Tomcat的使用总结(二)
Pipeline和Valve
Valve
Valve作为一个个基础的阀门,扮演着业务实际执行者的角色。我们看看Valve这个接口有哪些方法。
public interface Valve {
// 获取下一个阀门
public Valve getNext();
// 设置下一个阀门
public void setNext(Valve valve);
// 后台执行逻辑,主要在类加载上下文中使用到
public void backgroundProcess();
// 执行业务逻辑
public void invoke(Request request, Response response)
throws IOException, ServletException;
// 是否异步执行
public boolean isAsyncSupported();
}
Contained
ValveBase、Pipeline及其他相关组件都实现了Contained接口,我们看看这个接口有哪些方法。很简单,就是get/set容器操作。
public interface Contained {
/**
* Get the {@link Container} with which this instance is associated.
*
* @return The Container with which this instance is associated or
* <code>null</code> if not associated with a Container
*/
Container getContainer();
/**
* Set the <code>Container</code> with which this instance is associated.
*
* @param container The Container instance with which this instance is to
* be associated, or <code>null</code> to disassociate this instance
* from any Container
*/
void setContainer(Container container);
}
ValveBase
从Valve的类层次结构,我们发现几乎所有Valve都继承了ValveBase这个抽象类,所以这儿我们需要分析一下它。
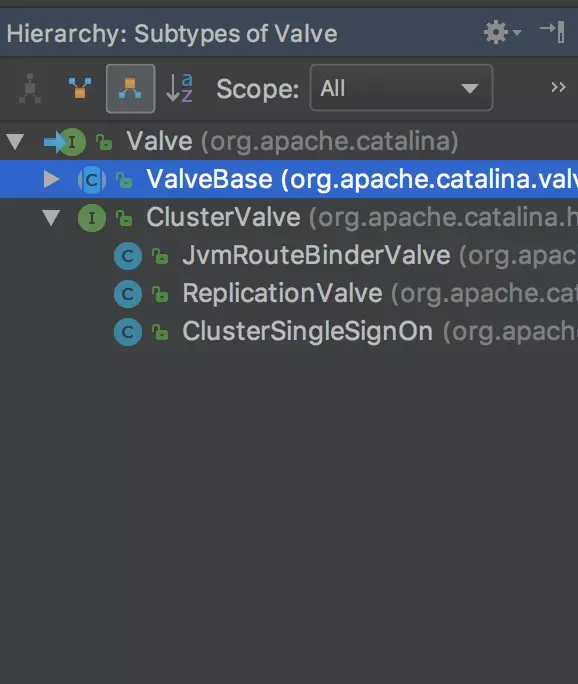
Valve类层次结构
public abstract class ValveBase extends LifecycleMBeanBase implements Contained, Valve {
// 国际化管理器,可以支持多国语言
protected static final StringManager sm = StringManager.getManager(ValveBase.class);
//------------------------------------------------------ Instance Variables
// 无参构造方法,默认不支持异步
public ValveBase() {
this(false);
}
// 有参构造方法,可传入异步支持标记
public ValveBase(boolean asyncSupported) {
this.asyncSupported = asyncSupported;
}
//------------------------------------------------------ Instance Variables
// 异步标记
protected boolean asyncSupported;
// 所属容器
protected Container container = null;
// 容器日志组件对象
protected Log containerLog = null;
// 下一个阀门
protected Valve next = null;
//-------------------------------------------------------------- Properties
// 获取所属容器
@Override
public Container getContainer() {
return container;
}
// 设置所属容器
@Override
public void setContainer(Container container) {
this.container = container;
}
// 是否异步执行
@Override
public boolean isAsyncSupported() {
return asyncSupported;
}
// 设置是否异步执行
public void setAsyncSupported(boolean asyncSupported) {
this.asyncSupported = asyncSupported;
}
// 获取下一个待执行的阀门
@Override
public Valve getNext() {
return next;
}
// 设置下一个待执行的阀门
@Override
public void setNext(Valve valve) {
this.next = valve;
}
//---------------------------------------------------------- Public Methods
// 后台执行,子类实现
@Override
public void backgroundProcess() {
// NOOP by default
}
// 初始化逻辑
@Override
protected void initInternal() throws LifecycleException {
super.initInternal();
// 设置容器日志组件对象到当前阀门的containerLog属性
containerLog = getContainer().getLogger();
}
// 启动逻辑
@Override
protected synchronized void startInternal() throws LifecycleException {
setState(LifecycleState.STARTING);
}
// 停止逻辑
@Override
protected synchronized void stopInternal() throws LifecycleException {
setState(LifecycleState.STOPPING);
}
// 重写toString,格式为[${containerName}]
@Override
public String toString() {
StringBuilder sb = new StringBuilder(this.getClass().getName());
sb.append('[');
if (container == null) {
sb.append("Container is null");
} else {
sb.append(container.getName());
}
sb.append(']');
return sb.toString();
}
// -------------------- JMX and Registration --------------------
// 设置获取MBean对象的keyProperties,格式如:a=b,c=d,e=f...
@Override
public String getObjectNameKeyProperties() {
StringBuilder name = new StringBuilder("type=Valve");
Container container = getContainer();
name.append(container.getMBeanKeyProperties());
int seq = 0;
// Pipeline may not be present in unit testing
Pipeline p = container.getPipeline();
if (p != null) {
for (Valve valve : p.getValves()) {
// Skip null valves
if (valve == null) {
continue;
}
// Only compare valves in pipeline until we find this valve
if (valve == this) {
break;
}
if (valve.getClass() == this.getClass()) {
// Duplicate valve earlier in pipeline
// increment sequence number
seq ++;
}
}
}
if (seq > 0) {
name.append(",seq=");
name.append(seq);
}
String className = this.getClass().getName();
int period = className.lastIndexOf('.');
if (period >= 0) {
className = className.substring(period + 1);
}
name.append(",name=");
name.append(className);
return name.toString();
}
// 获取所属域,从container获取
@Override
public String getDomainInternal() {
Container c = getContainer();
if (c == null) {
return null;
} else {
return c.getDomain();
}
}
}
Pipeline
Pipeline作为一个管道,我们可以简单认为是一个Valve的集合,内部会对这个集合进行遍历,调用每个元素的业务逻辑方法invoke()。
是不是这样呢?我们还是分析一下源码,先看看接口定义。
public interface Pipeline {
// ------------------------------------------------------------- Properties
// 获取基本阀门
public Valve getBasic();
// 设置基本阀门
public void setBasic(Valve valve);
// --------------------------------------------------------- Public Methods
// 添加阀门
public void addValve(Valve valve);
// 获取阀门数组
public Valve[] getValves();
// 删除阀门
public void removeValve(Valve valve);
// 获取首个阀门
public Valve getFirst();
// 管道内所有阀门是否异步执行
public boolean isAsyncSupported();
// 获取管道所属的容器
public Container getContainer();
// 设置管道所属的容器
public void setContainer(Container container);
// 查找非异步执行的所有阀门,并放置到result参数中,所以result不允许为null
public void findNonAsyncValves(Set<String> result);
}
StandardPipeline
接着我们分析一下Pipeline唯一的实现StandardPipeline。代码很长,但是都很简单。
public class StandardPipeline extends LifecycleBase
implements Pipeline, Contained {
private static final Log log = LogFactory.getLog(StandardPipeline.class);
// ----------------------------------------------------------- Constructors
// 构造一个没有所属容器的管道
public StandardPipeline() {
this(null);
}
// 构造一个有所属容器的管道
public StandardPipeline(Container container) {
super();
setContainer(container);
}
// ----------------------------------------------------- Instance Variables
/**
* 基本阀门,最后执行的阀门
*/
protected Valve basic = null;
/**
* 管道所属的容器
*/
protected Container container = null;
/**
* 管道里面的首个执行的阀门
*/
protected Valve first = null;
// --------------------------------------------------------- Public Methods
// 是否异步执行,如果一个阀门都没有,或者所有阀门都是异步执行的,才返回true
@Override
public boolean isAsyncSupported() {
Valve valve = (first!=null)?first:basic;
