前言
金三银四马上要来了,整理了Java一些经典面试题,也给出了答案,希望对大家有帮助,有哪里你觉得不正确的话,欢迎指出,非常感谢。
HashMap,HashTable,ConcurrentHash的共同点和区别
思路:可以从它们的底层结构、是否允许存储null,是否线性安全等几个维度进行描述,最后可以向面试官描述一下HashMap的死循环问题,以及ConcurrentHashMap为啥放弃分段锁。
HashMap
- 底层由链表+数组实现
- 可以存储null键和null值
- 线性不安全
- 初始容量为16,扩容每次都是2的n次幂
- 加载因子为0.75,当Map中元素总数超过Entry数组的0.75,触发扩容操作.
- 并发情况下,HashMap进行put操作会引起死循环,导致CPU利用率接近100%
有关于HashMap死循环,有兴趣可以看看这篇文章,写得很好: 老生常谈,HashMap的死循环
有关于HashMap这些常量设计目的,也可以看我这篇文章:
面试加分项-HashMap源码中这些常量的设计目的
HashTable
- HashTable的底层也是由链表+数组实现。
- 无论key还是value都不能为null
- 它是线性安全的,使用了synchronized关键字。
ConcurrentHashMap
- ConcurrentHashMap的底层是数组+链表/红黑树
- 不能存储null键和值
- ConcurrentHashMap是线程安全的
- ConcurrentHashMap使用锁分段技术确保线性安全
- JDK8为何又放弃分段锁,是因为多个分段锁浪费内存空间,竞争同一个锁的概率非常小,分段锁反而会造成效率低。
ArrayList和LinkedList有什么区别。
思路:从它们的底层数据结构、效率、开销进行阐述
- ArrayList是数组的数据结构,LinkedList是链表的数据结构。
- 随机访问的时候,ArrayList的效率比较高,因为LinkedList要移动指针,而ArrayList是基于索引(index)的数据结构,可以直接映射到。
- 插入、删除数据时,LinkedList的效率比较高,因为ArrayList要移动数据。
- LinkedList比ArrayList开销更大,因为LinkedList的节点除了存储数据,还需要存储引用。
String,Stringbuffer,StringBuilder的区别。
String:
- String类是一个不可变的类,一旦创建就不可以修改。
- String是final类,不能被继承
- String实现了equals()方法和hashCode()方法
StringBuffer:
