3.3 对数几率回归
针对二分类的分类模型中
给出 x x x希望模型得到的 f ( x ) f(x) f(x)代表正样本的概率
线性回归: f ( x ) ∈ R f(x) in R f(x)∈R
分类回归: f ( x ) ∈ [ 0 , 1 ] f(x)in[0,1] f(x)∈[0,1]
分类任务下使用线性回归
- 可以使用单调可微函数将分类任务的真实标记 y y y与线性回归模型的预测值联系起来
- 例,可使用单位阶跃函数
- 相当于给线性回归的函数套了一个映射函数
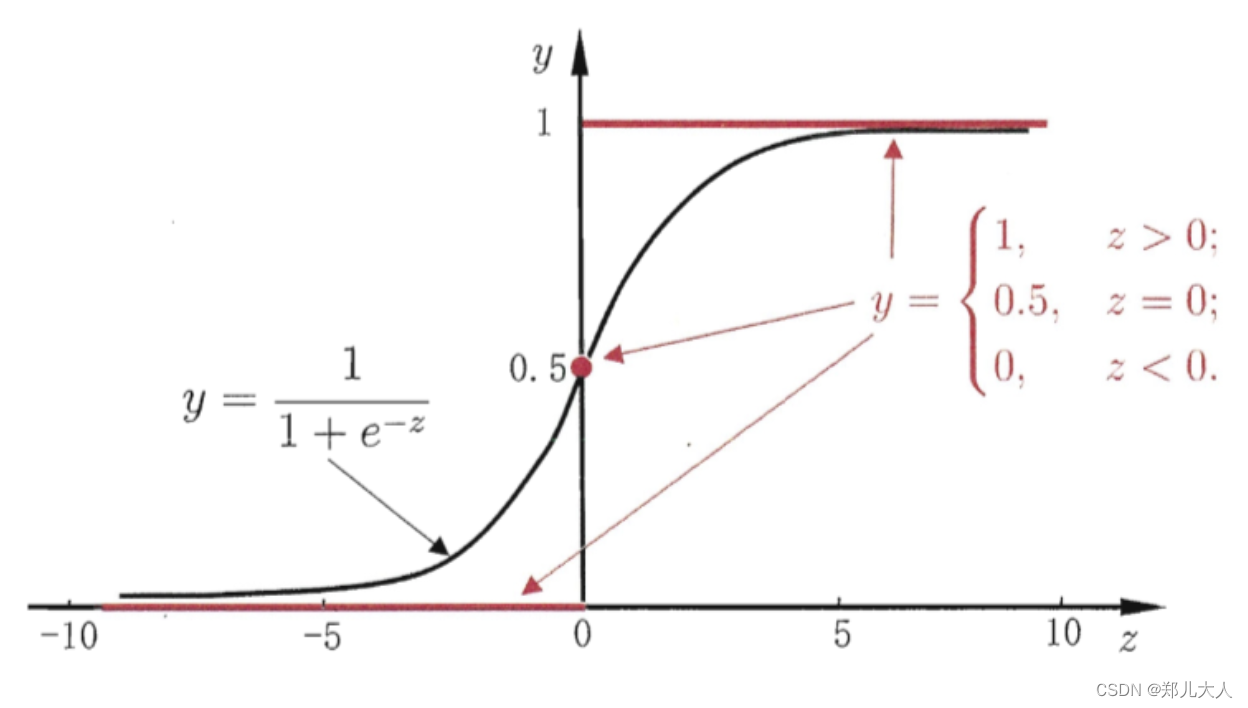
单位阶跃函数
Heaviside函数
例:
y = { 0 , z < 0 0.5 , z = 0 1 , z > 0 y=left{begin{array}{cc} 0, & z<0 \ 0.5, & z=0 \ 1, & z>0 end{array}right. y=⎩ ⎨ ⎧0,0.5,1,z<0z=0z>0
在这种情况下,若预测值 z z z大于0就判定为正例,小于0就判定为反例,预测值为临界值0则可以任意判别
存在的问题:单位阶跃函数不连续,不能直接使用 g − ( ⋅ ) g^{-}(cdot) g−(⋅)
对数几率函数
logistic function
简称”对率函数"
y = 1 1 + e − z y=frac{1}{1+e^{-z}} y=1+e−z1
y = 1 1 + e − ( w T x + b ) y=frac{1}{1+e^{-left(boldsymbol{w}^{mathrm{T}} boldsymbol{x}+bright)}} y=1+e−(wTx+b)1
特点
- 单调可微
- 一定程度上近似单位阶跃函数
- 一种"Sigmoid"函数
- 形似S的函数
- 对率函数是Sigmoid函数的重要代表
- 严格是取不到0,1的
对数几率函数原理
1)对数几率
将对数几率函数进一步变形
ln y 1 − y = w T x + b ln frac{y}{1-y}=boldsymbol{w}^{mathrm{T}} boldsymbol{x}+b ln1−yy=wTx+b
其中 y y y视为样本 x x x为正例的可能性, y − 1 y-1 y−1为反例的可能性,则二者的比值称为几率:
y 1 − y frac{y}{1-y} 1−yy
- “几率” ( odds ) 反映了 x x x作为正例的相对可能性
- 将几率取对数得到的称为"对数几率" (log odds, logit)
- ln y 1 − y ln frac{y}{1-y} ln1−yy
所以实际上这个过程是用线性回归模型的预测结果去逼近真实标记的对数几率
故对应的模型称为**“对数几率回归”(logistic regression, logit regression)**
- 虽然名称是回归,但是做的是回归算法
- 有的文献中译为逻辑回归
2)最大熵原理
对数几率函数的优点
- 直接对分类可能性进行建模,无需事先假设数据分布
- 得到了近似概率的预测,既包含了类别信息,又可以辅助利用概率进行决策的任务
- 很好的数学性质,有任意阶可导的凸函数
单位阶跃函数 v.s. 对数几率函数
损失函数的推导
极大似然估计角度
步骤
- 确定概率密度质量函数
- 写出似然函数
概率密度函数
针对不同样本,真实标记有两种情况0和1
在给定 x x x的情况下,模型针对 y = 1 y=1 y=1和 y = 0 y=0 y=0的预测概率结果分别为:
p ( y = 1 ∣ x ) = 1 1 + e − ( w T x + b ) = e w T x + b 1 + e w T x + b p ( y = 0 ∣ x ) = 1 − p ( y = 1 ∣ x ) = 1 1 + e w T x + b begin{array}{l} p(y=1 mid boldsymbol{x})=frac{1}{1+e^{-left(boldsymbol{w}^{mathrm{T}} boldsymbol{x}+bright)}}=frac{e^{boldsymbol{w}^{mathrm{T}} boldsymbol{x}+b}}{1+e^{boldsymbol{w}^{mathrm{T}} boldsymbol{x}+b}} \ p(y=0 mid boldsymbol{x})=1-p(y=1 mid boldsymbol{x})=frac{1}{1+e^{boldsymbol{w}^{mathrm{T}} boldsymbol{x}+b}} end{array} p(y=1∣x)=1+e−(wTx+b)1=1+ewTx+bewTx+bp(y=0∣x)=1−p(y=1∣x)=1+ewTx+b1
对式子进行化简, β = ( w ; b ) , x ^ = ( x ; 1 ) boldsymbol{beta}=(boldsymbol{w} ; b), hat{boldsymbol{x}}=(boldsymbol{x} ; 1) β=(w;b),x^=(x;1),得到结果
p ( y = 1 ∣ x ^ ; β ) = e β T x ^ 1 + e β T x ^ = p 1 ( x ^ ; β ) p ( y = 0 ∣ x ^ ; β ) = 1 1 + e β T x ^ = p 0 ( x ^ ; β ) begin{array}{l} p(y=1 mid hat{boldsymbol{x}} ; boldsymbol{beta})=frac{e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}}}{1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}}}=p_{1}(hat{boldsymbol{x}} ; boldsymbol{beta}) \ p(y=0 mid hat{boldsymbol{x}} ; boldsymbol{beta})=frac{1}{1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}}}=p_{0}(hat{boldsymbol{x}} ; boldsymbol{beta}) end{array} p(y=1∣x^;β)=1+eβTx^eβTx^=p1(x^;β)p(y=0∣x^;β)=1+eβTx^1=p0(x^;β)
