
翻译汇总文章:
HipHopBoy:Unity SRP 系列翻译汇总zhuanlan.zhihu.com
原文链接 :
Custom Shaderscatlikecoding.com
原作者:Jasper Flick
由于水平有限,可能翻译的会有错误,请大家在评论区指出,我会及时更新改正。
Custom Shaders (自定义shader)
- 写一个HLSL shader
- 定义常量数据缓冲区 ps:什么是常量缓冲区:(Shader Model 4.0 常量缓冲的一种组织形式,CPU访问的延迟较低,适用于需要频繁在CPU端更新的数据。)
- 使用渲染管线核心库
- 支持Gpu Instancing动态合批
这是一个系列教程的第二部分,涵盖了Unity的脚本渲染管线。这篇教程主要内容是使用HLSL创建一个着色器,通过动态合批来只用一个drawcall来渲染多个物体。
这篇教程使用的Unity版本是2018.3.0f2.

256个球,只有一个dc
- 自定义 Unlit Shader
虽然我们使用了默认的unlit着色器来测试管线,但是想要完全体现自定义管线的优点,我们还需要创建自定义Shader来和他一起使用。现在我们创建我们自己的的Shader去代替Unity默认的Unlit Shader
1.1 创建Shader
通过Assets/Create/Shader 菜单创建一个Unlit shader,删除里面的代码,命名为Unlit

关于shader文件的基础知识我们在
Rendering 2catlikecoding.com
这个系列以及讲过。如果你对shader的基础知识不了解,可以去读一下。
一个Shader的最低要求是定义一个带有Properties块的 Shader块加上一个包含一个Pass块的子着色器块。Unity会把它变成一个默认的白色无光Shader,Shader关键字后面的字符串会显示在材质的下拉菜单里面。我们用下面的 My Pipeline/Unlit 说明
Shader "My Pipeline/Unlit" {
Properties {}
SubShader {
Pass {}
}
}调整Unlit Opaque材质用我们的新Shader,它会显示白色。
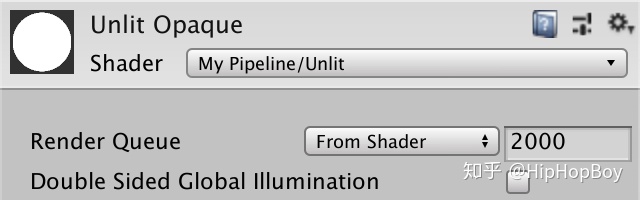
1.2 HLSL
我们要在我们自己Pass块里面放入一个program. Unity支持GLSL和HLSL两种语法。GLSL是shader的默认语法,在Rendering 2, Shader Fundamentals 我们用的也是GLSL。Unity新的渲染管线shader使用的是HLSL,所以我们在我们自定义的管线中也使用HLSL。所以我们必须要把我们的代码放到HLSLPROGRAM和ENDHLSL中间。
Pass {
HLSLPROGRAM
ENDHLSL
}一个最小的完整的Unity Shader还需要一个顶点着色器和片元着色器,每一个都用一个pragma编译器指令定义。我们把顶点着色器命名为UnlitPassvetex,把片元着色器命名为UnlitPassFragment.但是我们不会将这些函数的代码直接放到着色器文件中。相反,我们将把HLSL代码放在一个Unlit.hlsl的文件里面。把它和Unlit放在同一个文件夹。然后把它包含到HLSL程序中,在pragma指令之后。
HLSLPROGRAM
#pragma vertex UnlitPassVertex
#pragma fragment UnlitPassFragment
#include "Unlit.hlsl"
ENDHLSLUnity无法通过菜单按钮直接创建,所以我们要自己创建一个这样的文件。

