说明:
本文的部署方式是传统的解压包方式和Linux标准方式。配置的基本环境是win10下的Vmware workstation12.1pro,Linux版本为Centos 7.2,hadoop版本为hadoop3.0.0。部署完成后是一个cMaster主节点节点和两个从节点(cSlave0和cSlave1),均运行在Vmware虚拟机中。本文仅保证在该环境下配置能够正常使用,其他环境请自行酌情修改。
配置步骤:
1. 准备资源和环境。
下载Centos 7.2 的iso安装镜像,jdk1.8 for Linux压缩包,hadoop3.0.0压缩包。下载链接分别如下:
https://www.centos.org/download/
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
http://hadoop.apache.org/releases.html
下载完成后如图所示
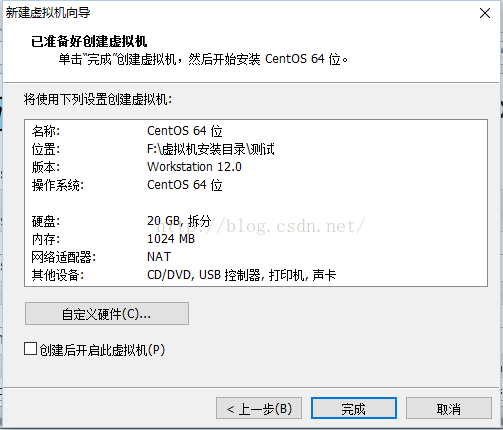
2. 安装虚拟机。
在Vmware workstation中用典型 typical 方式安装Centos7 ,每个虚拟机的资源为单核、1G内存、20GB磁盘。网络类型为NAT。
在安装的时候机器名称设置为cMaster(注意此处的名称只是在Vmware中的一个标识而已,真正新安装的centos7 系统里的机器名都为localhost.localdomain)
 啊
啊
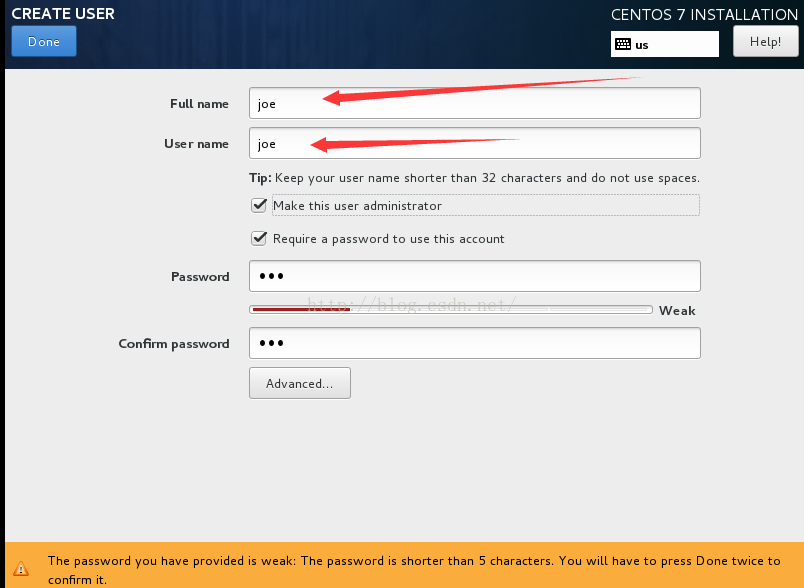
用户名使用joe 密码也为joe(可自行更改)
重复以上步骤,分别安装cSlave0和cSlave1两个从节点的虚拟机。
(只是在机器名处分别填写cSlave0 和cSlave1,其他步骤都相同)
注意:centos7默认是进行最小化安装,安装完成后是不带有图形化界面。如果需要图形化界面在软件安装选项里要勾选上gnome。
