Kubernetes简介
在Docker作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年,Borg系统运行管理着成千上万的容器应用;Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训;Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户
Kubernetes的好处:隐藏资源管理和错误处理,用户仅需要关注应用的开发;服务高可用、高可靠;可将负载运行在由成千上万的机器联合而成的集群中
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etcd),一切都基于分布式的存储系统
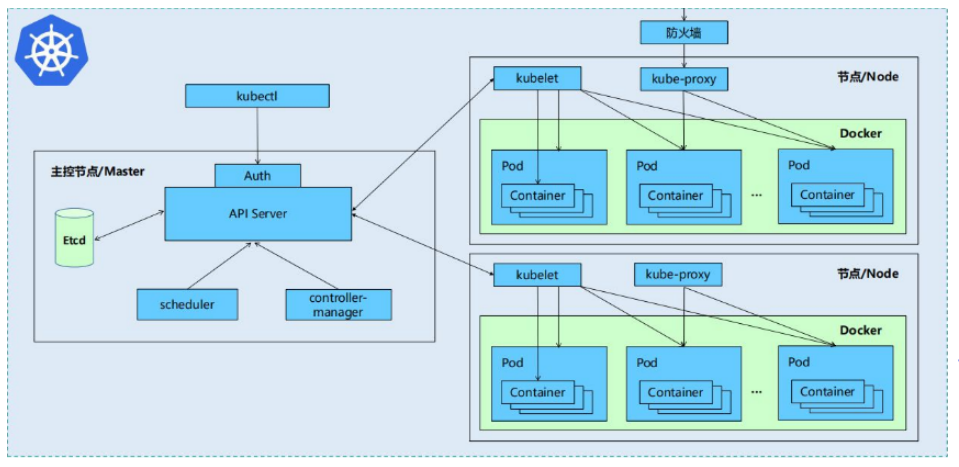
Kubernetes主要由以下几个核心组件构成:
etcd:保存了整个集群的状态
apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的集群节点上
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
除了以上核心组件,还有一些推荐的Add-ons:
kube-dns:负责为整个集群提供DNS服务
Ingress Controller:为服务提供外网入口
Heapster:提供资源监控
Dashboard:提供GUI
Federation:提供跨可用区的集群
Fluentd-elasticsearch:提供集群日志采集、存储与查询
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构
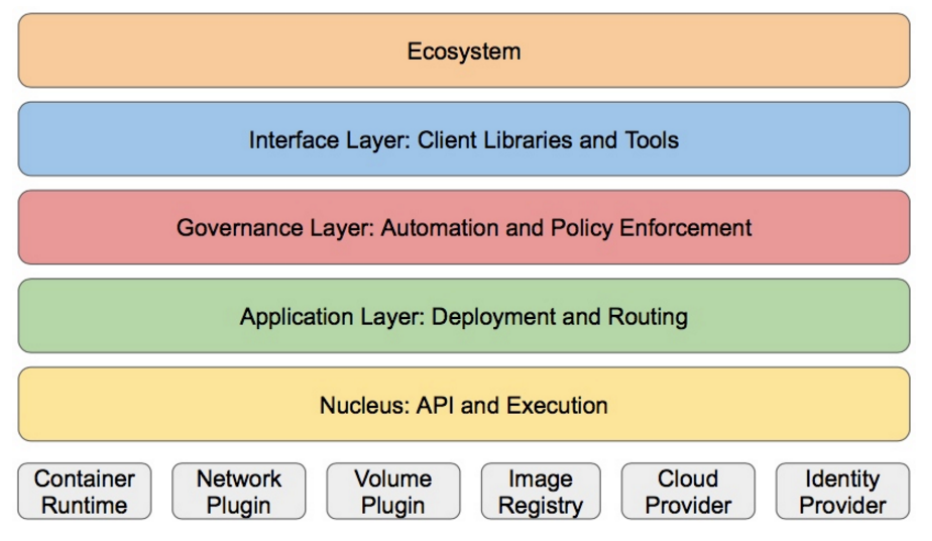
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
接口层:kubectl命令行工具、客户端SDK以及集群联邦
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为以下两个范畴
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等 Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
Kubernetes集群搭建
环境:
server131主机配置docker的私有仓库 IP=172.25.100.131
server132主机作为集群的master端 IP=172.25.100.132
server133主机作为集群节点 IP=172.25.100.133
server134主机作为集群节点 IP=172.25.100.134
部署:
关闭所有主机的selinux和iptables防火墙
所有集群主机部署docker引擎:yum install -y docker-ce
所有集群主机禁用swap分区:swapoff -a && 注释掉/etc/fstab文件中的swap定义



配置集群所有节点的私有仓库指向并重启docker使之生效
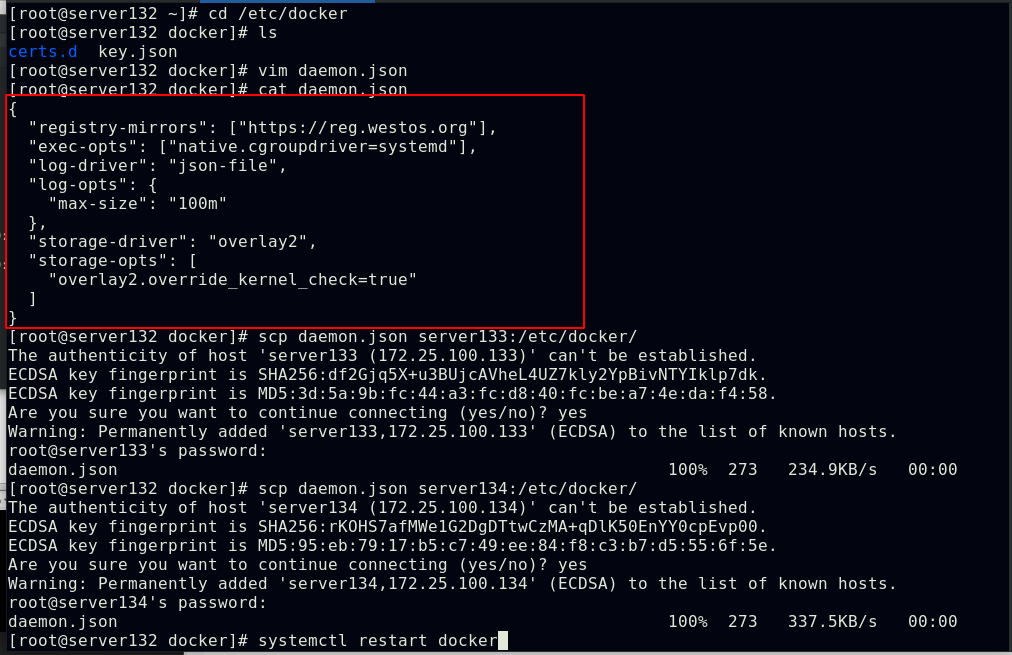
复制证书文件至节点的docker配置目录下,重启节点的docker服务
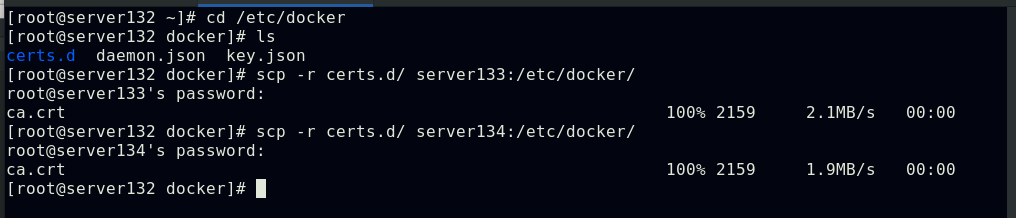
集群所有节点登陆私有镜像仓库,以便后续实验需要



所有节点安装部署软件kubeadm、kubectl、kubelet

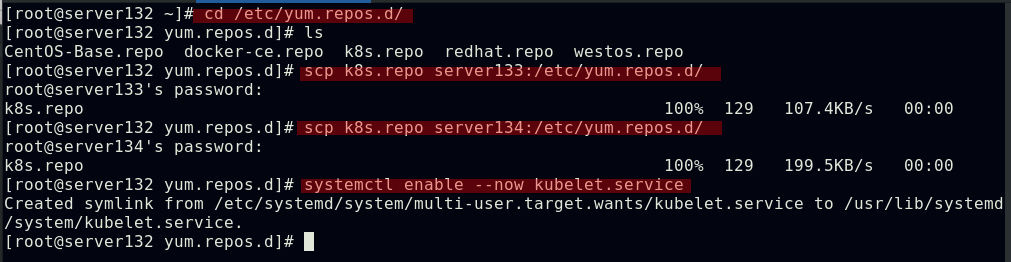
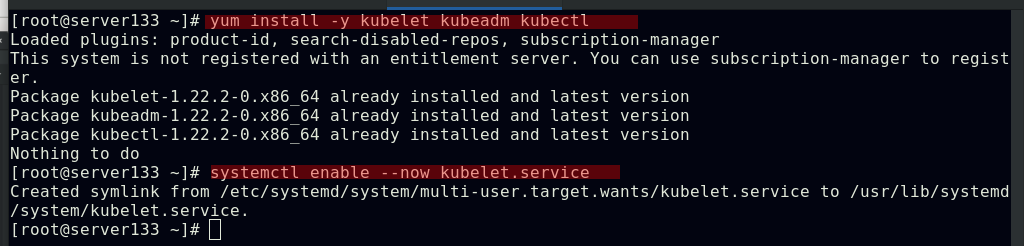
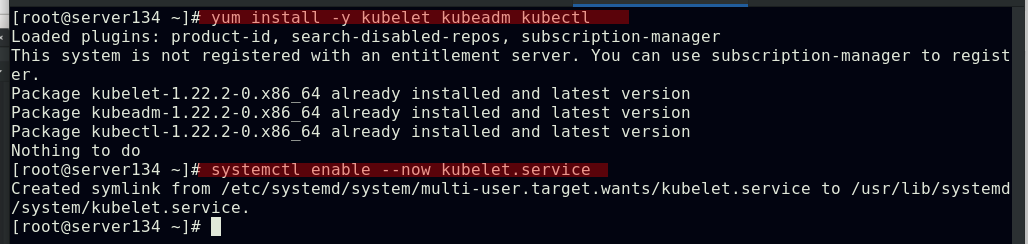
##kubelet运行在集群所有节点上,负责启动POD和容器;kubeadm是一个能快速部署kubernetes集群的工具,用于初始化集群;kubectl是kubenetes命令行工具,通过kubectl可以部署和管理应用,查看各种资源,创建,删除和更新组件
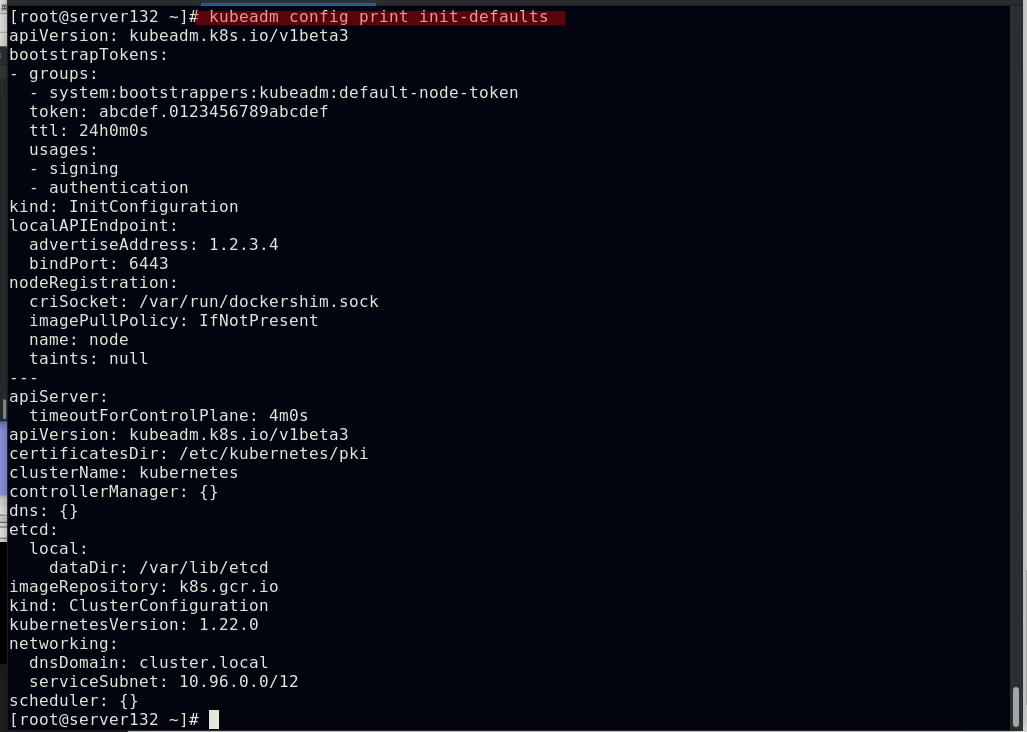
##查看默认kubernetes集群配置信息
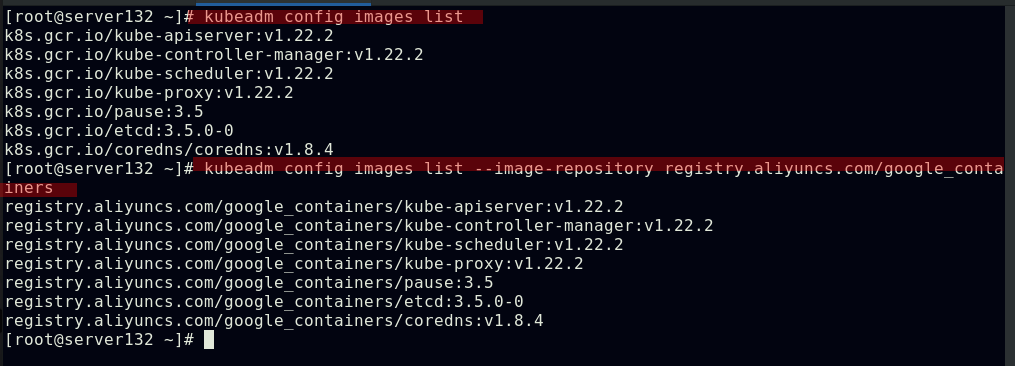
##列出配置kubernetes集群所需镜像,默认从k8s.gcr.io上下载组件镜像,此镜像源在外网,需要翻墙,但可以通过修改镜像源为国内aliyun的镜像源
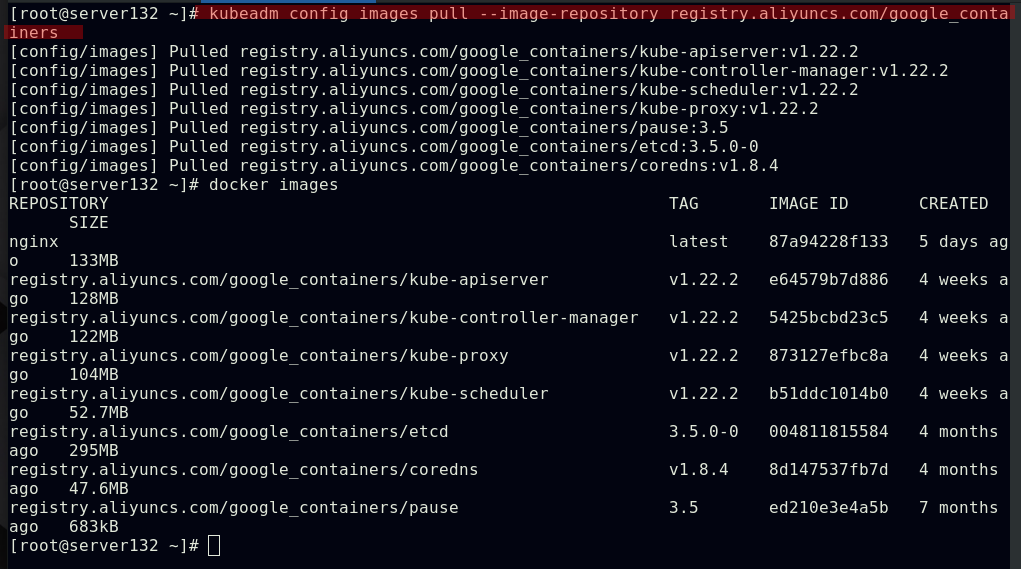
##从国内aliyun镜像源拉取集群所需镜像

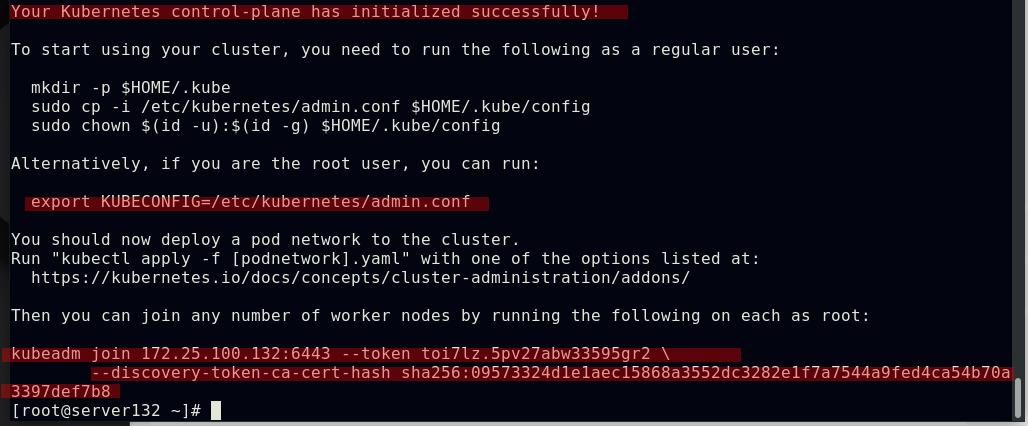
##在集群master端初始化集群

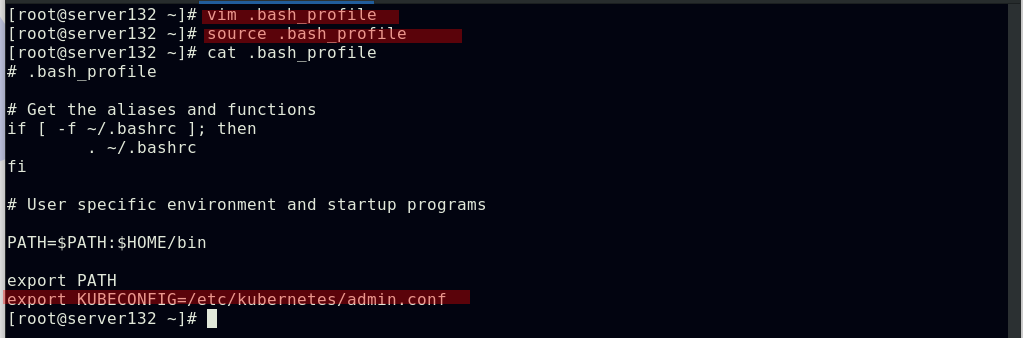
##指定kube配置文件启动集群,此条命令出现在初始化集群时的输出中;也可在文件中配置此环境变量,以免重启主机时每次手动声明
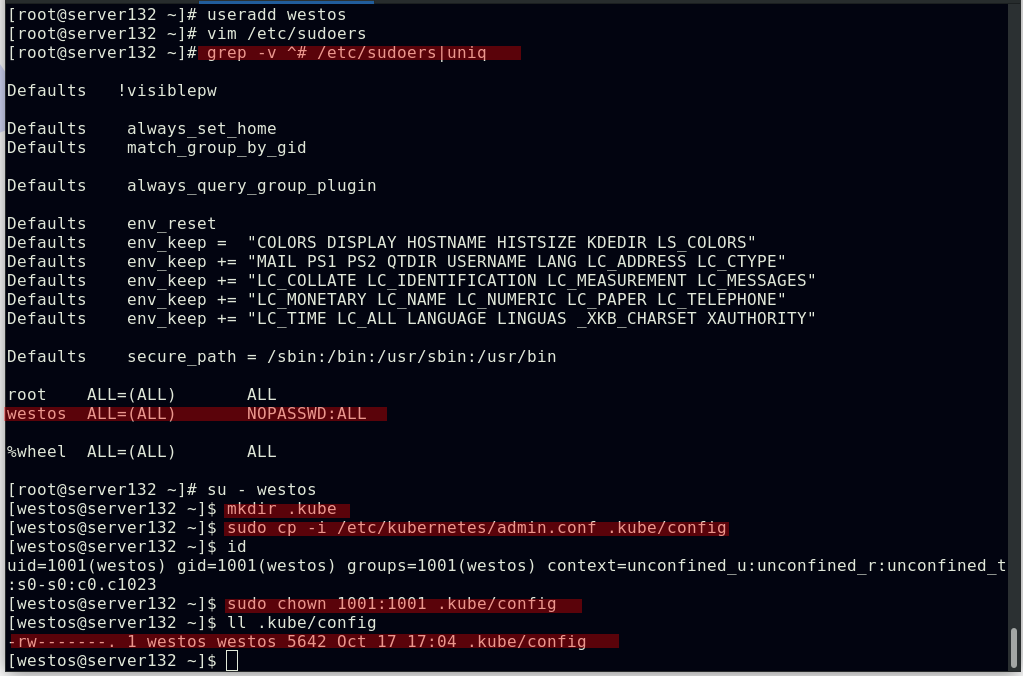
##对于普通用户可通过以上方式进行配置文件的声明

##配置kubectl命令补齐功能



##集群节点扩容,此时所有节点均未就绪;此条命令也出现在初始化集群的输出中

##下载flannel网络组件的资源文件,更改其中的镜像指向;此文件也在外网:https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
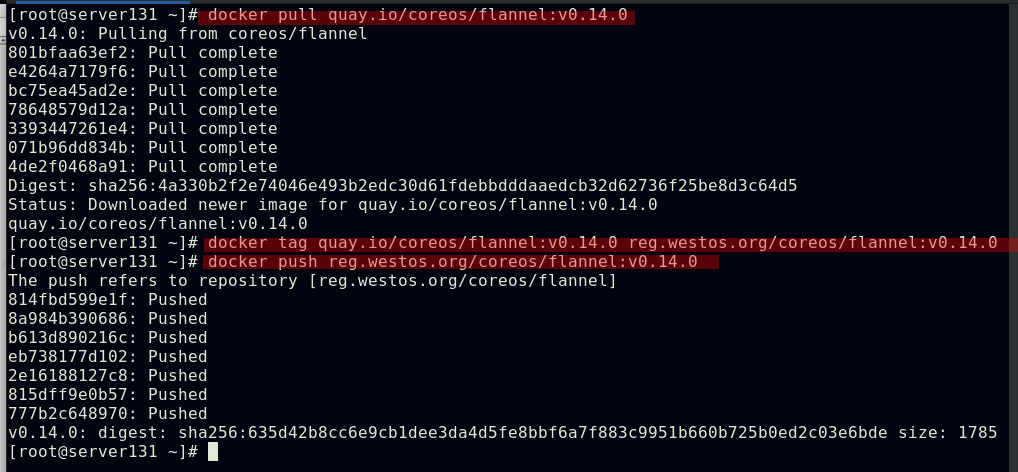
##在镜像仓库主机拉取flannel组件需要的镜像并上传至仓库(需在浏览器页面中新建项目)
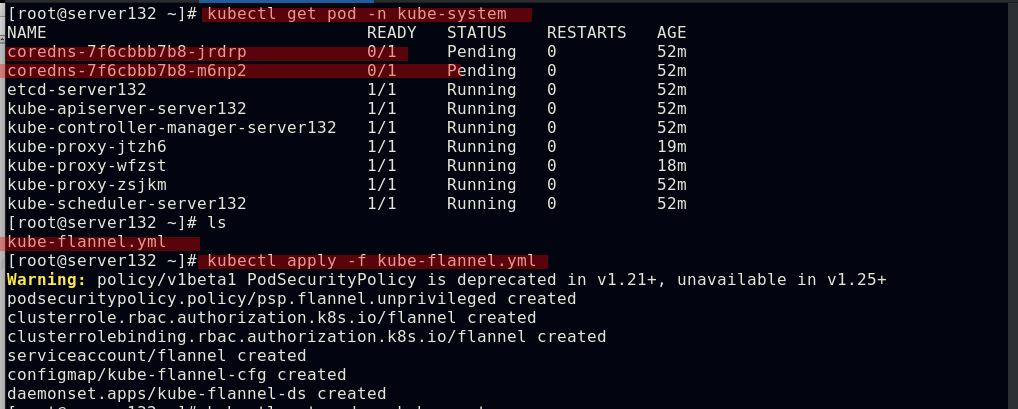
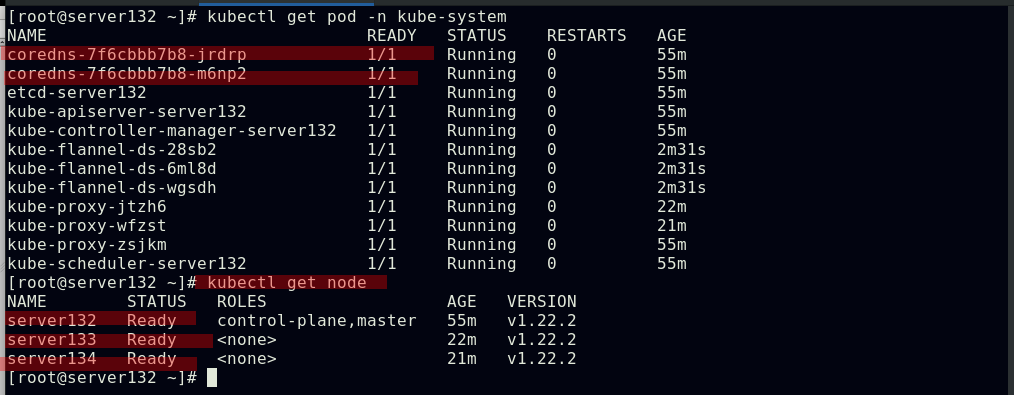
##在集群master端应用flannel网络组件的资源文件,此时集群中的所有节点均为就绪状态,集群的核心dns服务也正常启动
至此我们的一主两节点的kubernetes集群就搭建完成了
Pod管理
kubectl命令指南:
Kubectl Reference Docs https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commandsPod是可以创建和管理Kubernetes计算的最小可部署单元,一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commandsPod是可以创建和管理Kubernetes计算的最小可部署单元,一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip

一个pod类似一个豌豆荚(如上图),包含一个或多个容器(通常是docker容器),多个容器间共享IPC、Network和UTC namespace

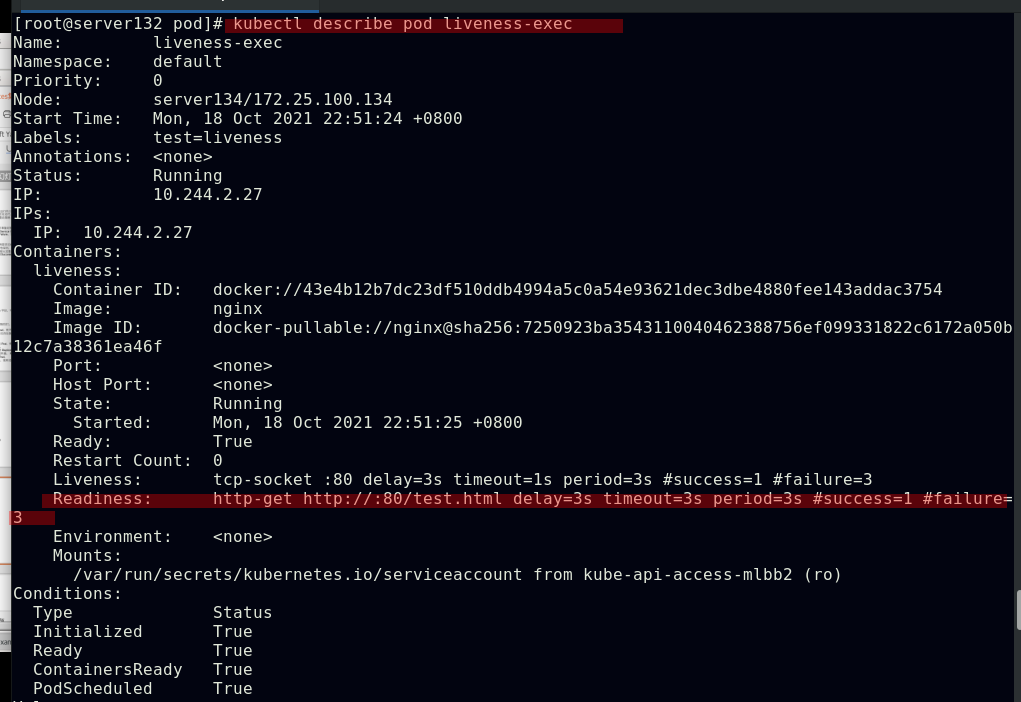
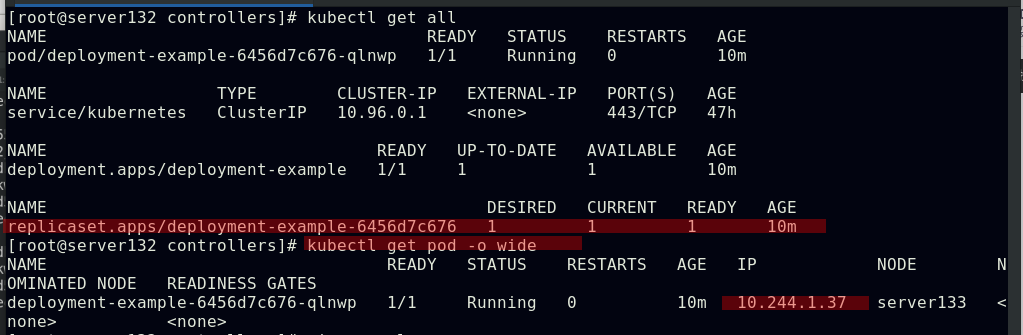
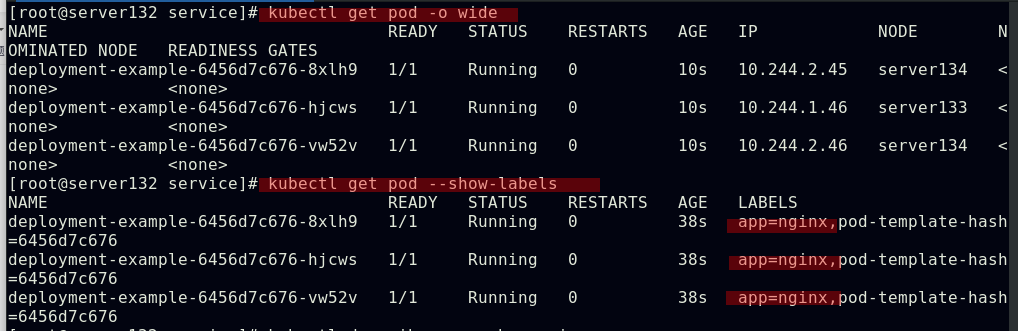
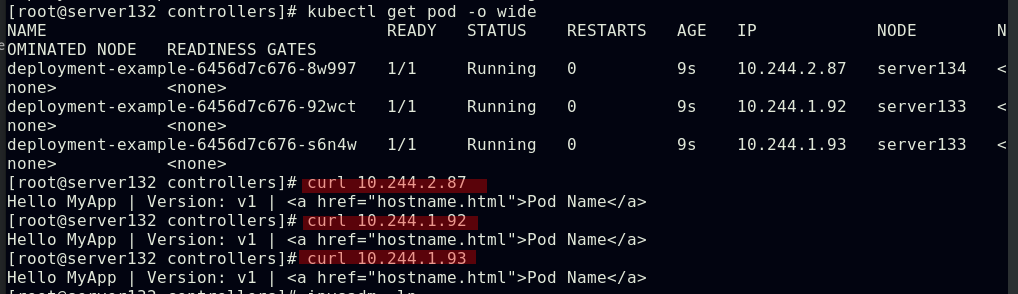
##创建pod,查看其被分配至哪个集群节点,也可使用kubectl describe pod nginx查看此pod的详细信息

##由上图知道此pod指派给了server134主机,即在此主机上拉取了nginx镜像(确保自己搭建的仓库中有镜像)
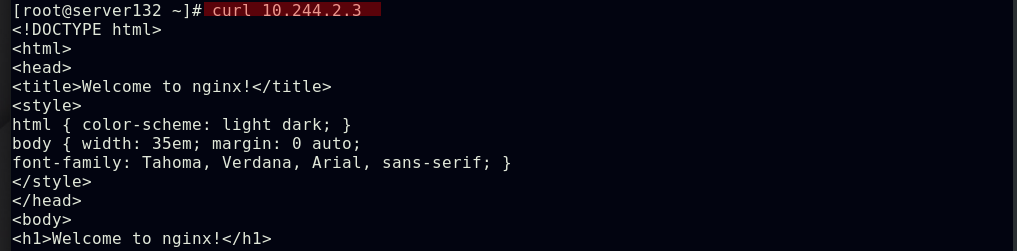
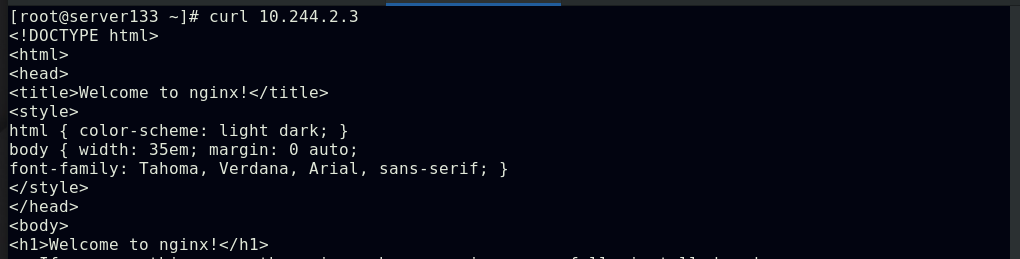
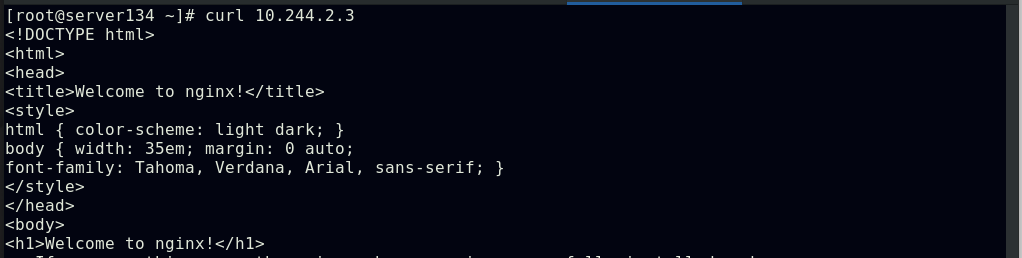

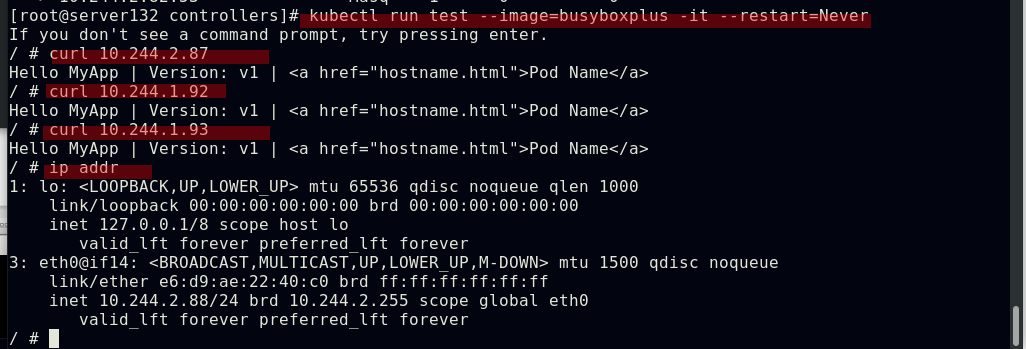
##集群内部任意节点可以访问Pod,但集群外部无法直接访问(server131主机为仓库主机,不属于集群)
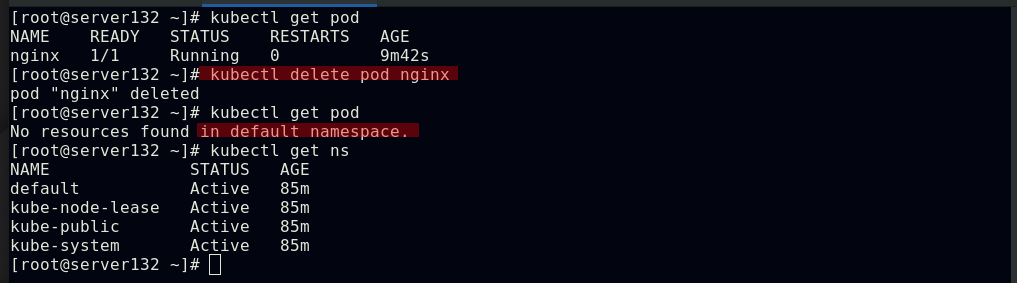
##删除pod,查看所有namespace


