目录
一、MySQL性能
1、数据库查询效率低下
2、执行次数比较多的语句
1.执行次数比较多的语句分类
2.查询累计插入和返回数据条数
3、sql批量插入及语句的执行效率
二、索引
1、MySQL索引分类
2、MySQL索引
1.创建索引
2.在已有表的字段上修改表时指定
3.建表时指定索引
4.查看与删除索引
5.索引的优缺点
6.索引创建原则(面试)
7.索引的数据结构
三、视图
1、视图应用与创建
1.视图概述
2.使用场景:
3.视图和表的区别
4.视图的优点
2、视图修改,查看与删除
1.视图修改
2.查看视图
3.删除视图
3、视图应用场景及好处
四、触发器(留存日志)
1、触发器概述
2、创建触发
3、触发器查看与删除
1)查看触发器
2) 删除触发器
一、MySQL性能
1、数据库查询效率低下
要提高操作数据库的性能,有如下两种方式:
1.硬优化:就是软优化之后性能还很低,只能采取硬优化,最后的步骤了,就是公司花钱购买服务器。在硬件上进行优化。
2.软优化: 在操作和设计数据库方面上进行优化(重点)(表结构和sql语句)
2、执行次数比较多的语句
1.执行次数比较多的语句分类
1)查询密集型
2)修改密集型 es solor
2.查询累计插入和返回数据条数
show global status like 'Innodb_rows%';3、sql批量插入及语句的执行效率
千万级别数据,十分钟左右
-- 1. 准备表
CREATE TABLE user(
id INT,
username VARCHAR(32),
password VARCHAR(32),
sex VARCHAR(6),
email VARCHAR(50)
);
-- 2. 创建存储过程,实现批量插入记录
DELIMITER $$ -- 声明存储过程的结束符号为$$
-- 可以将下面的存储过程理解为java中的一个方法,插入千万条数据之后,在调用存储过程
CREATE PROCEDURE auto_insert()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION; -- 开启事务
WHILE(i<=10000000)DO
INSERT INTO user VALUES(i,CONCAT('dijia',i),MD5(i),'male',CONCAT('dijia',i,'@ultraman.cn'));
SET i=i+1;
END WHILE;
COMMIT; -- 提交
END$$ -- 声明结束
DELIMITER ; -- 重新声明分号为结束符号
-- 3. 查看存储过程
SHOW CREATE PROCEDURE auto_insert;
-- 4. 调用存储过程
CALL auto_insert();二、索引
Mysql官方对索引的定义为:索引(index)是帮助Mysql高效获取数据的数据结构。
可以得到索引的本质:索引就是数据结构;
1、MySQL索引分类
* 主键(约束)索引
主键约束+提高查询效率
* 唯一(约束)索引
唯一约束+提高查询效率
* 普通索引
仅提高查询效率
* 组合(联合)索引
多个字段组成索引
[联合主键索引
联合唯一索引
联合普通索引]
* 全文索引
solr、es
* hash索引
根据key-value 效率非常高
等值查询,不适合范围查询 2、MySQL索引
1.创建索引
-- 创建普通索引
create index 索引名 on 表名(字段);
-- 创建唯一索引
create unique index 索引名 on 表名(字段);
-- 创建普通组合索引
create index 索引名 on 表名(字段1,字段2,..);
-- 创建唯一组合索引
create unique index 索引名 on 表名(字段1,字段2,..);说明:
1.如果在同一张表中创建多个索引,要保证索引名是不能重复的
2.上述创建索引的方式比较麻烦,还需要指定索引名
3.采用上述方式不能添加主键索引
2.在已有表的字段上修改表时指定
此时增加的索引名就是字段名字。
-- 添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
alter table 表名 add primary key(字段); --默认索引名:primary
-- 添加唯一索引(除了NULL外,NULL可能会出现多次)
alter table 表名 add unique(字段); -- 默认索引名:字段名
