计算机的组成
- 运算器,进行运算,算术运算和逻辑运算
- 控制器,控制指令的执行
- 存储器,包括内存和外存,外存有硬盘,u盘等形式
- 输入设备,鼠标,键盘等
- 输出设备,比如显示器
运算器和控制器组成中央处理单元cpu,但是cpu的范围更大一下,还包括一些寄存器,总线等
运算器中比较重要的寄存器
- 算术逻辑单元ALU
负责进行算术运算和逻辑运算 - 累加寄存器AC
存储源操作数,比如一个数加另一个数,在累加计算器中存储一个加数,算术逻辑单元中也只能存储一个加数,运算完成得到的结果没有别的地方存储,会重新存在累加寄存器中,当做源操作数 - 数据缓冲寄存器DR
暂时存储数据和指令 - 状态条件寄存器PSW
存储条件码,比如溢出状态,除数为0等 - 不只有上述几个寄存器,只是上面几个比较重要
控制器中比较重要的寄存器
- 指令寄存器IR
暂时存储要执行的指令 - 程序计数器PC
很重要,存储指令执行的地址,要根据这个地址取出指令,然后执行 - 地址寄存器AR
保存当前程序正在访问的地址 - 指令译码器ID
分析指令操作码,将指令编译成可执行的内容 - 不只有上述几个寄存器,只是上面几个比较重要
指令和数据都存储在地址中,怎么判断取出的是指令还是数据呢?
- 根据指令的执行周期来判断取出的是指令还是数据
- 指令的执行周期是先取出指令,然后分析指令操作码,之后再执行指令,执行指令的时候才会去取数据