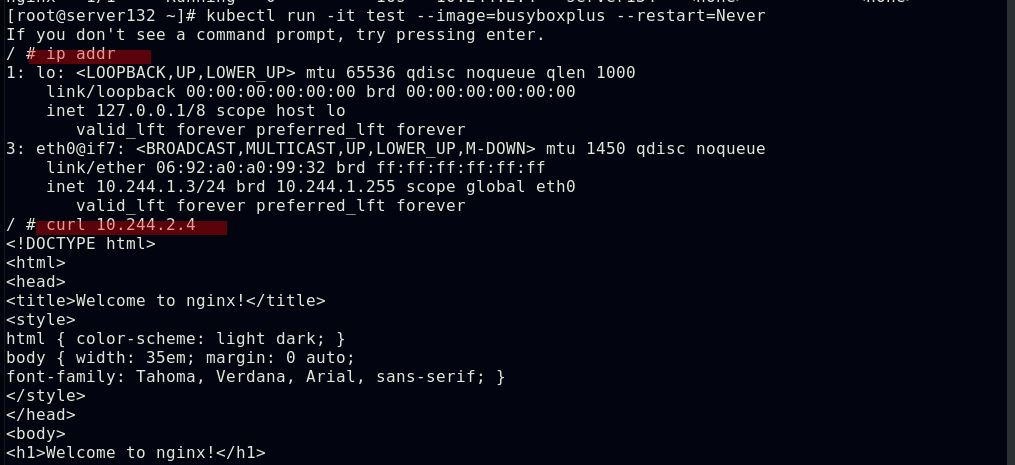

##同一namespace下的不同pod可以直接访问,--restart=Never表示pod退出后不让其此自动重启,默认的pod重启策略为always
初识控制器:
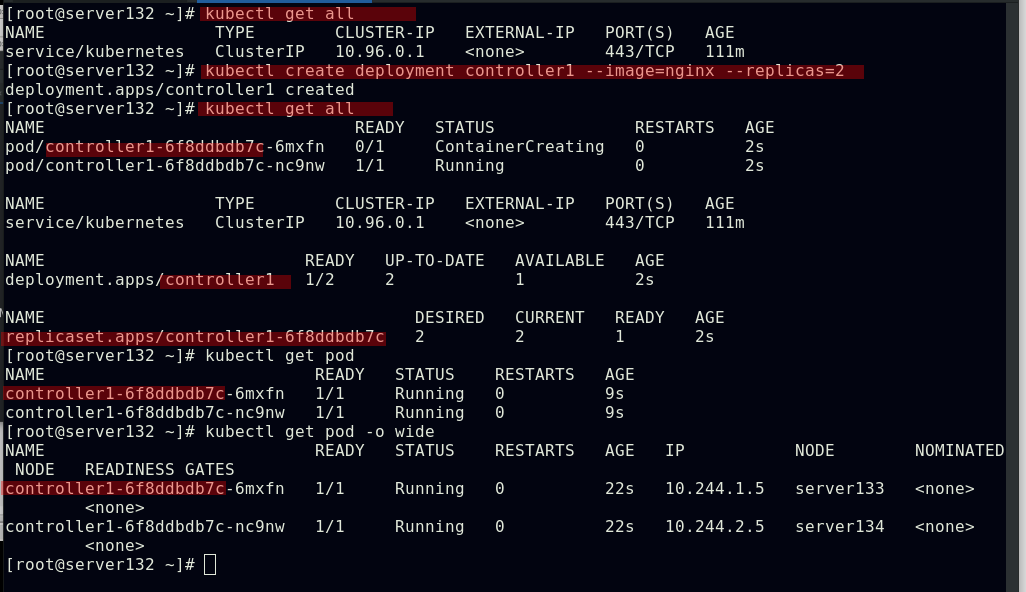
##创建副本数始终为2的控制器controller1,会生成两个pod;controller1-6f8ddbdb7c-nc9nw分别可以理解为:控制器名称,控制器的标识,pod副本的标识
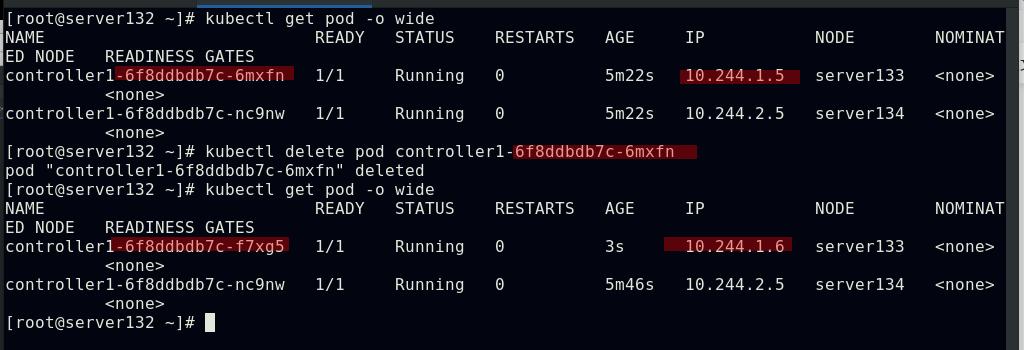
##删除控制器下的pod副本,控制器会自动启动一个新的pod顶上来,并且会重新获取新的IP,因为之前设置其的副本数始终为2
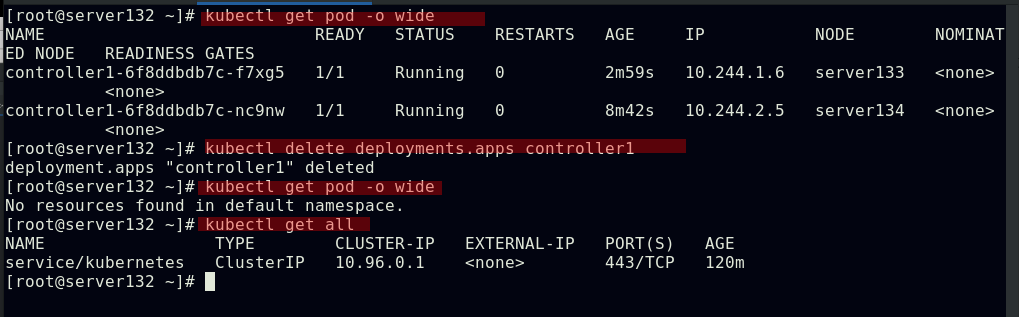
##删除控制器,其下pod被彻底删除
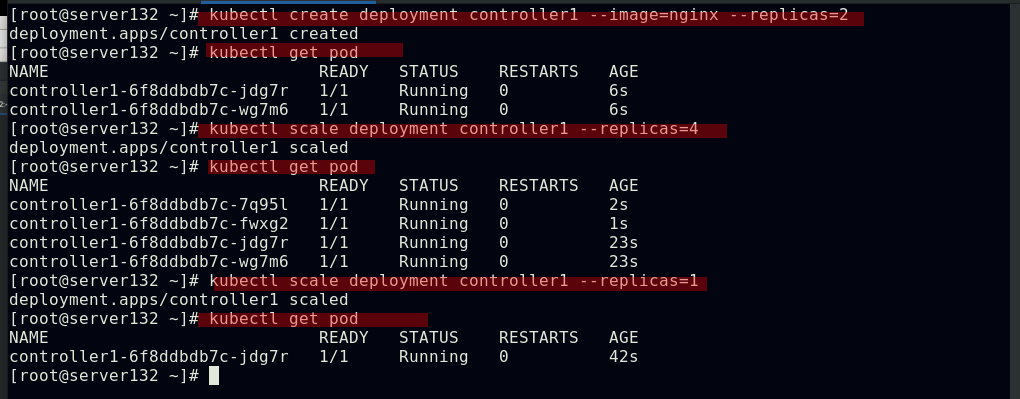
##pod的扩容与缩容
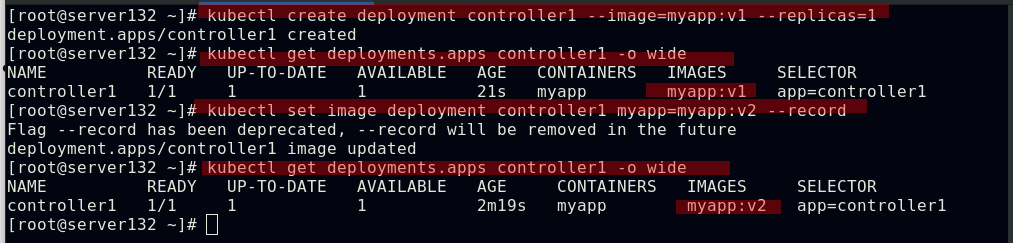
##更新pod镜像
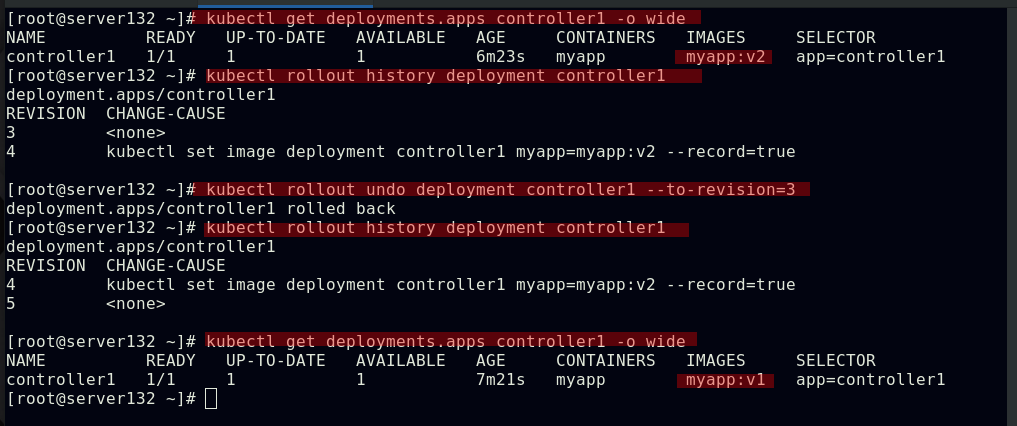
##查看pod镜像的历史版本(基于--record参数才可看到历史版本),回滚镜像版本
初识service:
service是一个抽象概念,定义了一个服务的多个pod逻辑合集和访问pod的策略,一般把service称为微服务
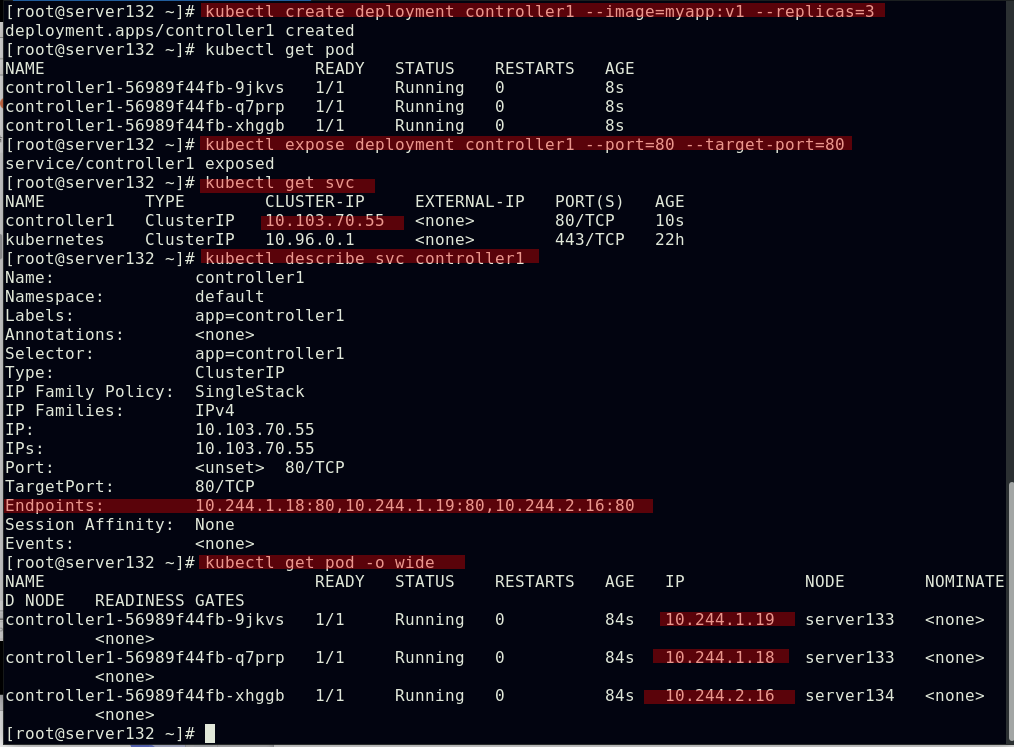
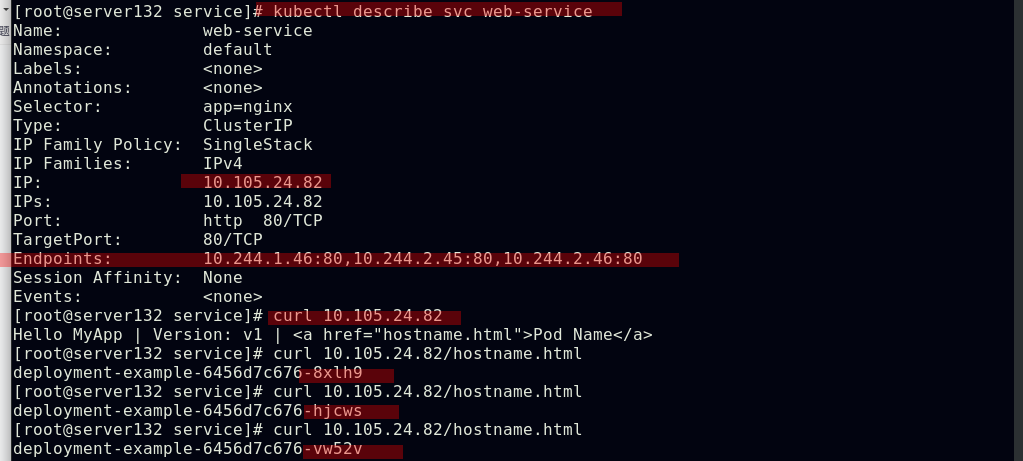
##创建service,此时pod客户端可以通过service的名称访问后端的三个Pod;ClusterIP: 默认的service类型,会自动分配到一个仅集群内部可以访问的虚拟IP
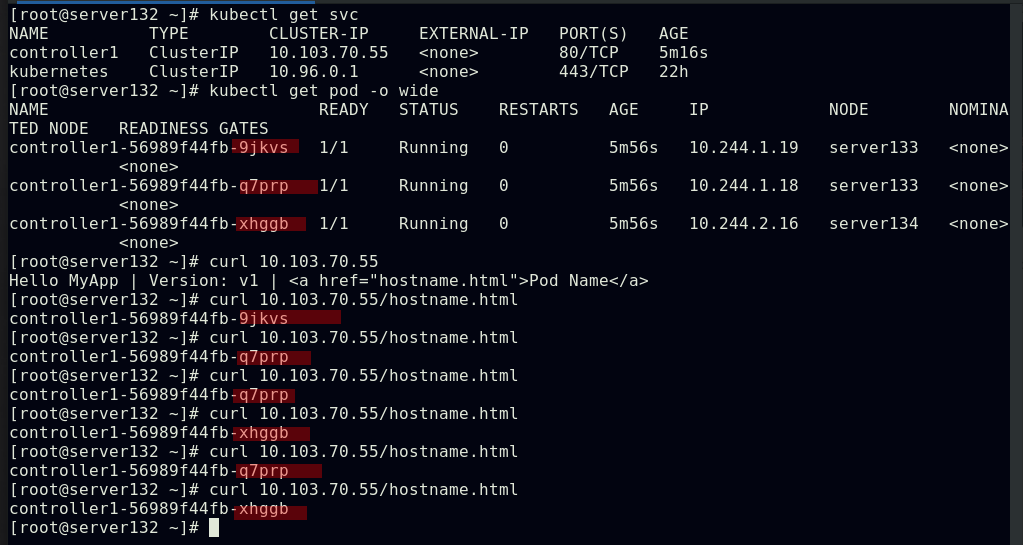
##通过此虚拟IP访问时可以实现负载均衡效果
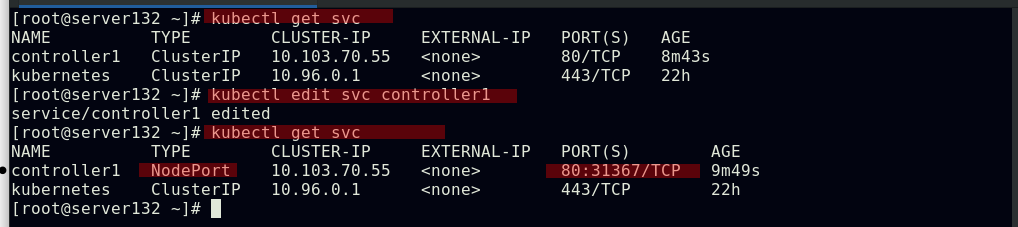
##将服务类型更改为NodePort形式,此时集群外部即可访问pod;也可通过参数--type=NodePort在创建service时指定类型



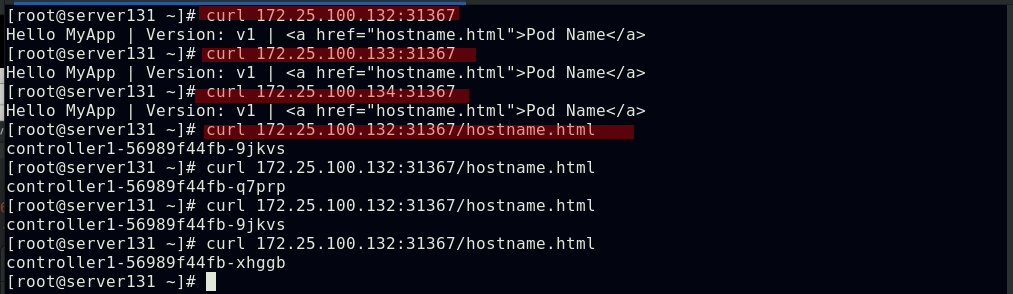
##NodePort类型是在在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过NodeIP:NodePort来访问该服务
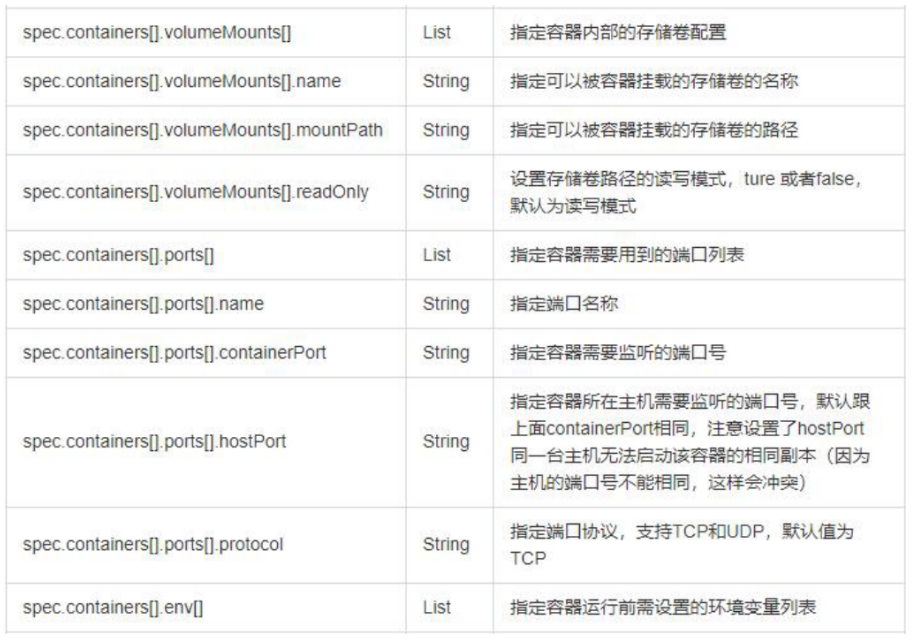
资源清单
在kubernetes中,一般使用yaml格式的文件来创建符合我们预期的pod,这样的yaml文件一般称为资源清单;什么叫资源?kubernetes中所有的内容都抽象为资源,资源实例化之后叫做对象
在kubernetes中有哪些资源?
工作负载型资源(workload):Pod、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job、CronJob(ReplicationController在v1.11版本被废弃)
服务发现及负载均衡型资源(ServiceDiscovery LoadBalance):Service、Ingress、...
配置与存储型资源:Volume(存储卷)、CSI(容器存储接口,可以扩展各种各样的第三方存储卷)
特殊类型的存储卷:ConfigMap(当配置中心来使用的资源类型)、Secret(保存敏感数据)、DownwardAPI(把外部环境中的信息输出给容器)
以上这些资源都是配置在命名空间级别
集群级资源:Namespace、Node、Role、ClusterRole、RoleBinding(角色绑定)、ClusterRoleBinding(集群角色绑定)
元数据型资源:HPA(Pod水平扩展)、PodTemplate(Pod模板,用于让控制器创建Pod时使用的模板)、LimitRange(用来定义硬件资源限制的)
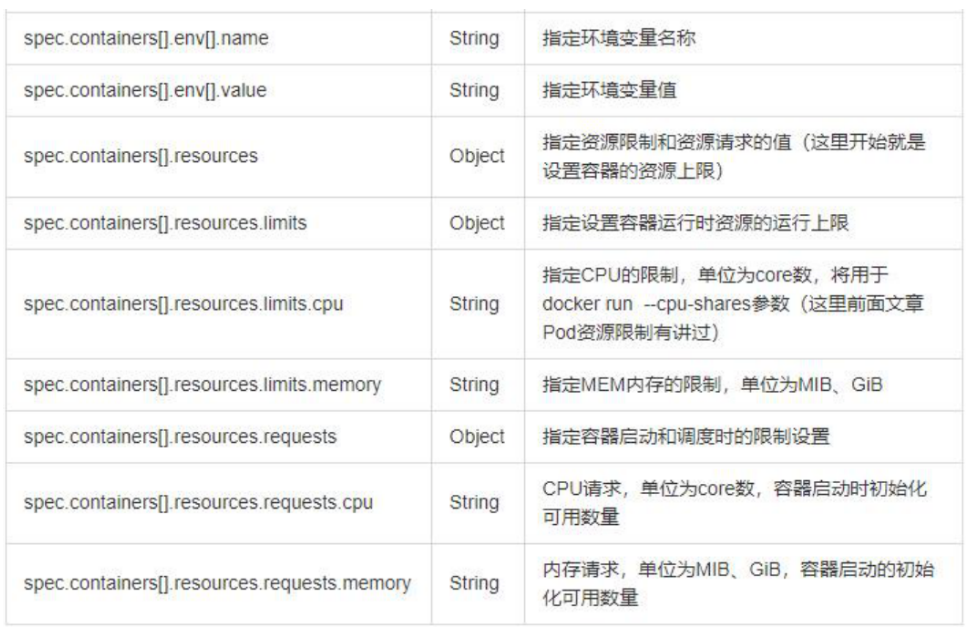
资源清单的格式:
apiserver:group/version
##指明api资源属于哪个群组和版本,同一个组可以有多个版本,如果没有给定group名称,那么默认为core;可以使用kubectl api-versions 获取当前k8s版本上所有的apiVersion版本信息(每个版本可能不同)
kind:标记创建的资源类型,k8s主要支持以下资源类别:Pod、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job、Cronjob
metadata:元数据
name:实例化的对象名称
namespace:对象所属的命名空间
labels:指定资源标签,标签是一种键值数据
annotation:资源注解,主要目的是方便用户阅读查找
spec:定义目标资源的期望状态(disired state),期望资源应该用于什么特性
status:当前状态(current state),本字段由kubernetes集群维护,用户不能自己定义
创建资源的方法:
apiserver仅接受JSON格式的资源定义;yaml格式文件提供配置清单,apiserver可自动将其转为JSON格式,而后再提交
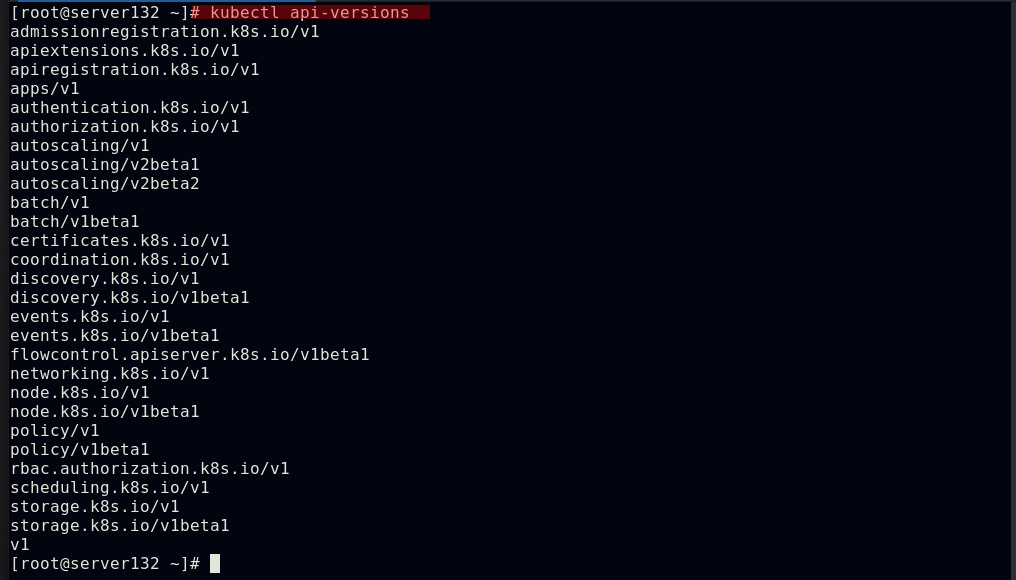
##查看当前版本上所有的apiVersion版本信息
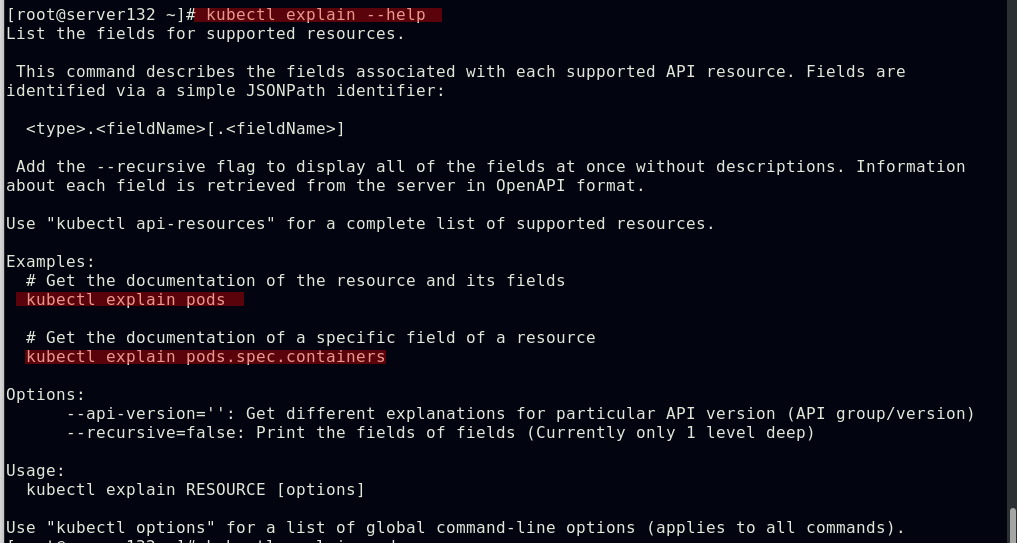
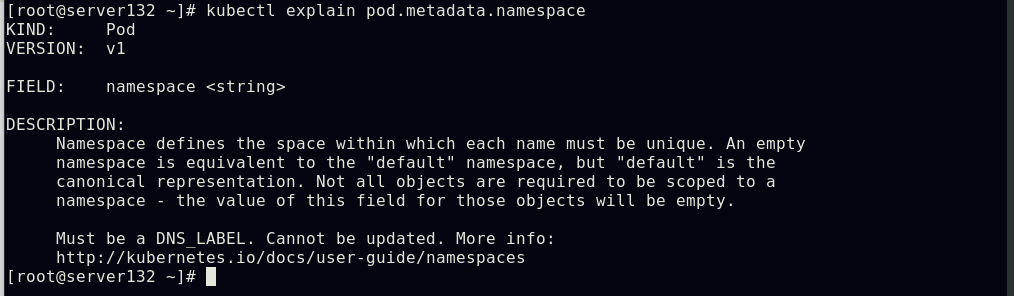
##可以使用kubectl explain命令来查看资源及其特定属性的释义
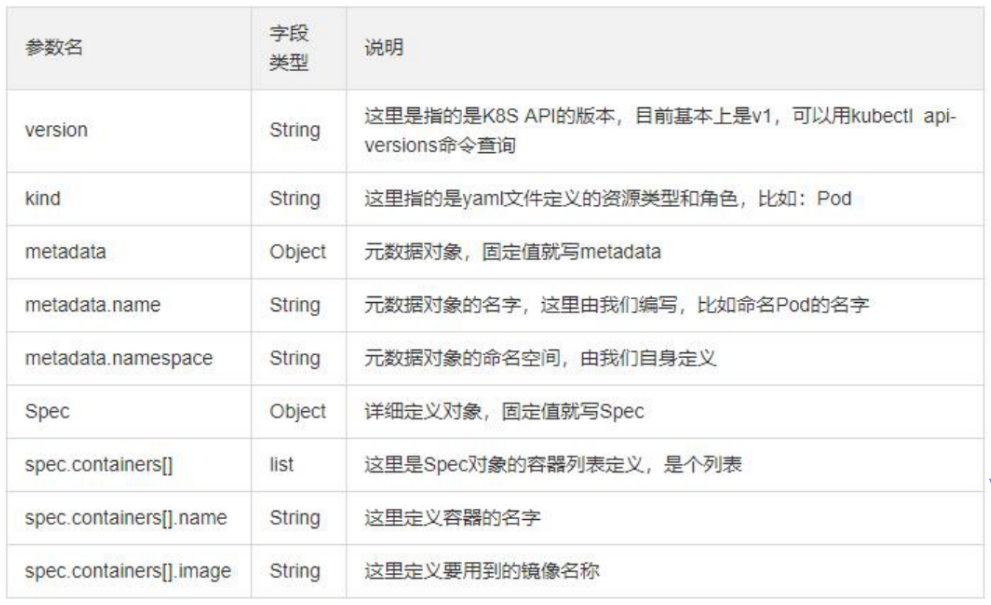
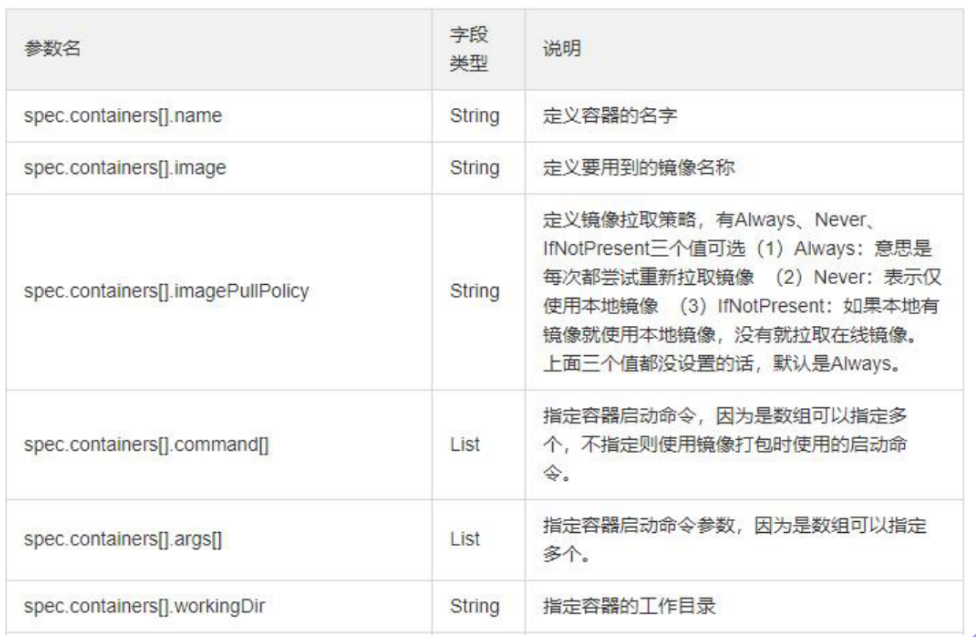
自主式pod资源清单
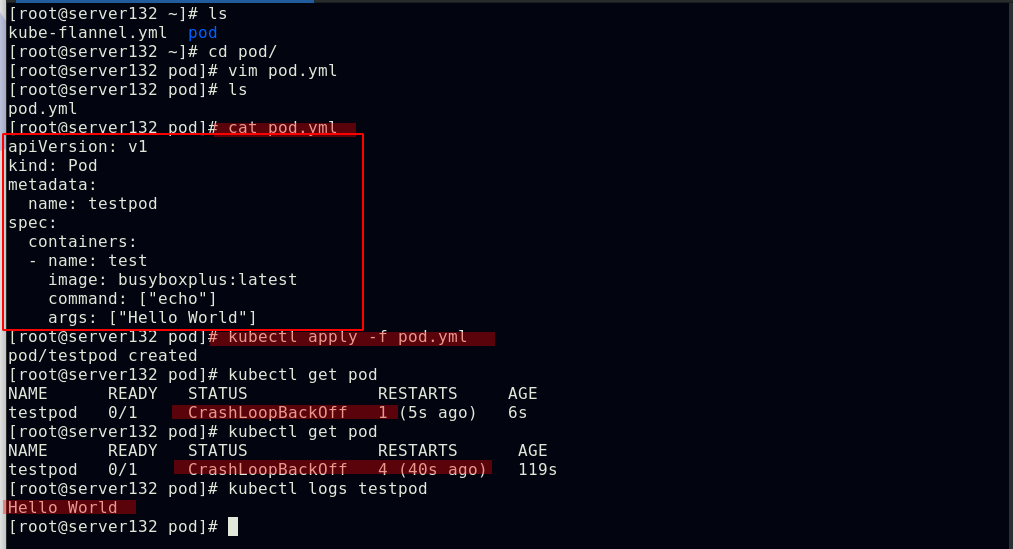
##应用资源清单文件创建pod,因未在清单文件中指定重启策略,故其默认为always,所以此pod的状态在不断重启失败后显示为崩溃循环,与使用的镜像有关;但是依然可以从pod的日志中查看到此pod已经成功运行
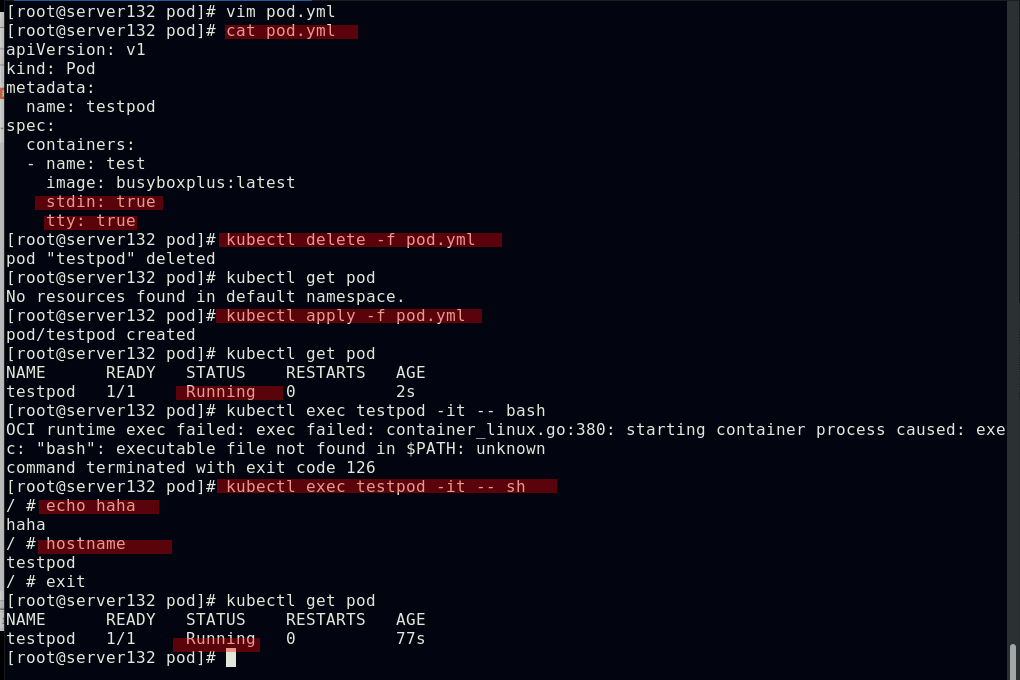
##此时在资源清单文件中添加交互式参数后,pod正常运行
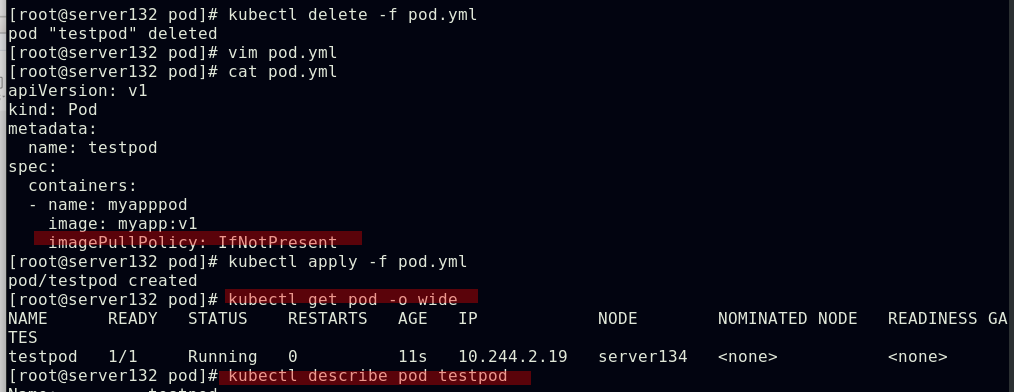

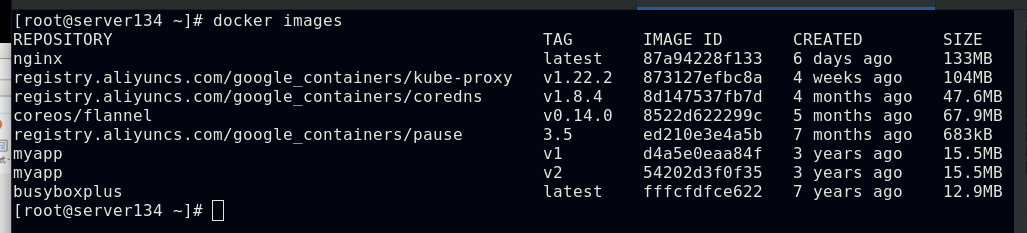
##在文件中指定镜像拉取策略为IfNotPresent,此pod分派的节点server134主机因本地存在该镜像,故此pod运行时未重新拉取镜像,提高了pod运行效率,未指定镜像拉取策略时默认为always,目的是为了pod运行时应用的镜像都是最新的
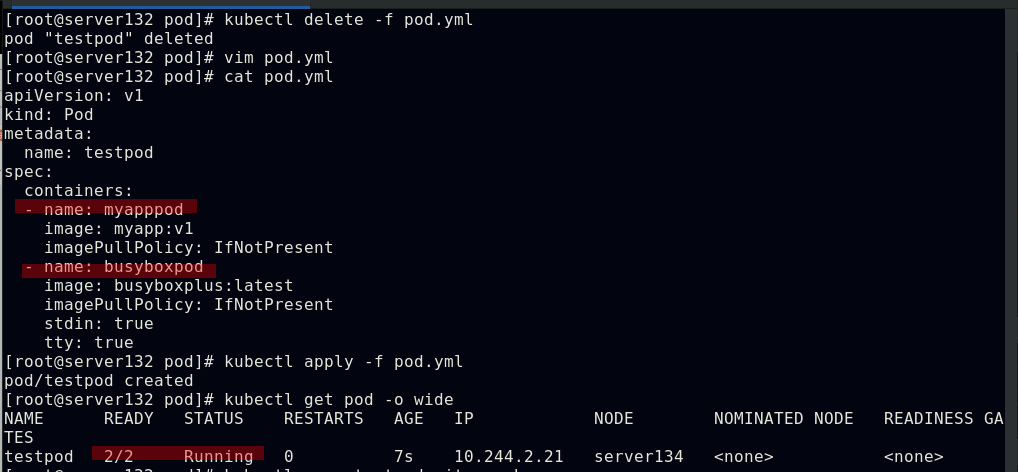
##一个pod中运行两个容器
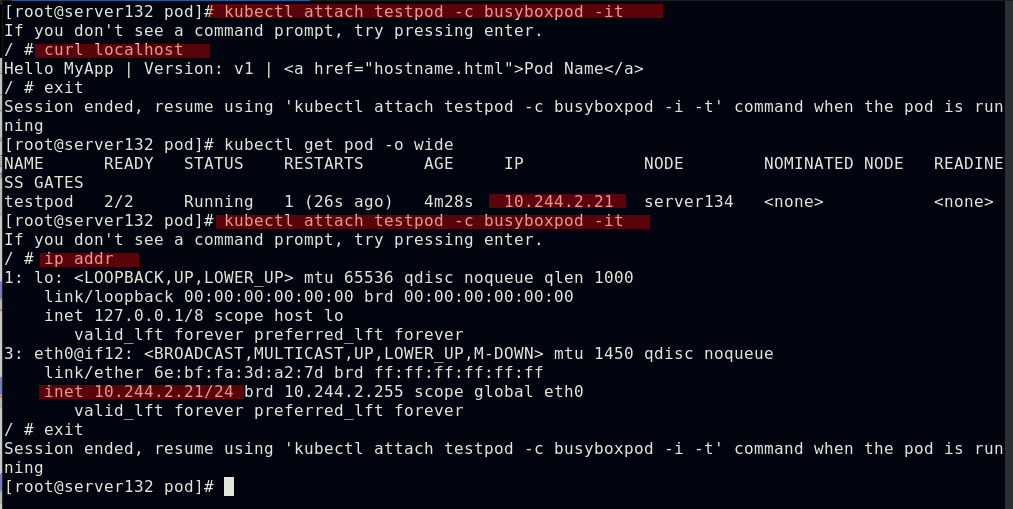
##此pod中的两个容器共用一个IP
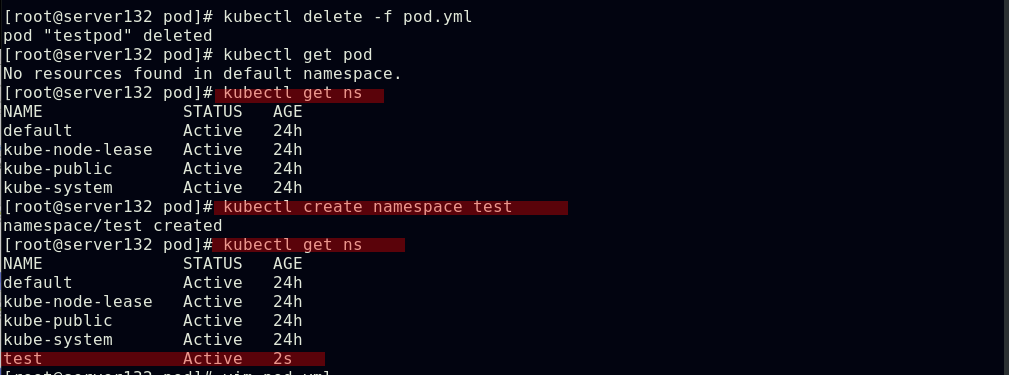
##创建namespace
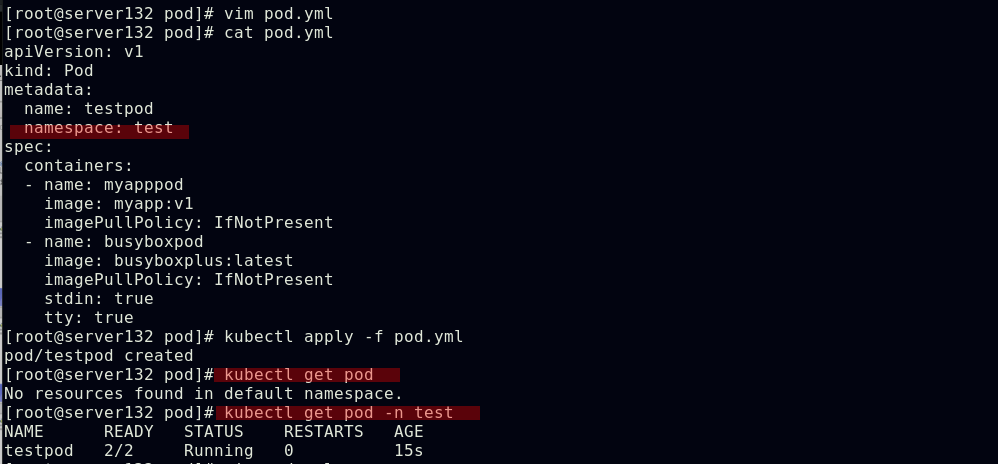
##创建此namespace下的pod
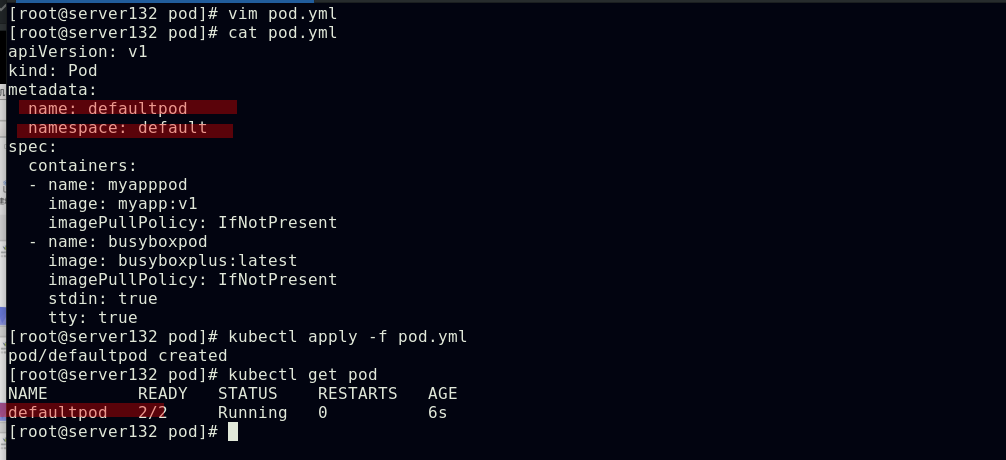
##创建默认namespace下的pod
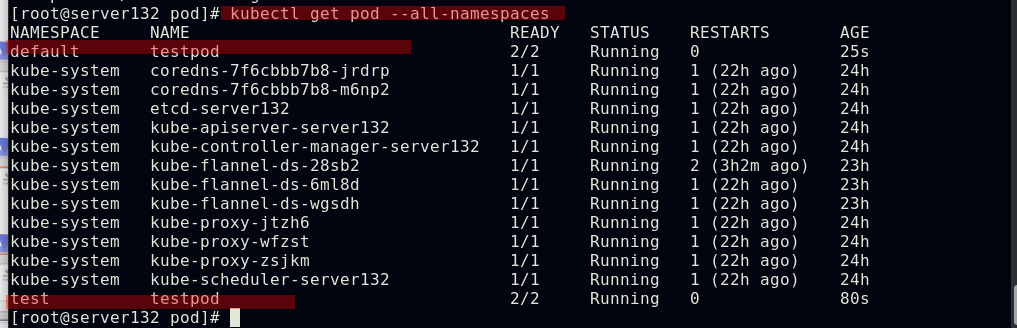
##查看所有namespace下的pod
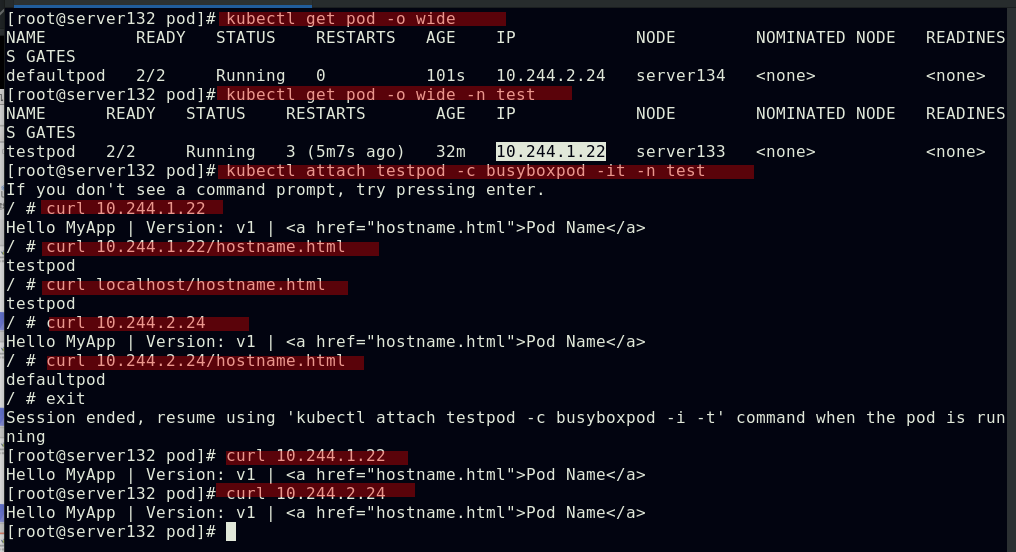
##此时不同namespace下的pod中的容器可以互相访问
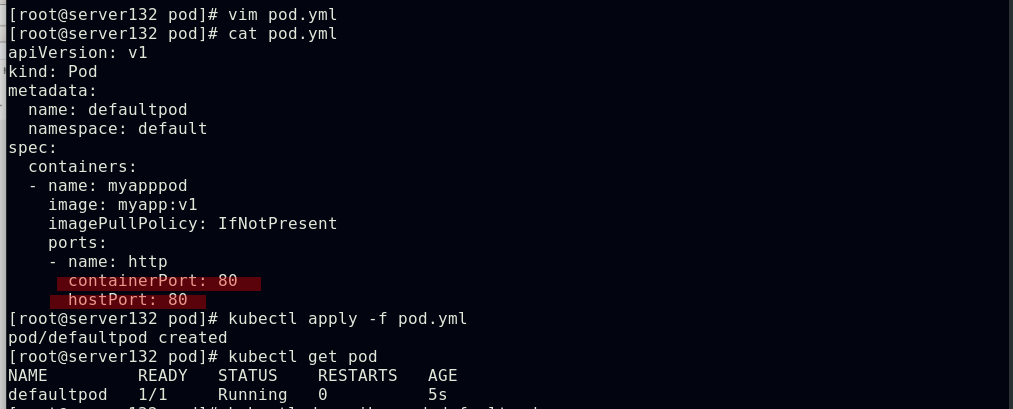
##创建pod,做端口映射