-- 添加普通索引,索引值可以出现多次。
alter table 表名 add index(字段); -- 默认索引名:字段名
ALTER TABLE 表名 ADD INDEX/KEY index(字段1,字段2,......字段N);
需求1:1.指定id为主键索引
alter table student2 add primary key(id);
需求2:指定name为普通索引
alter table student2 add index(name);
需求3:指定telephone为唯一索引
alter table student2 add unique(telephone);3.建表时指定索引
-- 创建学生表
CREATE TABLE student3(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引
name VARCHAR(32),
telephone VARCHAR(11) UNIQUE, -- 唯一索引
INDEX(name) -- 普通索引
);4.查看与删除索引
查看索引
show index from 表名;
删除索引
-- 两种方式
-- 方式1:直接删除
drop index 索引名 on 表名;
-- 方式2:-- 修改表时删除
alter table 表名 drop index 索引名;5.索引的优缺点
1)优势
- 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
- 索引底层就是排序,通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
2)劣势
-
在数据库建立过程中,需花费较多的时间去建立并维护索引,特别是随着数据总量的增加,所花费的时间将不断递增(在海量数据前提下,创建索引成本高)。
-
在数据库中创建的索引需要占用一定的物理存储空间,这其中就包括数据表所占的数据空间以及所创建的每一个索引所占用的物理空间(会额外占用磁盘空间)。
-
在对表中的数据进行修改时,例如对其进行增加、删除或者是修改操作时,索引还需要进行动态的维护,这给数据库的维护速度带来了一定的麻烦(维护成本高)。
6.索引创建原则(面试)
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高效的使用索引。
1. 字段内容可识别度不能低于70%,字段内数据唯一值的个数不能低于70%
例如:一个表数据只有50行,那么性别和年龄哪个字段适合创建索引,明显是年龄,因为年龄的唯一值个数比较多,性别只有两个选项。
select count(*) from student3;-- 8
select count(distinct name) from student3;
select (select count(distinct name) from student3)/(select count(*) from student3)2. 经常使用where条件搜索的字段,例如user表的id name等字段。
3. 经常使用表连接的字段(内连接、外连接),可以加快连接的速度。
4. 经常排序的字段 order by,因为索引已经是排过序的,这样一来可以利用索引的排序,加快排序查 询速度。
5.空间原则(字段占用空间越小也好)
* 注意: 索引并不是越多越好,因为索引的建立和维护都是需要耗时的 创建表时需要通过数据库去维护索引,添加记录、更新、修改时,也需要更新索引,会间接影响数据库的效率。
7.索引的数据结构
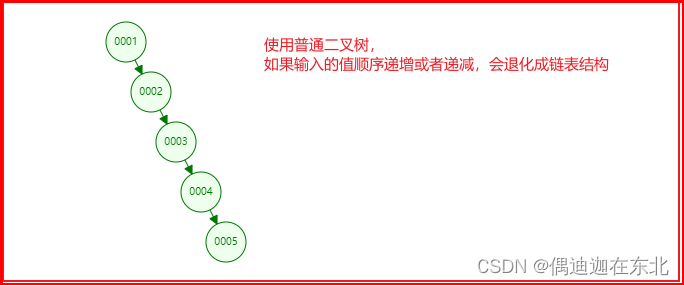
1)二叉查找树
左边的子节点比父节点小,右边的子节点比父节点大;
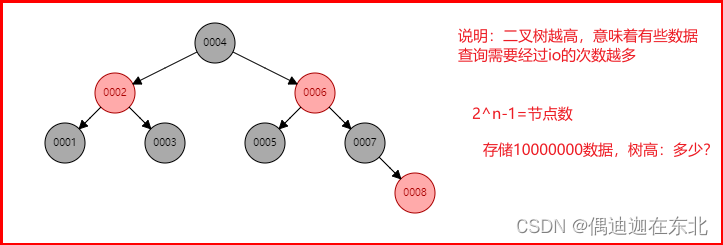
2)红黑树
平衡二叉树(左旋、右旋、变色),说明:存储千万数据,树高大约为23;
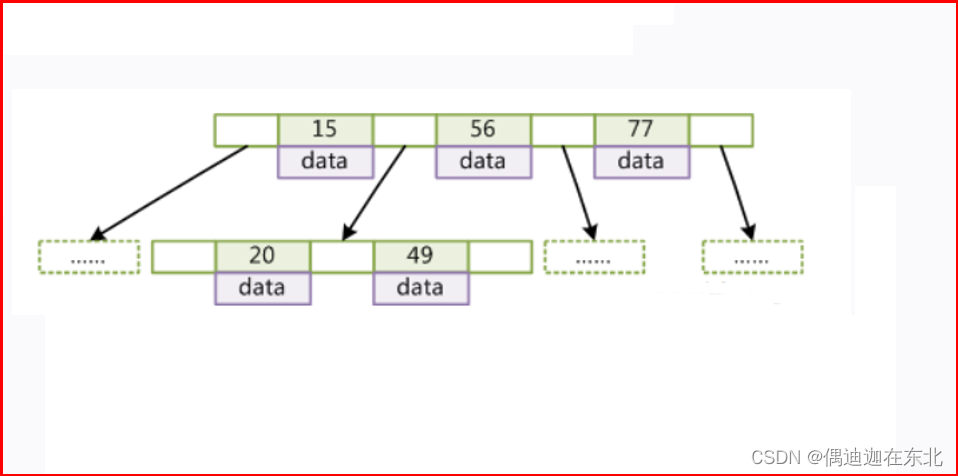
3)BTree
从结构树看,树的高度就是查询数据时的最多IO次数,如将树的高度压低则需将每个节点存储的数据尽量多一些。
多路平衡搜索树;
说明:数据库一个节点16KB,每个节点的元素由索引(8字节),指针域(6个字节),数据组成(比如1kb),存储千万数据树高接近6;
如果存储的数据占1kb,那么每个节点存储的元素个数是15个元素,那么如果存储1000w数据树高多少?6
如何进一步降低树的高度及优化查询?
