写在前面
个人情况:
- 数学基础 -> 考研数学一
- 编程基础 -> 过去偏向应用开发,任务需要会兼顾前后端,nlp相关知之甚少
- 整体情况 -> 小白一枚~
- 阅读目的 -> 初次阅读重点在于了解理论模型构建过程
原意是通过项目推动理论学习,不过基于零基础点NLP的技能树显然是有些不自量力。在学习某入门文本分类实践中,遇到了一个感兴趣的名词——SVM支持向量机。随后找到西瓜书略读相关理论,在6.4软间隔与正则化和6.6核方法分别遇到了对率损失和线性判别分析两个概念,它们都指向了第3章线性模型(没想到还是个西瓜书宇宙~)。本着求知(实则无奈~)的原则,读一读哈~
梳理框架
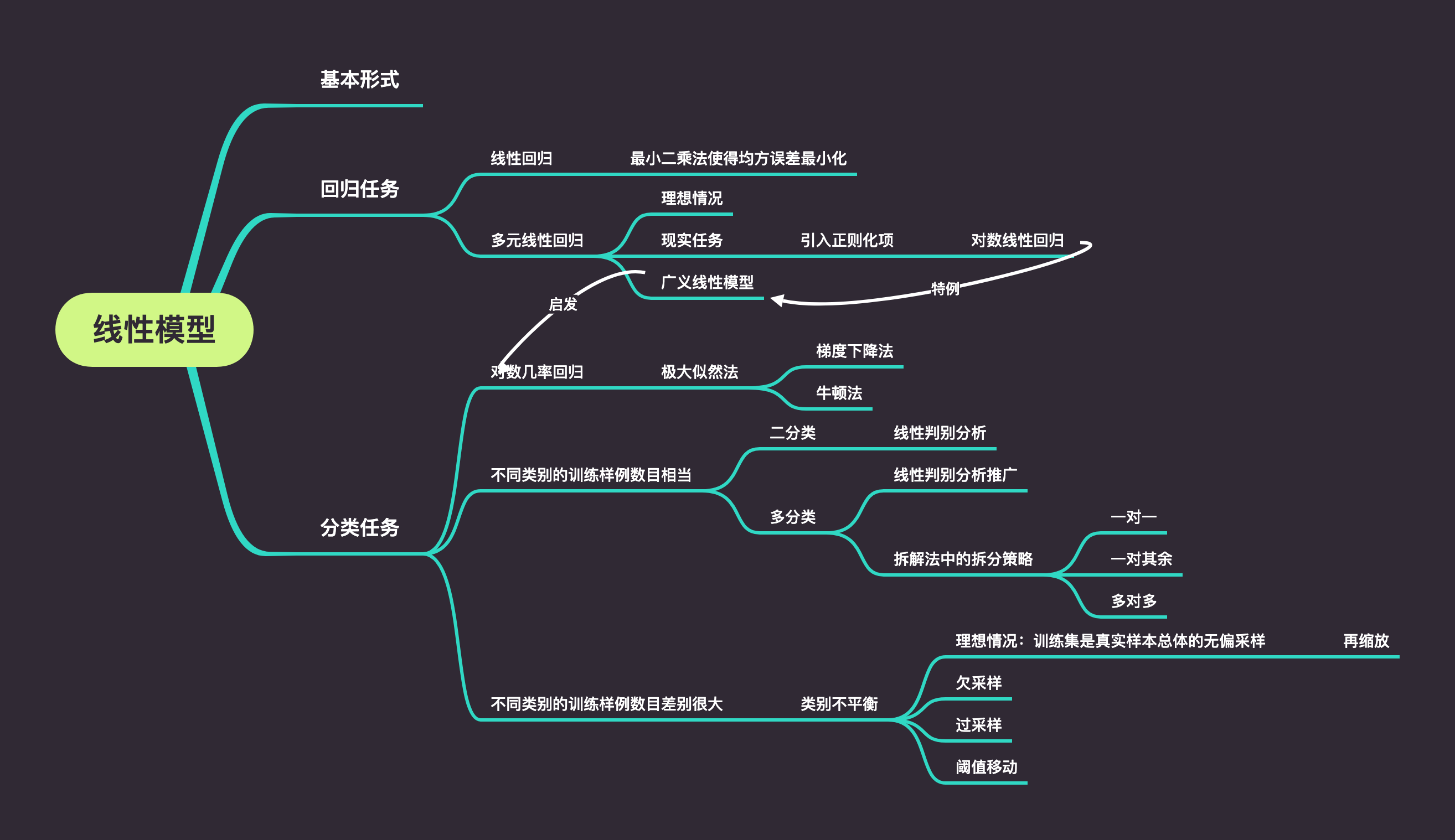
基本形式
给定由 d d d个属性描述的示例 x = ( x 1 ; x 2 ; . . . ; x d ) x=(x_1;x_2;...;x_d) x=(x1;x2;...;xd),其中 x i x_i xi是 x x x在第 i i i个属性上的取值,线性模型试图学得一个通过属性的线性组合来进行预测的函数,即
f ( x ) = ω 1 x 1 + ω 2 x 2 + . . . + ω d x d + b f(x)=omega_1x_1+omega_2x_2+...+omega_dx_d+b f(x)=ω1x1+ω2x2+...+ωdxd+b