##此时只有此pod所在主机的iptables策略中会添加上图中的这条策略
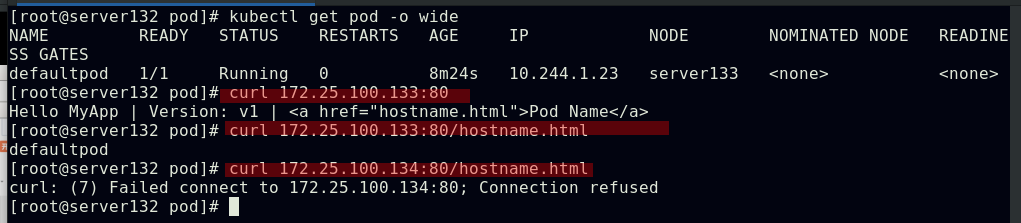

##此时集群内外都可以通过此主机IP:端口号访问到pod内的容器
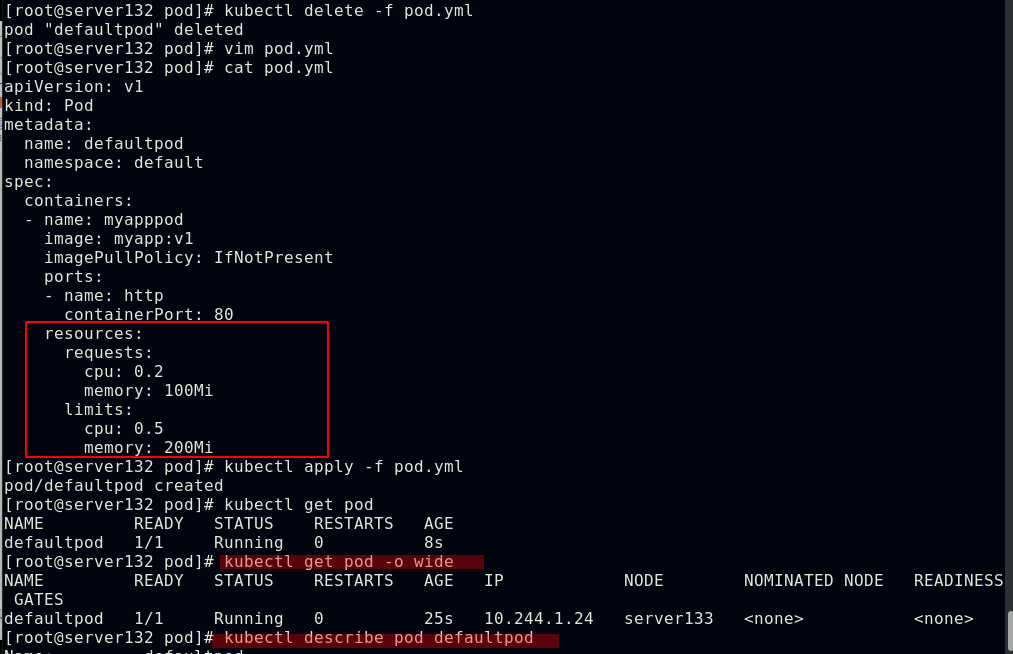
##配置pod中容器的使用系统资源的上限和下限(1MiB=2^20=1048576=1024KiB;1MB=10^6=1000000=1000KB)
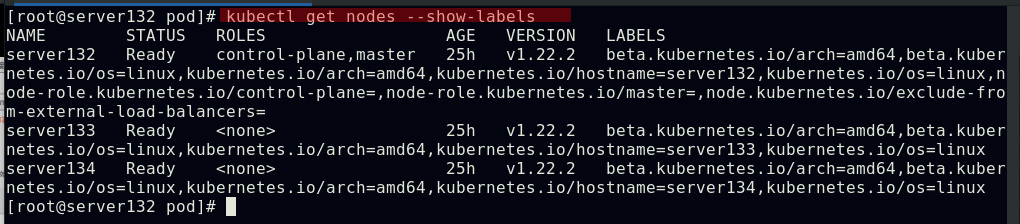
##查看集群中所有节点的标签键值
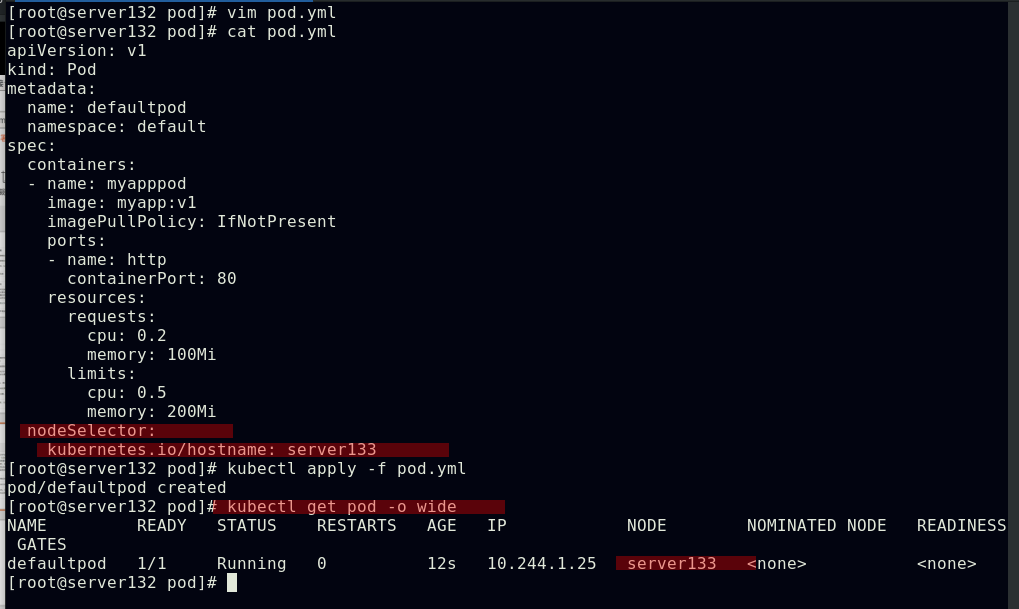
##在文件中配置标签选择器创建pod,此pod会分派至拥有此标签的集群节点上
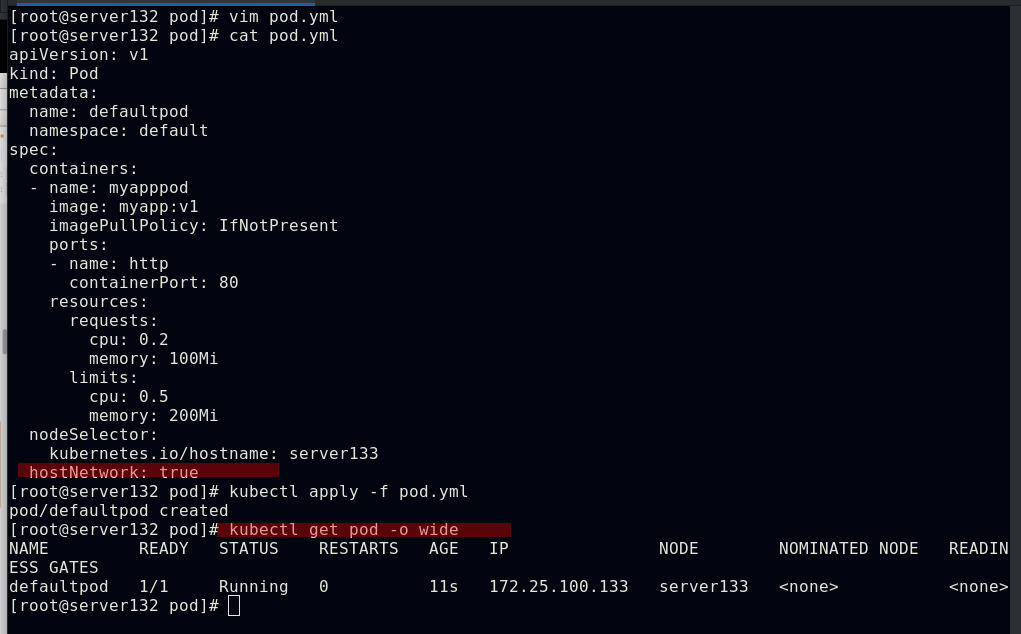
##配置pod使用主机网络



##此时集群内外即可以通过访问此pod所在节点的IP得到数据,不同于上述端口映射访问方式的是此种情况下对iptables的策略没有更改
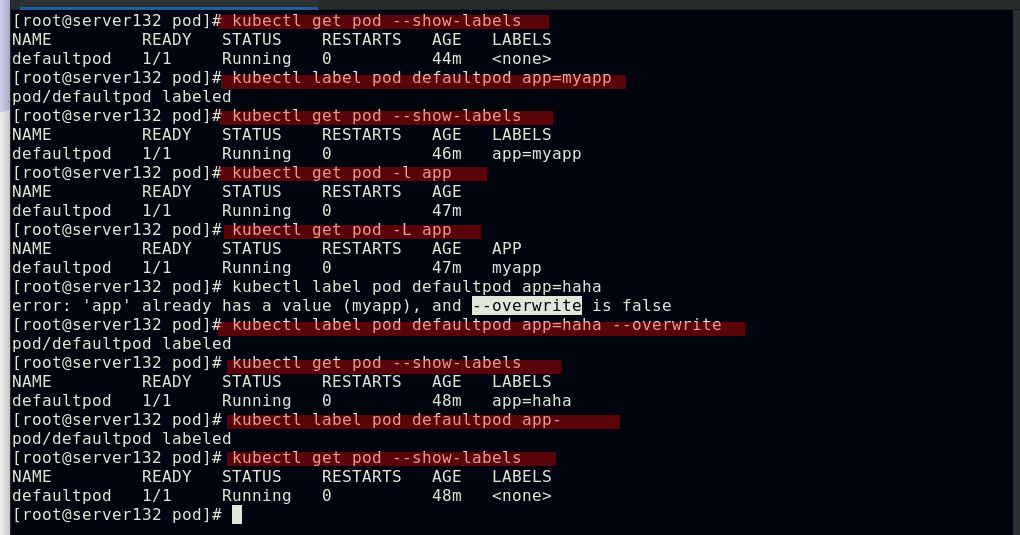
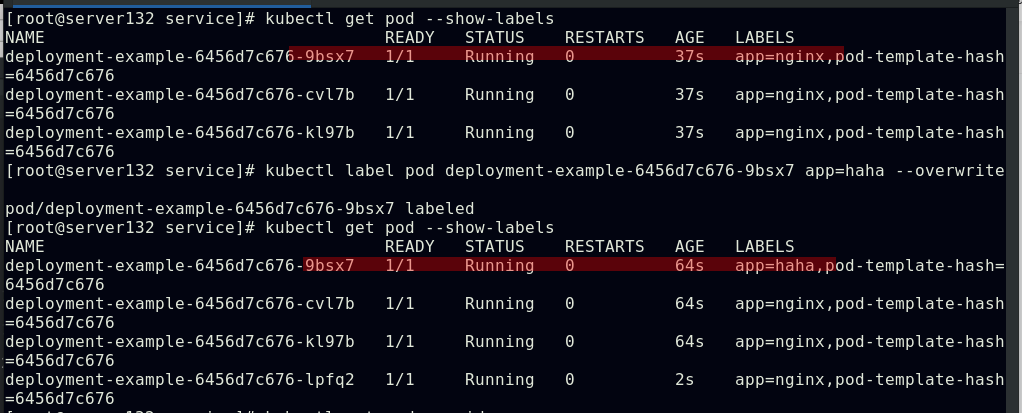
##查看pod标签、为pod打标签、过滤包含app的标签、更改标签、移除标签
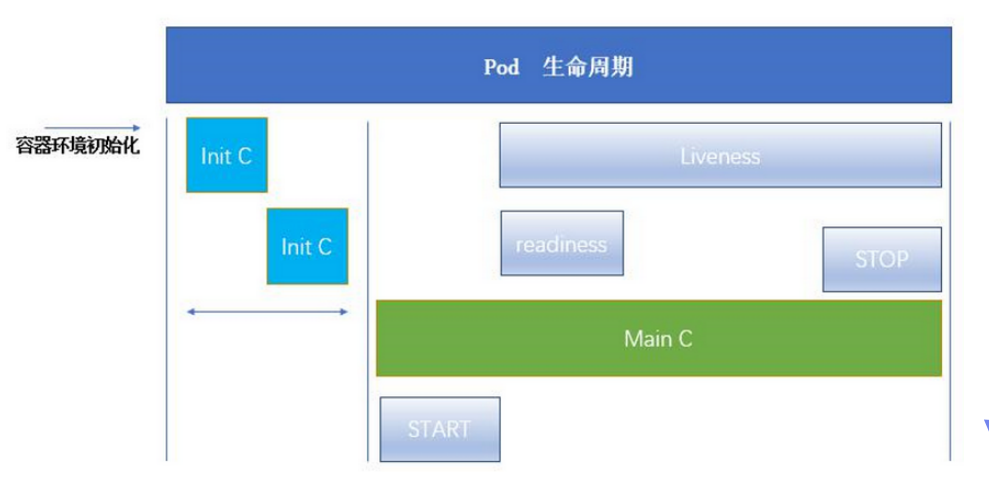
Pod生命周期
Pod可以包含多个容器,应用服务运行在这些容器中,同时 Pod也可以有一个或多个先于应用容器启动的Init容器
Init容器与普通的容器非常像,除了如下两点:
【1】它们总是运行到完成
【2】Init容器不支持Readiness,因为它们必须在Pod就绪之前就运行完成,每个Init容器必须运行成功,下一个才能够运行
如果Pod的Init容器运行失败,Kubernetes会不断重启该Pod,直到Init容器成功为止;然而,如果Pod对应的restartPolicy值为Never,便不会重新启动
Init容器能做什么:
Init容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码
Init容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像
Init容器能以不同于Pod内应用容器的文件系统视图运行;因此Init容器可具有访问Secrets的权限,而应用容器不能够访问
由于Init容器必须在应用容器启动之前运行完成,因此Init容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件,一旦前置条件满足,Pod内的所有的应用容器会并行启动
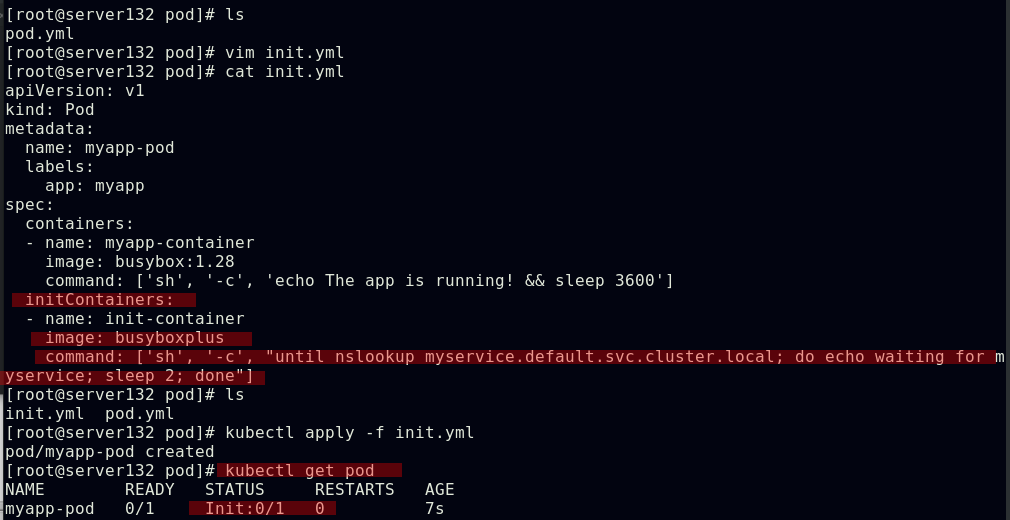
在pod中添加创建init容器
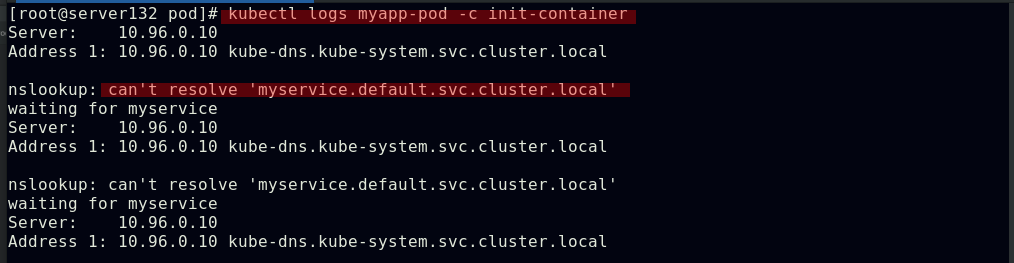
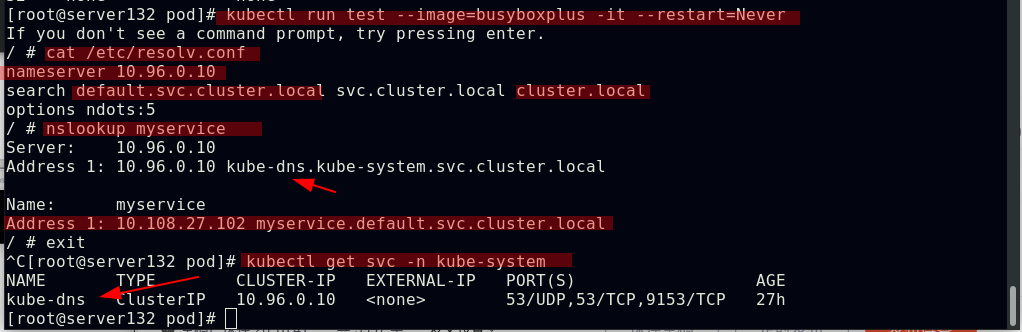
此时上述Init容器将会等待直至发现名称为myservice的service,才会就绪
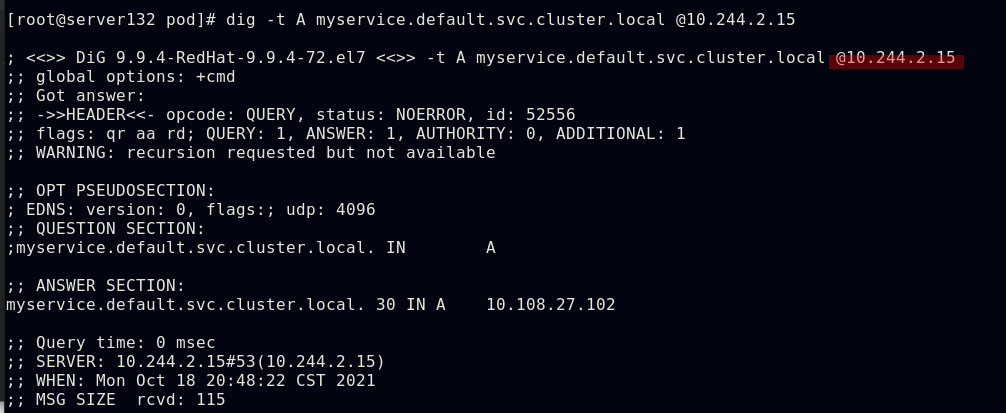
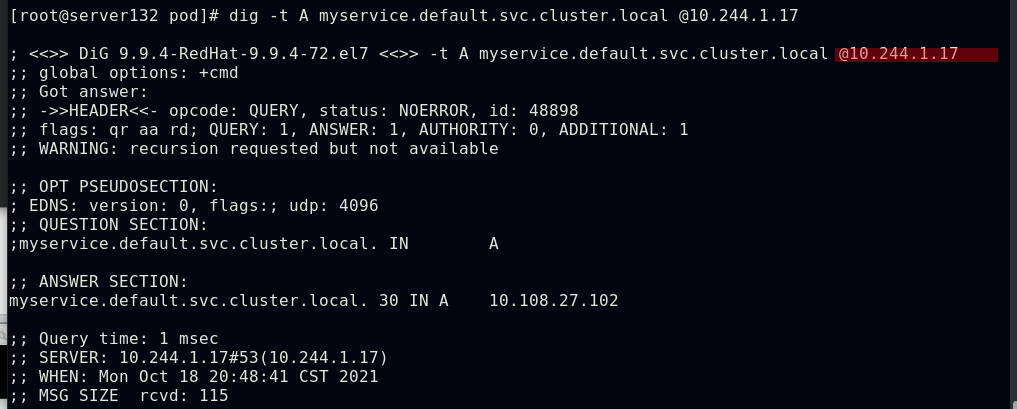
创建名为myservice的svc后,上述pod会先运行初始化容器,成功后后应用容器才会正常运行
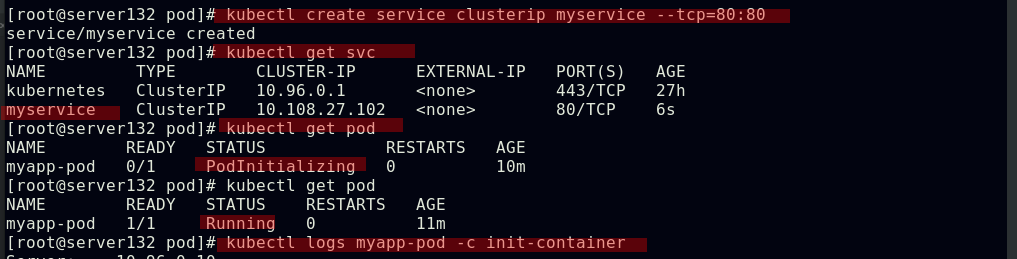

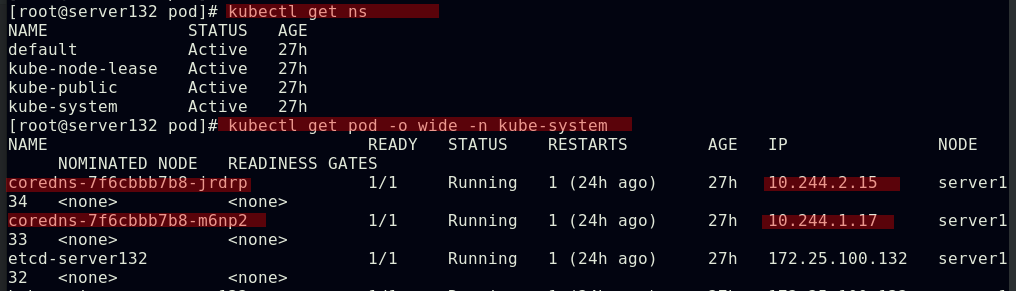
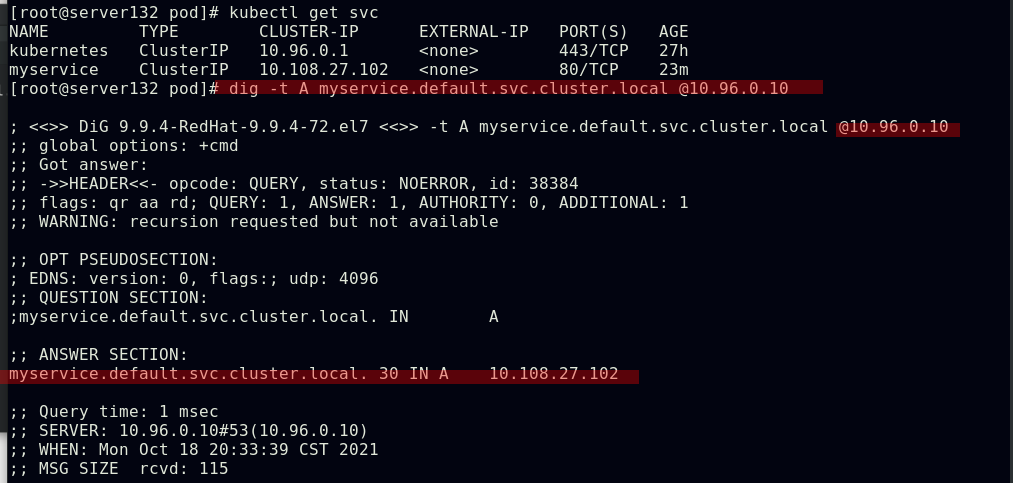
上述myservice微服务的地址解析是由kubernetes的kube-system命名空间中的两个核心dns服务来处理的
容器的探针是由kubelet对容器执行的定期诊断;主要包含以下三种探测方式
ExecAction:在容器内执行指定命令,如果命令退出时返回码为0,则认为诊断成功
TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查;如果端口打开,则诊断被认为是成功的
HTTPGetAction:对指定的端口和路径上的容器的IP地址执行HTTPGet请求,如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一: 成功==容器通过了诊断;失败==容器未通过诊断;未知==诊断失败,不会采取任何行动
Kubelet可以选择是否执行在容器上运行的三种探针和做出反应:
livenessProbe:指示容器是否正在运行;如果存活探测失败,则kubelet会杀死容器,并且容器将受到其重启策略的影响;如果容器不提供存活探针,则默认状态为Success
readinessProbe:指示容器是否准备好服务请求;如果就绪探测失败,端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址,初始延迟之前的就绪状态默认为Failure,如果容器不提供就绪探针,则默认状态为Success
startupProbe: 指示容器中的应用是否已经启动;如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止,如果启动探测失败,kubelet将杀死容器,容器服从其重启策略进行重启,如果容器没有提供启动探测,则默认状态为Success
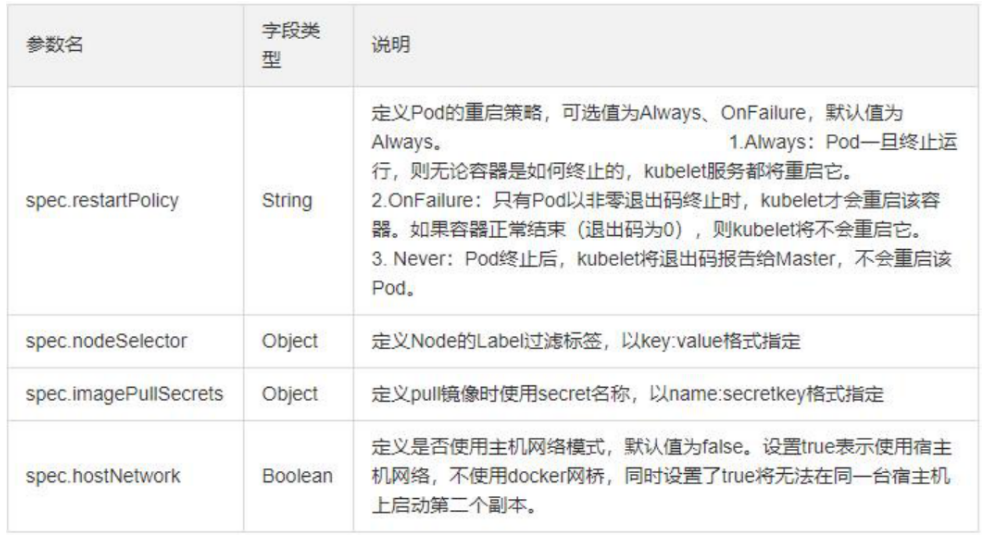
重启策略
PodSpec中有一个restartPolicy字段,可能的值为Always、OnFailure和Never;默认为Always
Pod的生命
一般Pod不会消失,直到人为销毁,这可能是一个人或控制器;建议创建适当的控制器来创建Pod,而不是直接自己创建Pod,因为单独的Pod在机器故障的情况下没有办法自动复原,而控制器却可以
三种可用的控制器
使用Job运行预期会终止的Pod,例如批量计算;Job仅适用于重启策略为OnFailure或Never的Pod
对预期不会终止的Pod使用ReplicationController、ReplicaSet和Deployment,例如Web服务器;ReplicationController仅适用于具有restartPolicy为Always的Pod
提供特定于机器的系统服务,使用DaemonSet为每台机器运行一个Pod
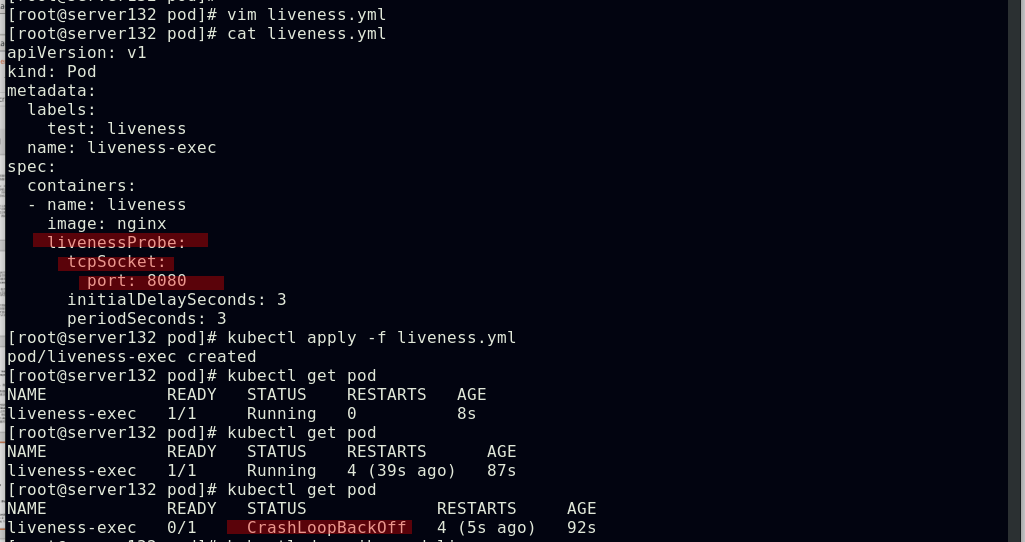
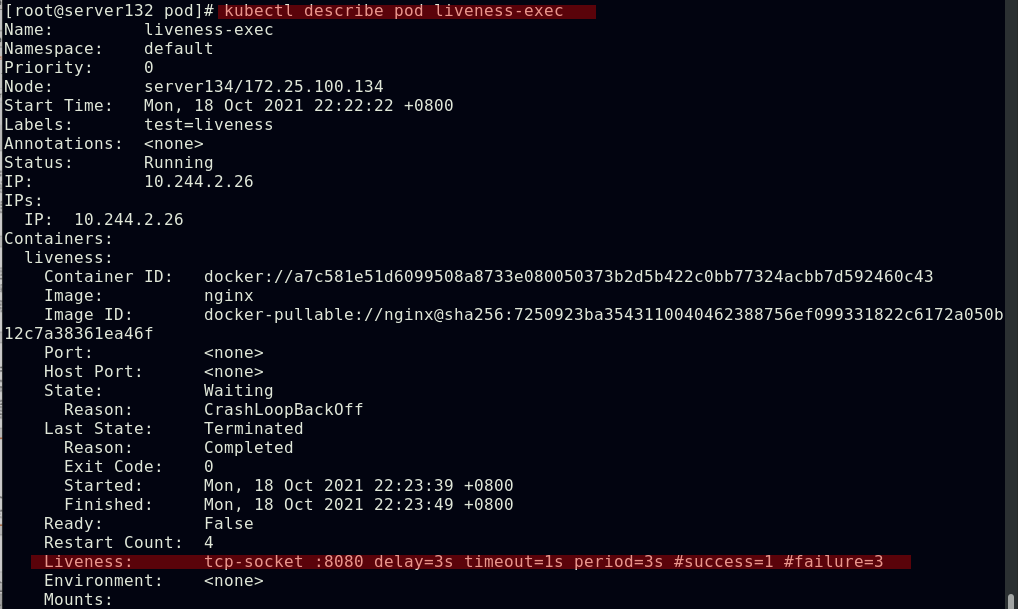
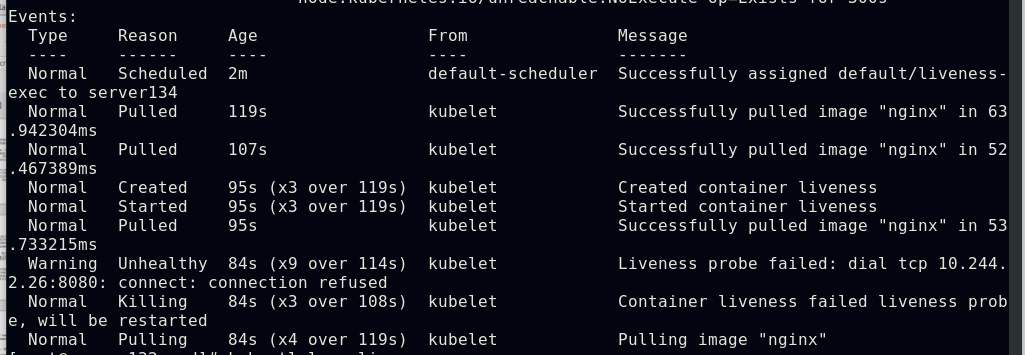
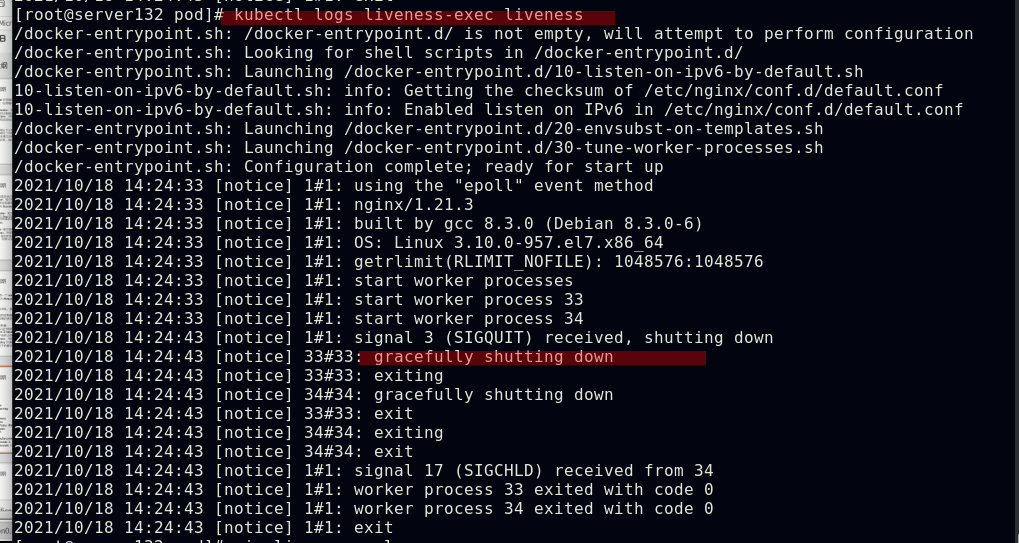
##采用TCPSocket探测方式配置pod容器的存活探针,因设定探测的端口号为8080而nginx默认使用的端口号为80,则此存活探针会得到的结果为失败,容器也会被kill掉
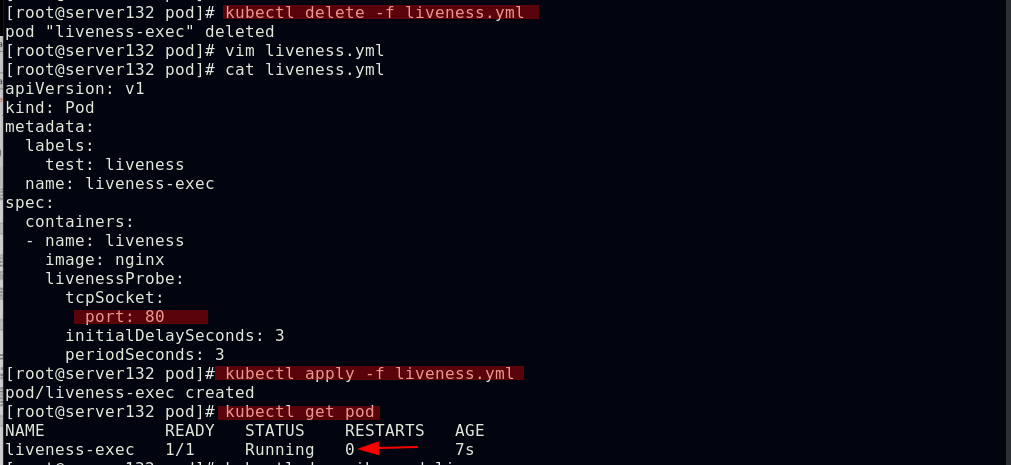
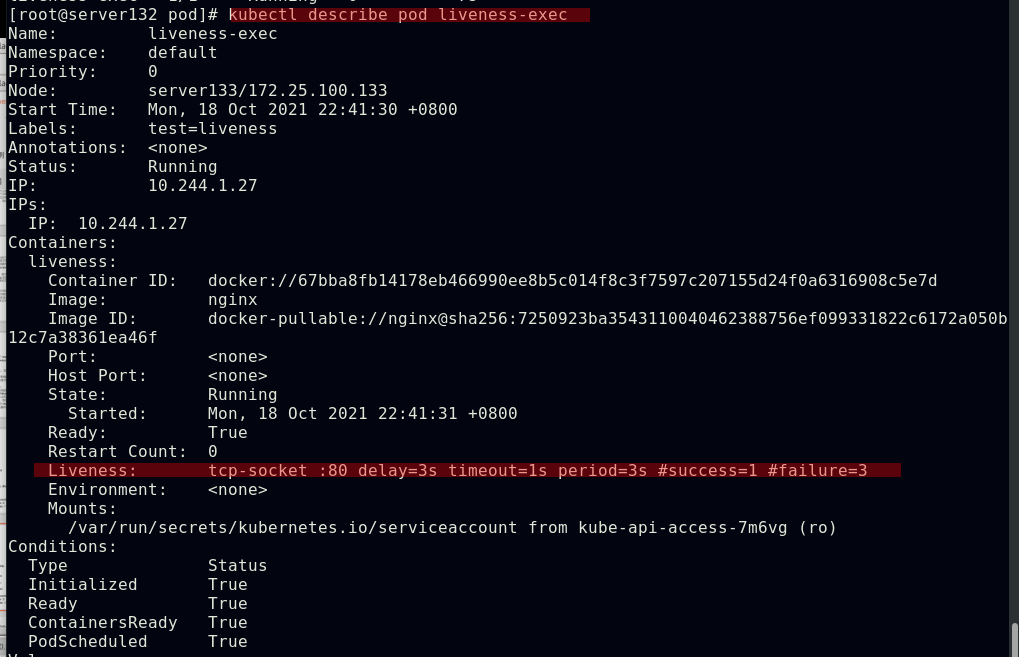

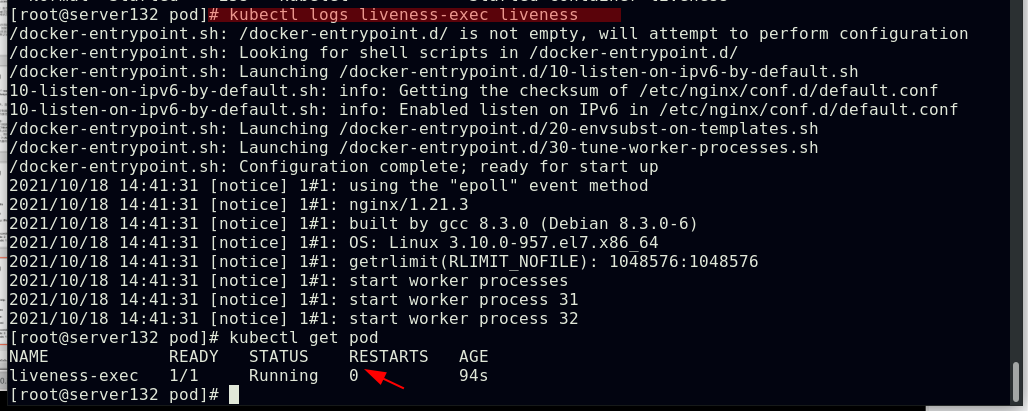
##更改存活探针文件中的探测端口为默认的80后,存活探测成功,容器正常运行,没有重启次数
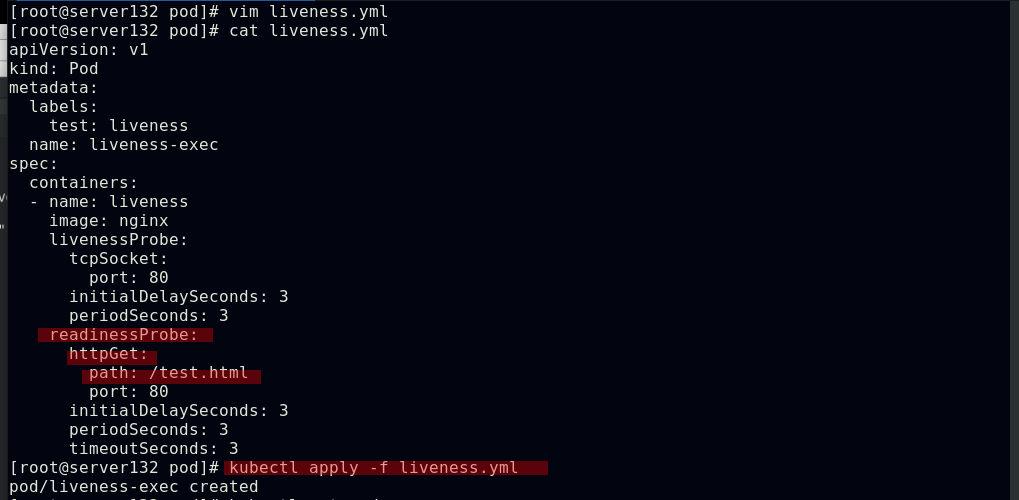

