
5 月 30 日,字节跳动技术沙龙 | 基础架构专场 进行了在线直播。我们邀请到了字节跳动基础架构团队资深研发工程师邵伟、江帆和大家进行分享交流。
本次沙龙给大家分享的主题是《大规模混合部署项目在字节跳动的落地实践》,希望这次的分享能够带给大家一些我们对混部的思考。
沙龙分享的内容将会围绕以下问题来进行:
-
首先是字节跳动为什么想要开启混部,它产生的背景是什么样的,字节内部的业务形态有什么样的特征使我们能够开启大规模的混部?
-
我们具体做了哪些事情来支持混部的顺利开启和落地,在其中遇到哪些问题和挑战?
-
以及,在字节内部,混部有哪些典型的应用场景,分别是为了解决什么问题,带来了哪些收益等等。
为了更好地回答这些问题,本次沙龙将分为两个议题,分别围绕上层控制逻辑和底层隔离技术进行展开。
以下是字节跳动基础架构团队资深研发工程师邵伟的分享主题沉淀,《自动化弹性伸缩如何支持百万级核心错峰混部》。
演讲内容大纲:
背景介绍
弹性伸缩
混部实践
下面我会首先着重介绍第一个议题,也就是《自动化弹性伸缩如何支持百万级核心错峰混部》,而关于底层隔离技术的分享将在稍后给大家带来。
首先了解下今天分享的大纲,在第一部分中,会对字节私有云平台的整体现状,和上面所托管的服务做一个简单的介绍,在这部分中将重点回答为什么需要对服务开启弹性伸缩,它跟混部间的关系是什么。第二部分的内容主要涉及到在控制层上如何实现大规模服务弹性伸缩,以及相关的基础组件如何才能支撑弹性伸缩的稳定性。最后,会介绍一下,我们在弹性伸缩的基础上逐步推动大规模混部上量的过程,以及具体落地的一些场景,还有对应的演进思路。
背景介绍
字节内部的私有云平台叫做 TCE,它底层使用 K8S 作为编排调度的系统,目前字节内部几乎所有无状态服务都是以容器的形式部署和运行在 TCE 之上,这些无状态服务主要包括典型的微服务,还有像推荐和广告等在类的偏算法型的服务。其中,微服务对于资源的申请比较简单,只涉及到 CPU 和 内存等,而算法类服务对稳定性要求更为严格,所以对资源有很更多定制化的需求,例如内存带宽、numa 节点的绑定等。这些无状态服务都是以 K8S Deployment 的形式进行多实例部署和管理的,每个实例通常会以 RPC 或 HTTP 的形式对外提供访问接口,并在上层通过 consul 或 lb 提供统一的外部访问入口和负载均衡的能力。这些特征使得这些无状态服务的实例天然是可以在集群的不同节点上进行动态迁移的,并且服务实例的资源利用情况跟流量的变化呈现正向的关系,这就为服务副本数的动态控制和调整提供了基础。
由于 TCE 上接管的服务数量非常众多,所以集群的规模也相应变得非常庞大,截止到目前为止,TCE 已经部署在中国、新加坡、美东等三个区域,底层搭建和托管的 K8S 集群数量超过了 40 个,总计包括约几十万台服务器资源;从应用规模上来说,TCE 上部署的服务数量也超过了 4w 个,对应的 Deployment 和 Pod 总量则分别超过了 30 万和 300 万个。随着业务的不断发展,集群规模还在处于不断增长的过程中。如此庞大的集群规模带来的问题就是资源成本的不断攀升,所以对于管理资源的架构团队而言,需要回答的一个核心问题就是如何才能尽可能的提高集群整体资源利用率。
