一、前言
1. 版本:
Hadoop 源码版本: Version 2.7.1
2. HDFS读一个文件的流程图
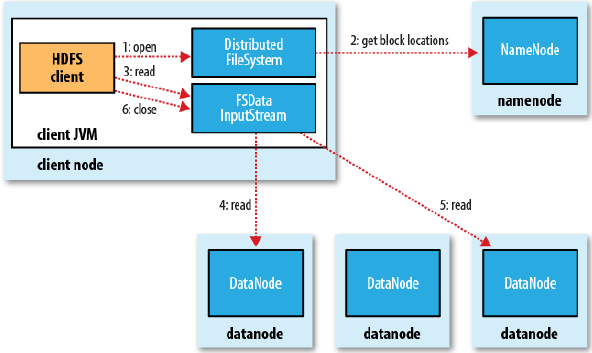
二、分析
1. 开始案例分析:
在使用Java读取一个文件系统中的一个文件时,我们会首先构造一个DataInputStream对象,然后就能够从文件中读取数据。对于存储在HDFS上的文件,也对应着类似的工具类,但是底层的实现逻辑却是非常不同的。我们先从使用DFSClient.HDFSDataInputStream方法(老版本是DFSClient.DFSDataInputStream)来读取HDFS上一个文件的一段代码来看,如下所示:
package org.shirdrn.hadoop.hdfs;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HdfsFileReader {
public static void main(String[] args) {
String file = "hdfs://hadoop-cluster-m:8020/data/logs/basis_user_behavior/201405071237_10_10_1_73.log";
Path path = new Path(file);
Configuration conf = new Configuration();
FileSystem fs;
FSDataInputStream in;
BufferedReader reader = null;
try {
fs = FileSystem.get(conf);
in = fs.open(path); // 打开文件path,返回一个FSDataInputStream流对象
reader = new BufferedReader(new InputStreamReader(in));
String line = null;
while((line = reader.readLine()) != null) { // 读取文件行内容
System.out.println("Record: " + line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(reader != null) reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}基于上面代码,我们可以看到,通过一个FileSystem对象可以打开一个Path文件,返回一个FSDataInputStream(HDFSDataInputStream和DFSDataInputStream的父类)文件输入流对象,然后从该FSDataInputStream对象就能够读取出文件的内容。
FSDataInputStream是怎么创建的?它封装了什么信息?
下面,详细说明整个创建FSDataInputStream流对象的过程:
1)先创建FileSystem对象
fs = FileSystem.get(conf);2)调用FileSystem的open方法打开一个文件流:
in = fs.open(path); 分析FileSystem的open:
/**
* Opens an FSDataInputStream at the indicated Path.
* @param f the file to open
*/
public FSDataInputStream open(Path f) throws IOException {
return open(f, getConf().getInt("io.file.buffer.size", 4096));
}FileSystem.open(Path f)调用FileSystem.open(Path f, int bufferSize)
/**
* Opens an FSDataInputStream at the indicated Path.
* @param f the file name to open
* @param bufferSize the size of the buffer to be used.
*/
public abstract FSDataInputStream open(Path f, int bufferSize)
throws IOException;由于FileSystem.open(Path f, int bufferSize)是抽象类FileSystem的抽象方法,将具体的打开操作留给具体子类实现,例如FTPFileSystem、HarFileSystem、WebHdfsFileSystem等,不同的文件系统具有不同打开文件的行为。类图关系如下:

3)FileSystem.open->DistributedFileSystem.open:
HDFS文件系统的具体实现类是DistributedFileSystem,我们来分析DistributedFileSystem.open方法实现代码如下所示:
@Override
public FSDataInputStream open(Path f, final int bufferSize)
throws IOException {
statistics.incrementReadOps(1);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver<FSDataInputStream>() {
@Override
public FSDataInputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
//其中dfs为DFSclient类型,先调用DFSclient.open构建DFSInputStream对象
//并且从namenode那里获取该文件(path)的block info信息
final DFSInputStream dfsis =
dfs.open(getPathName(p), bufferSize, verifyChecksum);
//最后封装DFSInputStream对象到HdfsDataInputStream (FSDataInputStream的子类)
return dfs.createWrappedInputStream(dfsis);
}
@Override
public FSDataInputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.open(p, bufferSize);
}
}.resolve(this, absF);
}可以看到DistributedFileSystem.open里用dfs.open(也就是DFSClient.open)创建了个DFSInputStream对象,而DFSInputStream对象的初始化是关键,后续详解。然后,调用dfs.createWrappedInputStream封装DFSInputStream对象到DFSClient对象里。
4)DistributedFileSystem.open->DFSClient.open:
DistributedFileSystem.open里调用了DFSClient.open函数,下面我们来看DFSClient的open方法实现,代码如下所示
/**
* Create an input stream that obtains a nodelist from the
* namenode, and then reads from all the right places. Creates
* inner subclass of InputStream that does the right out-of-band
* work.