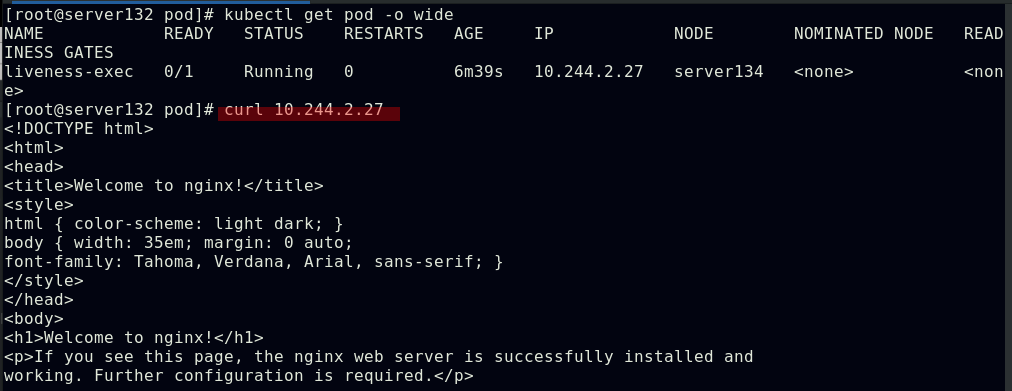
##采用HTTPGet探测方式配置pod容器的就绪探针,因设定探测nginx的测试页面为test.html而nginx的默认测试页为index.html,则此就绪探针会得到的结果为失败,永远不会就绪但容器会运行
![]()
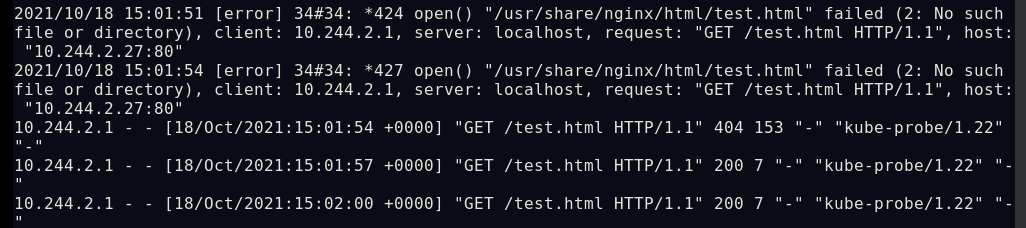
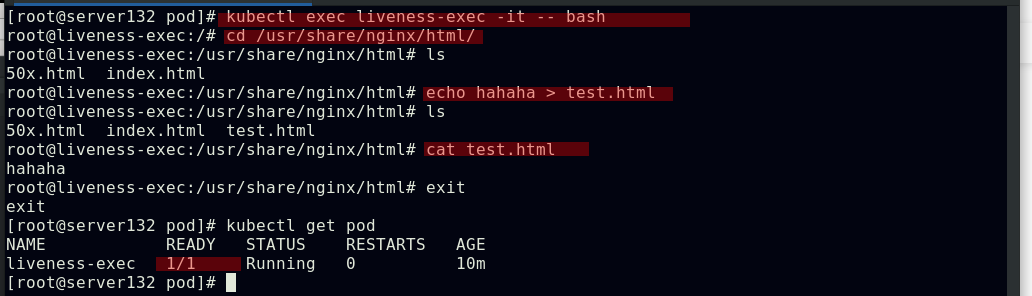
##进入容器创建测试页文件test.html,再次查看pod状态,容器成功就绪
控制器
在Kubernetes中,控制器通过监控集群的公共状态,并致力于将当前状态转变为期望的状态
更多信息详见官网控制器介绍
控制器 | Kubernetes https://kubernetes.io/zh/docs/concepts/architecture/controller/Pod 的分类
https://kubernetes.io/zh/docs/concepts/architecture/controller/Pod 的分类
自主式Pod:Pod退出后不会被创建
控制器管理的Pod:在控制器的生命周期里,始终要维持Pod的副本数目
控制器类型
Replication Controller和ReplicaSet、Deployment、DaemonSet、StatefulSet、Job、CronJob、HPA(Horizontal Pod Autoscaler)
Replication Controller和ReplicaSet:ReplicaSet是下一代的Replication Controller,官方推荐使用ReplicaSet;ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求;ReplicaSet确保任何时间都有指定数量的Pod副本在运行;虽然ReplicaSet可以独立使用,但今天它主要被Deployment用作协调Pod创建、删除和更新的机制
Deployment:Deployment为Pod和ReplicaSet提供了一个申明式的定义方法;典型的应用场景:用来创建Pod和ReplicaSet,滚动更新和回滚,扩容和缩容,暂停与恢复
DaemonSet:DaemonSet确保全部(或者某些)节点上运行一个Pod的副本;当有节点加入集群时,也会为他们新增一个Pod,当有节点从集群移除时,这些Pod也会被回收;删除DaemonSet将会删除它创建的所有Pod
DaemonSet的典型用法:在每个节点上运行集群存储DaemonSet,例如glusterd、ceph;在每个节点上运行日志收集DaemonSet,例如 fluentd、logstash;在每个节点上运行监控DaemonSet,例如Prometheus Node Exporter、zabbix agent等
一个简单的用法是在所有的节点上都启动一个DaemonSet,将被作为每种类型的daemon使用
一个稍微复杂的用法是单独对每种daemon类型使用多个DaemonSet,但具有不同的标志,并且对不同硬件类型具有不同的内存、CPU要求
StatefulSet:StatefulSet是用来管理有状态应用的工作负载API对象;实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,称为“有状态应用”;StatefulSet用来管理Deployment和扩展一组Pod,并且能为这些Pod提供 序号和唯一性保证 ;StatefulSet对于需要满足以下一个或多个需求的应用程序很有价值:稳定的、唯一的网络标识符;稳定的、持久的存储;有序的、优雅的部署和缩放;有序的、自动的滚动更新
Job:执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束
CronJob:Cron Job创建基于时间调度的Jobs;一个CronJob对象就像crontab(cron table)文件中的一行,它用Cron格式进行编写,并周期性地在给定的调度时间执行Job
HPA:根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放
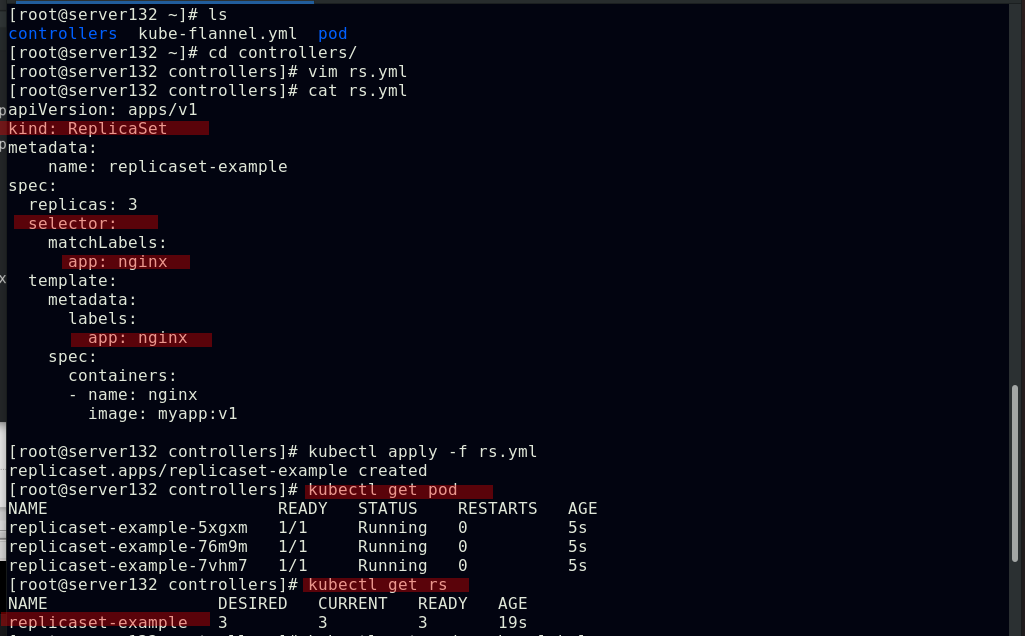
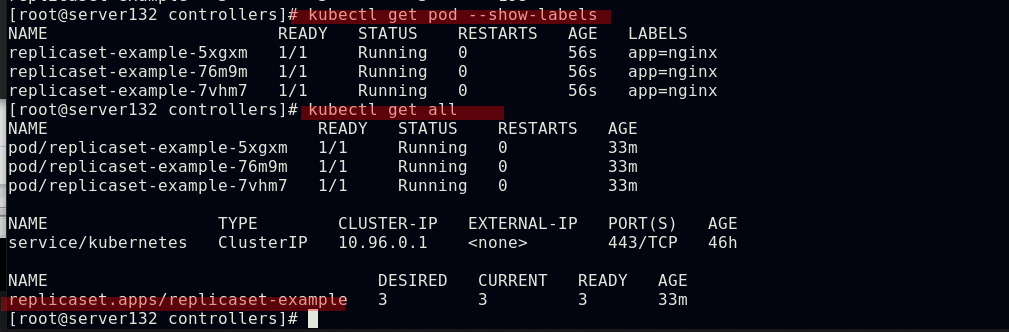
##创建replicaset控制器,并配置选择器
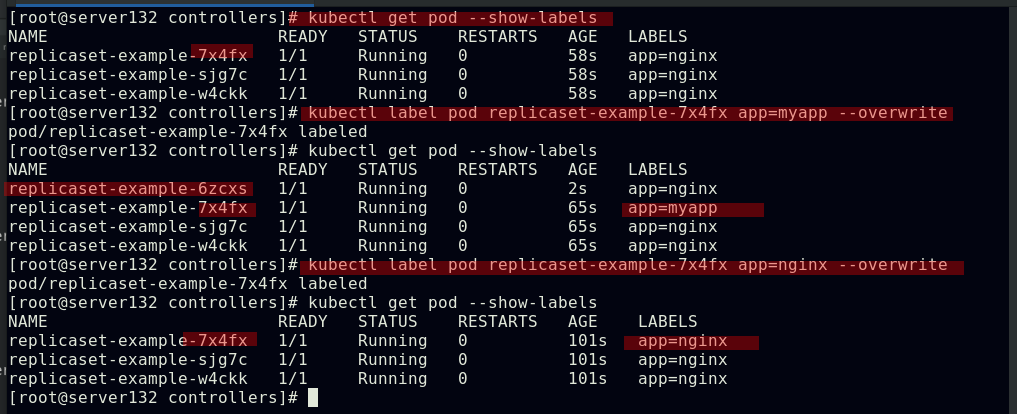
##更改其中一个副本的标签为不同于yml文件中定义的标签后,控制器会拉取一个新的副本以满足yml文件中定义的副本个数;当回改前述副本的标签为yml文件中定义的标签后,新拉取的pod副本会被回收以使副本个数符合yml文件中定义的个数
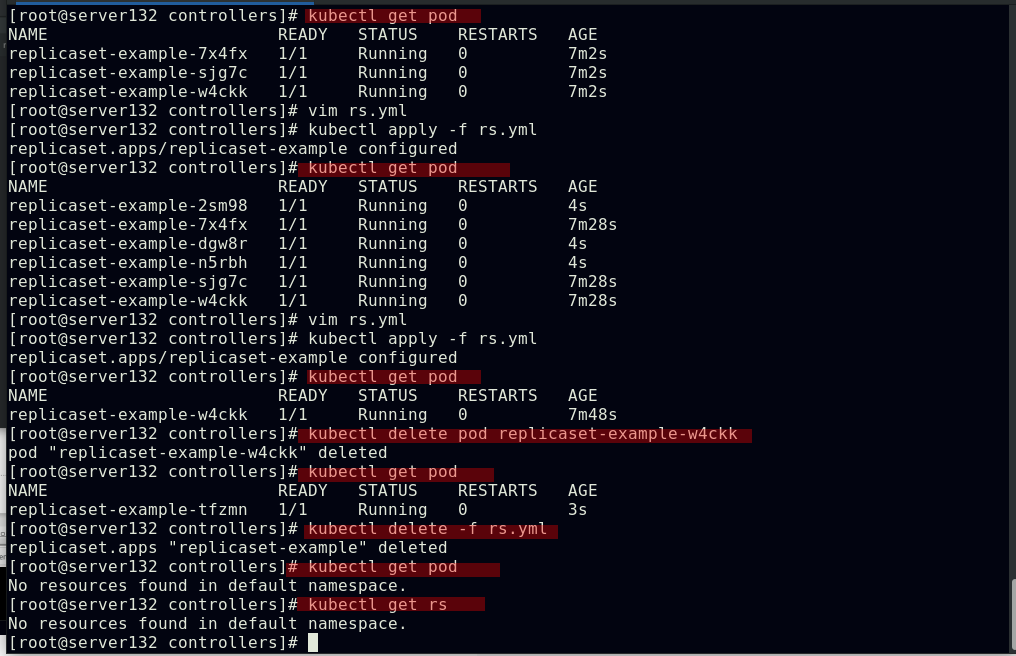
##pod副本的扩容与缩容;控制器被删除后,pod也被回收
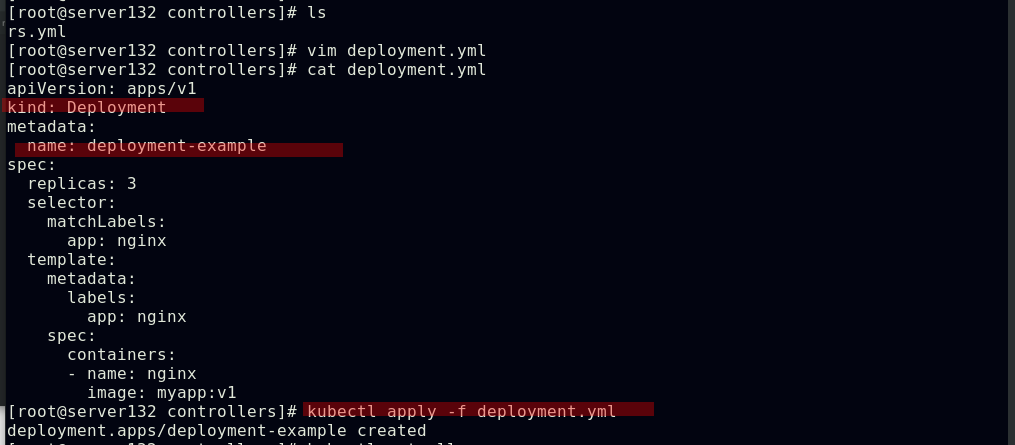
##创建deployment控制器
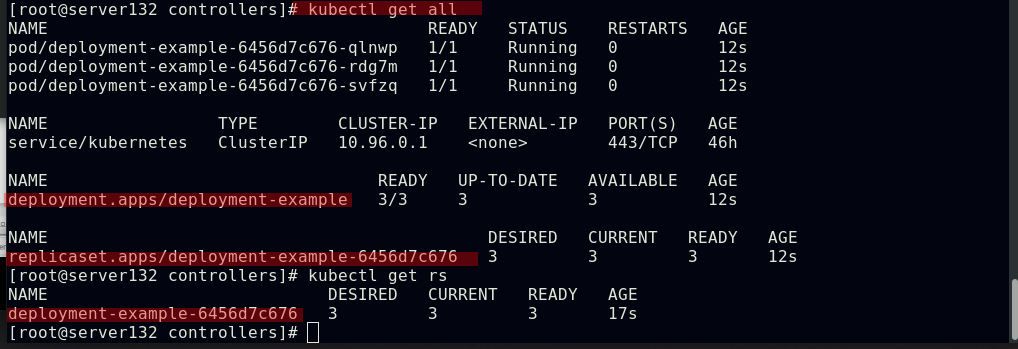
##创建deployment控制器的同时也创建了replicaset控制器,其被用做Deployment的协调项
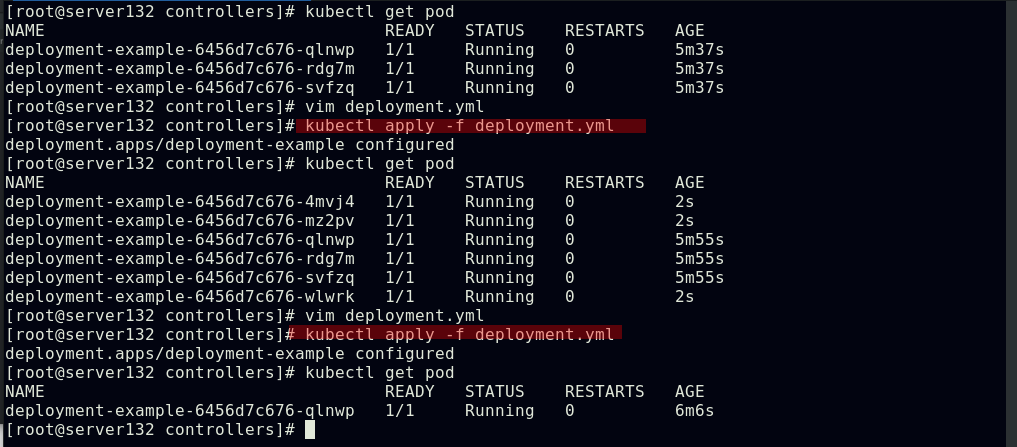
##deployment控制pod副本的扩容与缩容
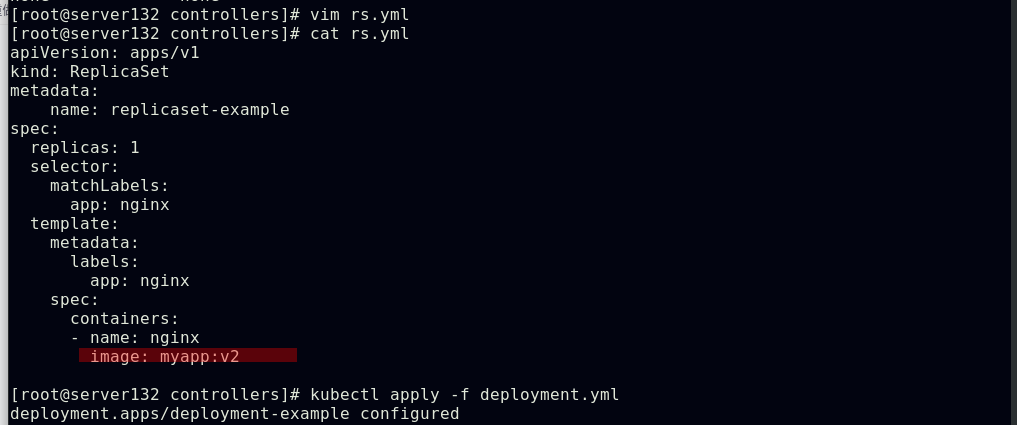
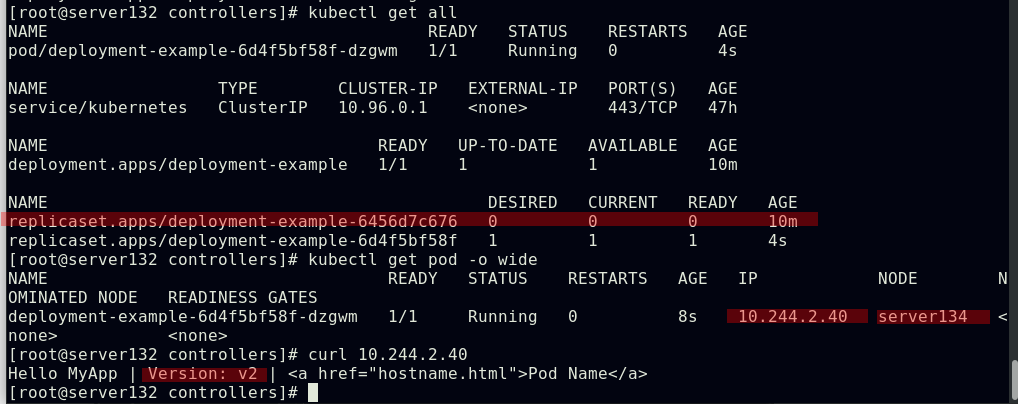
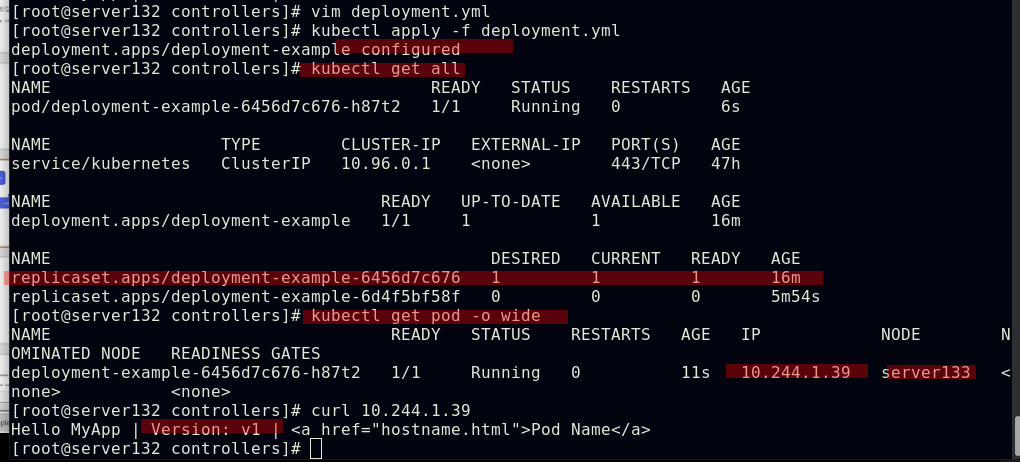
##deployment控制pod的更新与回滚
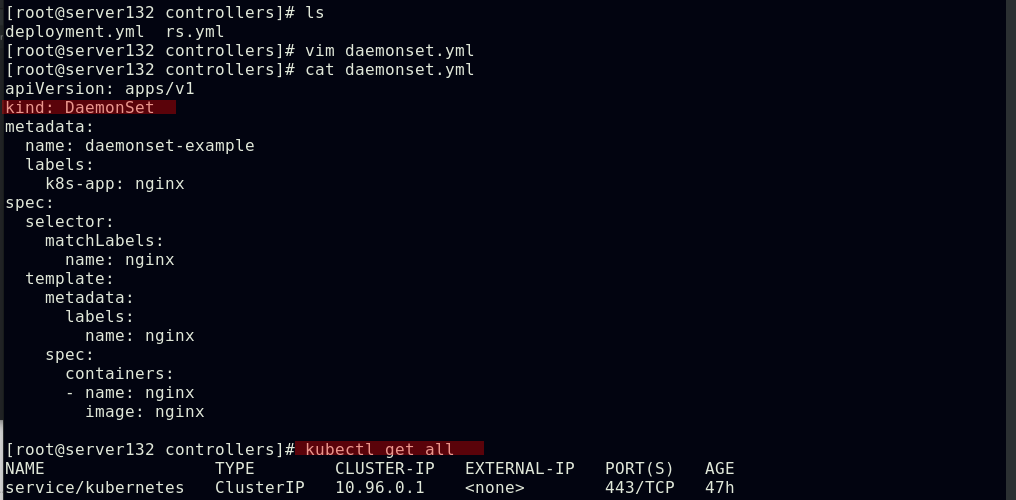
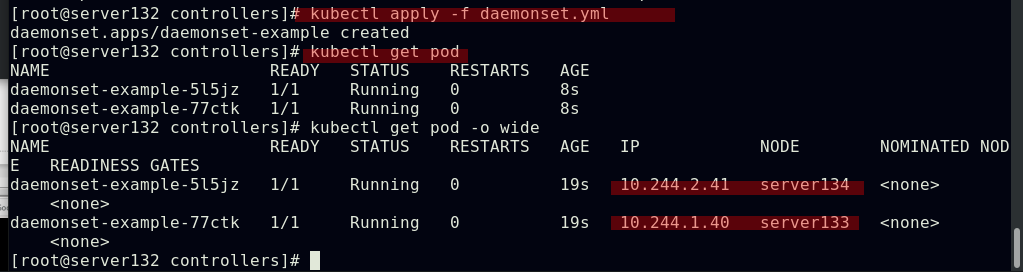
##daemonset控制器为集群中的每一个节点运行一个pod副本(除master节点)
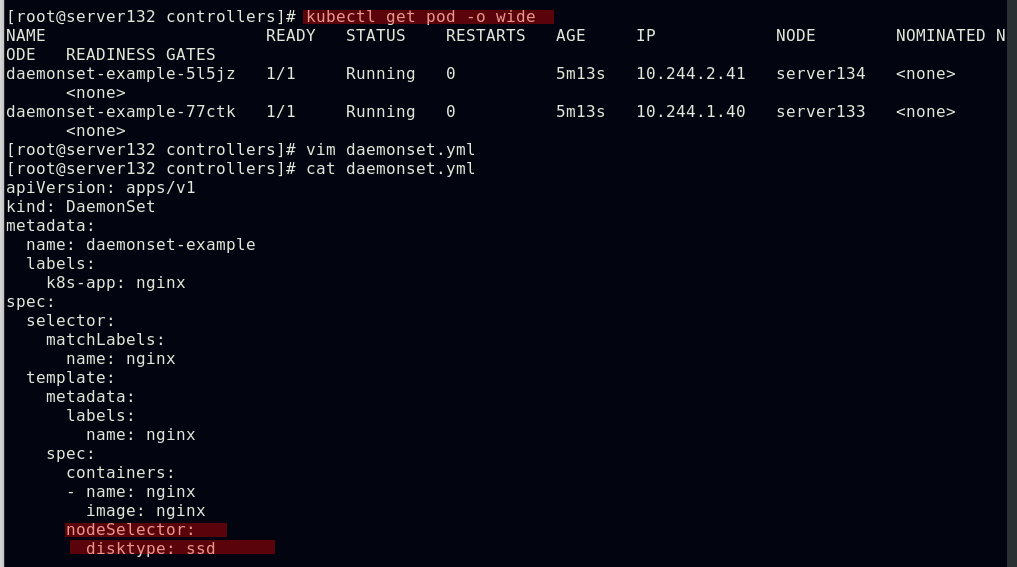
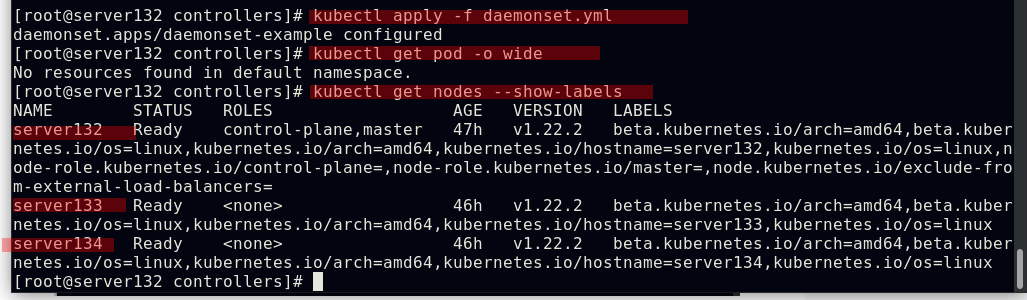
##配置daemonset控制器的节点选择器,此时因为集群中的两个节点都不具有yml文件中定义的选择键值标签,故不会在任何节点运行pod副本
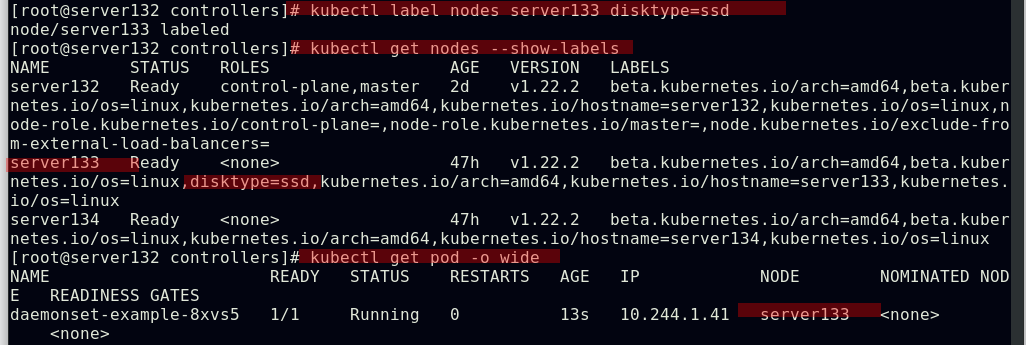
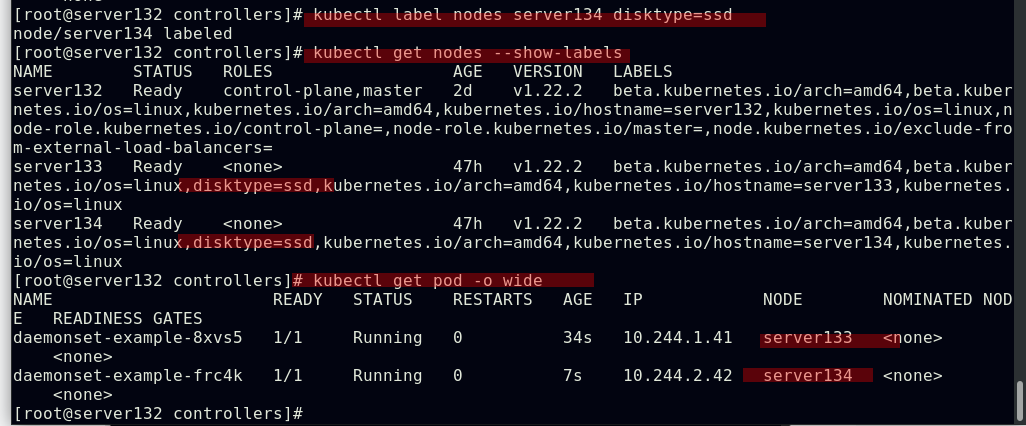
##为节点打上yml文件中定义的标签后,pod副本成功运行在符合标签的节点上
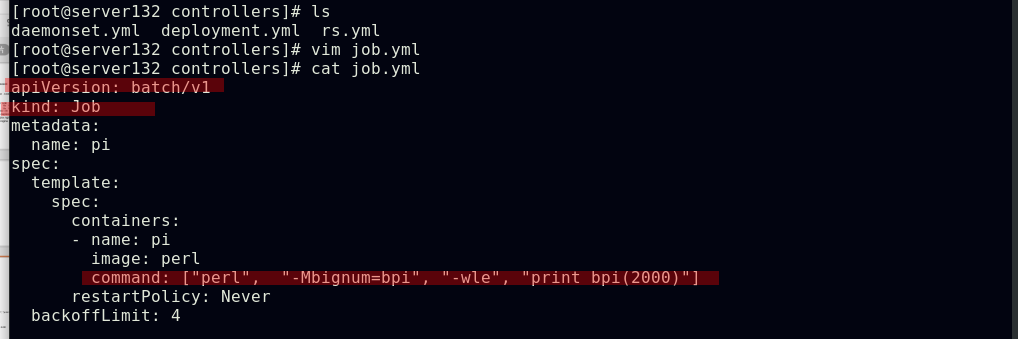
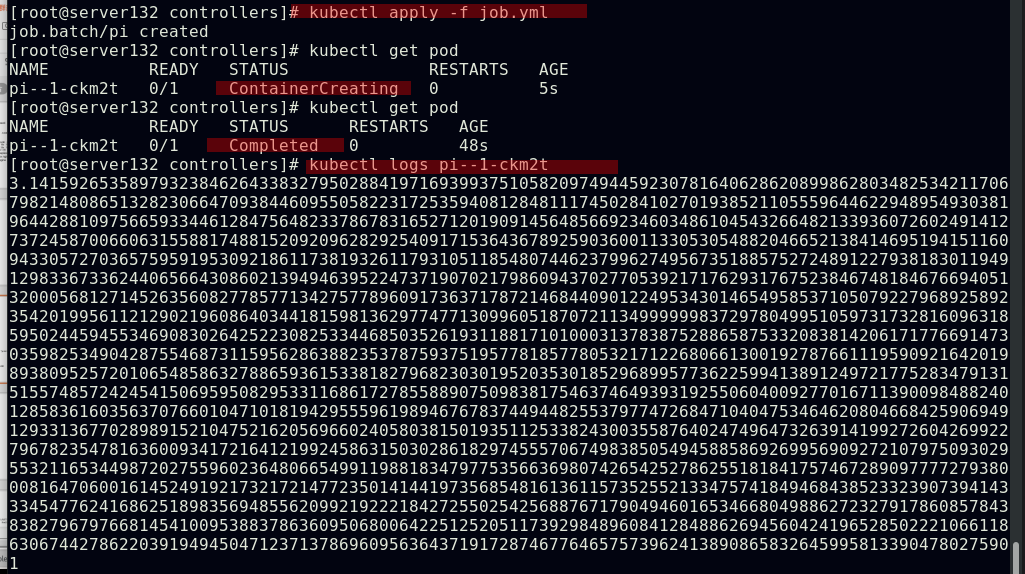
##创建job控制器,其仅执行一次任务,并保证任务的Pod成功结束
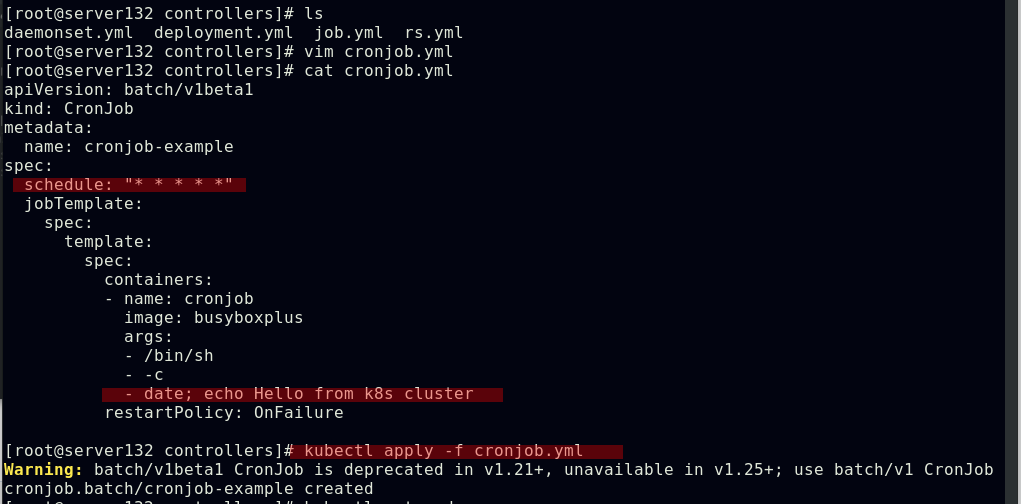
##创建cronjob控制器,指定每分钟执行一次
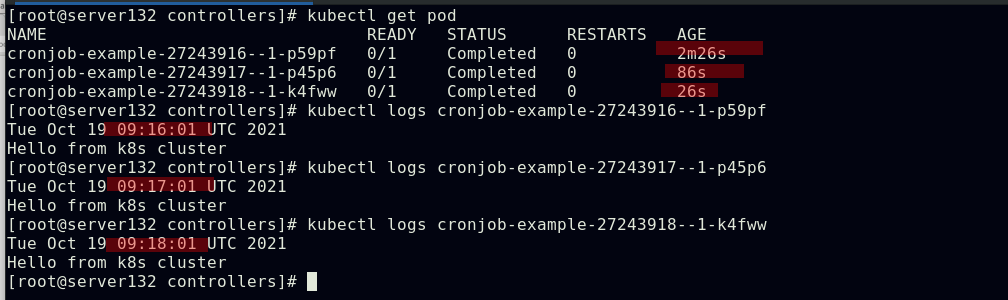
##cronjob控制器下的pod执行效果
service
Service可以看作是一组提供相同服务的Pod对外的访问接口,借助Service,应用可以方便地实现服务发现和负载均衡;service默认只支持4层负载均衡能力,没有7层功能(可以通过Ingress实现)
service的类型:
ClusterIP:默认值,kubernetes系统给service自动分配的虚拟IP,只能在集群内部访问
NodePort:将Service通过指定集群节点上的端口暴露给外部,访问任意一个NodeIP:NodePort都将路由到ClusterIP
LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到<NodeIP>:NodePort,此模式只能在云服务器上使用
ExternalName:将服务通过DNS CNAME记录方式转发到指定的域名(通过spec.externlName设定)
Service是由kube-proxy组件加上iptables来共同实现的;kube-proxy通过iptables处理Service的过程,需要在宿主机上设置相当多的iptables规则,如果宿主机有大量的Pod,不断刷新iptables规则会消耗大量的CPU资源;而IPVS模式的service,可以使kubernetes集群支持更多量级的Pod
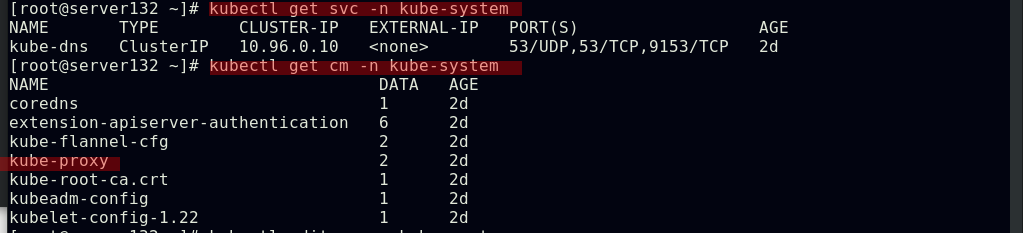
##查看kube-system命名空间下的service及configmap(ConfigMap是用来存储配置文件的kubernetes资源对象,所有的配置内容都存储在etcd中)
![]()

##编辑kube-proxy资源的配置文件更改其service模式为ipvs
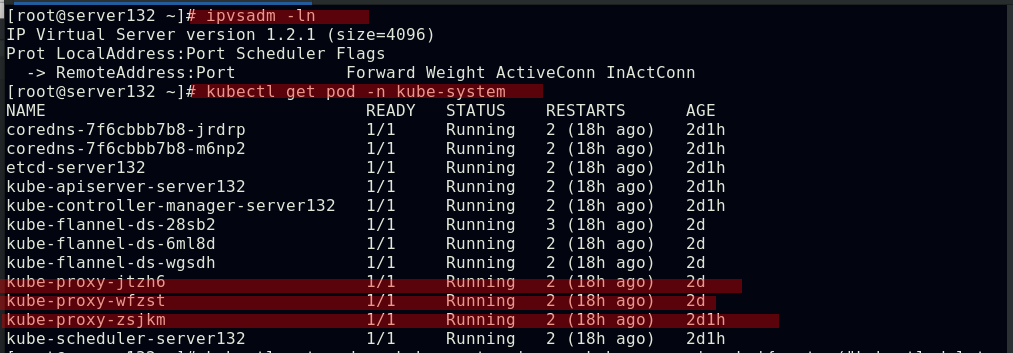
##此时ipvs模式还未接管处理service过程
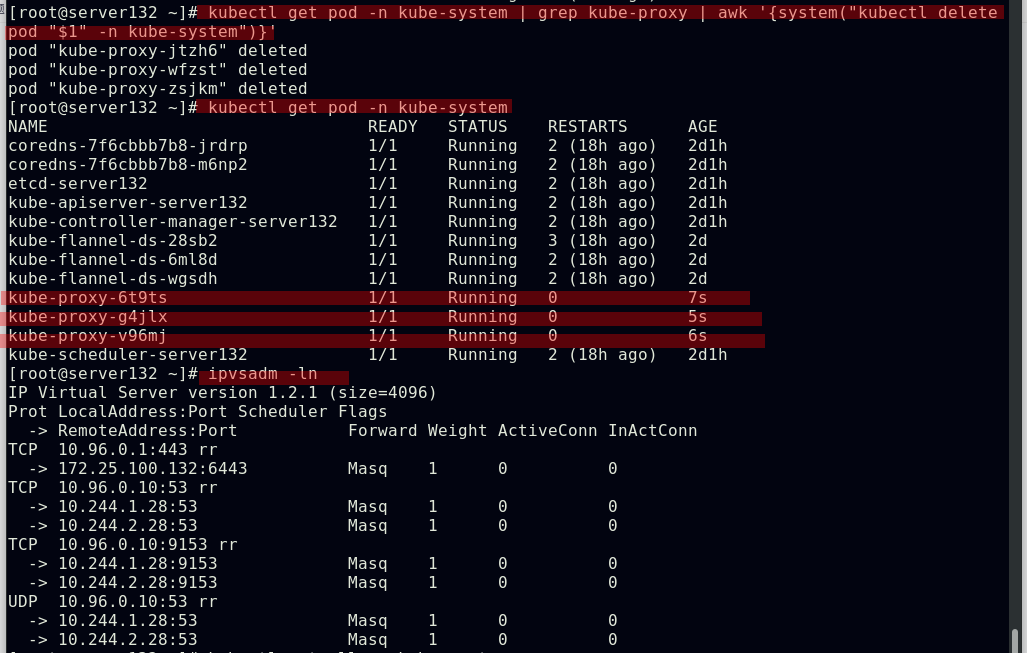
##删除kube-system命名空间下的kube-proxy--pod,以刷新ipvs模式的策略
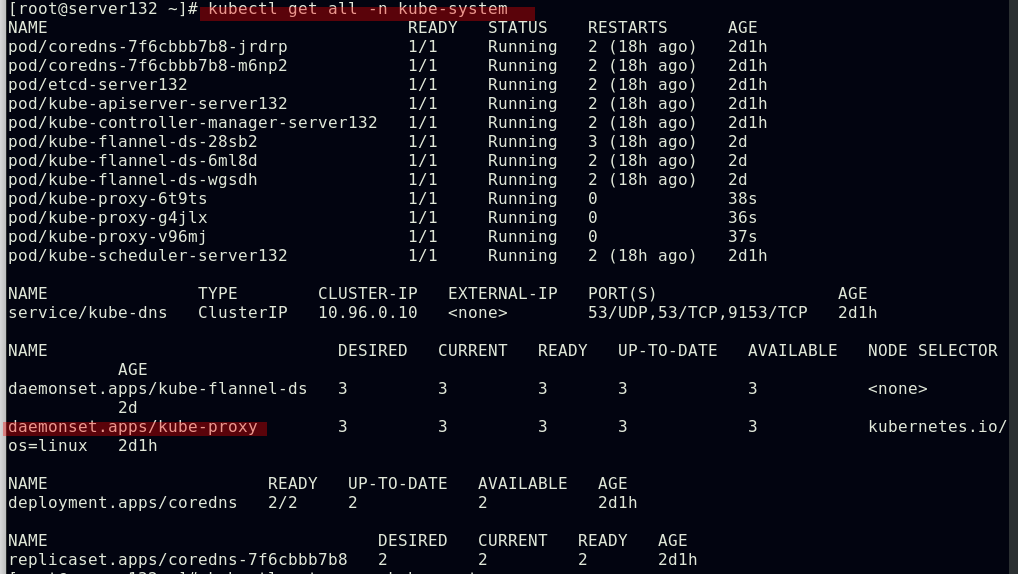

##因kube-system命名空间下存在kube-proxy--pod的daemonset控制器,故上图中删除kube-proxy--pod后会由控制器重新生成pod
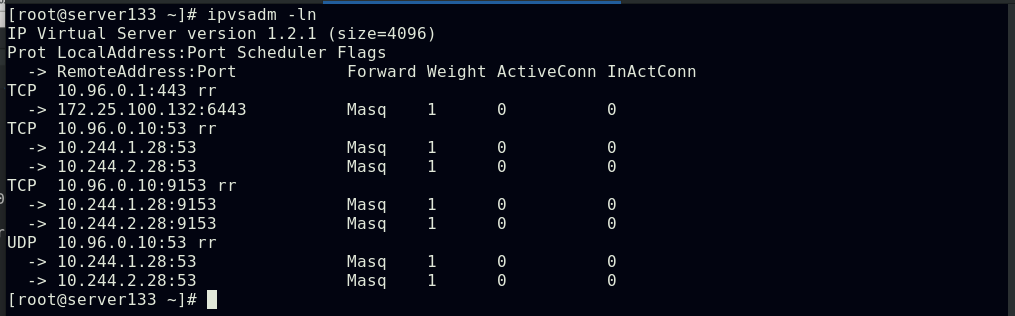
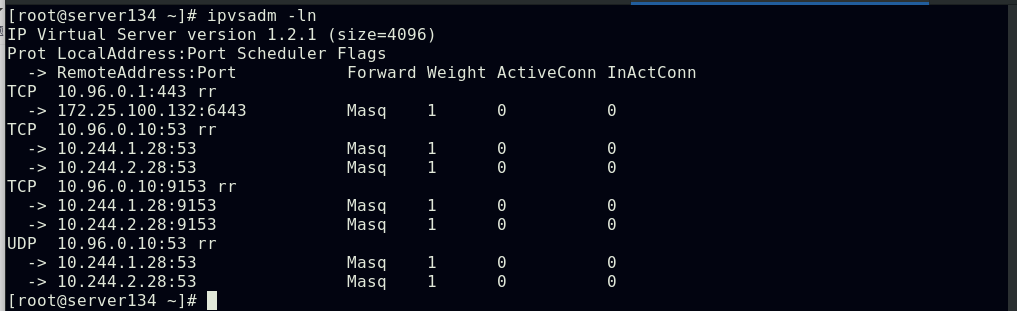
##集群中所有节点都会生成一致的ipvs策略