- 所以一开始取得是指令,在指令执行的时候取得是数据
一些寄存器的英文缩写
- PC程序计数器,控制器
- AR地址寄存器,控制器
- DR数据缓冲寄存器,运算器
- ID指令译码器,控制器
- PSW状态条件寄存器,运算器
- IR指令寄存器,控制器
- ALU算术逻辑单元,运算器
- AC累加寄存器,运算器
奇偶校验码
相关概念
码距
- 对于单个编码来说,要变成另一个编码只需要改变一位,所以码距为1,比如00改变一位就可以变成01或10
- 对于两个编码来说,A编码要变成B编码需要改变的位数,其实就是A编码和B编码有几位数不一样,比如00到11的码距就是2
- 对于校验来说,码距越大就越利于检错和纠错。因为码距越大,A编码就越不容易变成B编码
奇偶校验
- 奇偶校验就是在原本的编码最后面加一位校验码(注意只加一位),使得编码中1的个数为奇数(奇校验)或偶数(偶校验),这样码距就变成了2,也就是在传输一个编码时,这个编码最少变两个数,才会在接收的时候被当做正确数据接收。其实如果变得数多于两位,也必须是偶数个,才会被当做正确数据接收。
例子
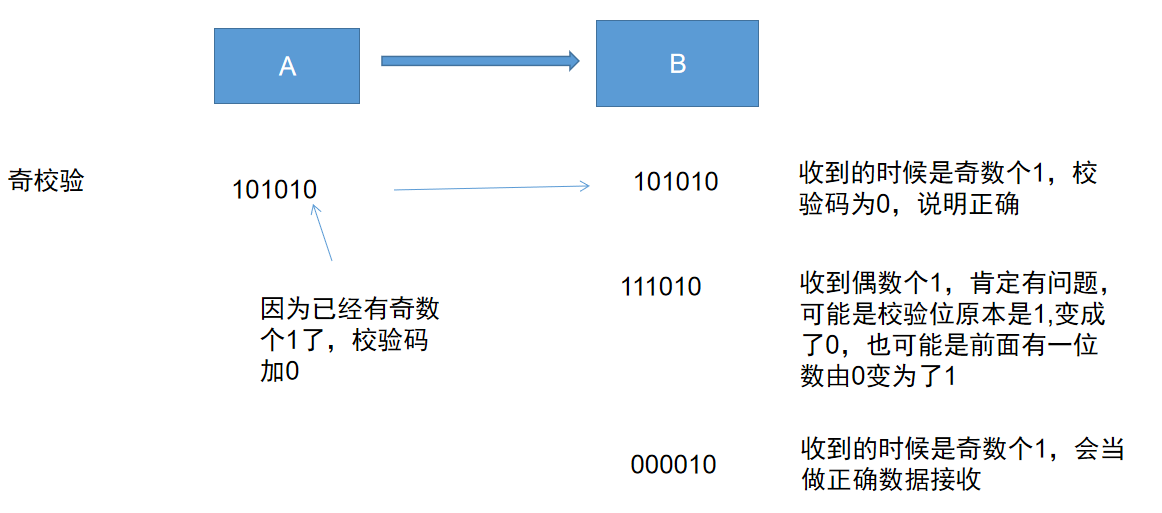
可以看出至少变码距位数时,才会让接收方误把错误数据当正确数据接收
循环冗余校验码CRC
步骤
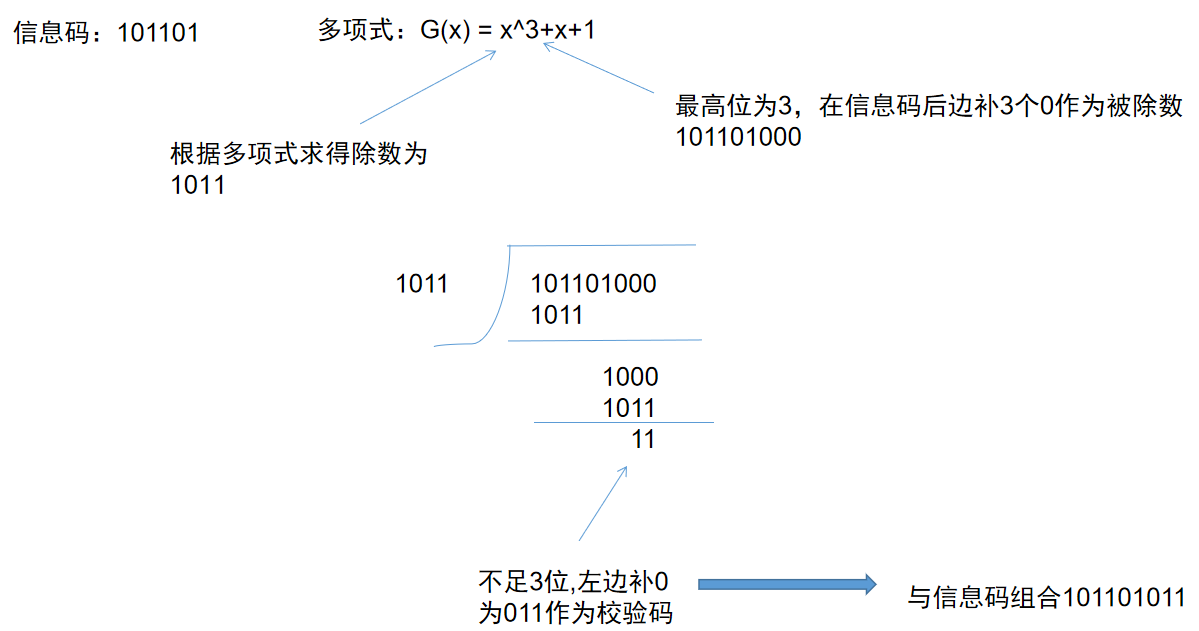
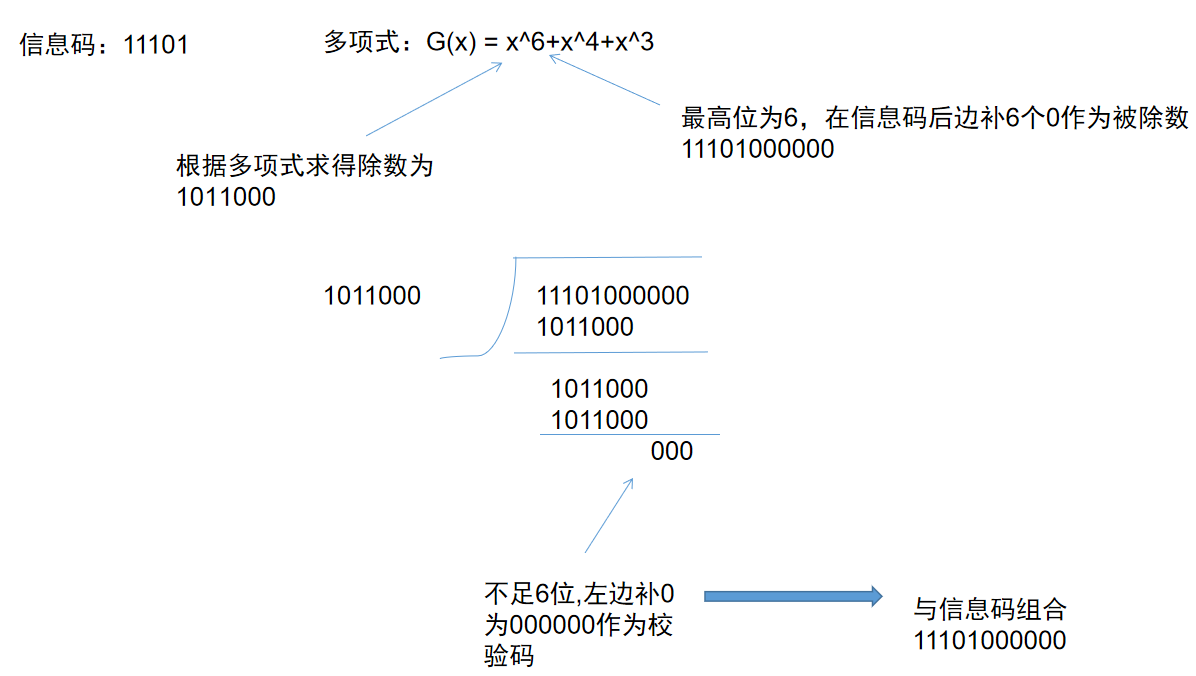