*/
public DFSInputStream open(String src, int buffersize, boolean verifyChecksum)
throws IOException, UnresolvedLinkException {
checkOpen();
// Get block info from namenode
TraceScope scope = getPathTraceScope("newDFSInputStream", src);
try {
return new DFSInputStream(this, src, verifyChecksum);
} finally {
scope.close();
}
}checkOpen方法就是检查一个标志位clientRunning,表示当前的dfs客户端对象是否已经创建并初始化,在dfs客户端创建的时候该标志就为true,表示客户端正在运行状态。我们知道,当客户端DFSClient连接到Namenode的时候,实际上是创建了一个到Namenode的RPC连接,Namenode作为Server角色,DFSClient作为Client角色,它们之间建立起Socket连接。只有显式调用DFSClient的close方法时,才会修改clientRunning的值为false,实际上真正地关闭了已经建立的RPC连接。
而DFSClient.open->DFSInputStream.DFSInputStream创建了DFSInputStream对象
5)我们来看一下创建DFSInputStream的构造方法实现:
DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum
) throws IOException, UnresolvedLinkException {
this.dfsClient = dfsClient;
this.verifyChecksum = verifyChecksum;
this.src = src;
synchronized (infoLock) {
//老版本这里的代码是prefetchSize = conf.getLong("dfs.read.prefetch.size", prefetchSize);
this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy();
}
openInfo();
}DFSInputStream的构造函数里,我们先来看看CachingStrategy的构造函数,如下:
public CachingStrategy(Boolean dropBehind, Long readahead) {
this.dropBehind = dropBehind;
this.readahead = readahead;
}而入参dropBehind和readahead是由配置参数hdfsgetconf dfs.client.cache.drop.behind.reads 和 hdfsgetconf dfs.client.cache.readahead决定的,代码如下:
public static final String DFS_CLIENT_CACHE_DROP_BEHIND_WRITES = "dfs.client.cache.drop.behind.writes";
public static final String DFS_CLIENT_CACHE_DROP_BEHIND_READS = "dfs.client.cache.drop.behind.reads";
。。。
Boolean readDropBehind = (conf.get(DFS_CLIENT_CACHE_DROP_BEHIND_READS) == null) ?
null : conf.getBoolean(DFS_CLIENT_CACHE_DROP_BEHIND_READS, false);
Long readahead = (conf.get(DFS_CLIENT_CACHE_READAHEAD) == null) ?
null : conf.getLong(DFS_CLIENT_CACHE_READAHEAD, 0);
Boolean writeDropBehind = (conf.get(DFS_CLIENT_CACHE_DROP_BEHIND_WRITES) == null) ?
null : conf.getBoolean(DFS_CLIENT_CACHE_DROP_BEHIND_WRITES, false);
this.defaultReadCachingStrategy =
new CachingStrategy(readDropBehind, readahead);
然后调用了openInfo方法,从Namenode获取到该打开文件的信息。
6)在openInfo方法中,具体实现如下所示:
/**
* Grab the open-file info from namenode
*/
void openInfo() throws IOException, UnresolvedLinkException {
synchronized(infoLock) {
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();
int retriesForLastBlockLength = dfsClient.getConf().retryTimesForGetLastBlockLength;
while (retriesForLastBlockLength > 0) {
// Getting last block length as -1 is a special case. When cluster
// restarts, DNs may not report immediately. At this time partial block
// locations will not be available with NN for getting the length. Lets
// retry for 3 times to get the length.
if (lastBlockBeingWrittenLength == -1) {
DFSClient.LOG.warn("Last block locations not available. "
+ "Datanodes might not have reported blocks completely."
+ " Will retry for " + retriesForLastBlockLength + " times");
waitFor(dfsClient.getConf().retryIntervalForGetLastBlockLength);
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();
} else {
break;
}
retriesForLastBlockLength--;
}
if (retriesForLastBlockLength == 0) {
throw new IOException("Could not obtain the last block locations.");
}
}
}openInfo函数里判断了未能成功读取文件的Block列表信息的条件,是因为Namenode无法获取到文件对应的块列表的信息,当整个集群启动的时候,Datanode会主动向NNamenode上报对应的Block信息,只有Block Report完成之后,Namenode就能够知道组成文件的Block及其所在Datanode列表的信息。openInfo方法方法中调用了fetchLocatedBlocksAndGetLastBlockLength方法,用来与Namenode进行RPC通信调用,实际获取对应的Block列表.