##IPVS模式下,kube-proxy会在宿主机上添加一个虚拟网卡kube-ipvs0
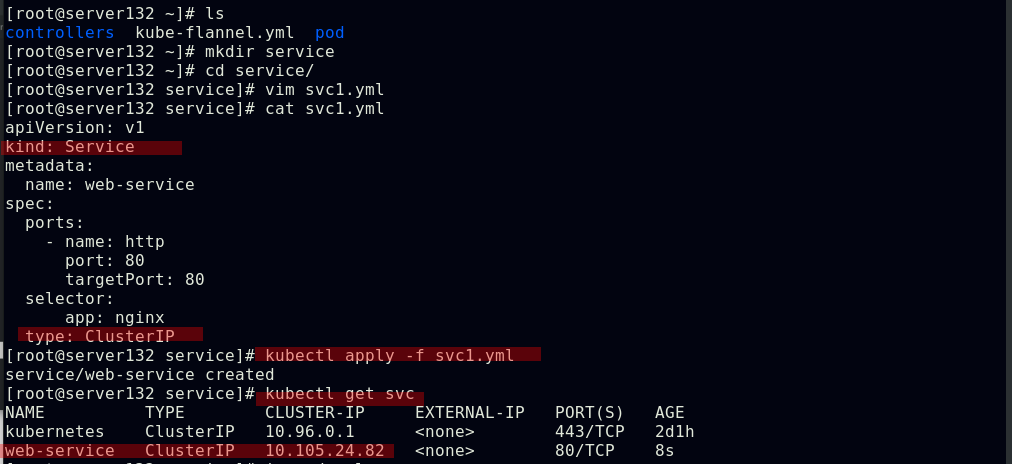
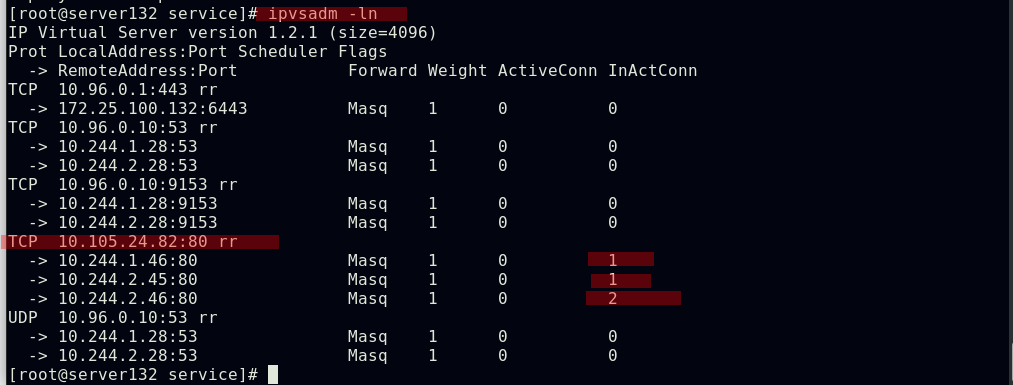
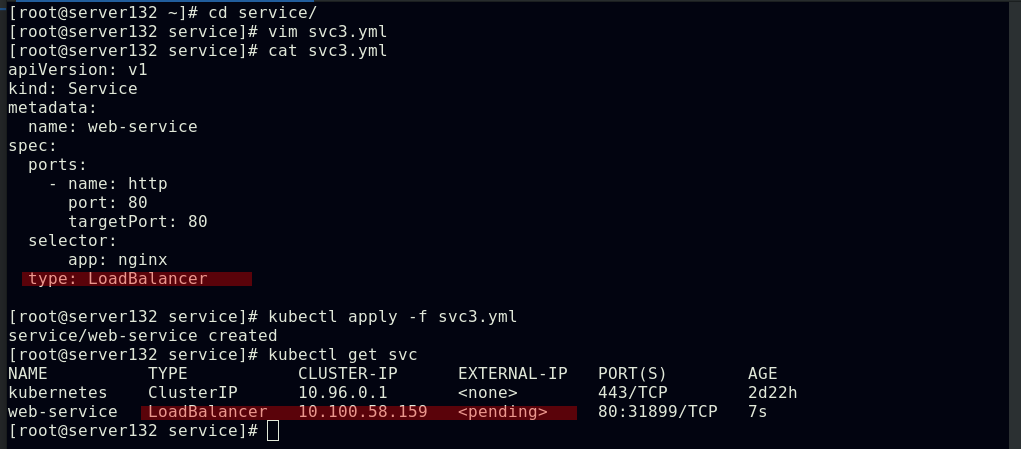
##创建一个名为web-service、类型为ClusterIP的service
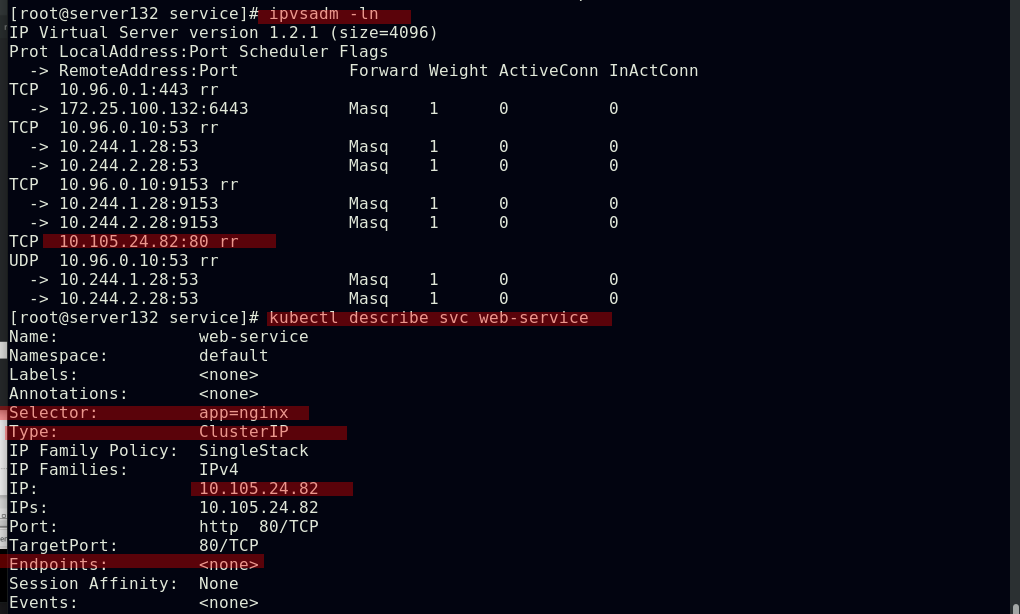
##service创建后会在ipvs中添加相关策略

##service创建后,虚拟网卡kube-ipvs0会为其分配IP
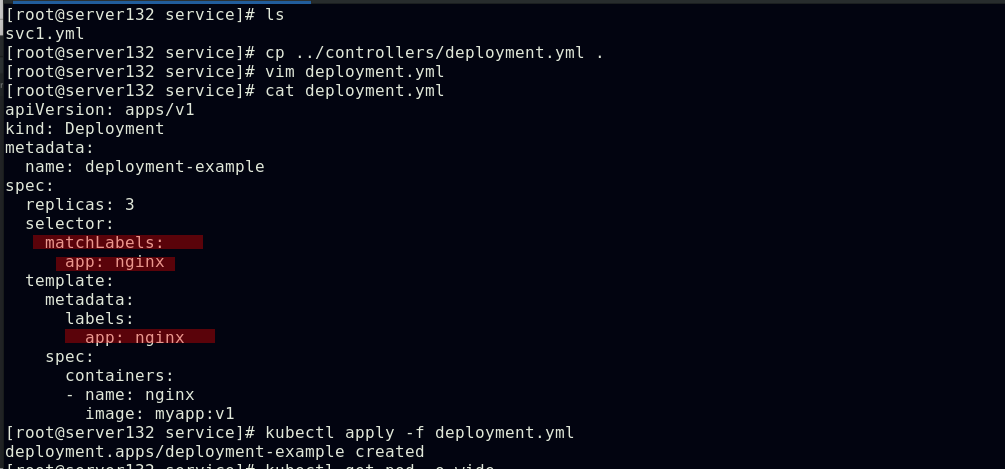
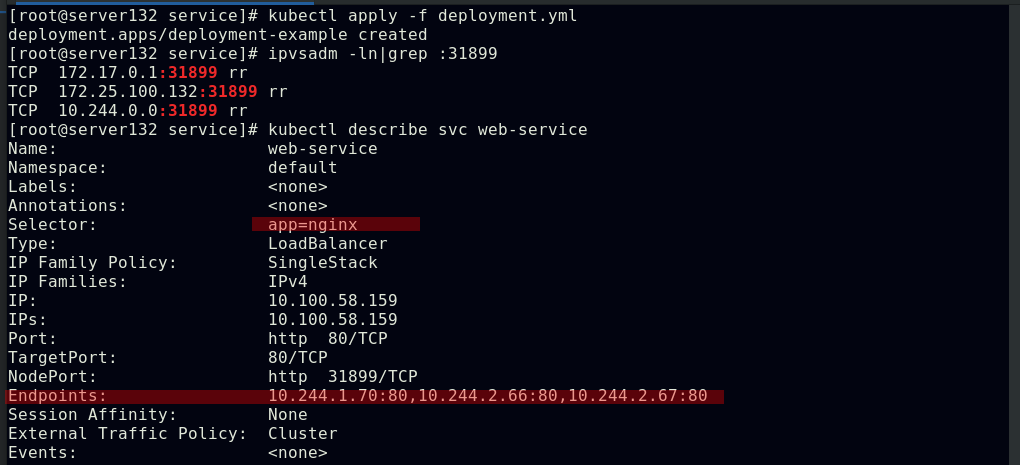
##创建web-service的后端pod
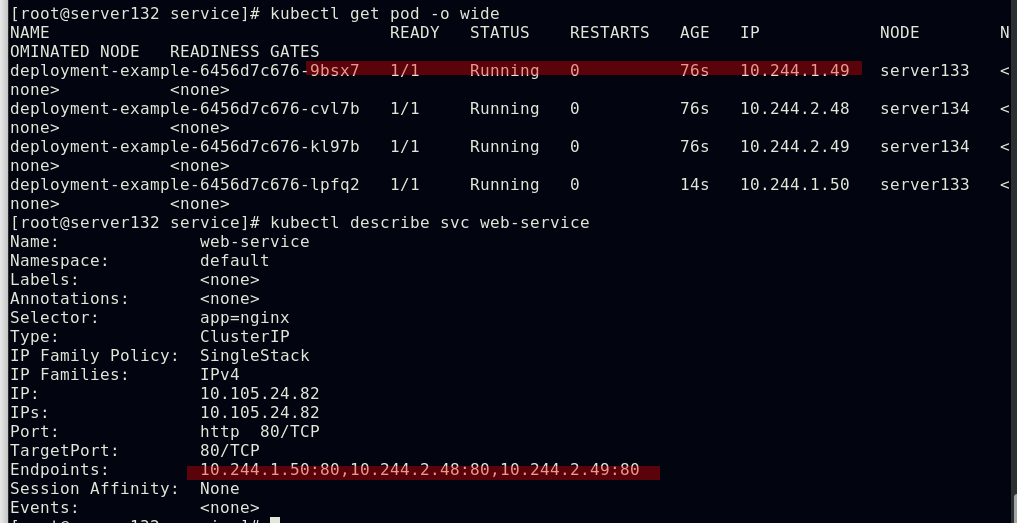
##service通过yml文件中定义的app=nginx这项键值选择器来实现后端pod的自动发现和负载均衡
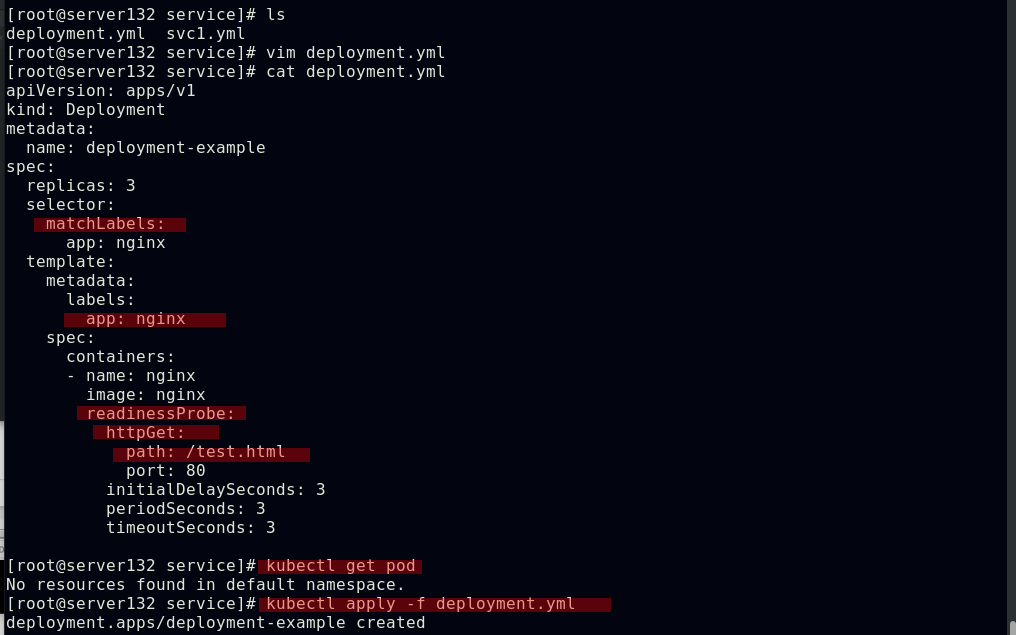
##结合就绪探针创建web-service的后端pod
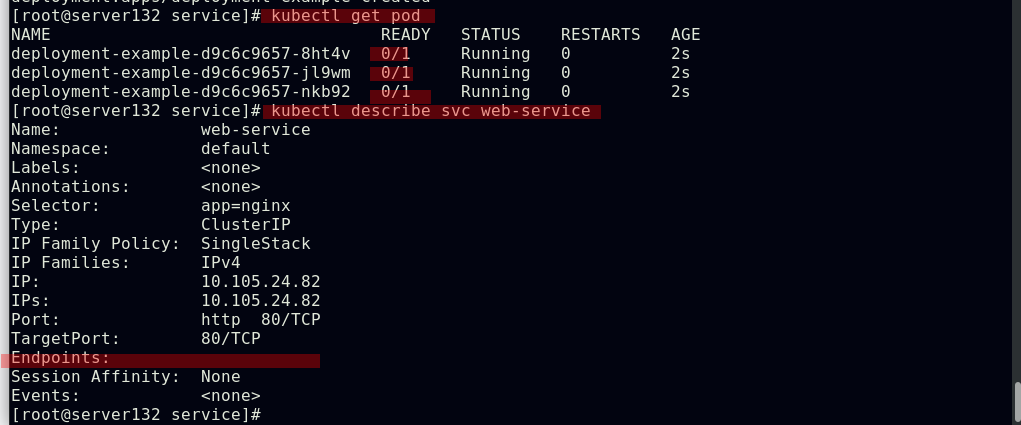
##因就绪探针探测失败,故后端pod即使在运行中也不会被web-service自动发现
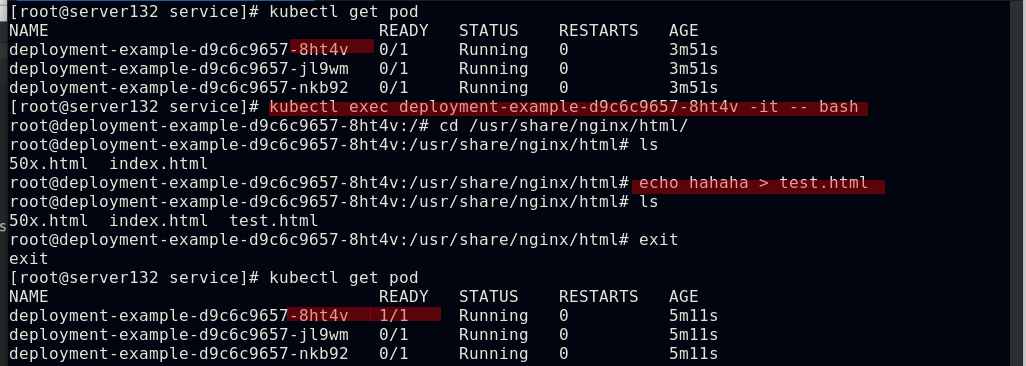
##进入到某个pod副本中创建就绪探针所需的test.html文件,对应的pod副本成功就绪
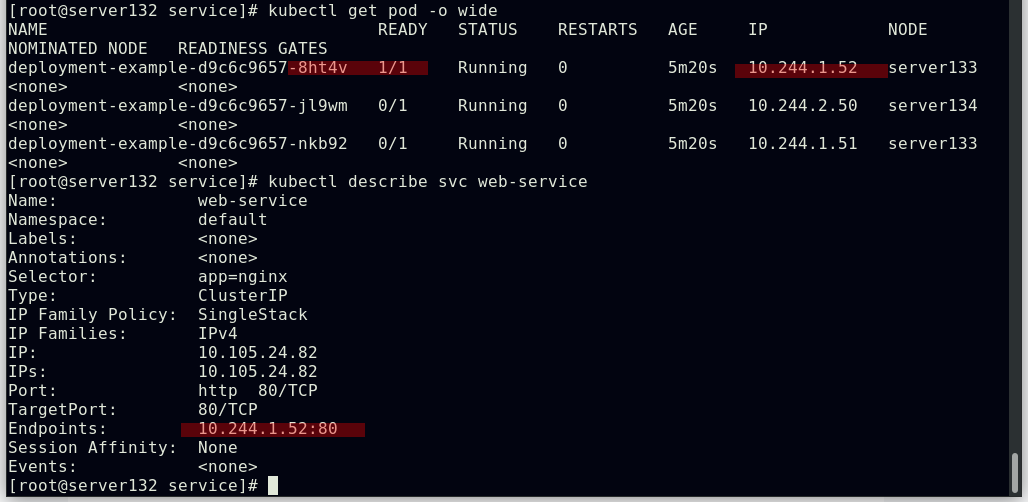
##就绪的pod副本会被自动发现到service的后端中
Headless Service(无头服务):Headless Service不需要分配一个VIP,而是直接以DNS记录的方式解析出被代理Pod的IP地址;域名格式:$(servicename).$(namespace).svc.cluster.local
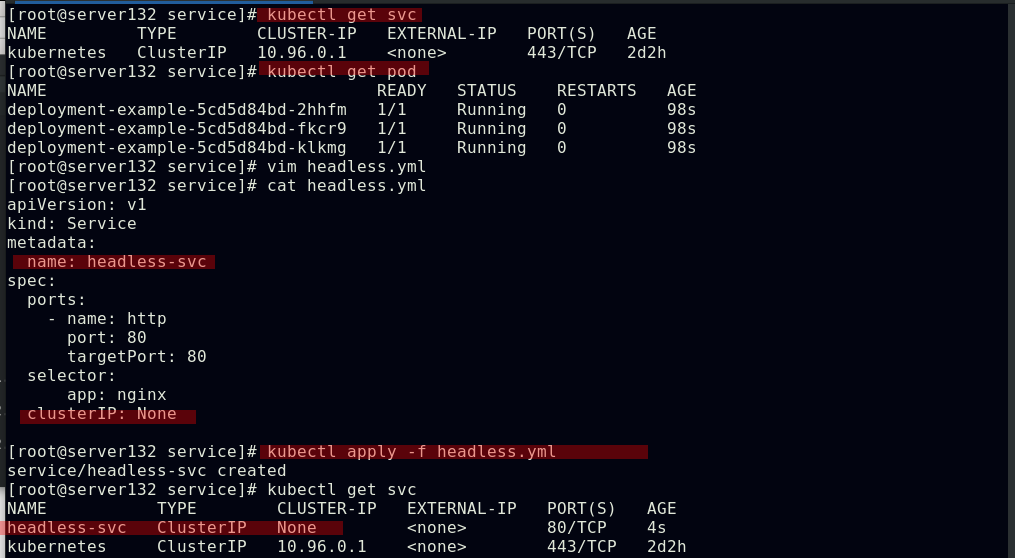

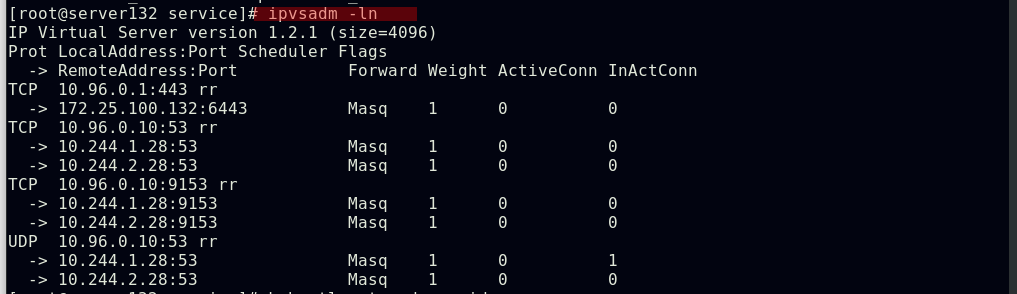
##创建headless-service,此svc未分配VIP,ipvs中也无相关策略

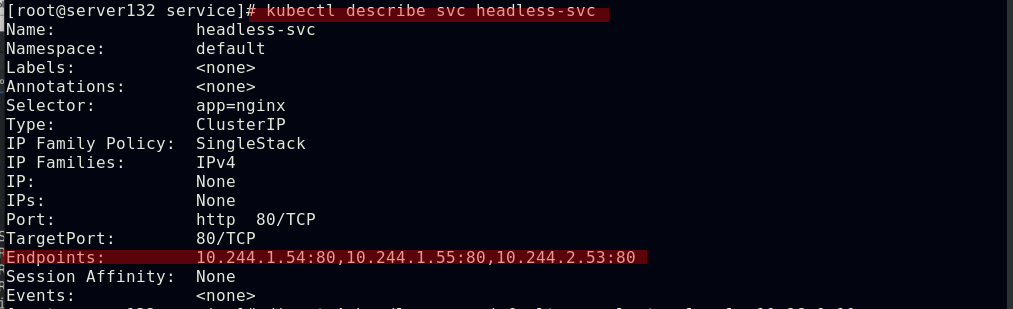
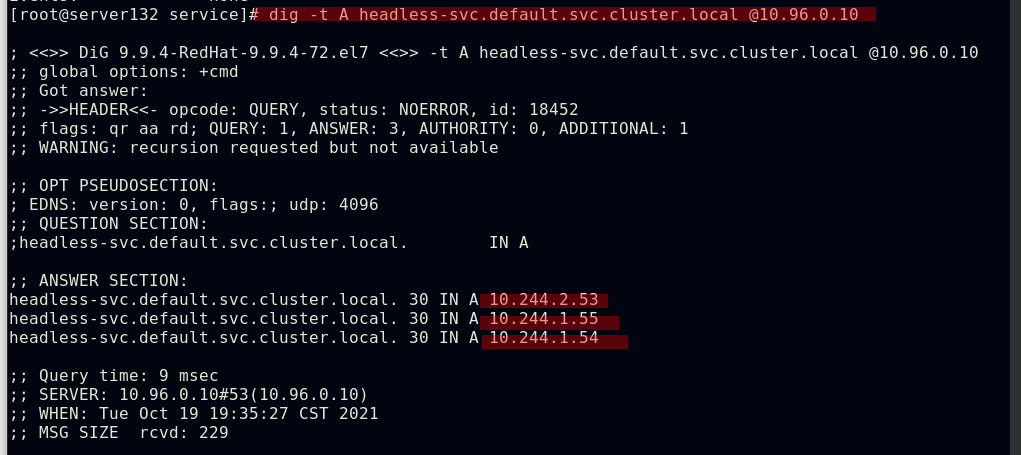
##但是此svc却有后端pod,dig其服务域名可以看到其A记录
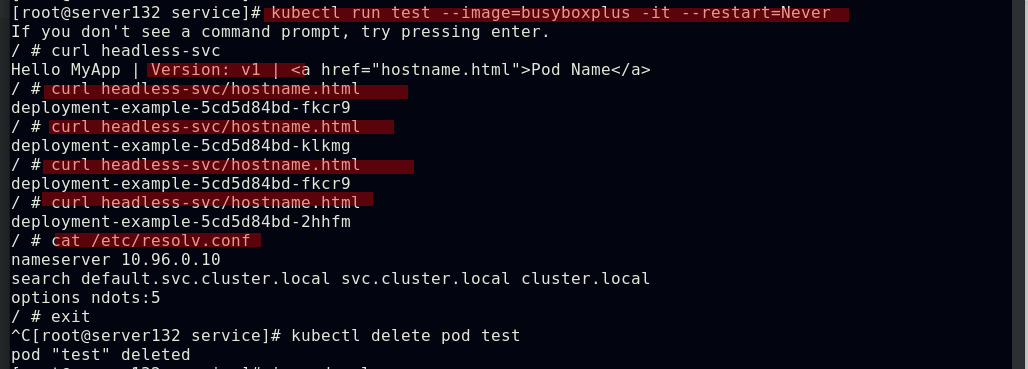
##在容器中访问服务域名,可以得到后端pod中容器的应用且也是负载均衡效果
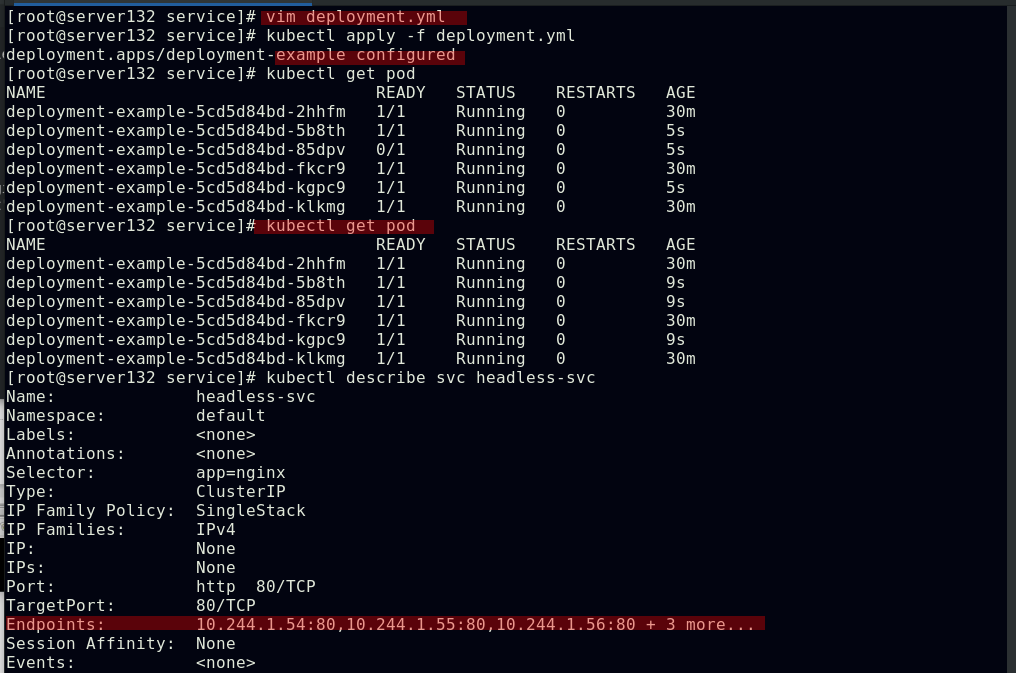
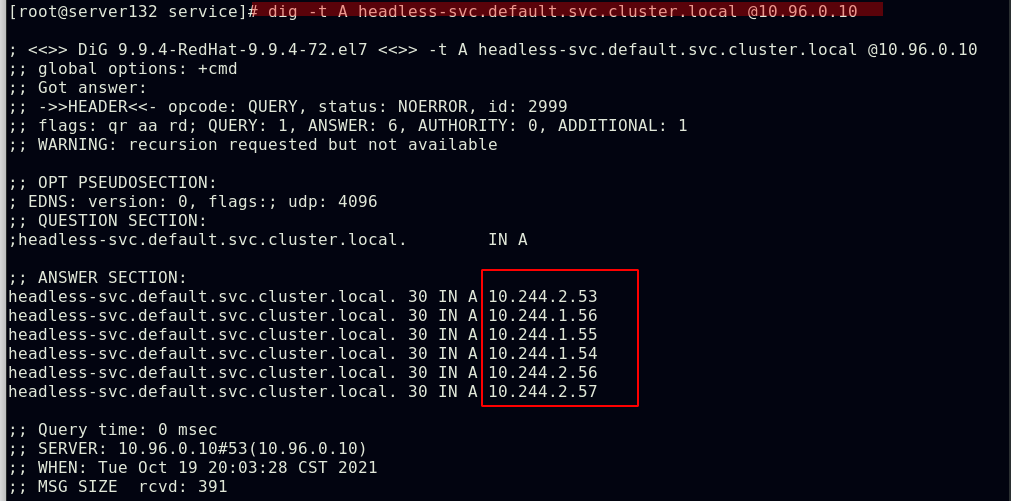
##pod滚动更新后依然可以解析的到
外部访问类型的service
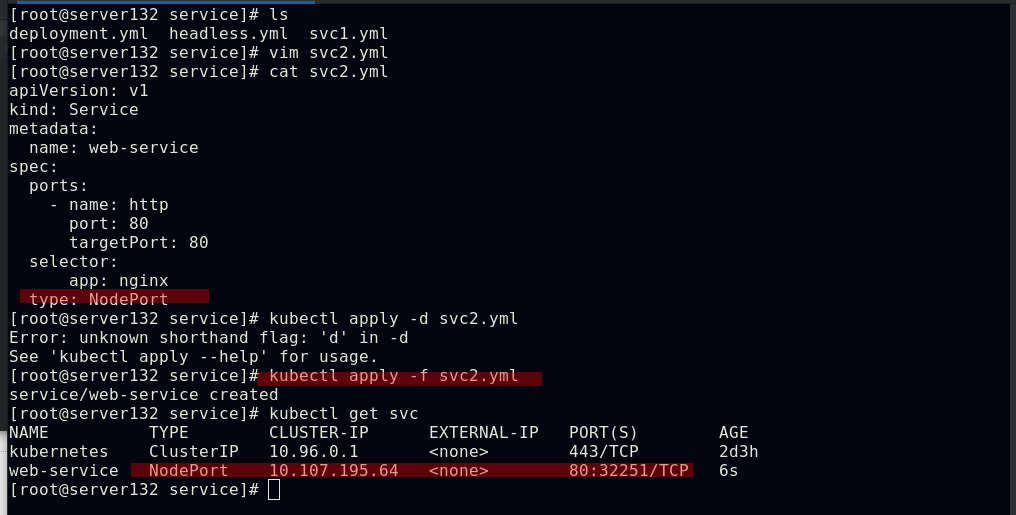
##创建NodePort类型的service
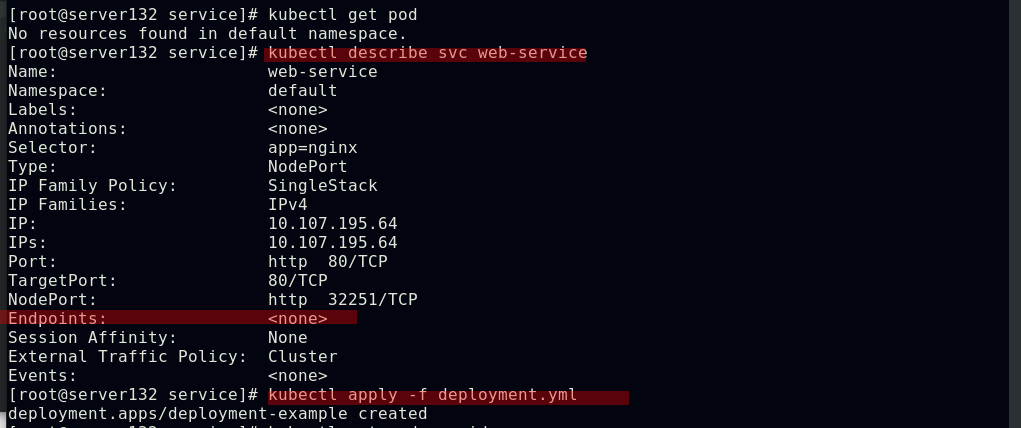
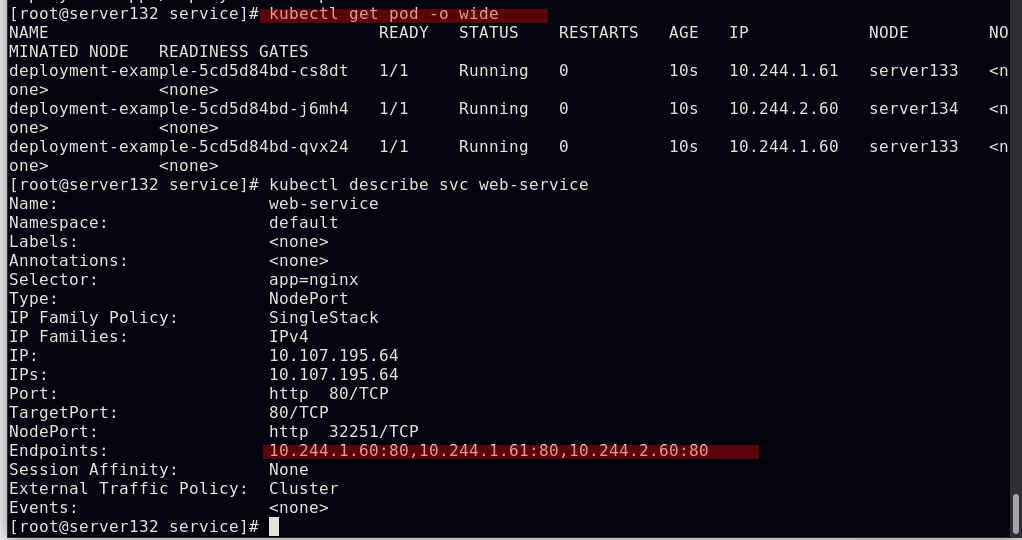
##配置web-service的后端pod
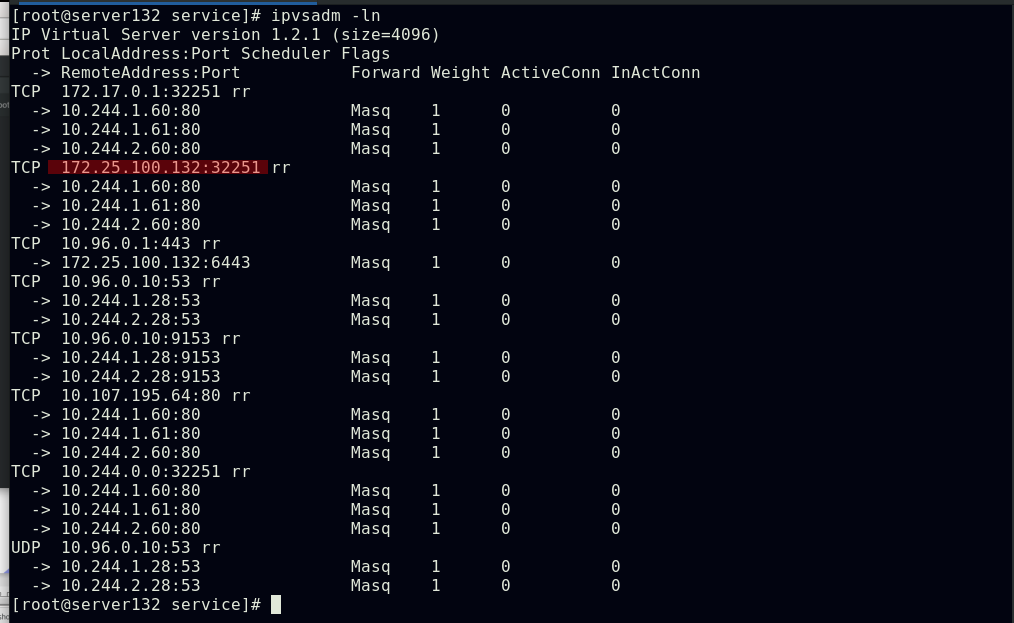
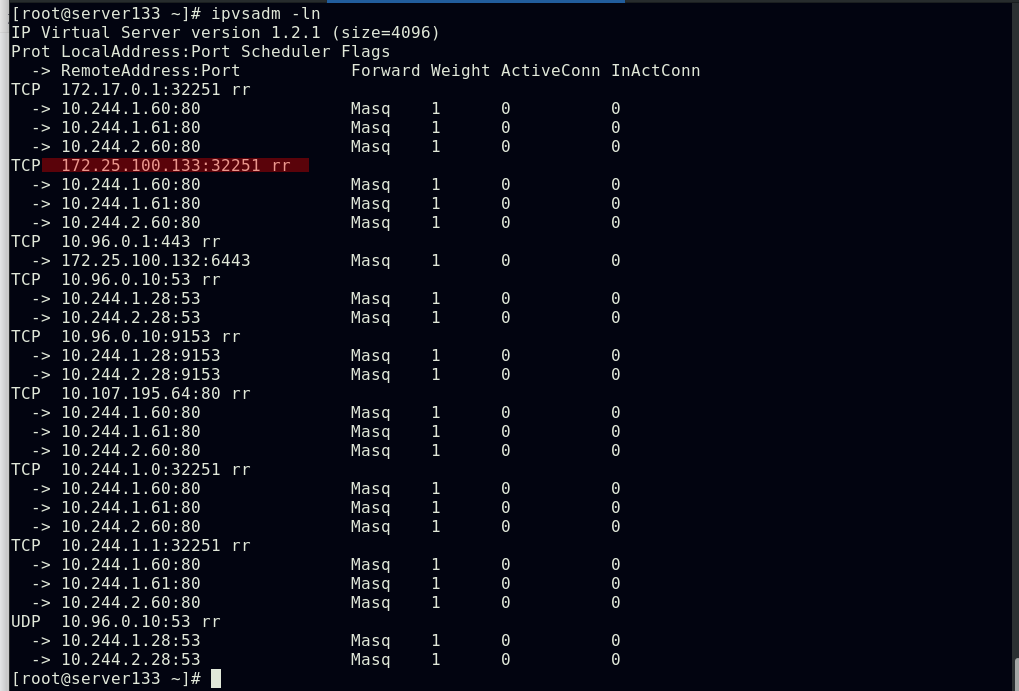
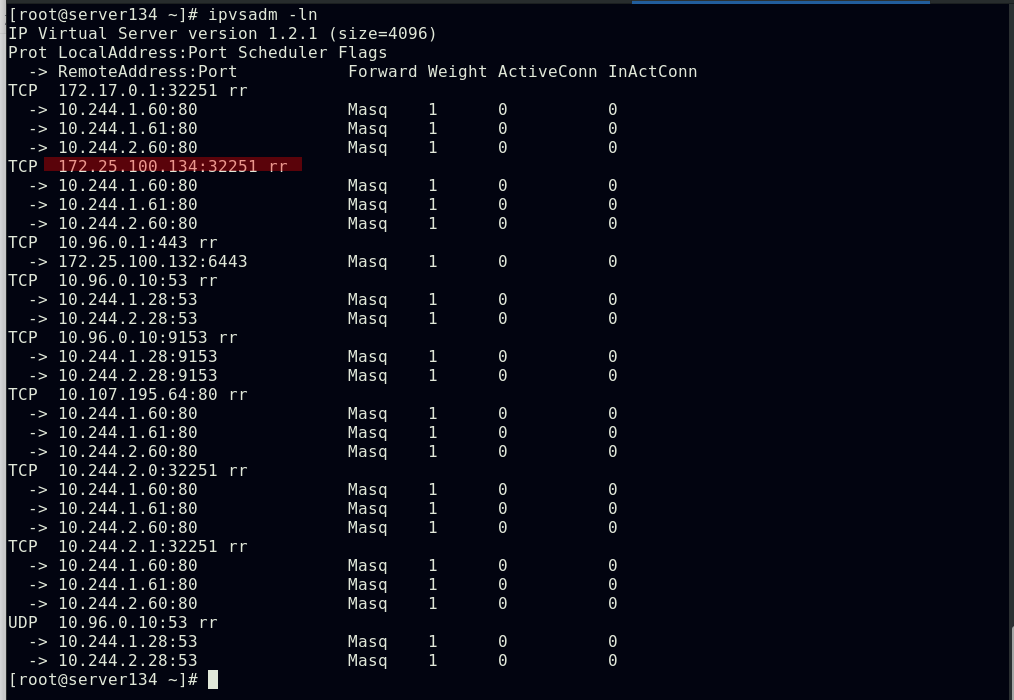
##集群中所有节点会更新对于开放端口的策略

##在集群外部访问,测试效果
##创建LoadBalancer类型的service,此类型适用于公有云上的Kubernetes服务;在service提交后,Kubernetes就会调用CloudProvider在公有云上创建一个负载均衡服务,并且把被代理的Pod 的IP地址配置给负载均衡服务做为后端
Kubernetes没有为裸机群集提供网络负载均衡器(类型为LoadBalancer的服务)的实现,如果你的kubernetes集群没有在公有云的IaaS平台(GCP,AWS,Azure …)上运行,则LoadBalancers将在创建时无限期地保持“挂起”状态,也就是说只有公有云厂商自家的kubernetes支持LoadBalancer
MetalLB旨在通过提供与标准网络设备集成的网络LB实现来纠正这种不平衡,以便裸机集群上的外部服务也“尽可能”地工作,即MetalLB能够帮助你在kubernetes中创建LoadBalancer类型的kubernetes服务
Metallb基本原理
Metallb会在Kubernetes内运行,监控服务对象的变化,一旦察觉有新的LoadBalancer服务运行,并且没有可申请的负载均衡器之后,就会完成两部分工作:
1.地址分配
用户需要在配置中提供一个地址池,Metallb将会在其中选取地址分配给服务
2.地址广播
根据不同配置,Metallb会以二层(ARP/NDP)或者BGP的方式进行地址的广播
Metallb官网:
MetalLB, bare metal load-balancer for Kubernetes https://metallb.universe.tf/安装MetalLB v0.10.3
https://metallb.universe.tf/安装MetalLB v0.10.3



