前言
选择的pivot会影响比较次数。为了进一步理解如何选pivot,我们从找出数组中第k小的数问题入手来理解。
例子:寻找第k小的元素
问题叙述
给定一个乱序数组A,试求该数组中第k小的元素?
最直接的解决办法就是数组排序返回index为k-1的元素,排序选用快排或归并(若不考虑内存使用),时间复杂度是O(nlogn)。
思考一下,实际上这个问题没有必要将数组完全排序再找第k个元素。
解决思路
参考快排的策略,我们可以有思路,将小于pivot的放到左边,大于pivot的放到右边。试想,如果有一个数左边的数(也就是比它小的数)的个数刚好是k-1,那么这个数就是我们要求的答案:第k小的元素。
这种方法只要求左边的数的个数是k-1,没有要求左边的数有序,减少许多冗余的比较排序操作。伪代码如下:
select(A,k):
S_l = [],S_r = [] // s_l存储小于pivot的值,s_r存储大于pivot的值
choose pivot A[p] // 随机选
for i = 0 to |A|-1:
if A[i] > A[p]:
put A[i] in S_r // 大放pivot右
else:
put A[i] in S_l // 小放pivot左
if |S_l| = k-1:
return A[p] // A[p]刚好是第k小元素
else if |S_l| > k-1:
return select(S_l,k) // 第k小元素落到了S_l集合中,递归查找
else:
return select(S_r,k-|S_l|-1) // 第k小元素落到了S_r集合中,k=k-|S_l|-1
与快排不同,此问题每次只做pivot一边的递归。上述算法的好坏取决于pivot的选择,由快排可知每次pivot的选择越靠近中心越好。
下面比较3种不同的pivot选择方法
随机选择
