一、前言
不卷了,能用就行!
哈哈哈,说好的不卷了,能凑活用就行了。但每次接到新需求时都手痒,想结合着上一次的架构设计和落地经验,在这一次需求上在迭代更新,或者找到完全颠覆之前的更优方案。卷完代码的那一刻总是神清气爽
其实大部分喜欢写代码的一类纯粹码农,都是比较卷的,就比如一个需求在实现上是能用大概是P5、如果这个做出来的功能不只是能用还非常好用是P6、除了好用还凝练共性需求开发成通用的组件服务是P7。每一个成长过来的码农,都是在造轮子的路上一次次验证自己的想法和加以实践,绝对不是一篇篇的八股文就能累出来一个高级的技术大牛。
二、延迟任务场景
什么是延迟任务?
当我们的实际业务需求场景中,有一些活动开始前的状态变更、订单结算后的T+1对账、贷款单息费的产生,都是需要使用到延迟任务来进行触达。实际的操作一般会有 Quartz、Schedule 来对你的库表数据进行定时扫描和处理,当条件满足后做数据状态的变更或者产生新的数据插入到表中。
这样一个简单的需求就是延迟任务最初需求,如果需求前期内容较少、使用方不多,可能在实际开发中就只是一个单台机器直接对着表一顿轮训就完事了。但随着业务需求的发展和功能的复杂度提升,往往反馈到研发设计和实现,就不那么简单了,比如:你需要保障尽可能低延迟完成较大规模的数据量扫描处理,否则就像贷款单息费的产生,已经到了第二天用户还没看到自己的息费信息或者是还款后的重新对账,可能就这个时候就要产生客诉了。
那么,类似这样的场景该如何设计呢?
三、延迟任务设计
通常的任务中心处理流程主要,主要是由定时任务扫描任务库表,把即将达到超时时间的任务信息扫描到处理队列(内存/MQ消息),再由业务系统进行处理任务,处理完成后更新库表中的任务状态。
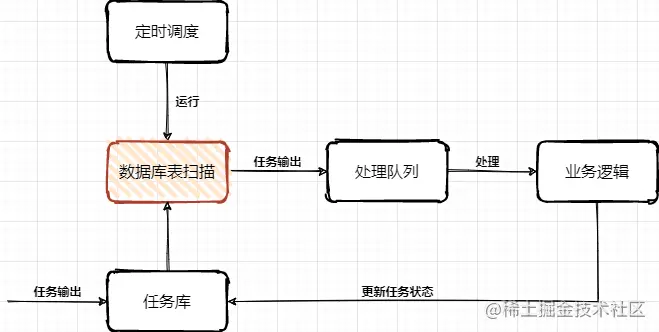
问题:
- 海量数据规模较大的任务列表数据,在分库分表下该需要快速扫描。
- 任务扫描服务与业务逻辑处理,耦合在一起,不具有通用性和复用性。
- 细分任务体系有些是需要低延迟处理的,不能等待过长时间。
1. 任务表方式
除了一些较小的状态变更场景,例如在各自业务的库表中,就包含了一个状态字段,这个字段一方面有程序逻辑处理变更的状态,也有到达指定到期时间后由任务服务自动变更处理的操作,一般这类功能,直接设计到自己的库表中即可。
那么还有一些较大也较为频繁使用的场景,如果都是在每个系统的各自所需的N多个表中,都添加这样的字段进行维护,就显得非常冗余了,也不那么易于维护。所以针对这样的场景就很适合做一个通用的任务延时系统,各业务系统把需要被延时执行的动作提交到延时系统中,再有延时系统在指定时间下进行回调,回调的动作可以是接口或者MQ消息进行触达。例如可以设计这样一个任务调度表:
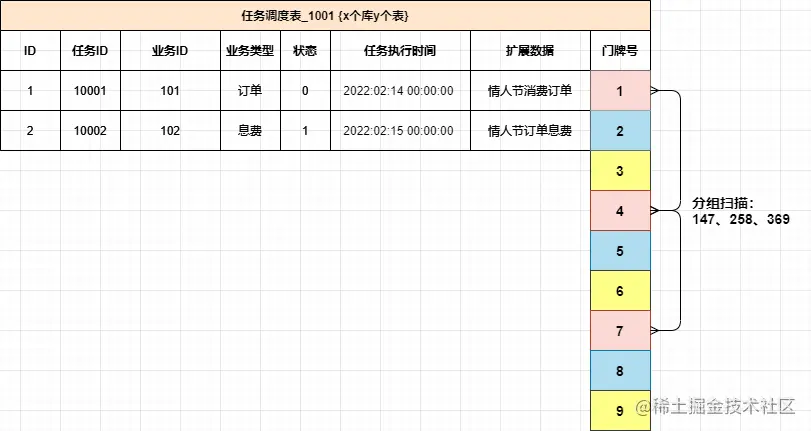
- 抽取的任务调度表,主要是拿到什么任务,在什么时间发起动作,具体的动作处理仍交给业务工程处理。