在被包含的文件里面,我们要定义一个宏,防止文件被重复包含,我们对每一个文件最好都这么多。
#ifndef MYRP_UNLIT_INCLUDED
#define MYRP_UNLIT_INCLUDED
#endif // MYRP_UNLIT_INCLUDED在vetex shader中,我们必须传入顶点程序中的顶点位置和输出一个齐次空间位置。所以我们要定义输出结构和输入结构,都包含一个float4 类型的位置。
#ifndef MYRP_UNLIT_INCLUDED
#define MYRP_UNLIT_INCLUDED
struct VertexInput {
float4 pos : POSITION;
};
struct VertexOutput {
float4 clipPos : SV_POSITION;
};
#endif // MYRP_UNLIT_INCLUDED下一步,我们实现UnlitPassVetex函数,我们先直接把模型顶点坐标作为齐次坐标返回。这是不正确的,为了快速得到一个编译通过的shader,我们先这么做,后面我们再改正回来。
struct VertexOutput {
float4 clipPos : SV_POSITION;
};
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
output.clipPos = input.pos;
return output;
}
#endif // MYRP_UNLIT_INCLUDED现在我们保持默认的白色,所以我们在片段着色器(fragment shader)里面直接返回1.fragment shader 是把顶点着色器的返回值进行插值后的结果作为输入的,虽然现在我们还没用,但是我们先把它当做参数传入进去。
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
output.clipPos = input.pos;
return output;
}
float4 UnlitPassFragment (VertexOutput input) : SV_TARGET {
return 1;
}
#endif // MYRP_UNLIT_INCLUDED1.3 矩阵转换
我们这时候如果编译shader,并不会看到有明显的结果改变。下一步是转换顶点坐标到正确的空间。如果我们有一个model-view-projection矩阵我们就可以直接把顶点从模型空间转换到齐次坐标空间,但是Untiy没有直接为我们创建一个这样的矩阵,我们只有模型矩阵可用,我们可以用它把顶点转换到世界空间。unity 希望我们用一个float4x4 类型的unity_ObjectToWorld的变量来存储它。因为我们用HLSL语言,所以我们要自己定义这个变量,然后用它转换的结果作为输出。
float4x4 unity_ObjectToWorld;
struct VertexInput {
float4 pos : POSITION;
};
struct VertexOutput {
float4 clipPos : SV_POSITION;
};
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
float4 worldPos = mul(unity_ObjectToWorld, input.pos);
output.clipPos = worldPos;
return output;
}下一步我要从世界空间转换到裁剪空间,这需要一个viewprojection矩阵,Unity 通过一个float4x4类型的unit_MatrixVP 的变量来完成。
float4x4 unity_MatrixVP;
float4x4 unity_ObjectToWorld;
…
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
float4 worldPos = mul(unity_ObjectToWorld, input.pos);
output.clipPos = mul(unity_MatrixVP, worldPos);
return output;
}现在我们的shader是正确的。所有使用unlit材质的物体再次可见,都是白色的。但是我们的转换并不是最高效的,因为我们的矩阵相乘是用的4d 向量。第四位总是1,通过显示赋值,我们可以优化它。
float4 worldPos = mul(unity_ObjectToWorld, float4(input.pos.xyz, 1.0));1.4 常量缓冲区(contant buffers)
Unity并没有为我们提供一个模型-视图-投影矩阵,因为这样可以避免M和VP矩阵的矩阵乘法,除此之外,VP矩阵还可以重用于在同一帧中使用同一个摄像机绘制的所有内容.Unity的着色器利用了这个特点,并把矩阵放在不同的常数缓冲区中。虽然我们将它们定义为变量,但它们的数据在绘制单个形状期间保持不变,而且通常更长。VP矩阵被放入per-frame buffer,,而M矩阵被放入per-draw buffer。(原文是 :The VP matrix gets put in a per-frame buffer, while the M matrix gets put in a per-draw buffer.) (ps:不是很明白这两个常量缓冲区在哪里)。
并不是一定要求要把shader变量放入常量缓冲区,只是把数据放入相同的缓冲区可以更高效的改变它。但是这个需要图形API支持,opengl 不支持。
为了尽可能高效,我们使用常量缓冲区,Unity 把VP矩阵放入UnityPerFrame 里面,把M矩阵放入 UnityPerDraw 里面。还有更多的数据需要放入缓冲区,这里用不到,所以我们也不需要包含进去。除了需要把cbuffer关键字放到前面来保留权限,一个常量缓冲区的定义和结构体很像。
cbuffer UnityPerFrame {
float4x4 unity_MatrixVP;
};
cbuffer UnityPerDraw {
float4x4 unity_ObjectToWorld;
}1.5 Core Library (核心库)
因为常量缓冲区不适用所有平台,所以Unity用宏定义来区分什么时候使用。CBUFFER_START宏用来替代开始,CBUFFER_END 用来替代cbuffer的结束。我们也用这种方式描述如下
CBUFFER_START(UnityPerFrame)
float4x4 unity_MatrixVP;
CBUFFER_END
CBUFFER_START(UnityPerDraw)
float4x4 unity_ObjectToWorld;
CBUFFER_END这会导致两个编译错误,因为这两个宏没有定义。我们将使用Unity的核心库来渲染管道,而不是自己去弄清楚什么时候使用常量缓冲区和定义宏是合适的。核心库可以通过Package Manage Window添加。切换到All package 列表,展开Advanced 选项,选择Render-pipelines.core,然后安装。我使用的是版本4.6.0-preview,这是Unity 2018.3中最高的版本。
现在我们可以包含通用函数库,我们可以通过Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl. 访问。它定义了很多有用的函数和宏,也包含常量缓冲区的宏,所以我们在使用宏之前引用这个文件。
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl"
CBUFFER_START(UnityPerFrame)
float4x4 unity_MatrixVP;
CBUFFER_END1.6 编译目标版本
现在我们的shader可以在大多数平台运行了。在包含核心库之后,我们的shader在opengl es 2的平台上编译失败。这是因为unity 默认不支持使用核心库编译的shader在opengl es2平台。我们可以通过添加#pragma prefer_hlslcc gles 宏去修复它,这是unity为轻量级渲染管线定制的宏。其实,我们只要简单的不支持Opengl es2就好了,因为我们不想在旧设备上运行。我们只要用 #pragma target 把等级从2.5改成3.5就好了。
#pragma target 3.5
#pragma vertex UnlitPassVertex
#pragma fragment UnlitPassFragment1.7 文件夹结构
注意,所有包含核心库文件的HLSL都位于ShaderLibrary文件夹中,我们也这么做,在MyPipeline下创建一个ShaderLibrary文件夹,然后把 Unlit.hlsl文件放到里面。把shader也都存放到Shaders文件夹。