- 首先会给一个原始的数据,和一个多项式
- 多项式的最高次数是n,则在原始的信息数据后面加n个0,作为被除数
- 根据多项式来写出除数,有多少次方,则第几加一位为1,比如多项式为G(x) = x4+x2+1,则相当于1x4+0*x3+1x2+0*x1+1*x^0,将左边1或0取出来就是10101,作为除数
- 除的时候,每一位做异或运算,相同则为0,不同则为1,只取最后的余数,不要商
- 最后的余数的位数,如果不足多项式最高次数n,则在左边补0,最后得到的数为校验码
- 将校验码放到信息位后边发送出去,接收方接收到之后,也根据这个多项式得到的除数做除法,如果能除尽,则说明数据没有出错。
与奇偶校验码比较
- 校验的位数更多,奇偶校验码两位数变更就检不出来了,循环冗余校验码CRC可以校验多位
- 奇偶校验码和CRC都是只能检错,不能纠错
例子
- 信息码101101 多项式G(x)= x^3 + x + 1
- 信息码11101 多项式G(x)= x^6 + x^4 + x^3
海明码
步骤
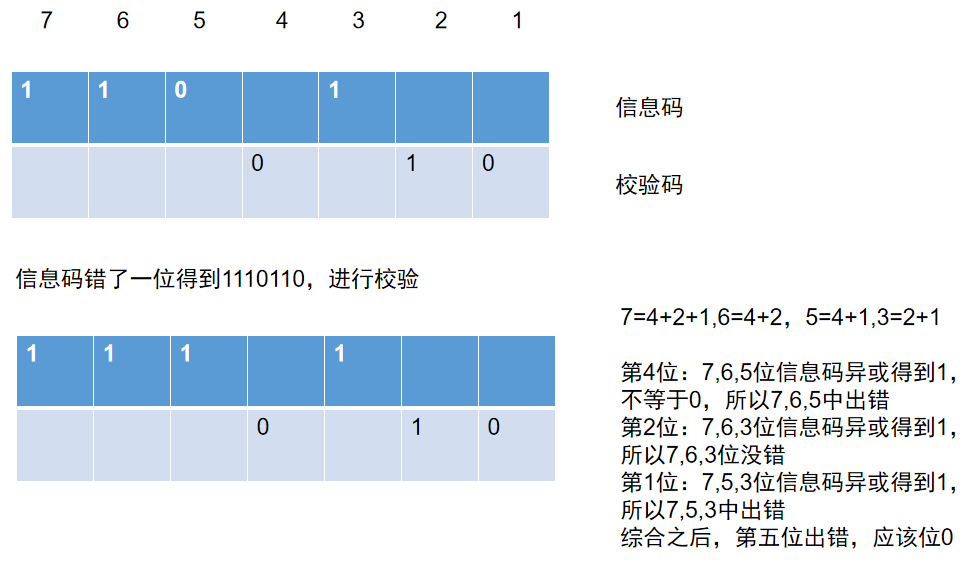
- 先确定在哪些位置插入校验码,校验码插入的位置是确定的,只不过个数不确定,会放在20,21,2^2……上,直到前面没有信息码不能再放校验码,组合成的数据,第一位必须是信息码
- 然后确定校验码各个位上是0还是1.