boolean supported = true;
while (supported && valve!=null) {
supported = supported & valve.isAsyncSupported();
valve = valve.getNext();
}
return supported;
}
// 查找所有未异步执行的阀门
@Override
public void findNonAsyncValves(Set<String> result) {
Valve valve = (first!=null) ? first : basic;
while (valve != null) {
if (!valve.isAsyncSupported()) {
result.add(valve.getClass().getName());
}
valve = valve.getNext();
}
}
// ------------------------------------------------------ Contained Methods
// 获取所属容器
@Override
public Container getContainer() {
return (this.container);
}
// 设置所属容器
@Override
public void setContainer(Container container) {
this.container = container;
}
// 初始化逻辑,默认没有任何逻辑
@Override
protected void initInternal() {
// NOOP
}
// 开始逻辑,调用所有阀门的start方法
@Override
protected synchronized void startInternal() throws LifecycleException {
// Start the Valves in our pipeline (including the basic), if any
Valve current = first;
if (current == null) {
current = basic;
}
while (current != null) {
if (current instanceof Lifecycle)
((Lifecycle) current).start();
current = current.getNext();
}
setState(LifecycleState.STARTING);
}
// 停止逻辑,调用所有阀门的stop方法
@Override
protected synchronized void stopInternal() throws LifecycleException {
setState(LifecycleState.STOPPING);
// Stop the Valves in our pipeline (including the basic), if any
Valve current = first;
if (current == null) {
current = basic;
}
while (current != null) {
if (current instanceof Lifecycle)
((Lifecycle) current).stop();
current = current.getNext();
}
}
// 销毁逻辑,移掉所有阀门,调用removeValve方法
@Override
protected void destroyInternal() {
Valve[] valves = getValves();
for (Valve valve : valves) {
removeValve(valve);
}
}
/**
* 重新toString方法
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder("Pipeline[");
sb.append(container);
sb.append(']');
return sb.toString();
}
// ------------------------------------------------------- Pipeline Methods
// 获取基础阀门
@Override
public Valve getBasic() {
return (this.basic);
}
// 设置基础阀门
@Override
public void setBasic(Valve valve) {
// Change components if necessary
Valve oldBasic = this.basic;
if (oldBasic == valve)
return;
// Stop the old component if necessary
// 老的基础阀门会被调用stop方法且所属容器置为null
if (oldBasic != null) {
if (getState().isAvailable() && (oldBasic instanceof Lifecycle)) {
try {
((Lifecycle) oldBasic).stop();
} catch (LifecycleException e) {
log.error("StandardPipeline.setBasic: stop", e);
}
}
if (oldBasic instanceof Contained) {
try {
((Contained) oldBasic).setContainer(null);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
}
}
}
// Start the new component if necessary
// 新的阀门会设置所属容器,并调用start方法
if (valve == null)
return;
if (valve instanceof Contained) {
((Contained) valve).setContainer(this.container);
}
if (getState().isAvailable() && valve instanceof Lifecycle) {
try {
((Lifecycle) valve).start();
} catch (LifecycleException e) {
log.error("StandardPipeline.setBasic: start", e);
return;
}
}
// Update the pipeline
// 替换pipeline中的基础阀门,就是讲基础阀门的前一个阀门的next指向当前阀门
Valve current = first;
while (current != null) {
if (current.getNext() == oldBasic) {
current.setNext(valve);
break;
}
current = current.getNext();
}
this.basic = valve;
}
// 添加阀门
@Override
public void addValve(Valve valve) {
// Validate that we can add this Valve
// 设置所属容器
if (valve instanceof Contained)
((Contained) valve).setContainer(this.container);
// Start the new component if necessary
// 调用阀门的start方法
if (getState().isAvailable()) {
if (valve instanceof Lifecycle) {
try {
((Lifecycle) valve).start();
} catch (LifecycleException e) {
log.error("StandardPipeline.addValve: start: ", e);
}
}
}
// Add this Valve to the set associated with this Pipeline
// 设置阀门,将阀门添加到基础阀门的前一个
if (first == null) {
first = valve;
valve.setNext(basic);
} else {
Valve current = first;
while (current != null) {
if (current.getNext() == basic) {
current.setNext(valve);
valve.setNext(basic);
break;
}
current = current.getNext();
}
}
container.fireContainerEvent(Container.ADD_VALVE_EVENT, valve);
}
// 获取阀门数组
@Override
public Valve[] getValves() {
ArrayList<Valve> valveList = new ArrayList<>();
Valve current = first;
if (current == null) {
current = basic;
}
while (current != null) {
valveList.add(current);
current = current.getNext();
}
return valveList.toArray(new Valve[0]);
}
// JMX方法,在此忽略
public ObjectName[] getValveObjectNames() {
ArrayList<ObjectName> valveList = new ArrayList<>();
Valve current = first;
if (current == null) {
current = basic;
}
while (current != null) {
if (current instanceof JmxEnabled) {
valveList.add(((JmxEnabled) current).getObjectName());
}
current = current.getNext();
}
return valveList.toArray(new ObjectName[0]);
}
// 移除阀门
@Override
public void removeValve(Valve valve) {
Valve current;
if(first == valve) {
// 如果待移出的阀门是首个阀门,则首个阀门的下一个阀门变成首个阀门
first = first.getNext();
current = null;
} else {
current = first;
}
// 遍历阀门集合,并进行移除
while (current != null) {
if (current.getNext() == valve) {
current.setNext(valve.getNext());
break;
}
current = current.getNext();
}
if (first == basic) first = null;
// 设置阀门所属容器为null
if (valve instanceof Contained)
((Contained) valve).setContainer(null);
// 调用待移除阀门的stop方法和destroy方法,并触发移除阀门事件
if (valve instanceof Lifecycle) {
// Stop this valve if necessary
if (getState().isAvailable()) {
try {
((Lifecycle) valve).stop();
} catch (LifecycleException e) {
log.error("StandardPipeline.removeValve: stop: ", e);
}
}
try {
((Lifecycle) valve).destroy();
} catch (LifecycleException e) {
log.error("StandardPipeline.removeValve: destroy: ", e);
}
}
container.fireContainerEvent(Container.REMOVE_VALVE_EVENT, valve);
}
// 获取首个阀门,如果阀门列表为null,返回基础阀门
@Override
public Valve getFirst() {
if (first != null) {
return first;
}
return basic;
}
}
总结
通过上面的代码分析,我们发现了几个关键的设计模式:
- 模板方法模式,父类定义框架,子类实现
- 责任链模式,就是这儿的管道/阀门的实现方式,每个阀门维护一个next属性指向下一个阀门
分析之初,我们还以为很复杂。分析之后,我们却发现,高级的东西并不一定复杂,反而简单易懂。或许这就是高级开发比中低级开发更理解软件开发的含义吧~
类加载机制
我们知道,Java默认的类加载机制是通过双亲委派模型来实现的。而Tomcat实现的方式又和双亲委派模型有所区别。原因在于一个Tomcat容器允许同时运行多个Web程序,每个Web程序依赖的类又必须是相互隔离的。因此,如果Tomcat使用双亲委派模式来加载类的话,将导致Web程序依赖的类变为共享的。
举个例子,假如我们有两个Web程序,一个依赖A库的1.0版本,另一个依赖A库的2.0版本,他们都使用了类xxx.xx.Clazz,其实现的逻辑因类库版本的不同而结构完全不同。那么这两个Web程序的其中一个必然因为加载的Clazz不是所使用的Clazz而出现问题!而这对于开发来说是非常致命的!