像普通快排中选择pivot一样随机选择一个元素作为pivot很暴力直接。每一次的选择导致的运行时间都不一致,但总体来说,可以证明是O(n)。
假设pivot的选择均匀划分了数组,例如1/2平分,因为每一次只需对一边递归,所以时间复杂度推导如下:
T ( n ) = T ( n 2 ) + c n = T ( n 4 ) + c n 2 + c n = . . . = c ( n + n 2 + n 4 + . . . + 1 ) = c ( 2 n − 1 ) = O ( n ) T(n) = T(frac{n}{2}) + cn\ = T(frac{n}{4}) + cfrac{n}{2}+ cn\ = ... \ =c(n+frac{n}{2} + frac{n}{4} + ...+ 1) \ =c(2n-1) = O(n) T(n)=T(2n)+cn=T(4n)+c2n+cn=...=c(n+2n+4n+...+1)=c(2n−1)=O(n)
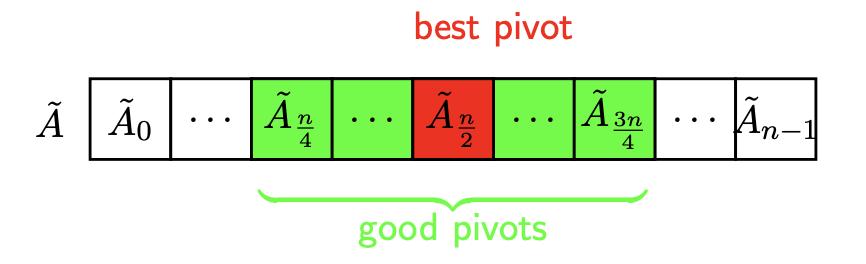
一般性,在较好情况下都能得到该时间复杂度(将[1/4,3/4]视为较好情况),因此我们考虑那些子实例大小在(3/4)^(j+1)n+1,j=0,1,2…此时称算法处于第j期。也就是直到选在了[1/4,3/4]内才算1期,概率论上讲50%的概率,平均2次就可以。
伪代码如下
QuickSelect(A, k)
Choose an element Ai from A uniformly at random;
S+ = {};
S− = {};
for all element Aj in A do
if Aj>Ai then
S+ = S+ ∪ {Aj};
else
S− = S− ∪ {Aj};
if |S−| = k − 1 then
return Ai ;