7)fetchLocatedBlocksAndGetLastBlockLength实现代码如下所示:
private long fetchLocatedBlocksAndGetLastBlockLength() throws IOException {
final LocatedBlocks newInfo = dfsClient.getLocatedBlocks(src, 0);
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("newInfo = " + newInfo);
}
if (newInfo == null) {
throw new IOException("Cannot open filename " + src);
}
if (locatedBlocks != null) {
Iterator<LocatedBlock> oldIter = locatedBlocks.getLocatedBlocks().iterator();
Iterator<LocatedBlock> newIter = newInfo.getLocatedBlocks().iterator();
while (oldIter.hasNext() && newIter.hasNext()) {
if (! oldIter.next().getBlock().equals(newIter.next().getBlock())) {
throw new IOException("Blocklist for " + src + " has changed!");
}
}
}
locatedBlocks = newInfo;
long lastBlockBeingWrittenLength = 0;
if (!locatedBlocks.isLastBlockComplete()) {
final LocatedBlock last = locatedBlocks.getLastLocatedBlock();
if (last != null) {
if (last.getLocations().length == 0) {
if (last.getBlockSize() == 0) {
// if the length is zero, then no data has been written to
// datanode. So no need to wait for the locations.
return 0;
}
return -1;
}
final long len = readBlockLength(last);
last.getBlock().setNumBytes(len);
lastBlockBeingWrittenLength = len;
}
}
fileEncryptionInfo = locatedBlocks.getFileEncryptionInfo();
return lastBlockBeingWrittenLength;
}而dfsClient.getLocatedBlocks的调用流程是 getLocatedBlocks(String src, long start) -> getLocatedBlocks(src, start, dfsClientConf.prefetchSize) -> callGetBlockLocations(namenode, src, start, length)->namenode.getBlockLocations->FSNamesystem.getBlockLocations->blockManager.getDatanodeManager().sortLocatedBlocks(clientMachine, blocks.getLocatedBlocks())
调用callGetBlockLocations方法,实际上是根据创建RPC连接以后得到的Namenode的代理对象,调用Namenode来获取到指定文件的Block的位置信息(位于哪些Datanode节点上):namenode.getBlockLocations(src, start, length)。调用callGetBlockLocations方法返回一个LocatedBlocks对象,该对象包含了文件长度信息、List blocks列表对象(LocatedBlocks的成员变量List<LocatedBlock> blocks;),其中LocatedBlock包含了一个Block的基本信息:
public class LocatedBlock {
private final ExtendedBlock b;
private long offset; // offset of the first byte of the block in the file