一般向量形式写成
f ( x ) = ω T x + b f(x)=omega^Tx+b f(x)=ωTx+b
其中 ω = ( ω 1 ; ω 2 ; . . . ; ω d ) omega=(omega_1;omega_2;...;omega_d) ω=(ω1;ω2;...;ωd). ω omega ω和 b b b学得之后,模型就得以确定
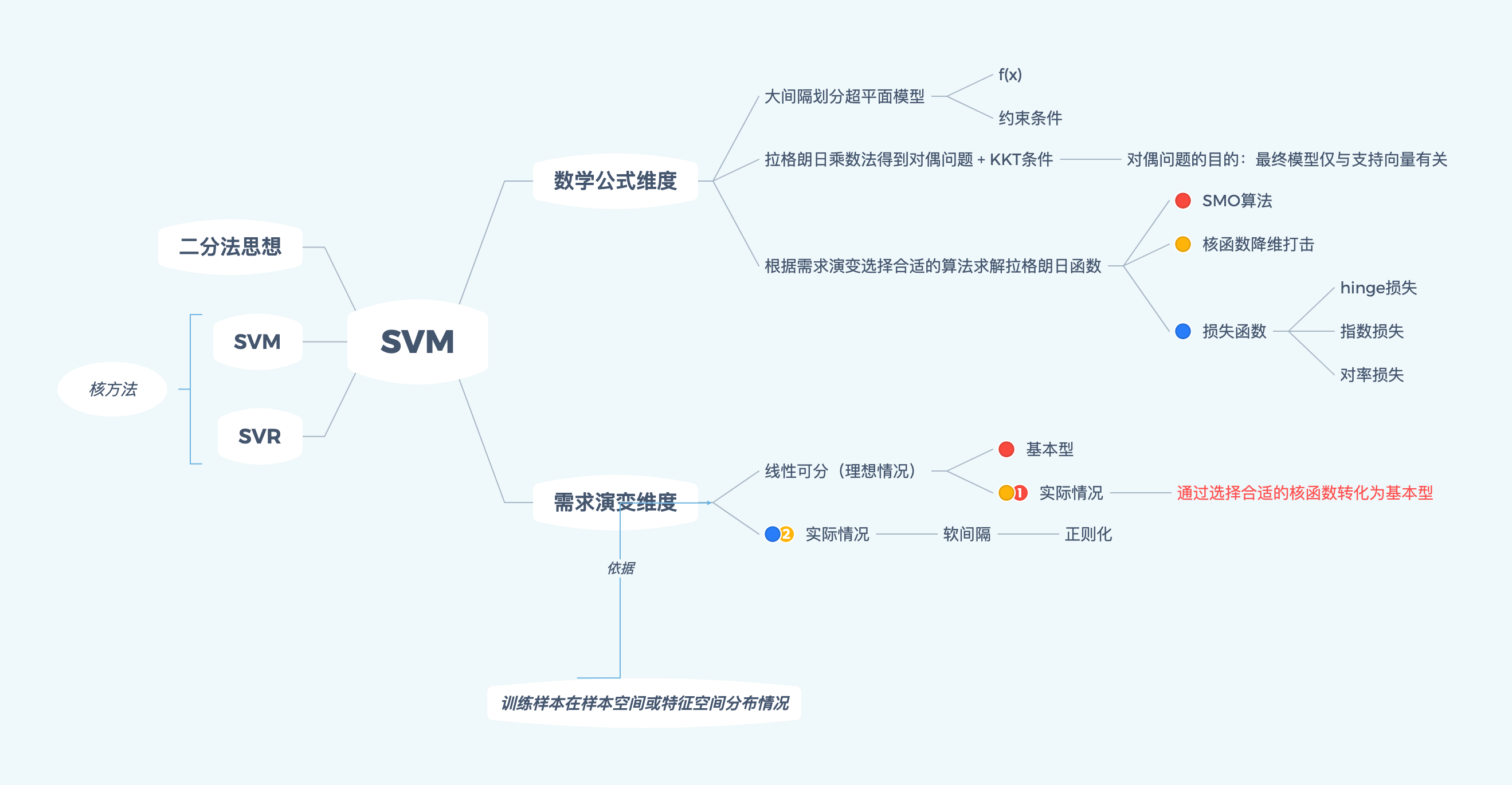
在粗读SVM向量机章节发现划分超平面也是通过类似的线性方程来表示,并且始终围绕着该线性组合做文章,比如在添加约束条件之后就变成了我们考研童鞋熟悉的多元微分条件极值,即基于拉格朗日乘数法思想求解
ω
omega
ω和
b
b
b.下图是SVM章节的粗读思维框架,也是下一次西瓜书笔记的内容~
因此,我们能隐约地发现线性模型形式简单易懂,也便于建模,但蕴涵着机器学习中一些重要的基本思想。而且,不难发现
ω
omega
ω能直观表达各属性在预测中的重要性,这使得线性模型由很好的可解释性。以如何挑选西瓜为例,可建立一个简易的线性模型
f
好
瓜
(
x
)
=
0.2
⋅
x
色
泽
+
0.5
⋅
x
根
蒂
+
0.3
⋅
x
敲
声
+
1
f_{好瓜}(x)=0.2cdot x_{色泽}+0.5cdot x_{根蒂}+0.3cdot x_{敲声}+1
f好瓜(x)=0.2⋅x色泽+0.5⋅x根蒂+0.3⋅x敲声+1,说明可以综合考虑色泽、根蒂和敲声来判断瓜的好坏,其中根蒂最重要。
回归任务
给一个前提条件:给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)} D={(x1,y1),(x2,y2),...,(xm,ym)},其中 x i = ( x i 1 ; x i 2 ; . . . ; x i d ) x_i=(x_{i1};x_{i2};...;x_{id}) xi=(xi1;xi2;...;xid), y i ∈ R y_iin R yi∈R.回归任务试图学得一个线性模型以尽可能准确地预测实值输出标记。接下来我们会逐渐提升情况的复杂程度。
线性回归
凡事由浅入深,化繁为简。最简单的情形显而易见,输入属性的数目只有一个(即一元)。线性回归试图学得
f
(
x
i
)
=
ω
x
i
+
b
f(x_i)=omega x_i+b
f(xi)=ωxi+b
使得
f
(
x
i
)
≈
y
i
f(x_i)approx y_i
f(xi)≈yi.
