前言
放假期间,突然接到老板电话,说系统出现了数据丢失问题,犹如晴天霹雳,内心慌得一批已经准备卷铺盖回家。
今天主要给大家分享mysql数据库出现数据丢失的几个场景以及解决数据丢失问题的相应手段,让大家以后心里有谱,放假不慌。
一、事务级数据丢失
说明:
1、批量操作数据时,由于没有添加事务控制,出现事务回滚时,出现部分数据操作成功,部分数据操作失败的问题。
2、事务提交成功到数据还没有刷写到磁盘,出现数据库宕机导致的数据丢失
范围: 事务级
严重级别: 低
处理手段:
- 添加事务控制
- 开启redo log、undo log
- 采用强一致日志刷写策略
1、开启事务控制
示例:批量保存用户信息
@Override
@Transactional(rollbackFor = {Exception.class})
public boolean saveBatch(Collection<User> entityList, int batchSize) {
try {
int size = entityList.size();
int idxLimit = Math.min(batchSize, size);
int i = 1;
//保存单批提交的数据集合
List<User> oneBatchList = new ArrayList<>();
for(Iterator<User> var7 = entityList.iterator(); var7.hasNext(); ++i) {
User element = var7.next();
oneBatchList.add(element);
if (i == idxLimit) {
userMapper.insertBatchSomeColumn(oneBatchList);
//每次提交后需要清空集合数据
oneBatchList.clear();
idxLimit = Math.min(idxLimit + batchSize, size);
}
}
}catch (Exception e){
log.error("saveBatch fail",e);
return false;
}
return true;
}
2、开启redo log、undo log
mysql中只有InnoDB引擎支持事务,而事务机制的实现离不开redo log和undo log。
默认情况下都是开启的,不需要主动调整。但如果出现事务级别的数据丢失,就需要检查相关配置。
- redo log:重做日志
- undo log:回滚日志