确认方法- 首先将信息码各位的位数使用2^n的形式相加
- 然后判断信息码各位的加数之中是否包含校验码所在的位数,将包含的信息码位数找出来
- 某位校验码的数字就由包含它位数的信息码的数字异或得来
例子
信息码1101

特点
与奇偶校验码和循环冗余校验码CRC不同的是,不但可以检错,还可以确定哪位信息码出错了,进行纠错
比如上面传过去之后错了一位
错的是信息码
错的是校验码

指令系统
CISC复杂指令系统
指令数量多,频率差别大,可变长格式,支持多种寻址方式
RISC精简指令系统
指令数量少,频率接近,定长格式,大多为单周期指令,操作寄存器,只有Load/Store操作内存,支持寻址方式少
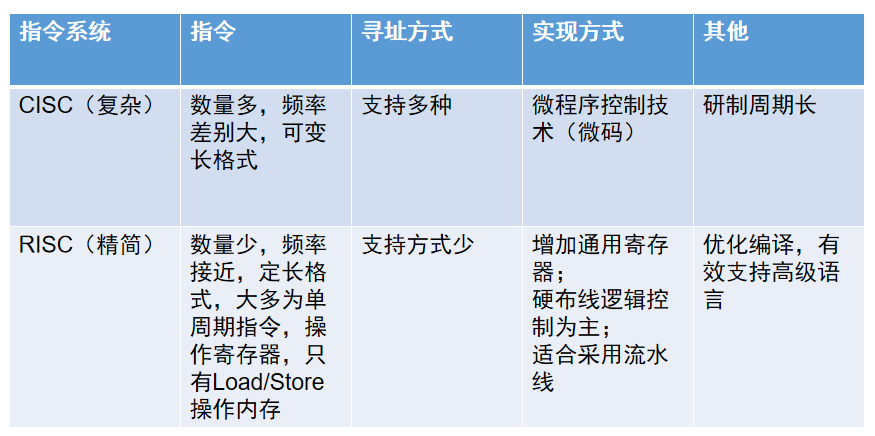
指令流水线
不使用指令流水线时,是一条指令的取指、分析、执行三个步骤全部执行完之后,再开始下一条指令的取指、分析、执行。可以看成每条指令的执行过程是串行的
使用指令流水线时,一条指令取指完就开始下一条指令的取指,同时开始该条指令的分析,可以看成是并行的
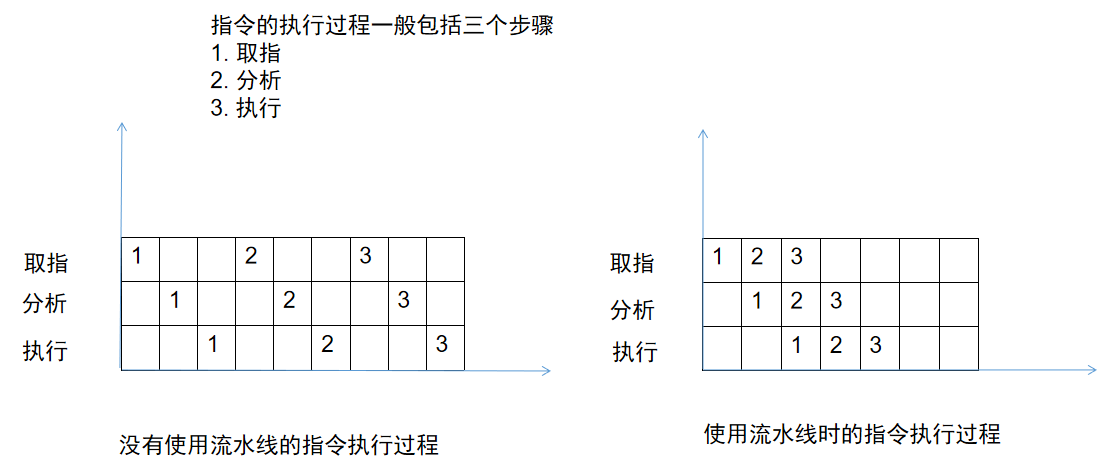
流水线周期
因为一条指令执行有三个步骤,每个步骤的时间不同,用时最长的步骤,所用的时间为一条指令的流水线周期
流水线执行时间
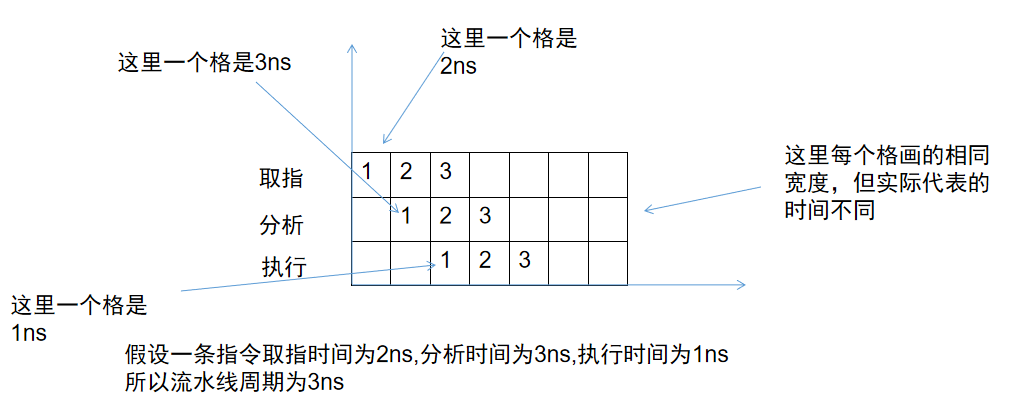
公式为:一条指令总执行时间 + (指令条数-1)*流水线周期
因为使用流水线时,第一条指令的执行时间就是总的三个步骤的执行时间,但从第二条指令开始,在第一条指令执行的过程中也在执行,增加的时间就只是一个流水线周期而已
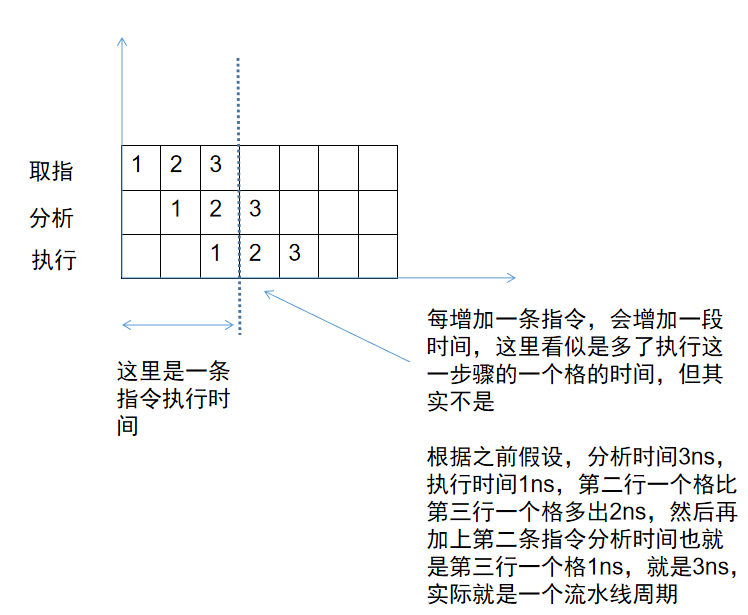