- 继承自AbstractStringBuilder,是可变类。
- StringBuffer是线程安全的
- 可以通过append方法动态构造数据。
StringBuilder:
- 继承自AbstractStringBuilder,是可变类。
- StringBuilder是非线性安全的。
- 执行效率比StringBuffer高。
JAVA中的几种基本数据类型是什么,各自占用多少字节。
| 基本类型 | 位数 | 字节 |
|---|---|---|
| int | 32 | 4 |
| short | 16 | 2 |
| long | 64 | 8 |
| byte | 8 | 1 |
| char | 16 | 2 |
| float | 32 | 4 |
| double | 64 | 8 |
| boolean | 1 | 1/8 |
看例子:
public class Test {
public static void main(String[] args) {
System.out.println("Byte bit num: " + Byte.SIZE);
System.out.println("Short bit num : " + Short.SIZE);
System.out.println("Character bit num: " + Character.SIZE);
System.out.println("Integer bit num: " + Integer.SIZE);
System.out.println("Float bit num: " + Float.SIZE);
System.out.println("Long bit num: " + Long.SIZE);
System.out.println("Double bit num: " + Double.SIZE);
}
}
运行结果:
Byte bit num: 8
Short bit num : 16
Character bit num: 16
Integer bit num: 32
Float bit num: 32
Long bit num: 64
Double bit num: 64
String s 与new String的区别
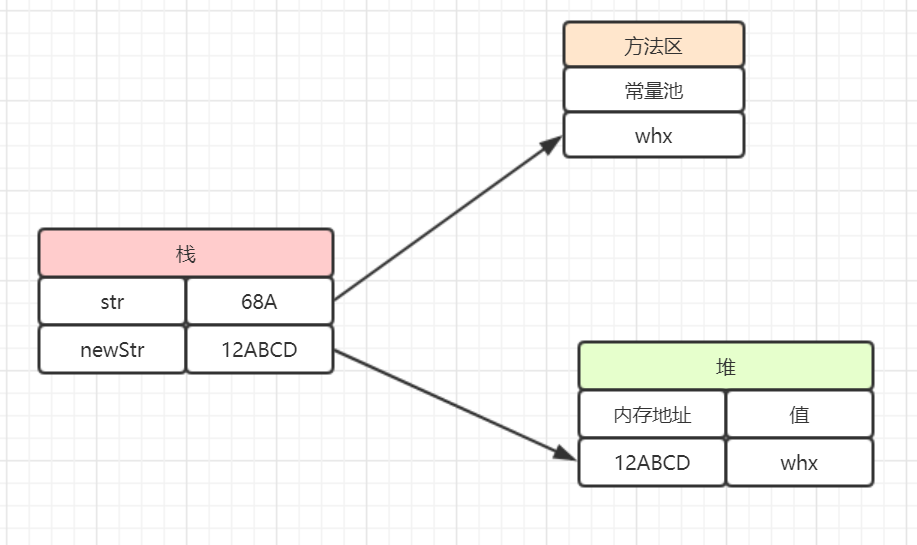
String str ="whx";
String newStr =new String ("whx");
String str ="whx"
先在常量池中查找有没有"whx" 这个对象,如果有,就让str指向那个"whx".如果没有,在常量池中新建一个“whx”对象,并让str指向在常量池中新建的对象"whx"。