Redo Log(重做日志)是MySQL中非常重要的日志模块。
官方解释:重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间纠正不完整事务写入的数据。
在正常操作期间,重做日志对由SQL语句或低级API调用产生的更改表数据的请求进行编码。在初始化期间和接受连接之前,会自动重播在意外关闭之前未完成更新数据文件的修改).
MySQL里经常说到的WAL技术(WAL的全称是Write-Ahead Logging),它的关键点就是日志先行(也称为写前日志,实际写数据之前,先把修改的数据记录到日志文之间中。即先写日志,再写磁盘),其实很多数据库软件设计的理念都是日志先行。(但是Redis的AOF(Append Only File)日志正好相反,它是写后日志,“写后”的意思是Redis的先执行命令,把数据写入内存,然后才记录日志),MySQL中日志先行的这个“日志”就是Redo Log。
Redo Log是InnoDB引擎特有的日志,而MySQL Server层也有自己的日志,称为binlog(不在我们本文的讨论范围,下一章我们就会见到它了,拭目以待吧)。正是因为有了Redo Log,才保证了InnoDB存储引擎的Crash-safe能力。
Redo Log是物理日志,记录的是“在某个数据页上做了什么修改(做了什么改动)”。一句话概括一下,Redo Log是为了保证已提交事务的ACID特性,同时能够提高数据库性能的技术。
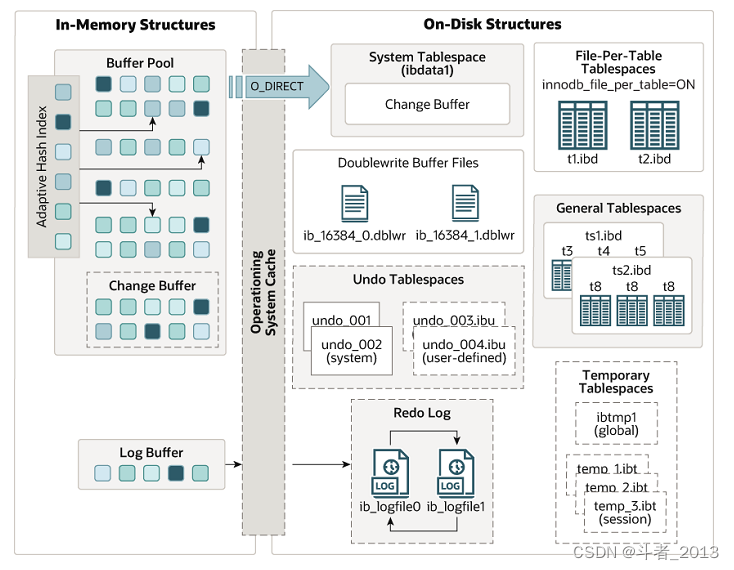
3、Redo log刷写策略
我们都知道,数据只有刷写到磁盘中才是最安全的,redo log从内存到刷写到磁盘经历了三层结构。
Redo Log的三层结构:
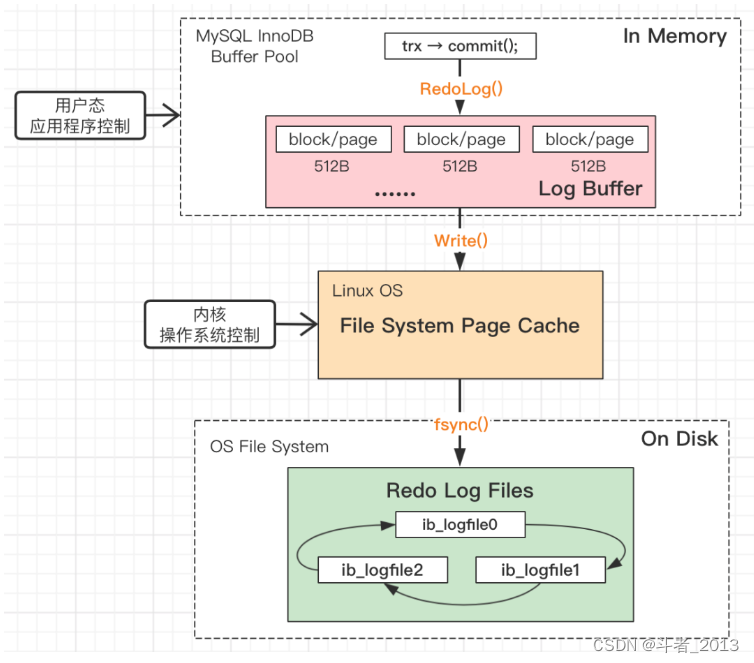
简单来说一下Redo Log的三层结构:
- 粉色部分:是InnoDB一项很重要的内存结构(In-Memory Structure),即我们的Log Buffer(日志缓冲区),这一层,是MySQL应用程序用户态控制。
- 黄色部分:操作系统文件系统的缓冲区(FS Page Cache),这一层,是操作系统OS内核态控制。
- 绿色部分:就是落盘的物理日志文件。
Redo Log刷写时机:
Redo log目前有三种刷写策略,即对应可设置的值可以是0、1或2。
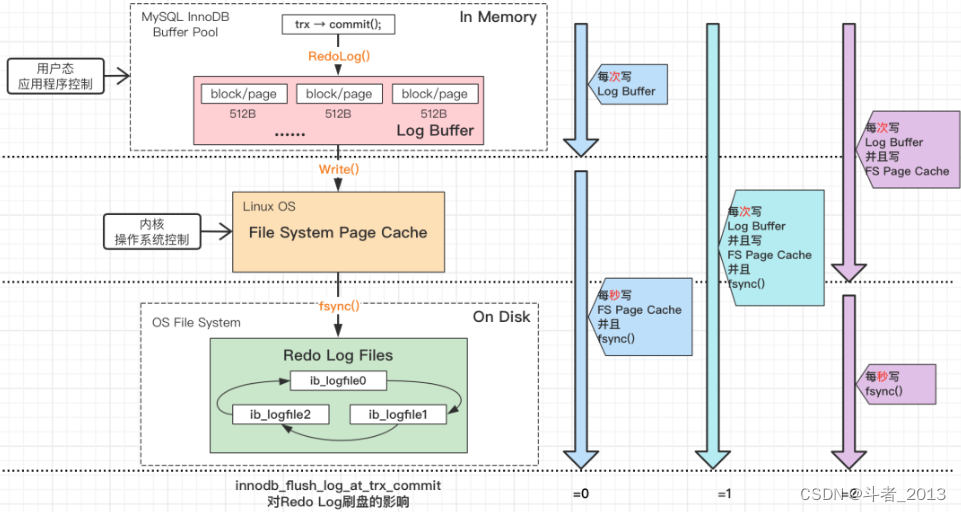
- 策略一:
最佳性能(innodb_flush_log_at_trx_commit=0)
