线性可分支持向量机
本文包括以下部分
- 1.支持向量机概述
- 2.线性可分支持向量机与硬间隔最大化
- (2.1)基本定义
- (2.2)函数间隔与几何间隔的关系
- (2.3) 硬间隔最大化
- (2.4) 支持向量和间隔边界 - 3. 对偶算法
1.支持向量机概述
支持向量机是一种二类分类模型.它的基本模型是定义在特征空间上的间隔最大的线性分类器。其学习策略是间隔最大化,可形式化为求解凸二次规划问题,也等价于正则化的合叶损失函数的最小化问题。
支持向量机学习方法包含构建由简至繁的模型,可分为线性可分支持向量机、线性支持向量机、非线性支持向量机。
- 线性可分支持向量机:当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,又称为硬间隔支持向量机.
- 线性支持向量机:当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性分类器,称为软间隔支持向量机.
- 非线性支持向量机:当训练数据不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机.
当输入空间为欧氏空间或离散集合,特征空间为希尔伯特空间时,核函数表示将输入从输入空间映射得到特征空间之间的内积,通过使用核函数可以学习非线性支持向量机,等价于隐式地在高维的特征空间中学习线性支持向量机,这样的方法称为核技巧。核方法是比支持向量机更为一般的机器学习方法。
本文按照上式思路首先记录线性可分支持向量机
2.线性可分支持向量机与硬间隔最大化
(2.1)基本定义
输入都由输入空间转换到特征空间,支持向量机的学习是在特征空间进行的。
假设给第一个特征空间上的训练数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
 
,
(
x
N
,
y
N
)
}
T=left{left(x_{1}, y_{1}right),left(x_{2}, y_{2}right), cdots,left(x_{N}, y_{N}right)right}
T={(x1,y1),(x2,y2),⋯,(xN,yN)}其中
x
i
∈
X
=
R
n
,
y
i
∈
Y
=
{
+
1
,
−
1
}
,
i
=
1
,
2
,
⋯
 
,
N
x_{i} in mathcal{X}=mathbf{R}^{n}, quad y_{i} in mathcal{Y}={+1,-1}, quad i=1,2, cdots, N
xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N,
x
i
x_i
xi为第
i
i
i个特征向量,也称为实例,
y
i
y_i
yi为
x
i
x_i
xi的类标记,当
y
i
=
+
1
y_i=+1
yi=+1时,称
x
i
x_i
xi为正例;当时
y
i
=
−
1
y_i=-1
yi=−1,称
x
i
x_i
xi为负例,
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi)称为样本点.再假设训练数据集是线性可分的.
定义1(线性可分支持向量机)给定线性可分训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习得到分离超平面为
w
∗
⋅
x
+
b
∗
=
0
(
1
)
w^{*} cdot x+b^{*}=0 quad(1)
w∗⋅x+b∗=0(1)以及相应的分类决策函数
f
(
x
)
=
sign
(
w
∗
⋅
x
+
b
∗
)
(
2
)
f(x)=operatorname{sign}left(w^{*} cdot x+b^{*}right) quad(2)
f(x)=sign(w∗⋅x+b∗)(2)称为线性可分支持向量机
定义2 (函数间隔) 对于给定的训练数据集
T
T
T和超平面
(
w
,
b
)
(w,b)
(w,b),定义超平面
(
w
,
b
)
(w,b)
(w,b)关于样本点
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi)的函数间隔为
γ
^
i
=
y
i
(
w
⋅
x
i
+
b
)
(
3
)
hat{gamma}_{i}=y_{i}left(w cdot x_{i}+bright) quad(3)
γ^i=yi(w⋅xi+b)(3) 定义超平面
(
w
,
b
)
(w,b)
(w,b)关于训练数据集
T
T
T的函数间隔为超平面
(
w
,
b
)
(w,b)
(w,b)关于中所有样本点
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi)的函数间隔之最小值,即
γ
^
=
min
i
=
1
,
⋯
 