流水线吞吐率
单位时间内指令的执行条数
公式:指令条数/流水线执行时间
流水线加速比
使用流水线比不使用流水线的效率提升程度,越高越好
公式:不使用流水线执行时间/使用流水线执行时间
存储系统
存储系统是分级的,分级是为了保持容量,速度和成本之间的平衡。
分级情况如下
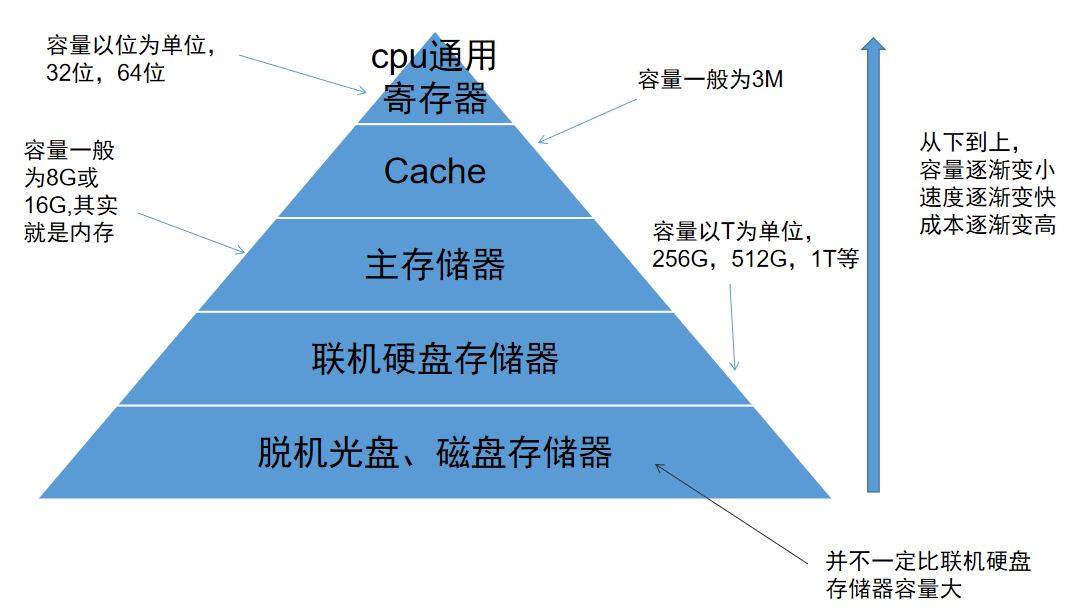
两级存储
Cache-主存
主存-辅存
局部性原理
局部性原理主要是为了处理Cache——主存之间的两级存储
cpu并不是直接访问Cache,而是访问主存。Cache中地址会对应到主存中的地址,主存中的地址也会对应到Cache
另一个问题是Cache存储容量小,只有3M,主存中哪些数据要存放到Cache中,需要有所取舍。按照取舍的规则,分为两种局部性原理
时间局部性原理
相邻时间内访问同一个数据项,则更有可能放在Cache中。即近期访问的频次越高,越应该放到Cache中
空间局部性原理
访问一个数据项,则其相邻空间的数据项更有可能放到Cache中
Cache高速缓冲区
cache中存储当前最活跃的数据(依据局部性原理),因为cpu和主存的速度相差太多,所以在中间添加一个过渡,cache对于我们来说是不可见的。由cpu直接访问cache,但是cpu中存储的是主存的地址,主存的地址有些按局部性原理映射到cache中
cache由控制器和存储器组成,存储器存储数据,控制器判断cpu访问的数据在不在cache中,即是否命中,如果命中,则取主存地址映射,如果不在则访问主存
地址映射
cpu中不直接存储cache中的地址,而是存储主存的地址,主存地址会映射到cache中地址。由硬件自动完成,对我们是不可见的。