String newStr =new String (“whx”);
是在堆中建立的对象"whx" ,在栈中创建堆中"whx" 对象的内存地址。
如图所示:
这篇文章讲的挺好的:
String和New String()的区别
Bio、Nio、Aio区别
BIO
就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用时可靠的线性顺序。它的有点就是代码比较简单、直观;缺点就是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
NIO
是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
AIO
是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,所以人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
以上内容来自这篇文章,大家可以看一下,写得比较详细
Java核心(五)深入理解BIO、NIO、AIO
谈谈spring的生命周期
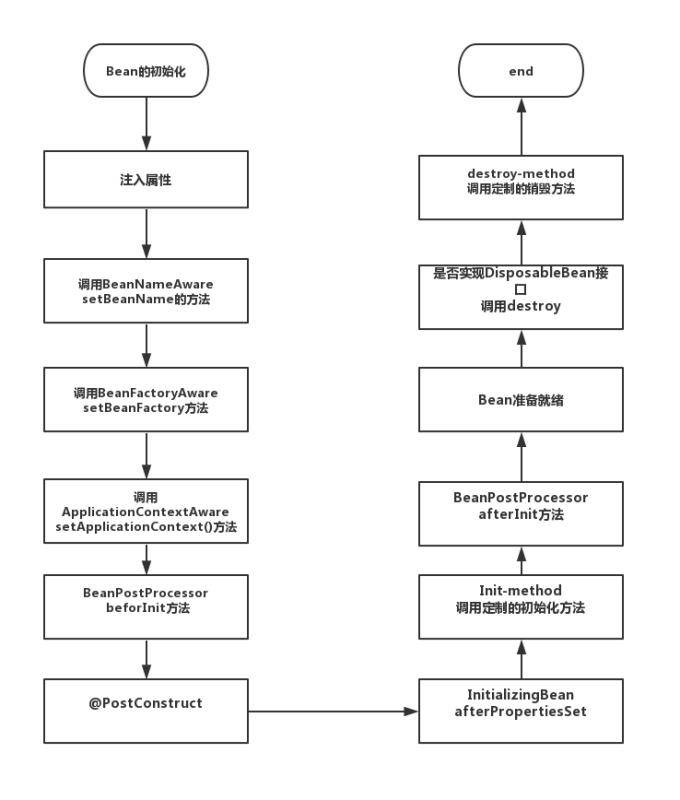
- 首先容器启动后,对bean进行初始化
- 按照bean的定义,注入属性
- 检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给bean,如BeanNameAware等
- 以上步骤,bean对象已正确构造,通过实现BeanPostProcessor接口,可以再进行一些自定义方法处理。
如:postProcessBeforeInitialzation。 - BeanPostProcessor的前置处理完成后,可以实现postConstruct,afterPropertiesSet,init-method等方法,
增加我们自定义的逻辑, - 通过实现BeanPostProcessor接口,进行postProcessAfterInitialzation后置处理
- 接着Bean准备好被使用啦。
- 容器关闭后,如果Bean实现了DisposableBean接口,则会回调该接口的destroy()方法
- 通过给destroy-method指定函数,就可以在bean销毁前执行指定的逻
反射的原理,反射创建类实例的三种方式是什么。
Java反射机制:
Java 的反射机制是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法; 并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能成为Java语言的反射机制