为这个目标,我们对业务的流量特性进行了分析。首先我们观察到在线业务的一个非常重要特性就是天级利用率具有很强的稳定性,在没有特殊变更的情况下,在线业务每天的流量几乎不会发生变化。从这张图中可以看到,服务天级利用率在一周的时间维度上具有相同的波动曲线。而且通常来说,业务会倾向于申请比自己实际需要更多的资源,这样对服务本身的好处是可以在最大程度上保证流量服务的稳定性,但是造成的问题就是,始终有部分资源是业务即使在高峰期也永远用不上的,即图中红线和绿线之间的 Gap 就是一定程度上的资源浪费。
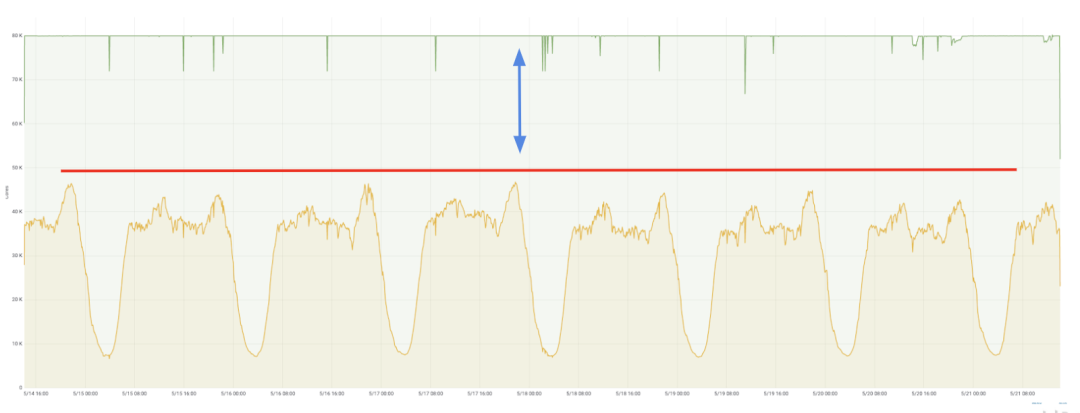
基于这一特性,我们可以采取的方式就是在合理范围内尽可能地把图中的绿线往下拉,具体的做法就是根据服务在过去一周中峰值利用率的最大值,动态调整服务的资源申请量,从而回收和再利用一定的冗余资源。当然我们会在峰值利用率的基础增加一定的 buffer 以适应服务 burst 的行为。这个策略就是服务级别的动态超售,超售对于微服务的资源回收具有非常明显的效果。
除此之外,我们发现在另外一些场景下仍然存在非常多资源的浪费,这就涉及到在线业务的另外一个特点,即在线业务的流量具有明显波峰波谷的潮汐变化。举个例子来说,几乎所有的用户都会在晚高峰的时段刷抖音,这样就会导致抖音相关服务的整体流量都上涨到一个比较高的水平。而到了凌晨,因为大家刷抖音的次数和频率又会下降,所以此时业务访问的流量会出现比较明显的波谷。这种潮汐现象对头部服务而言会非常明显,尤其是像抖音和推荐这类服务,它们波峰波谷间利用率的差距可能达到 40% 这种水平。业务部署时,为了使得其资源总量能够扛过晚高峰,必须按照晚高峰的流量预估申请资源,造成当业务处于流量低谷时,很多资源被浪费掉,并且这部分资源无法通过超售的当时进行回收。面对这种情况,如果能够通过弹性伸缩,在业务处于低谷时,通过回收业务副本数的方式来回收这部分资源,然后在业务处于峰值时,重新恢复业务的副本数,那么我们就能够在保证服务的 SLA 几乎不受影响的前提下,回收大量在线低谷时段的弹性资源。
当我们通过弹性伸缩回收了在线低谷时的资源后,下一步需要做的事情就是将这部分弹性资源进行二次的分配和利用,不然集群整体的利用率并没有因为服务弹性伸缩而得到本质的提升。但我们面临的事实是,所有在线业务的低谷时段几乎吻合,因为凌晨的时候所有在线 app 都会面临使用频次减少的情况,所以无法通过扩容在线的方式吃掉这部分资源量。但是我们发现,字节内部也有很多离线的任务同样需要资源进行调度,例如视频转码和模型训练等,而且这些任务对资源的需求相对来说没有特定的时间约束,所以天然能够利用闲置资源,于是我们就开启了在离线混部出让在线闲置的资源给离线使用。
后来我们进一步发现,因为总体资源量的限制,部分在线服务在流量高峰期时经常由于没有足够的资源供给,处于常态降级的状态,这种降级状态对业务来说其实是有损的。如果能够在这个时候将离线的资源通过混部的形式出让给在线使用,那么在线服务也能够从混部中得到收益。更进一步来说,如果能够在资源层面彻底打通在离线之间的壁垒,那么我们就能够通过更加灵活的手段来优化混部的策略,真正实现资源和调度的融合,从而从更大程度上提升在离线集群整体的利用率,关于这一点,我们会在第二个 topic 《在高服务器利用率和毫秒级 QoS 之间需求折中》中进行更为详细的阐述。