由于我们只关心预测真实标记的概率情况,所以针对单个样本的概率质量函数为:
p ( y ∣ x ^ ; β ) = y ⋅ p 1 ( x ^ ; β ) + ( 1 − y ) ⋅ p 0 ( x ^ ; β ) p(y mid hat{boldsymbol{x}} ; boldsymbol{beta})=y cdot p_{1}(hat{boldsymbol{x}} ; boldsymbol{beta})+(1-y) cdot p_{0}(hat{boldsymbol{x}} ; boldsymbol{beta}) p(y∣x^;β)=y⋅p1(x^;β)+(1−y)⋅p0(x^;β)
或者
p ( y ∣ x ^ ; β ) = [ p 1 ( x ^ ; β ) ] y [ p 0 ( x ^ ; β ) ] 1 − y p(y mid hat{boldsymbol{x}} ; boldsymbol{beta})=left[p_{1}(hat{boldsymbol{x}} ; boldsymbol{beta})right]^{y}left[p_{0}(hat{boldsymbol{x}} ; boldsymbol{beta})right]^{1-y} p(y∣x^;β)=[p1(x^;β)]y[p0(x^;β)]1−y
似然函数
考虑 m m m的样本
L ( β ) = ∏ i = 1 m p ( y i ∣ x ^ i ; β ) L(boldsymbol{beta})=prod_{i=1}^{m} pleft(y_{i} mid hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right) L(β)=i=1∏mp(yi∣x^i;β)
将似然函数进行转换
ℓ
(
β
)
=
ln
L
(
β
)
=
∑
i
=
1
m
ln
p
(
y
i
∣
x
^
i
;
β
)
ℓ
(
β
)
=
∑
i
=
1
m
ln
(
y
i
p
1
(
x
^
i
;
β
)
+
(
1
−
y
i
)
p
0
(
x
^
i
;
β
)
)
begin{array}{c} ell(boldsymbol{beta})=ln L(boldsymbol{beta})=sum_{i=1}^{m} ln pleft(y_{i} mid hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right) \ ell(boldsymbol{beta})=sum_{i=1}^{m} ln left(y_{i} p_{1}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)+left(1-y_{i}right) p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)right) end{array}
ℓ(β)=lnL(β)=∑i=1mlnp(yi∣x^i;β)ℓ(β)=∑i=1mln(yip1(x^i;β)+(1−yi)p0(x^i;β))
将
p
1
(
x
^
i
;
β
)
=
e
β
T
x
^
i
1
+
e
β
T
x
^
i
,
p
0
(
x
^
i
;
β
)
=
1
1
+
e
β
T
x
^
i
p_{1}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)=frac{e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}}{1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}}, p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)=frac{1}{1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}}
p1(x^i;β)=1+eβTx^ieβTx^i,p0(x^i;β)=1+eβTx^i1代入上式可得
ℓ
(
β
)
=
∑
i
=
1
m
ln
(
y
i
e
β
T
x
^
i
1
+
e
β
T
x
^
i
+
1
−
y
i
1
+
e
β
T
x
^
i
)
=
∑
i
=
1
m
ln
(
y
i
e
β
T
x
^
i
+
1
−
y
i
1
+
e
β
T
x
^
i
)
=
∑
i
=
1
m
(
ln
(
y
i
e
β
T
x
^
i
+
1
−
y
i
)
−
ln
(
1
+
e
β
T
x
^
i
)
)
begin{array}{l} ell(boldsymbol{beta})=sum_{i=1}^{m} ln left(frac{y_{i} e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}}{1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}}+frac{1-y_{i}}{1+e^{boldsymbol{beta}^{mathrm{T}}} hat{boldsymbol{x}}_{i}}right)\ =sum_{i=1}^{m} ln left(frac{y_{i} e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}+1-y_{i}}{1+e^{boldsymbol{beta}^{mathrm{T}}} hat{boldsymbol{x}}_{i}}right)\ =sum_{i=1}^{m}left(ln left(y_{i} e^{beta^{mathrm{T}} hat{boldsymbol{x}}_{i}}+1-y_{i}right)-ln left(1+e^{beta^{mathrm{T}} hat{boldsymbol{x}}_{i}}right)right) end{array}
ℓ(β)=∑i=1mln(1+eβTx^iyieβTx^i+1+eβTx^i1−yi)=∑i=1mln(1+eβTx^iyieβTx^i+1−yi)=∑i=1m(ln(yieβTx^i+1−yi)−ln(1+eβTx^i))
将 y i y_i yi等于1或者0代入,得到