获取 Class 类对象三种方式:
- 使用 Class.forName 静态方法
- 使用类的.class 方法
- 使用实例对象的 getClass() 方法
可以看一下我写的这篇文章:
谈谈Java反射:从入门到实践,再到原理
说几种实现幂等的方式
什么是幂等性?一次和多次请求某一个资源对于资源本身应该具有同样的结果。就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
实现幂等一般有以下几种方式:
- 悲观锁方式(如数据库的悲观锁,select…for update)
- 乐观锁方式 (如CAS算法)
- 唯一性约束(如唯一索引)
- 分布式锁 (redis分布式锁等)
可以看一下这篇文章,写得不错:
探讨一下实现幂等性的几种方式
讲讲类的实例化顺序,如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段等。
直接看个例子吧:
public class Parent {
{
System.out.println("父类非静态代码块");
}
static {
System.out.println("父类静态块");
}
public Parent() {
System.out.println("父类构造器");
}
}
public class Son extends Parent {
public Son() {
System.out.println("子类构造器");
}
static {
System.out.println("子类静态代码块");
}
{
System.out.println("子类非静态代码块");
}
}
public class Test {
public static void main(String[] args) {
Son son = new Son();
}
}
运行结果:
父类静态块
子类静态代码块
父类非静态代码块
父类构造器
子类非静态代码块
子类构造器
所以,类实例化顺序为:
父类静态代码块/静态域->子类静态代码块/静态域 -> 父类非静态代码块 -> 父类构造器 -> 子类非静态代码块 -> 子类构造器
反射中,Class.forName和ClassLoader区别
Class.forName和ClassLoader都可以对类进行加载。它们区别在哪里呢?
ClassLoader负责加载 Java 类的字节代码到 Java 虚拟机中。Class.forName其实是调用了ClassLoader,如下:
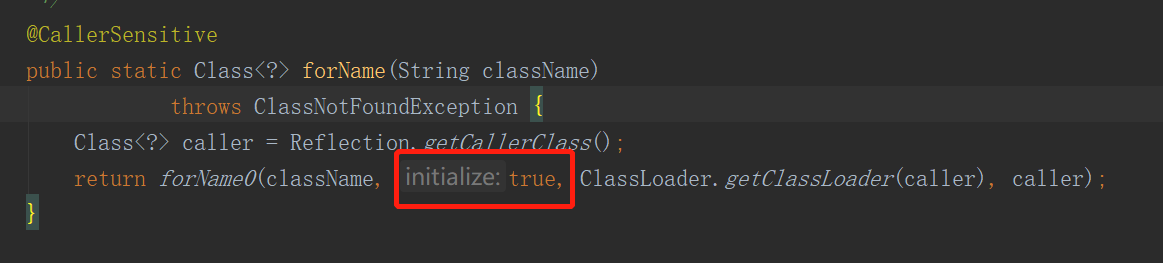