下面我们可以简单总结一下我们对于提升集群利用率的探索,我们主要使用了三种不同的手段相互配合来提升利用率,分别是:通过超售的方式回收业务申请的冗余资源,通过弹性伸缩回收在线业务波谷时段的冗余资源,最后在弹性伸缩的基础上通过通过混合部署实现在离线之间资源的灵活拆借。其中,弹性伸缩和混部的控制逻辑是第一个子议题中分享的重点,下面我会进一步分享这两个方面的实现细节。
弹性伸缩
在介绍实现细节之前,首先需要认识下服务弹性伸缩的大致过程,整体思路比较简单,服务 owner 可以根据服务自身特性配置资源利用率的阈值,这个阈值表征的就是理想状态下服务利用率应该达到的水平。当然这里阈值的概念可以是物理的资源,例如 CPU 和 内存的使用情况,也可以是逻辑上的资源,例如服务请求的 QPS 等。理论上任何能够反应出服务当前负载状况的指标都可以作为控制扩缩容行为的数据源。在有了资源利用率阈值后,弹性伸缩控制面会不断地去轮询该服务所有副本的平均资源利用率,然后和阈值进行对比。如果实际平均利用率低于阈值,那么就说明服务的实例数太多,存在一定冗余,此时可以通过减少一定副本数的操作来使得每个实例均摊的资源使用量增大,直到资源的实际使用情况接近阈值。同理,如果服务的平均利用率大于阈值,那么就需要通过增加副本数的手段来缓解每个实例的资源压力。
通过弹性伸缩的流程可以看到,整个控制逻辑中最重要的就是稳定性,对于在线业务来说,我们需要保证它们被缩容的实例在流量上涨之后能够被迅速地扩容,不然就有可能造成单实例流量过高影响服务的 SLA,严重时可能会导致服务不可用,甚至影响到整个请求调用链路。所以我们需要底层系统提供一整套的机制进行稳定性保证,主要包括几个方面:
首先集群本身在规模逐渐变大的过程中,需要具有较强的扩展性和可用性,只有这样才能支持频繁的扩缩容行为,同时保证扩缩容的效率,弹性资源的规模才能够上得去。
然后是需要有一套集群维度的监控体系,为弹性伸缩提供稳定实时的利用率数据,根据弹性伸缩的过程可以知看出,控制面强依赖于从监控系统中获取服务的实时资源利用率情况,我们需要尽可能避免利用率采集出错或者延迟太高,导致服务在需要扩容时扩不上去的问题。
最后,我们需要有一套 Quota 系统保证业务在伸缩的过程中,集群整体的资源量是可控的,不能出现在波谷时将服务的副本数缩容后,它所对应的 Quota 被别的服务占用且无法归还的情况。
下面针对这三个方面,我们将分别介绍下 TCE 在提升整个底层系统稳定上所做的工作。
第一个,对于集群自身稳定性的优化,我们投入了很多精力提升调度的效率和响应的速度,同时避免集群雪崩的风险。这一块涉及到的内容比较细节和繁多,而且有些性能问题是由于 TCE 特殊的使用方式带来的,所以在这里不会一一进行分享,而是挑两个来进行说明。我们会对 APIServer 中的请求进行分级,这个优化的实现实际上也是参考了社区的相关 KEP,希望做这个优化的背景是在一些特殊的异常情况下,APIServer 中会收到大量的请求而出现 429,此时弹性伸缩的控制面请求如果也因为 429 而出现大规模异常的话,将导致服务无法被正常扩容。为了规避此类风险,我们会将关键链路上的请求设置为更高优先级,从而保证对这类请求的优先响应。另外一个比较有重要的点就是,我们在多个 member K8S 集群上构建了联邦层,当某个 member 集群出现问题时,可以在上层中实现将服务副本数重新在其他集群上拉起,来规避单集群雪崩对在线服务的影响。当然集群稳定性的构建会是一个非常持久的话题,需要持续投入精力不断推进。