1)数据查询的过程中,有一些数据data的加载时没有意义且浪费磁盘io;
2)如果要进行范围查询,那么需要反复从根节点读取数据;
4)B+Tree
B+tree将树分为叶子节点和非叶子节点,其中非叶子节点只存储索引+指针,不存储数据,而叶子节点存储索引+指针域+数据;
如果一个B+tree的树高时3的话,那么非叶子节点2层,叶子节点1层;
非叶子节点两层:1170个元素,如果是两层,那么元素数量:1170*1170=1,368,900
叶子节点:因为包含索引+指针域+数据 -----16*1.24/(8+6+1025)=15
总共:1,368,900*15=20,533,500
优化BTree(非叶子节点:索引+指针、叶子节点:索引+数据【地址】);
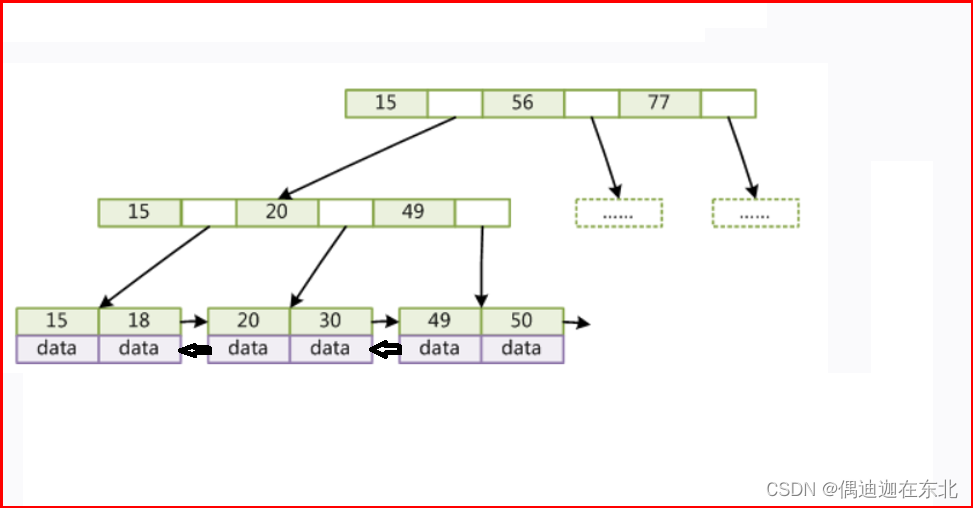
说明:b+tree通过非叶子节点不存储数据,进一步降低了树的高度;
通过叶子节点之间维护了指针双向指向,提高了区间的访问能力;
存储2千w数据,树高维护在3左右!