处理过程:每隔一秒,才将Log Buffer中的数据批量write入FS Page Cache,同时MySQL主动fsync。
缺点:这种策略,如果数据库奔溃,有一秒的数据丢失。 - 策略二:
强一致(innodb_flush_log_at_trx_commit=1)
处理过程:每次事务提交,都将Log Buffer中的数据write入FS Page Cache,同时MySQL主动fsync。这种策略,是InnoDB的默认配置,为的是保证事务ACID特性。
缺点:这种策略,性能较其余两种策略较差。 - 策略三:
折衷(innodb_flush_log_at_trx_commit=2)
处理过程:每次事务提交,都将Log Buffer中的数据write入FS Page Cache;每隔一秒,MySQL主动将FS Page Cache中的数据批量fsync。
缺点:这种策略,如果操作系统奔溃,最多有一秒的数据丢失。(因为OS也会fsync,MySQL主动fsync的周期是一秒,所以最多丢一秒数据。磁盘IO次数不确定,因为操作系统的fsync频率并不是MySQL能控制的)
综上,为了防止事务级数据丢失,必须设置redo log的刷写级别为强一致(innodb_flush_log_at_trx_commit=1)
二、page级数据丢失
说明: 由于mysql数据页page损坏出现的数据丢失
范围: page级
严重级别: 中
处理手段:
- 开启Doublewrite Buffer,默认开启
Linux文件系统页(OS Page)的大小是4KB,MySQL的页(Page)大小默认是16KB,
所以MySQL将Buffer Pool中一页数据刷入磁盘,要写4个文件系统里的页(也可以说成一个MySQL数据页映射4个系统页)。
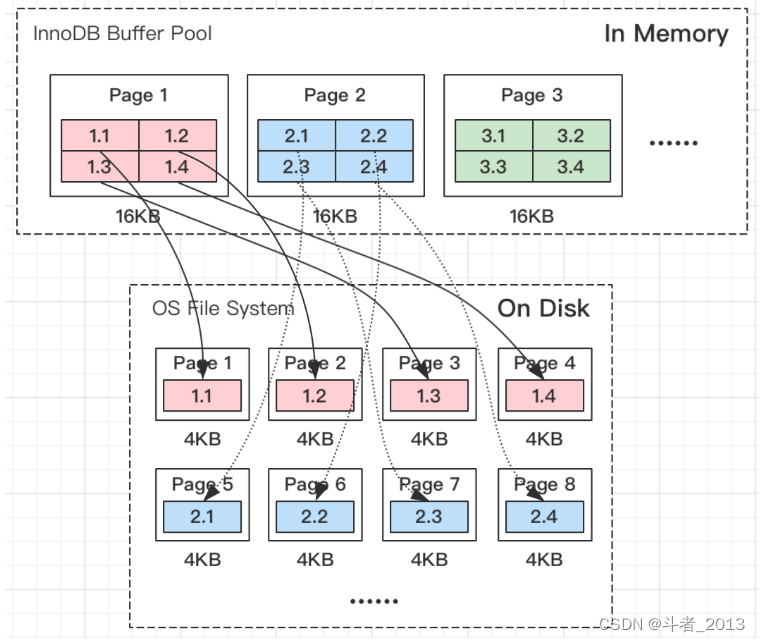
如上图所示,MySQL里Page 1的页,物理上对应磁盘的Page 1、Page 2、Page 3、Page 4四个页。
这个操作并非原子,如果执行到一半断电,会不会出现问题呢?
答案:会,这就是所谓的“页数据损坏”。
MySQL内Page 1的页准备刷入磁盘,才刷了3个文件系统里的页,掉电了,则会出现:重启后,MySQL内Page 1的页,物理上对应磁盘上的Page 1、Page 2、Page 3三个页,数据完整性被破坏。(Redo Log无法修复这类“页数据损坏”的异常,因为Redo Log修复的前提是“页数据正确”并且Redo日志正常)
针对上面出现的情况,如何解决这类“页数据损坏”的问题呢?