##配置kube-proxy的ipvs模式下的strictARP功能

##准备资源文件,并在其中配置IP地址池
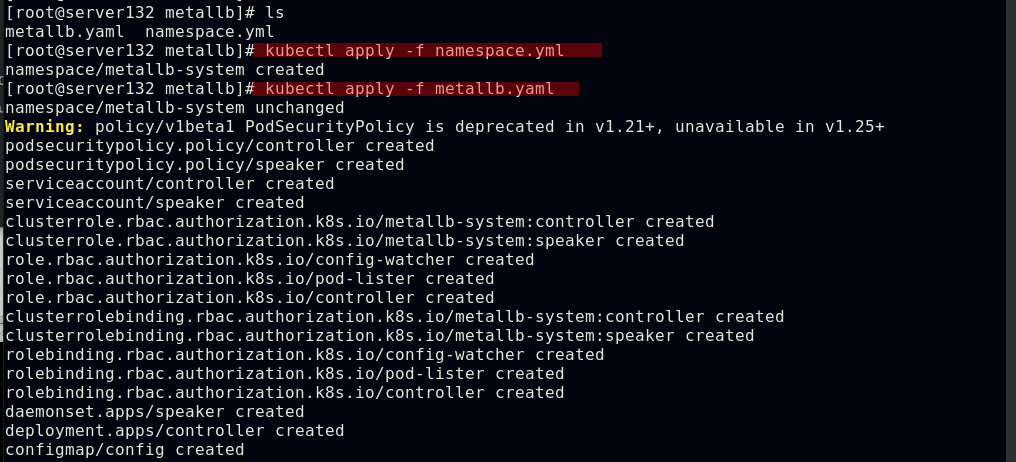

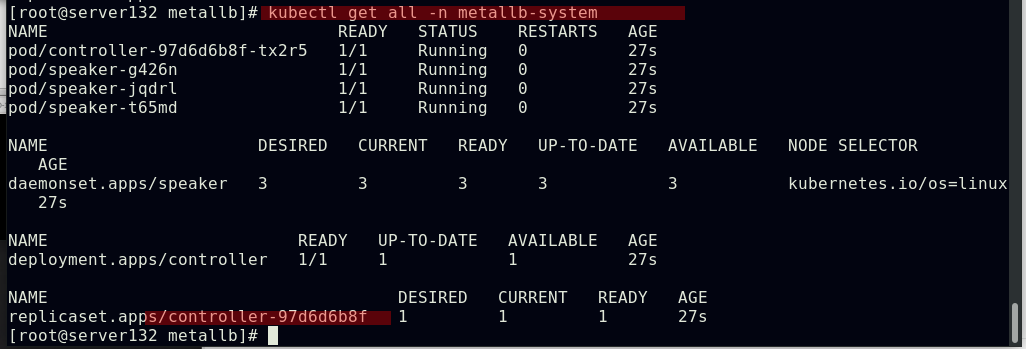
##应用资源文件,创建命名空间和其下的资源对象
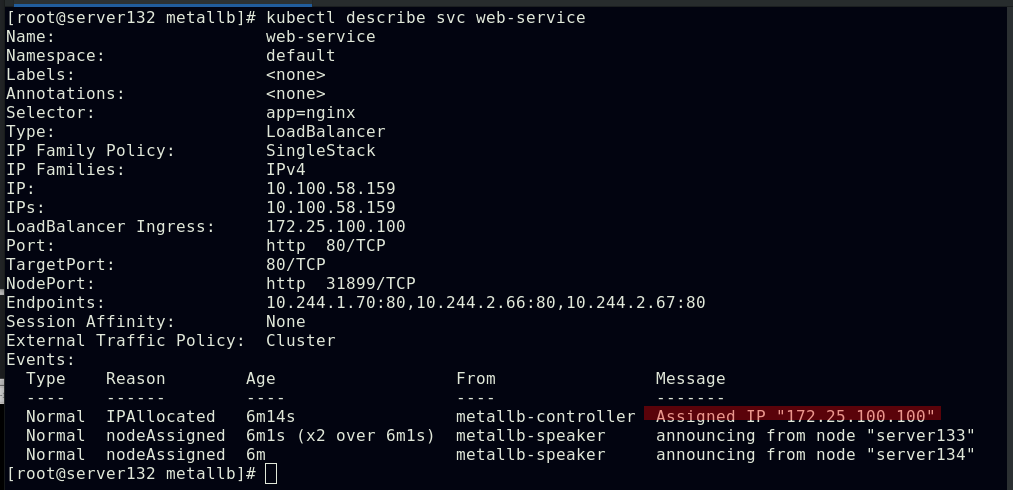

##上述创建完成后,对应LoadBalancer类型的service会分配到一个外部IP
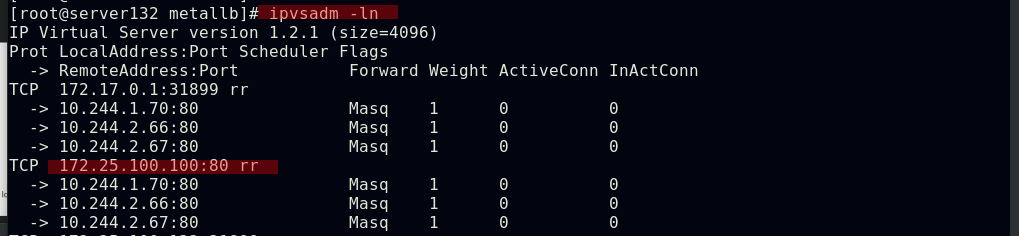
##ipvs中也会添加此IP的相关策略


##此时从外部主机访问此IP时即可访问到集群内的pod,并且是负载均衡效果


##外部主机的ARP表会获取到集群中某个节点的MAC地址
从外部访问的第三种方式叫做ExternalName

##创建命名空间webcluster
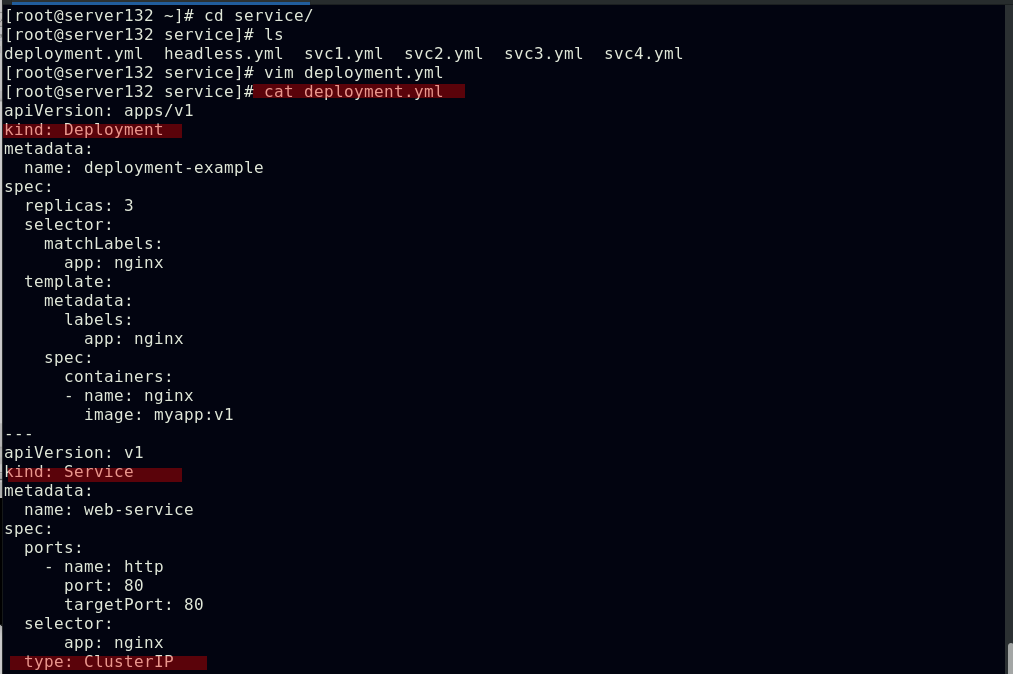
##创建控制器与service结合的资源文件
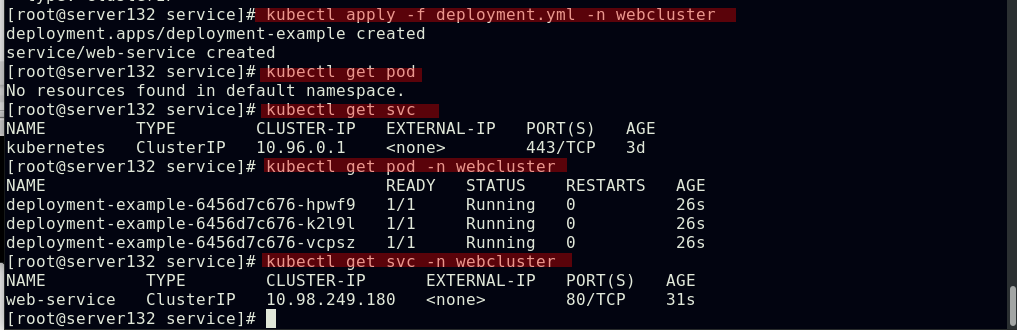
##在webcluster命名空间下应用此资源文件
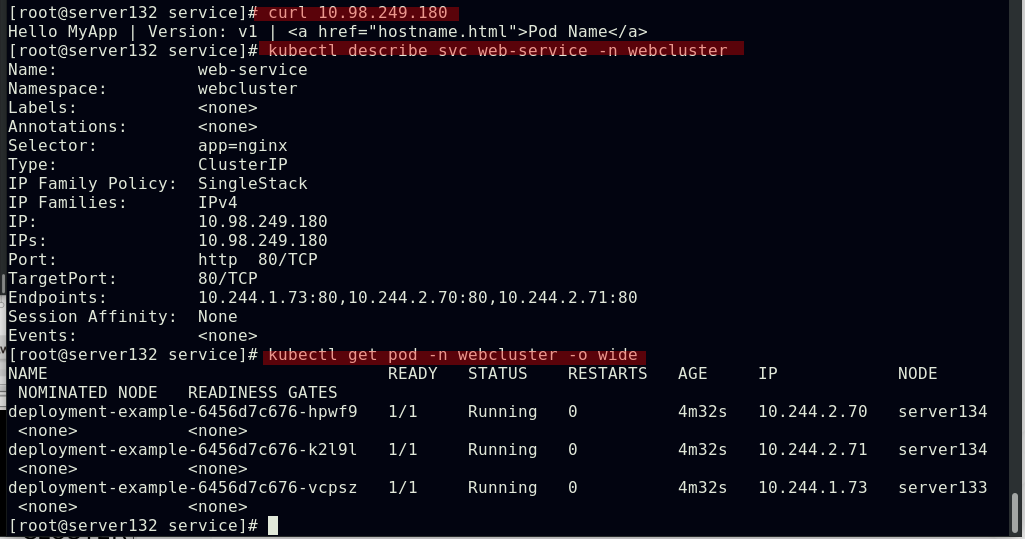
##webcluster命名空间下的service可以在default命名空间下访问到
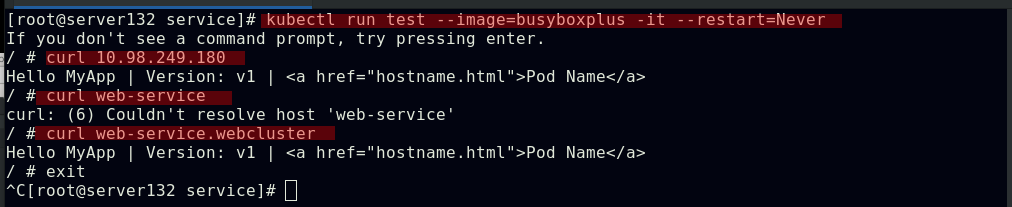
##在默认命名空间下的pod无法通过服务域名访问到非默认命名空间下的服务,需要加上该服务的命名空间
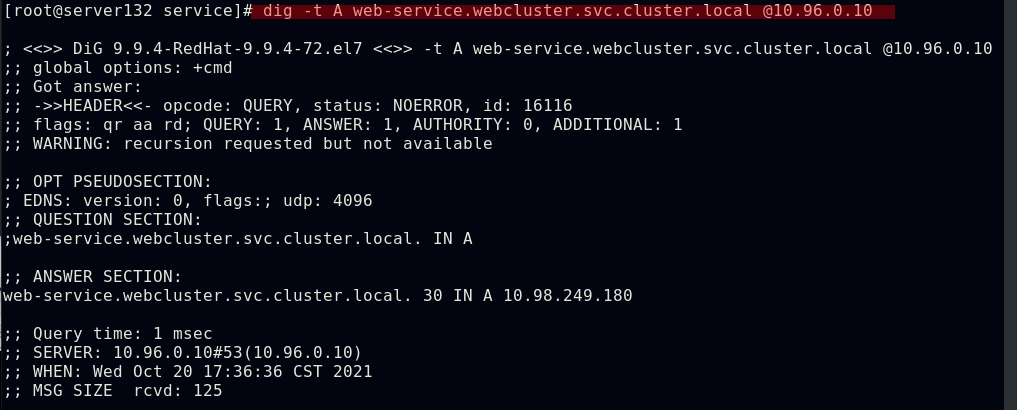
##在默认命名空间下可以解析到webcluster命名空间下的web-service
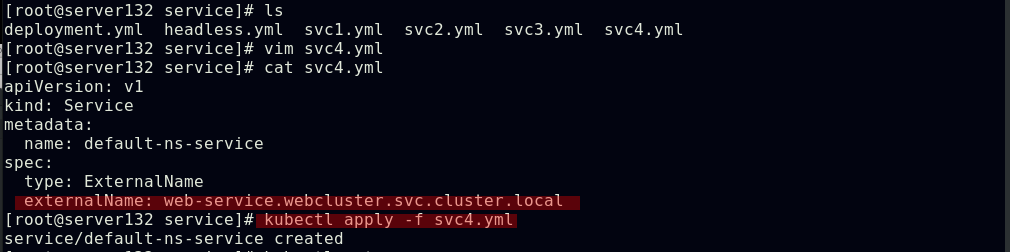
##在默认命名空间下创建服务default-ns-service,并让其与cluster命名空间下的web-service服务通过externalName做个映射
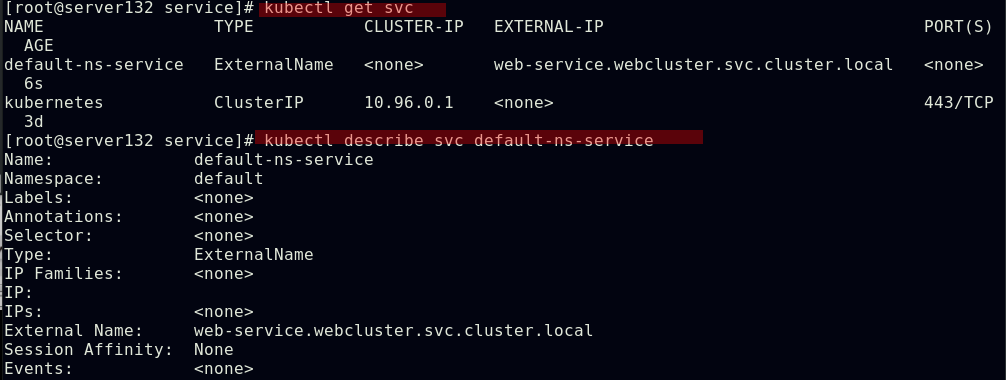
##此服务没有后端
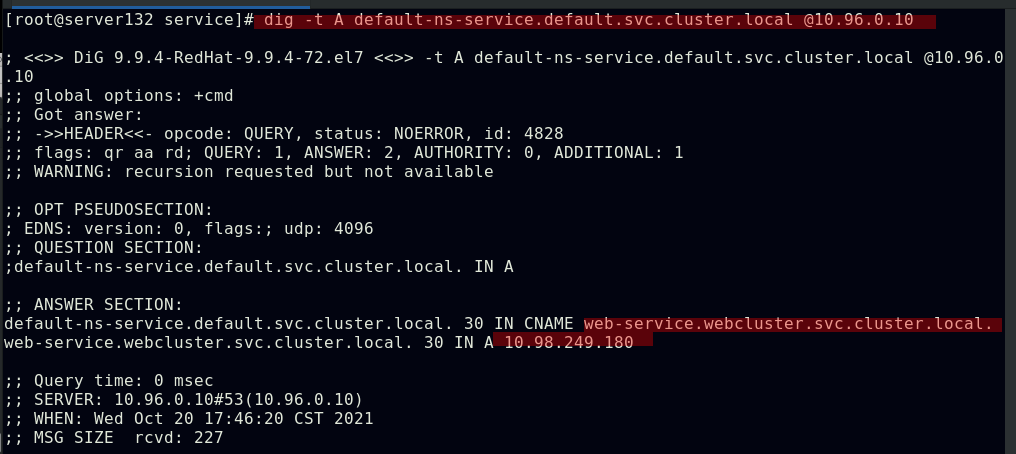
##解析default-ns-service时得到了webcluster命名空间下的web-service服务和其集群IP
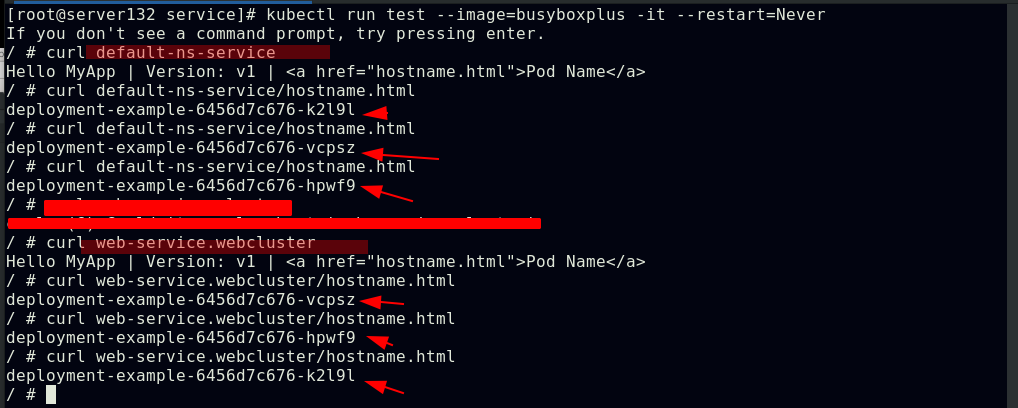
##在默认命名空间下运行pod,访问default-ns-service时得到的结果则是cluster命名空间下的web-service的负载均衡效果
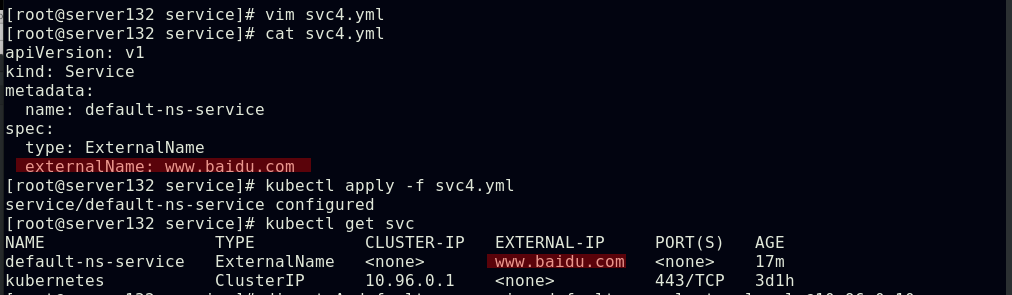
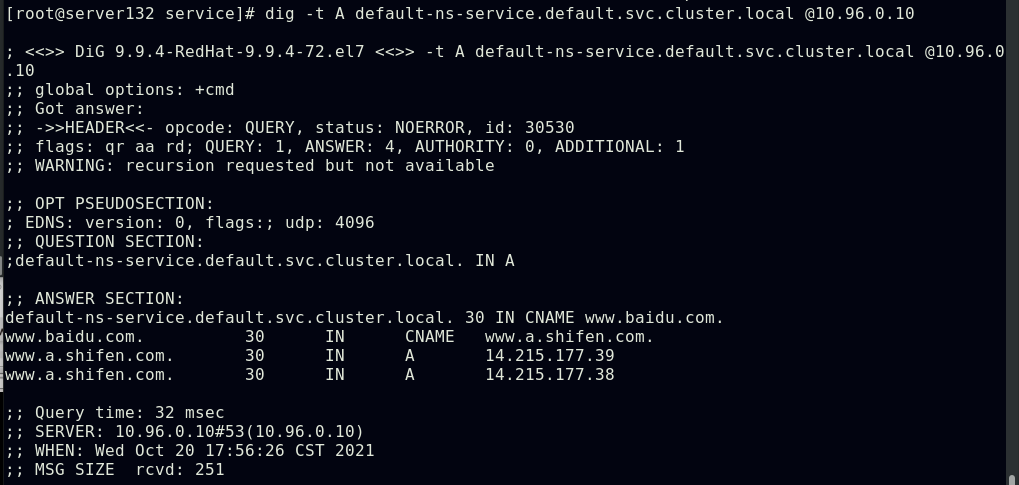
##将default-ns-service与百度做映射
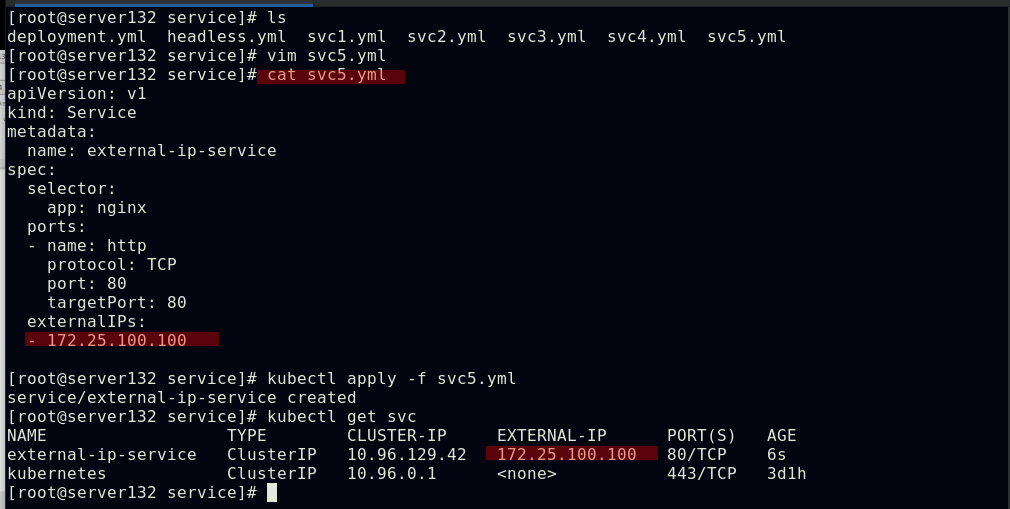
##创建service,并为其分配公有IP
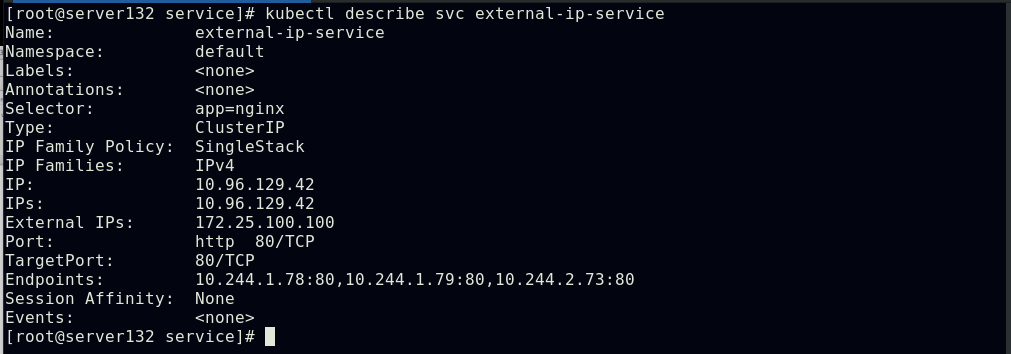

##但此时此IP在集群外部是无法访问的,集群内部可以
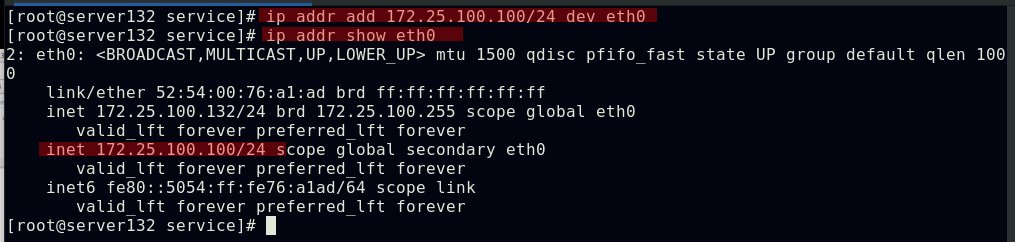

##在集群任一节点添加此IP后,即可从外部访问的到;此时外部主机获取到的此IP的mac地址即为集群中添加了此IP主机的mac地址
Ingress
kubernetes官网对于Ingress的介绍:
Ingress | KubernetesFEATURE STATE: Kubernetes v1.19 [stable] An API object that manages external access to the services in a cluster, typically HTTP. aka: tags: - networking - architecture - extension --- -- Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。术语 为了表达更加清晰,本指南定义了以下术语:服务(Service) that identifies a set of Pods using label selectors. Unless mentioned otherwise, Services are assumed to have virtual IPs only routable within the cluster network. -- 节点(Node): Kubernetes 集群中其中一台工作机器,是集群的一部分。 集群(Cluster): 一组运行由 Kubernetes 管理的容器化应用程序的节点。 在此示例和在大多数常见的 Kubernetes 部署环境中,集群中的节点都不在公共网络中。 边缘路由器(Edge router): 在集群中强制执行防火墙策略的路由器(router)。 可以是由云提供商管理的网关,也可以是物理硬件。 集群网络(Cluster network): 一组逻辑的或物理的连接,根据 Kubernetes 网络模型 在集群内实现通信。 服务(Service):Kubernetes 服务使用 标签选择算符(selectors)标识的一组 Pod。 除非另有说明,否则假定服务只具有在集群网络中可路由的虚拟 IP。 services within the cluster.https://kubernetes.io/zh/docs/concepts/services-networking/ingress/Kubernetes里的Ingress服务是一种全局的、为了代理不同后端Service而设置的负载均衡服务,由两部分组成:Ingress controller和Ingress服务
Ingress Controller会根据你定义的Ingress对象,提供对应的代理能力;业界常用的各种反向代理项目,比如Nginx、HAProxy、Envoy、Traefik等,都已经为Kubernetes专门维护了对应的Ingress Controller
部署Ingress-nginx控制器,准备资源文件(见以下链接)
Installation Guide - NGINX Ingress Controllerhttps://kubernetes.github.io/ingress-nginx/deploy/
准备所需镜像
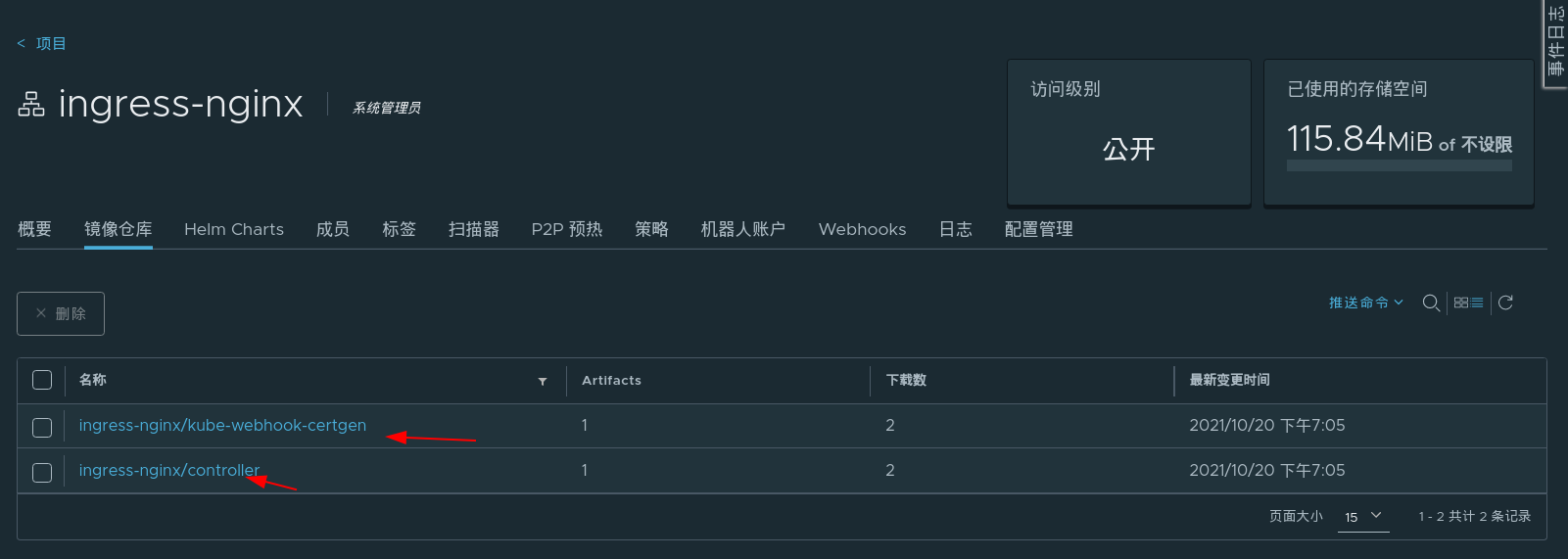
更改资源文件中的镜像指向



应用资源文件,会创建ingree-nginx命名空间下的三个pod和两个服务
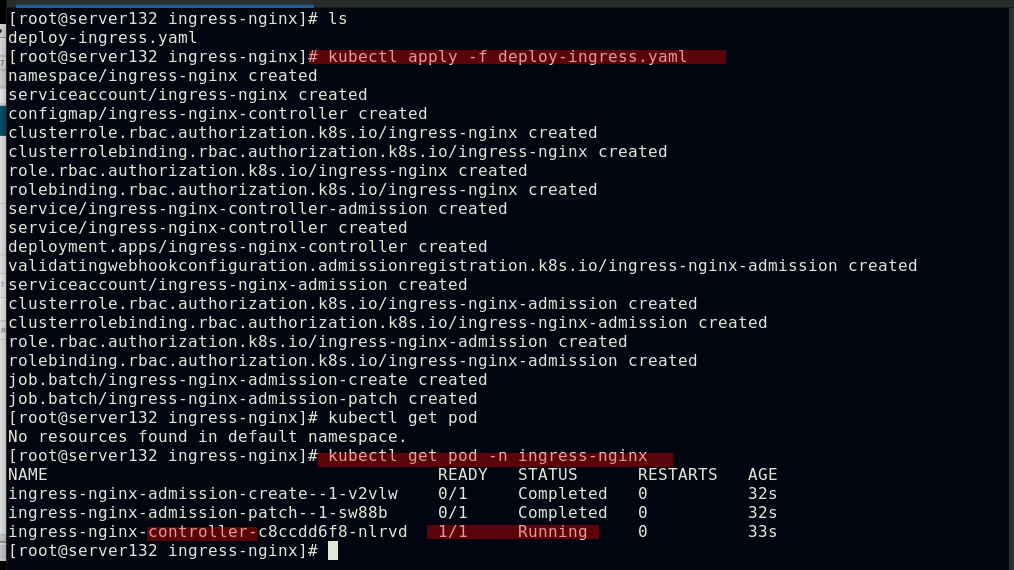

此时在集群外部通过NodeIP:NodePort访问是404状态

因为此时访问到的是资源文件中创建的ingress-nginx-controller服务,其对应的服务在集群内部访问时也是404状态
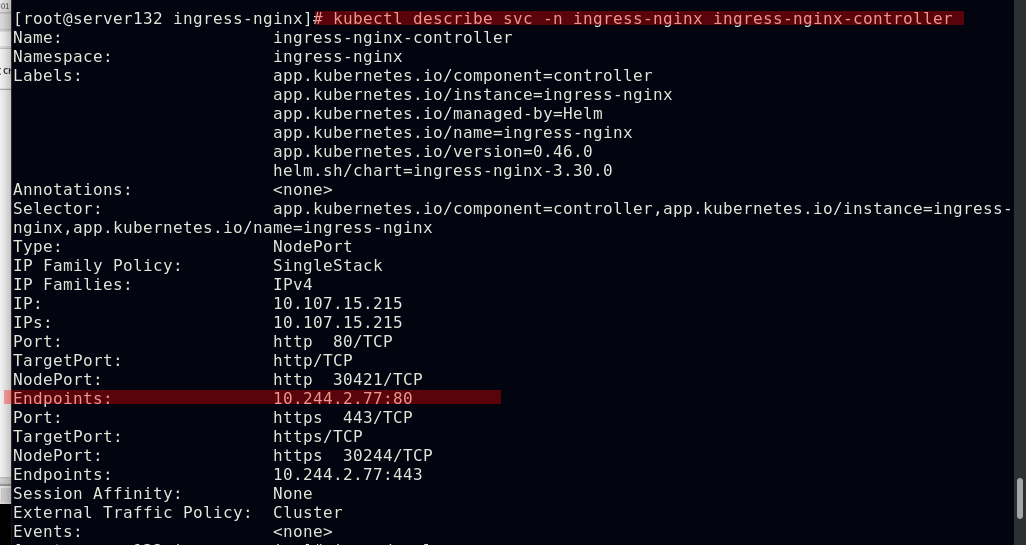
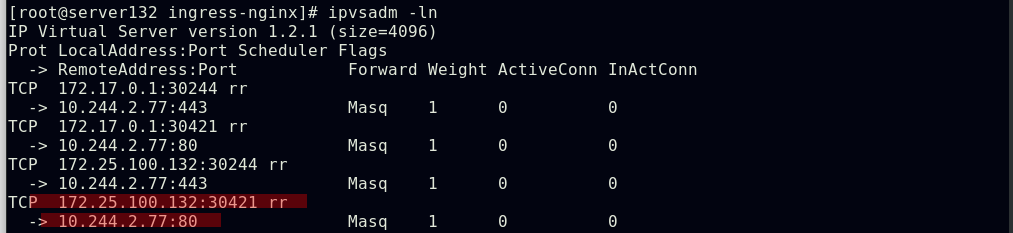

配置ingress的访问资源和后端pod
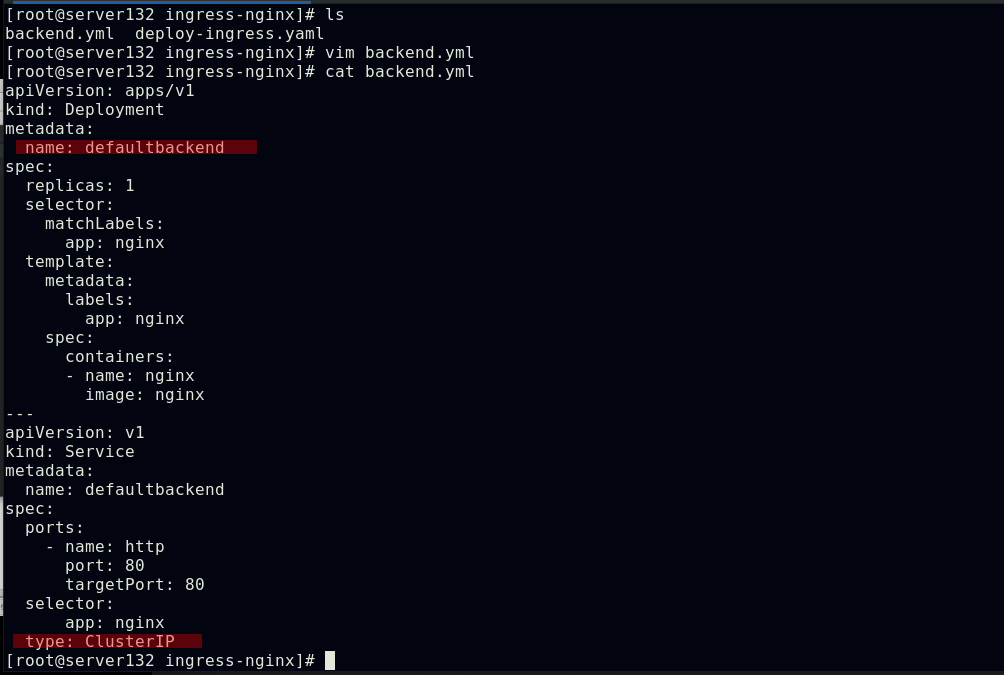
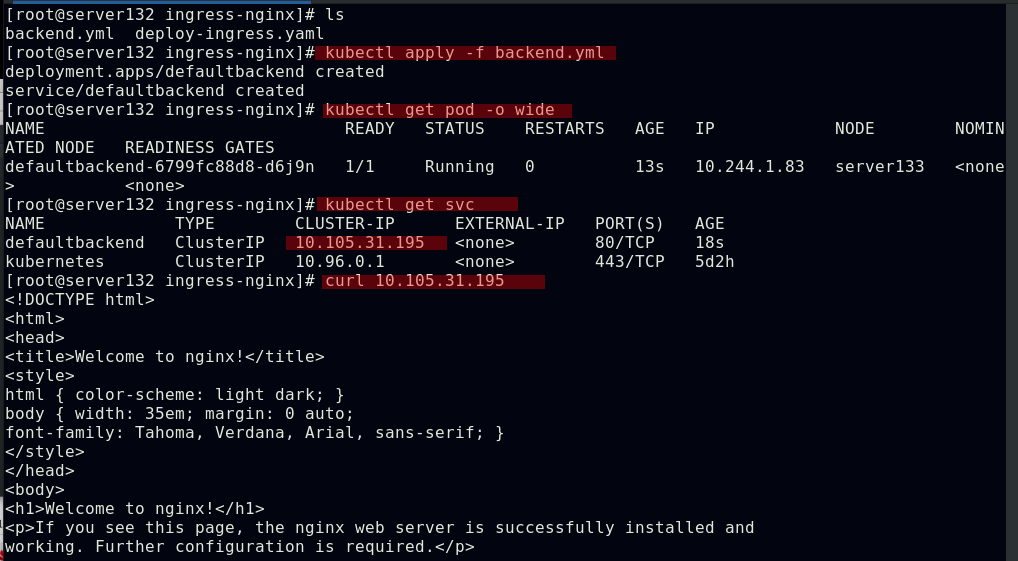

##创建新的服务和后端pod后集群外部仍然无法访问
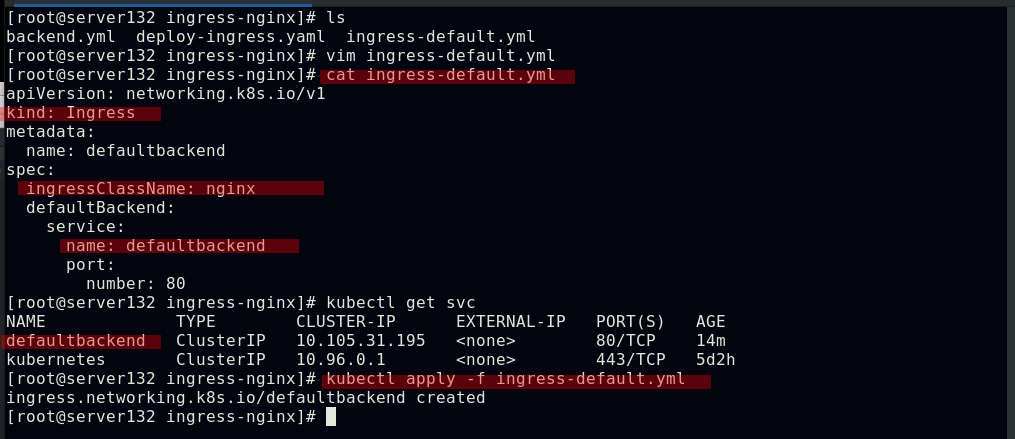
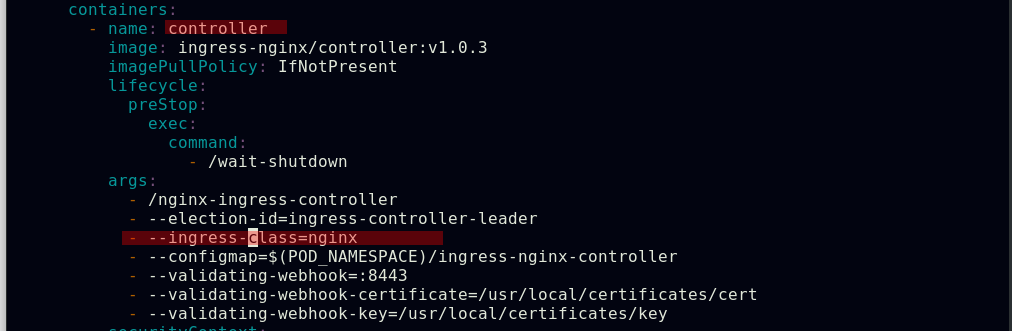
##编写ingress资源文件,配置我们自主创建的服务作为ingress的默认后端,此处文件中的默认后端服务名称需要和创建的服务名称相对应;ingress类名称需要和初始ingress-nginx资源文件中的类名称对应
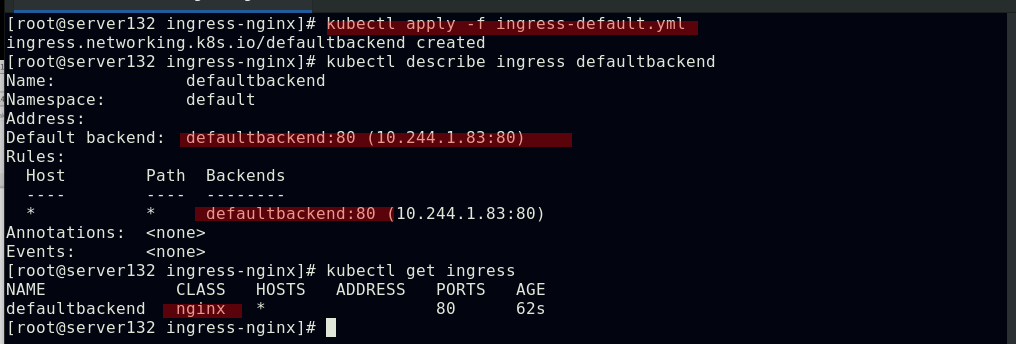
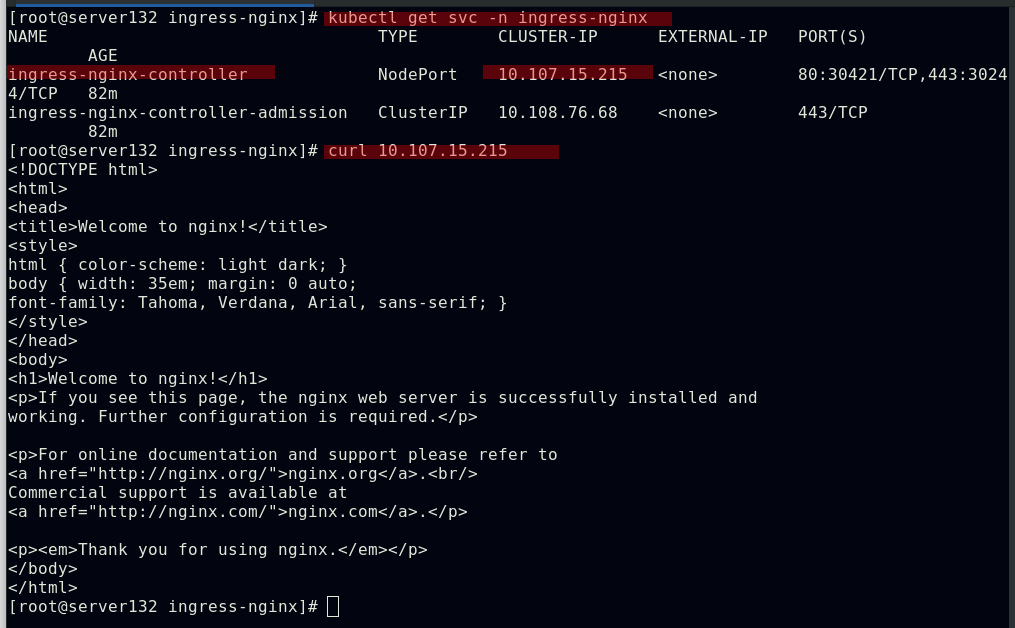
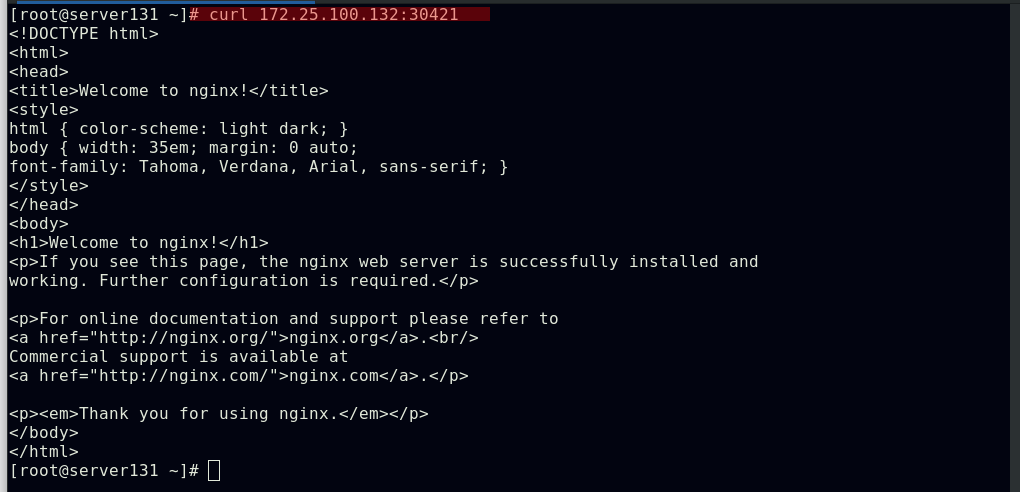
##应用资源文件后,我们创建的服务和后端将作为ingress的默认服务和后端,此时集群外部及可通过NodeIP:NodePort访问到集群的ingress服务
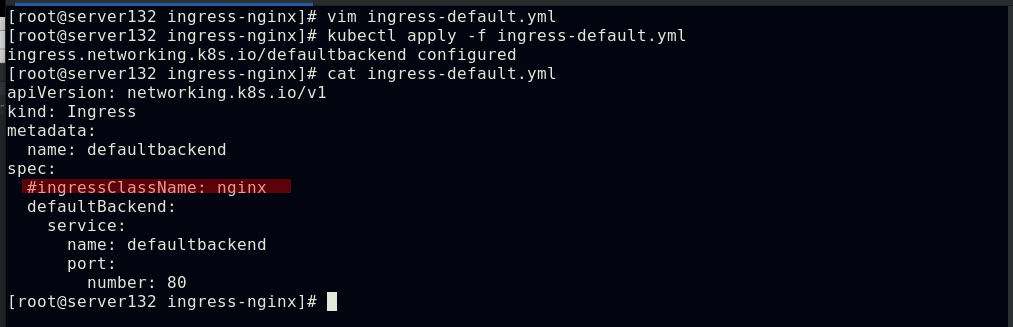