- 大批量的各自业务的任务进行集中处理,则需要设计一个分库分表,满足于后续业务体量的增长。
- 门牌号设计,针对一张表的扫描,如果数据量较大,又不希望只是一个任务扫描一个表,可以多个任务扫描一个表,加到扫描的体量。这个时候就需要一个门牌号来隔离不同任务扫描的范围,避免扫描出重复的任务数据。
2. 低延迟方式
低延迟处理方案,是在任务表方式的基础上,新增加的时间把控处理。它可以把即将到期的前一段时间的任务,放置到 Redis 集群队里中,在消费的时候再从队列中 pop 出来,这样可以更快的接近任务的处理时效,避免因为扫库间隔较大延迟任务执行。
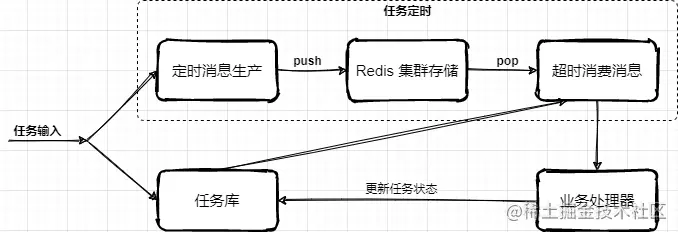
- 在接收业务系统提交进来的延迟任务时,按照执行时间的长短放置到任务库或者也同步到 Redis 集群中,一些执行时间较晚的任务则可以先放到任务库,再通过扫描的方式添加到超时任务执行队列中。
- 那么关于这块的设计核心在于 Redis 队列的使用,以及为了保证消费的可靠性需要引入二阶段消费、注册 ZK 注册中心至少保证一次消费的处理。本文重点主要放在 Redis 队列的设计,其他更多的逻辑处理,可以按照业务需求进行扩展和完善
Redis 消费队列
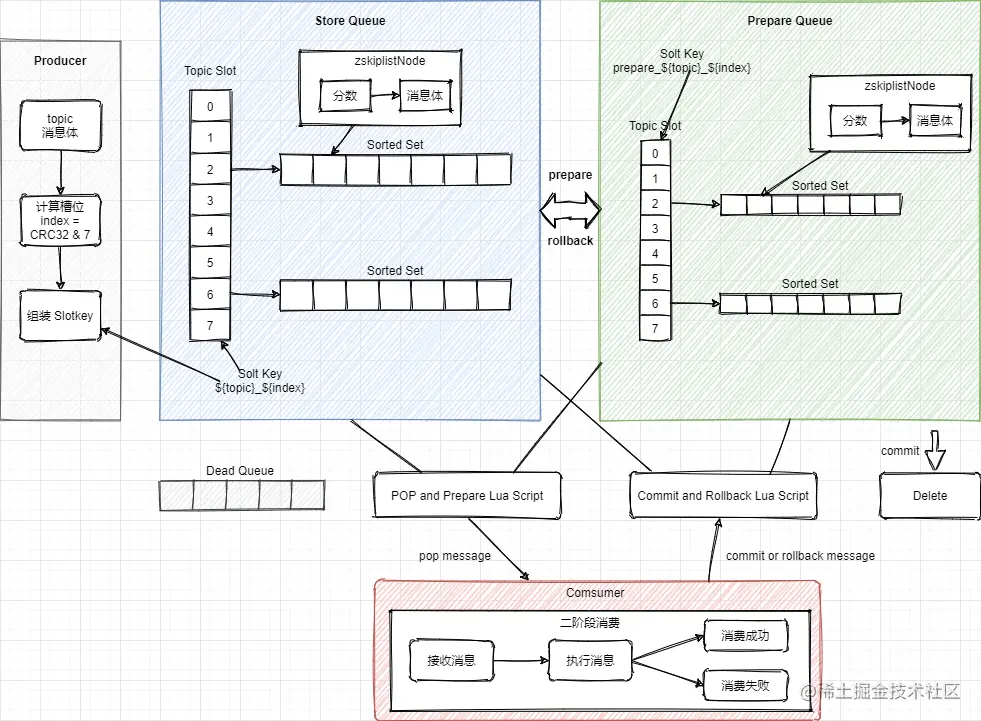
- 按照消息体计算对应数据所属的槽位 index = CRC32 & 7
- StoreQueue 采用 Slot 按照 SlotKey = #{topic}_#{index} 和 Sorted Set 的数据结构按执行任务分数排序,存放任务执行信息。定时消息将时间戳作为分数,消费时每次弹出分数小于当前时间戳的一个消息
- 为了保障每条消息至少可消费一次,消费者不是直接 pop 有序集合中的元素,而是将元素从 StoreQueue 移动到 PrepareQueue 并返回消息给消费者。消费成功后再从 PrepareQueue 从删除,如果消费失败则从PreapreQueue 重新移动到 StoreQueue,这样二阶段消费的方式进行处理。
- 参考文档:2021 阿里技术人的百宝黑皮书PDF文,低延迟的超时中心实现方式
简单案例
@Test
public void test_delay_queue() throws InterruptedException {
RBlockingQueue<Object> blockingQueue = redissonClient.getBlockingQueue("TASK");
RDelayedQueue<Object> delayedQueue = redissonClient.getDelayedQueue(blockingQueue);
new Thread(() -> {
try {
while (true){
Object take = blockingQueue.take();