else if |S−|>k−1 then
return QuickSelect(S− , k);
else
return QuickSelect(S+ , k−|S−|−1);
随机采样,选中位数
选中好区间的可能性越大越好,因此我们通过采样然后寻找更好中位数。
pivot选取算法步骤
- 首先从数组A中随机地取r个元素,设为S
- 对S排序,令u为S中(1−δ)r/2小的元素,v为S中(1+δ)r/2小的元素
可以将u,v视为分位点,δ是一个调整参数
- 将数组A划分成三部分,如下
L = A i : A i < u ; M = A i : u ≤ A i ≤ v ; H = A i : A i > v ; L = {A_i:A_i < u};\ M = {A_i:u le A_i le v};\ H = {A_i:A_i > v}; L=Ai:Ai<u;M=Ai:u≤Ai≤v;H=Ai:Ai>v;
- 检查M是否满足以下条件:
∣ L ∣ ≤ n 2 且 ∣ H ∣ ≤ n 2 , 这 保 证 了 中 位 数 在 M 中 ∣ M ∣ ≤ c δ n , M 不 能 太 大 |L|le frac{n}{2} 且 |H|le frac{n}{2},这保证了中位数在M中\ |M|le cdelta n,M不能太大 ∣L∣≤2n且∣H∣≤2n,这保证了中位数在M中∣M∣≤cδn,M不能太大
如果不满足上述条件,则回到第一步
举例图示如下:
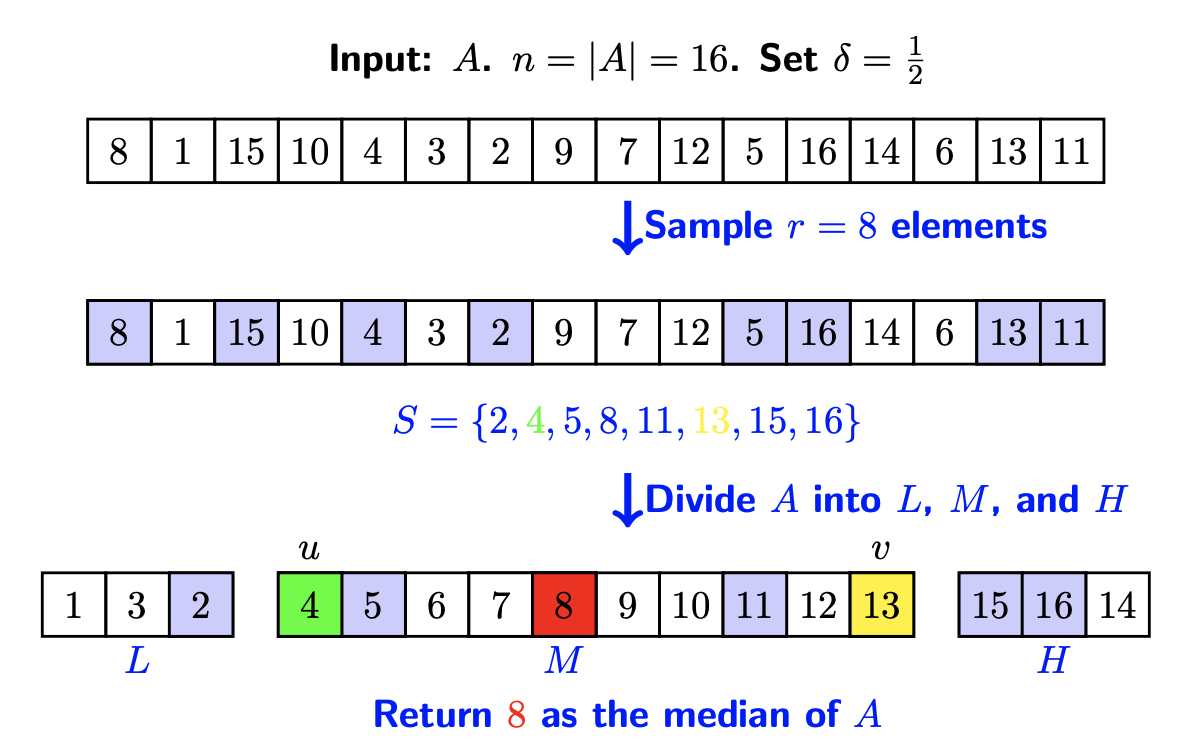
选到的pivot就是中位数,在划分的时候就能使得数据量呈指数级下降。接下来就是之前一样的select函数。
选择分组中位数的中位数
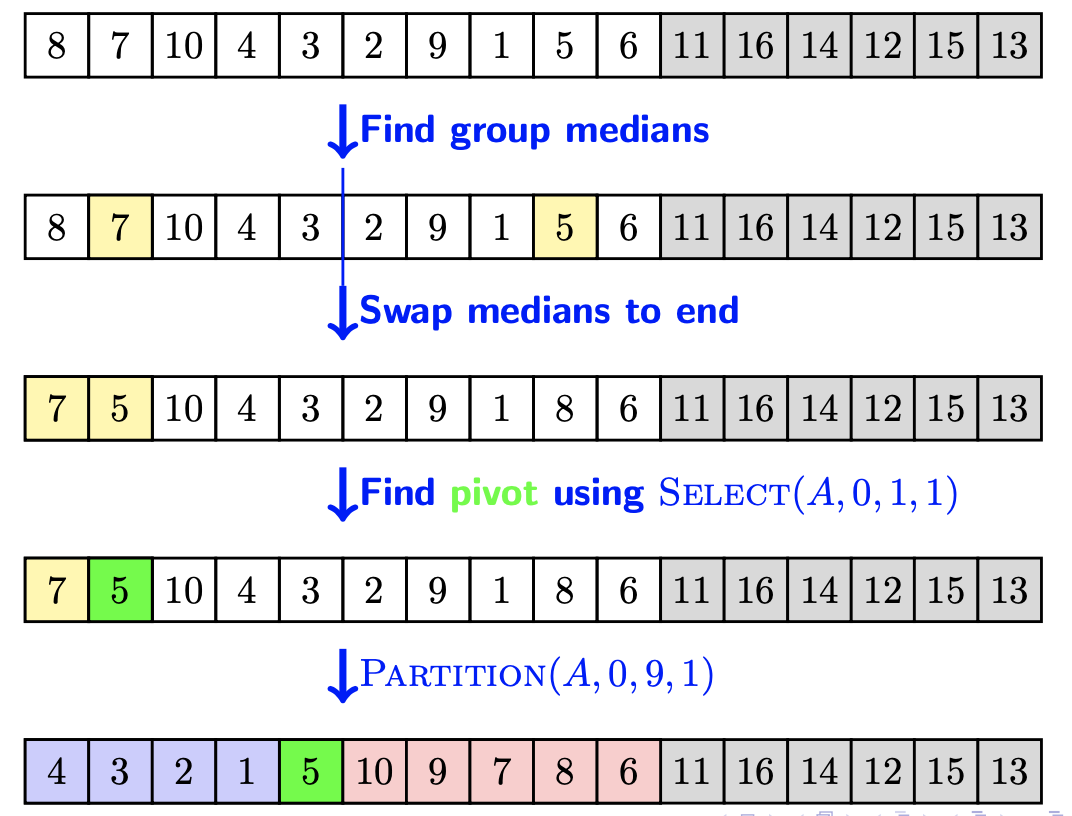
我们可以使用分组取中位数策略来尽量找到靠近中位数的数作为pivot,因为这样可以让划分更加均匀,时间复杂度更低。细节如下:
- 假设将数组所有元素按5个一组划分,一共n/5组
- 找出每一组的中位数,一共耗费6n/5时间
5个元素只需要6次比较就能找到中位数,过程可以参考这篇文章
3、递归寻找这些中位数的中位数(记为M),耗费T(n/5)
4、基于M将A划分成S_l 和 S_rS ,耗费O(n)时间
5、采用一开始的递归查找步骤
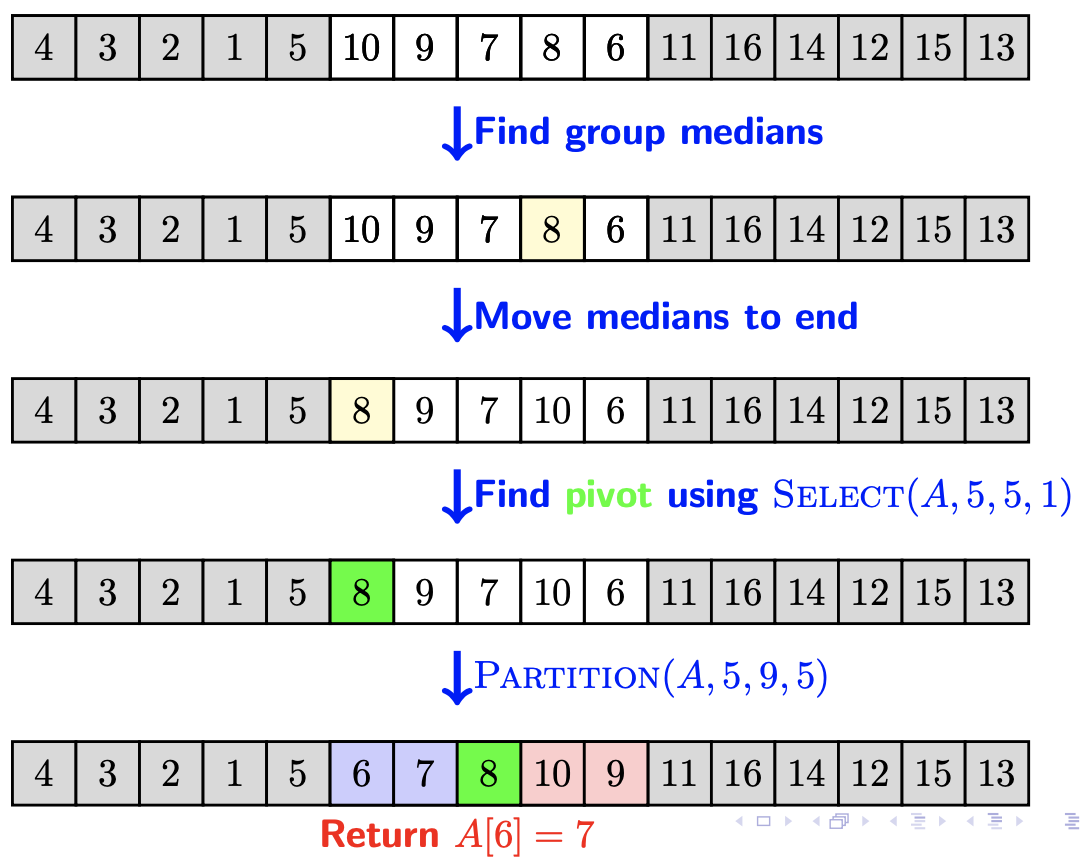
if |S_l| = k-1:
return M // M刚好是第k小元素
else if |S_l| > k-1:
return select(S_l,k) // 时间复杂度最多T(7n/10)
else:
return select(S_r,k-|S_l|-1) // 时间复杂度最多T(7n/10)
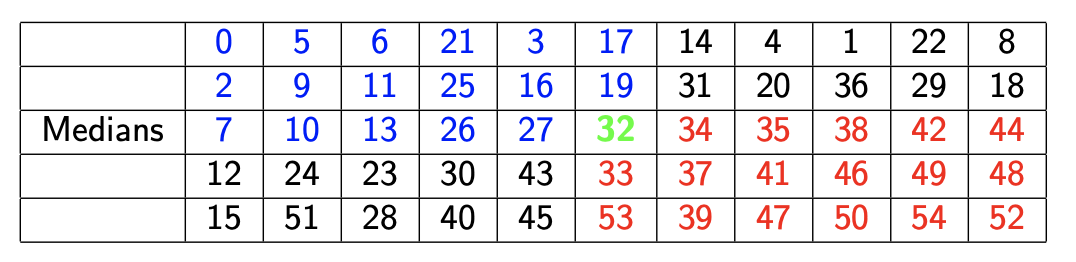
可以发现,依据这种方法找到M很接近实际中位数。且知道蓝色的区域一定小于M,红色的区域一定大于M,这两个区域的数量各占3/10n,那么我们如果用M作为pivot划分,至少可以分出3/10n的数据,所以下一步递归最多还需要处理7n/10的数据。
时间复杂度如下:
T ( n ) ≤ T ( n 5 ) + T ( 7 10 n ) + c n , c = 6 5 T(n)le T(frac{n}{5}) + T(frac{7}{10}n) + cn,c=frac{6}{5} T(n)≤T(5n)+T(107n)+cn,c=56
T
(
n
)
≤
T
(
n
5
)
+
T
(
7
10
n
)
+
c
n
≤
T
(
n
25
)
+
T
(
7
50
n
)
+
T
(
7
50
n
)
+
T
(
49
100
n
)
+
c
9
10
n
+
c
n
≤
.