怎么解决呢?这将是这篇文章所要探讨的问题!
双亲委派模式
Java是一门面向对象的语言,而对象又必然依托于类。类要运行,必须首先被加载到内存。我们可以简单地把类分为几类:
- Java自带的核心类
- Java支持的可扩展类
- 我们自己编写的类
如果所有的类都使用一个类加载器来加载,会出现什么问题呢?
假如我们自己编写一个类java.util.Object,它的实现可能有一定的危险性或者隐藏的bug。而我们知道Java自带的核心类里面也有java.util.Object,如果JVM启动的时候先行加载的是我们自己编写的java.util.Object,那么就有可能出现安全问题!
所以,Sun(后被Oracle收购)采用了另外一种方式来保证最基本的、也是最核心的功能不会被破坏。你猜的没错,那就是双亲委派模式!
双亲委派模式对类加载器定义了层级,每个类加载器都有一个父类加载器。在一个类需要加载的时候,首先委派给父类加载器来加载,而父类加载器又委派给祖父类加载器来加载,以此类推。如果父类及上面的类加载器都加载不了,那么由当前类加载器来加载,并将被加载的类缓存起来。
我们画一个图来辅助我们理解!
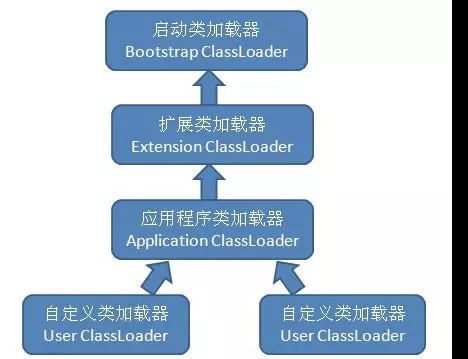
类加载模型
- Java自带的核心类 --
由启动类加载器加载 - Java支持的可扩展类 --
由扩展类加载器加载 - 我们自己编写的类 -- 默认
由应用程序类加载器或其子类加载
双亲委派模型解决了类错乱加载的问题,也设计得非常精妙。但它也不是万能的,在有些场景也会遇到它解决不了的问题。哪些场景呢?我们举一个例子来看看。
在Java核心类里面有SPI(Service Provider Interface),它由Sun编写规范,第三方来负责实现。SPI需要用到第三方实现类。如果使用双亲委派模型,那么第三方实现类也需要放在Java核心类里面才可以,不然的话第三方实现类将不能被加载使用。但是这显然是不合理的!怎么办呢?ContextClassLoader(上下文类加载器)就来解围了。
在java.lang.Thread里面有两个方法,get/set上下文类加载器
public void setContextClassLoader(ClassLoader cl)public ClassLoader getContextClassLoader()
我们可以通过在SPI类里面调用getContextClassLoader来获取第三方实现类的类加载器。由第三方实现类通过调用setContextClassLoader来传入自己实现的类加载器。这样就变相地解决了双亲委派模式遇到的问题。但是很显然,这种机制破坏了双亲委派模式。
Tomcat类加载机制
既然Tomcat的类加载机器不同于双亲委派模式,那么它又是一种怎样的模式呢?官网链接-ClassLoading有对此进行描述。
另外,我们还是先来看看Tomcat整体的类加载图是怎样的吧~
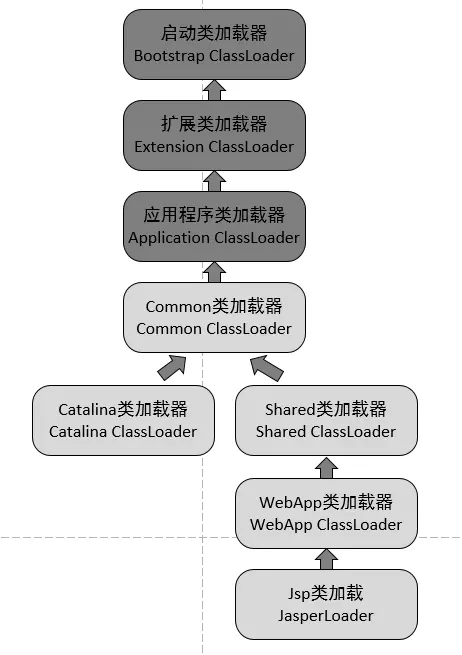
Tomcat类加载图
我们在这张图中看到很多类加载器,除了Jdk自带的类加载器,我们尤其关心Tomcat自身持有的类加载器。仔细一点我们很容易发现:Catalina类加载器和Shared类加载器,他们并不是父子关系,而是兄弟关系。为啥这样设计,我们得分析一下每个类加载器的用途,才能知晓。
我们在这张图中看到很多类加载器,除了Jdk自带的类加载器,我们尤其关心Tomcat自身持有的类加载器。仔细一点我们很容易发现:Catalina类加载器和Shared类加载器,他们并不是父子关系,而是兄弟关系。为啥这样设计,我们得分析一下每个类加载器的用途,才能知晓。
- Common类加载器,负责加载Tomcat和Web应用都复用的类
- Catalina类加载器,负责加载Tomcat专用的类,而这些被加载的类在Web应用中将不可见
- Shared类加载器,负责加载Tomcat下所有的Web应用程序都复用的类,而这些被加载的类在Tomcat中将不可见
- WebApp类加载器,负责加载具体的某个Web应用程序所使用到的类,而这些被加载的类在Tomcat和其他的Web应用程序都将不可见
- Jsp类加载器,每个jsp页面一个类加载器,不同的jsp页面有不同的类加载器,方便实现jsp页面的热插拔
CATALINA_HOME和CATALINA_BASE
在tomcat官网上有对他们进行描述,官网链接-CATALINA_HOME and CATALINA_BASE

官网说明
简单地说,CATALINA_HOME指的是安装目录,CATALINA_BASE指的是工作目录。在一台物理机上面,可以只有一个安装目录,但是允许有多个工作目录。
File的路径方法
java.io.File有3个方法可以获取路径,为了避免在阅读Tomcat源码的时候出现理解问题,这儿写出demo来说明其含义。
- getPath()
- getAbsolutePath()
- getCanonicalPath()
public class Main {
public static void main(String[] args) throws Exception {
System.out.println(System.getProperty("user.dir"));
System.out.println("-----默认相对路径:取得路径不同------");
File file1 = new File("../src/test1.txt");
System.out.println(file1.getPath());
System.out.println(file1.getAbsolutePath());
System.out.println(file1.getCanonicalPath());
System.out.println("-----默认相对路径:取得路径不同------");
File file = new File("./test1.txt");
System.out.println(file.getPath());
System.out.println(file.getAbsolutePath());
System.out.println(file.getCanonicalPath());
System.out.println("-----默认绝对路径:取得路径相同------");
File file2 = new File("/Users/pro/ws/learn/learn-javaagent/test1.txt");
System.out.println(file2.getPath());
System.out.println(file2.getAbsolutePath());
System.out.println(file2.getCanonicalPath());
}
}
输出结果如下:
-----默认相对路径:取得路径不同------
../src/test1.txt
/Users/pro/ws/learn/learn-javaagent/../src/test1.txt
/Users/pro/ws/learn/src/test1.txt
-----默认相对路径:取得路径不同------
./test1.txt
/Users/pro/ws/learn/learn-javaagent/./test1.txt
/Users/pro/ws/learn/learn-javaagent/test1.txt
-----默认绝对路径:取得路径相同------
/Users/pro/ws/learn/learn-javaagent/test1.txt
/Users/pro/ws/learn/learn-javaagent/test1.txt
/Users/pro/ws/learn/learn-javaagent/test1.txt
源码阅读
Tomcat启动的入口在Bootstrap的main()方法。main()方法执行前,必然先执行其static{}块。所以我们首先分析static{}块,然后分析main()方法
Bootstrap.static{}
static {
// 获取用户目录
// Will always be non-null
String userDir = System.getProperty("user.dir");
// 第一步,从环境变量中获取catalina.home,在没有获取到的时候将执行后面的获取操作
// Home first
String home = System.getProperty(Globals.CATALINA_HOME_PROP);
File homeFile = null;
if (home != null) {
File f = new File(home);
try {
homeFile = f.getCanonicalFile();
} catch (IOException ioe) {
homeFile = f.getAbsoluteFile();
}
}
// 第二步,在第一步没获取的时候,从bootstrap.jar所在目录的上一级目录获取
if (homeFile == null) {
// First fall-back. See if current directory is a bin directory
// in a normal Tomcat install
File bootstrapJar = new File(userDir, "bootstrap.jar");
if (bootstrapJar.exists()) {
File f = new File(userDir, "..");
try {
homeFile = f.getCanonicalFile();
} catch (IOException ioe) {
homeFile = f.getAbsoluteFile();
}
}
}