,
N
γ
^
i
(
4
)
hat{gamma}=min _{i=1, cdots, N} hat{gamma}_{i} quad(4)
γ^=i=1,⋯,Nminγ^i(4)定义3 (几何间隔) 对于给定的训练数据集
T
T
T和超平面
(
w
,
b
)
(w,b)
(w,b),定义超平面
(
w
,
b
)
(w,b)
(w,b)关于样本点
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi)的几何间隔为
γ
i
=
y
i
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
(
5
)
gamma_{i}=y_{i}left(frac{w}{|w|} cdot x_{i}+frac{b}{|w|}right) quad (5)
γi=yi(∥w∥w⋅xi+∥w∥b)(5)定义超平面
(
w
,
b
)
(w,b)
(w,b)关于训练数据集
T
T
T的函数间隔为超平面
(
w
,
b
)
(w,b)
(w,b)关于中所有样本点
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi)的几何间隔之最小值,即
γ
=
min
i
=
1
,
⋯
 
,
N
γ
i
(
6
)
gamma=min _{i=1, cdots, N} gamma_{i} quad(6)
γ=i=1,⋯,Nminγi(6)下图为函数间隔与几何间隔示例:
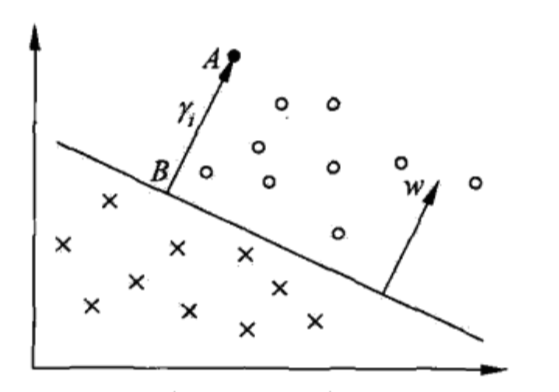
上图给出了超平面
(
w
,
b
)
(w,b)
(w,b)及其法向量
w
w
w,点
A
A
A表示某一实例
x
i
x_i
xi,其类标记
y
i
=
+
1
y_i=+1
yi=+1,点
A
A
A与超平面
(
w
,
b
)
(w,b)
(w,b)的距离由线段
A
B
AB
AB给出,记作
γ
i
gamma_i
γi,
γ
i
=
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
gamma_{i}=frac{w}{|w|} cdot x_{i}+frac{b}{|w|}
γi=∥w∥w⋅xi+∥w∥b其中,
∥
w
∥
|w|
∥w∥为
w
w
w的
L
2
L_2
L2范数,这是点
A
A
A在超平面正的一侧的情形,若点
A
A
A在超平面负的一侧,那么有
γ
i
=
−
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
gamma_{i}=-left(frac{w}{|w|} cdot x_{i}+frac{b}{|w|}right)
γi=−(∥w∥w⋅xi+∥w∥b)当样本点
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi)被超平面
(
w
,
b
)
(w,b)
(w,b)正确分类时,点
x
i
x_i
xi与超平面
(
w
,
b
)
(w,b)
(w,b)的距离是
γ
i
=
y
i
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
gamma_{i}=y_ileft(frac{w}{|w|} cdot x_{i}+frac{b}{|w|}right)
γi=yi(∥w∥w⋅xi+∥w∥b)
(2.2)函数间隔与几何间隔的关系
γ
i
=
γ
^
i
∥
w
∥
(
7
)
gamma_{i}=frac{hat{gamma}_{i}}{|{w}|} quad(7)
γi=∥w∥γ^i(7)
γ
=
γ
^
∥
w
∥
(
8
)
gamma=frac{hat{gamma}}{|w|}quad(8)
γ=∥w∥γ^(8)如果
∥
w
∥
=
1
|w|=1
∥w∥=1,那么函数间隔和几何间隔相等,如果超平面参数和成比例地改变(超平面没有改变),函数间隔也成比例改变,而几何间隔不变。实际上函数间隔
γ
^
i
=
y
i
(
w
⋅
x
i
+
b
)
=
y
i
f
i
(
x
)
hat{gamma}_{i}=y_{i}left(w cdot x_{i}+bright)=y_if_i(x)
γ^i=yi(w⋅xi+b)=yifi(x) 就是
∣
f
(
x
)
∣
|f(x)|
∣f(x)∣,只是人为定义的一个间隔度量;而几何间隔
γ
i
=
γ
^
i
∥
w
∥
=
∣
f
i
(
x
)
∣
∥
w
∥
gamma_{i}=frac{hat{gamma}_{i}}{|{w}|}=frac{|f_i(x)|}{|{w}|}
γi=∥w∥γ^i=∥w∥∣fi(x)∣才是直观上的点到超平面的距离.
点到平面距离公式:
d
=
∣
A
x
0
+
B
y
0
+
C
z
0
+
D
A
2
+
B
2
+
C
2
∣
d=left|frac{A x_{0}+B y_{0}+C z_{0}+D}{sqrt{A^{2}+B^{2}+C^{2}}}right|
d=∣∣∣A2+B2+C2Ax0+By0+Cz0+D∣∣∣
其中
(
x
0
,
y
0
,
z
0
)
(x_0,y_0,z_0)
(x0,y0,z0)为空间中一点,
A
x
+
B
y
+
C
z
+
D
=
0
Ax+By+Cz+D=0
Ax+By+Cz+D=0为平面方程,
d
d
d为点到平面的距离.
(2.3) 间隔最大化
假设将
w
w
w和
b
b
b按比例改变为
λ
a
lambda a
λa和
λ
b
lambda b
λb,这时函数间隔为
λ
γ
^
lambda hat{gamma}
λγ^,在超平面没有改变的情况下,函数间隔
γ
^
hat{gamma}
γ^可以任意大,因此函数间隔并不适合用来最大化一个量.几何间隔
γ
=
γ
^
∥
w
∥
gamma=frac{hat{gamma}}{|w|}
γ=∥w∥γ^就不会出现这样的问题.
支持向量机的基本思想是求解能够正确划分数据集和几何间隔最大的分离超平面.
间隔最大化:对数据集找个几何间隔最大化意味着以充分大的确信度对训练数据进行分类.我们希望最大化超平面
(
w
,
b
)
(w,b)
(w,b)关于训练数据集的几何间隔
γ
{gamma}
γ,约束条件表示的是超平面
(
w
,
b
)
(w,b)
(w,b)关于每个训练样本点的几何间隔至少是
γ
{gamma}
γ.
问题可以表示为下面的约束最优化问题:
max
w
,
b
γ
(
9
)
max _{w, b} quad gamma quad (9)
w,bmaxγ(9)
s.t.
y
i
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
⩾
γ
,
i
=
1
,
2
,
⋯
 
