LRU算法
1 原理
对于在内存中并且不被使用的数据块就是LRU,这类数据需要从内存中删除,以腾出空间来存储常用的数据。
LRU算法(Least Recently Used,最近最少使用),是内存管理的一种页面置换算法,就是用来删除内存中不被使用的数据,腾出空间来把常用的数据存进去。
LRU算法的实现原理:把所有的缓存数据存入链表中,新插入的或被访问的数据存入链表头,如果链表满了,就把尾部的数据清除。如下图所示:
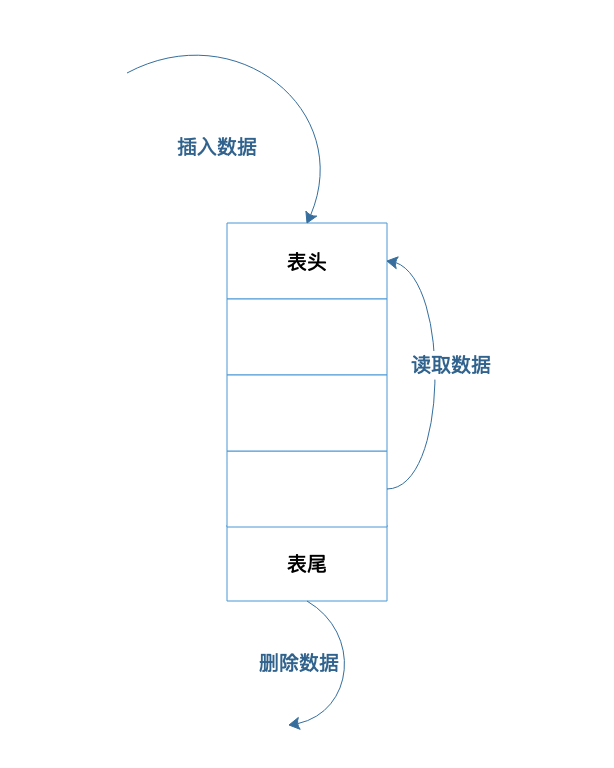
比如长度是5,缓存中的数据是:1,2,3,4,5
访问了2,那么缓存中的数据顺序变为:2,1,3,4,5
新插入了6,会变为:6,2,1,3,4
2 Java编码实现
2.1 基于linkedhashmap实现
linkedhashmap的底层实现是链表,使用linkedhashmap实现LRU算法的关键在于设置链表的长度,代码如下所示:
import java.util.LinkedHashMap;
import java.util.Map;
/**
* @ClassName LRU
* @Description 基于LinkedHashMap的LRU算法
* @Author boy
* @Date 2019/6/13 10:27 AM
*/
public class LRULinkedHashMap extends LinkedHashMap{
//缓存长度
int length;
public LRULinkedHashMap(int length){
super(length,0.75f,true);
this.length = length;
}
/*
* @Author boy
* @Description LRU算法的关键方法,超过最大长度就移除尾部元素
* @Date 2019/6/13 12:24 PM
* @Param [map]
* @return boolean
*/
@Override
public boolean removeEldestEntry(Map.Entry map){
return size()>length;
}
}
2.2 链表实现
可以自己维护一个链表,来实现LRU算法,但是这种方式的弊端是查询、插入的效率比较慢,代码实现如下所示:
/**
* @ClassName LRU
* @Description
* @Author boy
* @Date 2019/6/20 8:19 PM
*/
public class LRU{
//链表的头结点
Node head;
//链表的尾结点
Node tail;
//长度
int length;
public LRU(int length){
this.length = length;
}
public void addNode(String value){
Node node = new Node();
node.value = value;
if (null == head){
head = node;
tail = node;
return;
}
if (length<=size()){
delTailNode();
}
head.prev = node;
node.next = head;
head = node;
}
public Node getNode(String value){
Node node = head;
while (node!=null){
if (value.equals(node.value)){
Node preNode = node.prev;
preNode.next = node.next;
node.next.prev = preNode;
node.next = head;
head.prev = node;
head = node;
break;
}else {
node = node.next;
}
}
return node;
}
public void delTailNode(){
tail = tail.prev;
tail.next = null;
}
public void delNode(String value){
Node node = head;
while (node!=null){
if (value.equals(node.value)){
Node comNode = node.prev;
comNode.next = node.next;
node.next.prev = comNode;
break;
}else {
node = node.next;
}
}
}
public int size(){
int length = 0;
Node node = head;
while (node!=null){
length++;
node = node.next;
}
return length;
}
}
class Node{
//节点值
String value;
//指向上一个节点的引用
Node prev;
//指向下一个节点的引用
Node next;
}2.3 链表+HashTable实现
解决自己维护链表,插入、查询慢的问题,可以使用链表+HashTable来实现LRU算法,代码如下所示:
import java.util.Hashtable;
/**
* @ClassName LRUCache
* @Description 链表+HashTable实现LRU算法
* @Author boy
* @Date 2019/6/21 8:50 PM
*/
public class LRUCache {
private int cacheSize;
private Hashtable nodes;//缓存容器
private int currentSize;
private CacheNode first;//链表头
private CacheNode last;//链表尾
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable(i);//缓存容器
}
/**
* 获取缓存中对象
* @param key
* @return
*/
public Object get(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
moveToHead(node);
return node.value;
} else {
return null;
}
}
/**
* 添加缓存
* @param key
* @param value
*/
public void put(Object key, Object value) {
CacheNode node = (CacheNode) nodes.get(key);
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
if (last != null)//将最少使用的删除
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new CacheNode();
}
node.value = value;
node.key = key;
//将最新使用的节点放到链表头,表示最新使用的.
