来源:公众号阿飞Javaer , 作者 阿飞的博客JVM的GC机制绝对是很多程序员的福音,它让Java程序员省去了自己回收垃圾的烦恼。从而可以把大部分时间专注业务身上,大大提高了业务开发速度,让产品需求尽快的落地抢占市场。但是也正因为如此,导致很多Java程序员对JVM和GC知之甚少,以我愚见大家对JVM&GC不够了解的有几个原因:
- 门槛太高。我们平常接触的spring,dubbo,java集合&J.U.C,网上都有无数优秀的文章对其深入的分析。而且都是基于Java语言,我们在学习的过程中,可以自己很容易的debug源码更深入的了解。但是JVM则不然,它是C++开发的,能同时掌握C++和Java的程序员还是很少的,自己也不太好debug分析它的源码(就是编译jvm源码,都要折腾一番)。
- 有价值的系列文章太少。网上几乎没有完整体系的文章,优秀的书籍也很少(可能大家听过或者看过最多的就是周志明的深入理解Java虚拟机,这确实是JVM领域比较少见的佳作)。
- 接触的太少。虽然我们天天写Java代码,你写的每行代码JVM都会参与工作。但是很少进行GC调优,因为JVM是如此的优秀,绝大部分情况下,它只是默默的做你背后的女人(即使出问题了,也轮不到我们去排查,扎心了)。
R大是谁?语言是苍白的,请戳知乎链接:https://www.zhihu.com/question/24923005/answer/29512367。另外,如果对JVM很感兴趣的朋友,可以看一下R大在知乎上的一些答疑:https://www.zhihu.com/people/rednaxelafx。并且如果你也恰好看周志明的深入理解Java虚拟机,强烈建议结合R大的读书笔记进行阅读:https://book.douban.com/people/RednaxelaFX/annotation/24722612/。笔者还认识另外两位对JVM有一定研究的大牛:你假笨和占小狼,有性趣的同学可以关注并了解(网上其他文章,持保留意见)。对于JVM&GC,很多人没有去了解它,很多人也没机会去了解它,甚至有部分人都不原因去了解它。然而要想成为一名优秀的Java程序员,了解JVM和它的GC机制,写出JVM GC机制更喜欢的代码。并且你能知道JVM这个背后的女人是否发脾气了,还知道她发脾气的原因,这是必须要掌握的一门技术,是通往高级甚至优秀必须具备的技能。
这篇文章我不打算普及JVM&GC基础,而是主要讲解如何初步诊断GC是否正常,重点讲解诊断GC。所以看这篇文章的前提,需要你对JVM有一定的了解,比如常用的垃圾回收器,Java堆的模型等。如果你还对JVM一无所知,并且确实想初步了解这门技术,那么请先花点时间看一下周志明的<>,重点关注"第二部分 自动内存管理机制"。
GC概念纠正
初步诊断GC之前,先对GC中最常误解的几个概念普及一下。对GC机制有一定了解的同学都知道,GC主要有YoungGC,OldGC,FullGC(还有G1中独有的Mixed GC,收集整个young区以及部分Old区,提及的概率相对少很多,本篇文章不打算讲解),大概解释一下这三种GC,因为很多很多的同学对OldGC和FullGC有非常大的误解;
- Young GC:应该是最没有歧义的一种GC了,只是有些地方称之为Minor GC,或者简称YGC,都是没有问题的;
- Old GC:截止Java发展到现在JDK9为止,只单独回收Old区的只有CMS GC,并且我们常说的CMS是指它的background collection模式,这个模式包含CMS GC完整的5个阶段:初始化标记,并发标记,重新标记,并发清理,并发重置。由CMS的5个阶段可知,仍然有两个阶段需要STW,所以CMS并不是完全并发,而是Mostly Concurrent Mark Sweep,G1出来之前,CMS绝对是OLTP系统标配的垃圾回收器。
- FullGC:有些地方称之为Major GC,Major GC通常是跟FullGC是等价的,都是收集整个GC堆。但因为HotSpot VM发展了这么多年,外界对各种名词的解读已经完全混乱了,当有人说“Major GC”的时候一定要问清楚他想要指的是上面的FullGC还是OldGC(参考R大的Major GC和Full GC的区别:https://www.zhihu.com/question/41922036/answer/93079526)。大家普遍对这个GC的误解绝对是最大的(我可以说至少有80%的人都有误解),首先对于ParallelOldGC即默认GC在Old满了以后触发的FullGC是没有问题的,jstat命令查看输出结果FGC的值也会相应的+1,即发生了一次FGC。FGC误解主要来自最常用的ParNew+CMS组合,很多人误解FullGC可能是受到jstat命令结果的影响,因为发生CMS GC时,FGC也会增大(但是会+2,这是因为CMS GC的初始化标记和重新标记都会完全的STW,从而FGC的值会+2)。但是,事实上这并没有发生FullGC。jstat命令结果中的FGC并不表示就一定发生了FullGC,很有可能只是发生了CMS GC而已。事实上,FullGC的触发条件非常苛刻,判断是否发生了FullGC最好的方法是通过GC日志,日志中如果有"full gc"的字样,就表示一定发生了Full GC。所以强烈建议生产环境开启GC日志,它的价值远大于它对性能的影响(不用权衡这个影响有多大,开启就对了)。
