#随机字符串的统计可视化
#导入所需模块
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import random
import re
#中文显示设置
from matplotlib.font_manager import FontProperties #导入中文管理模块
font=FontProperties(fname=r’c:windowsfontssimsun.ttc’) #导入中文显示
#设置字符串种子
random_list=[list(‘adaflbnbhghvgh’),list(‘sdfdjtgghftrdrfcyh’),list(‘adaflakghggvvrtbyt23689po’)
,list(‘2rfrrikubzsxc’),list(‘khufrdyu67hfuhnzdxassczc’)]
print(random_list)
–out
[[‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’, ‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’,
‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘a’,
‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’], [
‘2’, ‘r’, ‘f’, ‘r’, ‘r’, ‘i’, ‘k’, ‘u’, ‘b’, ‘z’, ‘s’, ‘x’, ‘c’], [‘k’, ‘h’, ‘u’, ‘f’, ‘r’, ‘d’,
‘y’, ‘u’, ‘6’, ‘7’, ‘h’, ‘f’, ‘u’, ‘h’, ‘n’, ‘z’, ‘d’, ‘x’, ‘a’, ‘s’, ‘s’, ‘c’, ‘z’, ‘c’]]
#生成20行随机字符串
Stand_list=[np.random.choice(random_list) for i in range(30)]
print(Stand_list)
–out
[[‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’, ‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘a’,
‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’], [‘a’,
‘d’, ‘a’, ‘f’, ‘l’, ‘a’, ‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’,
‘9’, ‘p’, ‘o’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’,
‘h’], [‘2’, ‘r’, ‘f’, ‘r’, ‘r’, ‘i’, ‘k’, ‘u’, ‘b’, ‘z’, ‘s’, ‘x’, ‘c’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘a’,
‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’], [‘s’, ‘d’,
‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’,
‘a’, ‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’], [‘a’,
‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’, ‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’,
‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’, ‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘k’,
‘h’, ‘u’, ‘f’, ‘r’, ‘d’, ‘y’, ‘u’, ‘6’, ‘7’, ‘h’, ‘f’, ‘u’, ‘h’, ‘n’, ‘z’, ‘d’, ‘x’, ‘a’, ‘s’, ‘s’, ‘c’, ‘z’,
‘c’], [‘k’, ‘h’, ‘u’, ‘f’, ‘r’, ‘d’, ‘y’, ‘u’, ‘6’, ‘7’, ‘h’, ‘f’, ‘u’, ‘h’, ‘n’, ‘z’, ‘d’, ‘x’, ‘a’, ‘s’, ‘s’,
‘c’, ‘z’, ‘c’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’, ‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’,
‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’,
‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’,
‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘a’, ‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’,
‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’], [‘2’, ‘r’, ‘f’, ‘r’, ‘r’, ‘i’, ‘k’, ‘u’, ‘b’, ‘z’, ‘s’,
‘x’, ‘c’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘a’,
‘d’, ‘a’, ‘f’, ‘l’, ‘a’, ‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’,
‘p’, ‘o’], [‘k’, ‘h’, ‘u’, ‘f’, ‘r’, ‘d’, ‘y’, ‘u’, ‘6’, ‘7’, ‘h’, ‘f’, ‘u’, ‘h’, ‘n’, ‘z’, ‘d’, ‘x’, ‘a’, ‘s’,