##在ingress资源文件中注释掉ingress类型名称后外部主机又无法访问
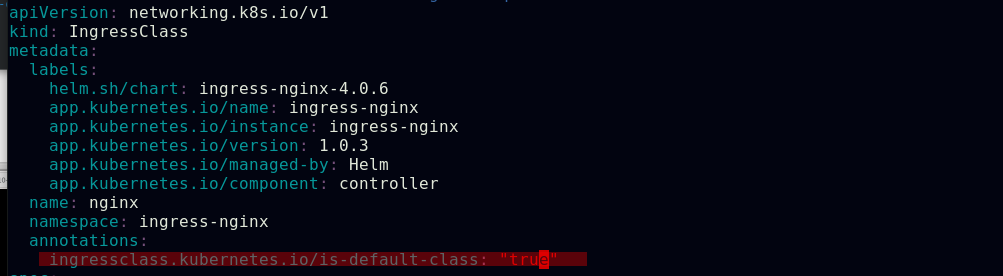
##可以在ingress-nginx清单文件中的ingressclass资源下添加注释,此注释会确保新的未指定ingress类的ingress资源能够被分配为这个默认的ingress类
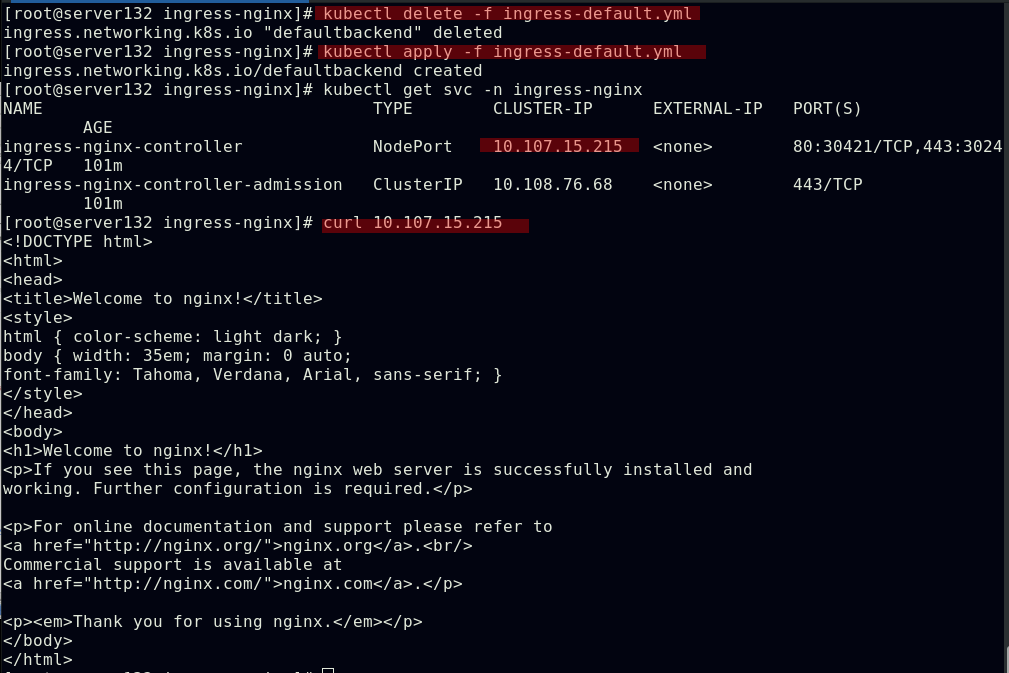
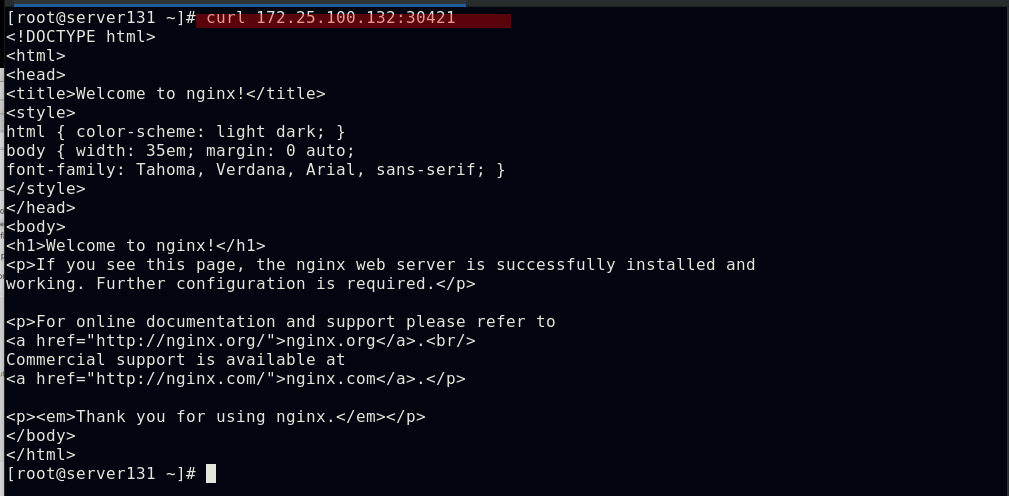

##此时集群内外都可以访问的到,未指定ingress类型的ingress资源被分配到默认的ingress资源类型
ingress实现基于名称的虚拟托管:基于名称的虚拟主机支持将针对多个主机名的HTTP流量路由到同一IP地址上
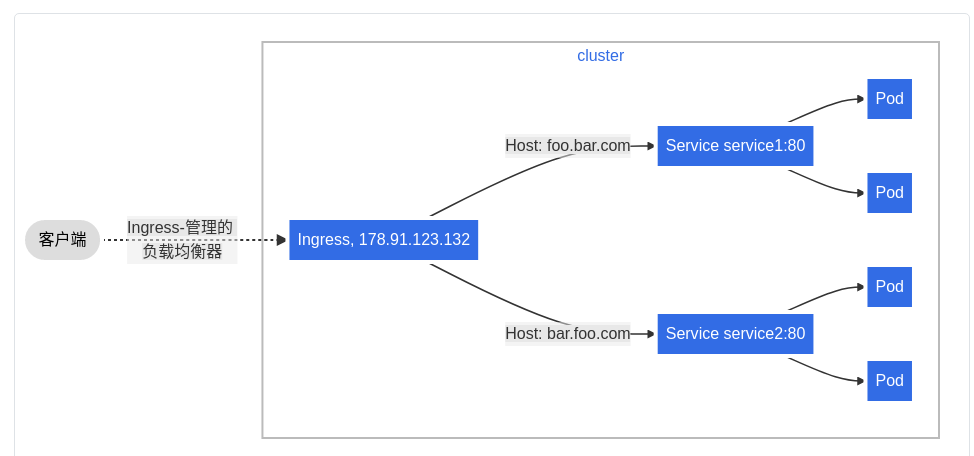
配置虚拟主机的ingress资源文件
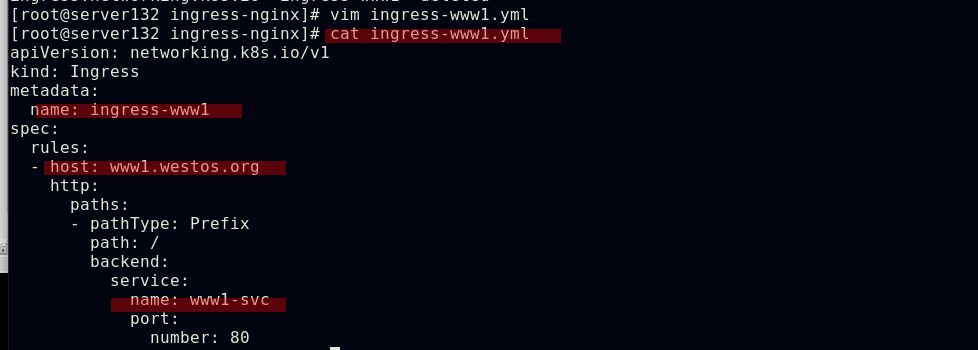
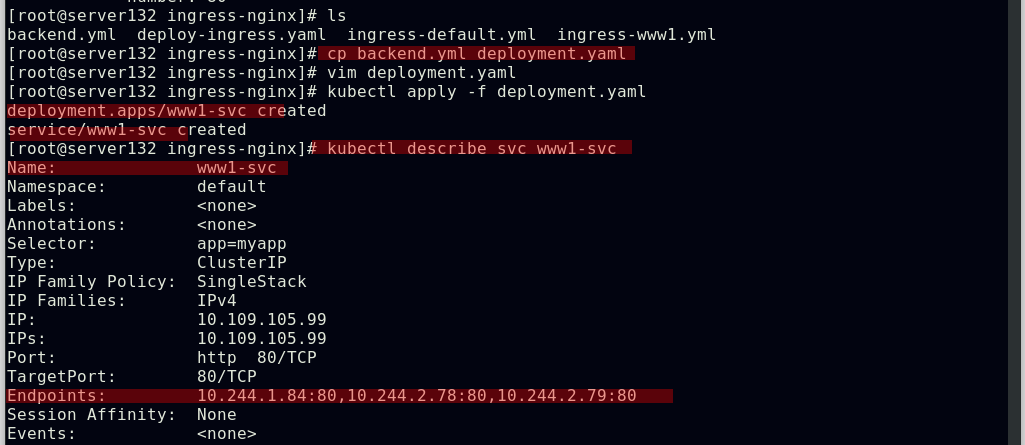
创建ingress资源文件中指定的服务和后端pod
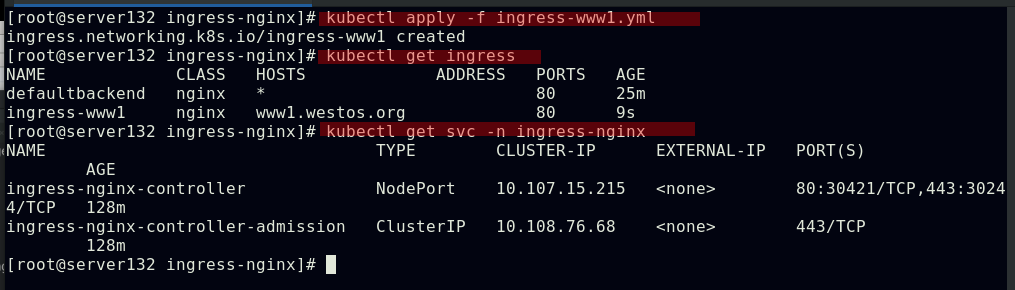
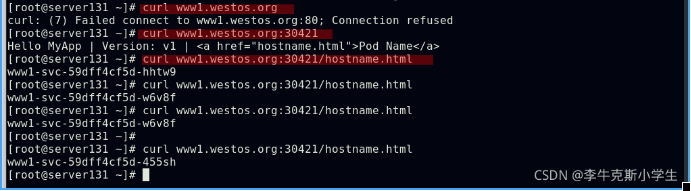
应用ingress虚拟主机资源文件,可以在集群外部通过HostName:NodePort的方式访问到
![]()
ingress-nginx控制器服务的默认类型是NodePort,我们还可以将它的类型配置为LoadBalancer
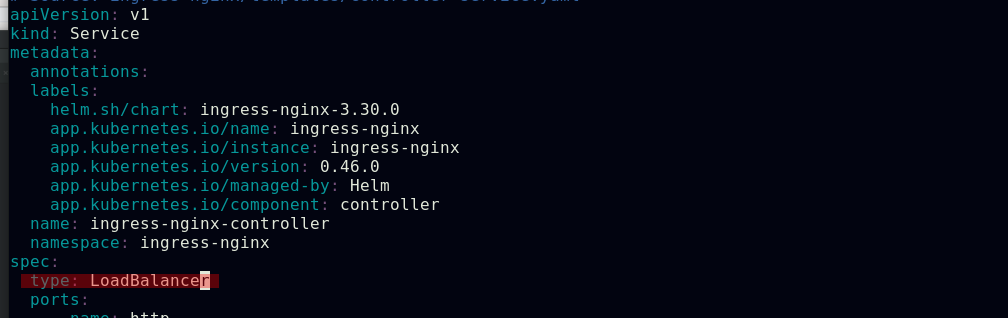
结合我们之前实验中做过的metallb在裸金属环境下为此ingress-controller服务分配一个IP
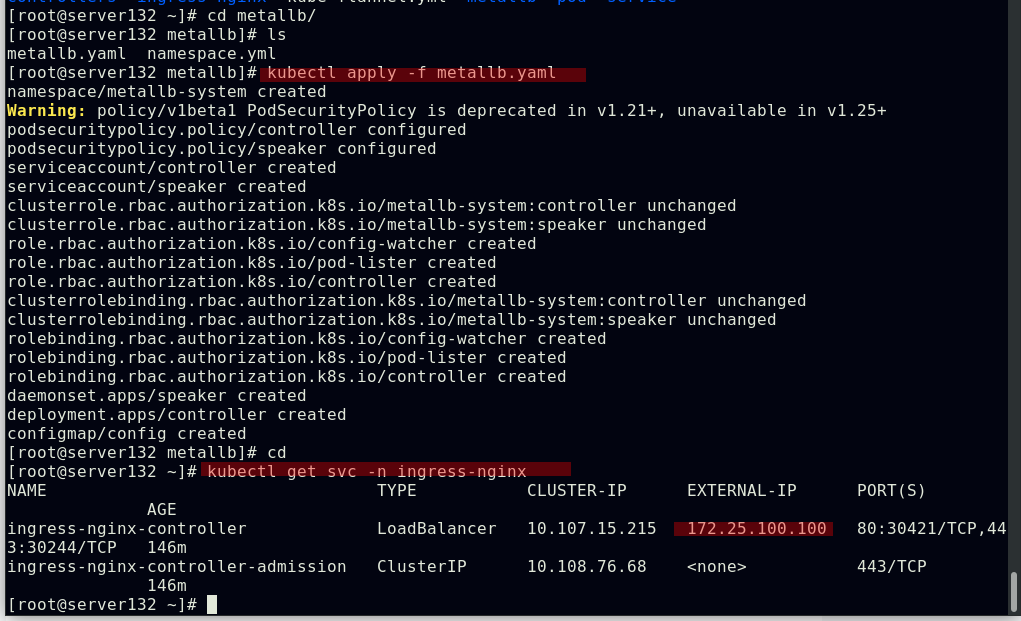
此时在外部主机做个地址解析后即可访问ingress服务

ingress服务还可以用DaemonSet结合nodeselector来部署ingress-controller到特定的集群节点上,然后使用HostNetwork直接把该pod与宿主机节点的网络打通,直接使用宿主机的80/443端口就能访问服务,这样的优点是整个请求链路最简单,性能相对NodePort模式更好;缺点是由于直接利用宿主机节点的网络和端口,一个节点主机只能部署一个ingress-controller pod,比较适合大并发的生产环境使用
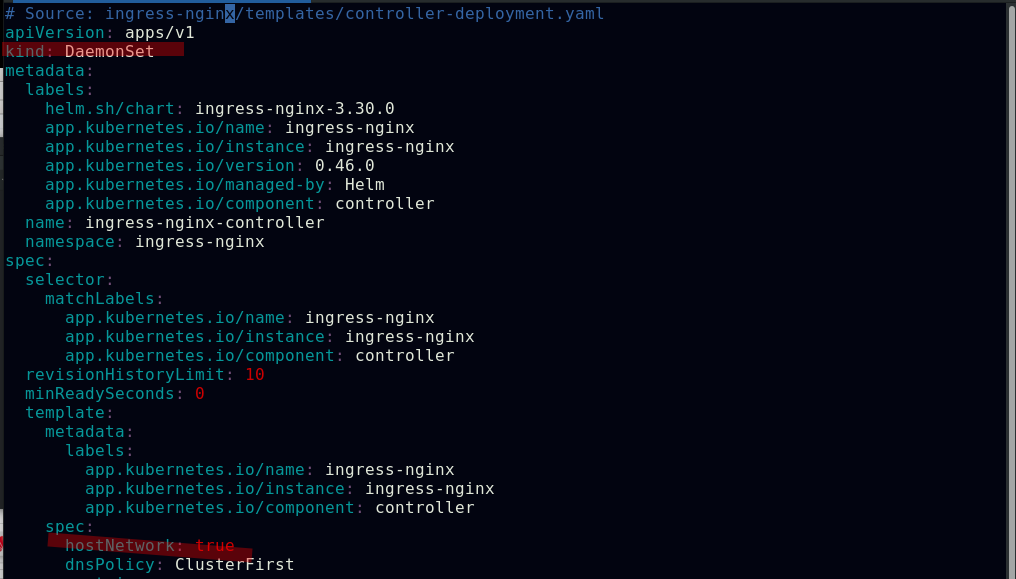
##配置ingress-controller的类型为DaemonSet,使用hostNetwork网络模式
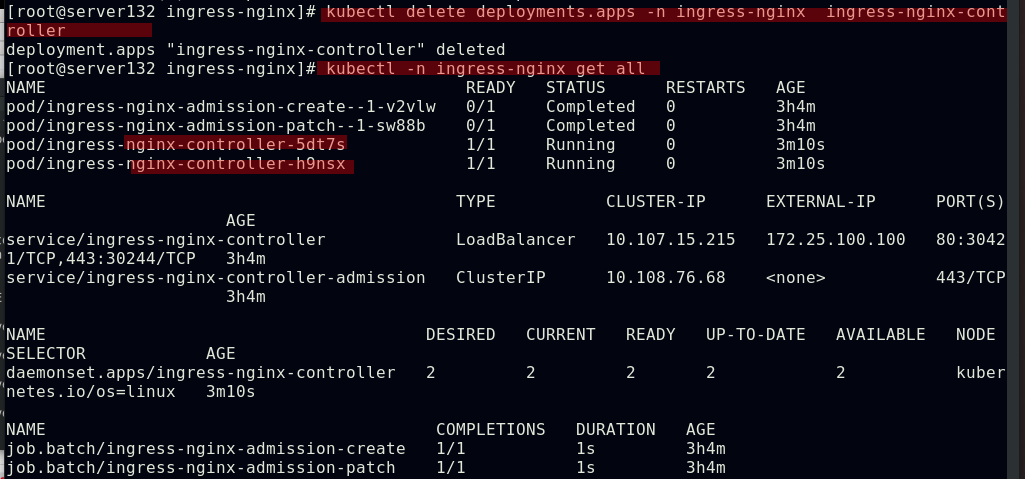
##重新应用ingress-nginx资源文件后删除原来的deployment控制器
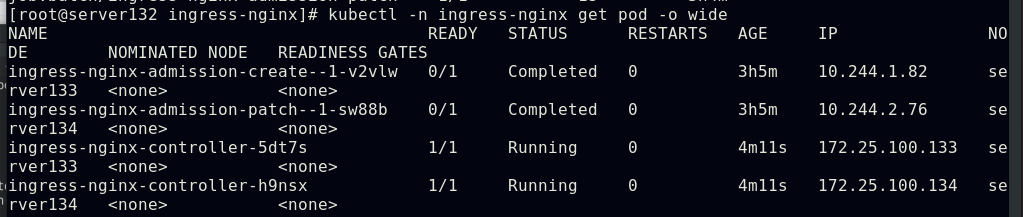
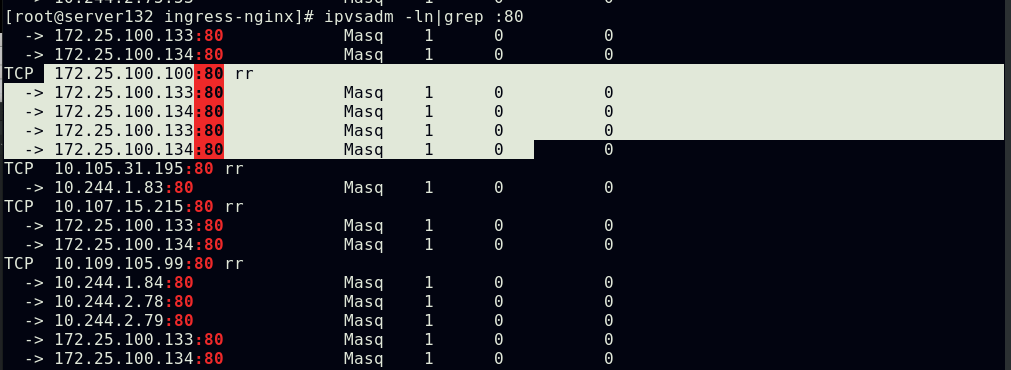
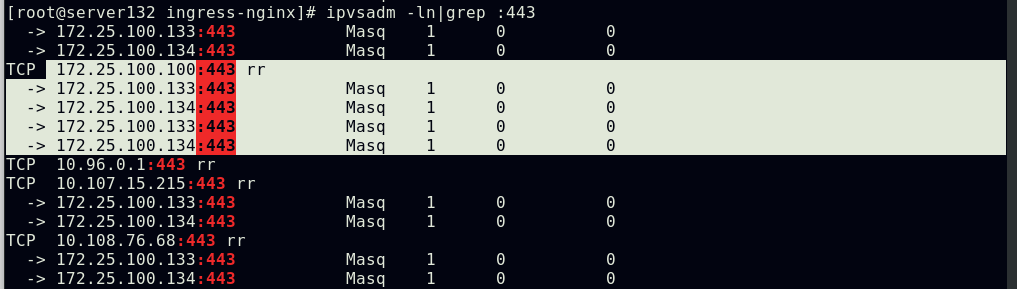
##查看ingress-controller控制器的运行及ipvs调度策略
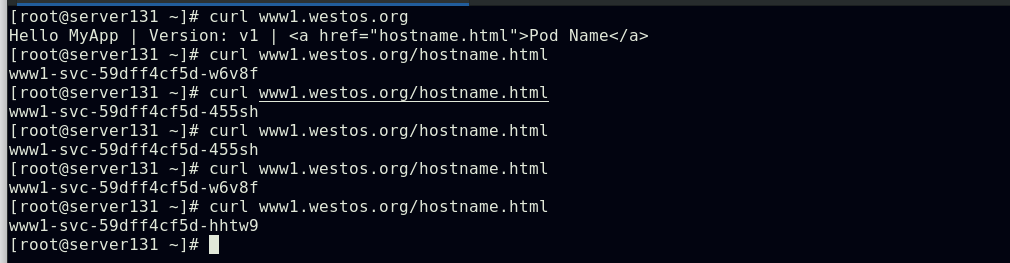
##此时集群外部主机即可通过80/443端口访问ingress服务
配置通过不同域名访问不同的ingress服务及后端pod
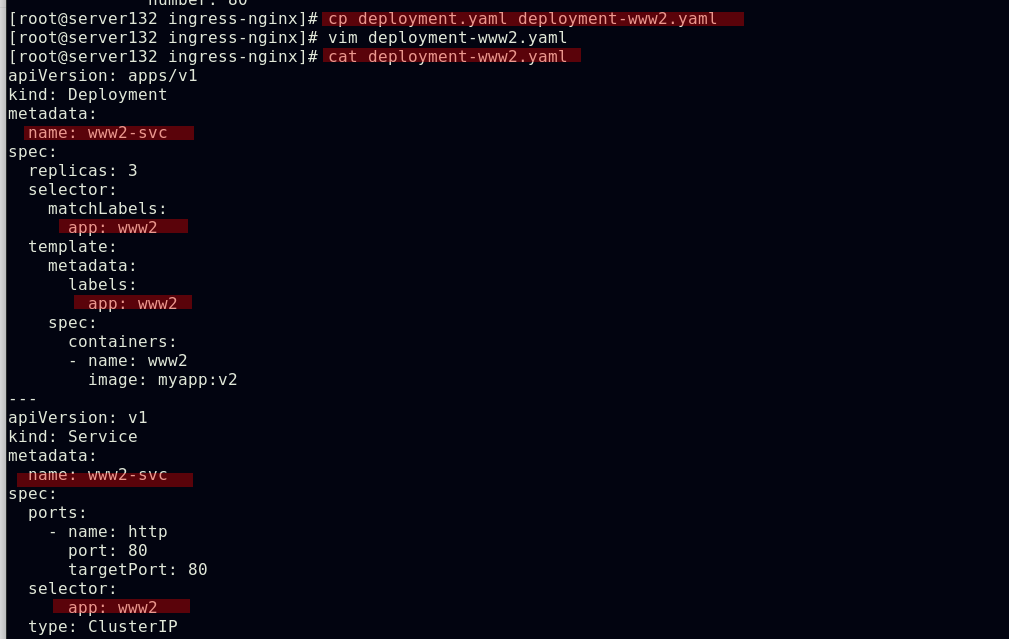
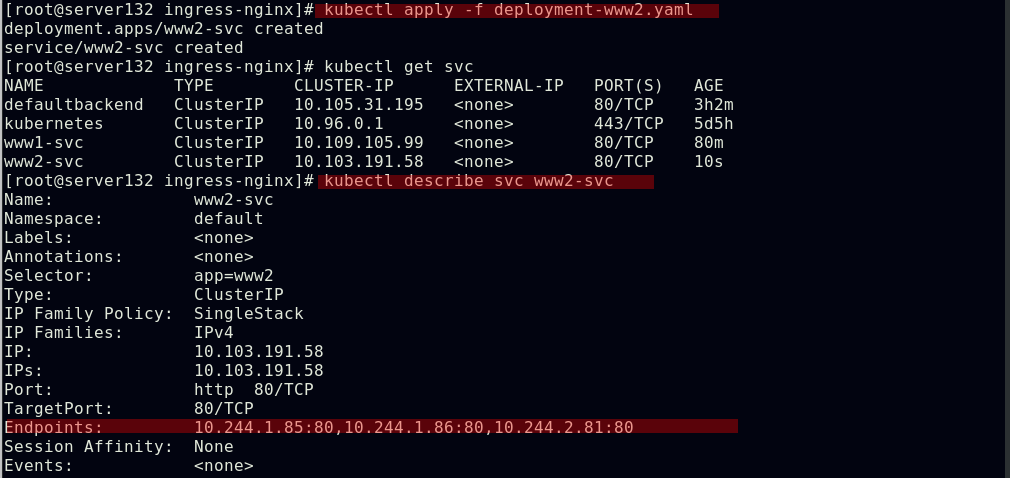
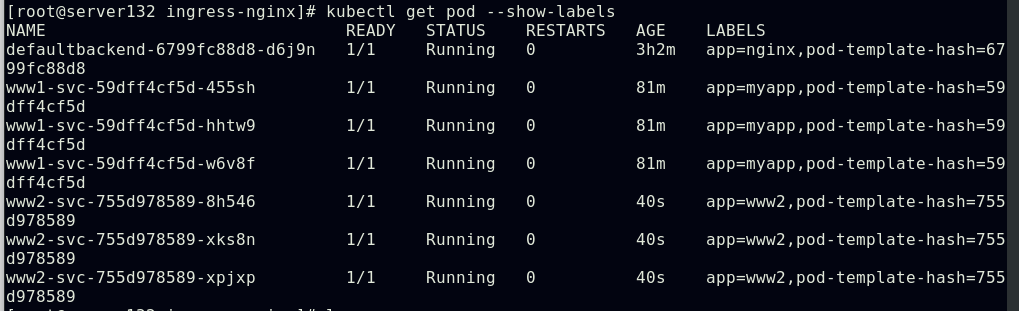
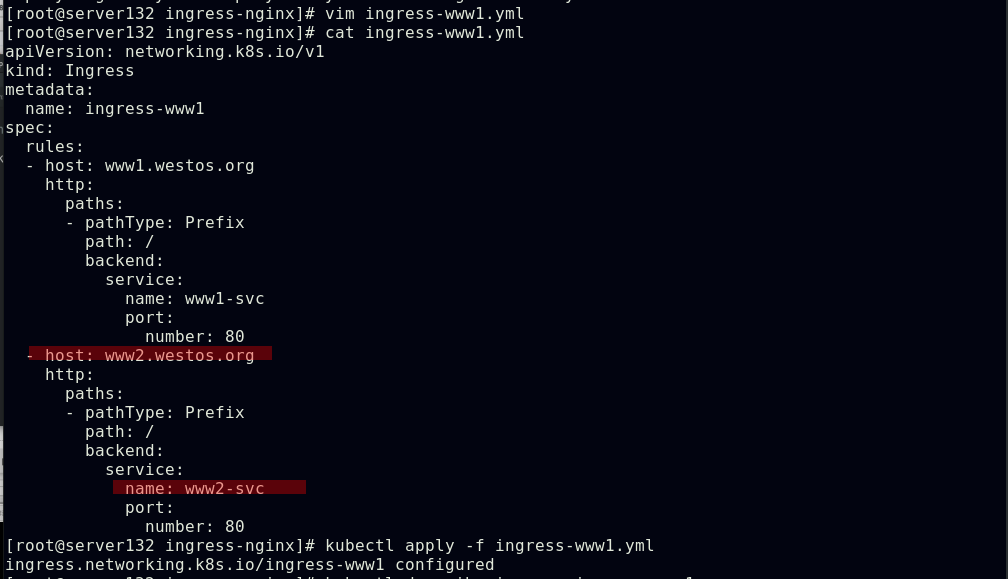
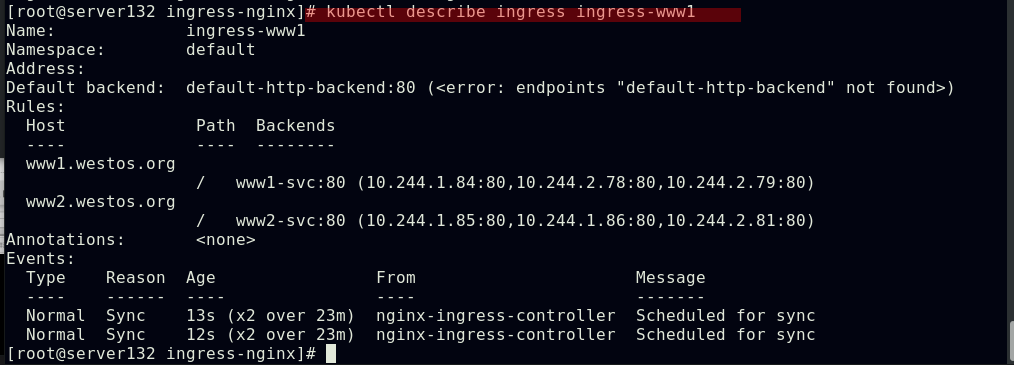
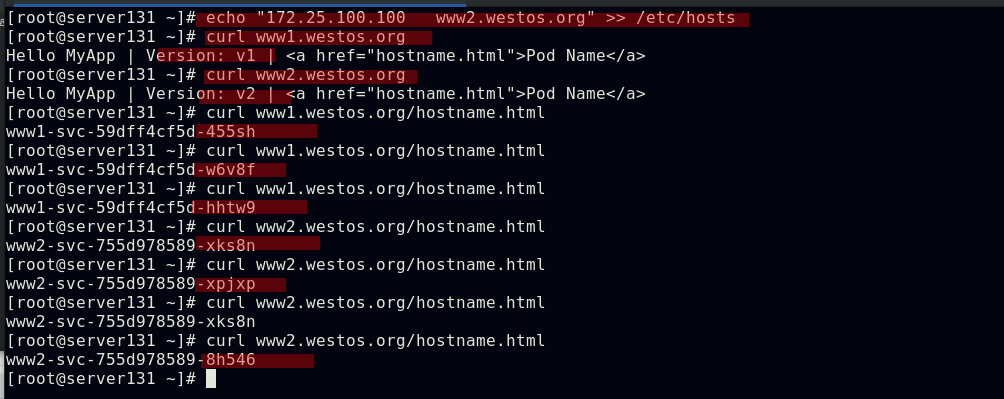
Ingress的TLS配置
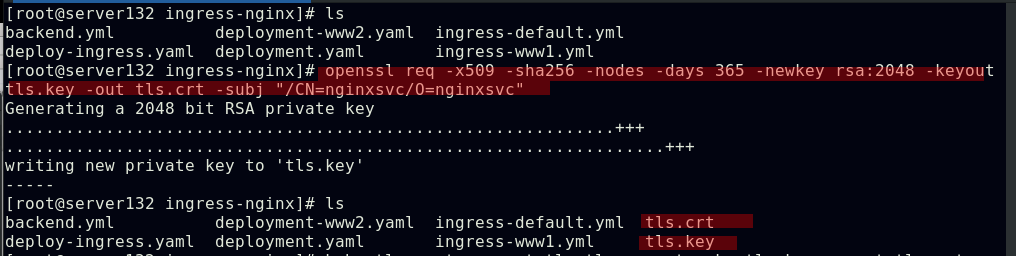
##创建证书和私钥

##创建kubernetes加密项
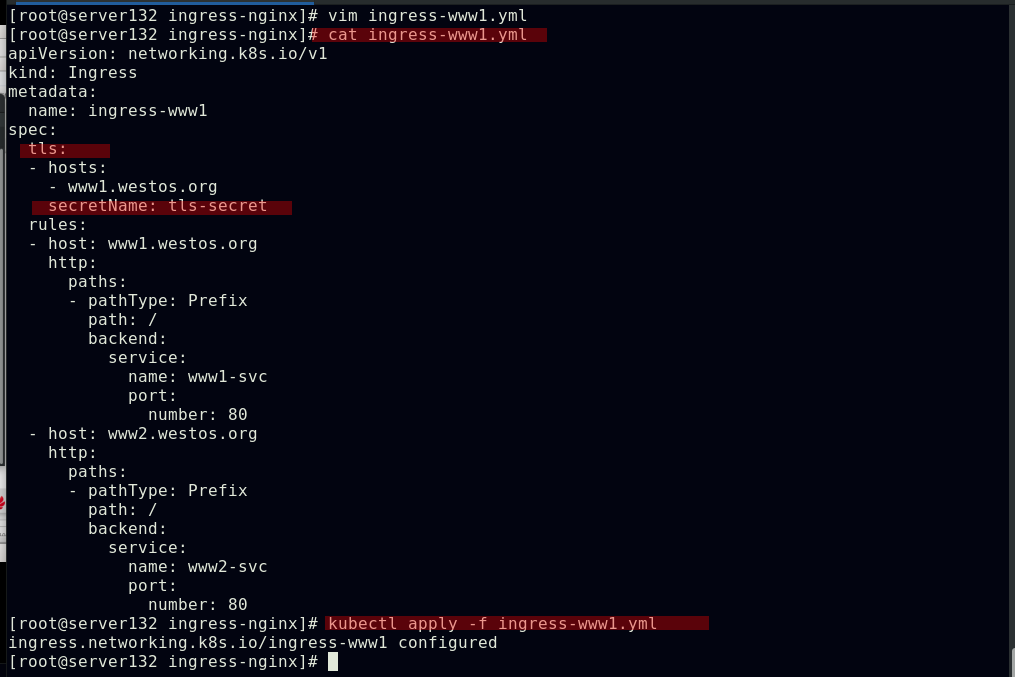
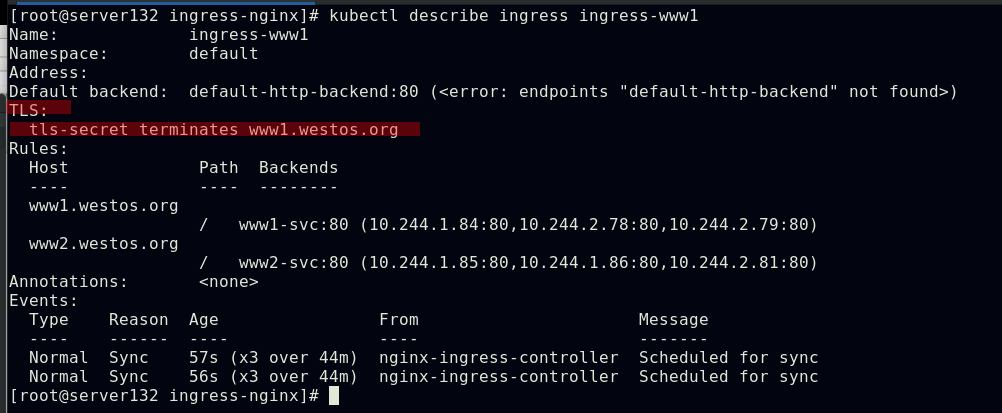
##在资源文件中使用加密
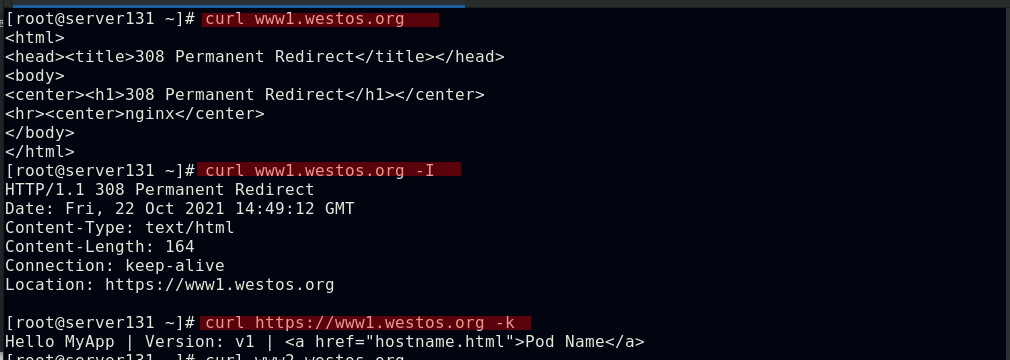
##使用加密后的访问效果
Ingress的认证配置
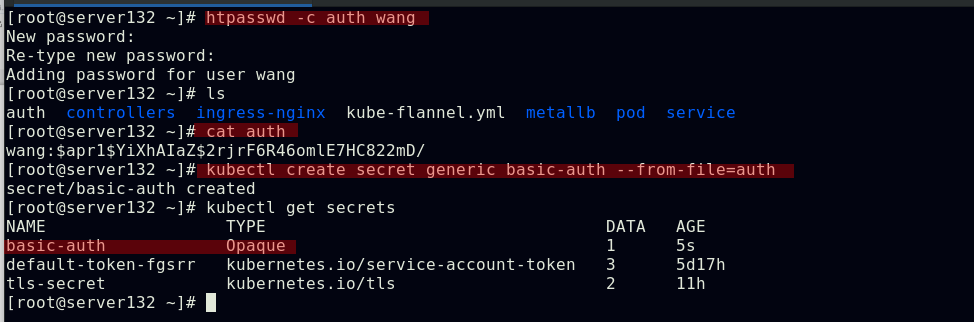
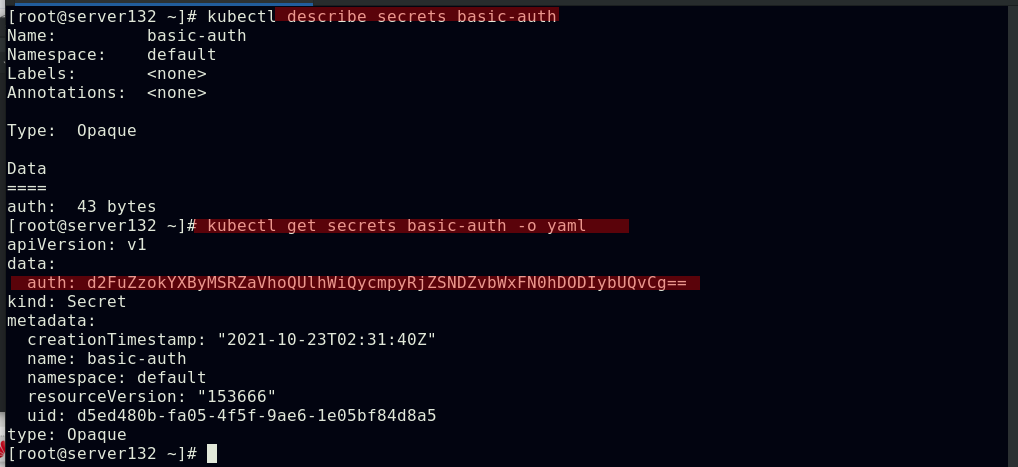
##生成用户认证

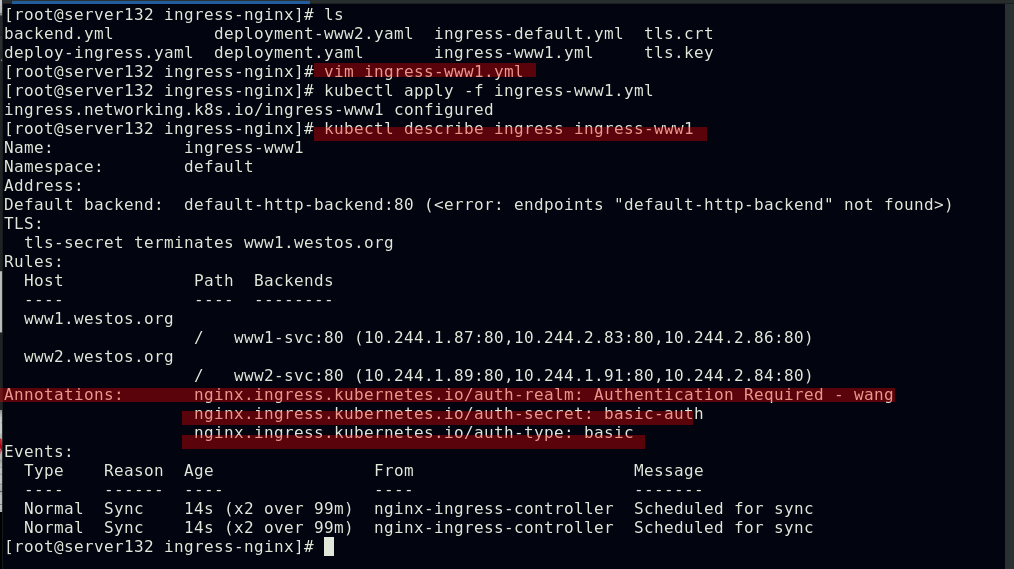
##在ingress资源文件中应用认证功能
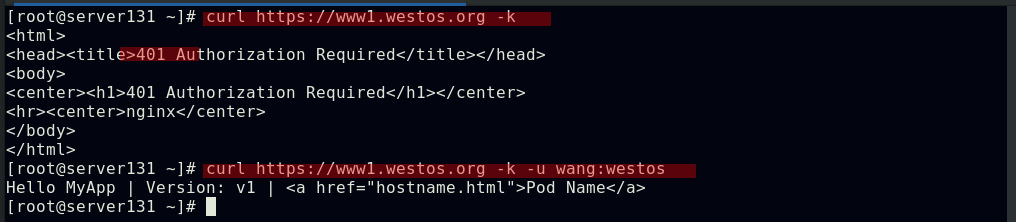
##此时访问时需要进行用户认证
Ingress地址重写