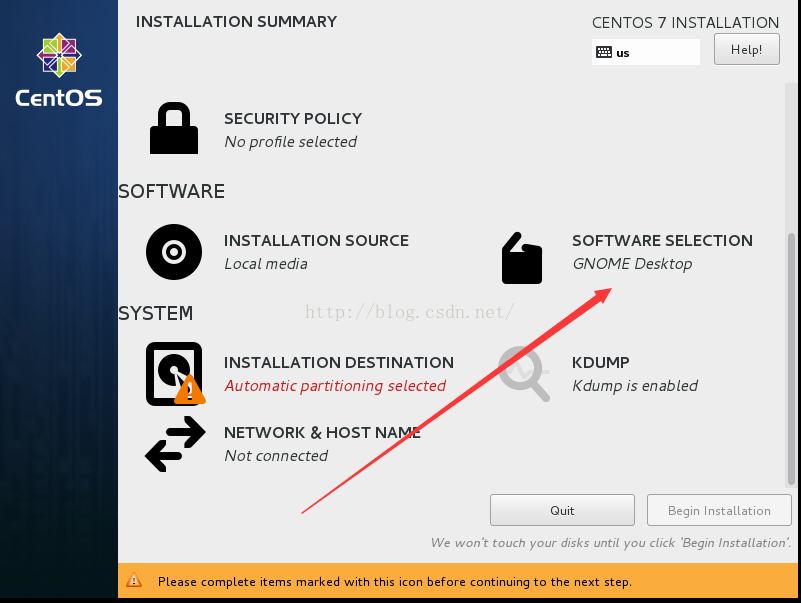
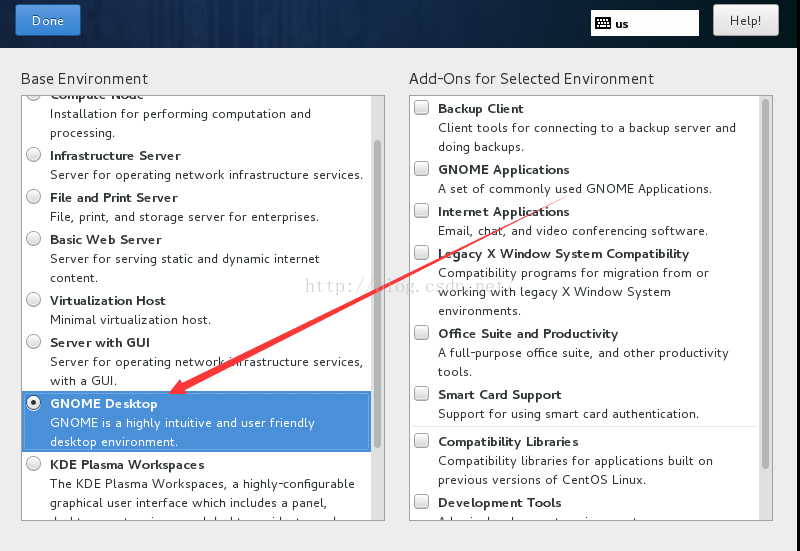
3. 修改配置文件。
当三台虚拟机均安装完成后,需要进行的是修改机器名、添加域名映射、关闭防火墙,并安装jdk。
(1) 修改机器名。
打开终端,切换到root用户下修改机器名称。
$ sudo su
$ vim /etc/sysconfig/network
在其中添加“HOSTNAME=cMaster”,然后重启当前虚拟机,再查看机器名就是cMaster了。
(如果重启之后机器名不是cMaster,可以使用命令hostnamectl set-hostnamecMaster 修改机器名)
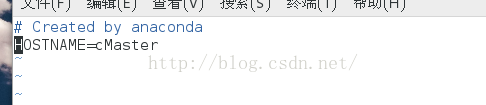

(2) 添加域名映射
使用ifconfig命令分别查看三台虚拟机的IP地址。然后将三个ip地址都添加到各自的/etc/hosts文件中。
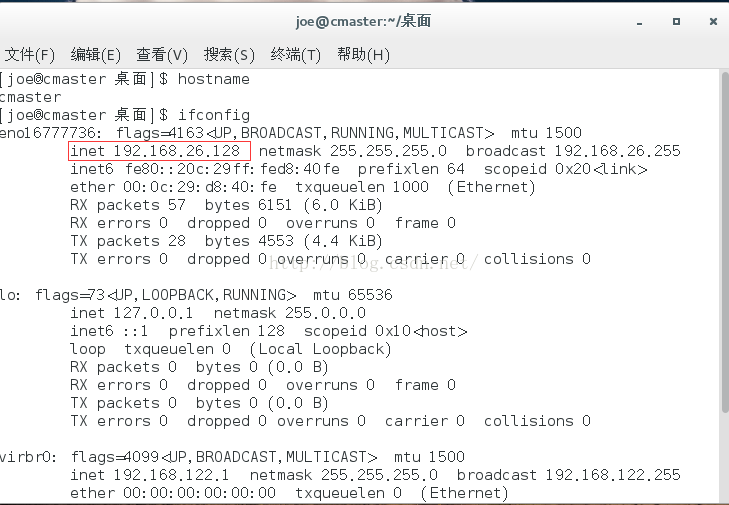
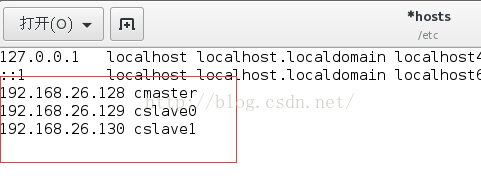
3台机器均修改完成后,使用pingslave0/cmaster/cslave1命令测试各机器之间是否能够正常通三台机信。如果出现下图所示信息说明通信正常。
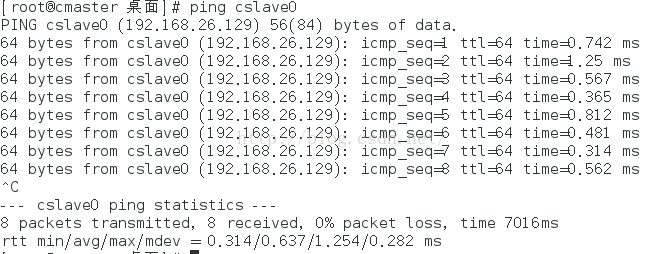
(3) 关闭当前机器的防火墙。
在root权限下执行以下两条指令,关闭防火墙并阻止其开机启动。
systemctl stop firewalld.service#停止firewall
systemctl disable firewalld.service#禁止firewall开机启动
(4) 安装JDK。
将之前下载好的jdk复制到虚拟机中的/home/joe/目录下,
使用命令rpm –ivh /home/joe/jdk-8u101-linux-x64.rpm解压安装
