目录
- 排序的基本概念
- 排序的定义
- 排序的稳定性
- 内排序和外排序
- 基于比较的排序算法的性能
- 插入排序
- 直接插入排序(straight insertion sort)
- 代码实现(不使用“哨兵”)
- 代码实现(使用“哨兵”)
- 运行结果
- 程序分析
- 折半插入排序(binary insertion sort)
- 代码实现(不使用“哨兵”)
- 代码实现(使用“哨兵”)
- 运行结果
- 程序分析
- 希尔排序(shell sort)
- 代码实现(不使用“哨兵”)
- 运行结果
- 程序分析
数据结构-排序(第十章)的整理笔记,若有错误,欢迎指正。
排 序 { 基 本 概 念 { 稳 定 性 衡 量 标 准 : 时 间 复 杂 度 、 空 间 复 杂 度 内 部 排 序 { 插 入 排 序 { 直 接 插 入 排 序 折 半 插 入 排 序 希 尔 排 序 交 换 排 序 { 冒 泡 排 序 快 速 排 序 选 择 排 序 { 简 单 快 速 排 序 堆 排 序 归 并 排 序 基 数 排 序 外 部 排 序 — — 多 路 归 并 排 序 排序begin{cases} 基本概念 begin{cases} 稳定性\ 衡量标准:时间复杂度、空间复杂度 end{cases} \ 内部排序 begin{cases} 插入排序 begin{cases} 直接插入排序\ 折半插入排序\ 希尔排序\ end{cases} \ 交换排序 begin{cases} 冒泡排序\ 快速排序\ end{cases} \ 选择排序 begin{cases} 简单快速排序\ 堆排序\ end{cases} \ 归并排序 \ 基数排序 \ end{cases} \ 外部排序——多路归并排序 \ end{cases} 排序⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧基本概念{稳定性衡量标准:时间复杂度、空间复杂度内部排序⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧插入排序⎩⎪⎨⎪⎧直接插入排序折半插入排序希尔排序交换排序{冒泡排序快速排序选择排序{简单快速排序堆排序归并排序基数排序外部排序——多路归并排序
排序的基本概念
- 假设被排序的数据是由一组元素组成的表,而元素由若干个数据项组成,其中指定一个数据项为关键字,关键字用作排序运算的依据。不同于查找,这里的关键字是可以重复的,也就是说,在排序表中可能存在关键字相同的两个或者多个元素。
- 对于任意序列进行基于比较的排序,求最少的比较次数应考虑最坏的情况。对任意n个关键字排序的比较次数至少为 ⌈ l o g 2 n ! ⌉ ⌈log_2^{n!}⌉ ⌈log2n!⌉。
- 待排序的顺序表中数据元素的类型声明如下:
typedef int KeyType; //定义关键字类型为int
typedef struct //元素类型
{
KeyType key; //关键字项
InfoType data; //其他数据项,类型为InfoType
}RecType; //排序元素的类型
排序的定义
- 排序(sort),就是重新排列表中的元素,使表中的元素满足按关键字有序的过程。为了查找方便,通常希望计算机中的表是按关键字有序的。排序的确切定义如下:
输入:n个记录 R 1 , R 2 , … , R n R_1,R_2,…,R_n R1,R2,…,Rn,对应的关键字为 k 1 , k 2 , . . . , k n k_1,k_2,...,k_n k1,k2,...,kn。
输出:输入序列的一个重排 R 1 ′ , R 2 ′ , … , R n ′ R_1',R_2',…,R_n' R1′,R2′,…,Rn′,使得 k 1 ′ ≤ k 2 ′ ≤ , … , ≤ k n ′ k_1'≤k_2'≤,…,≤k_n' k1′≤k2′≤,…,≤kn′(其中“≤”可以换成其他的比较大小的符号)。
排序的稳定性
- 若待排序表中有两个元素
R
i
R_i
Ri和
R
j
R_j
Rj,其对应的关键字相同,即
k
e
y
i
=
k
e
y
j
key_i=key_j
keyi=keyj,且在排序前
R
i
R_i
Ri在
R
j
R_j
Rj的前面,若使用某一排序算法排序后,
R
i
R_i
Ri仍然在
R
j
R_j
Rj的前面,则称这个排序算法是稳定的(stable),否则称排序算法是不稳定的(unstable)。
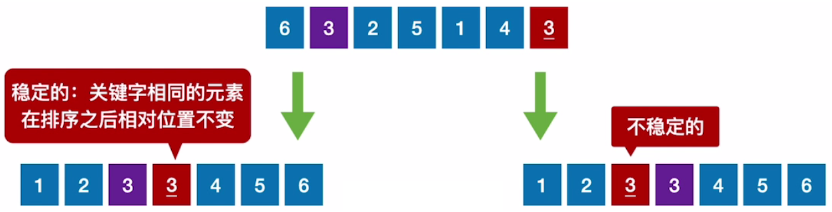
- 需要注意的是,算法是否具有稳定性并不能衡量一个算法的优劣,它主要是对算法的性质进行描述。如果待排序表中的关键字不允许重复,则排序结果是唯一的,那么选择排序算法时的稳定与否就无关紧要。
内排序和外排序
- 在排序过程中,根据数据元素是否完全在内存中,可将排序算法分为两类:
①内部排序(internal sort),是指在排序期间元素全部存放在内存中的排序;
②外部排序(external sort),是指在排序期间元素无法全部同时存放在内存中,必须在排序的过程中根据要求不断地在内、外存之间移动的排序。 - 内排序适用于元素个数不是很多的小表,外排序则适用于元素个数很多,不能一次将其全部元素放入内存的大表。内排序是外排序的基础。
- 按所用的策略不同,内排序方法可以分为需要关键字比较和不需要关键字比较两类。需要关键字比较的排序方法有插入排序、选择排序、交换排序和归并排序等;不需要关键字比较的排序方法有基数排序等。
基于比较的排序算法的性能
- 一般情况下,基于比较的算法在执行过程中都要进行两种操作:比较(compare)和移动(move)。通过比较两个关键字的大小,确定对应元素的前后关系,然后通过移动元素以达到有序。当然,并非所有的内部排序算法都要基于比较操作,事实上,基数排序就不基于比较。
- 每种排序算法都有各自的优缺点,适合在不同的环境下使用,就其全面性能而言,很难提出一种被认为是最好的算法。内部排序算法的性能取决于算法的时间复杂度和空间复杂度,而时间复杂度一般是由比较和移动的次数决定的。
插入排序
- 插入排序是一种简单直观的排序方法,其基本思想是每次将一个待排序的记录按其关键字大小插入前面已排好序的子序列,直到全部记录插入完成。由插入排序的思想可以引申出三个重要的排序算法:直接插入排序、折半插入排序和希尔排序。
直接插入排序(straight insertion sort)
- 假设待排序的元素存放在数组R[0…n-1]中,在排序过程的某一中间时刻,R被划分成两个子区间R[0…i-1]和R[i…n-1],其中前一个子区间是已排好序的有序区(ordered region),后一个子区间则是当前未排序的部分,称其为无序区(disordered region),初始时i=1,有序区只有R[0]一个元素。
- 直接插入排序的一趟操作是将当前无序区的开头元素 R [ i ] ( 1 ≤ i ≤ n − 1 ) R[i](1≤i≤n-1) R[i](1≤i≤n−1)插入到有序区R[0…i-1]中的适当位置,使R[0…i]变为新的有序区。这种方法通常称为增量法,因为它每次使有序区增加一个元素。
- 说明:直接插入排序每趟产生的有序区不一定是全局有序区,也就是说有序区中的元素不一定放在最终的位置上。当一个元素在整个排序前就已经放在其最终位置上称为归位(homing)