##在ingress资源文件中配置地址重定向
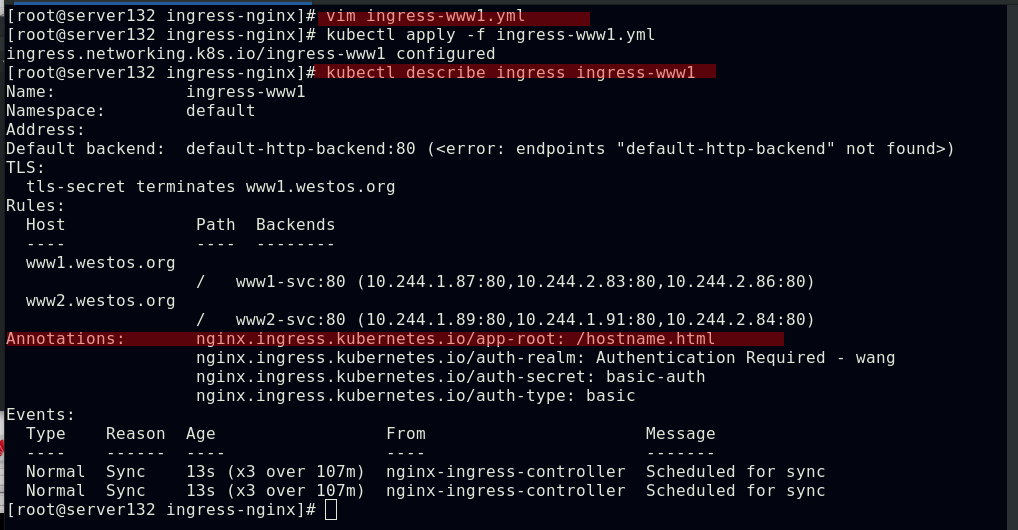
##应用资源文件
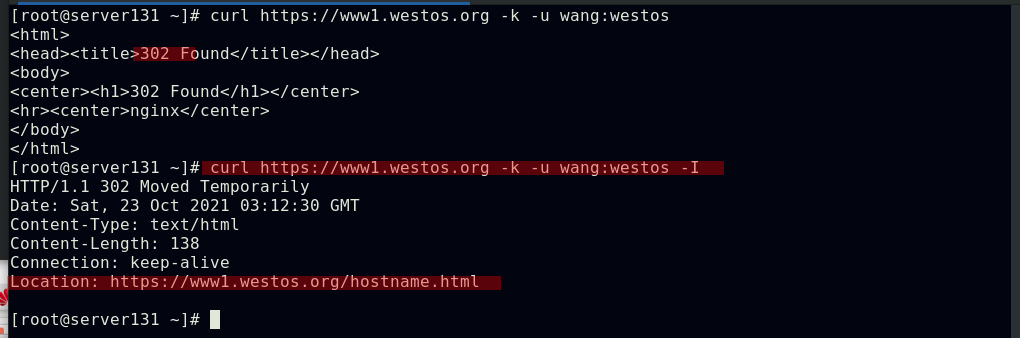
##此时访问,访问的地址被重定向至文件中指定的路径
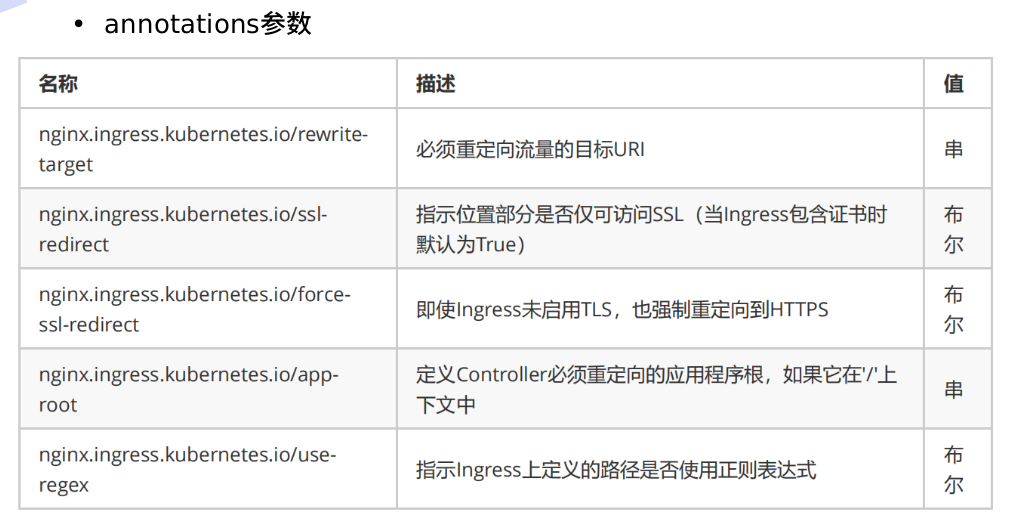
kubernetes网络通信
kubernetes通过CNI接口接入其他插件来实现网络通讯;目前比较流行的插件有flannel、calico等;CNI插件存放位置:/etc/cni/net.d/

插件使用的解决方案如下:虚拟网桥、虚拟网卡,多个容器共用一个虚拟网卡进行通信;多路复用:MacVLAN,多个容器共用一个物理网卡进行通信;硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好
容器间通信:同一个pod内的多个容器间的通信,通过lo即可实现
pod之间的通信:同一节点的pod之间通过cni网桥转发数据包;不同节点的pod之间的通信需要网络插件支持
pod和service通信:通过iptables或ipvs实现通信;ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
pod和外网通信:iptables的MASQUERADE
Service与集群外部客户端的通信:ingress、nodeport、loadbalancer
flannel网络
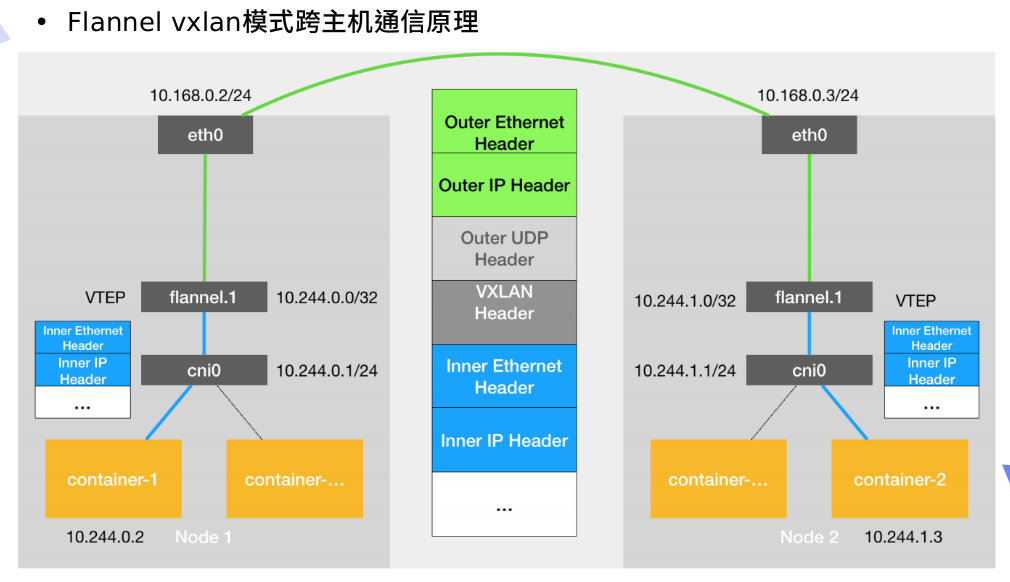
VXLAN:即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术;VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network)
VTEP:VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因
Cni0:网桥设备,每创建一个pod都会创建一对veth pair;其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)
Flannel.1:TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包);不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端
Flanneld:flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配;同时Flanneld监听kubernetes集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息
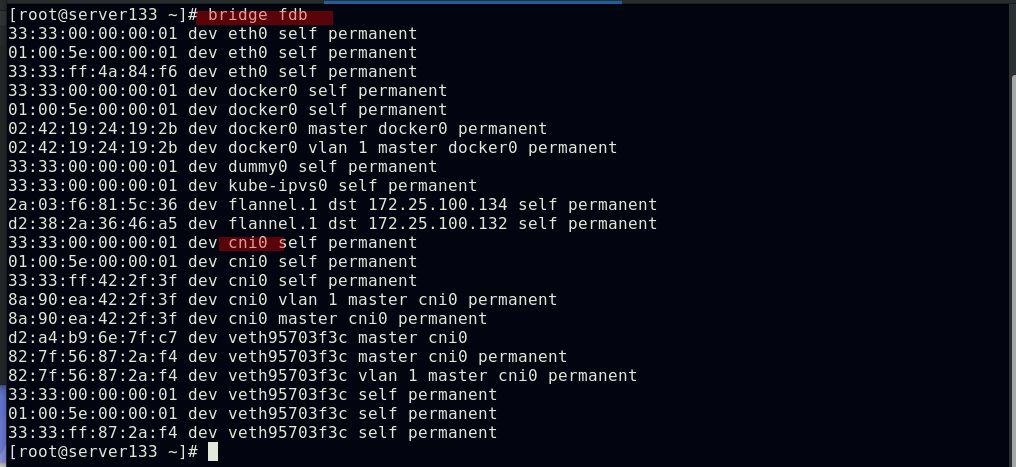
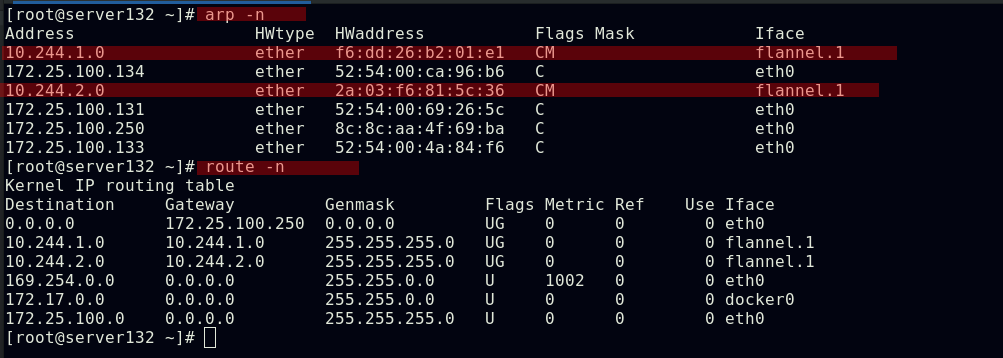
flannel网络原理
当容器发送IP包,通过veth pair发往cni网桥,再路由到本机的flannel.1设备进行处理;VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备;内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输;Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识;flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么;在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的;linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取;此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备;目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器
flannel支持多种后端
Vxlan:vxlan(报文封装,默认)Directrouting(直接路由,跨网段使用vxlan,同网段使用host-gw模式)
host-gw:主机网关,性能好,但只能在二层网络中,不支持跨网络,如果有成千上万的Pod,容易产生广播风暴,不推荐
UDP:性能差,不推荐
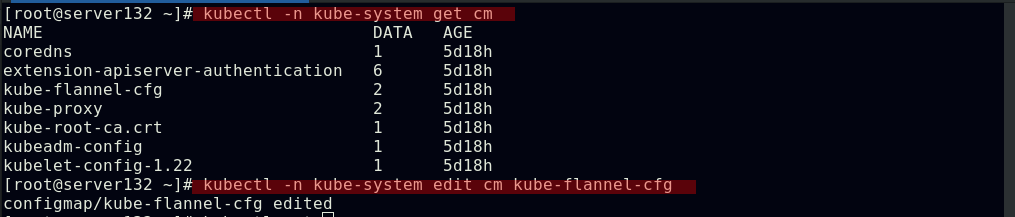

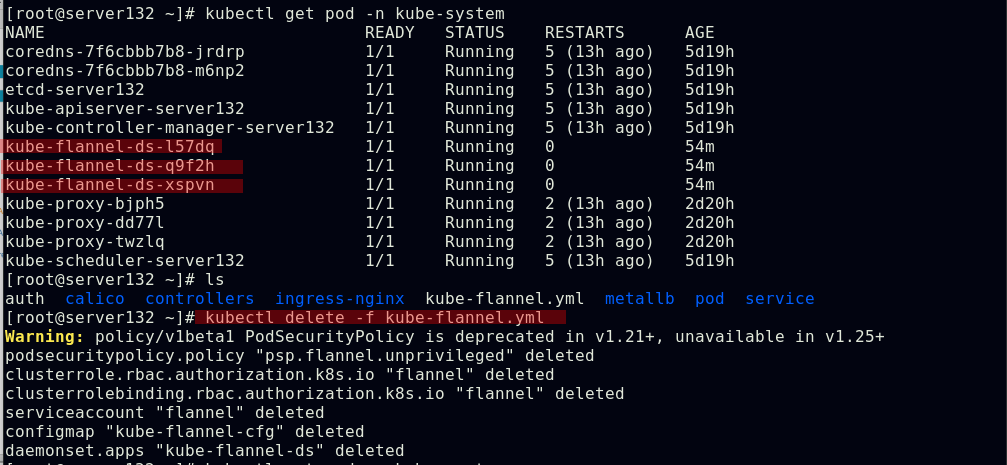
##配置fannel后端为host-gw模式(此模式需要节点在同一vlan下)
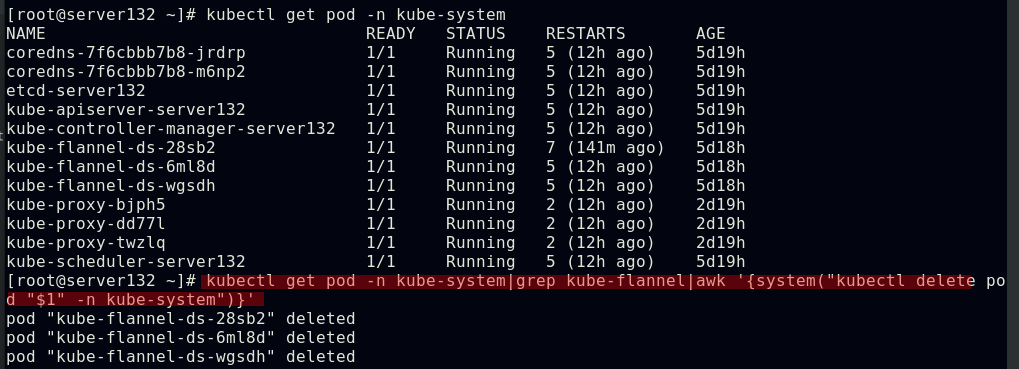
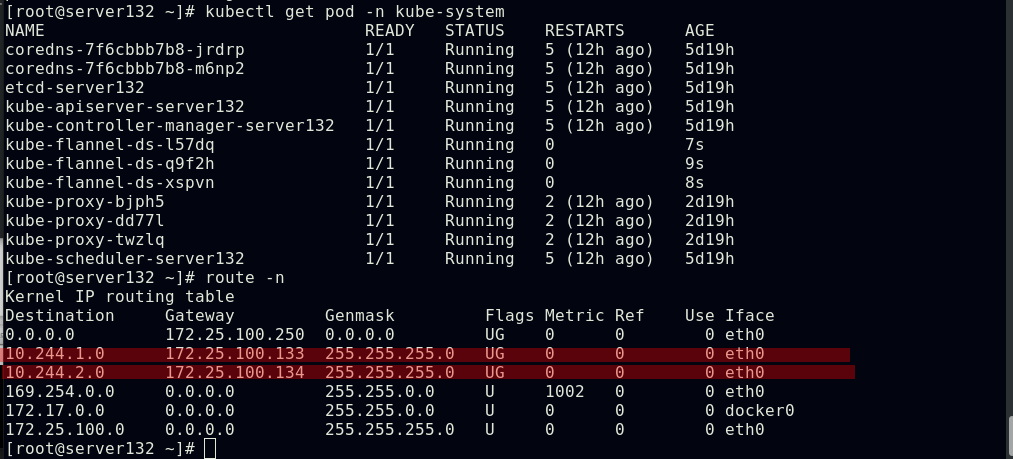
##删除kube-falnnel的pod以重载,使配置生效
##此时跨节点仍可以正常访问
calico网络插件
calico简介:
flannel实现的是网络通信,calico的特性是在pod之间的隔离;通过BGP路由,但大规模端点的拓扑计算和收敛往往需要一定的时间和计算资源;使用纯三层的转发,中间没有任何的NAT和overlay,转发效率最好;Calico仅依赖三层路由可达;Calico较少的依赖性使它能适配所有VM、Container、白盒或者混合环境场景
软件官网
Install Calico networking and network policy for on-premises deploymentshttps://docs.projectcalico.org/getting-started/kubernetes/self-managed-onprem/onpremises安装calico网络插件

##下载calico清单文件
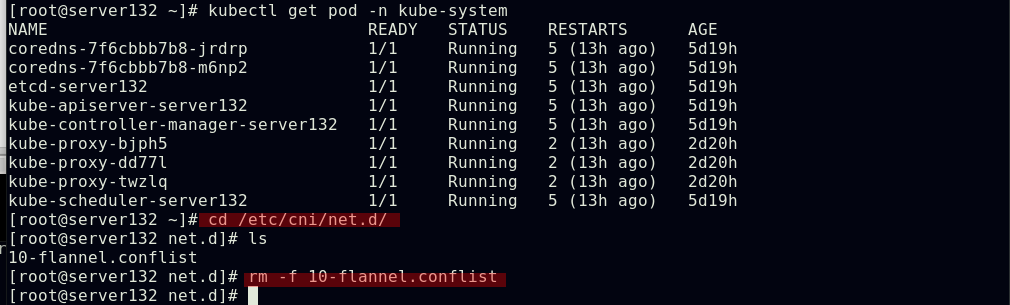


##停用flannel资源文件,删除所有节点的flannel文件
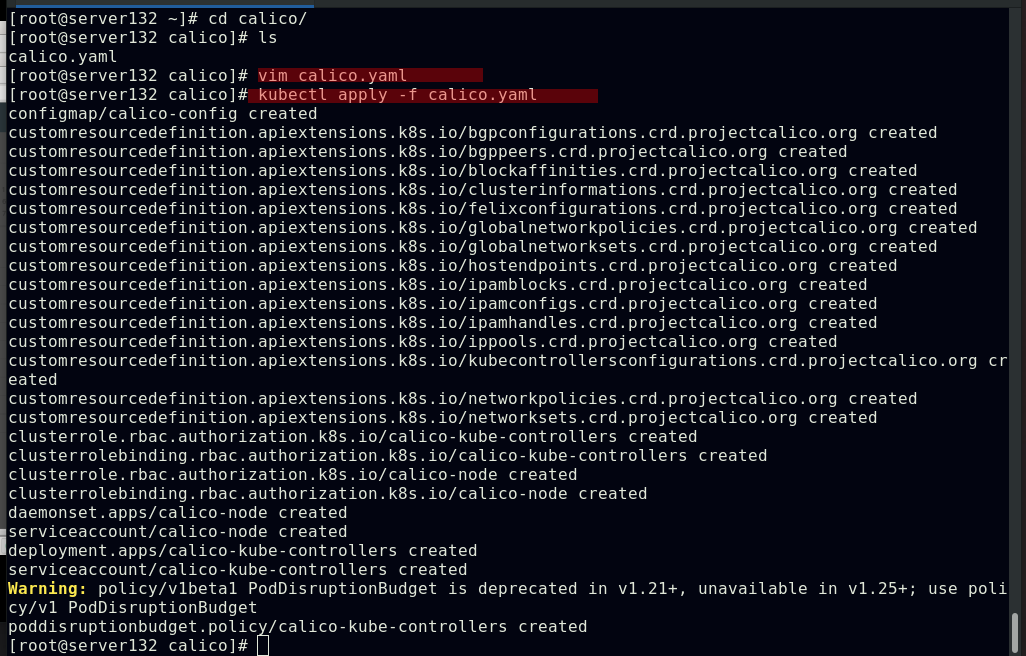

##编辑calico的资源文件更改其中镜像指向自己搭建的私有仓库;关闭IPIP模式(前提是私有仓库中有此镜像,可以在仓库主机直接使用docker pull命令拉取)
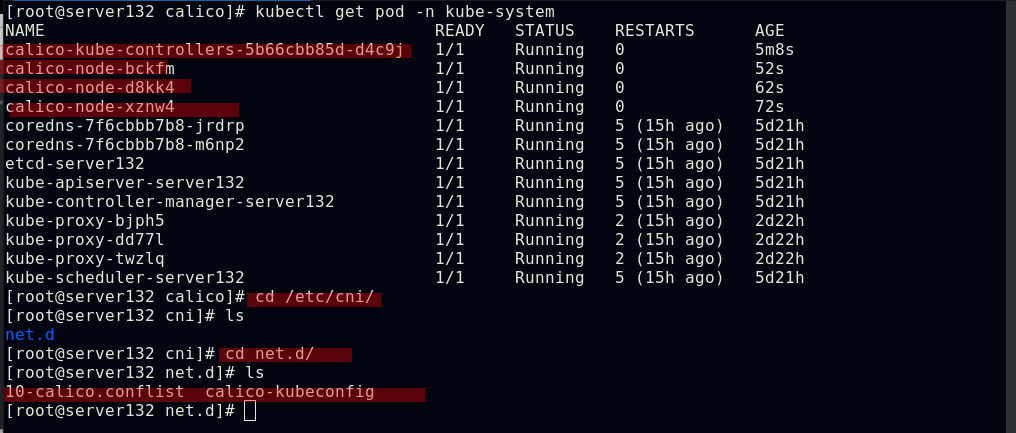
##应用后会在插件目录下生成两个文件,也会在kube-system命名空间下生成相关的calico控制器及pod
calico网络架构
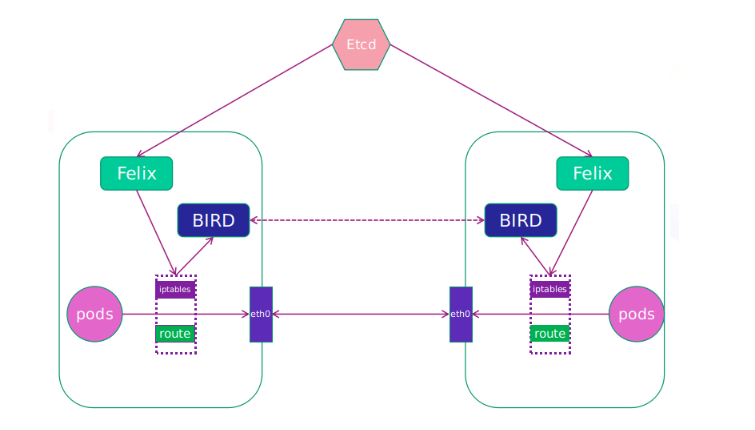
Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡,同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离
BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个集群其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里来
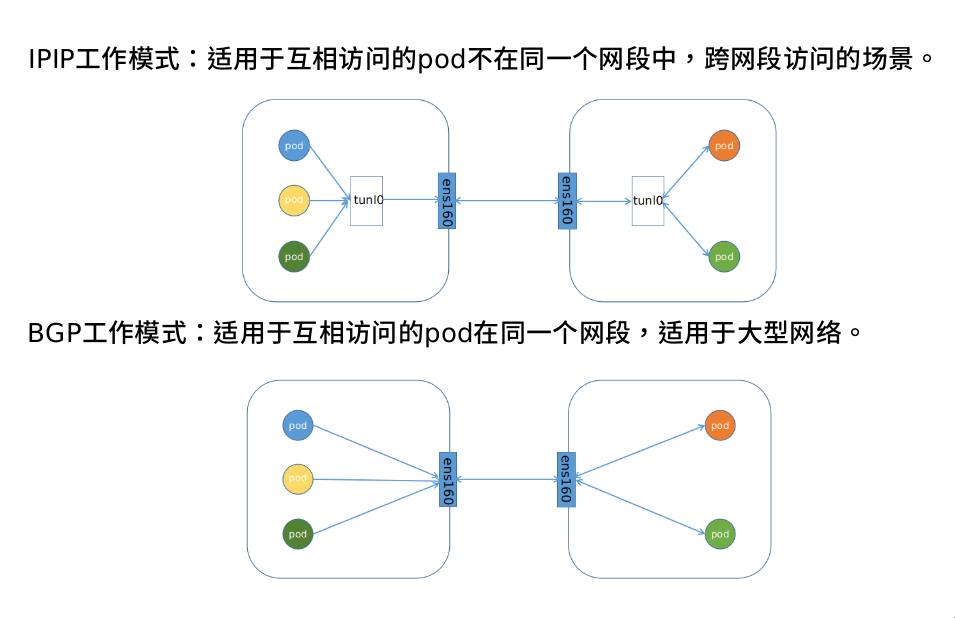
calico工作模式
网络策略
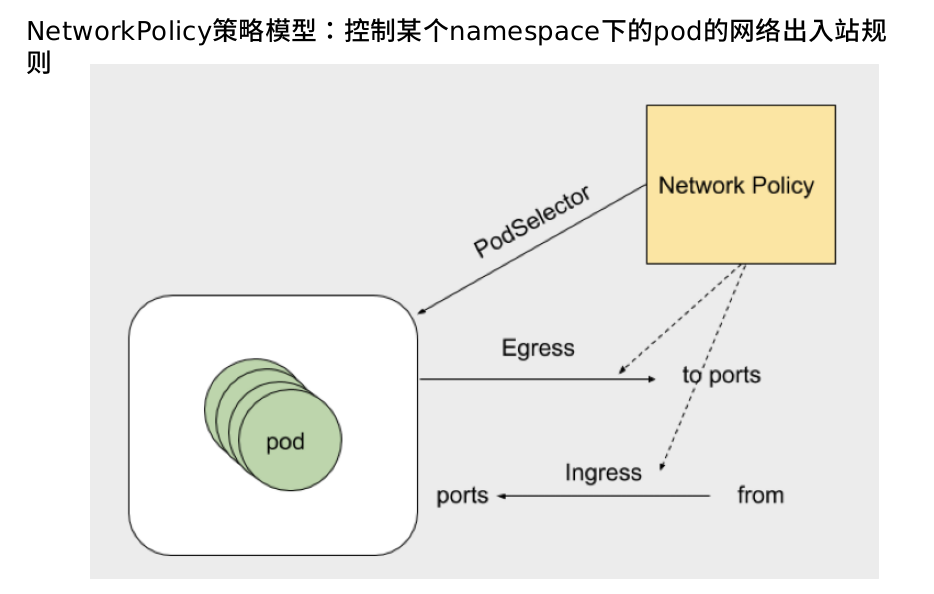
kubernetes官网解释:
网络策略 | Kubernetespod is allowed to communicate with various network "entities" (we use the word "entity" here to avoid overloading the more common terms such as "endpoints" and "services", which have specific Kubernetes connotations) over the network. -- 如果你希望在 IP 地址或端口层面(OSI 第 3 层或第 4 层)控制网络流量, 则你可以考虑为集群中特定应用使用 Kubernetes 网络策略(NetworkPolicy)。 NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许 Pod 与网络上的各类网络“实体” (我们这里使用实体以避免过度使用诸如“端点”和“服务”这类常用术语, 这些术语在 Kubernetes 中有特定含义)通信。Pod 可以通信的 Pod 是通过如下三个标识符的组合来辩识的: 其他被允许的 Pods(例外:Pod 无法阻塞对自身的访问) 被允许的名字空间 IP 组块(例外:与 Pod 运行所在的节点的通信总是被允许的, 无论 Pod 或节点的 IP 地址) selector to specify what traffic is allowed to and from the Pod(s) that match the selector.https://kubernetes.io/zh/docs/concepts/services-networking/network-policies/NetworkPolicy资源实验步骤:
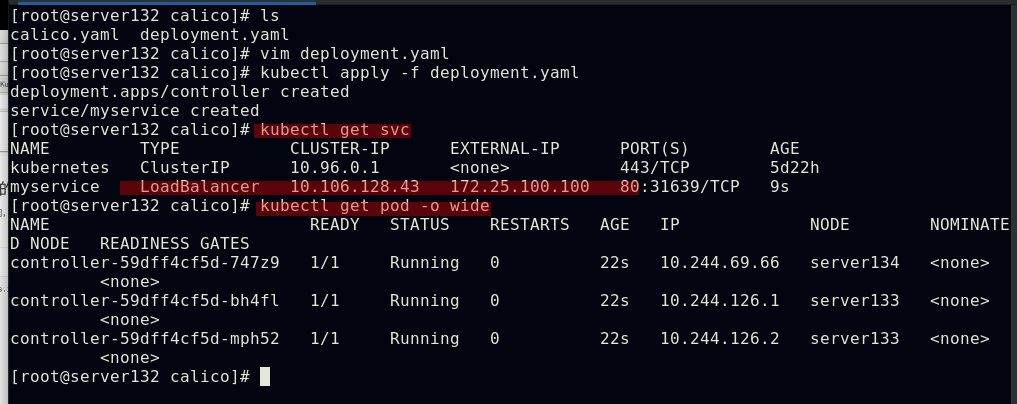
##创建实验素材,所需的service及其后端pod;此处的externalIP依旧是利用之前实验中创建的metallb功能生成的
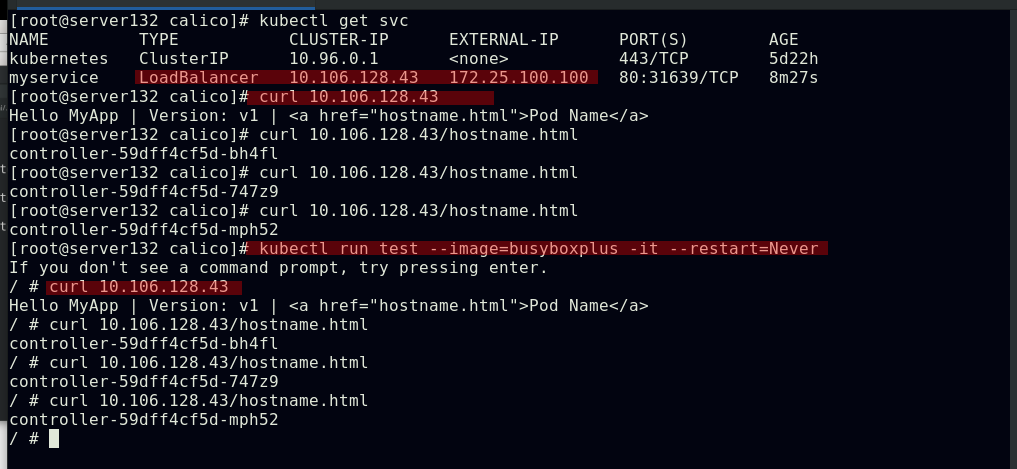
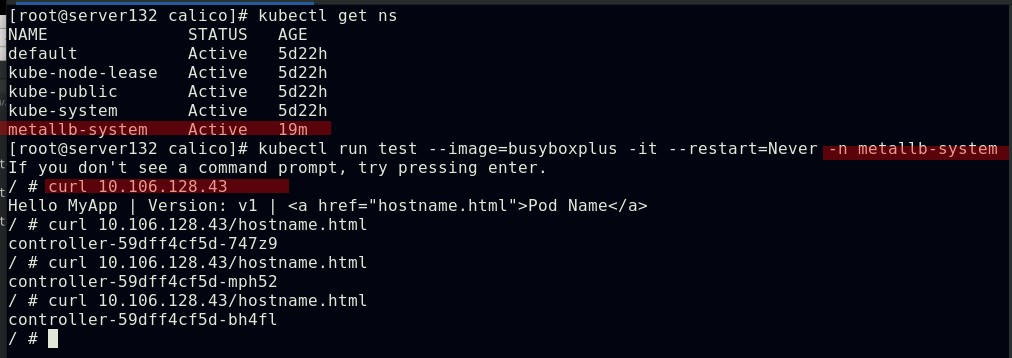
##默认情况下,Pod是非隔离的,它们接受任何来源的流量
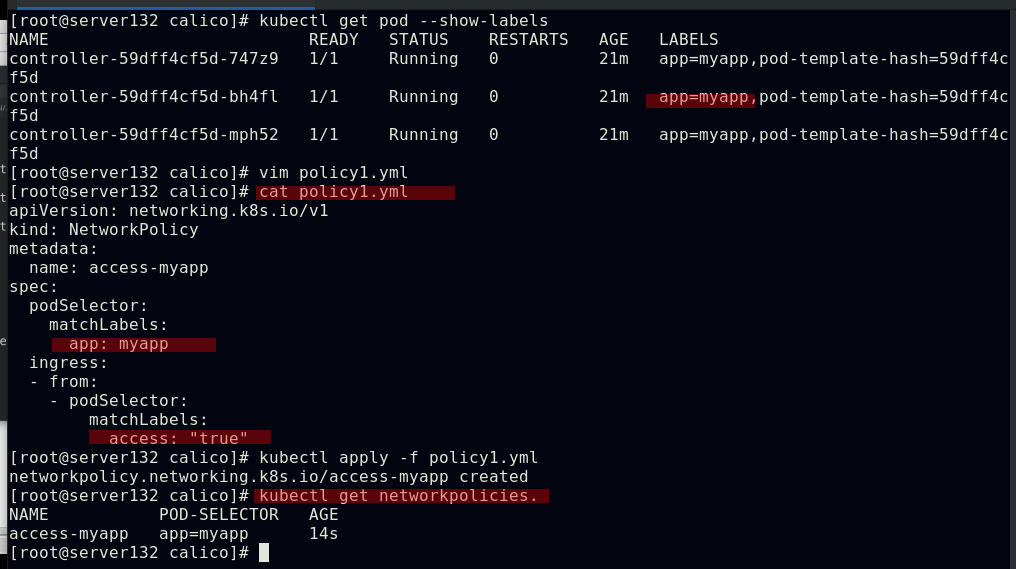
##创建网络策略文件并应用生成基于pod标签筛选的pod入站(ingress)策略
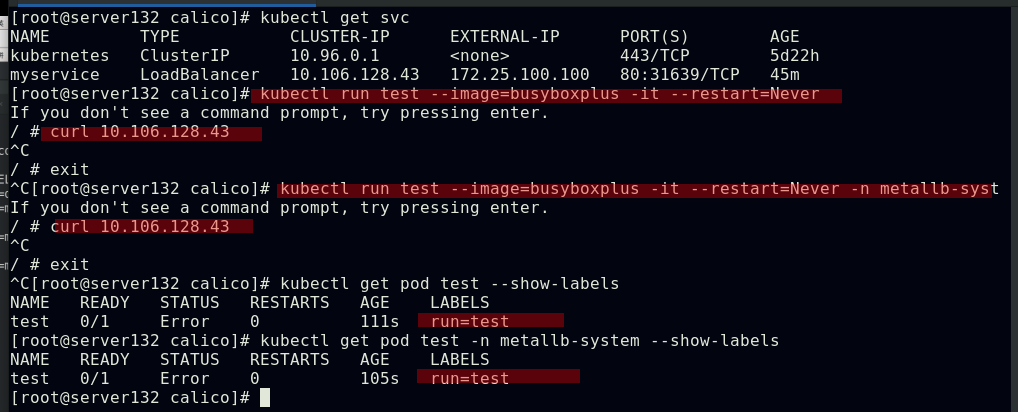
##此时具有指定标签的pod被隔离,未拥有策略文件中定义的标签的pod无法访问被隔离的pod

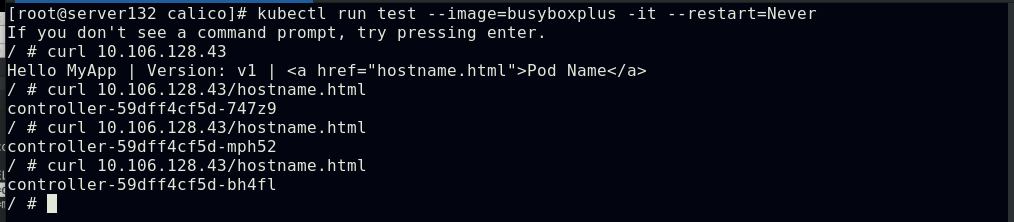
##此时为测试pod打上策略文件中定义的标签后即可访问隔离的pod


##以上方式对于跨命名空间的访问隔离pod不会生效
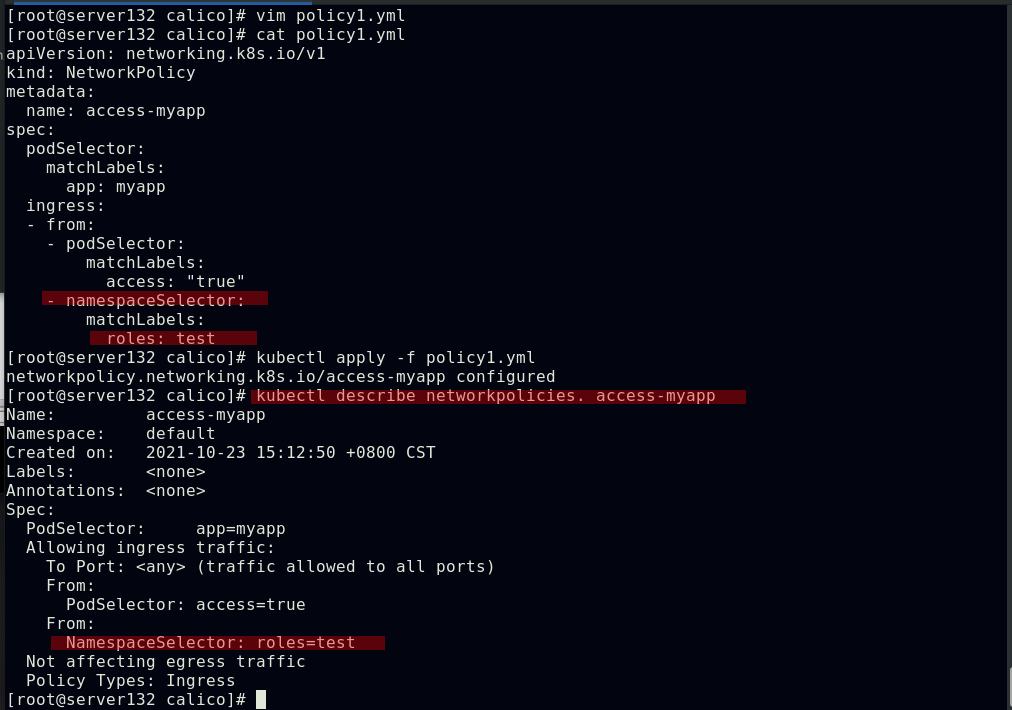
##更新策略文件,添加对于namespace的隔离策略
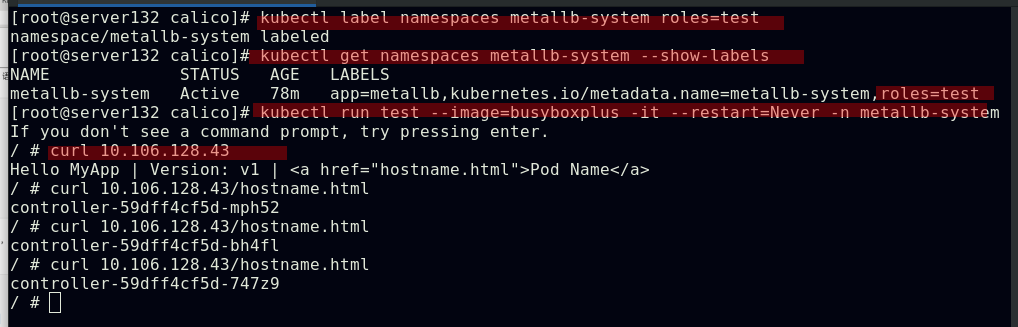
##对命名空间添加策略文件中指定的标签后,在此命名空间下运行的pod即可访问隔离的pod

##此时此命名空间下的pod不需要有策略文件中定义的pod标签
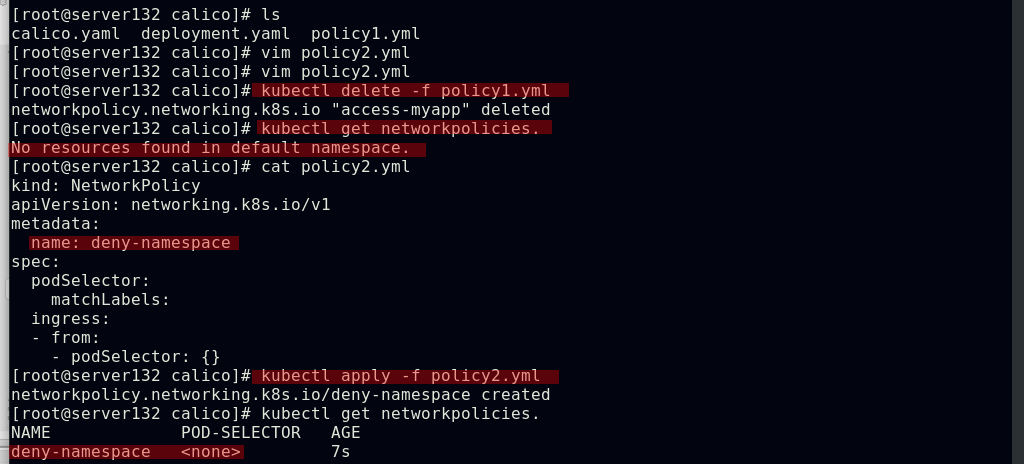
##创建禁止跨命名空间的pod互访的策略
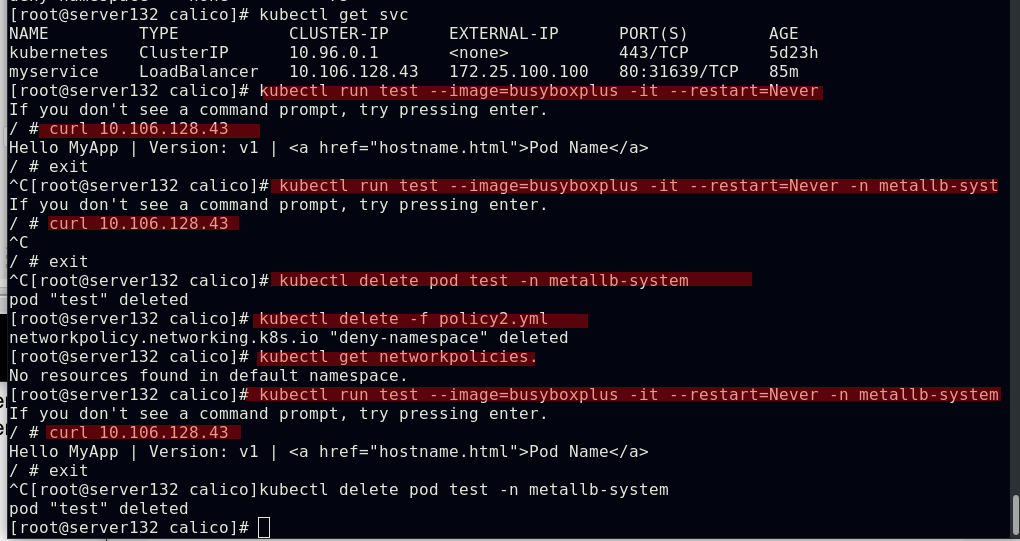
##访问效果

##允许外网访问服务策略

##允许指定网段访问服务
最后
以上就是壮观水壶最近收集整理的关于容器技术---(二)kubernetes集群部署 Kubernetes简介Kubernetes集群搭建Pod管理资源清单Pod生命周期控制器servicekubernetes网络通信的全部内容,更多相关容器技术---(二)kubernetes集群部署 Kubernetes简介Kubernetes集群搭建Pod管理资源清单Pod生命周期控制器servicekubernetes网络通信内容请搜索靠谱客的其他文章。








发表评论 取消回复