那么问题来了,如何确定
ω
omega
ω和
b
b
b呢?这里我们可以运用回归任务中最常用的性能度量——均方误差,即衡量
f
(
x
)
f(x)
f(x)与
y
y
y的差别。所以我们的最终目的就是使均方误差最小化,即
(
ω
∗
,
b
∗
)
=
a
r
g
(
ω
,
b
)
m
i
n
Σ
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
(omega^*,b^*)=arg_{(omega,b)}minSigma^m _{i=1} (f(x_i)-y_i)^2
(ω∗,b∗)=arg(ω,b)minΣi=1m(f(xi)−yi)2
=
a
r
g
(
ω
,
b
)
m
i
n
Σ
i
=
1
m
(
y
i
−
ω
x
i
−
b
)
2
=arg_{(omega,b)}minSigma^m _{i=1} (y_i-omega x_i-b)^2
=arg(ω,b)minΣi=1m(yi−ωxi−b)2
这里我们介绍一种方法——最小二乘法,它是基于均方误差最小化进行模型求解的。而在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线的欧氏距离之和最小。
求解 ω omega ω和 b b b使 E ( ω , b ) = Σ i = 1 m ( y i − ω x i − b ) 2 E_{(omega,b)}=Sigma^m _{i=1} (y_i-omega x_i-b)^2 E(ω,b)=Σi=1m(yi−ωxi−b)2最小化的过程,称为线性回归模型的最小二乘“参数估计”。对 E ( ω , b ) E_{(omega,b)} E(ω,b)分别求 ω omega ω和 b b b的偏导,得到
进而令上述两式为零,得到 ω omega ω和 b b b的最优解的闭式解
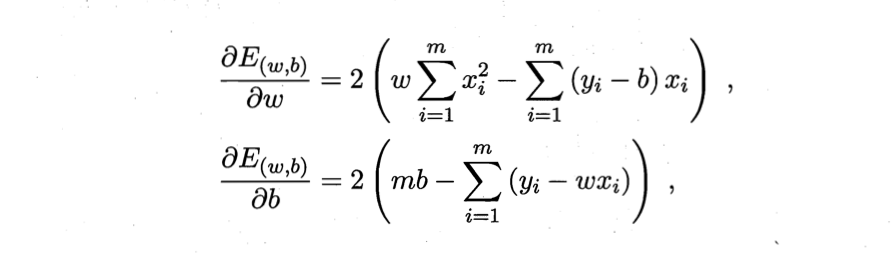
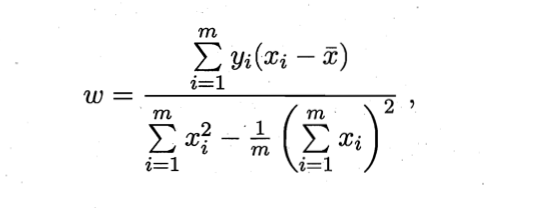
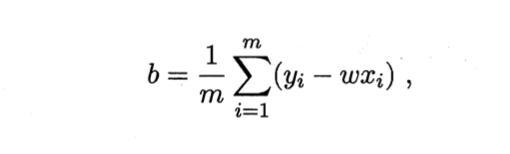
注:这里 E ( ω , b ) E_{(omega,b)} E(ω,b)是关于 ω omega ω和 b b b的凸函数,当他关于 ω omega ω和 b b b的导数均为零时,得到 ω omega ω和 b b b的最优解。
个人理解:什么是凸函数?举一个简单的例子: f ( x ) = x 2 f(x)=x^2 f(x)=x2(脑海里很容易出现该函数图像~)。在高数中,我们知道如何判断函数的凹凸性,即判断二阶导的正负性。这样我们就可以很容易理解令偏导为零得到最优解。因为我们的目的是使均方误差最小化,而凸函数一阶导为零能求出极小值(想刚才那个简单的函数图像~)。这样我们就可以将线性回归的最小二乘法与高数内容联系到一起,从而更好地理解数学推导过程。
多元线性回归
现在进一步推广,回到开头,样本由
d
d
d个属性描述,此时我们试图学得
f
(
x
)
=
ω
T
x
+
b
f(x)=omega^Tx+b
f(x)=ωTx+b
这就是多元线性回归(对应上一小节的一元).