moveToHead(node);
nodes.put(key, node);
}
/**
* 将缓存删除
* @param key
* @return
*/
public Object remove(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
return node;
}
public void clear() {
first = null;
last = null;
}
/**
* 删除链表尾部节点
* 表示 删除最少使用的缓存对象
*/
private void removeLast() {
//链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* 移动到链表头,表示这个节点是最新使用过的
* @param node
*/
private void moveToHead(CacheNode node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
}
/**
* 链表节点
* @author Administrator
*
*/
class CacheNode {
CacheNode prev;//前一节点
CacheNode next;//后一节点
Object value;//值
Object key;//键
CacheNode() {
}
}LRU算法的演变
LRU-K算法
LRU算法的弊端是会产生“缓存污染”,比如周期性访问的数据。为了解决这个问题,我们引入LRU-K算法。举个例子,需要查询的数据特别频繁,我们从redis或者数据库中拉取数据比较慢可以放在jvm缓存中,如下图所示:
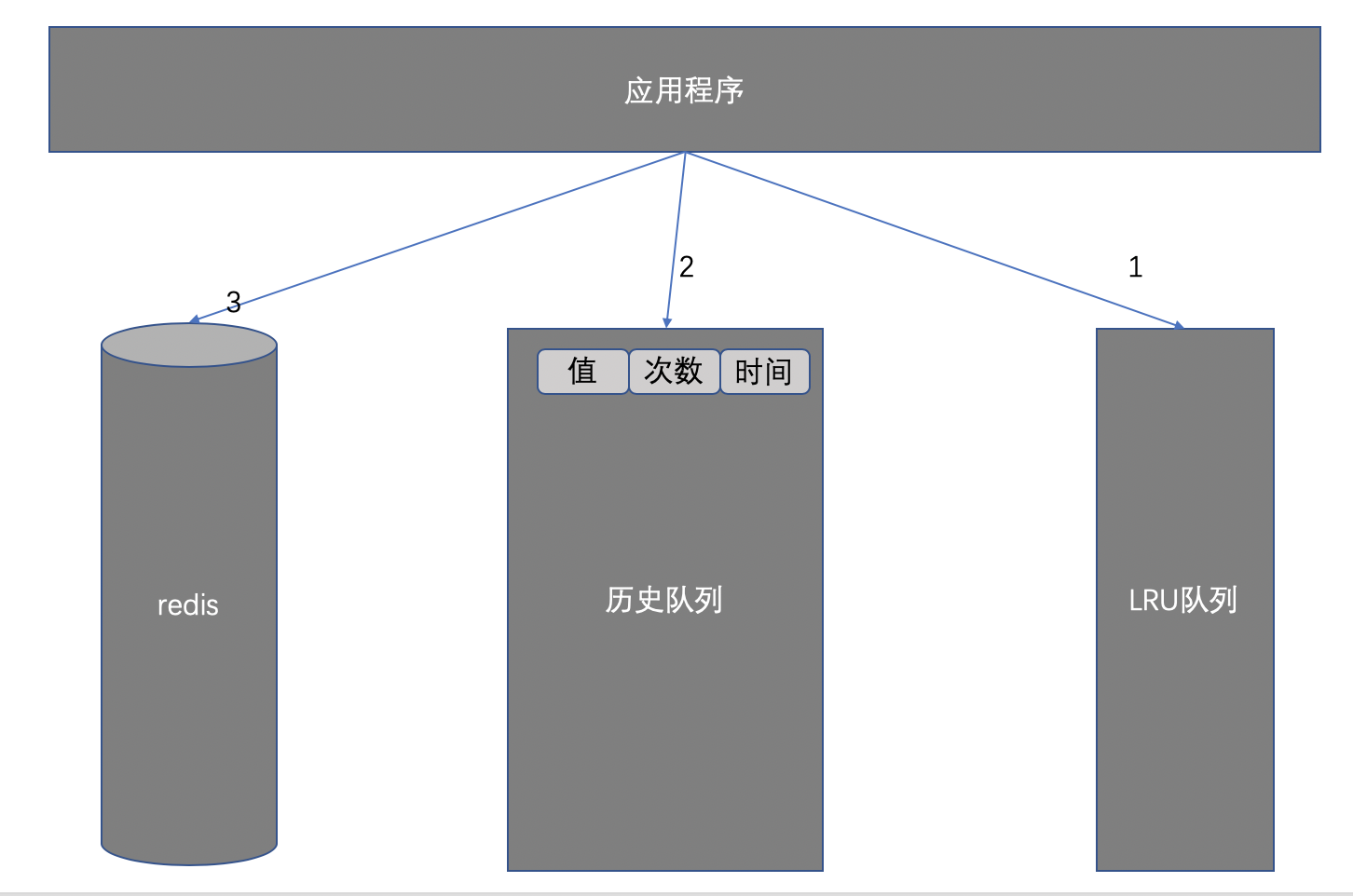
满足条件的数据放在LRU队列中,应用程序第一次拉取数据从LRU队列中来拿,如果没有再从历史队列中拿,如果还拿不到就从redis中拿,并把拿到的数据放入历史队列中,历史队列的数据满足一定条件就放入LRU队列中
最后
以上就是无限人生最近收集整理的关于缓存置换算法 - LRU算法LRU算法LRU算法的演变的全部内容,更多相关缓存置换算法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复