这里面,forName0的第二个参数为true,表示对加载的类进行初始化化。其实还可以调用Class<?> forName(String name, boolean initialize, ClassLoader loader)方法实现一样的功能,它的源码如下:
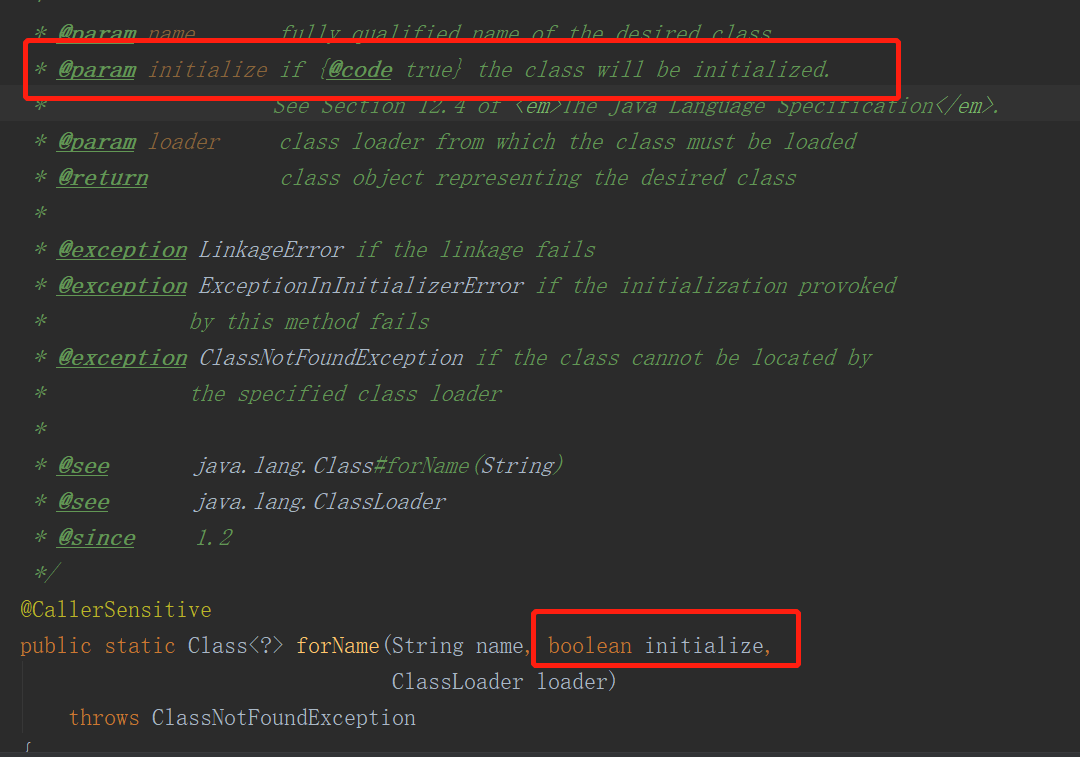
所以,Class.forName和ClassLoader的区别,就是在类加载的时候,class.forName有参数控制是否对类进行初始化。
JDK动态代理与cglib实现的区别
- java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
- cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
- JDK动态代理只能对实现了接口的类生成代理,而不能针对类
- cglib是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法。因为是继承,所以该类或方法最好不要声明成final
这篇文章写得不错,描述Java动态代理的几种实现方式,分别说出相应的优缺点
error和exception的区别,CheckedException,RuntimeException的区别。
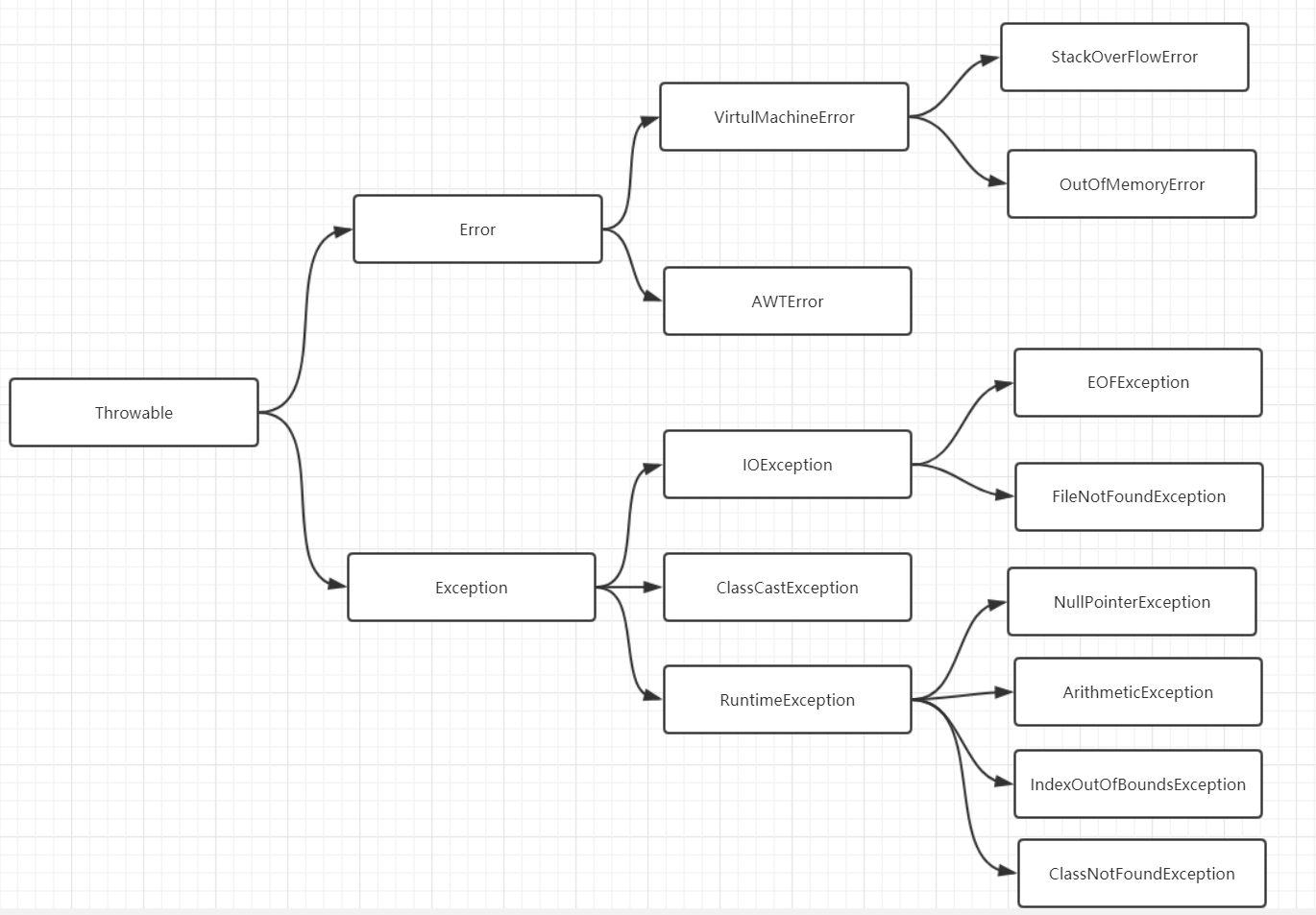
Error: 表示编译时或者系统错误,如虚拟机相关的错误,OutOfMemoryError等,error是无法处理的。
Exception: 代码异常,Java程序员关心的基类型通常是Exception。它能被程序本身可以处理,这也是它跟Error的区别。
它可以分为RuntimeException(运行时异常)和CheckedException(可检查的异常)。
常见的RuntimeException异常:
- NullPointerException 空指针异常
- ArithmeticException 出现异常的运算条件时,抛出此异常
- IndexOutOfBoundsException 数组索引越界异常
- ClassNotFoundException 找不到类异常
- IllegalArgumentException(非法参数异常)
常见的 Checked Exception 异常:
- IOException (操作输入流和输出流时可能出现的异常)
- ClassCastException(类型转换异常类)
有兴趣可以看我之前写得这篇文章:
Java程序员必备:异常的十个关键知识点
CAS机制是什么,如何解决ABA问题?