// 第三步,第二步中的bootstrap.jar可能不存在,这时我们直接把user.dir作为我们的home目录
if (homeFile == null) {
// Second fall-back. Use current directory
File f = new File(userDir);
try {
homeFile = f.getCanonicalFile();
} catch (IOException ioe) {
homeFile = f.getAbsoluteFile();
}
}
// 重新设置catalinaHome属性
catalinaHomeFile = homeFile;
System.setProperty(
Globals.CATALINA_HOME_PROP, catalinaHomeFile.getPath());
// 接下来获取CATALINA_BASE(从系统变量中获取),若不存在,则将CATALINA_BASE保持和CATALINA_HOME相同
// Then base
String base = System.getProperty(Globals.CATALINA_BASE_PROP);
if (base == null) {
catalinaBaseFile = catalinaHomeFile;
} else {
File baseFile = new File(base);
try {
baseFile = baseFile.getCanonicalFile();
} catch (IOException ioe) {
baseFile = baseFile.getAbsoluteFile();
}
catalinaBaseFile = baseFile;
}
// 重新设置catalinaBase属性
System.setProperty(
Globals.CATALINA_BASE_PROP, catalinaBaseFile.getPath());
}
我们把代码中的注释搬下来总结一下:
- 获取用户目录
- 第一步,从环境变量中获取catalina.home,在没有获取到的时候将执行后面的获取操作
- 第二步,在第一步没获取的时候,从bootstrap.jar所在目录的上一级目录获取
- 第三步,第二步中的bootstrap.jar可能不存在,这时我们直接把user.dir作为我们的home目录
- 重新设置catalinaHome属性
- 接下来获取CATALINA_BASE(从系统变量中获取),若不存在,则将CATALINA_BASE保持和CATALINA_HOME相同
- 重新设置catalinaBase属性
简单总结一下,就是加载并设置catalinaHome和catalinaBase相关的信息,以备后续使用。
main()
main方法大体分成两块,一块为init,另一块为load+start。
public static void main(String args[]) {
// 第一块,main方法第一次执行的时候,daemon肯定为null,所以直接new了一个Bootstrap对象,然后执行其init()方法
if (daemon == null) {
// Don't set daemon until init() has completed
Bootstrap bootstrap = new Bootstrap();
try {
bootstrap.init();
} catch (Throwable t) {
handleThrowable(t);
t.printStackTrace();
return;
}
// daemon守护对象设置为bootstrap
daemon = bootstrap;
} else {
// When running as a service the call to stop will be on a new
// thread so make sure the correct class loader is used to prevent
// a range of class not found exceptions.
Thread.currentThread().setContextClassLoader(daemon.catalinaLoader);
}
// 第二块,执行守护对象的load方法和start方法
try {
String command = "start";
if (args.length > 0) {
command = args[args.length - 1];
}
if (command.equals("startd")) {
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
} else if (command.equals("stopd")) {
args[args.length - 1] = "stop";
daemon.stop();
} else if (command.equals("start")) {
daemon.setAwait(true);
daemon.load(args);
daemon.start();
if (null == daemon.getServer()) {
System.exit(1);
}
} else if (command.equals("stop")) {
daemon.stopServer(args);
} else if (command.equals("configtest")) {
daemon.load(args);
if (null == daemon.getServer()) {
System.exit(1);
}
System.exit(0);
} else {
log.warn("Bootstrap: command "" + command + "" does not exist.");
}
} catch (Throwable t) {
// Unwrap the Exception for clearer error reporting
if (t instanceof InvocationTargetException &&
t.getCause() != null) {
t = t.getCause();
}
handleThrowable(t);
t.printStackTrace();
System.exit(1);
}
}
我们点到init()里面去看看~
public void init() throws Exception {
// 非常关键的地方,初始化类加载器s,后面我们会详细具体地分析这个方法
initClassLoaders();
// 设置上下文类加载器为catalinaLoader,这个类加载器负责加载Tomcat专用的类
Thread.currentThread().setContextClassLoader(catalinaLoader);
// 暂时略过,后面会讲
SecurityClassLoad.securityClassLoad(catalinaLoader);
// 使用catalinaLoader加载我们的Catalina类
// Load our startup class and call its process() method
if (log.isDebugEnabled())
log.debug("Loading startup class");
Class<?> startupClass = catalinaLoader.loadClass("org.apache.catalina.startup.Catalina");
Object startupInstance = startupClass.getConstructor().newInstance();
// 设置Catalina类的parentClassLoader属性为sharedLoader
// Set the shared extensions class loader
if (log.isDebugEnabled())
log.debug("Setting startup class properties");
String methodName = "setParentClassLoader";
Class<?> paramTypes[] = new Class[1];
paramTypes[0] = Class.forName("java.lang.ClassLoader");
Object paramValues[] = new Object[1];
paramValues[0] = sharedLoader;
Method method =
startupInstance.getClass().getMethod(methodName, paramTypes);
method.invoke(startupInstance, paramValues);
// catalina守护对象为刚才使用catalinaLoader加载类、并初始化出来的Catalina对象
catalinaDaemon = startupInstance;
}
关键的方法initClassLoaders,这个方法负责初始化Tomcat的类加载器。通过这个方法,我们很容易验证我们上一小节提到的Tomcat类加载图。
private void initClassLoaders() {
try {
// 创建commonLoader,如果未创建成果的话,则使用应用程序类加载器作为commonLoader
commonLoader = createClassLoader("common", null);
if( commonLoader == null ) {
// no config file, default to this loader - we might be in a 'single' env.