依旧采用最小二乘法,不过为便于讨论,把
ω
omega
ω和
b
b
b吸收入向量形式
ω
Λ
=
(
ω
,
b
)
omega^Lambda=(omega,b)
ωΛ=(ω,b).相应,把数据集
D
D
D表示为一个
m
×
(
d
+
1
)
mtimes(d+1)
m×(d+1)大小的矩阵
X
X
X,其中每行对应于一个示例,该行前
d
d
d个元素对应于示例的
d
d
d个属性值,最后一个元素恒置为1,即
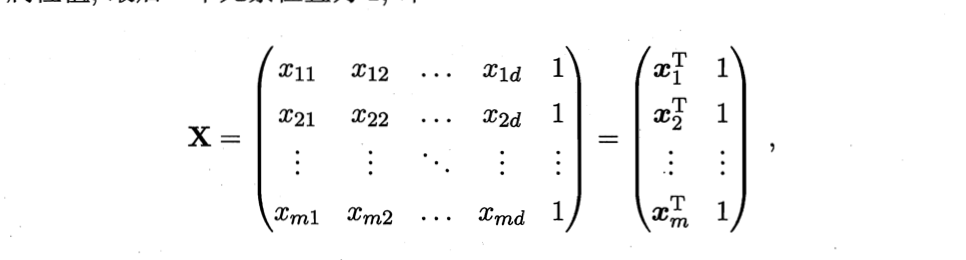
之后将以向量形式改写均方误差最小化的式子,有
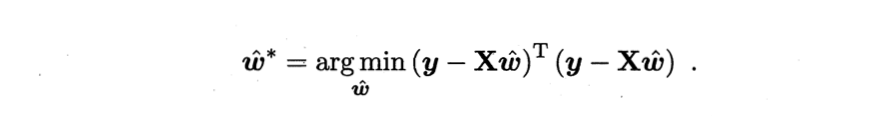
随后也是相同的动作——求导。得到:
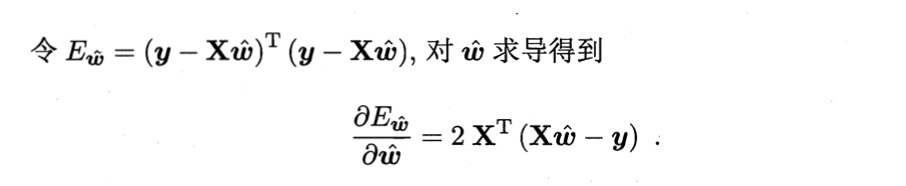
同样地,令其为零,即可得到最优解的闭式解,但由于涉及到矩阵逆运算,情况比较复杂,所以我们要做一个讨论。
当
X
T
X
X^TX
XTX为满秩矩阵或正定矩阵(此处又涉及到线性代数的概念),再令上式为零得到
ω
∗
=
(
X
T
X
)
−
1
X
T
y
omega^*=(X^TX)^{-1}X^Ty
ω∗=(XTX)−1XTy
令
x
i
Λ
=
(
x
i
,
1
)
x^Lambda _i=(x_i,1)
xiΛ=(xi,1),最终得到多元回归模型
f
(
x
i
Λ
)
=
x
Λ
i
T
(
X
T
X
)
−
1
X
T
y
f(x^Lambda _i)={x^Lambda}^T _i(X^TX)^{-1}X^Ty
f(xiΛ)=xΛiT(XTX)−1XTy
当然,这是理想情况,现实中往往不是满秩矩阵,甚至会遇到数目超过样例数的情况(线代知识,列大于行,肯定不满秩,而且会出现多解)。我们可能求出多个解均使均方误差最小化,这时选哪一个作为输出,常用的做法是引入正则化项。
我们要明白,我们的目的始终是预测值逼近真实值,如果直接逼近可能遇到阻力,那么是否可以使预测值逼近真实值的衍生物,也就是说我们制造一个缓冲区,作为连接预测值与真实值的桥梁。书中假设我们认为示例所对应的输出标记是在指数尺度上变化,这时我们可以取对数,即预测值逼近真实值的对数。给出数学公式,
l
n
y
=
ω
T
x
+
b
lny=omega^Tx+b
lny=ωTx+b
这就是对数线性回归(区别于对数几率回归)。形式上依旧是线性回归,但实质上已经是在求取输入空间到输出空间到非线性函数映射。
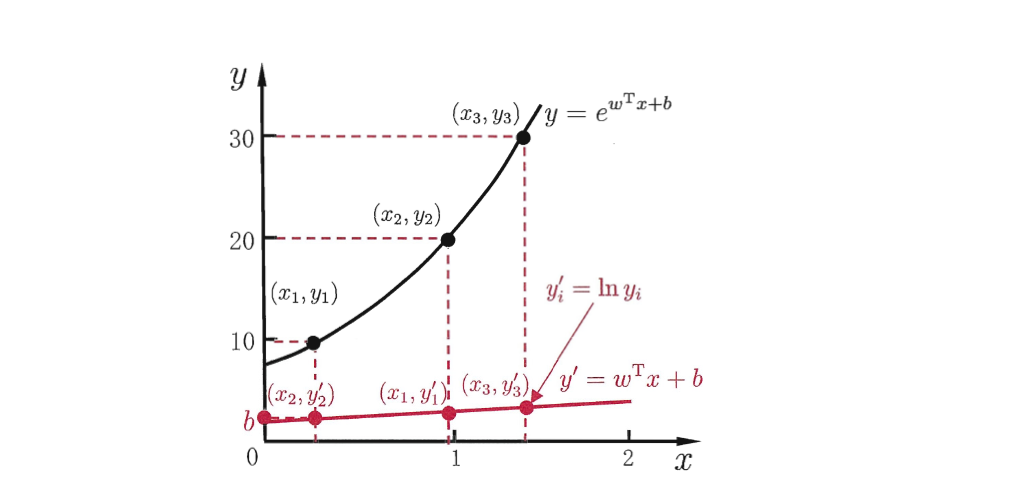
继续一般化,令
y
=
g
−
1
(
ω
T
x
+
b
)
y=g^{-1}(omega^Tx+b)
y=g−1(ωTx+b)
这样就得到“广义线性模型”,其中
g
(
⋅
)
g(·)
g(⋅)称为“联系函数”。
分类任务
如何使用线性模型进行分类任务学习?