为了保持着色器完整,我们应该依赖相对路径,所以我们把路径引用从 Unlit.hlsl 修改为 ../ShaderLibrary/Unlit.hlsl.
#include "../ShaderLibrary/Unlit.hlsl"2 动态合批 (Dynamic Batching)
现在我们有了一个最小的自定义着色器,我们可以使用它来进一步研究我们的管道如何渲染东西。一个很大的问题是如何高效渲染。我们将通过用一堆球体填充场景来测试这一点,这些球体使用了我们的非发光材质。你可以用几千个,但几十个也能传达信息。它们可以有不同的位置和旋转,但是保持缩放比例一致,也就是每个缩放比例的 x y z都是相等的。

我们通过framedebugger来研究它,你发现一个球都需要一个单独的drawcall。这效率很低,因为每多一个drawcall都会增加cpu和gpu的通信开销。理想情况下,应该尽可能的让多个球通过一个drawcall来绘制,现在并不是这种情况,当您选择一个drawcall调用时,Frame debugger会给出一个提示。

2.1 开启批处理
Frame debugger 告诉我们动态合批没有被使用,可能是因为我们关掉了这个功能,也可能是因为深度排序打断了它。如果你检查Player setting,你会发现动态合批确实被关闭了,但是当你打开它之后,你发现并没有生效,这是因为Player setting 只对Unity 默认的管线有效,对自定义管线是无效的。
为了让我们自定义的管线也能开启动态合批,我们需要在DrawSetting 中表明它,通过下面的代码开启,就是drawSettings.flags = DrawRendererFlags.EnableDynamicBatching;
var drawSettings = new DrawRendererSettings(
camera, new ShaderPassName("SRPDefaultUnlit")
);
drawSettings.flags = DrawRendererFlags.EnableDynamicBatching;
drawSettings.sorting.flags = SortFlags.CommonOpaque;我们发现还是没有动态合批,但是原因已经变了。动态合批是在绘制之前把多个物体合并成一个Mesh.这需要cpu每一帧都花费时间去检查mesh的顶点个数没有超过限制的数字。如果超过300个顶点就会合批失败。

因为球形mesh顶点太多,换成立方体就可以了。你可以选择全部,把他们用一个Mesh filter.