commonLoader=this.getClass().getClassLoader();
}
// 创建catalinaLoader,父类加载器为commonLoader
catalinaLoader = createClassLoader("server", commonLoader);
// 创建sharedLoader,父类加载器为commonLoader
sharedLoader = createClassLoader("shared", commonLoader);
} catch (Throwable t) {
// 如果创建的过程中出现异常了,日志记录完成之后直接系统退出
handleThrowable(t);
log.error("Class loader creation threw exception", t);
System.exit(1);
}
}
所有的类加载器的创建都使用到了方法createClassLoader,所以,我们进一步分析一下这个方法。createClassLoader用到了CatalinaProperties.getProperty("xxx")方法,这个方法用于从conf/catalina.properties文件获取属性值。
private ClassLoader createClassLoader(String name, ClassLoader parent)
throws Exception {
// 获取类加载器待加载的位置,如果为空,则不需要加载特定的位置,使用父类加载返回回去。
String value = CatalinaProperties.getProperty(name + ".loader");
if ((value == null) || (value.equals("")))
return parent;
// 替换属性变量,比如:${catalina.base}、${catalina.home}
value = replace(value);
List<Repository> repositories = new ArrayList<>();
// 解析属性路径变量为仓库路径数组
String[] repositoryPaths = getPaths(value);
// 对每个仓库路径进行repositories设置。我们可以把repositories看成一个个待加载的位置对象,可以是一个classes目录,一个jar文件目录等等
for (String repository : repositoryPaths) {
// Check for a JAR URL repository
try {
@SuppressWarnings("unused")
URL url = new URL(repository);
repositories.add(
new Repository(repository, RepositoryType.URL));
continue;
} catch (MalformedURLException e) {
// Ignore
}
// Local repository
if (repository.endsWith("*.jar")) {
repository = repository.substring
(0, repository.length() - "*.jar".length());
repositories.add(
new Repository(repository, RepositoryType.GLOB));
} else if (repository.endsWith(".jar")) {
repositories.add(
new Repository(repository, RepositoryType.JAR));
} else {
repositories.add(
new Repository(repository, RepositoryType.DIR));
}
}
// 使用类加载器工厂创建一个类加载器
return ClassLoaderFactory.createClassLoader(repositories, parent);
}
createClassLoader方法里面有几个关键的信息,一个为Repository,另一个为ClassLoaderFactory.createClassLoader。我们逐一来分析一下。
首先来看Repository,非常简单,就是一个POJO,里面有一个location表示位置,type表示类型。type的枚举有4种:目录、jar集合、jar和url路径。
public enum RepositoryType {
DIR,
GLOB,
JAR,
URL
}
public static class Repository {
private final String location;
private final RepositoryType type;
public Repository(String location, RepositoryType type) {
this.location = location;
this.type = type;
}
public String getLocation() {
return location;
}
public RepositoryType getType() {
return type;
}
}
其次,我们来分析一下ClassLoaderFactory.createClassLoader--类加载器工厂创建类加载器。这个方法可谓是非常的长!前方高能~
public static ClassLoader createClassLoader(List<Repository> repositories,
final ClassLoader parent)
throws Exception {
if (log.isDebugEnabled())
log.debug("Creating new class loader");
// Construct the "class path" for this class loader
Set<URL> set = new LinkedHashSet<>();
// 遍历repositories,对每个repository进行类型判断,并生成URL,每个URL我们都要校验其有效性,有效的URL我们会放到URL集合中
if (repositories != null) {
for (Repository repository : repositories) {
if (repository.getType() == RepositoryType.URL) {
URL url = buildClassLoaderUrl(repository.getLocation());
if (log.isDebugEnabled())
log.debug(" Including URL " + url);
set.add(url);
} else if (repository.getType() == RepositoryType.DIR) {
File directory = new File(repository.getLocation());
directory = directory.getCanonicalFile();
if (!validateFile(directory, RepositoryType.DIR)) {
continue;
}
URL url = buildClassLoaderUrl(directory);
if (log.isDebugEnabled())
log.debug(" Including directory " + url);
set.add(url);
} else if (repository.getType() == RepositoryType.JAR) {
File file=new File(repository.getLocation());
file = file.getCanonicalFile();
if (!validateFile(file, RepositoryType.JAR)) {
continue;
}
URL url = buildClassLoaderUrl(file);
if (log.isDebugEnabled())
log.debug(" Including jar file " + url);
set.add(url);
} else if (repository.getType() == RepositoryType.GLOB) {
File directory=new File(repository.getLocation());
directory = directory.getCanonicalFile();
if (!validateFile(directory, RepositoryType.GLOB)) {
continue;
}
if (log.isDebugEnabled())
log.debug(" Including directory glob "
+ directory.getAbsolutePath());
String filenames[] = directory.list();
if (filenames == null) {
continue;
}
for (int j = 0; j < filenames.length; j++) {
String filename = filenames[j].toLowerCase(Locale.ENGLISH);
if (!filename.endsWith(".jar"))
continue;
File file = new File(directory, filenames[j]);
file = file.getCanonicalFile();
if (!validateFile(file, RepositoryType.JAR)) {
continue;
}
if (log.isDebugEnabled())
log.debug(" Including glob jar file "
+ file.getAbsolutePath());
URL url = buildClassLoaderUrl(file);
set.add(url);
}
}
}
}
// Construct the class loader itself
final URL[] array = set.toArray(new URL[set.size()]);
if (log.isDebugEnabled())
for (int i = 0; i < array.length; i++) {
log.debug(" location " + i + " is " + array[i]);
}
// 从这儿看,最终所有的类加载器都是URLClassLoader的对象~~
return AccessController.doPrivileged(
new PrivilegedAction<URLClassLoader>() {
@Override
public URLClassLoader run() {
if (parent == null)
return new URLClassLoader(array);
else
return new URLClassLoader(array, parent);
}
});
}
类加载器工厂方法中有用到validateFile方法,这个方法是干嘛的呢?我们分析一下。
private static boolean validateFile(File file,
RepositoryType type) throws IOException {
// 对于目录类型或者jar集合目录类型,我们会校验是否为目录和是否可读
if (RepositoryType.DIR == type || RepositoryType.GLOB == type) {
if (!file.isDirectory() || !file.canRead()) {
String msg = "Problem with directory [" + file +
"], exists: [" + file.exists() +
"], isDirectory: [" + file.isDirectory() +
"], canRead: [" + file.canRead() + "]";
File home = new File (Bootstrap.getCatalinaHome());
home = home.getCanonicalFile();
File base = new File (Bootstrap.getCatalinaBase());
base = base.getCanonicalFile();
File defaultValue = new File(base, "lib");
// Existence of ${catalina.base}/lib directory is optional.