对数几率回归
受上一节末广义线性模型的启发,我们也可以找一个单调可微函数将分类任务的真实标记
y
y
y与线性回归模型的预测值联系到一起。
仅考虑二分类任务,其输出标记
y
∈
{
0
,
1
}
yin {0,1}
y∈{0,1}.考虑到线性回归模型
z
=
ω
T
x
+
b
z=omega^Tx+b
z=ωTx+b产生的预测值是实数,所以我们将
z
z
z转换成0/1值,最理想的是“单位阶跃函数”
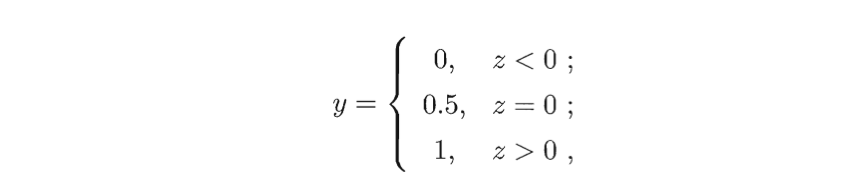
不过显而易见,单位阶跃函数不连续,不能直接作为联系函数。这时我们可以找一个替代的函数,近似单位阶跃函数的性质,而对数几率函数就满足我们的需求
y
=
1
1
+
e
−
z
y=frac{1}{1+e^{-z}}
y=1+e−z1
下图为单位阶跃函数与对数几率函数的对比图,注意输出值在
z
=
0
z=0
z=0附近变化很陡。
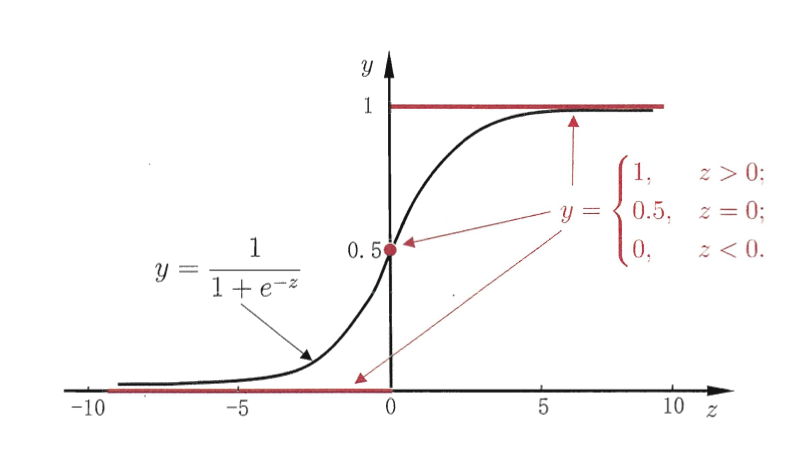
我们发现,这时一个包裹着回归外衣的分类学习方法。这种方法有很多优点,比如它直接对分类可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题。
自然而然,我们要确定 ω omega ω和 b b b。书中给出了“极大似然法”,类似于我们概率论与数理统计中参数估计章节的最大似然估计法。并且在求解似然函数部分举例运用了梯度下降法和牛顿法得到最优解。具体数学推导部分可参考书籍(其实没推明白~)。
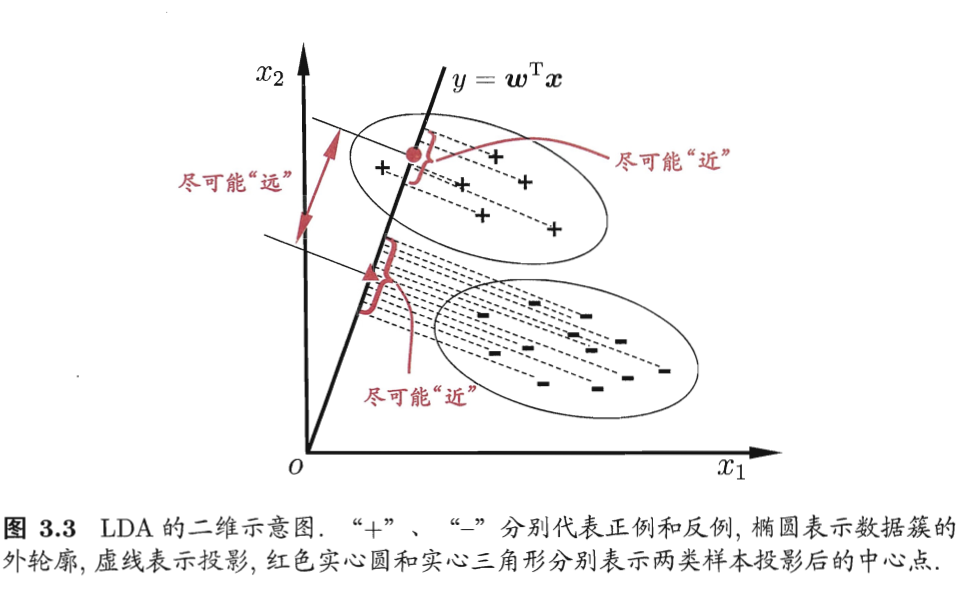
线性判别分析(LDA)
思想比较朴素:给定训练样例集,设法将样例投影到一条直线上,使同类样例投影点尽可能接近、异类样例投影点尽可能远离;对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
多分类
基本思路是“拆解法”,即将多分类任务拆若干个二分类任务求解。具体来说,先对问题进行拆分,然后对拆出的每个二分类任务训练一个分类器;在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。书中该章节主要介绍拆分策略。
