Do We Really Need to Access the Source Data? Source Hypothesis Transfer for
Unsupervised Domain Adaptation
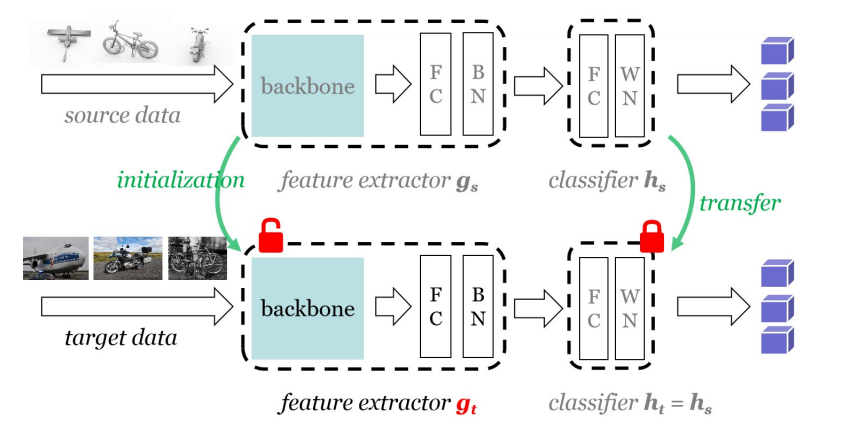
个人感觉这篇论文的思想还是挺好的,出发点很贴近实际,我对于迁移学习的理解很少,但据我所知,之前有关迁移学习的大多模型都是需要用到源域的数据或者特征,而这在现实中其实是不切实际的,因为源域的数据其实也包含着隐私,如果直接将其暴露那势必会遭到隐私泄露,这似乎也是该文章的一个目的。 所以该文章在只包含源域训练好的模型下,固定分类器,利用目标域数据来训练预训练好的特征提取器,使其最后再目标域上也能有良好的性能表现。
于是自己首先复现了这篇论文,发现在MNIST >>>>usps的迁移效果很好,而且是否使用标签平滑也就是代码中’–cls_par’的选择对最终的结果影响并不大,感觉会不会是数据集的原因?
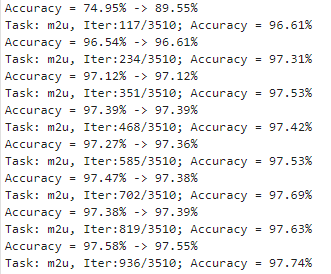
在源码中,整个算法大致也就是三个过程,首先训练源域数据,该过程没有什么特别的
#加过标签平滑的交叉熵损失 只会在源域的训练中使用到
classifier_loss = loss.CrossEntropyLabelSmooth(num_classes=args.class_num, epsilon=args.smooth)(outputs_source, labels_source)
而CrossEntropyLabelSmooth损失在loss.py中的形式就是
log_probs = self.logsoftmax(inputs)
targets = torch.zeros(log_probs.size()).scatter_(1, targets.unsqueeze(1).cpu(), 1)
if self.use_gpu: targets = targets.cuda()
#target表示的就是标签平滑后的损失 epsilon是就标签平滑系数
targets = (1 - self.epsilon) * targets + self.epsilon / self.num_classes
if self.size_average: #如果采用size_average的话会取一个平均值
loss = (- targets * log_probs).mean(0).sum()
else:
loss = (- targets * log_probs).sum(1)
return loss
在训练好源域得到模型后,随即丢弃源域数据,然后用训练好的网路来初始化目标域对应的网络,最后固定住模型的分类器,只训练F以及B,具体地,在代码中的展现过程就是:
#读取预训练好的模型参数
args.modelpath = args.output_dir + '/source_F.pt'
netF.load_state_dict(torch.load(args.modelpath))
args.modelpath = args.output_dir + '/source_B.pt'
netB.load_state_dict(torch.load(args.modelpath))
args.modelpath = args.output_dir + '/source_C.pt'
netC.load_state_dict(torch.load(args.modelpath))
netC.eval()
for k, v in netC.named_parameters():
v.requires_grad = False #此操作是不是代表着固定住分类器,不参与训练
在原文中,目标域的损失函数为:
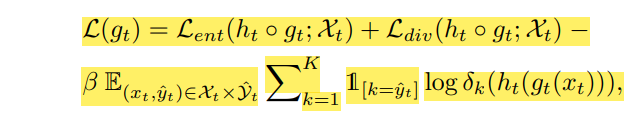
它在论文中的体现就是:
inputs_test = inputs_test.cuda() #加载测试输入
features_test = netB(netF(inputs_test)) #提取输入的特征
outputs_test = netC(features_test) #得到对应的的输出结果
if args.cls_par > 0: #cls_par 表示的应该是整个损失的β值 如果选用该策略就提取伪标签
pred = mem_label[tar_idx]
classifier_loss = args.cls_par * nn.CrossEntropyLoss()(outputs_test, pred) #该损失就是分类器交叉熵损失
else:
classifier_loss = torch.tensor(0.0).cuda() #如果不取用伪标签 则整个损失的最后一项就是0