// Hide the warning if Tomcat runs with separate catalina.home
// and catalina.base and that directory is absent.
if (!home.getPath().equals(base.getPath())
&& file.getPath().equals(defaultValue.getPath())
&& !file.exists()) {
log.debug(msg);
} else {
log.warn(msg);
}
return false;
}
}
// 对于JAR,我们会校验文件是否可读
else if (RepositoryType.JAR == type) {
if (!file.canRead()) {
log.warn("Problem with JAR file [" + file +
"], exists: [" + file.exists() +
"], canRead: [" + file.canRead() + "]");
return false;
}
}
return true;
}
- 对于目录类型或者jar集合目录类型,我们会校验是否为目录和是否可读
- 对于JAR,我们会校验文件是否可读
我们已经对initClassLoaders分析完了,接下来分析SecurityClassLoad.securityClassLoad,我们看看里面做了什么事情
public static void securityClassLoad(ClassLoader loader) throws Exception {
securityClassLoad(loader, true);
}
static void securityClassLoad(ClassLoader loader, boolean requireSecurityManager) throws Exception {
if (requireSecurityManager && System.getSecurityManager() == null) {
return;
}
loadCorePackage(loader);
loadCoyotePackage(loader);
loadLoaderPackage(loader);
loadRealmPackage(loader);
loadServletsPackage(loader);
loadSessionPackage(loader);
loadUtilPackage(loader);
loadValvesPackage(loader);
loadJavaxPackage(loader);
loadConnectorPackage(loader);
loadTomcatPackage(loader);
}
private static final void loadCorePackage(ClassLoader loader) throws Exception {
final String basePackage = "org.apache.catalina.core.";
loader.loadClass(basePackage + "AccessLogAdapter");
loader.loadClass(basePackage + "ApplicationContextFacade$PrivilegedExecuteMethod");
loader.loadClass(basePackage + "ApplicationDispatcher$PrivilegedForward");
loader.loadClass(basePackage + "ApplicationDispatcher$PrivilegedInclude");
loader.loadClass(basePackage + "ApplicationPushBuilder");
loader.loadClass(basePackage + "AsyncContextImpl");
loader.loadClass(basePackage + "AsyncContextImpl$AsyncRunnable");
loader.loadClass(basePackage + "AsyncContextImpl$DebugException");
loader.loadClass(basePackage + "AsyncListenerWrapper");
loader.loadClass(basePackage + "ContainerBase$PrivilegedAddChild");
loadAnonymousInnerClasses(loader, basePackage + "DefaultInstanceManager");
loader.loadClass(basePackage + "DefaultInstanceManager$AnnotationCacheEntry");
loader.loadClass(basePackage + "DefaultInstanceManager$AnnotationCacheEntryType");
loader.loadClass(basePackage + "ApplicationHttpRequest$AttributeNamesEnumerator");
}
这儿其实就是使用catalinaLoader加载tomcat源代码里面的各个专用类。我们大致罗列一下待加载的类所在的package:
- org.apache.catalina.core.*
- org.apache.coyote.*
- org.apache.catalina.loader.*
- org.apache.catalina.realm.*
- org.apache.catalina.servlets.*
- org.apache.catalina.session.*
- org.apache.catalina.util.*
- org.apache.catalina.valves.*
- javax.servlet.http.Cookie
- org.apache.catalina.connector.*
- org.apache.tomcat.*
好了,至此我们已经分析完了init里面涉及到的几个关键方法,真不容易呀~
load()和start()
我们上面提到main()方法除了初始化方法init,还有load和start。下面我们逐一来分析他们。
private void load(String[] arguments)
throws Exception {
// Call the load() method
String methodName = "load";
Object param[];
Class<?> paramTypes[];
if (arguments==null || arguments.length==0) {
paramTypes = null;
param = null;
} else {
paramTypes = new Class[1];
paramTypes[0] = arguments.getClass();
param = new Object[1];
param[0] = arguments;
}
Method method =
catalinaDaemon.getClass().getMethod(methodName, paramTypes);
if (log.isDebugEnabled())
log.debug("Calling startup class " + method);
method.invoke(catalinaDaemon, param);
}
load()方法只是调用了Catalina的load()方法,只是会根据main方法传入的参数来判断是调用public void load()还是public void load(String args[])。
public void start() throws Exception {
if( catalinaDaemon==null ) init();
Method method = catalinaDaemon.getClass().getMethod("start", (Class [] )null);
method.invoke(catalinaDaemon, (Object [])null);
}
如果Catalina对象不为null,则调用其init()方法来初始化,初始化完成之后,调用Catalina对象的start方法。
WebApp类加载器
到这儿,我们隐隐感觉到少分析了点什么!没错,就是WebApp类加载器。整个启动过程分析下来,我们仍然没有看到这个类加载器。它又是在哪儿出现的呢?
我们知道WebApp类加载器是Web应用私有的,而每个Web应用其实算是一个Context,那么我们通过Context的实现类应该可以发现。在Tomcat中,Context的默认实现为StandardContext,我们看看这个类的startInternal()方法,在这儿我们发现了我们感兴趣的WebApp类加载器。
protected synchronized void startInternal() throws LifecycleException {
if (getLoader() == null) {
WebappLoader webappLoader = new WebappLoader(getParentClassLoader());
webappLoader.setDelegate(getDelegate());
setLoader(webappLoader);
}
}
入口代码非常简单,就是webappLoader不存在的时候创建一个,并调用setLoader方法。我们接着分析setLoader
public void setLoader(Loader loader) {
Lock writeLock = loaderLock.writeLock();
writeLock.lock();
Loader oldLoader = null;
try {
// Change components if necessary
oldLoader = this.loader;
if (oldLoader == loader)
return;
this.loader = loader;
// Stop the old component if necessary
if (getState().isAvailable() && (oldLoader != null) &&
(oldLoader instanceof Lifecycle)) {
try {
((Lifecycle) oldLoader).stop();
} catch (LifecycleException e) {
log.error("StandardContext.setLoader: stop: ", e);
}
}
// Start the new component if necessary
if (loader != null)
loader.setContext(this);
if (getState().isAvailable() && (loader != null) &&
(loader instanceof Lifecycle)) {
try {
((Lifecycle) loader).start();
} catch (LifecycleException e) {
log.error("StandardContext.setLoader: start: ", e);
}
}
} finally {
writeLock.unlock();
}
// Report this property change to interested listeners
support.firePropertyChange("loader", oldLoader, loader);
}
这儿,我们感兴趣的就两行代码:
((Lifecycle) oldLoader).stop(); // 旧的加载器停止((Lifecycle) loader).start(); // 新的加载器启动
总结
我们终于完整地分析完了Tomcat的整个启动过程+类加载过程。也了解并学习了Tomcat不同的类加载机制是为什么要这样设计,带来的附加作用又是怎样的。
从最后分析的load和start来看,第二入口在Catalina这个类,其对应的方法为load()和start()。后续分析源码,我们会从这两个方法入手。
除了Catalina之后,我们还要逐一分析巨多的tomcat组件,希望每个组件的分析都能带给我们不一样的阅读体验和设计方式~
Digester组件
Tomcat中的xml解析,是使用的apache开源组件digester。在tomcat源码中,Digester类所在位置为org.apache.tomcat.util.digester.Digester,它把开源组件digester的源代码拷贝了过来。
本文,我们主要是想了解一下digester的用法。以便在阅读tomcat源码的时候,看到xml解析相关代码的时候不会一脸茫然和懵逼。
digester有两种使用方式:
- 一种为tomat内嵌的
org.apache.tomcat.util.digester.Digester; - 另一种为
digester maven依赖。
本文采用第二种--maven依赖的方式。
digester实现原理
digester最初是作为struct的一个工具模块,来完成xml解析的功能。但是很快地,有人发现并觉得digester不应该仅仅局限在struct,而应该变得更通用。于是经过apache的孵化,最终加入到了apache commons类库家族中,并形成了一个xml另类解析的工具类库。
digester底层是基于SAX+事件驱动+栈的方式来搭建实现的。那么在digester中,这三种元素分别起到什么作用呢?