ℓ ( β ) = { ∑ i = 1 m ( − ln ( 1 + e β T x ^ i ) ) , y i = 0 ∑ i = 1 m ( β T x ^ i − ln ( 1 + e β T x ^ i ) ) , y i = 1 ell(boldsymbol{beta})=left{begin{array}{ll} sum_{i=1}^{m}left(-ln left(1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}right)right), & y_{i}=0 \ sum_{i=1}^{m}left(boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}-ln left(1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}right)right), & y_{i}=1 end{array}right. ℓ(β)=⎩ ⎨ ⎧∑i=1m(−ln(1+eβTx^i)),∑i=1m(βTx^i−ln(1+eβTx^i)),yi=0yi=1
将两个式子进行综合得到
ℓ ( β ) = ∑ i = 1 m ( y i β T x ^ i − ln ( 1 + e β T x ^ i ) ) ell(boldsymbol{beta})=sum_{i=1}^{m}left(y_{i} boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}-ln left(1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}right)right) ℓ(β)=i=1∑m(yiβTx^i−ln(1+eβTx^i))
通常损失函数是以最小化为优化目标
所以可以将式子取相反数,得到损失函数的优化目标为
ℓ ( β ) = − ∑ i = 1 m ( y i β T x ^ i − ln ( 1 + e β T x ^ i ) ) ell(boldsymbol{beta})=-sum_{i=1}^{m}left(y_{i} boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}-ln left(1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}right)right) ℓ(β)=−i=1∑m(yiβTx^i−ln(1+eβTx^i))
信息论角度
自信息
I ( X ) = − log b p ( x ) I(X)=-log _{b} p(x) I(X)=−logbp(x)
当 b = 2 b=2 b=2时单位为bit,当 b = e b=e b=e时单位为nat
信息熵
H ( X ) = E [ I ( X ) ] = − ∑ x p ( x ) log b p ( x ) H(X)=E[I(X)]=-sum_{x} p(x) log _{b} p(x) H(X)=E[I(X)]=−x∑p(x)logbp(x)
(离散型信息熵)
自信息的期望
度量随机变量 X X X的不确定性,信息熵越大越不确定
约定:若 p ( x ) = 0 p(x)=0 p(x)=0,则 p ( x ) log b p ( x ) = 0 p(x) log _{b} p(x)=0 p(x)logbp(x)=0
相对熵 ( KL散度 )
D K L ( p ∥ q ) = ∑ x p ( x ) log b ( p ( x ) q ( x ) ) = ∑ x p ( x ) ( log b p ( x ) − log b q ( x ) ) = ∑ x p ( x ) log b p ( x ) − ∑ x p ( x ) log b q ( x ) begin{aligned} D_{K L}(p | q) &=sum_{x} p(x) log _{b}left(frac{p(x)}{q(x)}right) \ &=sum_{x} p(x)left(log _{b} p(x)-log _{b} q(x)right) \ &=sum_{x} p(x) log _{b} p(x)-sum_{x} p(x) log _{b} q(x) end{aligned} DKL(p∥q)=x∑p(x)logb(q(x)p(x))=x∑p(x)(logbp(x)−logbq(x))=x∑p(x)logbp(x)−x∑p(x)logbq(x)
其中 − ∑ x p ( x ) log b q ( x ) -sum_{x} p(x) log _{b} q(x) −∑xp(x)logbq(x)称为交叉熵
求和的含义是遍历 x x x所有的值
度量两个分布的差异
典型使用场景,度量理想分布 p ( x ) p(x) p(x)和模拟分布 q ( x ) q(x) q(x)之间的差异
优化原理
- 理想分布最接近的模拟分布即为最优分布
- 因此可以通过最小化相对熵这个策略来求出最优分布
- 理想分布 p ( x ) p(x) p(x)是未知但固定,所以 ∑ x p ( x ) log b p ( x ) sum_{x} p(x) log _{b} p(x) ∑xp(x)logbp(x)为常量
- 最小化相对熵就等价于最小化交叉熵
以对数几率回归为例,对单个样本 y i y_i yi来说,它的理想分布是
p ( y i ) = { p ( 1 ) = 1 , p ( 0 ) = 0 , y i = 1 p ( 1 ) = 0 , p ( 0 ) = 1 , y i = 0 pleft(y_{i}right)=left{begin{array}{ll} p(1)=1, p(0)=0, & y_{i}=1 \ p(1)=0, p(0)=1, & y_{i}=0 end{array}right. p(yi)={p(1)=1,p(0)=0,p(1)=0,p(0)=1,yi=1yi=0
现在模型的模拟分布是