给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } , y i ∈ { C 1 , C 2 , . . . , C N } D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)},y_iin {C_1,C_2,...,C_N} D={(x1,y1),(x2,y2),...,(xm,ym)},yi∈{C1,C2,...,CN}
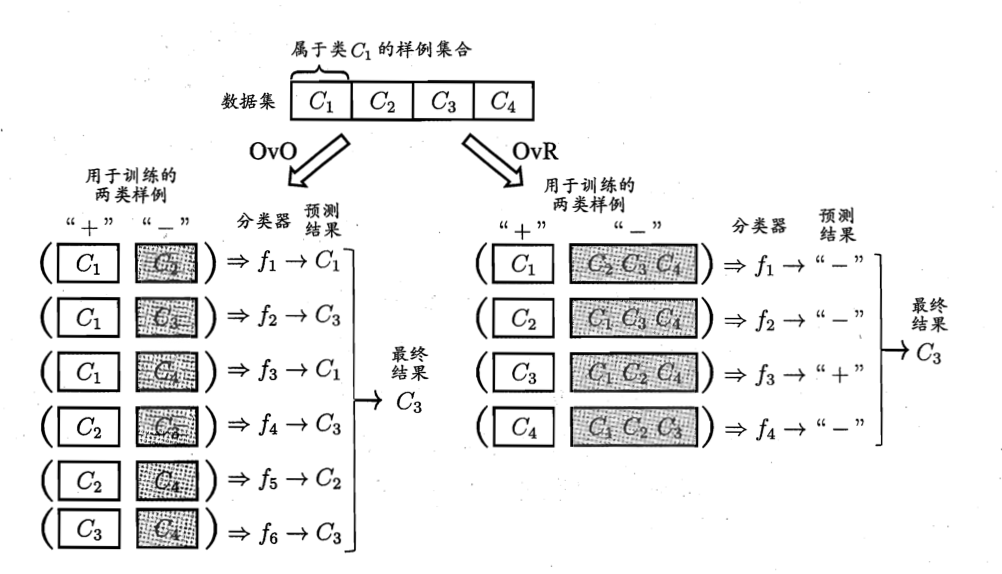
一对一(OvO)
将这N个类别两两配对,例如OvO将为区分类别 C i C_i Ci和 C j C_j Cj训练一个分类器,该分类器把 D D D中的 C i C_i Ci类样例作为正例, C j C_j Cj类样例作为反例。在测试阶段,新样本将同时提交给所有分类器,然后得到 N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2个结果,最终结果通过投票产生:即把被预测得最多的类别作为最终分类结果。后面会给出示意图。
一对其余(OvR)
每次将一个类的样例作为正例、所有其他类的法样例作为反例来训练 N N N个分类器,在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果。若有多个分类器预测为正类,则考虑各个分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
下图为OvO与OvR的过程图。
多对多(MvM)
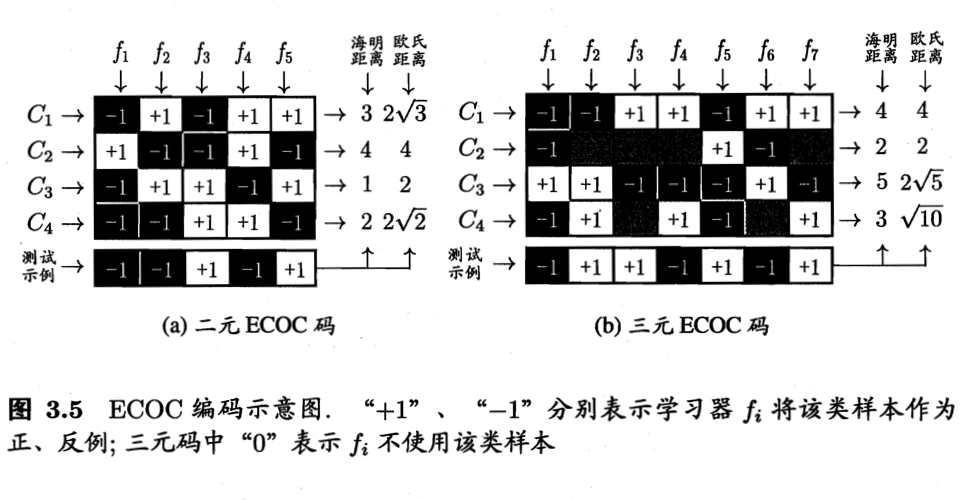
每次将若干个类作为正类,若干个其他类作为反类。MvM的正、反类构造必须有特殊的设计,书中介绍一种常用的技术:纠错输出码(ECOC)。
- 编码:对 N N N个类别做 M M M次划分,每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生 M M M个训练集,可训练出 M M M个分类器。
