Nodejs 解读
概念
Node.js® 是一个基于 Chrome V8 引擎 的 JavaScript 运行时环境。
Nodejs可以做什么
- 轻量级、高性能的 Web 服务
- 前后端 JavaScript 的同构开发
- 便捷高效的前端工程化
Nodejs架构
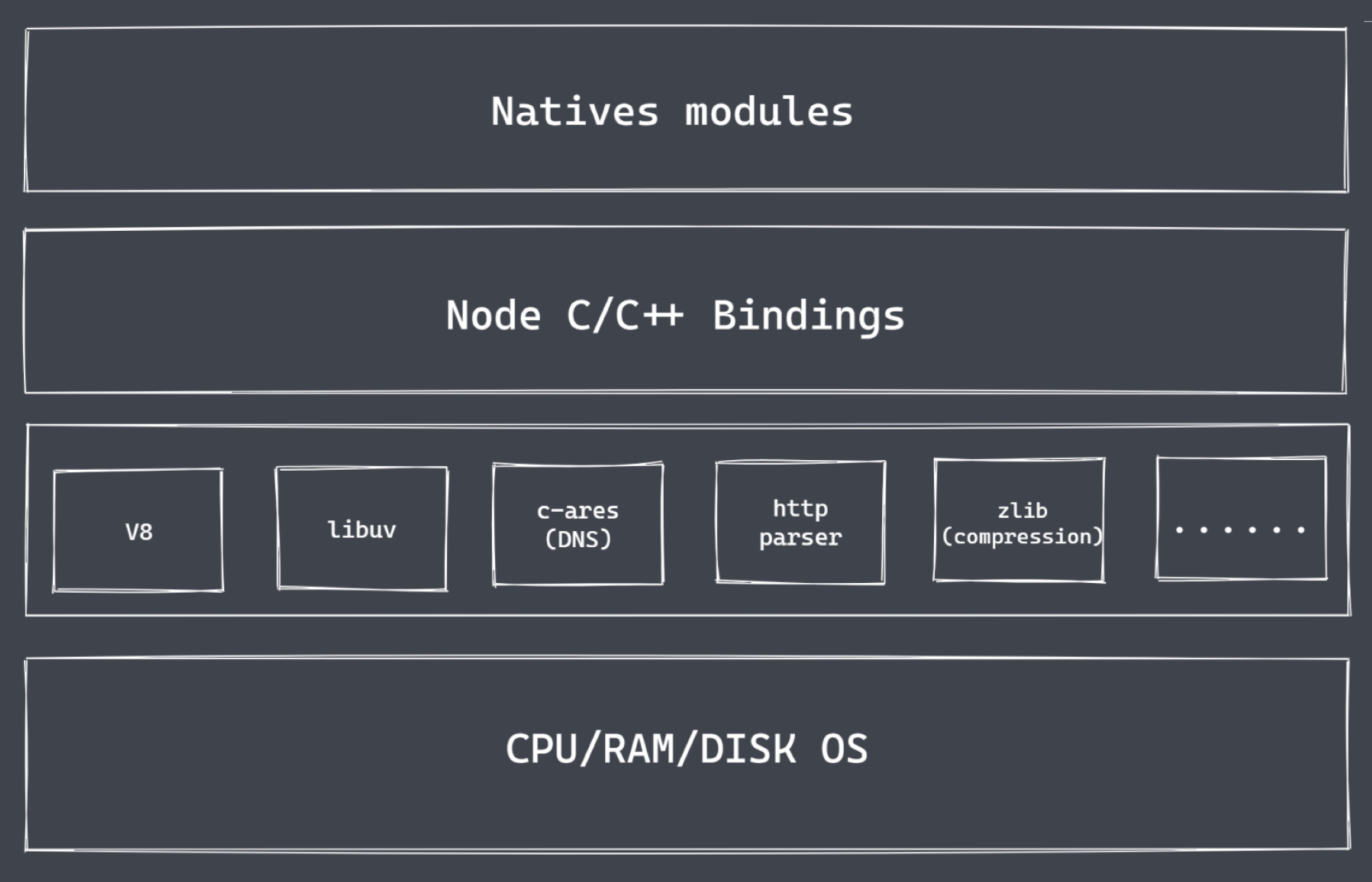
Natives modules
- 当前层内容由 JS 实现
- 提供应用程序可直接调用库,例如 fs、path、http等
- JS 语言无法直接操作底层硬件设置
Builtin modules “胶水层” 由C/C++实现
底层
- V8:执行 JS 代码,提供桥梁接口;
- Libuv: 事件循环、事件队列、异步IO;
- 第三方模块:zlib、http、c-ares等
Nodejs优势
Nodejs 更适用于 IO 密集型的高并发请求
Nodejs 异步 IO
- IO 是应用程序的瓶颈所在(应用执行 IO 都是需要消耗时间的)
- 异步 IO 提高性能,无需原地等待结果返回,直接去处理之后的代码执行;
- IO 操作属于操作系统级别,libuv都对其有对应的封装有很好跨平台效果;
- Nodejs 单线程配合事件驱动架构及libuv很好的实现了异步 IO;
Nodejs 事件驱动架构
- 类似发布订阅模式
- Nodejs有内置的事件模块(events),通过监听和触发事件,来通知 IO 操作的完成;(类似回调函数的方式)
Nodejs 单线程
- Nodejs 单线程模式,配合异步 IO、事件驱动、事件循环等实现高并发的请求,可实现高效可伸缩的高性能 Web 服务器;
- Nodejs 单线程是指 V8 的主线程是单线程的,并不是没有多线程,Libuv库中是有多个线程池的;
- Nodejs 单线程缺点是,不好处理CPU密集型的代码,需要等待CPU执行完再继续;
Nodsjs 更加适合 IO 密集型的任务
实际中应用一般有:
- 前后端之间的 BFF 层,中台;
- 操作数据库的 API 服务;
- 实施的聊天应用程序等;
Nodejs 常见的全局变量
- __filename: 返回正在执行脚本文件的绝对路径;
- __dirname: 返回正在执行脚本所在目录;
- timer类函数: 执行顺序与事件循环间的关系;
- process: 提供与当前进程互动的接口;
- require: 实现模块的加载;
- module、exports: 处理模块的导出
核心模块path
处理路径的模块,有许多API
Buffer 缓冲区
- 无须 require 的一个全局变量
- 实现 Nodejs 平台下的二进制数据操作
- 不占据 V8 堆内存大小的内存空间
- 内存的使用由 Node 来控制,由 V8 的 CG 来回收
- 一般配合 Stream 流使用,充当数据的缓冲区
创建Buffer方法
- Buffer.alloc: 创建指定字节大小的 Buffer
- Buffer.allocUnsafe: 创建指定字节大小的 Buffer (不安全)
- Buffer.from:接收数据 创建 Buffer
- 不推荐使用 new 直接创建
Buffer 实例方法
- fill: 使用数据填充 buffer
- write: 向 buffer 中写入数据
- toString: 从 buffer 中提取数据
- slice: 截取 buffer
- indexOf: 在 buffer 中查找数据
- copy: 拷贝 buffer 中的数据
Buffer 静态方法
- concat: 将多个buffer 拼接成一个新的 buffer
- isBuffer: 判断当前数据是否是buffer
FS模块 文件处理
几个概念
- fs 是 Nodejs 中内置核心模块
- 代码层面上 fs 分为基本操作类和常用 API
- 权限位、标识符、操作符
fs 常用的api
- readFile:从指定文件中读取数据
- writeFile:向指定文件中写入数据
- appendFile:追加的方式向指定文件中写入数据