代码实现(不使用“哨兵”)
#include<stdio.h>
#define MaxSize 100
void Input(int a[], int num)
{
int data;
printf("输入数据元素:");
for (int i = 0; i < num; i++)
{
scanf("%d", &data);
a[i] = data;
}
}
void InsertSort(int a[],int num) //直接插入排序
{
int temp, i, j;
for (i = 1; i < num; i++) //将各元素插入到已排好序的序列
{
if (a[i] < a[i - 1]) //若a[i]关键字小于前驱
{
temp = a[i]; //用temp暂存a[i]
for (j = i - 1; j >= 0 && a[j] > temp; j--) //检查前面所有已排好序的元素
a[j + 1] = a[j]; //所有大于temp的元素都向后挪位
a[j + 1] = temp; //复制到插入位置
}
}
}
void Print(int a[], int num)
{
for (int i = 0; i < num; i++)
printf("%d ", a[i]);
}
int main()
{
int a[MaxSize] = { 0 };
int num;
printf("输入要创建的数组长度:");
scanf("%d", &num);
Input(a, num);
InsertSort(a, num);
printf("输出从小到大的排序结果:");
Print(a, num);
return 0;
}
代码实现(使用“哨兵”)
- 优点:不用每轮循环都判断j>=0
#include<stdio.h>
#define MaxSize 100
void Input(int a[], int num)
{
int data;
printf("输入数据元素:");
for (int i = 1; i <= num; i++)
{
scanf("%d", &data);
a[i] = data;
}
}
void InsertSort(int a[],int num) //直接插入排序
{
int i, j;
for (i = 2; i <= num; i++) //依次将a[2]~a[n]插入前面已排序序列
{
if (a[i] < a[i - 1]) //若a[i]关键字小于前驱,将a[i]插入有序表
{
a[0] = a[i]; //复制为哨兵,a[0]不存放元素
for (j = i - 1; a[0] < a[j]; j--) //从后往前查找待插入位置
a[j + 1] = a[j]; //向后挪位
a[j + 1] = a[0]; //复制到插入位置
}
}
}
void Print(int a[], int num)
{
for (int i = 1; i <= num; i++)
printf("%d ", a[i]);
}
int main()
{
int a[MaxSize] = { 0 };
int num;
printf("输入要创建的数组长度:");
scanf("%d", &num);
Input(a, num);
InsertSort(a, num);
printf("输出从小到大的排序结果:");
Print(a, num);
return 0;
}
运行结果