映射方法分为:直接映射,全相连映射,组组相连映射
cache的命中率
其实就是访问的数据有多少存储在cache中
访问时间计算
考试中计算方法是
cache命中率*cache中访问时间+(1-cache命中率)*主存中访问时间
但其实上述计算方法有漏洞,因为cpu都会先访问cache,没有再访问主存,所以cache中访问时间应该乘于1,因为无论如何都会访问cache
忘掉这个漏洞,考试时就按上面的方法计算
磁盘
概念
磁盘是一个圆盘,就像光盘,分为内外两个盘面。在磁盘上有一个个的同心圆,叫做磁道,然后又将这个圆划分成一个个的扇形,这样每个磁道的每个扇形就叫做扇区,数据就存储在一个个扇区上。
读取数据的过程
有一个磁头,要读取数据的话,首先要确定数据存储在那个磁道,然后磁头移动到这个磁道,等待磁盘转动,在磁盘转动的过程中,当磁头划过数据所在的扇区时,就读取到了数据。
因此读取数据的过程分为两个
- 寻找磁道
- 等待磁盘转动过对应扇区
读取数据时间
寻道时间+等待时间(平均寻找磁道时间+磁盘转动过对应扇区的时间)
寻道时间是比较慢的,等待时间很快,因为磁盘每分钟几千转,速度很快
寻道的几种方式
-
先访问先服务
比如先要访问第7磁道的数据,后要访问第1磁道的数据,磁头要先到第7磁道,再到第1磁道 -
最短寻道时间优先
比如当前磁头在第5磁道,要访问第6磁道和第3磁道的数据,因为第5磁道和第6磁道离得更近,所以先访问第6磁道,再访问第3磁道 -
扫描算法
既能由里向外扫描,也能由外向里扫描,但某个方向上要扫描到要访问数据的最远磁道再掉头,就像电梯一样。假设磁盘共有20个磁道,要访问的数据分别在第3,4,7,10,13磁道上,此时磁头位于第8磁道,方向为从里到外,磁头会先按顺序移动到第13磁道,然后掉头再依次移动到第3磁道。并不会一直移动到最远的第20磁道才掉头 -