- copyFile: 将某个文件中的数据拷贝至另一个文件中;
- watchFile:对指定文件进行监控
常见 flag 操作符
- r: 可读;
- w: 可写;
- s: 同步;
- +: 执行相反操作;
- x: 排他操作;
- a: 追加操作;
fd 就是操作系统分配给被打开文件的标识
常见目录操作的 API
- access:判断文件或者目录是否具有操作权限;
- stat:获取目录及文件信息;
- mkdir:创建目录;
- rmdir:删除目录;
- readdir:读取目录中内容;
- unlink:删除指定文件;
Common JS 规范(NodeJs的模块加载)
Common JS 规范定义模块的加载是同步完成的;
Nodejs 按 Common JS规范进行了实现;
- 任意一个文件就是一个模块,具有独立作用域;
- 使用require 导入其他模块;
- 将模块 ID 传入 require 实现目标模块定位;
模块API的使用
module属性
- 任意 js 文件就是一个模块,可以直接使用 module 属性;
API有
- id:返回返回模块标识符,一般是一个绝对路径;
- filename:返回文件模块的绝对路径;
- loaded:返回布尔值,表示模块是否完成加载;
- parent:返回对象,存放调用当前模块的模块;
- children:返回数组,存放当前模块调用的其它模块;
- exports:返回当前模块需要暴露的内容;
- paths:返回数组,存放不同目录下的 node_modules 位置;
require 属性
- 基本功能是读入并且执行一个模块文件;
API 有
- resolve:返回模块文件绝对路径;
- extensions:依据不同后缀名执行解析操作;
- main:返回主模块对象
NodeJs的模块加载机制,大致分为一下几个部分
- 路径分析:查找要导入文件的路径,一般为绝对路径;
- 缓存优化:先查找是否有文件缓存,优先读取缓存文件;
- 文件定位:识别是,.js、.json、.node 文件类型;
- 编译执行:将导入的字符串文件,变为可执行代码,并执行;(处理作用域、传参等问题)
模块加载中,执行字符串代码转换的是利用的 内置模块 vm ,将字符串变为可执行代码,
const vm = require('vm')
vm.runInThisContext('console.log("abc")')
事件模块-EventEmitter 常见 API
- on:添加当事件被触发时调用的回调函数;
- emit:触发事件,按照注册的序同步调用每个事件监听器;
- once:添加当事件在注册之后首次被触发时调用的回调函数;
- off:移除特定的监听器
NodeJs 事件循环机制
Node中的事件队列有6个之多
timers -> pending callbacks -> idle, prepare -> poll -> check -> close ballbacks
队列说明
- timers:执行 setTimeout 与 setInterval 回调;
- pending callbacks:执行系统操作的回调,例如 tcp udp;
- idle, prepare:只在系统内部进行使用;
- poll:执行与I/O相关的回调;
- check:执行 setImmediate 中的回调;
- close callbacks:执行 close 事件的回调;
NodeJs 完整事件环
- 执行同步代码,将不同的任务添加至相应的队列;
- 所有同步代码执行后会去,查看微任务队列,执行满足条件微任务;
- 所有微任务代码执行后会执行 timer 队列中满足的宏任务;
- tImer 中的所有宏任务执行完成后就会依次切换队列;每次切换队列都会去执行微任务队列
- 注意:在完成队列切换之前会先清空微任务代码
注意:nodejs 微任务中,process.nextTick 任务的优先级要高于Promise
Node 与 浏览器事件环 不同
- 任务队列数不同, 浏览器认为有两个,node 有一个微任务多个宏任务;