q ( y i ) = { e β T x ^ 1 + e β T x ^ = p 1 ( x ^ ; β ) , y i = 1 1 1 + e β T = p 0 ( x ^ ; β ) , y i = 0 qleft(y_{i}right)=left{begin{array}{ll} frac{e^{beta^{mathrm{T}} hat{x}}}{1+e^{beta^{mathrm{T}} hat{x}}}=p_{1}(hat{boldsymbol{x}} ; boldsymbol{beta}), & y_{i}=1 \ frac{1}{1+e^{beta^{mathrm{T}}}}=p_{0}(hat{boldsymbol{x}} ; boldsymbol{beta}), & y_{i}=0 end{array}right. q(yi)={1+eβTx^eβTx^=p1(x^;β),1+eβT1=p0(x^;β),yi=1yi=0
对于单个样本 y i y_i yi的交叉熵为
− ∑ y i p ( y i ) log b q ( y i ) -sum_{y_{i}} pleft(y_{i}right) log _{b} qleft(y_{i}right) −yi∑p(yi)logbq(yi)
将模型的预测结果进行代入
− p ( 1 ) ⋅ log b p 1 ( x ^ ; β ) − p ( 0 ) ⋅ log b p 0 ( x ^ ; β ) -p(1) cdot log _{b} p_{1}(hat{boldsymbol{x}} ; boldsymbol{beta})-p(0) cdot log _{b} p_{0}(hat{boldsymbol{x}} ; boldsymbol{beta}) −p(1)⋅logbp1(x^;β)−p(0)⋅logbp0(x^;β)
同时令 b = e b=e b=e
− y i ln p 1 ( x ^ ; β ) − ( 1 − y i ) ln p 0 ( x ^ ; β ) -y_{i} ln p_{1}(hat{boldsymbol{x}} ; boldsymbol{beta})-left(1-y_{i}right) ln p_{0}(hat{boldsymbol{x}} ; boldsymbol{beta}) −yilnp1(x^;β)−(1−yi)lnp0(x^;β)
全体训练样本的交叉熵为
∑ i = 1 m [ − y i ln p 1 ( x ^ i ; β ) − ( 1 − y i ) ln p 0 ( x ^ i ; β ) ] ∑ i = 1 m { − y i [ ln p 1 ( x ^ i ; β ) − ln p 0 ( x ^ i ; β ) ] − ln ( p 0 ( x ^ i ; β ) ) } ∑ i = 1 m [ − y i ln ( p 1 ( x ^ i ; β ) p 0 ( x ^ i ; β ) ) − ln ( p 0 ( x ^ i ; β ) ) ] begin{aligned} operatorname{} & sum_{i=1}^{m}left[-y_{i} ln p_{1}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)-left(1-y_{i}right) ln p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)right] \ &sum_{i=1}^{m}left{-y_{i}left[ln p_{1}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)-ln p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)right]-ln left(p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)right)right} \ & sum_{i=1}^{m}left[-y_{i} ln left(frac{p_{1}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)}{p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)}right)-ln left(p_{0}left(hat{boldsymbol{x}}_{i} ; boldsymbol{beta}right)right)right] \ end{aligned} i=1∑m[−yilnp1(x^i;β)−(1−yi)lnp0(x^i;β)]i=1∑m{−yi[lnp1(x^i;β)−lnp0(x^i;β)]−ln(p0(x^i;β))}i=1∑m[−yiln(p0(x^i;β)p1(x^i;β))−ln(p0(x^i;β))]
将具体的式子代入后得到
∑ i = 1 m [ − y i ln ( e β T x ^ 1 + e β T x ^ 1 1 + e β T x ^ ) − ln ( 1 1 + e β T x ^ ) ] sum_{i=1}^{m}left[-y_{i} ln left(frac{frac{e^{beta^{mathrm{T}} hat{boldsymbol{x}}}}{1+e^{beta^{mathrm{T}} hat{boldsymbol{x}}}}}{frac{1}{1+e^{beta^{mathrm{T}} hat{x}}}}right)-ln left(frac{1}{1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}}}right)right] i=1∑m⎣ ⎡−yiln⎝ ⎛1+eβTx^11+eβTx^eβTx^⎠ ⎞−ln(1+eβTx^1)⎦ ⎤
经整理后得到
∑ i = 1 m ( − y i β T x ^ i + ln ( 1 + e β T x ^ i ) ) sum_{i=1}^{m}left(-y_{i} boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}+ln left(1+e^{boldsymbol{beta}^{mathrm{T}} hat{boldsymbol{x}}_{i}}right)right) i=1∑m(−yiβTx^i+ln(1+eβTx^i))
可以发现这两种角度下得到的损失函数结果是相同的
3.4 线性判别分析
Linear Discriminant Analysis ( LDA )
LDA思想
- 将样例投射到一条直线上
- 样例之间的关系
- 同类样例的投影点尽可能接近
- 异类样例的投影点尽可能远离
- 对于新样本进行分类时,投射到同样的直线上,根据投影点位置确定新样本的类别