单向扫描调度算法
只能向一个方向扫描,扫描到头再掉头。比如上述例子,磁头会先从第8磁道移动到第20磁道,然后掉头移动到第1磁道
输入输出技术
计算机和外设之间数据传输的方式
程序控制方式
由cpu判断数据传输是否完成,如果没有传输完成,cpu就会一直等着。就像while循环一样,没有循环完就会一直等待。传输效率最差
程序中断方式
这种方式相较上一种方式效率有所提升。cpu和数据传输是并行的。在数据传输的时候,cpu也在处理其他事物。当数据传输完成时会向cpu发送中断请求,cpu接到请求后,就会先中断当前正在处理的服务,处理传输的数据,等处理完了之后再回去处理中断的程序。向鼠标键盘就是使用的程序中断方式
中断响应时间
从发送中断请求到cpu开始中断处理程序之间所需的时间
中断处理时间
从中断处理程序开始到中断处理程序接收所需的时间,这里指的是处理数据传输
中断向量
cpu需要通过中断向量找到要处理的服务程序的入口
DMA方式(直接主存存取)
这种方式cpu只进行必要的初始化操作,之后就不管理,直接由DMA控制器控制数据的传输,直接将数据传输到主存中,cpu什么时候想用直接在主存中取
总线
总线是设备与设备之间传输信息的通道,由所有设备共用,所以设备只要接入总线,就可以与其他设备之间传输信息
分类
内部总线
芯片级的总线
系统总线
板级的总线
数据总线
决定并行传输的通道数,如有8条数据总线,则可以有8条并行的数据传输通道
地址总线
决定内存的空间大小
32位系统,内存空间是2^32B,也就是4G
控制总线
用来传送控制命令
外部总线
用来接USB这种外部接口