CAS涉及三个操作数
- 1.需要读写的内存地址V
- 2.进行比较的预期原值A
- 3.拟写入的新值B
如果内存位置的值V与预期原A值相匹配,那么处理器会自动将该位置值更新为新值B。
CAS思想:要进行更新时,认为位置V上的值还是跟A值相等,如果是是相等,就认为它没有被别的线程更改过,即可更新为B值。否则,认为它已经被别的线程修改过,不更新为B的值,返回当前位置V最新的值。
有兴趣的朋友可以看一下我这篇文章,一次CAS思想解决实际问题:
CAS乐观锁解决并发问题的一次实践
深拷贝和浅拷贝区别
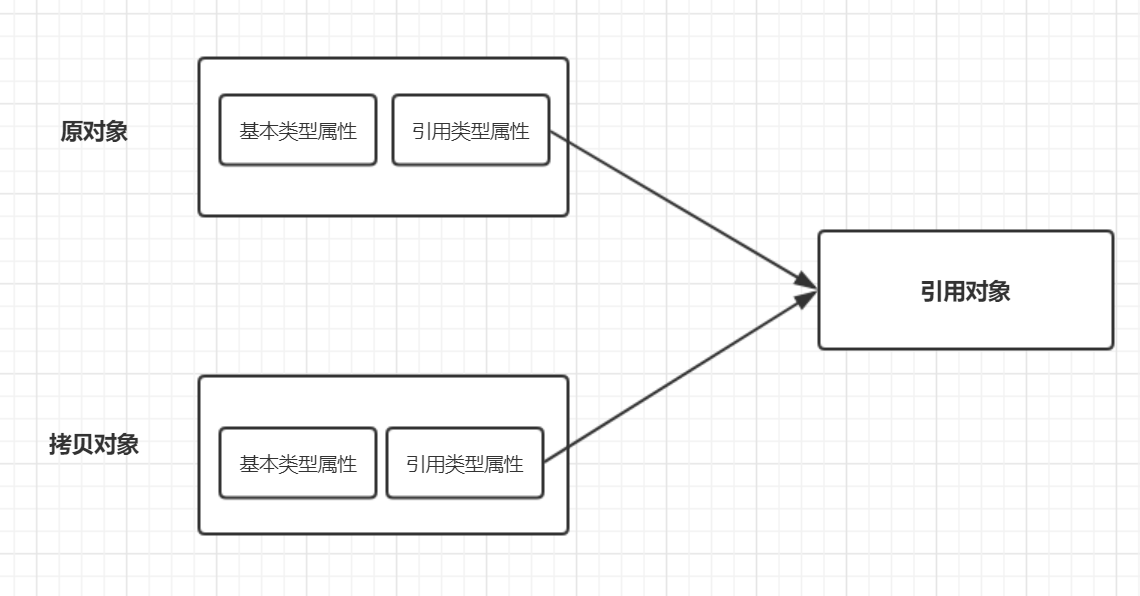
浅拷贝
复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化。
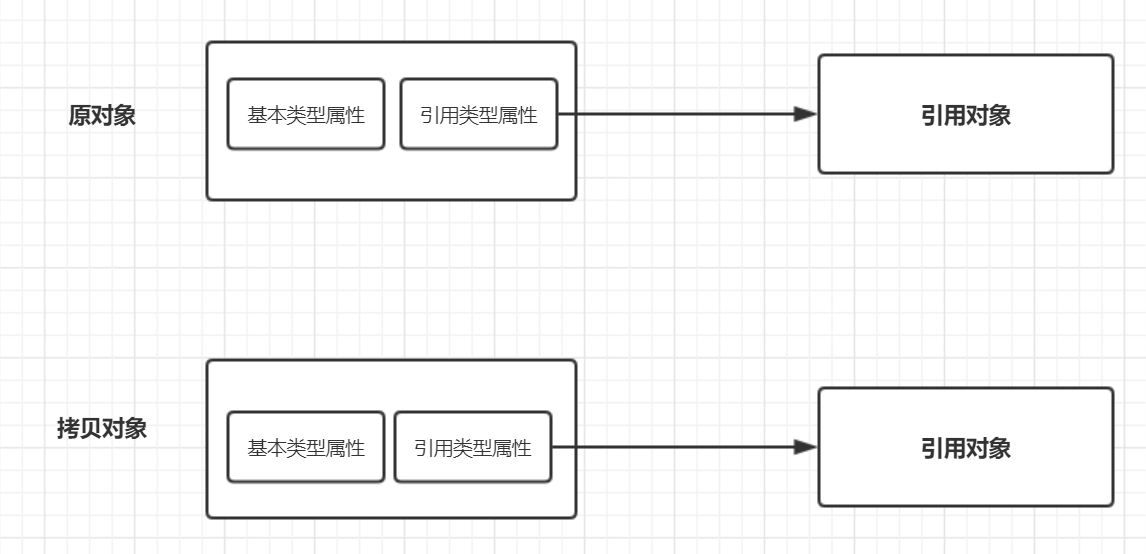
深拷贝
将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变
谈谈序列化与反序列化
- 序列化是指将对象转换为字节序列的过程,而反序列化则是将字节序列转换为对象的过程。
- Java对象序列化是将实现了Serializable接口的对象转换成一个字节序列,能够通过网络传输、文件存储等方式传输 ,传输过程中却不必担心数据在不同机器、不同环境下发生改变,也不必关心字节的顺序或其他任何细节,并能够在以后将这个字节序列完全恢复为原来的对象。
这篇文章写得很好:
Java Serializable:明明就一个空的接口嘛
==与equlas有什么区别?