System.out.println(take);
Thread.sleep(10);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
int i = 0;
while (true){
delayedQueue.offerAsync("测试" + ++i, 100L, TimeUnit.MILLISECONDS);
Thread.sleep(1000L);
}
}
测试数据
2022-02-13 WARN 204760 --- [ Finalizer] i.l.c.resource.DefaultClientResources : io.lettuce.core.resource.DefaultClientResources was not shut down properly, shutdown() was not called before it's garbage-collected. Call shutdown() or shutdown(long,long,TimeUnit)
测试1
测试2
测试3
测试4
测试5
Process finished with exit code -1
- 源码:github.com/fuzhengwei/…
- 描述:使用 redisson 中的 DelayedQueue 作为消息队列,写入后等待消费时间进行 POP 消费。
四、总结
- 调度任务的使用在实际的场景中非常频繁,例如我们经常使用 xxl-job,也有一些大厂自研的分布式任务调度组件,这些可能原本都是很小很简单的功能,但经过抽象、整合、提炼,变成了一个个核心通用的中间件服务。
- 当我们在考虑使用任务调度的时候,无论哪种方式的设计和实现,都需要考虑这个功能使用时候的以为迭代和维护性,如果仅仅是一个非常小的场景,又没多少人使用的话,那么在自己机器上折腾就可以。过渡的设计和使用有时候也会把研发资源代入泥潭
- 其实各项技术的知识点,都像是一个个工具,刀枪棍棒斧钺钩,那能怎么结合各自的特点,把这些兵器用起来,才是一个程序员不断成长的过程。如果你希望了解更多此类有深度的技术内容,可以加入 Lottery 分布式抽奖秒杀系统 学习更有价值的更抗用的实战手段。
原文链接:https://juejin.cn/post/7064732138339303431
作者:马小莫QAQ
链接:https://www.jianshu.com/p/70110459ca88
相关资源:
Redis数据的导出和导入 - Dcsdn
GitOps 初探 - Dcsdn
java 对Redis的导入和导出 - Dcsdn
最后
以上就是高贵小蜜蜂最近收集整理的关于给面试加点硬菜:延迟任务场景,该如何提高吞吐量和时效性的全部内容,更多相关给面试加点硬菜:延迟任务场景内容请搜索靠谱客的其他文章。








发表评论 取消回复