关于CMS的foreground collect模式,以及FullGC:
- foreground collect
它发生的场景,比如业务线程请求分配内存,但是内存不够了,于是可能触发一次CMS GC,这个过程就必须要等待内存分配成功后线程才能继续往下面走,因此整个过程必须STW,因此这种CMS GC整个过程都是暂停应用的,但是为了提高效率,它并不是每个阶段都会走的,只走其中一些阶段,这些省下来的阶段主要是并行阶段:Precleaning、AbortablePreclean,Resizing这几个阶段都不会经历,但不管怎么说如果走了类似foreground这种CMS GC,那么整个过程业务线程都是不可用的,效率会影响挺大。相关源码可以在openjdk的concurrentMarkSweepGeneration.cpp中找到。
- G1下的FullGC
G1或者ParNew+CMS组合前提下,如果真的发生FullGC,则是单线程完全STW的回收方式(SerialGC),可以想象性能有多差,如果是es,hbase等需要几十个G的堆,那更是灾难。不过JDK10将对其进行优化,可以参考:http://openjdk.java.net/jeps/307,如下图所示:

JEP 307: Parallel Full GC for G1
后面还有一段描述(Description):
The G1 garbage collector is designed to avoid full collections, but when the concurrent collections can't reclaim memory fast enough a fall back full GC will occur. The current implementation of the full GC for G1 uses a single threaded mark-sweep-compact algorithm. We intend to parallelize the mark-sweep-compact algorithm and use the same number of threads as the Young and Mixed collections do. The number of threads can be controlled by the -XX:ParallelGCThreads option, but this will also affect the number of threads used for Young and Mixed collections.
FullGC触发条件
这里列举一些可能导致FullGC的原因,这也是一些高级面试可能问到的问题:
- 没有配置 -XX:+DisableExplicitGC情况下System.gc()可能会触发FullGC;
- Promotion failed;
- concurrent mode failure;
- Metaspace Space使用达到MaxMetaspaceSize阈值;
- 执行jmap -histo:live或者jmap -dump:live;
说明:统计发现之前YGC的平均晋升大小比目前old gen剩余的空间大,触发的是CMS GC;如果配置了CMS,并且Metaspace Space使用量达到MetaspaceSize阈值也是触发CMS GC;
这里可以参考笔者另外一篇文章:PermSize&MetaspaceSize区别
执行jmap -histo:live触发FullGC的gc log如下--关键词Heap Inspection Initiated GC,通过jstat -gccause pid 2s的LGCC列也能看到同样的关键词:
[Full GC (Heap Inspection Initiated GC) 2018-03-29T15:26:51.070+0800: 51.754: [CMS: 82418K->55047K(131072K), 0.3246618 secs] 138712K->55047K(249088K), [Metaspace: 60713K->60713K(1103872K)], 0.3249927 secs] [Times: user=0.32 sys=0.01, real=0.32 secs]执行jmap -dump:live触发FullGC的gc log如下--关键词Heap Dump Initiated GC,通过jstat -gccause pid 2s的LGCC列也能看到同样的关键词:
[Full GC (Heap Dump Initiated GC) 2018-03-29T15:31:53.825+0800: 354.510: [CMS2018-03-29T15:31:53.825+0800: 354.510: [CMS: 55047K->56358K(131072K), 0.3116120 secs] 84678K->56358K(249088K), [Metaspace: 62153K->62153K(1105920K)], 0.3119138 secs] [Times: user=0.31 sys=0.00, real=0.31 secs]健康的GC