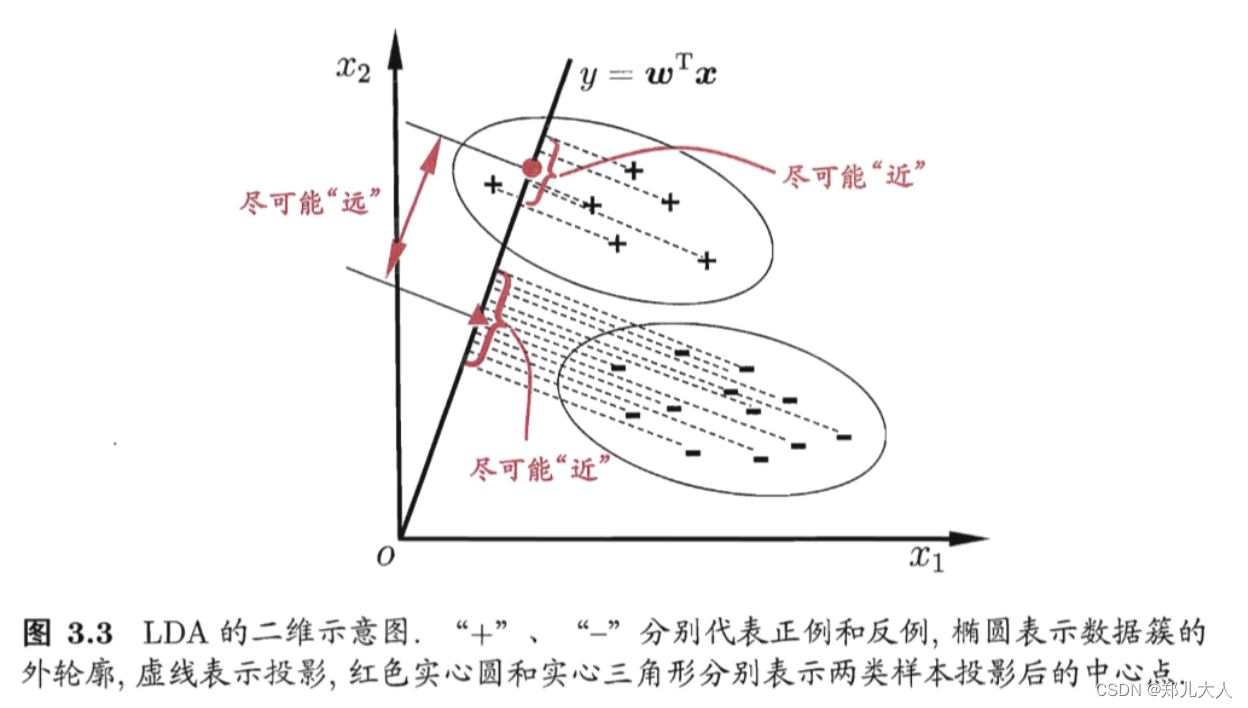
线性判别分析 v.s. Fisher判别分析
在分类问题上,Fisher判别分析更早提出
LDA假设了各类样本的协方差矩阵相同且满秩
LDA的形式化表述
X i X_i Xi其中 X 0 X_0 X0, X 1 X_1 X1分别代表所有的负样本和正样本
μ 0 mu_0 μ0和 μ 1 mu_1 μ1分别代表负样本和正样本的均值
∑ 0 sum_0 ∑0和 ∑ 1 sum_1 ∑1分别代表负样本和正样本的方差
∑ i = ∑ x ∈ X i ( x − μ i ) ( x − μ i ) T sum_i=sum_{x \in X_i}(x-mu_i)(x-mu_i)^T ∑i=∑x∈Xi(x−μi)(x−μi)T
在式子的表示中省略掉了 1 m i frac{1}{m_i} mi1,但是这个系数并不影响LDA的结果
求解 w w w向量的时候,为什么只关注于方向而不关心大小
以均值 μ 0 mu_0 μ0和 μ 1 mu_1 μ1为例,利用模型得到的 y y y值本质上是均值对直线的投影
y = ∣ μ ∣ c o s θ y=|mu| costheta y=∣μ∣cosθ
说明直线的向量最主要的是影响方向,真正影响长度的是你向量本身。所以直线的向量的大小并不是关键因素
损失函数的推导
异类样本中心尽可能远
m a x ∣ ∣ ∣ μ 0 ∣ ⋅ c o s θ 0 − ∣ μ 1 ∣ ⋅ c o s θ 1 ∣ ∣ 2 2 max|| |mu_0|cdot costheta_0 - |mu_1|cdot costheta_1||_2^2 max∣∣∣μ0∣⋅cosθ0−∣μ1∣⋅cosθ1∣∣22
为了方便后续进行计算推导,同时不关心 w w w的大小,所以可以乘以 ∣ w ∣ |w| ∣w∣
max ∥ ∣ w ∣ ⋅ ∣ μ 0 ∣ ⋅ cos θ 0 − ∣ w ∣ ⋅ ∣ μ 1 ∣ ⋅ cos θ 1 ∥ 2 2 max left||boldsymbol{w}| cdotleft|boldsymbol{mu}_{0}right| cdot cos theta_{0}-|boldsymbol{w}| cdotleft|boldsymbol{mu}_{1}right| cdot cos theta_{1}right|_{2}^{2} max∥∣w∣⋅∣μ0∣⋅cosθ0−∣w∣⋅∣μ1∣⋅cosθ1∥22
就可以将这个式子,转换为向量内积的形式
max ∥ w T μ 0 − w T μ 1 ∥ 2 2 max left|boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{0}-boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{1}right|_{2}^{2} max∥ ∥wTμ0−wTμ1∥ ∥22
同类样本方差尽可能小
min w T Σ 0 w min boldsymbol{w}^{mathrm{T}} boldsymbol{Sigma}_{0} boldsymbol{w} minwTΣ0w
解释下为什么这种形式表示为方差
具体式子展开如下
其实这个式子是在投影维度上考虑的方差形式
w T Σ 0 w = w T ( ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T ) w = ∑ x ∈ X 0 ( w T x − w T μ 0 ) ( x T w − μ 0 T w ) begin{aligned} boldsymbol{w}^{mathrm{T}} boldsymbol{Sigma}_{0} boldsymbol{w} &=boldsymbol{w}^{mathrm{T}}left(sum_{boldsymbol{x} in X_{0}}left(boldsymbol{x}-boldsymbol{mu}_{0}right)left(boldsymbol{x}-boldsymbol{mu}_{0}right)^{mathrm{T}}right) boldsymbol{w} \ &=sum_{boldsymbol{x} in X_{0}}left(boldsymbol{w}^{mathrm{T}} boldsymbol{x}-boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{0}right)left(boldsymbol{x}^{mathrm{T}} boldsymbol{w}-boldsymbol{mu}_{0}^{mathrm{T}} boldsymbol{w}right) end{aligned} wTΣ0w=wT(x∈X0∑(x−μ0)(x−μ0)T)w=x∈X0∑(wTx−wTμ0)(xTw−μ0Tw)
其中
w
T
x
−
w
T
μ
0
boldsymbol{w}^{mathrm{T}} boldsymbol{x}-boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{0}
wTx−wTμ0代表的就是投影长度之间的
(
w
⊤
x
−
w
⊤
μ
0
)
2
left(w^{top} x-w^{top} mu_{0}right)^{2}
(w⊤x−w⊤μ0)2形式就是类似于
(
x
−
x
ˉ
)
2
(x-bar{x})^{2}
(x−xˉ)2方差的形式
二范数
∥ x ∥ 2 = ( ∣ x 1 ∣ 2 + ∣ x 2 ∣ 2 + ⋯ + ∣ x n ∣ 2 ) 1 / 2 |x|_{2}=left(left|x_{1}right|^{2}+left|x_{2}right|^{2}+cdots+left|x_{n}right|^{2}right)^{1 / 2} ∥x∥2=(∣x1∣2+∣x2∣2+⋯+∣xn∣2)1/2
拉格朗日乘子法
min x f ( x ) s.t. h i ( x ) = 0 i = 1 , 2 , … , n begin{array}{cl} min _{boldsymbol{x}} & f(boldsymbol{x}) \ text { s.t. } & h_{i}(boldsymbol{x})=0 quad i=1,2, ldots, n end{array} minx s.t. f(x)hi(x)=0i=1,2,…,n