‘s’, ‘c’, ‘z’, ‘c’], [‘s’, ‘d’, ‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’],
[‘s’, ‘d’, ‘f’, ‘d’, ‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘s’, ‘d’, ‘f’, ‘d’,
‘j’, ‘t’, ‘g’, ‘g’, ‘h’, ‘f’, ‘t’, ‘r’, ‘d’, ‘r’, ‘f’, ‘c’, ‘y’, ‘h’], [‘2’, ‘r’, ‘f’, ‘r’, ‘r’, ‘i’, ‘k’, ‘u’,
‘b’, ‘z’, ‘s’, ‘x’, ‘c’], [‘2’, ‘r’, ‘f’, ‘r’, ‘r’, ‘i’, ‘k’, ‘u’, ‘b’, ‘z’, ‘s’, ‘x’, ‘c’], [‘a’, ‘d’, ‘a’, ‘f’,
‘l’, ‘a’, ‘k’, ‘g’, ‘h’, ‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’], [‘a’,
‘d’, ‘a’, ‘f’, ‘l’, ‘b’, ‘n’, ‘b’, ‘h’, ‘g’, ‘h’, ‘v’, ‘g’, ‘h’], [‘a’, ‘d’, ‘a’, ‘f’, ‘l’, ‘a’, ‘k’, ‘g’, ‘h’,
‘g’, ‘g’, ‘v’, ‘v’, ‘r’, ‘t’, ‘b’, ‘y’, ‘t’, ‘2’, ‘3’, ‘6’, ‘8’, ‘9’, ‘p’, ‘o’]]
#统计字符串长度
print(len(Stand_list))
–out
30
#去重字符串中字符
rows_list=len(Stand_list)
cloumns_list=[]
for i in Stand_list:
for j in i:
cloumns_list.append(j)
cloumns_list=list(set(cloumns_list))
print(cloumns_list)
–out
[‘g’, ‘y’, ‘l’, ‘p’, ‘d’, ‘6’, ‘8’, ‘9’, ‘u’, ‘h’, ‘7’, ‘x’, ‘t’, ‘k’, ‘b’, ‘v’, ‘3’, ‘o’, ‘r’, ‘f’, ‘2’, ‘z’,
‘c’, ‘j’, ‘a’, ‘n’, ‘s’, ‘i’]
#计算字符数量
cloumns_l=len(cloumns_list)
print(cloumns_l)
–out
28
#利用pandas生成DataFrame数据,生成30行,28列的一组全是0的二维数据,列索引用我们去重后的字母
df=pd.DataFrame(np.zeros(rows_list*cloumns_l).reshape(rows_list,cloumns_l),index=range(rows_list),columns=cloumns_list)
print(df)
g y l p d 6 8 … z c j a n s i
0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
6 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
7 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
8 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
9 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
10 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
11 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
12 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
13 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
14 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
15 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
16 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
17 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
18 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
19 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
20 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
21 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
22 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
23 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
24 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
25 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
26 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
27 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
28 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
29 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0 0.0 0.0 0.0
#字符串列表中出现的字符在相应的列赋值为1,便于我们统计出现的次数
for i in range(df.shape[0]):