- 解码: M M M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个类别各自的编码进行比较,返回其中举例最小的类别作为最终预测结果。
类别不平衡
让我们回到现实,前面介绍的分类学习法都有一个共同的基本假设,即不同类别的训练样例数目相当。如果差别很大呢?例如有998个反例,2个正例,那么学习方法只需返回一个永远将新样本预测为反例的学习器,就能达到99.8%的精度,显然这样的学习器没有价值,因为它不能预测出任何正例。
基于线性分类器的角度讨论,这里有一个类别不平衡学习的一个基本策略——“再缩放”。
y
′
1
−
y
′
=
y
1
−
y
×
m
−
m
+
frac{y'}{1-y'}=frac{y}{1-y}times frac{m^-}{m^+}
1−y′y′=1−yy×m+m−
其中
m
−
m^-
m−表示反例数目,
m
+
m^+
m+表示正例数目,
y
y
y就是对数几率回归里的正例可能性。通常我们假设训练集时真实样本总体的无偏样本(参考参数估计的无偏估计)。
再缩放的思想简单,但实际操作很复杂,主要是因为“训练集时真实样本总体的无偏采样”这个假设往往不成立,也就是说,我们未必能有效基于训练集观测几率来推断真实几率。现有技术有三类做法:欠采样、过采样、阈值移动。各方法的过程以及优缺点对比见书~
结尾
能力有限,还未作出完整有效的思路输出,且对书中的公式推导存在许多疑惑,仍需努力。
未来还会随着理解的加深不断修改文章。
参考链接
周志华.机器学习[M]:清华大学出版社,2016
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。
本人blog:http://breadhunter.gitee.io
最后
以上就是复杂白昼最近收集整理的关于西瓜书笔记:第3章·线性模型的全部内容,更多相关西瓜书笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复