第二个是监控体系的构建,我们知道 K8S 有一套原生的监控系统 Metrics Server,但是 TCE 中没有采用,主要是基于这样一些考虑。首先, Metrics Server 只能代理实时数据不存储历史数据,如果希望在弹性伸缩中根据历史数据做一些更平滑的策略无法得到更好的满足。其次,由于我们做了多个集群的联邦,所以需要在联邦层上得到服务资源使用情况的汇聚数据。最后,不是只有弹性伸缩依赖监控系统,业务也需要实时通过字节内部的监控管理系统查询业务的实时数据和历史数据,还有前文所说的超售也需要获取到相关的统计数据才能进行资源回收,所以监控系统内还需要将数据同步到字节内部的离线分析系统。为了更好支持这些特殊的逻辑,TCE 借鉴 Metrics Server 实现了一套监控系统,主要包括以下的组件,其中 SysProbe 是内部的资源采集 Agent,负责提供单机上 Pod 聚合数据,Metrics Agent 通过轮询收集每台机器上的数据,然后通过 Proxy 写入到 Store 中,Store 是一个基于内存的数据库。
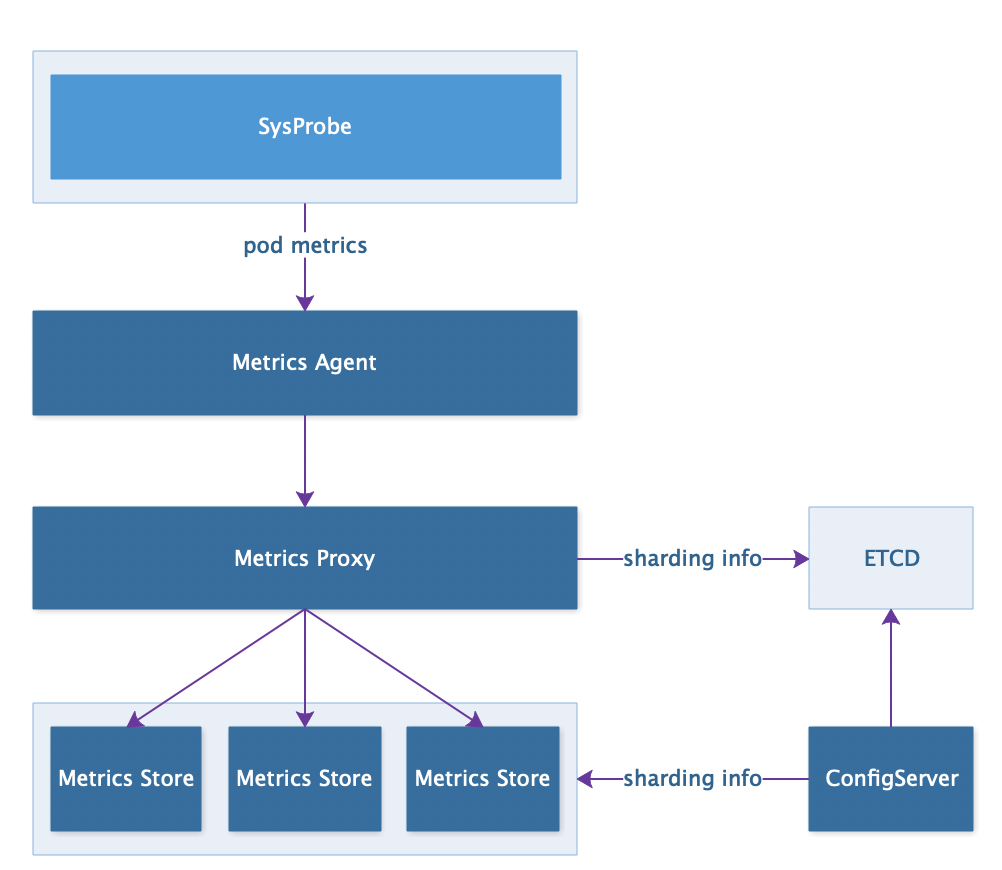
第三,在提高整个数据采集链路的高可用和高性能方面,我们也做了一定的优化,例如对所有组件都采用多实例 stand by 的方式部署。监控数据存储时使用多分片,分片信息在 etcd 中维护,由专门的组件 configServer 进行同步;Proxy 从 Store 中读写数据时采用 quorum 机制保证数据的准确性;Store 自身支持故障恢复和数据同步;每个 Store 实例都在内存中以 podName 为 key 构建 B 树以提高查询效率,并对数据内容进行压缩来降低存储压。同时 Store 还支持一些控制面计算逻辑的下发,例如直接返回服务的平均利用率等信息,由于 TCE 中的部分服务可能规模非常庞大,单 deployment 副本数可以达到 5000 +,所以计算逻辑放在 metrics 系统中实现能够大大降级数据传输的量和延迟。目前这套监控系统单次查询延迟在 30ms 左右,单次采集延迟在 60s 左右,基本能够满足弹性伸缩的需求
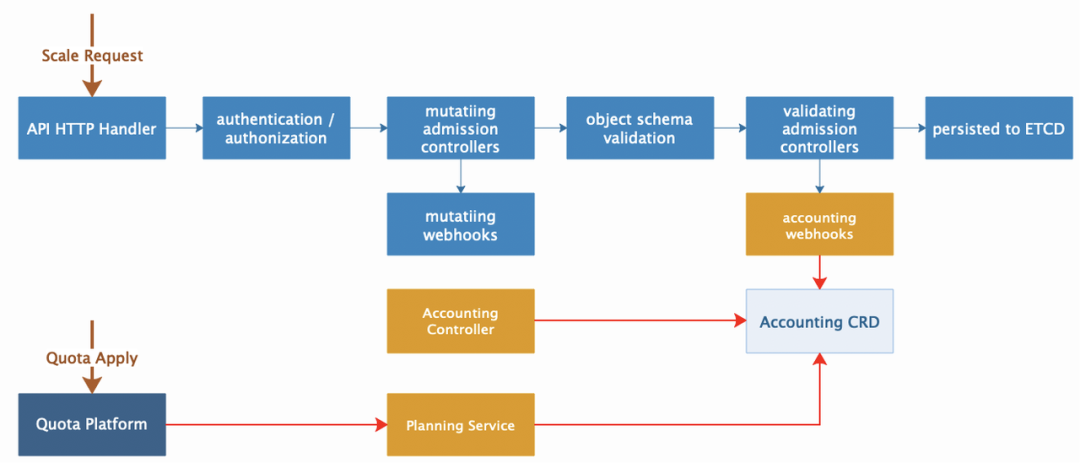
最后一个关键的底层支撑系统就是 Quota 系统,同样的,K8S 原生也提供了简单的 Quota 实现,但是由于字节内部的服务有特定的组织形式,组织内部存在着比较复杂的嵌套关系,套用原生的 Quota 系统会非常难以维护,同时也无法对计算类服务所需求的定制化资源进行更好地支持,所以 TCE 从零开始构建了自己的 Quota 计量体系。具体来说,字节中的服务大致会按所属的业务划分到不同组中,我们使用 CRD 对象来记录各个组中所有服务的总体资源可用量和使用量的信息,然后通过旁路的 Controller 不断轮询更新对象的内容。当业务方对服务副本数进行修改时,APIServer 的请求处理链中会通过 validation webhook 对该服务的资源进行校验和准入控制。尤其需要说明的是,当服务开启弹性伸缩后,Quota 系统将通过扩容的实例数上限进行资源的预留,从而保证资源弹性伸缩过程中资源量可控。