程序分析
- 直接插入排序算法的性能分析如下:
- 空间效率:只使用i、j和temp这3个辅助变量,与问题规模n无关,故空间复杂度为O(1),也就是说,它是一个就地排序算法。
- 时间效率:在排序过程中,向有序子表中逐个地插入元素的操作进行了n-1趟,每趟操作都分为比较关键字和移动元素,而比较次数和移动次数取决于待排序表的初始状态。
在最好情况下,表中元素已经有序,此时每插入一个元素,都只需比较一次而不用移动元素,总的比较次数达到最小,为n-1。因而时间复杂度为O(n);在最坏情况下,表中元素顺序刚好与排序结果中的元素顺序相反(逆序),总的比较次数达到最大,为 ∑ i = 1 n − 1 i = n ( n − 1 ) 2 sum_{i=1}^{n-1}i=frac{n(n-1)}2 ∑i=1n−1i=2n(n−1),总的移动次数也达到最大,为 ∑ i = 1 n − 1 ( i + 2 ) = ( n − 1 ) ( n − 4 ) 2 sum_{i=1}^{n-1}(i+2)=frac{(n-1)(n-4)}{2} ∑i=1n−1(i+2)=2(n−1)(n−4),时间复杂度为 O ( n 2 ) O(n^2) O(n2);平均情况下,考虑待排序表中元素是随机的,此时可以取上述最好与最坏情况的平均值作为平均情况下的时间复杂度,总的比较次数与总的移动次数均约为 n 2 4 frac{n^2}4 4n2。因此,直接插入排序算法的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 稳定性:由于每次插入元素时总是从后向前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是一个稳定的排序方法。
- 适用性:直接插入排序算法适用于顺序存储和链式存储的线性表。为链式存储时,可以从前往后查找指定元素的位置。
- !注意:大部分排序算法都仅适用于顺序存储的线性表。

折半插入排序(binary insertion sort)
- 直接插入排序中将无序区的开头元素 R [ i ] ( 1 ≤ i ≤ n − 1 ) R[i](1≤i≤n-1) R[i](1≤i≤n−1)插入到有序区R[0…i-1]是采用顺序比较的方法。由于有序区的元素是有序的,可以采用折半查找方法先在R[0…i-1]中找到插入位置,再通过移动元素进行插入,这样的插入排序称为折半插入排序或二分插入排序。
- 第i趟在R[Iow…high](初始时low=0,high=i-1)中采用折半查找方法查找插入R的位置为R[right+1],再将R[right+1…i-1]元素后移一个位置,并置R[right+1]=R[i]。
- 说明:和直接插入排序一样,折半插入排序每趟产生的有序区并不一定是全局有序区。
代码实现(不使用“哨兵”)
void BinInsertSort(int a[], int num) //折半插入排序
{
int temp, i, j, low, high, mid;
for (i = 1; i < num; i++) //将各元素插入到已排好序的序列
{
if (a[i - 1] > a[i]) //初始数据正序时移动次数为零
{
temp = a[i]; //依次将a[2]~a[n]插入前面已排序序列
low = 0; //设置折半查找范围
high = i - 1;
while (low <= high) //折半查找(默认递增有序)
{
mid = (low + high) / 2; //取中间点
if (a[mid] > temp) high = mid - 1; //查找左子表
else low = mid + 1; //查找右子表
}
for (j = i - 1; j >= high + 1; j--) a[j + 1] = a[j]; //统一后移元素,空出插入位置
a[high + 1] = temp; //插入操作
}
}
}
代码实现(使用“哨兵”)
void BinInsertSort(int a[],int num) //折半插入排序
{
int i, j, low, high, mid;
for (i = 2; i <= num; i++) //将各元素插入到已排好序的序列
{
a[0] = a[i]; //依次将a[2]~a[n]插入前面已排序序列
low = 1; //设置折半查找范围
high = i - 1;
while (low <= high) //折半查找(默认递增有序)
{
mid = (low + high) / 2; //取中间点
if (a[mid] > a[0]) high = mid - 1; //查找左子表
else low = mid + 1; //查找右子表
}
for (j = i - 1; j >= high + 1; j--) a[j + 1] = a[j]; //统一后移元素,空出插入位置
a[high + 1] = a[0]; //插入操作
}
}
运行结果

