2019独角兽企业重金招聘Python工程师标准>>> 
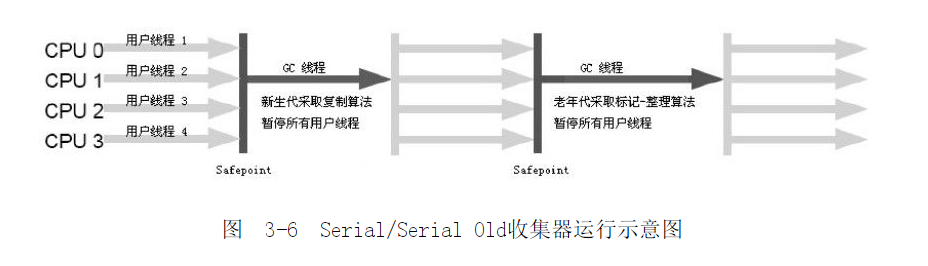
一、Serial/Serial Old收集器
- 历史最悠久的收集器
- 单线程的收集器
- 在工作时需要停掉虚拟机所有线程
- 优点是在做事专一,动作迅速
- 在Client端的新生代中一般使用这个收集器回收,回收200M以内的新生代只需要不到100ms,这对于Client是可以接受的
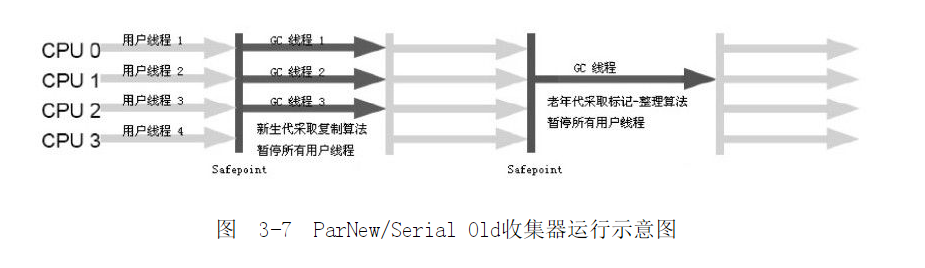
二、ParNew收集器
- Serial收集器的多线程版本
- 只有ParNew收集器可以与CMS收集器配合使用
三、Parallel Scavenge收集器
- 吞吐连优先的收集器
- 吞吐量:代码运行时间/(代码运行时间 + 垃圾收集时间)
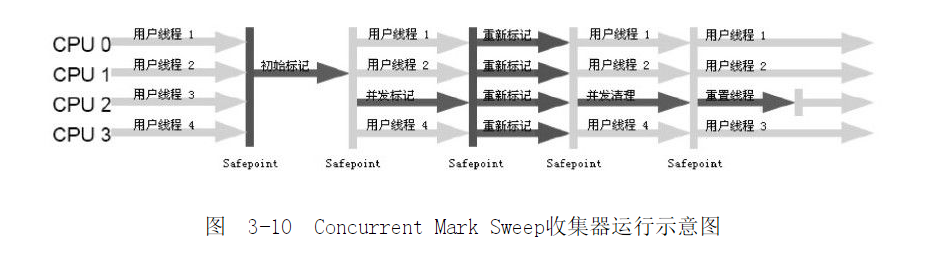
四、CMS收集器
- 老年代并发收集器
- 基于 标记清除算法实现
- 执行垃圾收集时有四个步骤
- 初始标记(Stop the World):标记一下GC Root能直接关联的对象,速度很快
- 并发标记:使用可达性分析算法,标记需要回收的对象
- 重新标记(Stop the World):标记 并发标记 期间变化的对象(多线程)
- 并发清除
- CMS优点:并发收集、低停顿
- CMS缺点:
- 并发占用CPU,导致用户线程变慢
- 会产生浮动垃圾(并发清除时产生的垃圾),因为在并发清除时还用用户线程在执行,所以要预留一部分内存,所以可以通过参数设定当老年代内存被占用 X% 时触发CMS回收,如果回收失败,会触发Serial Old收集器,进行再一次回收
- CMS收集器是使用标记清除算法实现的,所以会残生大量内存碎片,所以当CMS收集器触发Serial Old时要进行内存整理操作(这个过程无法并发,所以会导致程序变慢,可以通过参数设定)
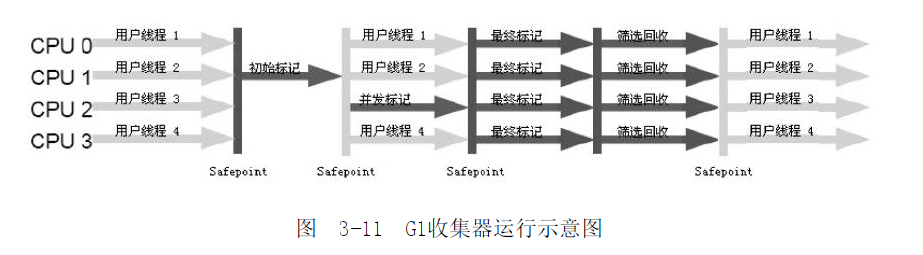
五、G1收集器
- G1收集器是注重停顿时间的收集器
- G1收集器可以不需要其他收集器配合,独立管理新生代和老年代
- G1收集器将java堆分成多个Region(新生代和老年代穿插在不同的Region里,不再物理隔离),两个Region通过复制算法手机,整体看来通过标记整理算法手机,不会产生内存碎片
- 通过建立可预测的停顿时间模型,可以让使用者明确在M毫秒内的内存回收不超过N毫秒
- G1收集器,会根据停顿时间模型计算每个Region回收的经验值,根据可以回收的时间(N毫秒)来回收最有回收价值的Region
- G1收集器通过Remebered Set记录Region中对象有没有被其他Region中的对象引用(为了避免全堆扫描)
- G1收集器的过程:
- 初始标记(Stop the World):标记一下GC Root能直接关联的对象,速度很快,与CMS不同的是,这个阶段会修改TAMS值,让 并发标记 阶段产生的新对象都在正确可用的Region中创建
- 并发标记:通过可达性分析算法标记回收的对象
- 最终标记:修正在并发标记时改变的对象,并记录到Remebered Set Logs中,然后虚拟机将Logs合并到Remebered Set中,这个过程是并行的(非并发)
- 筛选回收:根据Region的回收价值大小回收
转载于:https://my.oschina.net/u/3001485/blog/801833
最后
以上就是长情铃铛最近收集整理的关于六、Hotspot中的垃圾收集器的全部内容,更多相关六、Hotspot中内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复