安装完成后使用javac命令测试jdk是否安装成功,如果出现了如下图提示,说明安装jdk成功。

4.解压hadoop,部署hadoop
(1)按照以上步骤配置完成后,最好重启一下所有机器,确保所有的设置生效。
然后利用joe账户分别登录三台机器。将事先下载好的hadoop压缩包复制到每台机器的/home/joe/目录下,然后在每一台机器上分别使用
tar–zxvf /home/joe/ hadoop-3.0.0-alpha1.tar.gz 命令解压安装hadoop3.0.

(2)解压完成后需要修改hadoop的配置文件。
(本小节步骤在三台机器上都完全相同,三台机器都需要进行修改)
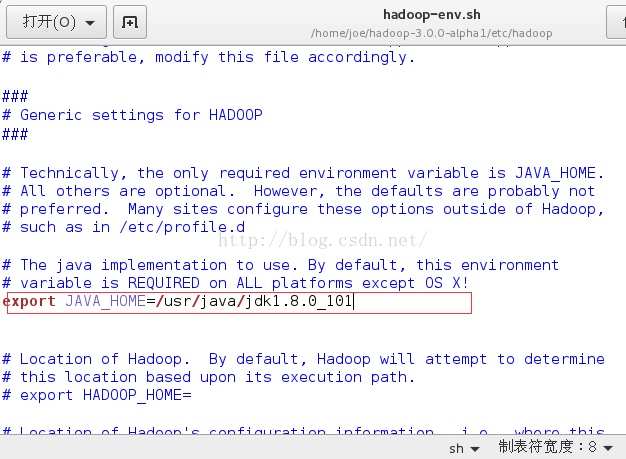
A.使用如下指令编辑hadoop-env.sh文件
gedit/home/joe/hadoop-3.0.0-alpha1/etc/hadoop/hadoop-env.sh
在文件中找到exportJAVA_HOME=${JAVA_HOME}
修改为exportJAVA_HOME=/usr/java/jdk1.8.0_101(填写自己安装的jdk的路径)
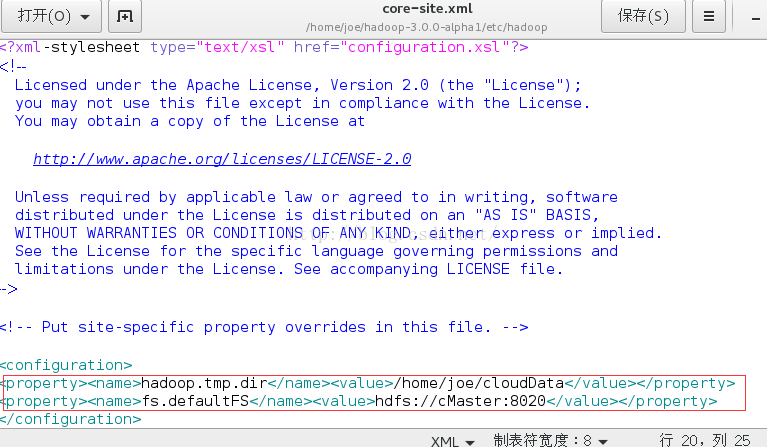
B.修改core-site.xml文件
使用命令gedit/home/joe/hadoop-3.0.0-alpha1/etc/hadoop/core-site.xml
在<configuration>标签之间插入以下内容。
<property><name>hadoop.tmp.dir</name><value>/home/joe/cloudData</value></property>
<property><name>fs.defaultFS</name><value>hdfs://cMaster:8020</value></property>
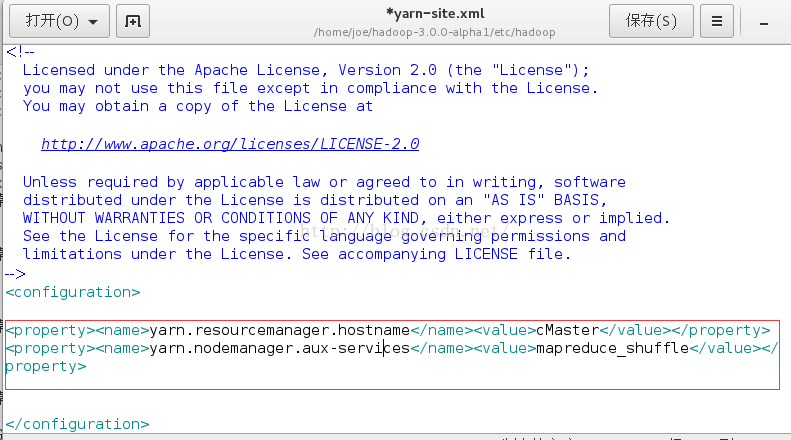