,
N
(
10
)
text { s.t. } quad y_{i}left(frac{w}{|w|} cdot x_{i}+frac{b}{|w|}right) geqslant gamma, quad i=1,2, cdots, N quad (10)
s.t. yi(∥w∥w⋅xi+∥w∥b)⩾γ,i=1,2,⋯,N(10) 由几何间隔和函数间隔的关系
γ
=
γ
^
∥
w
∥
gamma=frac{hat{gamma}}{|w|}
γ=∥w∥γ^,问题可以改写为
max
w
,
b
γ
^
∥
w
∥
(
11
)
max _{w, b} quad frac{hat{gamma}}{|w|} quad (11)
w,bmax∥w∥γ^(11)
s.t.
y
i
(
w
⋅
x
i
+
b
)
⩾
γ
^
,
i
=
1
,
2
,
⋯
 
,
N
(
12
)
text { s.t. } quad y_{i}left(w cdot x_{i}+bright) geqslant hat{gamma}, quad i=1,2, cdots, N quad (12)
s.t. yi(w⋅xi+b)⩾γ^,i=1,2,⋯,N(12)函数间隔
γ
^
hat{gamma}
γ^的取值并不影响最优化问题的解。
假设将
w
w
w和
b
b
b按比例改变为
λ
a
lambda a
λa和
λ
b
lambda b
λb,这时函数间隔为
λ
γ
^
lambda hat{gamma}
λγ^,而函数间隔的改变对最优化问题的不等式约束无影响,对目标函数的优化也没有影响,这样就可以取
γ
^
=
1
hat{gamma} =1
γ^=1,将
γ
^
=
1
hat{gamma} =1
γ^=1带入上面的优化问题
(
11
)
(11)
(11),由于最大化
1
∥
w
∥
frac{1}{|{w}|}
∥w∥1和最小化
1
2
∥
w
∥
2
frac{1}{2}|w|^{2}
21∥w∥2是等价的,因此可得到下面的最优化问题
min
w
,
b
1
2
∥
w
∥
2
(
13
)
min _{w, b}quad frac{1}{2}|w|^{2} quad(13)
w,bmin21∥w∥2(13)
s.t.
y
i
(
w
⋅
x
i
+
b
)
−
1
⩾
0
,
i
=
1
,
2
,
⋯
 