其中自变量 x ∈ R n , f ( x ) 和 h i ( x ) boldsymbol{x} in mathbb{R}^{n}, f(boldsymbol{x}) 和 h_{i}(boldsymbol{x}) x∈Rn,f(x)和hi(x) 均有连续的一阶偏导数。首先列出其拉格朗日函 数:
L ( x , λ ) = f ( x ) + ∑ i = 1 n λ i h i ( x ) L(boldsymbol{x}, boldsymbol{lambda})=f(boldsymbol{x})+sum_{i=1}^{n} lambda_{i} h_{i}(boldsymbol{x}) L(x,λ)=f(x)+∑i=1nλihi(x)
其中 λ = ( λ 1 , λ 2 , … , λ n ) T boldsymbol{lambda}=left(lambda_{1}, lambda_{2}, ldots, lambda_{n}right)^{mathrm{T}} λ=(λ1,λ2,…,λn)T 为拉格朗日乘子。然后对拉格朗日函数关于 x boldsymbol{x} x 求偏导, 并令导数等于 0 mathbf{0} 0 再搭配约束条件 h i ( x ) = 0 h_{i}(boldsymbol{x})=0 hi(x)=0 解出 x boldsymbol{x} x , 求解出的所有 x boldsymbol{x} x 即为上述优化问题的所有 可能【极值点】
极值点中存在最大值和最小值
最终损失函数的式子
max J = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = ∥ ( w T μ 0 − w T μ 1 ) T ∥ 2 2 w T ( Σ 0 + Σ 1 ) w = ∥ ( μ 0 − μ 1 ) T w ∥ 2 2 w T ( Σ 0 + Σ 1 ) w = [ ( μ 0 − μ 1 ) T w ] T ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w = w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w begin{aligned} max J &=frac{left|boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{0}-boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{1}right|_{2}^{2}}{boldsymbol{w}^{mathrm{T}} boldsymbol{Sigma}_{0} boldsymbol{w}+boldsymbol{w}^{mathrm{T}} boldsymbol{Sigma}_{1} boldsymbol{w}} \ &=frac{left|left(boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{0}-boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{1}right)^{mathrm{T}}right|_{2}^{2}}{boldsymbol{w}^{mathrm{T}}left(boldsymbol{Sigma}_{0}+boldsymbol{Sigma}_{1}right) boldsymbol{w}} \ &=frac{left|left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w}right|_{2}^{2}}{boldsymbol{w}^{mathrm{T}}left(boldsymbol{Sigma}_{0}+boldsymbol{Sigma}_{1}right) boldsymbol{w}} \ &=frac{left[left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w}right]^{mathrm{T}}left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w}}{boldsymbol{w}^{mathrm{T}}left(boldsymbol{Sigma}_{0}+boldsymbol{Sigma}_{1}right) boldsymbol{w}} \ &=frac{boldsymbol{w}^{mathrm{T}}left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w}}{boldsymbol{w}^{mathrm{T}}left(boldsymbol{Sigma}_{0}+mathbf{Sigma}_{1}right) boldsymbol{w}} end{aligned} maxJ=wTΣ0w+wTΣ1w∥ ∥wTμ0−wTμ1∥ ∥22=wT(Σ0+Σ1)w∥ ∥(wTμ0−wTμ1)T∥ ∥22=wT(Σ0+Σ1)w∥ ∥(μ0−μ1)Tw∥ ∥22=wT(Σ0+Σ1)w[(μ0−μ1)Tw]T(μ0−μ1)Tw=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw
为了方便记录和讨论
设定 S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_b=(mu_0-mu_1)(mu_0-mu_1)^T Sb=(μ0−μ1)(μ0−μ1)T, S w = ( ∑ 0 + ∑ 1 ) S_w=(sum_0+sum_1) Sw=(∑0+∑1)
式子表示为
max J = w T S b w w T S w w max J=frac{boldsymbol{w}^{mathrm{T}} mathbf{S}_{b} boldsymbol{w}}{boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}} maxJ=wTSwwwTSbw
下一步进行求解时,由于 w w w的长度完全不影响结果,所以可以先将 w w w固定,添加约束 w T S w w = 1 boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}=1 wTSww=1