C.修改yarn-site.xml文件
使用以下命令修改gedit /home/joe/hadoop-3.0.0-alpha1/etc/hadoop/yarn-site.xml
在<configuration>标签之间插入以下内容
<property><name>yarn.resourcemanager.hostname</name><value>cMaster</value></property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
D.修改mapred-site.xml.template
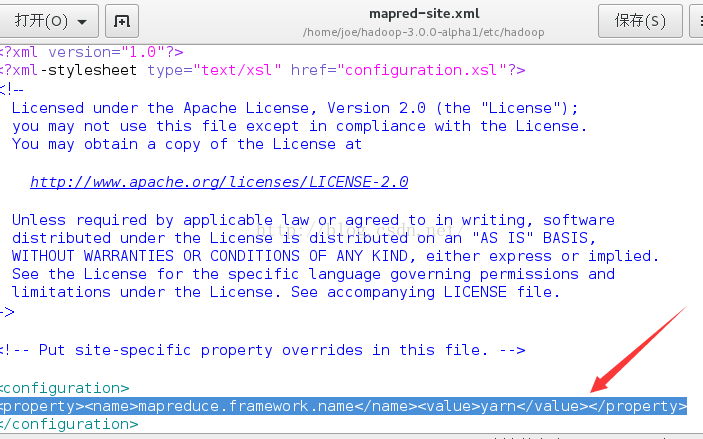
将/home/joe/hadoop-3.0.0-alpha1/etc/hadoop/目录下的mapred-site.xml.template重命名为mapred-site.xml
并用命令gedit/home/joe/hadoop-3.0.0-alpha1/etc/hadoop/mapred-site.xml
在<configuration>标签之间加入如下内容:
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
E.启动hadoop
首先格式化主节点命名空间,使用命令:
/home/joe/hadoop-3.0.0-alpha1/bin/hdfsnamenode –formate
其次在主节点上启动存储服务和资源管理主服务。使用命令:
/home/joe/hadoop-3.0.0-alpha1/sbin/hadoop-daemon.sh start namenode #启动主存储服务
/home/joe/hadoop-3.0.0-alpha1/sbin/yarn-daemon.sh start resourcemanager # 启动资源管理服务。
最后在从节点上启动存储从服务和资源管理从服务(以下两条命令要在两台机器上分别执行)