.
.
≤
c
n
+
c
9
10
n
+
c
(
9
10
)
2
n
+
.
.
.
=
c
n
(
1
−
(
9
10
)
i
1
−
9
10
)
=
O
(
n
)
T(n) le T(frac{n}{5})+T(frac{7}{10}n)+cn \ le T(frac{n}{25})+T(frac{7}{50}n)+T(frac{7}{50}n)+T(frac{49}{100}n)+cfrac{9}{10}n+cn\ le...\ le cn+cfrac{9}{10}n+c(frac{9}{10})^2n+...\ = cn(frac{1-(frac{9}{10})^i}{1-frac{9}{10}})\ =O(n)
T(n)≤T(5n)+T(107n)+cn≤T(25n)+T(507n)+T(507n)+T(10049n)+c109n+cn≤...≤cn+c109n+c(109)2n+...=cn(1−1091−(109)i)=O(n)
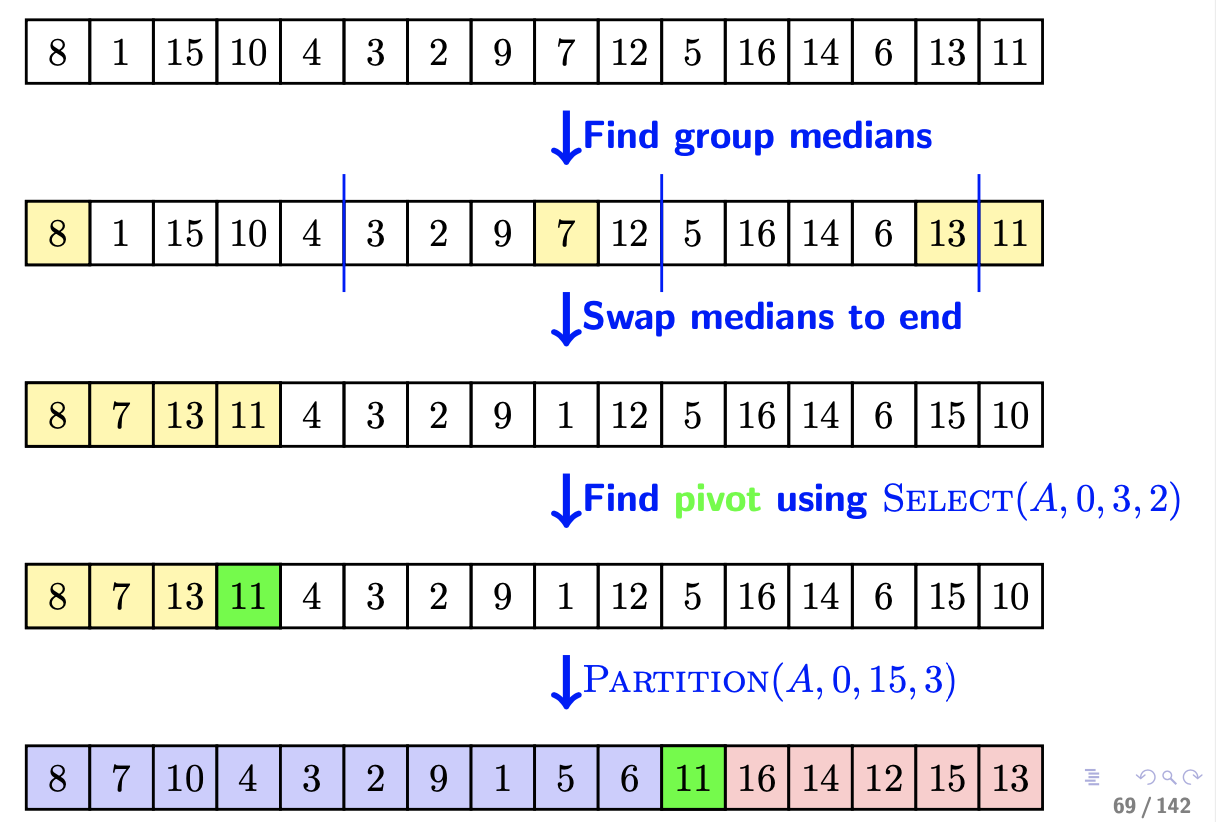
- 为什么分成5个一组?
假如3个一组,则时间复杂度:
T ( n ) ≤ T ( n 3 ) + T ( 2 3 n ) + O ( n ) = O ( n l o g n ) T(n) le T(frac{n}{3})+T(frac{2}{3}n)+O(n) = O(nlogn) T(n)≤T(3n)+T(32n)+O(n)=O(nlogn)
假如我们要找的数很接近中间,例如在55个数中找第28小,下一次递归我们就是找(0-31)中第28小,但这个时候按照中位数的原则,我们选中的pivot往往是15左右的数,发现与28相距甚远。这就使得我们需要递归几次来逼近28。也就是说此轮的要找的数如果很接近中间,则下轮的数会比较偏靠边。基于此,有人提出了优化算法如下:
- α−β算法
首先回顾一下上述算法的简要步骤:
- 将A分成若干块,组成集合G,G中每个块长度要求大于3(因为前面证明了3会导致时间复杂度提升)