print(Stand_list[i])
for j in Stand_list[i]:
print(j)
df.loc[[i],[j]]=1
print('填充')
print(df)
–out
g y l p d 6 8 … z c j a n s i
0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 … 0.0 0.0 0.0 1.0 1.0 0.0 0.0
1 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
2 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
3 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
4 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 1.0 1.0 0.0 0.0 0.0 1.0 1.0
5 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
6 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
7 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
8 1.0 0.0 1.0 0.0 1.0 0.0 0.0 … 0.0 0.0 0.0 1.0 1.0 0.0 0.0
9 1.0 0.0 1.0 0.0 1.0 0.0 0.0 … 0.0 0.0 0.0 1.0 1.0 0.0 0.0
10 1.0 0.0 1.0 0.0 1.0 0.0 0.0 … 0.0 0.0 0.0 1.0 1.0 0.0 0.0
11 0.0 1.0 0.0 0.0 1.0 1.0 0.0 … 1.0 1.0 0.0 1.0 1.0 1.0 0.0
12 0.0 1.0 0.0 0.0 1.0 1.0 0.0 … 1.0 1.0 0.0 1.0 1.0 1.0 0.0
13 1.0 0.0 1.0 0.0 1.0 0.0 0.0 … 0.0 0.0 0.0 1.0 1.0 0.0 0.0
14 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
15 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
16 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
17 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
18 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 1.0 1.0 0.0 0.0 0.0 1.0 1.0
19 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
20 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
21 0.0 1.0 0.0 0.0 1.0 1.0 0.0 … 1.0 1.0 0.0 1.0 1.0 1.0 0.0
22 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
23 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
24 1.0 1.0 0.0 0.0 1.0 0.0 0.0 … 0.0 1.0 1.0 0.0 0.0 1.0 0.0
25 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 1.0 1.0 0.0 0.0 0.0 1.0 1.0
26 0.0 0.0 0.0 0.0 0.0 0.0 0.0 … 1.0 1.0 0.0 0.0 0.0 1.0 1.0
27 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
28 1.0 0.0 1.0 0.0 1.0 0.0 0.0 … 0.0 0.0 0.0 1.0 1.0 0.0 0.0
29 1.0 1.0 1.0 1.0 1.0 1.0 1.0 … 0.0 0.0 0.0 1.0 0.0 0.0 0.0
#统计数据
df_count=df.sum(axis=0)
print(df_count)
–out
g 23.0
y 20.0
l 14.0
p 8.0
d 26.0
6 11.0
8 8.0
9 8.0
u 7.0
h 26.0
7 3.0
x 7.0
t 17.0
k 15.0
b 18.0
v 14.0
3 8.0
o 8.0
r 24.0
f 30.0
2 12.0
z 7.0
c 16.0
j 9.0
a 17.0
n 9.0
s 16.0
i 4.0
dtype: float64
#由低到高进行排序
df_count=df_count.sort_values(ascending=True)
print(df_count)
–out
7 3.0
i 4.0
u 7.0
z 7.0
x 7.0
p 8.0
8 8.0
9 8.0
o 8.0
3 8.0
n 9.0
j 9.0
6 11.0
2 12.0
l 14.0
v 14.0
k 15.0
s 16.0
c 16.0
t 17.0
a 17.0
b 18.0
y 20.0
g 23.0
r 24.0
h 26.0
d 26.0
f 30.0
dtype: float64
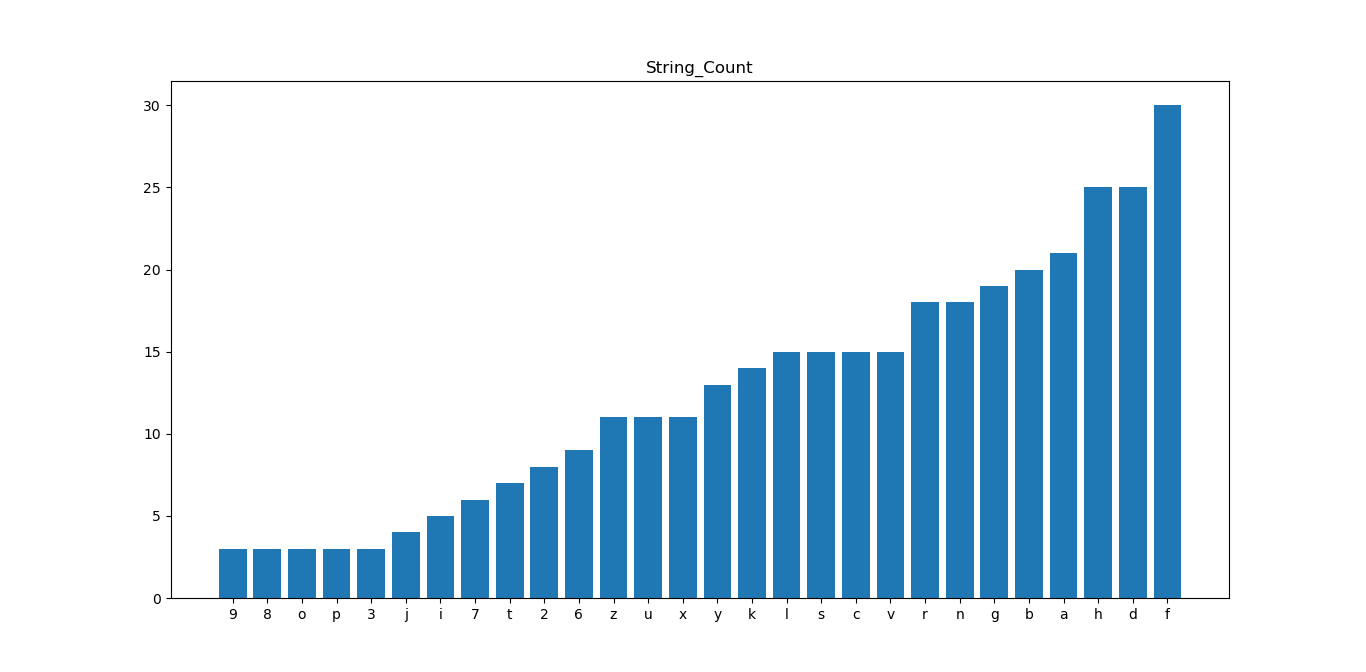
#可视化处理
plt.figure(figsize=(18,8))
plt.title(‘String_Count’)
plt.bar(df_count.index,df_count.values)
plt.show()
#最终效果
最后
以上就是无心自行车最近收集整理的关于Numpy、Pandas、Matplotlib随机字符串的统计可视化的全部内容,更多相关Numpy、Pandas、Matplotlib随机字符串内容请搜索靠谱客的其他文章。








发表评论 取消回复