,
N
(
14
)
text { s.t. } quad y_{i}left(w cdot x_{i}+bright)-1 geqslant 0, quad i=1,2, cdots, N quad(14)
s.t. yi(w⋅xi+b)−1⩾0,i=1,2,⋯,N(14)这是一个凸二次规划问题.
凸优化问题是指约束最优化问题
min
w
f
(
w
)
(
15
)
min _{w} f(w) quad(15)
wminf(w)(15)
s.t.
g
i
(
w
)
⩽
0
,
i
=
1
,
2
,
⋯
 
,
k
(
16
)
text { s.t. } quad g_{i}(w) leqslant 0, quad i=1,2, cdots, k quad(16)
s.t. gi(w)⩽0,i=1,2,⋯,k(16)
h
i
(
w
)
=
0
,
i
=
1
,
2
,
⋯
 
,
l
(
17
)
h_{i}(w)=0, quad i=1,2, cdots, l quad(17)
hi(w)=0,i=1,2,⋯,l(17)其中,目标函数
f
(
w
)
f(w)
f(w)和约束函数
g
i
(
w
)
g_i(w)
gi(w)都是
R
n
R^n
Rn上的连续可微的凸函数,约束函数
h
i
(
w
)
h_i(w)
hi(w)是
R
n
R^n
Rn上的仿射函数,当目标函数
f
(
w
)
f(w)
f(w)是二次函数且约束函数
g
i
(
w
)
g_i(w)
gi(w)是仿射函数是,上述凸最优化问题称为凸二次规划问题.
最大间隔分离超平面的存在唯一性
定理1(最大间隔分离超平面的存在唯一性) 若训练数据集线性可分,则将训练数据集中的样本点完全正确分开的最大间隔分离超平面存在且唯一.
证明:(1)存在性 (2)唯一性
(2.4) 支持向量和间隔边界
在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点点实例称为支持向量,支持向量是使约束条件式等号成立的点,即 y i ( w ⋅ x i + b ) − 1 = 0 y_{i}left(w cdot x_{i}+bright)-1=0 yi(w⋅xi+b)−1=0.
- 对 y i = + 1 y_{i}=+1 yi=+1的正例点,支持向量在超平面 H 1 : w ⋅ x + b = 1 H_{1} : w cdot x+b=1 H1:w⋅x+b=1上
- 对 y i = − 1 y_{i}=-1 yi=−1的负例点,支持向量在超平面 H 2 : w ⋅ x + b = − 1 H_{2} : w cdot x+b=-1 H2:w⋅x+b=−1上
注意到
H
1
H_1
H1和
H
2
H_2
H2平行,在
H
1
H_1
H1和
H
2
H_2
H2之间形成一条长带,分离超平面与它们平行且位于它们中央,即
H
1
H_1
H1和
H
2
H_2
H2之间的距离成为间隔,间隔依赖于分离超平面的法向量
w
w
w,等于
2
∥
w
∥
frac{2}{|{w}|}
∥w∥2,
H
1
H_1
H1和
H
2
H_2
H2称为间隔边界.
在决定分离超平面时只有支持向量起作用,而其他实例点并不起作用。支持向量在确定分离超平面起着决定性作用,所以将这种分类模型称为支持向量机。支持向量的个数一般很少,所以支持向量机由很少的重要的训练样本确定。
3. 对偶算法
通过求解对偶问题得到原始问题的最优解,这就是线性可分支持向量机的对偶算法,其优点,一是对偶问题更容易求解. 二是自然引入核函数,进而推广到非线性分离问题
min
w
,
b
1
2
∥
w
∥
2
min _{w, b}quad frac{1}{2}|w|^{2}
w,bmin21∥w∥2
s.t.
y
i
(
w
⋅
x
i
+
b
)
−
1
⩾
0
,
i
=
1
,
2
,
⋯
 