在有了底层系统为弹性伸缩的稳定性背书后,就可以真正开始介绍对应的控制流程了。弹性伸缩的控制链路可以结合这张图进行理解,这里 AppScaling Controller 会起到类似原生 HPA Controller 的作用, 它会以 30s 的粒度同步每个服务的配置,并通过 Metrics Proxy 读取 Deployment 下所有 pod 的利用率数据,据此调整实例数。TCE 中没有使用原生的 HPA,而是使用了自定义的 CRD HPAExtension,这样我们可以具体更强的控制能力,同时补充一些内部需要的特性。
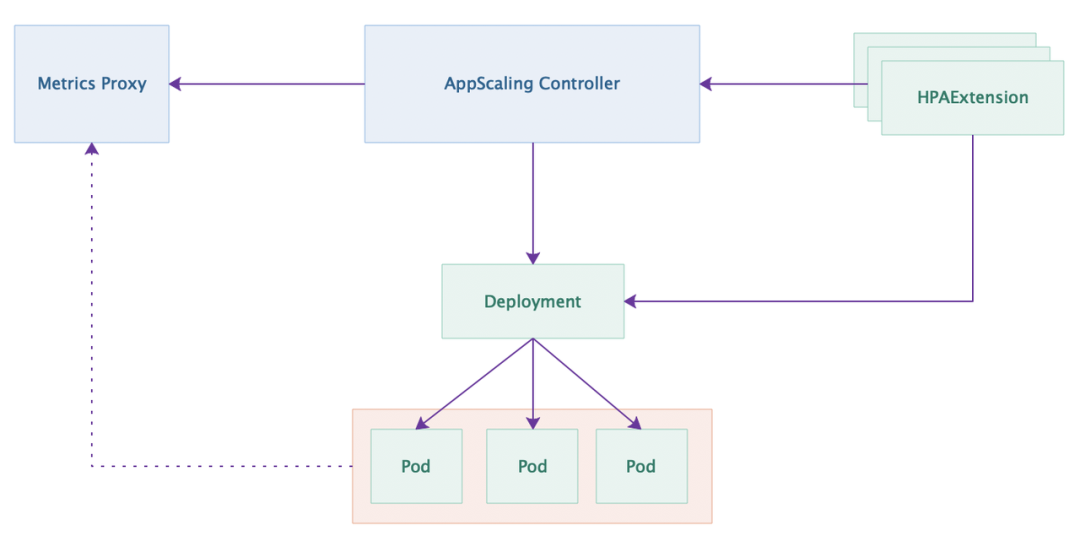
目前我们支持根据 CPU、内存、GPU 等多个资源维度进行弹性伸缩,另外我们还补充了一些新的特性,这里会挑一些重点特性进行介绍。例如我们支持根据时间段设置不同的配置、支持设置服务级别的对利用率小幅波动的容忍度、支持单步扩缩容的步长。关于这个配置的背景主要是因为一些算法相关的服务在启动和退出时需要进行数据的同步操作,如果单次扩缩容实例数较多,可能会对底层的存储组件造成较大的瞬时压力,所以需要将一次较大的扩缩容行为拆分为多次较小扩缩容行为来做一个缓冲,使得服务副本数的变化更加平滑。另外一个比较重要的点是我们会使用每个服务小时级别的历史数据作为保底的策略,以应对监控系统异常的情况,这里我们还是利用了服务天级的利用率比较稳定的特性,万一监控系统出现问题导致无法获取监控数据时,控制面可以使用该服务昨天相同时段的利用率数据来作为指导扩缩容的兜底策略。
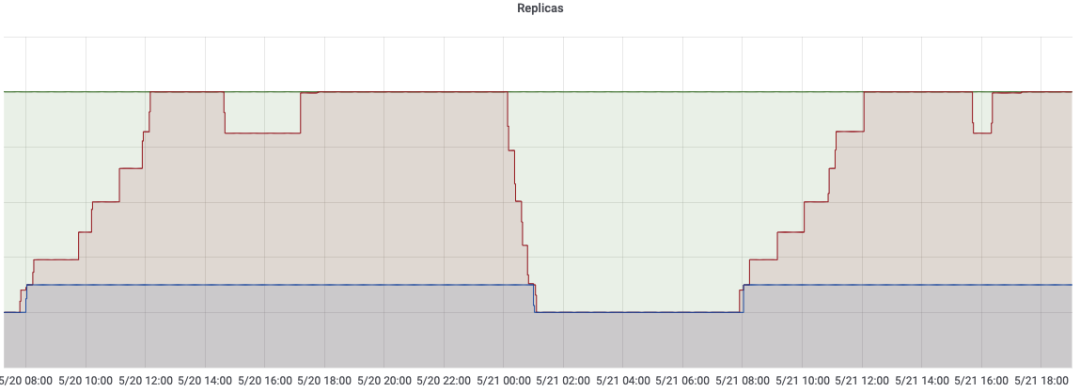
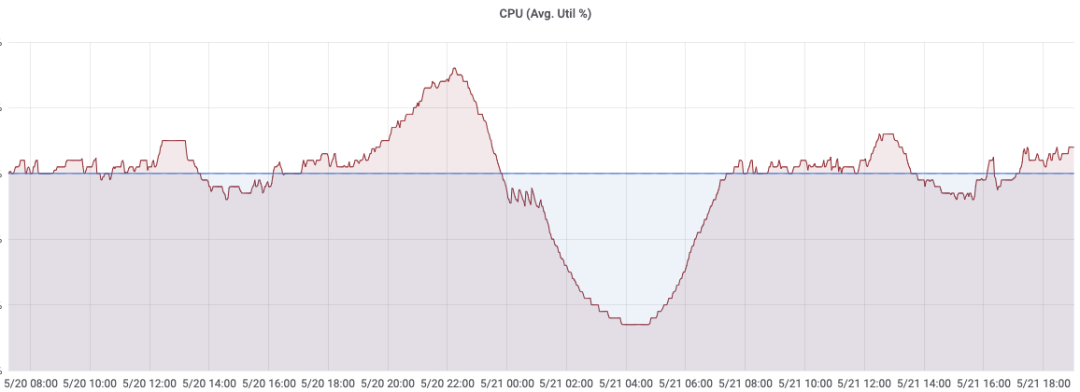
我们结合一个线上开启弹性伸缩的服务看一下对应的效果,其中上面这张图展示的是服务实例数的变化曲线,下面这张图则展示的是 CPU 平均利用率的变化曲线,图中也同样标注了用户在不同时间段的配置,例如最大扩容副本数、最小可缩容副本数、利用率阈值等。从图中可以看到,在一天的绝大部分时间段里,服务的 CPU 利用率基本维持在给定阈值的范围内小幅波动,这也是我们希望看到的最显著的效果。另外,由于该服务配置的最小可缩容副本数较高,所以在夜间低峰时,服务利用率仍然会降到低于阈值的水平,对于较为 critical 的服务,这种策略为服务提供了一定兜底的能力,在一定程度上是可以接受的,当然对于这部分资源浪费,我们仍然可以通过常态混部的手段进一步压榨和利用。最后,该服务晚高峰时的副本数已经扩到了上限,但是利用率仍然高于给定的阈值,出现这种情况一般有两种可能,一种是服务配置的资源利用率阈值不够合理,另一种就是服务的流量确实出现了增长,可扩容的上限已经不能够满足业务的需求,无论是哪种情况,TCE 都会给对应的服务 owner 发送报警,告诉他需要对弹性伸缩的配置进行一定的调整以适应流量的变化和特性。