2.2 Colors
动态合批适用于处理多个同一材质的小mesh物体,但是当多个材质被涉及的时候,情况就会变的复杂。为了举例说明,我们尽可能的去改变我们unlit shader 的颜色。添加一个_Color属性,用白色作为默认颜色
Properties {
_Color ("Color", Color) = (1, 1, 1, 1)
}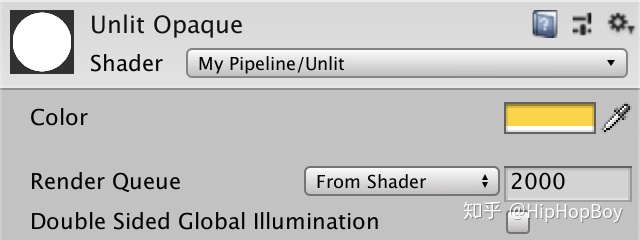
现在我们可以调整材质的颜色,但是还不会影响绘制的效果。添加一个float4 _Color变量到我们的引用文件里面,然后在UnlitPassFragment里面返回它,替换之前的固定值。每一个材质都会定义一个Color,所以我们可以放到常量缓冲区里面,只有材质切换时才需要改变。 我们把这个buffer命名为 UnityPerMaterial,像Unity一样。
CBUFFER_START(UnityPerDraw)
float4x4 unity_ObjectToWorld;
CBUFFER_END
CBUFFER_START(UnityPerMaterial)
float4 _Color;
CBUFFER_END
struct VertexInput {
float4 pos : POSITION;
};
…
float4 UnlitPassFragment (VertexOutput input) : SV_TARGET {
return _Color;
}复制我们的材质,给他们不同的颜色,以便于我们区分它们。选择几个cube然后给他们我们新的材质,然后你会看到不同颜色的cube在一个场景中。


这是两个材质,四个批次。
动态合批依然起作用,但是产生了多个批次。因为每个材质都有一批,每一批都需要不同的材质数据。但通常会有更多的批次,因为Unity更喜欢在空间上对对象进行分组,以减少overdraw.