5)MySQL中的B+Tree
-- 查看mysql索引节点大小
show global status like 'innodb_page_size'; -- 16kb
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
三、视图
数据:
创建国家和城市表。
1. 1个国家有多个城市,一个城市只属于一个国家
2. 国家和城市是:1对多
CREATE TABLE country (
country_id int(11) PRIMARY KEY AUTO_INCREMENT,
country_name varchar(100) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE city (
city_id int(11) PRIMARY KEY AUTO_INCREMENT,
city_name varchar(50) NOT NULL,
country_id int(11) NOT NULL,
constraint ref_country_fk foreign key(country_id) references country(country_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into country values(1,'China');
insert into country values(2,'America');
insert into country values(3,'Japan');
insert into country values(4,'UK');
insert into city values(1,'西安',1);
insert into city values(2,'NewYork',2);
insert into city values(3,'北京',1);
insert into city values(4,'上海',1);1、视图应用与创建
1.视图概述
(View)是一种虚拟存在的表,行和列的数据来源于定义视图的查询中使用的表,并且是在使用视图时动态生成的。视图和普通表一样使用,但是视图并不存储数据。通俗的讲,视图就是一条SELECT语句执行后返回的结果集。
2.使用场景:
多个地方用到同样的查询结果,该查询结果使用的sql语句较复杂
创建视图的语法格式:
create view 视图名 as 查询语句;
需求:查看所有国家和对应城市的信息
create view country_view as select country.*,city.city_id,city.city_name from city,country where city.country_id=country.country_id;3.视图和表的区别
使用方式 占用物理空间
视图 完全相同 视图中的数据不保存,仅保存sql逻辑,磁盘上只有表结构无数据
表 完全相同 占用
4.视图的优点
1)提高sql语句重用性,效率高(避免sql语句多次编译)
2)和表实现了分离,提高了安全性,使用视图的用户只能访问他们被允许查询的结果集
2、视图修改,查看与删除
1.视图修改
1)创建过程覆盖旧的视图,达到修改的操作
说明:如果存在该视图名就是修改视图,如果不存在该视图名则创建视图。
create or replace view 视图名
as
查询语句;
说明:如果存在该视图名就是修改视图,如果不存在该视图名则创建视图。
需求:修改上述视图city_country_view,select语句变为查询城市名是上海的城市信息和所属国家信息
create or replace view country_view as
select country.*,city.city_id,city.city_name
from city,country
where city.country_id=country.country_idand country.country_id=1;
-- create or replace:表示如果视图存在则replace替换,不存在则create创建;2)使用alter修改
alter view 视图名 as 查询语句;
需求:修改上述视图city_country_view,select语句变为查询城市名是北京的城市信息和所属国家信息
alter view country_view2 as
select country.*,city.city_id,city.city_name from city,country
where city.country_id=country.country_id and country.country_id=2;2.查看视图
查看视图指令与table指令格式一致.
show tables;
desc country_view;
show create table country_view;3.删除视图
drop view 视图名,视图名,.....;
需求:删除 country_view视图
drop view country_view;3、视图应用场景及好处
场景:
1)多场景使用相同且非常复杂的查询sql;
2)在一些数据敏感,涉及到安全的场景;
3)网络访问密集的场景(减少网络io开销)
好处:
1)提高sql的复用性;
2)提高数据的安全性;
3)减少网络io开销
四、触发器(留存日志)
1、触发器概述
1.触发器主要是通过事件进行触发而被执行的,我们可以在修改数据的前后绑定事件,触发执行定义的SQL;
2.触发器是与表有关的数据库对象,指在 insert/update/delete 之前或之后,触发并执行触发器中定义的SQL语句集合。
3.使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。
说明:OLD表示操作前的对象,NEW 表示操作之后的对象。
| 触发器类型 | NEW 和 OLD的使用 |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据,插入之前没有数据,所以不能使用OLD |
| UPDATE 型触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据,删除之后没有数据了,所以不能使用NEW |
2、创建触发
-- 语法
create trigger 触发器名
before/after insert/update/delete
on 表名
for each row -- 行级触发器
trigger_stmt ;
说明:
1)before/after位置称为触发时机,一个触发器只能选择一个
2)insert/update/delete位置称为触发事件,一个触发器只能选择一个
3)for each row称为行级触发器,触发器绑定实质是表中的所有行,因此当每一行发生指定改变的时候,就会触发触发器。数据准备:
-- 创建员工表,员工信息
create table emp(
id int primary key auto_increment,
name varchar(30) not null,
age int,
salary int
);
insert into emp(id,name,age,salary) values(null, '金毛狮王',40,2500);
insert into emp(id,name,age,salary) values(null, '青翼蝠王',38,3100);
-- 创建一张日志表,存放日志信息
create table emp_logs(
id int(11) primary key auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作表的ID,emp表数据的id',
operate_params varchar(500) comment '操作参数,插入emp中的数据'
)engine=innodb default charset=utf8;创建 update 型触发器,完成更新数据时的日志记录
-- 需求2:创建 update 型触发器,完成更新数据时的日志记录
create trigger emp_trigger
after update on emp
for each row
insert into emp_logs values(null,'update',now(),old.id,concat('更新之前:',old.id,old.name,old.age,old.salary,'更新之后:',new.id,new.name,new.age,new.salary));
-- 测试
update emp set name='紫衫龙王',age=18,salary=10000 where id=2;3、触发器查看与删除
1)查看触发器
可使用指令或者可视化工具查看触发器;
SHOW TRIGGERS;2) 删除触发器
drop trigger trigger_name ;最后
以上就是执着便当最近收集整理的关于java回顾:MySQL性能、索引、视图(虚拟查询表)、触发器(可留存日志)一、MySQL性能二、索引三、视图四、触发器(留存日志)的全部内容,更多相关java回顾内容请搜索靠谱客的其他文章。








发表评论 取消回复