,
N
text { s.t. } quad y_{i}left(w cdot x_{i}+bright)-1 geqslant 0, quad i=1,2, cdots, N
s.t. yi(w⋅xi+b)−1⩾0,i=1,2,⋯,N对上述不等式约束
(
14
)
(14)
(14)引进拉格朗日乘子
α
i
⩾
0
,
i
=
1
,
2
,
⋯
 
,
N
alpha_{i} geqslant 0, quad i=1,2, cdots, N
αi⩾0,i=1,2,⋯,N,定义拉格朗日数:
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
−
∑
i
=
1
N
α
i
y
i
(
w
⋅
x
i
+
b
)
+
∑
i
=
1
N
α
i
(
18
)
L(w, b, alpha)=frac{1}{2}|w|^{2}-sum_{i=1}^{N} alpha_{i} y_{i}left(w cdot x_{i}+bright)+sum_{i=1}^{N} alpha_{i} quad(18)
L(w,b,α)=21∥w∥2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi(18)根据拉格朗日对偶性,原始问题的对偶问题是极大极小问题:
max
α
min
w
,
b
L
(
w
,
b
,
α
)
max _{alpha} min _{w, b} L(w, b, alpha)
αmaxw,bminL(w,b,α)所以,为得到对偶问题的解,需要先求
L
(
w
,
b
,
α
)
L(w, b, alpha)
L(w,b,α)对
w
,
b
w,b
w,b的极小,再求对
α
alpha
α的极大.
1)求
min
w
,
b
L
(
w
,
b
,
α
)
min _{w, b} L(w, b, alpha)
minw,bL(w,b,α), 将拉格朗日函数分别对
w
,
b
w,b
w,b求偏导数并令其等于0
∇
w
L
(
w
,
b
,
α
)
=
w
−
∑
i
=
1
N
α
i
y
i
x
i
=
0
nabla_{w} L(w, b, alpha)=w-sum_{i=1}^{N} alpha_{i} y_{i} x_{i}=0
∇wL(w,b,α)=w−i=1∑Nαiyixi=0
∇
b
L
(
w
,
b
,
α
)
=
∑
i
=
1
N
α
i
y
i
=
0
nabla_{b} L(w, b, alpha)=sum_{i=1}^{N} alpha_{i} y_{i}=0
∇bL(w,b,α)=i=1∑Nαiyi=0得
w
=
∑
i
=
1
N
α
i
y
i
x
i
w=sum_{i=1}^{N} alpha_{i} y_{i} x_{i}
w=i=1∑Nαiyixi
∑
i
=
1
N
α
i
y
i
=
0
sum_{i=1}^{N} alpha_{i} y_{i}=0
i=1∑Nαiyi=0将上两式
(
19
)
(19)
(19)带入
(
18
)
(18)
(18),并利用
(
20
)
(20)
(20)即得
L
(
w
,
b
,
α
)
=
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
y
i
(
(
∑
j
=
1
N
α
j
y
j
x
j
)
⋅
x
i
+
b
)
+
∑
i
=
1
N
α
i
L(w, b, alpha)=frac{1}{2} sum_{i=1}^{N} sum_{j=1}^{N} alpha_{i} alpha_{j} y_{i} y_{j}left(x_{i} cdot x_{j}right)-sum_{i=1}^{N} alpha_{i} y_{i}left(left(sum_{j=1}^{N} alpha_{j} y_{j} x_{j}right) cdot x_{i}+bright)+sum_{i=1}^{N} alpha_{i}
L(w,b,α)=21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαiyi((j=1∑Nαjyjxj)⋅xi+b)+i=1∑Nαi
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
=-frac{1}{2} sum_{i=1}^{N} sum_{j=1}^{N} alpha_{i} alpha_{j} y_{i} y_{j}left(x_{i} cdot x_{j}right)+sum_{i=1}^{N} alpha_{i}
=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi即
min
w
,
b
L
(
w
,
b
,
α
)
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
min _{w, b} L(w, b, alpha)=-frac{1}{2} sum_{i=1}^{N} sum_{j=1}^{N} alpha_{i} alpha_{j} y_{i} y_{j}left(x_{i} cdot x_{j}right)+sum_{i=1}^{N} alpha_{i}
w,bminL(w,b,α)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
2) 求
min
w
,
b
L
(
w
,
b
,
α
)
min _{w, b} L(w, b, alpha)
minw,bL(w,b,α)对
α
alpha
α的极大,即是对偶问题
max
α
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
max _{alpha}-frac{1}{2} sum_{i=1}^{N} sum_{j=1}^{N} alpha_{i} alpha_{j} y_{i} y_{j}left(x_{i} cdot x_{j}right)+sum_{i=1}^{N} alpha_{i}
αmax−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
s.t.
∑
i
=
1
N
α
i
y
i
=
0
text { s.t. } sum_{i=1}^{N} alpha_{i} y_{i}=0
s.t. i=1∑Nαiyi=0
α
i
⩾
0
,
i
=
1
,
2
,
⋯
 