通常优化问题中都考虑最小化问题,所以将式子转换为
min w − w T S b w s.t. w T S w w = 1 begin{array}{cl} min _{boldsymbol{w}} & -boldsymbol{w}^{mathrm{T}} mathbf{S}_{b} boldsymbol{w} \ text { s.t. } & boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}=1 end{array} minw s.t. −wTSbwwTSww=1
求解 w w w
min w − w T S b w s.t. w T S w w = 1 ⇔ w T S w w − 1 = 0 begin{array}{cl} min _{boldsymbol{w}} & -boldsymbol{w}^{mathrm{T}} mathbf{S}_{b} boldsymbol{w} \ text { s.t. } & boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}=1 Leftrightarrow boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}-1=0 end{array} minw s.t. −wTSbwwTSww=1⇔wTSww−1=0
由拉格朗日乘子法可得拉格朗日函数为
L ( w , λ ) = − w T S b w + λ ( w T S w w − 1 ) L(boldsymbol{w}, lambda)=-boldsymbol{w}^{mathrm{T}} mathbf{S}_{b} boldsymbol{w}+lambdaleft(boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}-1right) L(w,λ)=−wTSbw+λ(wTSww−1)
利用矩阵微分公式,对 w boldsymbol{w} w 求偏导可得
∂ L ( w , λ ) ∂ w = − ∂ ( w T S b w ) ∂ w + λ ∂ ( w T S w w − 1 ) ∂ w = − ( S b + S b T ) w + λ ( S w + S w T ) w begin{aligned} frac{partial L(boldsymbol{w}, lambda)}{partial boldsymbol{w}} &=-frac{partialleft(boldsymbol{w}^{mathrm{T}} mathbf{S}_{b} boldsymbol{w}right)}{partial boldsymbol{w}}+lambda frac{partialleft(boldsymbol{w}^{mathrm{T}} mathbf{S}_{w} boldsymbol{w}-1right)}{partial boldsymbol{w}} \ &=-left(mathbf{S}_{b}+mathbf{S}_{b}^{mathrm{T}}right) boldsymbol{w}+lambdaleft(mathbf{S}_{w}+mathbf{S}_{w}^{mathrm{T}}right) boldsymbol{w} end{aligned} ∂w∂L(w,λ)=−∂w∂(wTSbw)+λ∂w∂(wTSww−1)=−(Sb+SbT)w+λ(Sw+SwT)w
由于 S b S_b Sb和 S w S_w Sw都对称 S b = S b T , S w = S w T mathbf{S}_{b}=mathbf{S}_{b}^{mathrm{T}}, mathbf{S}_{w}=mathbf{S}_{w}^{mathrm{T}} Sb=SbT,Sw=SwT , 所以
∂ L ( w , λ ) ∂ w = − 2 S b w + 2 λ S w w frac{partial L(boldsymbol{w}, lambda)}{partial boldsymbol{w}}=-2 mathbf{S}_{b} boldsymbol{w}+2 lambda mathbf{S}_{w} boldsymbol{w} ∂w∂L(w,λ)=−2Sbw+2λSww
令上面的式子为0,即可得到
S b w = λ S w w mathbf{S}_{b} boldsymbol{w}=lambda mathbf{S}_{w} boldsymbol{w} Sbw=λSww
将 S b S_b Sb展开后,可以得到
( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w = λ S w w left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w}=lambda mathbf{S}_{w} boldsymbol{w} (μ0−μ1)(μ0−μ1)Tw=λSww
( μ 0 − μ 1 ) T w left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w} (μ0−μ1)Tw为行向量和列向量相乘,所以可以令 ( μ 0 − μ 1 ) T w = γ left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right)^{mathrm{T}} boldsymbol{w}=gamma (μ0−μ1)Tw=γ
将式子进行整理,得到
w = γ λ S w − 1 ( μ 0 − μ 1 ) boldsymbol{w}=frac{gamma}{lambda} mathbf{S}_{w}^{-1}left(boldsymbol{mu}_{0}-boldsymbol{mu}_{1}right) w=λγSw−1(μ0−μ1)
正常在利用拉格朗日乘子法进行求解的时候需要考虑约束条件,由于不关系 w w w的大小,会关心方向,所以隐含的没有考虑,同时 γ gamma γ只受 w w w影响, λ lambda λ未知但是固定,所以令 γ λ = 1 frac{gamma}{lambda}=1 λγ=1
论证为什么使用拉格朗日乘子法求出的极值点 w w w一定是最小值点
