立即学习:https://edu.csdn.net/course/play/6861/341446?utm_source=blogtoedu
静态网页:可以通过f12 快捷键获取前段所有信息,每一个链接信息都不一样
动态网页:点击下一个网页,但是页面无变化,例如天气相关的网页

从当前页找到异步页
从天气页面f12 network js 点击下一个月
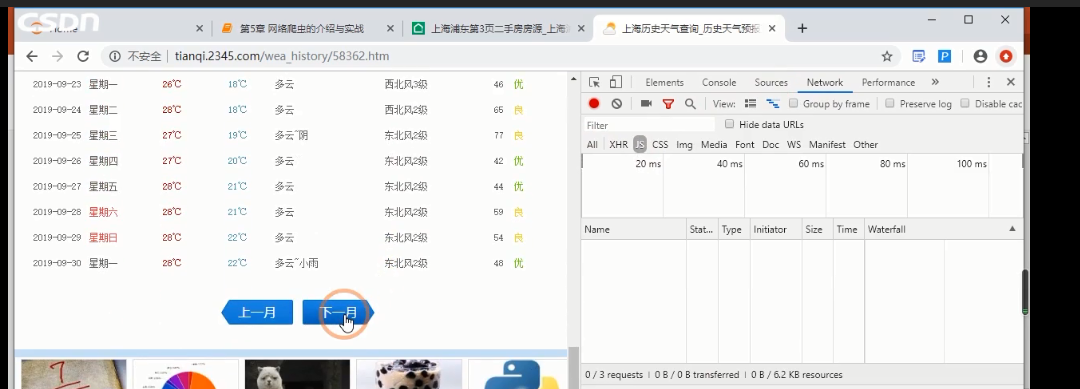
多出了一个刷新的文件
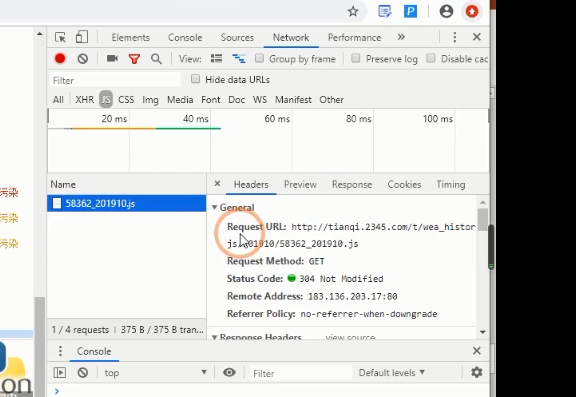
找到request URL 复制到浏览器地址栏中得到

不是html文件就不能使用beautifulSoup
只能使用正则表达式
例如:找到2019年10月1日的天气信息
并列出表格
日期:
date = re.findall("ymd:'([d-]+)'",response.text);
print(date)
温度:
re.findall("bWendu:'([d-]+)℃'",response.text)
url = r'http://tianqi.2345.com/t/wea_history/js/201910/71141_201910.js'
response = requests.get(url)
print(response.text)
date = re.findall("ymd:'([d-]+)'",response.text)
#print(date)
tem = re.findall("bWendu:'([d-]+)℃'",response.text)
wea = re.findall("tianqi:'(.*?)'",response.text)
fengxiang = re.findall("fengxiang:'(.*?)'",response.text)
kongqi = re.findall("aqiInfo:'(.*?)'",response.text)
pd.DataFrame({'date':date,'tem':tem,'wea':wea,'fengxiang':fengxiang,'kongqi':kongqi})
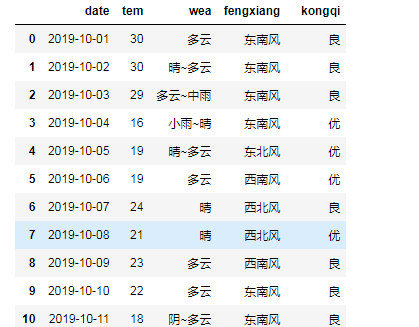
最后
以上就是热心皮卡丘最近收集整理的关于学习笔记(28):零基础搞定Python数据分析与挖掘-爬虫案例3 -- 历史天气数据的全部内容,更多相关学习笔记(28):零基础搞定Python数据分析与挖掘-爬虫案例3内容请搜索靠谱客的其他文章。








发表评论 取消回复