,
N
alpha_{i} geqslant 0, quad i=1,2, cdots, N
αi⩾0,i=1,2,⋯,N上式等价为
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
min _{alpha} frac{1}{2} sum_{i=1}^{N} sum_{j=1}^{N} alpha_{i} alpha_{j} y_{i} y_{j}left(x_{i} cdot x_{j}right)-sum_{i=1}^{N} alpha_{i}
αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
s.t.
∑
i
=
1
N
α
i
y
i
=
0
text { s.t. } sum_{i=1}^{N} alpha_{i} y_{i}=0
s.t. i=1∑Nαiyi=0
原始问题满足《拉格朗日对偶性》中定理2的条件,所以存在
w
∗
,
α
∗
,
β
∗
w^{*}, alpha^{*}, beta^{*}
w∗,α∗,β∗,使
w
∗
w^*
w∗是原始问题的解,
α
∗
,
β
∗
alpha^{*}, beta^{*}
α∗,β∗是对偶问题的解,因此原始问题可以转换为对偶问题求解。对线性可分训练数据集,假设对偶优化问题对
α
alpha
α的解为
α
∗
=
(
α
1
∗
,
α
2
∗
,
⋯
 
,
α
N
∗
)
T
alpha^{*}=left(alpha_{1}^{*}, alpha_{2}^{*}, cdots, alpha_{N}^{*}right)^{mathrm{T}}
α∗=(α1∗,α2∗,⋯,αN∗)T,可以由
α
∗
alpha^{*}
α∗求得原始优化问题对
(
w
,
b
)
(w,b)
(w,b)的解
w
∗
,
b
∗
w^*,b^*
w∗,b∗.有下面定理
定理2 设
α
∗
=
(
α
1
∗
,
α
2
∗
,
⋯
 
,
α
N
∗
)
T
alpha^{*}=left(alpha_{1}^{*}, alpha_{2}^{*}, cdots, alpha_{N}^{*}right)^{mathrm{T}}
α∗=(α1∗,α2∗,⋯,αN∗)T是对偶最优化问题
(
22
)
∼
(
24
)
(22) sim(24)
(22)∼(24)的解,则寻在下标
j
j
j,使得
α
j
∗
>
0
alpha_j ^*>0
αj∗>0,并可按下是求的原始优化问题
(
13
)
∼
(
14
)
(13) sim(14)
(13)∼(14)的解
w
∗
,
b
∗
w^*,b^*
w∗,b∗:
w
∗
=
∑
i
=
1
N
α
i
∗
y
i
x
i
(
25
)
w^{*}=sum_{i=1}^{N} alpha_{i}^{*} y_{i} x_{i}quad (25)
w∗=i=1∑Nαi∗yixi(25)
b
∗
=
y
j
−
∑
i
=
1
N
α
i
∗
y
i
(
x
i
⋅
x
j
)
(
26
)
b^{*}=y_{j}-sum_{i=1}^{N} alpha_{i}^{*} y_{i}left(x_{i} cdot x_{j}right) quad(26)
b∗=yj−i=1∑Nαi∗yi(xi⋅xj)(26)证明:根据《拉格朗日对偶性》定理3,KKT条件成立,即得
∇
w
L
(
w
∗
,
b
∗
,
α
∗
)
=
w
∗
−
∑
i
=
1
N
α
i
∗
y
i
x
i
=
0
nabla_{w} Lleft(w^{*}, b^{*}, alpha^{*}right)=w^{*}-sum_{i=1}^{N} alpha_{i}^{*} y_{i} x_{i}=0
∇wL(w∗,b∗,α∗)=w∗−i=1∑Nαi∗yixi=0
∇
b
L
(
w
∗
,
b
∗
,
α
∗
)
=
−
∑
i
=
1
N
α
i
∗
y
i
=
0
nabla_{b} Lleft(w^{*}, b^{*}, alpha^{*}right)=-sum_{i=1}^{N} alpha_{i}^{*} y_{i}=0
∇bL(w∗,b∗,α∗)=−i=1∑Nαi∗yi=0
α
i
∗
(
y
i
(
w
∗
⋅
x
i
+
b
∗
)
−
1
)
=
0
,
i
=
1
,
2
,
⋯
 