/home/joe/hadoop-3.0.0-alpha1/sbin/hadoop-daemon.sh start datanode #启动从存储服务
/home/joe/hadoop-3.0.0-alpha1/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务

服务启动后在三台机器上分别使用jps命令查看是否启动。
cSlave0和cSlave1如下图所示

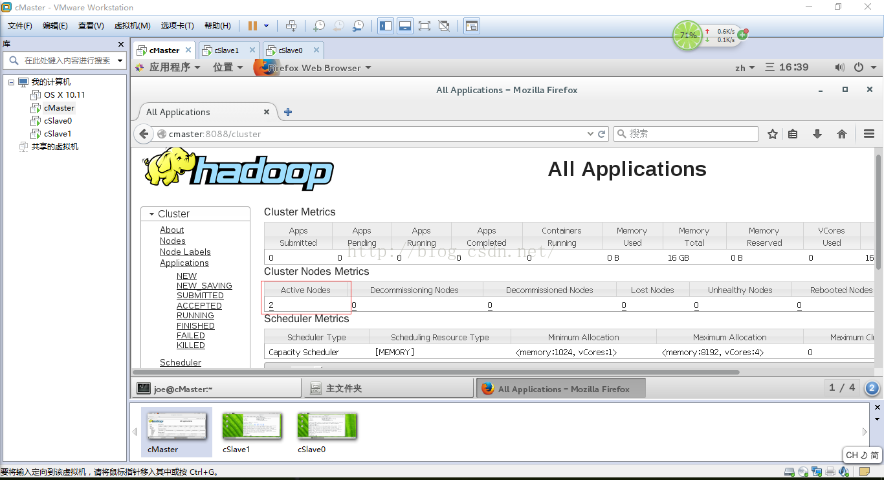
cMaster节点显示如下图所示

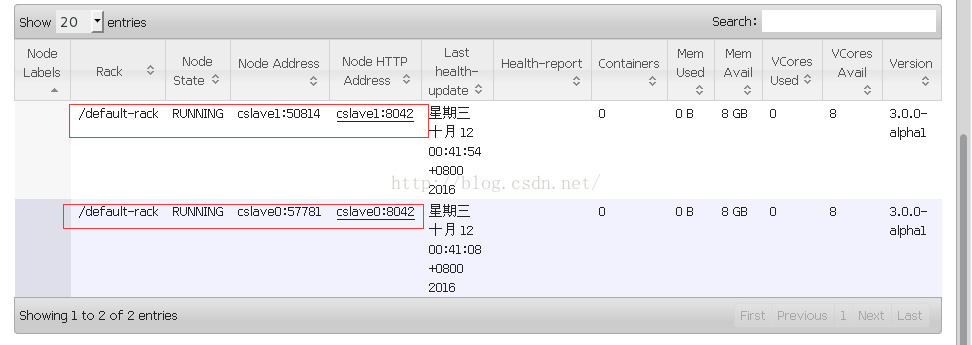
在cMaster机器的浏览器地址栏里输入cMaster:50070可以看到HDFS的相关信息,cMaster:8088可以看到Yarn的相关信息。
如图还可以查看从节点的信息。
至此 Hadoop3.0的配置工作已经完成了。接下来可以使用示例程序Wordcount来利用分布式系统统计某个文件中单词出现的次数。
在cMaster上以joe用户登录,然后执行以下的操作命令:
cd/home/joe/hadoop-3.0.0-alpha1/
bin/hdfs dfs -mkdir /in
bin/hdfs dfs -put/home/joe/hadoop-3.0.0-alpha1/etc/hadoop/* /in
bin/hadoop jarshare/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha1.jar wordcount /in /out/wc
如下图,在浏览器中输入cMaster:50070 可以看到hdfs,切换到相应文件夹下可以看到统计出的结果。
最后
以上就是优美便当最近收集整理的关于centos7 下配置hadoop3.0 教程的全部内容,更多相关centos7内容请搜索靠谱客的其他文章。








发表评论 取消回复