==
- 如果是基本类型,==表示判断它们值是否相等;
- 如果是引用对象,==表示判断两个对象指向的内存地址是否相同。
equals
- 如果是字符串,表示判断字符串内容是否相同;
- 如果是object对象的方法,比较的也是引用的内存地址值;
- 如果自己的类重写equals方法,可以自定义两个对象是否相等。
谈谈AQS 原理以及AQS同步组件
AQS原理面试题的核心回答要点
- state 状态的维护。
- CLH队列
- ConditionObject通知
- 模板方法设计模式
- 独占与共享模式。
- 自定义同步器。
- AQS全家桶的一些延伸,如:ReentrantLock等。
可以看我这篇文章:AQS解析与实战
final、finalize()、finally的区别
- final是关键字,用于修饰类、成员变量和成员方法。
- Finalize是object类中的一个方法,子类可以重写finalize()方法实现对资源的回收。
- finally一般跟try一起,出现在异常处理代码块中
synchronized 底层如何实现?
可以看一下我这篇文章:
Synchronized解析——如果你愿意一层一层剥开我的心
Java线程池的原理?线程池有哪些?线程池工厂有哪些线程池类型,及其线程池参数是什么?
对于Java线程池,这个流程图比较重要:
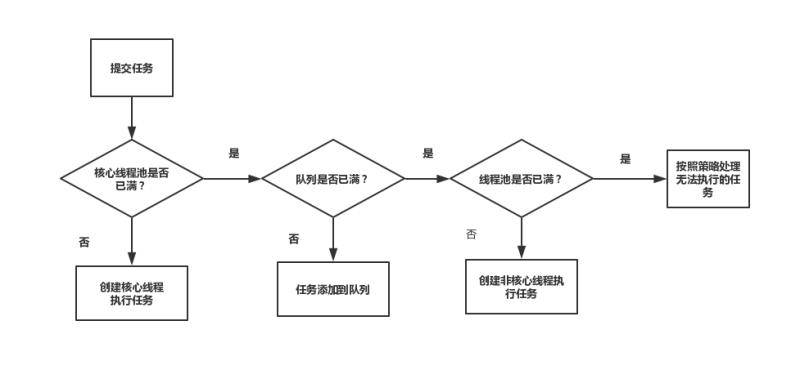
可以看我这篇文章:
面试必备:Java线程池解析
待更新
还有哪些经典Java面试题呢?你也可以告诉我,哈哈。
参考与感谢
- String和New String()的区别
- 老生常谈,HashMap的死循环
- Java核心(五)深入理解BIO、NIO、AIO
- 探讨一下实现幂等性的几种方式
- 在Java的反射中,Class.forName和ClassLoader的区别
- Java Serializable:明明就一个空的接口嘛
个人公众号

- 如果你是个爱学习的好孩子,可以关注我公众号,一起学习讨论。
- 如果你觉得本文有哪些不正确的地方,可以评论,也可以关注我公众号,私聊我,大家一起学习进步哈。
最后
以上就是犹豫帽子最近收集整理的关于常见Java面试题解析(基础篇,附答案)的全部内容,更多相关常见Java面试题解析(基础篇内容请搜索靠谱客的其他文章。








发表评论 取消回复