if args.ent: #默认使用信息最大化损失 IM loss
softmax_out = nn.Softmax(dim=1)(outputs_test)
entropy_loss = torch.mean(loss.Entropy(softmax_out)) # 该损失应该就是对应着Lent
if args.gent:
msoftmax = softmax_out.mean(dim=0) #msoftmax表示的应该是Pk
entropy_loss -= torch.sum(-msoftmax * torch.log(msoftmax + 1e-5))
#torch.sum(-msoftmax * torch.log(msoftmax + 1e-5)) 该损失应该对应着Ldiv
im_loss = entropy_loss * args.ent_par #还有一个乘法系数?
classifier_loss += im_loss #感觉这里整个符号是不是取反了? 跟论文里的损失描述不一致
optimizer.zero_grad()
classifier_loss.backward()
optimizer.step()
如果不选用伪标签策略,其实到这里,整个训练过程也就结束了,就可以得到上面那张图的结果。如果选取了伪标签策略,那就还有一个obtain_label的过程,其中核心代码为:
all_fea = torch.cat((all_fea, torch.ones(all_fea.size(0), 1)), 1) #
all_fea = (all_fea.t() / torch.norm(all_fea, p=2, dim=1)).t()
all_fea = all_fea.float().cpu().numpy()
print(all_fea.size())
K = all_output.size(1)
aff = all_output.float().cpu().numpy()
initc = aff.transpose().dot(all_fea)
initc = initc / (1e-8 + aff.sum(axis=0)[:,None])
dd = cdist(all_fea, initc, 'cosine') #计算两组输入之间的距离 对应论文中聚类的过程
pred_label = dd.argmin(axis=1)
acc = np.sum(pred_label == all_label.float().numpy()) / len(all_fea)
for round in range(1): #实验结果证明只用更新一次就可以得到一个较好的结果
aff = np.eye(K)[pred_label] #
initc = aff.transpose().dot(all_fea)
initc = initc / (1e-8 + aff.sum(axis=0)[:,None])
dd = cdist(all_fea, initc, 'cosine')
pred_label = dd.argmin(axis=1)
acc = np.sum(pred_label == all_label.float().numpy()) / len(all_fea)
log_str = '这个可是获取label过程中的哦 Accuracy = {:.2f}% -> {:.2f}%'.format(accuracy*100, acc*100)
args.out_file.write(log_str + 'n')
args.out_file.flush()
print(log_str+'n')
return pred_label.astype('int') #返回的是预测的伪标签
这一部分代码设计到了很多矩阵计算,只能大致的理解这个过程是一个聚类的过程,但是还是有些地方不是很明白,被维数给弄昏头了,0.0
基于这个,我自己也尝试做了个实验,将同一种数据集变道两个分布,其中一个分布的数据集作为源域进行训练,然后另外一个分布做为目标域按照它的方法来进行迁移,但是最终的结果就很差,Accracy大概也就是随机猜的概率,不知道问题出在了哪里,人没了。
参考文献《Do We Really Need to Access the Source Data? Source Hypothesis Transfer for
Unsupervised Domain Adaptation》
源码地址:https://github.com/tim-learn/SHOT
最后
以上就是傻傻水壶最近收集整理的关于记一次不成功的迁移学习《Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervise》的全部内容,更多相关记一次不成功的迁移学习《Do内容请搜索靠谱客的其他文章。








发表评论 取消回复