混部实践
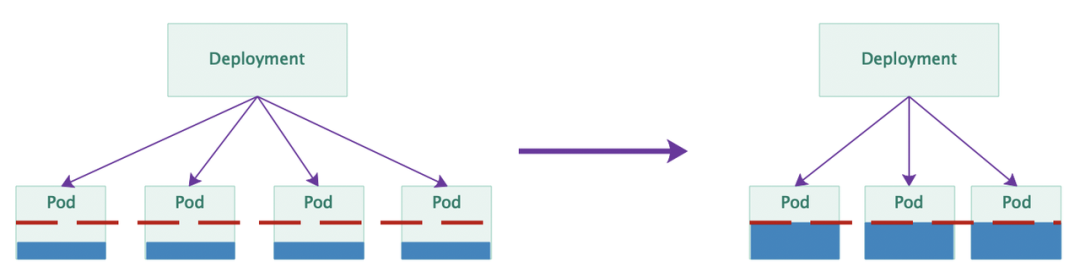
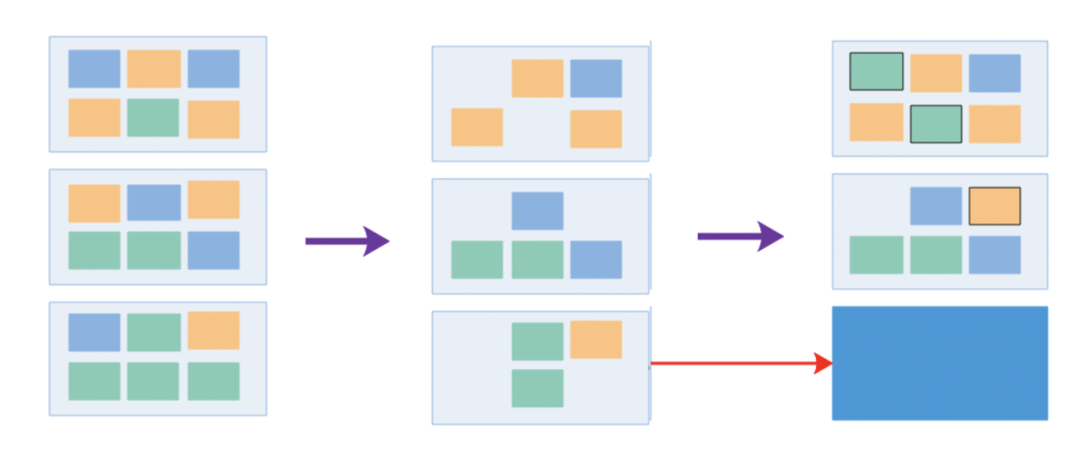
在开启了大规模弹性伸缩后,TCE 中的在线服务也就具备了生产和使用弹性资源的能力了。正如背景里介绍中提到的,为了能够充分地使用弹性资源,我们采取的方案是和离线的作业进行混合部署。最开始开展混部项目的时候,我们底层的隔离能力还没有非常完善,所以我们采取的是 0/1 的方式进行混部。具体来说,就是把在线服务波谷时产生的弹性资源折合成同等资源规模的整机出让给离线使用,使得同一时段不会同时有在线服务和离线任务跑在同一台机器上,减少在离线之间的互相影响,然后当在线波峰来临时进行回收。为了实现这个逻辑,我们引入了集群部署水位的概念,结合这张图可以对部署水位和资源出让的过程有更加清晰的了解。
初始情况下,在线服务没有进行弹性伸缩,集群中整体的资源部署处于满载状态。当在线服务的波谷来临后,几乎所有服务都会因为弹性缩容而导致副本数降低。从整体上看,集群里节点上的 Pod 会变得非常稀疏,集群整体资源部署水位也随之降低。当集群的部署水位低于设置的阈值后,控制面会通过一定规则选取部分在线节点,将该节点上的 Pod 驱逐到别的节点上,并标记该节点不可调度,最后通过某种机制将该节点加到离线的集群中实现资源的出借。同理,当在线服务的波峰来临后,会发生一个逆向的控制过程,控制面在通知并确保离线任务撤离后,重新将节点加回到在线集群中设置为可调度状态,实现资源的回收。在实际操作中,TCE 集群的水位阈值通常会定义在 90% 的水平上,这就意味着集群在常态下会始终维持在一个接近满载的部署状态中,从而能够最大限度地提升资源利用率。
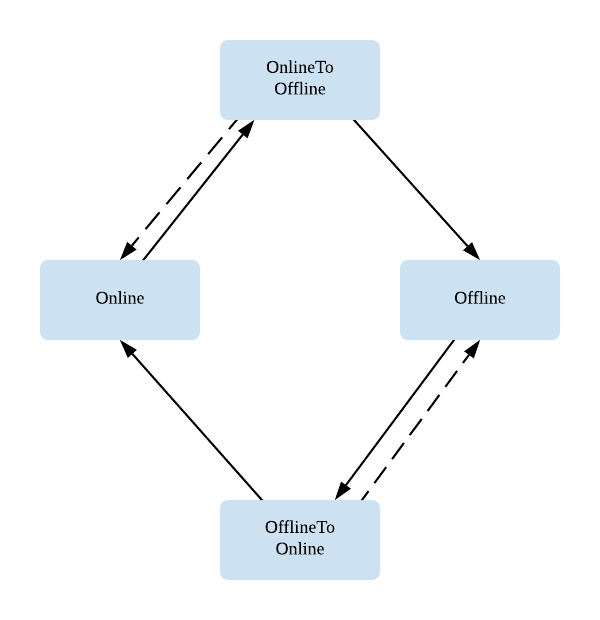
错峰控制面最主要的职责就是控制节点的动态出让和回收,即节点的动态伸缩。为了使得节点出让的过程更加透明,我们使用一个状态机来描述节点的转移状态,其中 Online 和 Offline 分别表示节点处于在线使用和离线使用的状态。而当节点被选择进行出让和回收时,会分别先进入到 OnlineToOffline 或 OfflineToOnline 的中间状态。在此状态下在离线都无法调度新的任务到节点上来,控制面会负责清理残留的在线的 Pod 和离线任务,并执行用户所配置的 hook 函数,只有当这些工作都处理完成后,才会真正完成节点的出让和回收逻辑。控制面会不断循环检查各个节点的状态并驱动状态转换的过程,同时尽可能地保证出让过程的平滑和稳定,尤其是减少对于离线业务的影响,这个主要是因为离线任务通常运行的时间稍长一些,频繁杀死和重跑任务相对来说影响较大,所以控制面需要引入提前通知的机制,在提前通知的时间窗口内,离线调度器不会再调度新的任务,同时尽可能保证那些已经被调度的任务顺利跑完,从而将任务杀死率维持在一个可接受的范围内。