诊断GC的第一步,当然是知道你的JVM的GC是否正常。那么GC是否正常,首先就要看YoungGC,OldGC和FullGC是否正常;无论是定位YoungGC,OldGC,FullGC哪一种GC,判断其是否正常主要从两个维度:GC频率和STW时间;要得到这两个维度的值,我们需要知道JVM运行了多久,执行如下命令即可:
ps -p pid -o etime运行结果参考如下,表示这个JVM运行了24天16个小时37分35秒,如果JVM运行时间没有超过一天,执行结果类似这样"16:37:35":
[afei@ubuntu ~]$ ps -p 11864 -o etime ELAPSED24-16:37:35那么怎样的GC频率和STW时间才算是正常呢?这里以我以前开发过的一个读多写少的dubbo服务作为参考,该dubbo服务基本情况如下:
- 日调用量1亿+次,接口平均响应时间8ms以内
- 4个JVM
- 每个JVM设置Xmx和Xms为4G并且Xmn1G
- 4核CPU + 8G内存服务器
- JDK7
- AWS云服务器
GC情况如下图所示:
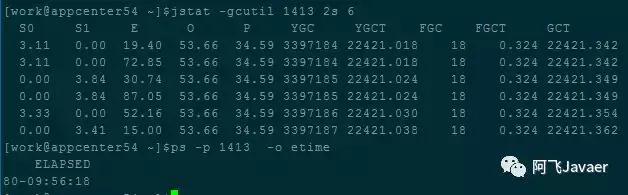
GC统计信息
根据这张图输出数据,可以得到如下一些信息:
- JVM运行总时间为7293378秒(80*24*3600+9*3600+56*60+18)
- YoungGC频率为2秒/次(7293378/3397184,jstat结果中YGC列的值)
- CMS GC频率为9天/次(因为FGC列的值为18,即最多发生9次CMS GC,所以CMS GC频率为80/9≈9天/次)
- 每次YoungGC的时间为6ms(通过YGCT/YGC计算得出)
- FullGC几乎没有(JVM总计运行80天,FGC才18,即使是18次FullGC,FullGC频率也才4.5天/次,更何况实际上FGC=18肯定包含了若干次CMS GC)
如果要清楚的统计CMS GC和FullGC的次数,只能通过GC日志了。
根据上面的GC情况,给个可参考的健康的GC状况:
- YoungGC频率不超过2秒/次;
- CMS GC频率不超过1天/次;
- 每次YoungGC的时间不超过15ms;
- FullGC频率尽可能完全杜绝;
说明:这里只是参考,不是绝对,不能说这个GC状况有多好,起码横向对比业务规模,以及服务器规格,你的GC状况不能与笔者的dubbo服务有明显的差距。
了解GC健康时候的样子,那么接下来把脉你的JVM GC,看看是有疾在腠理,还是在肌肤,还是在肠胃,甚至已经在骨髓,病入膏肓没救了;
YGC
YGC是最频繁发生的,发生的概率是OldGC和FullGC的的10倍,100倍,甚至1000倍。同时YoungGC的问题也是最难定位的。这里给出YGC定位三板斧(都是踩过坑):
- 查看服务器SWAP&IO情况,如果服务器发生SWAP,会严重拖慢GC效率,导致STW时间异常长,拉长接口响应时间,从而影响用户体验(推荐神器sar,yum install sysstat即可,想了解该命令,请搜索"linux sar");
- 查看StringTable情况(请参考:探索StringTable提升YGC性能)
- 排查每次YGC后幸存对象大小(JVM模型基于分配的对象朝生夕死的假设设计,如果每次YGC后幸存对象较大,可能存在问题)
- 未完待续……(可以在留言中分享你的idea)
排查每次YGC后幸存对象大小可通过GC日志中发生YGC的日志计算得出,例如下面两行GC日志,第二次YGC相比第一次YGC,整个Heap并没有增长(都是647K),说明回收效果非常理想:
2017-11-28T10:22:57.332+0800: [GC (Allocation Failure) 2017-11-28T10:22:57.332+0800: [ParNew: 7974K->0K(9216K), 0.0016636 secs] 7974K->647K(19456K), 0.0016865 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-11-28T10:22:57.334+0800: [GC (Allocation Failure) 2017-11-28T10:22:57.334+0800: [ParNew: 7318K->0K(9216K), 0.0002355 secs] 7965K->647K(19456K), 0.0002742 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 再看下面两行GC日志,第二次YGC相比第一次YGC,整个Heap从2707K增长到了4743K,说明回收效果不太理想,如果每次YGC时发现好几十M甚至上百M的对象幸存,那么可能需要着手排查了:
2017-11-28T10:26:41.890+0800: [GC (Allocation Failure) 2017-11-28T10:26:41.890+0800: [ParNew: 7783K->657K(9216K), 0.0013021 secs] 7783K->2707K(19456K), 0.0013416 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-11-28T10:26:41.892+0800: [GC (Allocation Failure) 2017-11-28T10:26:41.892+0800: [ParNew: 7982K->0K(9216K), 0.0018354 secs] 10032K->4743K(19456K), 0.0018536 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 可参考的健康的GC状况给出建议YGC频率不超过2秒/次,经验值2秒~10秒/次都是比较合理的YGC频率;
- 如果YGC频率远高于这个值,例如20秒/次,30秒/次,甚至60秒/次,这种情况下,说明JVM相当空闲,处于基本上无事可做的状态。建议缩容,减少服务器浪费;
- 如果YoungGC频率远低于这个值,例如1秒/次,甚至1秒/好多次,这种情况下,JVM相当繁忙,建议follow如下步骤进行初步症断:
- 检查Young区,Young区在整个堆占比在25%~40%比较合理,如果Young区太小,建议扩大Xmn。
- 检查SurvivorRatio,保持默认值8即可,Eden:S0:S1=8:1:1是一个比较合理的值;
OldGC
上面已经提及:到目前为止HotSpot JVM虚拟机只单独回收Old区的只有CMS GC。触发CMS GC条件比较简单,JVM有一个线程定时扫描Old区,时间间隔可以通过参数-XX:CMSWaitDuration设置(默认就是2s),扫描发现Old区占比超过参数-XX:CMSInitiatingOccupancyFraction设定值(CMS条件下默认为68%),就会触发CMS GC。建议搭配-XX:+UseCMSInitiatingOccupancyOnly参数使用,简化CMS GC触发条件,只有在Old区占比满足-XX:CMSInitiatingOccupancyFraction条件的情况下才触发CMS GC;
可参考的健康的GC状况给出建议CMS GC频率不超过1天/次,如果CMS GC频率1天发生数次,甚至上10次,说明你的GC情况病的不轻了,建议follow如下步骤进行初步症断:
- 检查Young区与Old区比值,尽量留60%以上的堆空间给Old区;
- 通过jstat查看每次YoungGC后晋升到Old区对象占比,如果发现每次YoungGC后Old区涨好几个百分点,甚至上10个点,说明有大对象,建议dump(参考jmap -dump:format=b,file=app.bin pid)后用MAT分析;
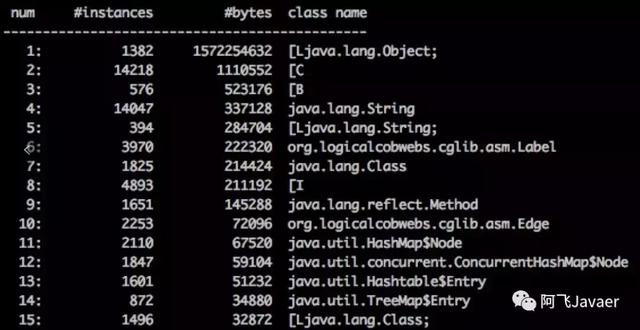
- 如果不停的CMS GC,Old区降不下去,建议先执行jmap -histo pid | head -n10 查看TOP10对象分布,如果除了[B和[C,即byte[]和char[],还有其他占比较大的实例,如下图所示中排名第一的Object数组,也可通过dump后用MAT分析问题;
- 如果TOP10对象中有StandartSession对象,排查你的业务代码中有没有显示使用HttpSession,例如String id = request.getSession().getId();,一般的OLTP系统都是无状态的,几乎不会使用HttpSession,且HttpSession的的生命周期很长,会加快Old区增长速度;
异常的大对象.png
笔者曾经帮一位朋友排查过一个问题:他也是TOP对象中有StandartSession对象,并且占比较大,后面让他排查发现在接口中使用了HttpSession生成一个唯一ID,让他改成用UUID就解决了OldGC频繁的问题。
FullGC
如果配置CMS,由于CMS采用标记清理算法,会有内存碎片的问题,推荐配置一个查看内存碎片程度的JVM参数:PrintFLSStatistics。
如果配置ParallelOldGC,那么每次Old区满后,会触发FullGC,如果FullGC频率过高,也可以通过上面OldGC提及的排查方法;
如果没有配置-XX:+DisableExplicitGC,即没有屏蔽System.gc()触发FullGC,那么可以通过排查GC日志中有System字样判断是否由System.gc()触发,日志样本如下:
558082.666: [Full GC (System) [PSYoungGen: 368K->0K(42112K)] [PSOldGen: 36485K->32282K(87424K)] 36853K->32282K(129536K) [PSPermGen: 34270K->34252K(196608K)], 0.2997530 secs]或者通过jstat -gccause pid 2s pid判定,LGCC表示最近一次GC原因,如果为System.gc,表示由System.gc()触发,GCC表示当前GC原因,如果当前没有GC,那么就是No GC:

System.gc引起的FullGC
最后
以上就是简单豌豆最近收集整理的关于gc就是fullgc吗 major_你的JVM还好吗?GC初步诊断FullGC触发条件FullGC的全部内容,更多相关gc就是fullgc吗内容请搜索靠谱客的其他文章。








发表评论 取消回复