- Nodejs 微任务执行时机不同, 浏览器每个宏任务完成后执行微任务, node 每个宏任务完成后和宏任务队列切换时;
- 微任务优先级不同, Node中process.nextTick 任务的优先级要高于Promise
Node队列执行的常见问题;
setTimeout(() => {
console.log('timeout')
});
setImmediate(() => {
console.log('Immediate');
})
执行循序先后可能变化,因为setTimeout 有传入时间的延迟,执行时机可能有变化;
但是放入I/O操作回调中就会固定先执行 setImmediate
const fs = require('fs')
fs.readFile('./m1.js', () => {
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immdieate')
})
})
I/O操作回调是在poll宏任务队列中,执行完切换队列,首先会切换到 check 任务队列,所以先执行setImmediate;
核心模块之 stream
流处理数据的优势
- 时间效率:流的分段处理可以同时操作多个数据 chunk
- 空间效率:同一时间流无须占据大内存空间;
- 使用方便:流配合管理,扩展程序变得简单;
NodeJs 中流的分类
- Readable:可读流,能够实现数据的读取;
- Writeable:可写流,能够实现数据的写操作;
- Duplex:双工流,即可读又可写;
- Tranform:转换流,可读可写,还能实现数据转换;
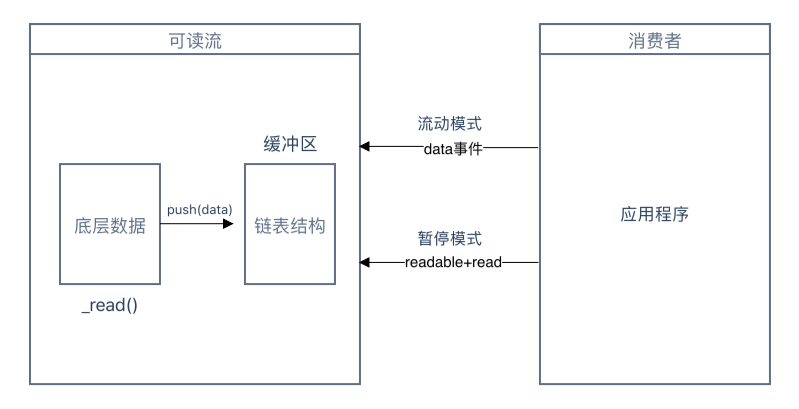
Readable 可读流
生产供程序消费的数据流
const { Readable } = require('stream');
const source = ['zhi', 'age', 'name'];
class MyReadable extends Readable{
constructor(source){
super()
this.source = source;
}
_read() {
let data = this.source.shift() || null;
this.push(data);
}
}
let myex = new MyReadable(source);
// 暂停模式
myex.on('readable', () => {
let data = null;
while((data = myex.read(3)) != null){
console.log(data.toString());
}
})
// 流动模式
myex.on('data', (chunk) => {
console.log(chunk.toString());
})
Writeable可写流
用于消费的数据流
可写流事件
- pipe 事件:可读流调用 pipe() 方法时触发;
- unpipe:事件:可读流调用 unpipe() 方法时触发;
- drain 事件:write 返回 false,数据可执行写入时触发;
const { Writable } = require('stream');
class MyWritable extends Writable{
constructor(){
super()
}
_write(chunk, en, cb) {
process.stdout.write(chunk.toString() + '--------');
process.nextTick(cb);
}
}
let Mywr = new MyWritable()
Mywr.write('按理说的结论是', 'utf-8', (err, data) => {
console.log('写入完成')
})
Duplex 双工流
let {Duplex} = require('stream')
class MyDuplex extends Duplex{
constructor(source) {
super()
this.source = source