当开启了基于在线部署水位的混部之后,我们使得弹性资源得到了有效的利用,但是正如背景介绍中所讲的那样,由于整体资源的紧缺,部分关键在线服务在高峰期会存在资源缺口,所以不得不一直处于一定程度的降级状态,并且这个资源缺口的量相对来说比较稳定,所以我们需要通过一种有保障的方式进行弹性资源的供给,使得业务从常态降级的状态中解脱出来。在这样的背景下我们开启了基于定时定量的错峰混部模式。在该模式下,我们能够通过定时定量的方式,在在线流量高峰期将离线整机加入到在线集群中,然后按照在线服务各自的资源需求进行扩容,等流量高峰过了之后,在线服务缩容归还整机给离线。
至此,我们其实实现的是一套基于两阶段的混部模式,即白天离线出让定量资源满足在线业务高峰期的资源缺口,夜间在线通过基于资源利用率的方式进行弹性伸缩,出让闲置资源支持离线的训练。对于在线和离线双方来说,它们实际每天使用的资源总量并没有发生任何变化,只是我们通过分时的方式,在满足在离线各自资源需求的同时,实现了资源动态灵活的配比。
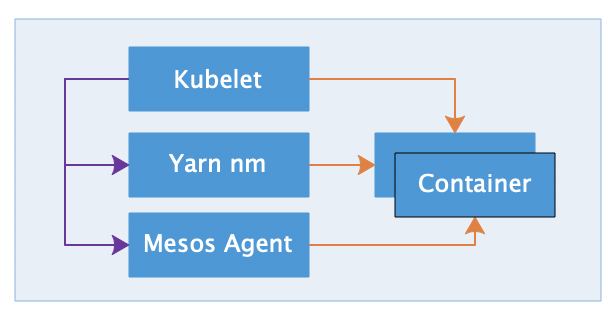
前面的讲述过程中遗留掉的一个重要问题就是在离线之间如何做到资源的互通,为了对这个问题进行解释,我们首先需要对参与混部的离线方做一个简单的分类。目前来说,混部离线方主要包括两类,一类是基于 YARN 进行任调度的模型训练任务,一类是基于 Mesos 进行任务调度的视频转码任务。这些离线调度器的单机 Agent 都是以 K8S Daemon 的形式部署在 TCE 集群里的。在在离线资源共享的方案中,K8S 会作为资源的主导方,负责实时告知这些 Agent 它们可以使用的资源。
当节点处于在线使用的状态下,K8S 看到的是整机资源都被在线使用,所以会通过暴露一个查询接口来告知离线可用资源量为 0,此时离线就不会往节点上任务调度任务。而当节点被选择出让后,控制面会通过在 Node 对象上注入特定的 label,将节点标记为在线不可用。此时对于 K8S 来说,效果等同于该节点中在线可用的资源量变为 0,所以它会通知节点上的离线 Agent 可用资源量是整机的资源。这里需要提到的是,对于 YARN 和 Mesos 使用弹性资源来说会有一些区别。通常来说,YARN 上跑的模型训练任务运行时间会比较长,任务杀死后重启的成本相对较高,所以 YARN 在自己的调度队列中会区分弹性资源和常驻资源。而对于 Mesos 来说,视频转码主要以短视频为主,通常一个任务运行的时间在几十秒左右,重跑代价较小,所以弹性资源和常驻资源的使用方式目前是无差别的。
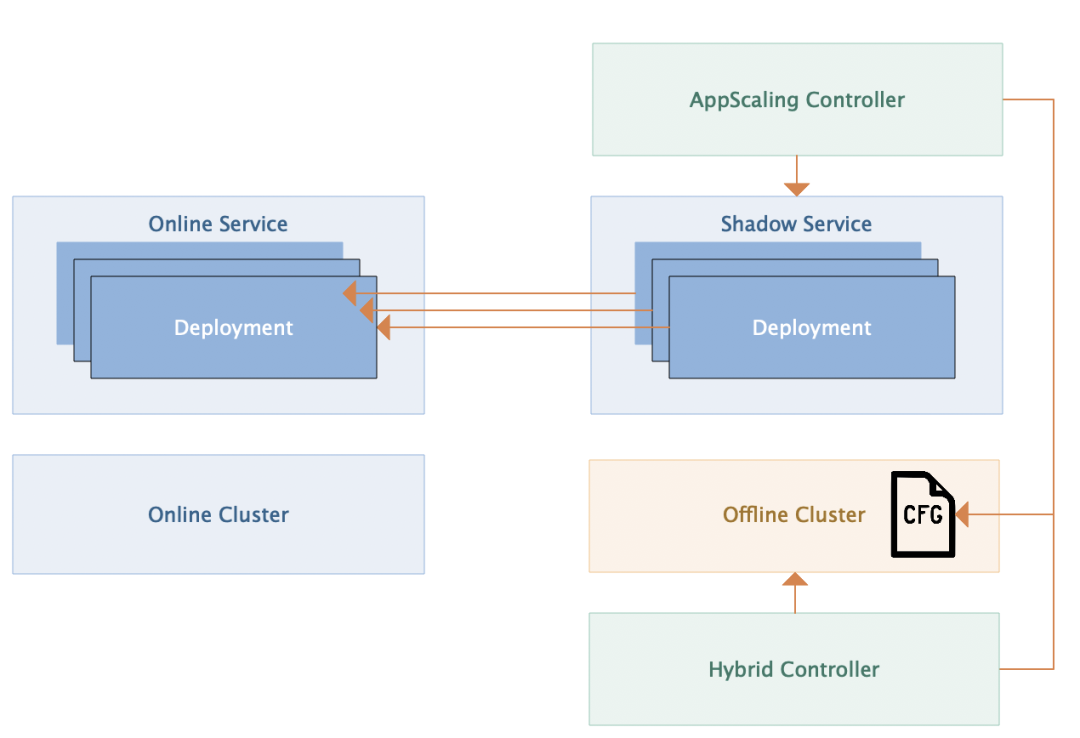
到这里关于 0/1 混部的控制逻辑已经梳理得比较清楚了。下面我们可以结合一个更为具体的例子来介绍一下混部的落地场景。我们知道在春节等活动中,在线业务的流量随时可能会出现激增,例如在抢红包等环节,如果在线业务根据流量激增时的资源预估提前进行资源申请,可能会一些问题:首先通常来说,活动场景下整体资源都会处于比较紧张的状态,在线集群本身很可能没有更多额外的资源提供 buffer。另外资源预估通常不够准确,而且按照峰值进行资源预留会导致常态情况下存在大量的资源浪费。所以最好的解决方式就是使用弹性资源来填充这个随时可能出现的资源缺口。