另一种分类
单工总线
只能向一个方向传输数据的总线
半双工总线
可以向两个方向传输数据,但是不能同时传
双工总线
可以向两个方向传输数据,而且可以同时传,一般用两条总线来实现
另另一种分类
串行总线
只有一条总线,适用于传输距离长的情况,传输的速度慢
并行总线
有多条总线,并行传输数据,适用于传输距离短的情况,高速传输
可靠性
概念
平均无故障时间MTTF
平均故障修复时间MTTR
平均故障间隔时间MTTB=MTTF+MTTR
系统可用性MTTF/(MTTF+MTTR)*100%
串并联设备的可靠性
设每个设备的可靠性分别为R1,R2,R3……Rn
串联
总的系统的可靠性R=R1R2R3*……*Rn
因为总的系统可靠要求每个设备都可靠
并联
总的系统的可靠性R=1-(1-R1)(1-R2)……(1-Rn)
1减去所有设备都不可靠的情况,就是总的系统的可靠性,也就是说只要有一个设备可靠,则整个系统就可靠
最后
我将上述内容整理成了一个思维导图,正在等待上传审核,在后面的文章中可以下载。
大概内容如下
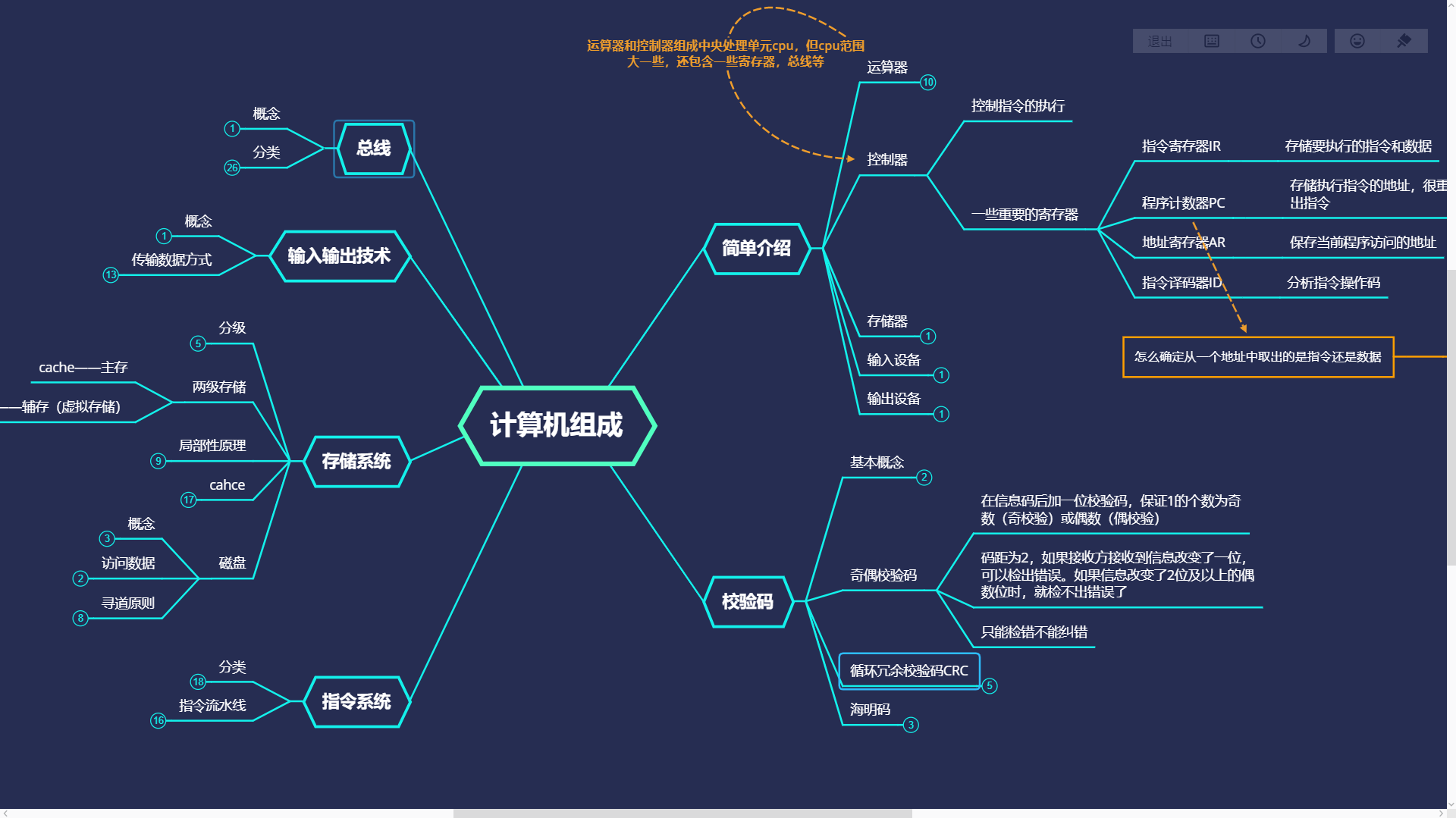
最后
以上就是大力橘子最近收集整理的关于计算机组成(超详细)+附带思维导图计算机的组成奇偶校验码循环冗余校验码CRC海明码指令系统指令流水线存储系统Cache高速缓冲区磁盘输入输出技术总线可靠性最后的全部内容,更多相关计算机组成(超详细)+附带思维导图计算机内容请搜索靠谱客的其他文章。





![[超详细!]计算机组成原理期末、考研复习思维导图](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)


发表评论 取消回复