2.3 批处理选项
动态合批可能带来好处,但也可能不会有任何改变,甚至会降低性能。如果你的场景中没有很多使用了同一个材质的小物体,那么禁用这个功能是有意义的,因为Unity不用在每一帧都去判断是否使用它。所以我们添加一个选项去开启动态合批在我们的渲染管线里。我们不依赖Player settintgs. 我们在MyPipelineAsset上添加一个开关控制,然后我们就可以在编辑器里面通过我们的PipelineAsset控制它。
[SerializeField]
bool dynamicBatching;
当MyPipeline实例创建的时候,我们告诉它是否使用动态合批,我们通过构造函数传入这个设置。
protected override IRenderPipeline InternalCreatePipeline () {
return new MyPipeline(dynamicBatching);
}为了让他生效,我们不在使用默认的构造函数。我们提供一个public方法,用一个bool值来控制动态合批。我们根据bool值设置drawflags 字段让它生效。
DrawRendererFlags drawFlags;
public MyPipeline (bool dynamicBatching) {
if (dynamicBatching) {
drawFlags = DrawRendererFlags.EnableDynamicBatching;
}
}然后把这个flags 赋值给 Render上的draw settings
drawSettings.flags = drawFlags;请注意,当我们在编辑器中切换资产的动态批处理选项时,Unity的批处理行为会立即改变。每次我们调整资产时,都会创建一个新的管道实例。
3 GPU Instancing (Gpu实例化)
动态合批不是我们减少drawcall的唯一方法。还有一个方法是Gpu Instancing。这种情况下,CPU通过一个drawcall 告诉GPU多次绘制网格和材质。这就可以对使用相同材质和网格的对象进行分组,而不用创建新的网格。这样就能解除网格大小的限制。
3.1 实例化选项
GPU 实例化是默认开启的,但是我们用我们自定义的Draw flags 覆盖了它。让我们也为GPU实例化做一个开关,这样我们可以很容易的对比开启它和关闭它的结果。同样的,我们通过MyPipeline的构造函数传入。
[SerializeField]
bool instancing;
protected override IRenderPipeline InternalCreatePipeline () {
return new MyPipeline(dynamicBatching, instancing);
}在MyPipeline构造函数方法中,我们也添加了一个实例化标志。在本例中,flags的值是DrawRendererFlags.EnableInstancing和原来flags的值做逻辑或操作,所以动态批处理和实例化可以在同一时间启用。当两者都启用时,Unity更倾向使用Gpu Instancing。
public MyPipeline (bool dynamicBatching, bool instancing) {
if (dynamicBatching) {
drawFlags = DrawRendererFlags.EnableDynamicBatching;
}
if (instancing) {
drawFlags |= DrawRendererFlags.EnableInstancing;
}
}
3.2 材质支持
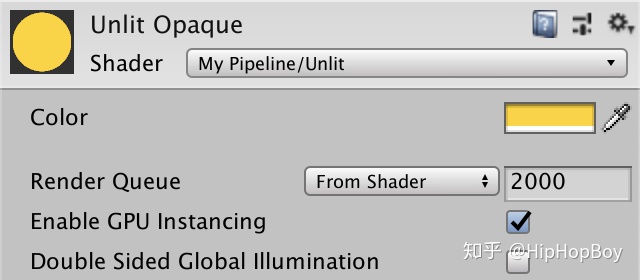
开启Gpu 实例化并不意味着所有的对象都会自动Gpu实例化。它还需要他们使用的材质支持才可以。因为GPU实例化不是总是需要的,他是个可选项,这就需要两个shader变体,一个支持一个不支持。我们通过在我们的shader里面添加#pragma multi_compile_instancing 来 创建我们所需要的shader变体。在我们的例子里面,它产生了两个变体,一个定义了 INSTANCINT_ON 关键字,一个没有定义。
#pragma target 3.5
#pragma multi_compile_instancing
#pragma vertex UnlitPassVertex
#pragma fragment UnlitPassFragment这个改变也会使材质上出现一个 Enable GPU Instancing的选项
3.3 Shader 支持
当实例化开启的时候,GPU被通知用同样的常量数据绘制一个同样的网格多次。但是模型矩阵是这个数据的一部分。也就意味着我们用同样的方式渲染多次后得到的是同一个mesh。为了避免这个问题,我们把一个包含所有对象模型矩阵的数组放到常量缓冲区。每个实例绘制根据自己索引从数组里面取出自己的模型矩阵。
我们使用实例化的时候使用数组,不使用的时候使用unity_ObjectToWorld,为了在UnlitPassVertex中保持代码一致,我们用UNITY_MATRIX_M 这个宏来定义矩阵。我们使用这个宏名,因为核心库有一个包含支持实例化宏的文件,并且它还重新定义了UNITY_MATRIX_M来在需要的时候使用矩阵数组。
CBUFFER_START(UnityPerDraw)
float4x4 unity_ObjectToWorld;
CBUFFER_END
#define UNITY_MATRIX_M unity_ObjectToWorld
…
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
float4 worldPos = mul(UNITY_MATRIX_M, float4(input.pos.xyz, 1.0));
output.clipPos = mul(unity_MatrixVP, worldPos);
return output;
}因为UnityInstancing.hlsl 文件可能会重定义 UNITY_MATRIX_M,所以我们在我们定义的宏后面要引用它。
#define UNITY_MATRIX_M unity_ObjectToWorld
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/UnityInstancing.hlsl"当使用实例化时,当前被绘制的对象的索引被GPU添加到它的顶点数据. UNITY_MATRIX_M要用到这个索引,所以我们要把他加到VertexInput的这个结构体里。我们用UNITY_VERTEX_INPUT_INSTANCE_ID 代表它。
struct VertexInput {
float4 pos : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};最后,我们要在UNITY_MATRIX_M 使用前使索引生效,我们通过input作为参数传给UNITY_SETUP_INSTANCE_ID 让他生效。
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
UNITY_SETUP_INSTANCE_ID(input);
float4 worldPos = mul(UNITY_MATRIX_M, float4(input.pos.xyz, 1.0));
output.clipPos = mul(unity_MatrixVP, worldPos);
return output;
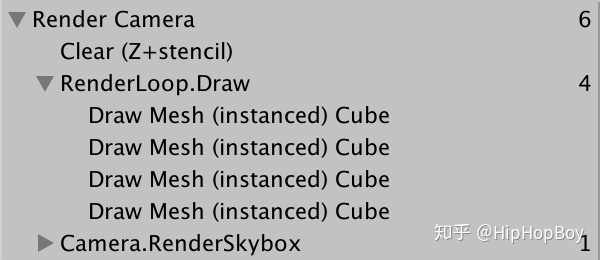
}我们的立方体现在使用了GPUInstancing。就像动态批处理一样,我们最终会得到多个批处理,因为我们使用了不同的材质。确保所有材质都启用了GPU实例化。
除了ObjectToWorld矩阵之外,Unity默认也把WorldToObject矩阵也放入了常量缓冲区。这是模型矩阵的转置,当使用非同一的缩放比例时,他需要法向量。但是我们只在统一缩放的时候使用,所以我们不需要添加这些额外的矩阵。我们可以通过把#pragma instancing_options assumeuniformscaling指令添加到我们的着色器来从缓冲区中去掉世界-模型矩阵。
#pragma multi_compile_instancing
#pragma instancing_options assumeuniformscaling如果您需要支持非均匀缩放,那么您将不得不使用一个没有启用此选项的着色器。
3.4 多种颜色
如果我们想要在场景中包含更多的颜色,我们需要制作更多的材质,这意味着我们会得到更多的批次。但是既然矩阵可以放到一个数组里,那么颜色应该也可以。我们就可以合并多个不同颜色的对象在一个批次里面。只用做一点点工作,就可以实现它。
第一步是可以让每个对象都可以设置独立的颜色,我们不能使用材质,因为它是所有对象共享的。我们为他来创建一个InstanceColor的组件,提供一个可以配置的颜色字段。因为它不是为我们的渲染管线定制的,所以把他放到My Pipeline文件夹之外。
using UnityEngine;
public class InstancedColor : MonoBehaviour {
[SerializeField]
Color color = Color.white;
}为了覆盖材质的颜色,我们必须为对象的渲染器组件提供一个材质属性块。通过创建一个新的MaterialPropertyBlock对象实例,通过它的SetColor方法给它一个_Color属性,然后通过调用它的SetPropertyBlock方法把它传递给对象的MeshRenderer组件。我们假设颜色在播放模式下保持不变,所以在类的Awake方法中这样做。
void Awake () {
var propertyBlock = new MaterialPropertyBlock();
propertyBlock.SetColor("_Color", color);
GetComponent<MeshRenderer>().SetPropertyBlock(propertyBlock);
}将我们的组件添加到场景中的一个对象中。你会看到它的颜色改变了,但只是在我们进入播放模式之后。
要在编辑模式下立即看到场景中的颜色变化,请将设置颜色的代码移动到OnValidate方法。然后,Awake方法可以简单地调用OnValidate,这样我们就不需要复制代码了。
void Awake () {
OnValidate();
}
void OnValidate () {
var propertyBlock = new MaterialPropertyBlock();
propertyBlock.SetColor("_Color", color);
GetComponent<MeshRenderer>().SetPropertyBlock(propertyBlock);
}将组件添加到所有形状中,选择所有形状并添加一次,但请确保一个对象只有一个。也让他们都用同样的材质。替代材质可以删除,因为我们为每个对象配置颜色。