具体的做法是在离线集群中也搭建一套 K8S 集群,并且在该集群中复制在线 K8S 集群中的服务,我们称这些被复制的服务为“影子服务”。在常态情况下,“影子服务”的副本数都是 0,并且对业务来说是不可见的,所以不会对离线任务的运行产生任何影响。在此基础上,我们可以根据流量预估提前定义一个离线资源出让的比例和“影子服务”弹性伸缩的规则,当然这个配置也是可以随时变更的。当在线服务流量出现激时,我们就能够通过一键的方式,下线掉离线任务并扩容在线“影子服务”,从而有效地缓解在线流量的瞬时压力。而当在线激增的流量下去之后,我们又可以通过一键的方式,将影子服务缩容并重新将节点加回到离线中。通过这种方式,我们有效支持了多次活动场景下,在线服务临时的资源需求。
目前的混部已经在很大程度帮助我们提升了集群整体的资源效率,并支持了不同多种资源需求场景,但仍然存在着一些比较关键的问题。无论是水位模式还是错峰模式,它们的问题都在于需要进行节点的驱逐,使得在离线不会同时跑在一台机器上,这样在保证安全的情况下却使得碎片资源无法得到更加高效的利用,所以随着我们隔离能力的逐步完善,我们逐步尝试将在离线同时运行在一台机器上,通过隔离技术和资源动态分配的策略实现资源层彻底融合。
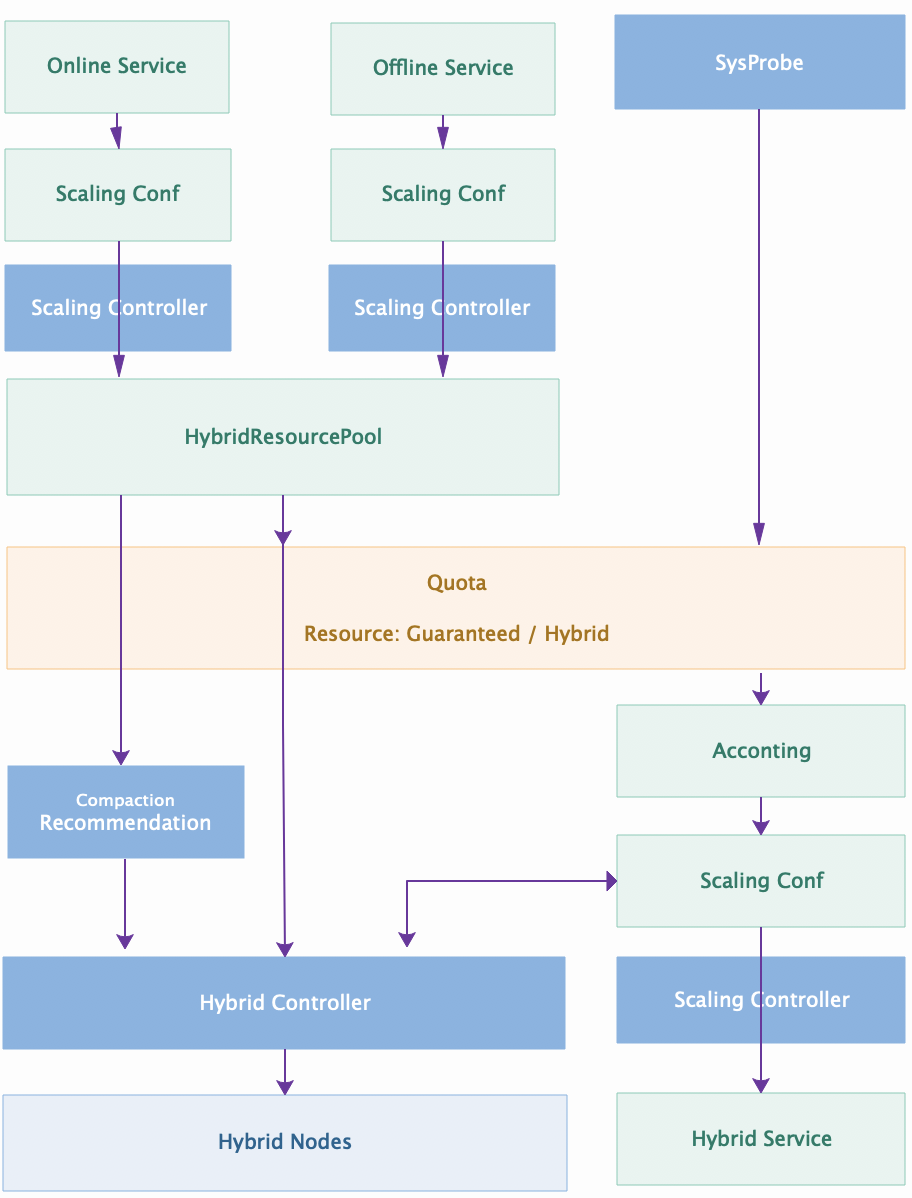
此外,混部整个控制链路自身也存在一定的缺陷,首先是资源出让方和使用方存在一定意义上的静态绑定关系,由 A 出让的弹性资源如果分配了给 B 使用后,如果 C 和 D 也想共享使用这些资源,需要通过管理员从整体上重新规划这部分资源的分配比例,随着混部规模的扩大和接入业务方的增多,相应的运维成本也会变得非常高。其次,由于我们现阶段没有统一的一层来记录弹性资源的具体情况,所以就无法给出一些全局维度的可观测数据,继而也就无法回答出“在全天的时间维度上我们还有哪些时段各有多少资源可以申请和使用”等类似的问题。最后一个痛点就是缺乏对弹性资源标准化的审计能力,进而导致我们无法进行有效的成本核算。
为了解决以上这些问题,我们后续会朝着资源出让和使用更加解耦的方向进行演进,具体来说,我们将会使用资源市场来统一对弹性资源的管理。在资源市场中,我们会抽象出资源池的概念统一所有弹性资源的入口,无论是在线服务,还是离线任务,都能将出让的资源写入到对应的资源池中,这样资源出让方将不再关注自己弹性缩容出来的资源流量问题。然后我们会在资源池的基础上构建分时分级的 Quota 系统,作为弹性资源的统一出口,以及成本核算的基。在 Quota 系统中,常驻资源将永远是有保障的,而弹性资源将是会以尽可能满足的形式进行供给,Quota 系统需要保证每时每刻常驻资源和弹性资源的总量不超过资源资源上限。资源使用方也不再关心弹性资源是从哪里来的,他们可以像使用常驻资源一样申请对弹性资源的使用。最后我们会对弹性资源的使用方进行分级,这样就可以在常态资源无法满足的情况下,通过杀死优先级较低的服务,实现对常驻资源有保障这一语义的支持。
以上就是今天我分享的主要内容,谢谢大家。
最后
以上就是大气小丸子最近收集整理的关于自动化弹性伸缩如何支持百万级核心错峰混部 | 架构沙龙回顾背景介绍弹性伸缩混部实践的全部内容,更多相关自动化弹性伸缩如何支持百万级核心错峰混部内容请搜索靠谱客的其他文章。








发表评论 取消回复