- 取G中每个块的中位数,构成集合M
- 选择M的中位数作为pivot
- …
引理:若α=k/n=1/2,设下一次迭代需要找第 k′ 小的数,α′=k′/n,则必然有α′≤1/4或α′≥3/4 ,简言之,就是如果要找的数k靠近中位数,那么下一次迭代中要找的数k′必然靠近数组的边缘。
将改进算法的算法简要步骤整理如下:
- 将A分成若干块,组成集合G,G中每个块长度要求大于3(因为前面证明了3会导致时间复杂度提升)
- 取G中每个块的中位数,构成集合M
- 依据要找的第k小数在n中的位置α(α=k/n),去求我们要返回的pivot在M中的位置β(β由α决定)
- …
α ≤ 1 4 + λ → β = 3 2 α , 目 标 在 左 半 部 分 α ≥ 3 4 − λ → β = 3 2 α − 1 2 , 目 标 在 右 半 部 分 1 4 + λ < α < 3 4 − λ → β = α , 目 标 在 中 间 alpha le frac{1}{4} + lambda to beta = frac{3}{2}alpha,目标在左半部分\ alpha ge frac{3}{4} - lambda to beta = frac{3}{2}alpha - frac{1}{2},目标在右半部分\ frac{1}{4} + lambda lt alpha lt frac{3}{4} - lambda to beta = alpha,目标在中间\ α≤41+λ→β=23α,目标在左半部分α≥43−λ→β=23α−21,目标在右半部分41+λ<α<43−λ→β=α,目标在中间
总结
- 将算法中的常数改为可调参数,然后寻找调整参数的策略,来优化算法
- 手动模拟算法的运行过程,发现规律
最后
以上就是无奈蓝天最近收集整理的关于分治思想-选pivot问题的全部内容,更多相关分治思想-选pivot问题内容请搜索靠谱客的其他文章。








发表评论 取消回复