注意,每次设置颜色时,我们都会创建一个新的MaterialPropertyBlock实例。这是不必要的,因为每个网格渲染器内部都引用被覆盖的属性,从属性块中复制他们。这意味着我们可以重用它,所以只要引用单个静态块,只在需要时创建它。
static MaterialPropertyBlock propertyBlock;
…
void OnValidate () {
if (propertyBlock == null) {
propertyBlock = new MaterialPropertyBlock();
}
propertyBlock.SetColor("_Color", color);
GetComponent<MeshRenderer>().SetPropertyBlock(propertyBlock);
}此外,我们还可以通过着色器PropertyToID方法,预取color属性的属性ID来稍微加快颜色属性的匹配。每个着色器属性名获得一个全局标识符整数。这个表示在一个会话期间保持不变,就是在编译和播放的时候不会改变。所以我们只取一次就可以了,可以用一个静态变量来完成。
static int colorID = Shader.PropertyToID("_Color");
…
void OnValidate () {
if (propertyBlock == null) {
propertyBlock = new MaterialPropertyBlock();
}
propertyBlock.SetColor(colorID, color);
GetComponent<MeshRenderer>().SetPropertyBlock(propertyBlock);
}3.5 预实例颜色
重写每个对象的颜色会导致GPU实例化失败。尽管我们使用的是同一个材质,但真正重要的是用于渲染的数据颜色是不同的。因为我们设置不同的颜色,所以他们会单独渲染。在这种情况下,我们需要自己完成,因为核心库不会为自定义属性重新定义宏

