 注意,变量前后需要加引号
sql2 = (select_count + "WHERE " + product_9)
cursor1.execute(sql2)
i = cursor1.fetchall()[0][0]
if i == 0:
print('查询索引部分没有记录,说明是新数据,insert即可')
cursor1.execute(sql, one_row)
else:
# 索引部分有记录,再检查加上修改字段是否有记录
sql3 = (select_count + "WHERE "
+ "j='" + str(one_row[9])
+ "' and k='" + str(one_row[10])
+ "' and " + product_9)
cursor1.execute(sql3)
i = cursor1.fetchall()[0][0]
if i == 0:
print('索引部分有记录,加上修改字段没有记录,说明修改过,insert前修改旧filter_data')
sql4 = ("UPDATE abcd SET "
+ "filter_data = 1" + " WHERE " + product_9)
cursor1.execute(sql4)
cursor1.execute(sql, one_row)
else:
print('找到该记录10个字段完全相同,说明未修改,忽略即可')
send_mysql(excel_to_tuple_list(read_excel("./新建Excel.xlsx")))
执行结果:
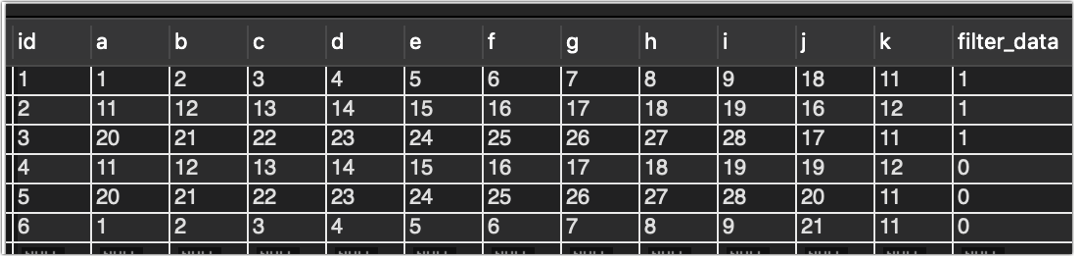
可以看到id是连续的了,无论执行多少次,无论怎么修改,id都只增长1个。
用a排序来讲一下,可以看到,旧数据全被打上了1,以后直接查filter_data =0的数据即可。

其实这样做,完全可以不要索引了,因为全靠我自己select去查是否有重复数据,而且如果你观察仔细,可以发现我把insert ignore改成了insert,因为插入时不可能有重复的数据,所以可以省略。
讲一下代码,前面的部分没什么特别的,主要是后面的函数a(),把每行的数据都查一遍,cursor1.fetchall()[0][0]返回的是匹配数据的条数,当条数为0时,说明不存在,就可以进行一系列的判断。
另一个部分就是send_mysql函数,我把批量插入的函数改成循环每行判断,这样做看起来效率会比较低但是经过我的测试,40w的数据,程序跑起来也是比较快的,基本上1秒1张Excel表没问题,加上我本来设计的每读完一张表就要延迟一下再读下一张,免得卡死电脑,所以这点影响基本不大。
由于技术有限,有错误或者更好的解决办法,欢迎指教!
最后
以上就是生动雪碧最近收集整理的关于【MySQL】新增数据时id不连续的解决思路的全部内容,更多相关【MySQL】新增数据时id不连续内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复