很容易想到的方法是,能有一个“副本”,对原来的页进行还原,这个存储“副本”的地方,就是Doublewrite Buffer。Doublewrite Buffer,它与传统的“Buffer”又不同,它分为内存和磁盘的两层架构。(传统的“Buffer”,大部分是内存存储;而DWB里的数据,是需要落地的)
Doublewrite Buffer工作流程:
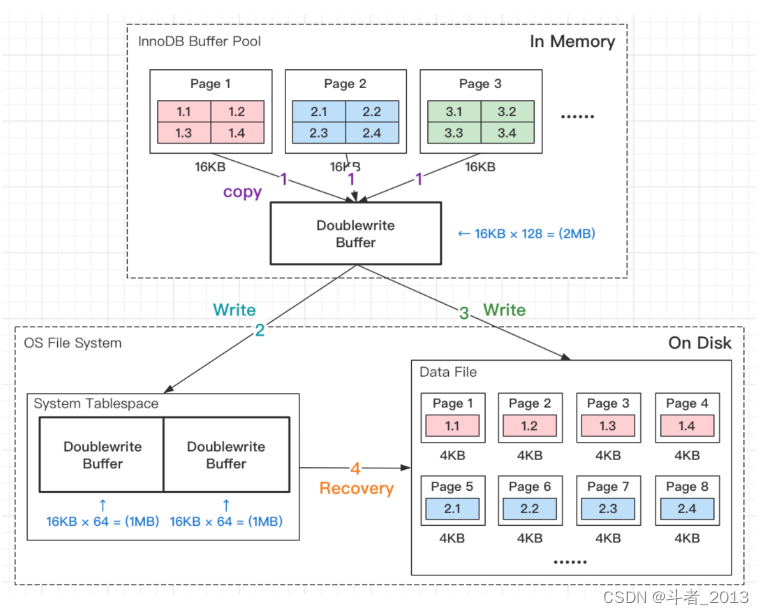
如上图所示,当有页数据要刷盘时:
- 第1步:页数据先memcopy到DWB的内存里;
- 第2步:DWB的内存里的数据页,会先刷到DWB的磁盘上;
- 第3步:DWB的内存里的数据页,再刷到数据磁盘存储.ibd文件上;
备注:DWB内存结构由128个页(Page)构成,所以容量只有:16KB × 128 = 2MB。
DWB为什么能解决“页数据损坏”问题呢?
假设步骤2掉电,磁盘里依然是Page 1、Page 2、Page 3、Page 4的完整数据。只要有页数据完整,就能通过Redo Log还原数据;假如步骤3掉电,DWB磁盘结构里存储着完整的数据。所以,一定不会出现“页数据损坏”问题。同时写了DWB磁盘和Data File,总有一个地方的数据是OK的。
是否开启DoubleWrite
SHOW VARIABLES LIKE 'innodb_doublewrite';

三、磁盘级数据丢失
说明: 磁盘损坏导致的数据丢失
范围: 磁盘级
严重级别: 严重
处理手段:
- 磁盘矩阵
- 数据库集群
- 冷热备份
不要以为数据正确完整的写到磁盘上就万事大吉,在程序整体架构的考虑中,除了软件层面的问题,必须还要考虑硬件层面的风险。
比如,由于Mysql存储数据的磁盘由于故障损坏了,造成了整个系统的数据丢失,这样的情况将使灾难性的。那么我们该如何应对磁盘级的数据丢失风险呢?其核心就是就好数据备份。
磁盘矩阵
核心是利用多块磁盘的冗余存储,保障即是一块磁盘损坏也不会出现数据丢失。
RAID1 是磁盘阵列中单位成本最高的一种方式。因为它的原理是在往磁盘写数据的时候,将同一份数据无差别的写两份到磁盘,分别写到工作磁盘和镜像磁盘,那么它的实际空间使用率只有50%了,两块磁盘当做一块用,这是一种比较昂贵的方案。
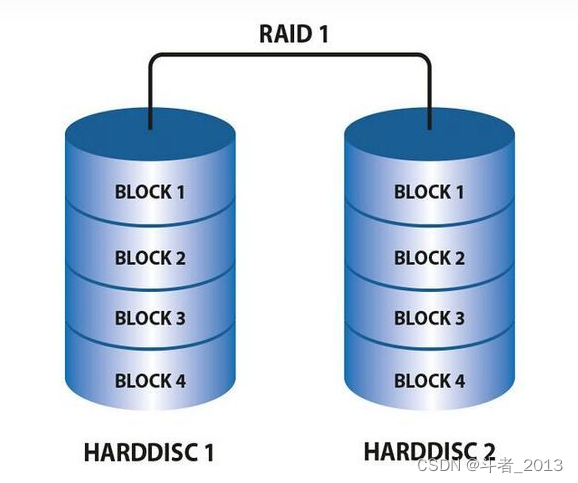
优点:是简单,一般做硬件运维的同事都能操作。
缺点:成本较高,备份数据的精读较粗,一般是整个服务器级别,往往是财大气粗的政府机关和银行在使用。另外不能做到远程宰备,如果整机房都出了问题,往往还是会出现数据丢失。
数据库集群备份Replication