μ 0 mu_0 μ0和 μ 1 mu_1 μ1投影后一定存在最大值和最小值
同时 − w T S b w = − ∥ w T μ 0 − w T μ 1 ∥ 2 2 ⩽ 0 -boldsymbol{w}^{mathrm{T}} mathbf{S}_{b} boldsymbol{w}=-left|boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{0}-boldsymbol{w}^{mathrm{T}} boldsymbol{mu}_{1}right|_{2}^{2} leqslant 0 −wTSbw=−∥ ∥wTμ0−wTμ1∥ ∥22⩽0
所以当求出的极值点代入到目标函数的式子中,不为0的点就是最小值点
拓展到多线性判别分析
W = ( w 1 , w 2 , . . . , w n ) W=(w_1,w_2,...,w_n) W=(w1,w2,...,wn)
S b ( w 1 , w 2 , . . . , w 3 ) = λ S w ( w 1 , w 2 , . . . , w 3 ) S_b(w_1,w_2,...,w_3)=lambda S_w(w_1,w_2,...,w_3) Sb(w1,w2,...,w3)=λSw(w1,w2,...,w3)
S b w 1 = λ S w w 1 S_bw_1=lambda S_ww_1 Sbw1=λSww1
相当于是 n n n个二分类的线性判别问题
补充数学知识
广义特征值
A x = λ x Ax=lambda x Ax=λx,普通求特征值
A x = λ B x Ax=lambda B x Ax=λBx, 广义特征值
其中 A A A和 B B B为 n n n阶方阵,称 λ lambda λ为 A A A相对于 B B B的广义特征值
x x x为 A A A相对于 B B B的属于广义特征值 λ lambda λ的特征向量
广义瑞利商
设 A , B mathbf{A}, mathbf{B} A,B 为 n n n阶厄米 (Hermitian) 矩阵, 且 B mathbf{B} B 正定, 称 R ( x ) = x H A x x H B x ( x ≠ 0 ) R(boldsymbol{x})=frac{boldsymbol{x}^{mathrm{H}} mathbf{A} boldsymbol{x}}{boldsymbol{x}^{mathrm{H}} mathbf{B} boldsymbol{x}}(boldsymbol{x} neq mathbf{0}) R(x)=xHBxxHAx(x=0) 为 A mathbf{A} A 相对于 B mathbf{B} B 的广义瑞利商。特别地, 当 B = I mathbf{B}=mathbf{I} B=I (单位矩阵) 时, 广义瑞利商退化为瑞利商。
(这里可以先简单理解为厄米矩阵是对称矩阵)
广义瑞利商的性质:设 λ i , x i ( i = 1 , 2 , … , n ) lambda_{i}, boldsymbol{x}_{i}(i=1,2, ldots, n) λi,xi(i=1,2,…,n) 为 A mathbf{A} A 相对于 B mathbf{B} B 的广义特征值和特征向量, 且 $lambda_{1} leqslant lambda_{2} leqslant ldots leqslant lambda_{n} $。
min x ≠ 0 R ( x ) = x H A x x H B x = λ 1 , x ∗ = x 1 max x ≠ 0 R ( x ) = x H A x x H B x = λ n , x ∗ = x n begin{array}{l} min _{boldsymbol{x} neq mathbf{0}} R(boldsymbol{x})=frac{boldsymbol{x}^{mathrm{H}} mathbf{A} boldsymbol{x}}{boldsymbol{x}^{mathrm{H}} mathbf{B} boldsymbol{x}}=lambda_{1}, boldsymbol{x}^{*}=boldsymbol{x}_{1} \ max _{boldsymbol{x} neq mathbf{0}} R(boldsymbol{x})=frac{boldsymbol{x}^{mathrm{H}} mathbf{A} boldsymbol{x}}{boldsymbol{x}^{mathrm{H}} mathbf{B} boldsymbol{x}}=lambda_{n}, boldsymbol{x}^{*}=boldsymbol{x}_{n} end{array} minx=0R(x)=xHBxxHAx=λ1,x∗=x1maxx=0R(x)=xHBxxHAx=λn,x∗=xn
【证明】:当固定 x H B x = 1 boldsymbol{x}^{mathrm{H}} mathbf{B} boldsymbol{x}=1 xHBx=1 时,使用拉格朗日乘子法可推得 A x = λ B x mathbf{A} boldsymbol{x}=lambda mathbf{B} boldsymbol{x} Ax=λBx 这样一个广义特征值问题, 因此 x boldsymbol{x} x 所有可能的解即为 x i ( i = 1 , 2 , … , n ) boldsymbol{x}_{i}(i=1,2, ldots, n) xi(i=1,2,…,n) 这 n mathrm{n} n 个广义特征向量, 将其分别代入 R ( x ) R(boldsymbol{x}) R(x) 即可推得上述结论。
其实也就是将特征值由小到大排列,然后需要几个解,就按照顺序取几个特征值对应的特征向量
参考资料
[1]周志华. 《机器学习》[J]. 中国民商, 2016, 03(No.21):93-93.
[2]机器学习公式详解
最后
以上就是丰富早晨最近收集整理的关于【机器学习-西瓜书】-第3章-线性回归-学习笔记-下3.3 对数几率回归3.4 线性判别分析参考资料的全部内容,更多相关【机器学习-西瓜书】-第3章-线性回归-学习笔记-下3.3内容请搜索靠谱客的其他文章。






![[机器学习 > 周志华]第三章 线性模型第三章 线性模型](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)

发表评论 取消回复