进入第二季之后,开始熟悉第二季的平台,在延续了第一季的算法后,在大数据上约取得了4%的F1值,itemCF是在map-reduce下完成,统计模型是
基本在基于odps的sql操作表级下完成
之后转战回归模型
这里先回忆一下回归模型的基础:
谓LR分类器(Logistic Regression Classifier),并没有什么神秘的。在分类的情形下,经过学习之后的LR分类器其实就是一组权值w0,w1,...,wm.
当测试样本集中的测试数据来到时,这一组权值按照与测试数据线性加和的方式,求出一个z值:
z = w0+w1*x1+w2*x2+...+wm*xm。 ① (其中x1,x2,...,xm是某样本数据的各个特征,维度为m)
之后按照sigmoid函数的形式求出:
σ(z) = 1 / (1+exp(z)) 。②
由于sigmoid函数的定义域是(-INF, +INF),而值域为(0, 1)。因此最基本的LR分类器适合于对两类目标进行分类。
那么LR分类器的这一组权值w0,w1,...,wm是如何求得的呢?这就需要涉及到极大似然估计MLE和优化算法的概念了。
我们将sigmoid函数看成样本数据的概率密度函数,每一个样本点,都可以通过上述的公式①和②计算出其概率密度
逻辑回归模型
考虑具有p个独立变量的向量![]() ,设条件概率
,设条件概率![]() 为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为
为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为
![]() (1.1)
(1.1)
上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。

其中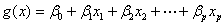 。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
 (1.2)
(1.2)
定义不发生事件的条件概率为
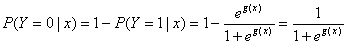 (1.3)
(1.3)
那么,事件发生与事件不发生的概率之比为
![]() (1.4)
(1.4)
这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0<p<1,故odds>0。对odds取对数,即得到线性函数,
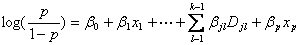 (1.5),
(1.5),
极大似然函数
假设有n个观测样本,观测值分别为![]() 设
设![]() 为给定条件下得到yi=1(原文
为给定条件下得到yi=1(原文![]() )的概率。在同样条件下得到yi=0(
)的概率。在同样条件下得到yi=0(![]() )的条件概率为
)的条件概率为![]() 。于是,得到一个观测值的概率为
。于是,得到一个观测值的概率为
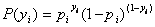 (1.6) -----此公式实际上是综合前两个等式得出,并无特别之处
(1.6) -----此公式实际上是综合前两个等式得出,并无特别之处
因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
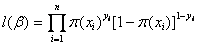
上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数![]() ,使上式取得最大值。
,使上式取得最大值。
对上述函数求对数
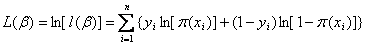 (1.8)
(1.8)
上式称为对数似然函数。为了估计能使![]() 取得最大的参数
取得最大的参数![]() 的值。
的值。
之后我们结合自己选取的特征利用LP的方法进行处理,再融合了itenCF的方法
最后
以上就是无奈乌龟最近收集整理的关于天猫大数据3—回归模型的全部内容,更多相关天猫大数据3—回归模型内容请搜索靠谱客的其他文章。








发表评论 取消回复