,
N
alpha_{i}^{*}left(y_{i}left(w^{*} cdot x_{i}+b^{*}right)-1right)=0, quad i=1,2, cdots, N
αi∗(yi(w∗⋅xi+b∗)−1)=0,i=1,2,⋯,N
y
i
(
w
∗
⋅
x
i
+
b
∗
)
−
1
⩾
0
,
i
=
1
,
2
,
⋯
 
,
N
y_{i}left(w^{*} cdot x_{i}+b^{*}right)-1 geqslant 0, quad i=1,2, cdots, N
yi(w∗⋅xi+b∗)−1⩾0,i=1,2,⋯,N
α
i
∗
⩾
0
,
i
=
1
,
2
,
⋯
 
,
N
alpha_{i}^{*} geqslant 0, quad i=1,2, cdots, N
αi∗⩾0,i=1,2,⋯,N由此得
w
∗
=
∑
i
α
i
∗
y
i
x
i
w^{*}=sum_{i} alpha_{i}^{*} y_{i} x_{i}
w∗=∑iαi∗yixi
其中至少有一个
α
j
∗
>
0
alpha_{j}^{*}>0
αj∗>0(反证法,假设
α
∗
=
0
alpha^{*}=0
α∗=0,可知
w
∗
=
0
w^*=0
w∗=0,而
w
∗
=
0
w^*=0
w∗=0不是约束最优化问题的解,产生矛盾),因此对
j
j
j有,
y
j
(
w
∗
⋅
x
j
+
b
∗
)
−
1
=
0
(
28
)
y_{j}left(w^{*} cdot x_{j}+b^{*}right)-1=0 quad(28)
yj(w∗⋅xj+b∗)−1=0(28)将
(
25
)
(25)
(25)带入
(
28
)
(28)
(28)并注意到
y
j
2
=
1
y_{j}^{2}=1
yj2=1,即得
b
∗
=
y
j
−
∑
i
=
1
N
α
i
∗
y
i
(
x
i
⋅
x
j
)
b^{*}=y_{j}-sum_{i=1}^{N} alpha_{i}^{*} y_{i}left(x_{i} cdot x_{j}right)
b∗=yj−∑i=1Nαi∗yi(xi⋅xj)由此定理,分离超平面可以写成
∑
i
=
1
N
α
i
∗
y
i
(
x
⋅
x
i
)
+
b
∗
=
0
(
29
)
sum_{i=1}^{N} alpha_{i}^{*} y_{i}left(x cdot x_{i}right)+b^{*}=0 quad(29)
i=1∑Nαi∗yi(x⋅xi)+b∗=0(29)分类决策函数可以写成
f
(
x
)
=
sign
(
∑
i
=
1
N
α
i
∗
y
i
(
x
⋅
x
i
)
+
b
∗
)
(
30
)
f(x)=operatorname{sign}left(sum_{i=1}^{N} alpha_{i}^{*} y_{i}left(x cdot x_{i}right)+b^{*}right) quad(30)
f(x)=sign(i=1∑Nαi∗yi(x⋅xi)+b∗)(30)
参考:李航 《统计学习方法》
July 《支持向量机通俗导论 ——理解SVM的三层境界》
https://blog.csdn.net/v_july_v/article/details/7624837
最后
以上就是顺利面包最近收集整理的关于支持向量机SVM(1)-线性可分支持向量机的全部内容,更多相关支持向量机SVM(1)-线性可分支持向量机内容请搜索靠谱客的其他文章。








发表评论 取消回复