把颜色放到数组里,会避免这个问题。在这种情况下,我们需要自己完成,因为核心库不会为自定义属性重新定义宏。我们通过UNITY_INSTANCING_BUFFER_START宏和对应的结束宏手动创建一个用于GPU实例化的常量缓冲区,并且命名为PerInstance。在缓冲区内,我们将颜色定义为UNITY_DEFINE_INSTANCED_PROP(float4, _Color),当禁用GPU实例化时该宏就相当于float4 _Color,当启用GPU实例化时我们会得到一组实例数据。
//CBUFFER_START(UnityPerMaterial)
//float4 _Color;
//CBUFFER_END
UNITY_INSTANCING_BUFFER_START(PerInstance)
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_INSTANCING_BUFFER_END(PerInstance)要处理颜色现在可以定义的两种可能的方法,我们必须通过UNITY_ACCESS_INSTANCED_PROP宏来访问它,将我们的缓冲区和属性名传递给它。
float4 UnlitPassFragment (VertexOutput input) : SV_TARGET {
return UNITY_ACCESS_INSTANCED_PROP(PerInstance, _Color);
}现在实例索引也必须在UnlitPassFragment中可用。因此,将UNITY_VERTEX_INPUT_INSTANCE_ID添加到VertexOutput中,然后在UnlitPassFragment中使用UNITY_SETUP_INSTANCE_ID,就像我们在UnlitPassVertex中所做的那样。要做到这一点,我们必须将索引从顶点输入复制到顶点输出,为此我们可以使用UNITY_TRANSFER_INSTANCE_ID宏。
struct VertexInput {
float4 pos : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct VertexOutput {
float4 clipPos : SV_POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
VertexOutput UnlitPassVertex (VertexInput input) {
VertexOutput output;
UNITY_SETUP_INSTANCE_ID(input);
UNITY_TRANSFER_INSTANCE_ID(input, output);
float4 worldPos = mul(UNITY_MATRIX_M, float4(input.pos.xyz, 1.0));
output.clipPos = mul(unity_MatrixVP, worldPos);
return output;
}
float4 UnlitPassFragment (VertexOutput input) : SV_TARGET {
UNITY_SETUP_INSTANCE_ID(input);
return UNITY_ACCESS_INSTANCED_PROP(PerInstance, _Color);
}
现在所有对象都在一个draw调用中结束,即使它们都使用不同的颜色。但是,可以将多少数据放入常量缓冲区是有限制的。最大的实例批处理大小取决于每个实例改变多少数据。除此之外,每个平台的缓冲区最大值是不同的。我们仍然局限于使用相同的网格和材质。例如,混合立方体和球体将分批。


在这里,我们有一个最小的着色器,可以用来绘制尽可能有效的许多对象。将来,我们将在这个基础上创建更高级的着色器。
下一篇教程是灯光。
作者仓库:
Bitbucketbitbucket.org我的github地址:
zhudianyu/MyUnityToturialgithub.com
最后
以上就是能干夏天最近收集整理的关于document.onmousemove放在onmousedown 里面定义_Unity SRP 2.自定义shader的全部内容,更多相关document.onmousemove放在onmousedown内容请搜索靠谱客的其他文章。








发表评论 取消回复