程序分析
- 折半插入排序仅减少了比较元素的次数,平均比较次数约为 l o g 2 i + 1 − 1 log_2^{i+1}-1 log2i+1−1,该比较次数与待排序表的初始状态无关,仅取决于表中的元素个数n;而元素的移动次数并未改变,它依赖于待排序表的初始状态;平均移动元素的次数为 i 2 + 2 frac i2+2 2i+2。
- 空间效率:只使用i、j、low、high和mid这5个辅助变量,与问题规模n无关,故空间复杂度为O(1),也就是说,它也是一个就地排序算法。
- 时间效率:折半插入排序的时间复杂度仍为 O ( n ² ) O(n²) O(n²)。
- 适用性:对于数据量不是很大的排序表,折半插入排序往往能表现出很好的性能。
- 稳定性:折半插入排序是一种稳定的排序方法。
希尔排序(shell sort)
- 从前面的分析可知,直接插入排序算法的时间复杂度为 O ( n 2 ) O(n^2) O(n2),但若待排序列为“正序”时,其时间复杂度可提高至 O ( n ) O(n) O(n),由此可见它更适用于基本有序的排序表和数据量不大的排序表。希尔排序正是基于这两点分析对直接插入排序进行改进而得来的,又称缩小增量排序,实际上是一种分组插入方法。
- 希尔排序的基本思想是:先将待排序表分割成若干形如 L [ i , i + d , i + 2 d , . . . , i + k d ] L[i,i+d,i+2d,...,i+kd] L[i,i+d,i+2d,...,i+kd]的“特殊”子表,即把相隔某个“增量”的记录组成一个子表,对各个子表分别进行直接插入排序,当整个表中的元素已呈“基本有序”时,再对全体记录进行一次直接插入排序。
- 希尔排序的过程如下:先取一个小于n的步长
d
1
d_1
d1,把表中的全部记录分成
d
1
d_1
d1组,所有距离为
d
1
d_1
d1的倍数的记录放在同一组,在各组内进行直接插入排序;然后取第二个步长
d
2
<
d
1
d_2<d_1
d2<d1,重复上述过程,直到所取到的
d
t
=
1
d_t=1
dt=1,即所有记录已放在同一组中,再进行直接插入排序,由于此时已经具有较好的局部有序性,故可以很快得到最终结果。到目前为止,尚末求得一个最好的增量序列,希尔提出的方法是
d
1
=
n
2
,
d
i
+
1
=
⌊
d
i
2
⌋
d_1=frac n2,d_{i+1}=⌊frac{d_i}2⌋
d1=2n,di+1=⌊2di⌋,并且最后一个增量等于1。

代码实现(不使用“哨兵”)
void InsertSort(int a[], int num)
{
int temp, i, j, d;
for (d = num / 2; d >= 1; d = d / 2) //步长变化
for (i = d; i < num; i++)
if (a[i] < a[i - d]) //需将a[i]插入到有序增量子表
{
temp = a[i];
for (j = i - d; j >= 0 && temp < a[j]; j = j - d)
a[j + d] = a[j]; //记录后移,查找插入的位置
a[j + d] = temp;
}
}
运行结果

程序分析
- 希尔排序算法的性能分析如下:
- 空间效率:仅使用了常数个辅助单元,因而空间复杂度为O(1)。
- 时间效率:由于希尔排序的时间复杂度依赖于增量序列的函数,这涉及数学上尚未解决的难题,所以其时间复杂度分析比较困难。当n在某个特定范围时,希尔排序的时间复杂度约为 O ( n 1.3 ) O(n^{1.3}) O(n1.3)。当增量d初始就取1时,希尔排序退化为直接插入排序,在最坏情况下希尔排序的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 稳定性:当相同关键字的记录被划分到不同的子表时,可能会改变它们之间的相对次序,因此希尔排序是一种不稳定的排序方法。
- 适用性:希尔排序算法仅适用于线性表为顺序存储的情况。
最后
以上就是无情跳跳糖最近收集整理的关于数据结构—排序(Part Ⅰ)—直接插入/折半插入/希尔排序排序的基本概念插入排序的全部内容,更多相关数据结构—排序(Part内容请搜索靠谱客的其他文章。








发表评论 取消回复