- SAX,用于解析xml
- 事件驱动,在SAX解析的过程中加入事件来支持我们的对象映射
- 栈,当解析xml元素的开始和结束的时候,需要通过xml元素映射的类对象的入栈和出栈来完成事件的调用
通过一些实实在在的场景和例子,我们发现一个元素的作用无非是在其解析前后加入一些扩展逻辑!例如:
- 开始解析某个节点的时候,是否需要创建一个类
- 开始解析某个节点的时候,是否需要入栈操作
- 结束解析某个节点的时候,是否需要执行某个方法
- 结束解析某个节点的时候,是否需要出栈操作
如何引入依赖包
以maven为例,使用下面的dependency。
<dependency>
<groupId>commons-digester</groupId>
<artifactId>commons-digester</artifactId>
<version>2.1</version>
</dependency>
如何使用
假如我们需要解析的xml为下面的格式。
<?xml version='1.0' encoding='utf-8'?>
<School name="Jen">
<Grade name="1">
<Class name="1" number="31"/>
<Class name="2" number="32"/>
</Grade>
<Grade name="2">
<Class name="1" number="41"/>
<Class name="2" number="42"/>
<Class name="3" number="37"/>
</Grade>
</School>
同时,我们假设下面的约定成立:
- 一个学校有名字属性,下面有多个年级
- 每个年级有名字属性,下面有多个班
- 每个班有名字和学生人数两个属性
根据上面的规则,我们需要创建关联的3个类,School、Grade和Class。
School有一个方法addGrade用于往学校对象中添加年级。
package com.juconcurrent.learn.apache.digester;
public class School {
private String name;
private Grade grades[] = new Grade[0];
private final Object servicesLock = new Object();
public void addGrade(Grade g) {
synchronized (servicesLock) {
Grade results[] = new Grade[grades.length + 1];
System.arraycopy(grades, 0, results, 0, grades.length);
results[grades.length] = g;
grades = results;
}
}
public Grade[] getGrades() {
return grades;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
同样的,年级有一个addClass方法,用于往Grade对象添加Class班对象。
package com.juconcurrent.learn.apache.digester;
public class Grade {
private String name;
private Class classes[] = new Class[0];
private final Object servicesLock = new Object();
public void addClass(Class c) {
synchronized (servicesLock) {
Class results[] = new Class[classes.length + 1];
System.arraycopy(classes, 0, results, 0, classes.length);
results[classes.length] = c;
classes = results;
}
}
public Class[] getClasses() {
return classes;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Class就比较简单了,只是一个简单的POJO对象。
package com.juconcurrent.learn.apache.digester;
public class Class {
private String name;
private int number;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
}
好了,我们已经定义好了我们所需要创建对象的类。那么如何使用digester来创建我们所需的数据呢?我们先给出例子,然后再来详细分析其中的关键方法。
package com.juconcurrent.learn.apache.digester;
import org.apache.commons.digester.Digester;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class DigesterTest {
// 属性和get/set方法,假设我们解析出来的School对象放在这儿
private School school;
public School getSchool() {
return school;
}
public void setSchool(School s) {
this.school = s;
}
private void digester() throws IOException, SAXException {
// 读取根据文件的路径,创建InputSource对象,digester解析的时候需要用到
File file = new File("/Users/pro/ws/learn/learn-javaagent/src/main/resources/School.xml");
InputStream inputStream = new FileInputStream(file);
InputSource inputSource = new InputSource(file.toURI().toURL().toString());
inputSource.setByteStream(inputStream);
// 创建Digester对象
Digester digester = new Digester();
// 是否需要用DTD验证XML文档的合法性
digester.setValidating(true);
// 将当前对象放到对象堆的最顶层,这也是这个类为什么要有school属性的原因!
digester.push(this);
/*
* 下面开始为Digester创建匹配规则
* Digester中的School、School/Grade、School/Grade/Class,分别对应School.xml的School、Grade、Class节点
*/
// 为School创建规则
/*
* Digester.addObjectCreate(String pattern, String className, String attributeName)
* pattern, 匹配的节点
* className, 该节点对应的默认实体类
* attributeName, 如果该节点有className属性, 用className的值替换默认实体类
*
* Digester匹配到School节点
*
* 1. 如果School节点没有className属性,将创建com.juconcurrent.learn.apache.digester.School对象;
* 2. 如果School节点有className属性,将创建指定的(className属性的值)对象
*/
digester.addObjectCreate("School", School.class.getName(), "className");
// 将指定节点的属性映射到对象,即将School节点的name的属性映射到School.java
digester.addSetProperties("School");
/*
* Digester.addSetNext(String pattern, String methodName, String paramType)
* pattern, 匹配的节点
* methodName, 调用父节点的方法
* paramType, 父节点的方法接收的参数类型
* Digester匹配到School节点,将调用DigesterTest(School的父节点)的setSchool方法,参数为School对象
*/
digester.addSetNext("School", "setSchool", School.class.getName());
// 为School/Grade创建规则
digester.addObjectCreate("School/Grade", Grade.class.getName(), "className");
digester.addSetProperties("School/Grade");
// Grade的父节点为School
digester.addSetNext("School/Grade", "addGrade", Grade.class.getName());
// 为School/Grade/Class创建规则
digester.addObjectCreate("School/Grade/Class", Class.class.getName(), "className");
digester.addSetProperties("School/Grade/Class");
digester.addSetNext("School/Grade/Class", "addClass", Class.class.getName());
// 解析输入源
digester.parse(inputSource);
}
// 只是将School对象进行控制台输出
private void print(School s) {
if (s != null) {
System.out.println(s.getName() + "有" + s.getGrades().length + "个年级");
for (int i = 0; i < s.getGrades().length; i++) {
if (s.getGrades()[i] != null) {
Grade g = s.getGrades()[i];
System.out.println(g.getName() + "年级 有 " + g.getClasses().length + "个班:");
for (int j = 0; j < g.getClasses().length; j++) {
if (g.getClasses()[j] != null) {
Class c = g.getClasses()[j];
System.out.println(c.getName() + "班有" + c.getNumber() + "人");
}
}
}
}
}
}
// 入口main()方法
public static void main(String[] args) throws IOException, SAXException {
DigesterTest digesterTest = new DigesterTest();
digesterTest.digester();
digesterTest.print(digesterTest.school);
}
}
这儿我们需要着重说明一下digester里面的几个方法,大体上我们可以将其方法分为两类:操作类和规则类。
- 操作类
- public void setValidating(boolean validating) //
是否根据DTD校验XML - public void push(Object object) //
将对象压入栈 - public Object peek() //
获取栈顶对象 - public Object pop() //
弹出栈顶对象 - public Object parse(InputSource input) //
解析输入源
- public void setValidating(boolean validating) //
- 规则类
- public void addObjectCreate(String pattern, String className, String attributeName) //
增加对象创建规则,当匹配到pattern模式时,如果指定了attributeName,则根据attributeName创建类对象;否则根据className创建类对象 - public void addSetProperties(String pattern) //
增加属性设置规则,当匹配到pattern模式时,就填充其属性 - public void addSetNext(String pattern, String methodName, String paramType) //
增加设置下一个规则,当匹配到pattern模式时,调用父节点的methodName方法,paramType为方法传入参数的类型 - public void addRule(String pattern, Rule rule) //
当匹配到pattern模式时,增加一个自定义规则 - public void addRuleSet(RuleSet ruleSet) //