通过搭建mysql数据库集群,让集群中每台服务器保存完整的数据库信息,这样即使一台服务器上的数据出现了丢失,也能从备份的数据库中找回。
而且mysql的主备数据库可以实现无感知的切换,宅难恢复的速度更快。
而且通过主备数据库,也可以方便实现数据库的读写分离,缓解单台数据库上的读写压力。
是目前最主流的数据库灾备方式。
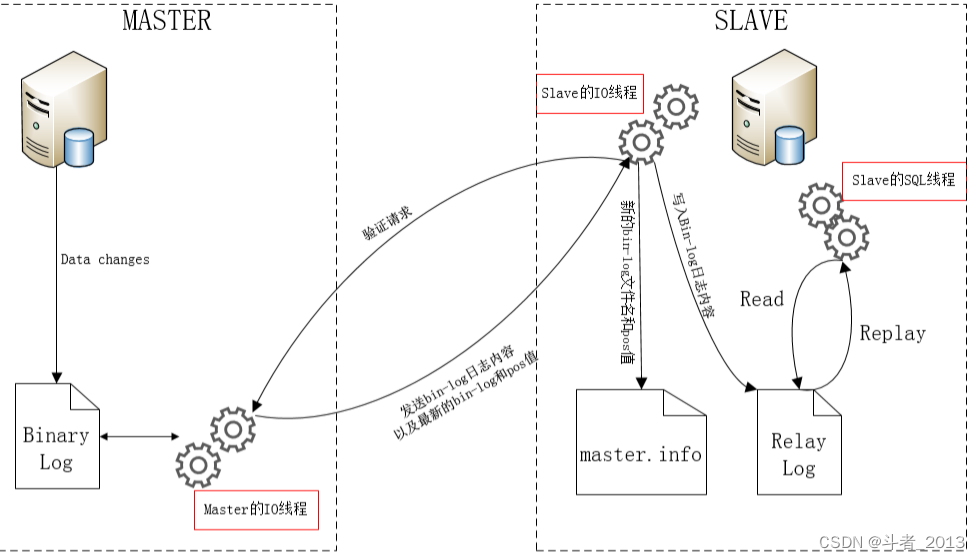
优点:程序级别的数据备份,更节省成本,能较方便的实现远程备份,宅难恢复更快。
缺点:如果是程序勿操作导致的数据丢失,从库也会执行相同操作,造成数据无法找回。
冷热备份
MySQL备份功能在实际应用中的重要程度不需要多说,在误删重要数据后或者数据库被攻击后,备份数据的作用就突显出来了。
MySQL备份方式从不同的角度分析有不同的分类。 从运行状态分析,有冷备份和热备份之分。冷备份一般是在数据库关闭或者暂时不对外提供服务时,选择某一时间节点对完整数据库进行快照备份。热备份一般是在数据库运行的状态下,直接对数据进行备份,不影响MySQL对外提供服务。这里主要讲下这两种方式的实现。
直接通过MySQL自带的mysqldump工具进行备份
-- 数据备份
mysqldump -uroot -proot test > /data/backup/test.sql
-- 数据恢复
mysql -f -uroot -proot test < /data/backup/test.sql
一般将备份的数据文件存放在其他服务器上。
总结
本文主要对mysql数据库数据丢失的几种常见场景进行了介绍。作为程序开发者可能只需要注意程序开发中过程中事务的使用规范,但是如果作为项目负责人、架构师等视角来看,必须把数据库运维的问题也考虑在内,做到软硬件风险全盘考虑,防止出现重大事故。
- 事务级数据丢失:添加事务控制,开启Redo log并采用
强一致(innodb_flush_log_at_trx_commit=1)刷写机制。 - 数据页损坏级别的数据丢失:数据双写机制
double wirte - 如何防止磁盘级别的数据丢失:
磁盘矩阵,数据库集群,数据库冷热备份。
MySQL各种“Buffer”之Doublewrite Buffer
MySQL各种“Buffer”之Log Buffer
MySQL的冷热备份
最后
以上就是淡定凉面最近收集整理的关于mysql中怎么防止数据丢失前言一、事务级数据丢失二、page级数据丢失三、磁盘级数据丢失总结的全部内容,更多相关mysql中怎么防止数据丢失前言一、事务级数据丢失二、page级数据丢失三、磁盘级数据丢失总结内容请搜索靠谱客的其他文章。








发表评论 取消回复