}
_read() {
let data = this.source.shift() || null
this.push(data)
}
_write(chunk, en, next) {
process.stdout.write(chunk)
process.nextTick(next)
}
}
let source = ['a', 'b', 'c']
let myDuplex = new MyDuplex(source)
/* myDuplex.on('data', (chunk) => {
console.log(chunk.toString())
}) */
myDuplex.write('拉勾教育', () => {
console.log(1111)
})
Transform 转换流
let {Transform} = require('stream')
class MyTransform extends Transform{
constructor() {
super()
}
_transform(chunk, en, cb) {
this.push(chunk.toString().toUpperCase())
cb(null)
}
}
let t = new MyTransform()
t.write('a')
t.on('data', (chunk) => {
console.log(chunk.toString())
})
fs.createWriteStream 写入流
const fs = require('fs');
let ws = fs.createWriteStream('text1.txt')
let flag = ws.write('12323', () => {
console.log('写入完成')
})
// flag 返回true和false 表示总写入量是否大于等于缓存区大小了, 通知消费速度已经更不上生产速度了,可以先停止生产,减少消耗。
// 当缓冲区又有空余时,并且返回的flag为false时,会触发 drain 事件通知,可以开始继续生产数据了。
控制写入的速度
const fs = require('fs');
let ws = fs.createWriteStream('text.txt', {
highWaterMark: 3
})
// ws.write('天启熟练度空间');
let source = '天启熟练度空间'.split('');
let num = 0;
let flag = true;
function executeWrite() {
flag = true;
while(num < source.length && flag){
flag = ws.write(source[num++])
}
}
executeWrite();
ws.on('drain', () => {
console.log('写入停止。。。');
executeWrite()
})
背压机制 根据写入的速度,暂停和开始读取流,减少内存消耗
let fs = require('fs')
let rs = fs.createReadStream('test.txt', {
highWaterMark: 4
})
let ws = fs.createWriteStream('test1.txt', {
highWaterMark: 1
})
let flag = true
rs.on('data', (chunk) => {
flag = ws.write(chunk, () => {
console.log('写完了')
})
if (!flag) {
rs.pause()
}
})
ws.on('drain', () => {
rs.resume()
})
// 相当于 pipe
// rs.pipe(ws)
最后
以上就是活力钻石最近收集整理的关于Nodejs 解读Nodejs 解读的全部内容,更多相关Nodejs内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复