private final DatanodeInfoWithStorage[] locs;
/** Cached storage ID for each replica */
private String[] storageIDs;
/** Cached storage type for each replica, if reported. */
private StorageType[] storageTypes;
// corrupt flag is true if all of the replicas of a block are corrupt.
// else false. If block has few corrupt replicas, they are filtered and
// their locations are not part of this object
private boolean corrupt;
private Token<BlockTokenIdentifier> blockToken = new Token<BlockTokenIdentifier>();
/**
* List of cached datanode locations
*/
private DatanodeInfo[] cachedLocs;
。。。
}有了文件的这些meta信息(文件长度、文件包含的Block的位置等信息),DFSClient就能够执行后续读取文件数据的操作了,详细过程我们在后面 帖子继续分析。
2. 用一张图总结一下文件系统各个类的继承和调用关系:
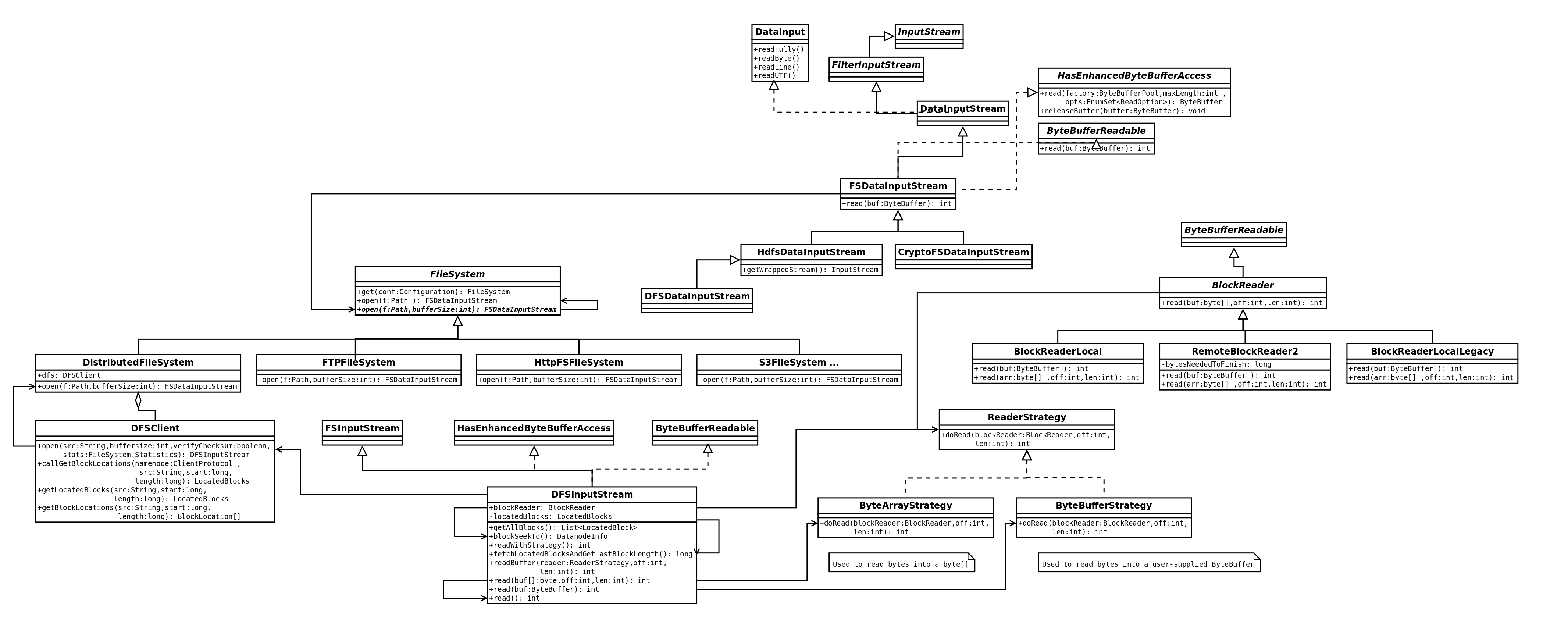
DFSInputStream是个关键类,做到了承上启下的作用,它的其中两个个关键函数 blockSeekTo(long target)和 readBuffer(strategy, off, realLen, corruptedBlockMap)是具体read操作都会经过的调用。
例如:
ByteBufferStrategy流程:
FSDataInputStream.read(ByteBuffer buf)=> read(final ByteBuffer buf) => readWithStrategy(new ByteBufferStrategy(buf))) => blockSeekTo(pos) -> readBuffer(strategy, off, realLen, corruptedBlockMap)
ByteArrayStrategy流程:
read() 读单个 byte 或者 具体的文件系统直接调用该接口读数据到buf[] => read(final byte buf[], int off, int len) => readWithStrategy(new ByteArrayStrategy(buf)) => blockSeekTo(pos) -> readBuffer(strategy, off, realLen, corruptedBlockMap)
三、总结
这篇主要分析了从用户App里调用FileSystem的API,FileSystem.open->DistributedFileSystem.open->DFSClient.open->new DFSInputStream()的调用,其中DFSInputStream的构造函数里DFSInputStream()->openInfo方法,而openInfo方法真正获取到打开文件的meta信息(文件长度、文件包含的Block的位置等信息)。
流程openInfo->fetchLocatedBlocksAndGetLastBlockLength-> getLocatedBlocks(String src, long start) -> getLocatedBlocks(src, start, dfsClientConf.prefetchSize) -> callGetBlockLocations(namenode, src, start, length)后,把获取到的block信息等保存到DFSInputStream的成员变量locatedBlocks和其它成员变量里。
四、后续分析
在获取到的block信息等信息后,由于block可能是本地的或者远程的,它们是怎么被读的?
请后续分析:https://blog.csdn.net/don_chiang709/article/details/86496541
五、参考
老版本的Hadoop源码分析: http://shiyanjun.cn/archives/925.html
最后
以上就是威武导师最近收集整理的关于HDFS读数据分析(一):用户的读文件代码是怎么走到HDFS,获取block位置信息的?的全部内容,更多相关HDFS读数据分析(一):用户内容请搜索靠谱客的其他文章。








发表评论 取消回复