增加规则集,一个规则集指的是对一个节点及下面的所有后续节点(子节点、子节点的子节点...)的解析
- public void addObjectCreate(String pattern, String className, String attributeName) //
Tomcat中的规则解析例子
上面我们写了一个非常简单的例子,相信通过这样的例子我们可以很快地入门了。那么tomcat里面又是怎样写的呢?我们看看org.apache.catalina.startup.Catalina.createStartDigester这个方法,这个方法用于定义对server.xml的解析。该方法比较长,但是我并不打算对这个方法进行阉割和压缩,而是原封不动地拷贝到这儿,以便大家对此有一个比较完整的认识。
protected Digester createStartDigester() {
long t1=System.currentTimeMillis();
// Initialize the digester
Digester digester = new Digester();
digester.setValidating(false);
digester.setRulesValidation(true);
// 这儿设置无效的属性,fake是赝品的意思,也就是在检查到这些属性直接认为是无效的
Map<Class<?>, List<String>> fakeAttributes = new HashMap<>();
List<String> objectAttrs = new ArrayList<>();
objectAttrs.add("className");
fakeAttributes.put(Object.class, objectAttrs);
// Ignore attribute added by Eclipse for its internal tracking
List<String> contextAttrs = new ArrayList<>();
contextAttrs.add("source");
fakeAttributes.put(StandardContext.class, contextAttrs);
digester.setFakeAttributes(fakeAttributes);
// 设置是否使用线程上下文类加载器
digester.setUseContextClassLoader(true);
// Configure the actions we will be using
digester.addObjectCreate("Server",
"org.apache.catalina.core.StandardServer",
"className");
digester.addSetProperties("Server");
digester.addSetNext("Server",
"setServer",
"org.apache.catalina.Server");
digester.addObjectCreate("Server/GlobalNamingResources",
"org.apache.catalina.deploy.NamingResourcesImpl");
digester.addSetProperties("Server/GlobalNamingResources");
digester.addSetNext("Server/GlobalNamingResources",
"setGlobalNamingResources",
"org.apache.catalina.deploy.NamingResourcesImpl");
digester.addObjectCreate("Server/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Listener");
digester.addSetNext("Server/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
digester.addObjectCreate("Server/Service",
"org.apache.catalina.core.StandardService",
"className");
digester.addSetProperties("Server/Service");
digester.addSetNext("Server/Service",
"addService",
"org.apache.catalina.Service");
digester.addObjectCreate("Server/Service/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Listener");
digester.addSetNext("Server/Service/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
//Executor
digester.addObjectCreate("Server/Service/Executor",
"org.apache.catalina.core.StandardThreadExecutor",
"className");
digester.addSetProperties("Server/Service/Executor");
digester.addSetNext("Server/Service/Executor",
"addExecutor",
"org.apache.catalina.Executor");
digester.addRule("Server/Service/Connector",
new ConnectorCreateRule());
digester.addRule("Server/Service/Connector",
new SetAllPropertiesRule(new String[]{"executor", "sslImplementationName"}));
digester.addSetNext("Server/Service/Connector",
"addConnector",
"org.apache.catalina.connector.Connector");
digester.addObjectCreate("Server/Service/Connector/SSLHostConfig",
"org.apache.tomcat.util.net.SSLHostConfig");
digester.addSetProperties("Server/Service/Connector/SSLHostConfig");
digester.addSetNext("Server/Service/Connector/SSLHostConfig",
"addSslHostConfig",
"org.apache.tomcat.util.net.SSLHostConfig");
digester.addRule("Server/Service/Connector/SSLHostConfig/Certificate",
new CertificateCreateRule());
digester.addRule("Server/Service/Connector/SSLHostConfig/Certificate",
new SetAllPropertiesRule(new String[]{"type"}));
digester.addSetNext("Server/Service/Connector/SSLHostConfig/Certificate",
"addCertificate",
"org.apache.tomcat.util.net.SSLHostConfigCertificate");
digester.addObjectCreate("Server/Service/Connector/SSLHostConfig/OpenSSLConf",
"org.apache.tomcat.util.net.openssl.OpenSSLConf");
digester.addSetProperties("Server/Service/Connector/SSLHostConfig/OpenSSLConf");
digester.addSetNext("Server/Service/Connector/SSLHostConfig/OpenSSLConf",
"setOpenSslConf",
"org.apache.tomcat.util.net.openssl.OpenSSLConf");
digester.addObjectCreate("Server/Service/Connector/SSLHostConfig/OpenSSLConf/OpenSSLConfCmd",
"org.apache.tomcat.util.net.openssl.OpenSSLConfCmd");
digester.addSetProperties("Server/Service/Connector/SSLHostConfig/OpenSSLConf/OpenSSLConfCmd");
digester.addSetNext("Server/Service/Connector/SSLHostConfig/OpenSSLConf/OpenSSLConfCmd",
"addCmd",
"org.apache.tomcat.util.net.openssl.OpenSSLConfCmd");
digester.addObjectCreate("Server/Service/Connector/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Connector/Listener");
digester.addSetNext("Server/Service/Connector/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
digester.addObjectCreate("Server/Service/Connector/UpgradeProtocol",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Connector/UpgradeProtocol");
digester.addSetNext("Server/Service/Connector/UpgradeProtocol",
"addUpgradeProtocol",
"org.apache.coyote.UpgradeProtocol");
// Add RuleSets for nested elements
digester.addRuleSet(new NamingRuleSet("Server/GlobalNamingResources/"));
digester.addRuleSet(new EngineRuleSet("Server/Service/"));
digester.addRuleSet(new HostRuleSet("Server/Service/Engine/"));
digester.addRuleSet(new ContextRuleSet("Server/Service/Engine/Host/"));
addClusterRuleSet(digester, "Server/Service/Engine/Host/Cluster/");
digester.addRuleSet(new NamingRuleSet("Server/Service/Engine/Host/Context/"));
// When the 'engine' is found, set the parentClassLoader.
digester.addRule("Server/Service/Engine",
new SetParentClassLoaderRule(parentClassLoader));
addClusterRuleSet(digester, "Server/Service/Engine/Cluster/");
// 根据t1和t2,算出整个server.xml的Digester创建花费的时间
long t2=System.currentTimeMillis();
if (log.isDebugEnabled()) {
log.debug("Digester for server.xml created " + ( t2-t1 ));
}
return (digester);
}
这儿我们看到,在tomcat中明显地用到了前面例子中说明的几个规则,我们再简单罗列一下:
- addObjectCreate,对象创建规则
- addSetProperties,属性设置规则
- addSetNext,设置下一个规则
- addRule,自定义规则
- digester.addRuleSet,自定义规则集
总结
本文我们对digester做了一个使用说明。
我们首先简单地说明了一下digester是什么,内部基于什么原理来实现的。然后通过一个School、Grade和Class这样的生活中的例子来说明digester的用法。最后通过查看tomcat中关于digester的例子代码,加深了我们对于digester的理解。
最后
以上就是隐形白猫最近收集整理的关于Tomcat的使用总结(二)的全部内容,更多相关Tomcat内容请搜索靠谱客的其他文章。








发表评论 取消回复