
开始前,先附上Mathwork强化学习Toolbox介绍的官方页面;
- https://ww2.mathworks.cn/products/reinforcement-learning.html
- Brain大佬真传:https://www.youtube.com/watch?v=Wypc1a-1ZYA&list=PLn8PRpmsu08rVoOEEaF3xtSQCLg4E0rtK&index=4
怀着敬畏之心,我决定尝试一些Matlab大法的官方的强化学习demo,体验一下这种丝滑流畅的感觉;
第一个demo是一个双足机器人,采用的势Simscape和Multibody进行建模,用DDPG与TD3智能体进行测试,对性能进行比较;首先对这两种算法进行简单的介绍:
1. 关于DDPG(Deep Determinisitic Policy Gradient Agents)
这个算法在无人机、无人船、水下、多足等机器人场景中已经有着广泛的应用,其可以学习连续动作,而且确定性的策略非常容易去学。关键点如下:
- 动作空间连续,状态空间连续或者离散场景;
- 在每个训练步骤使用随机噪声模型扰动策略所选择的动作(OU-Noise);
- 经验池重放;
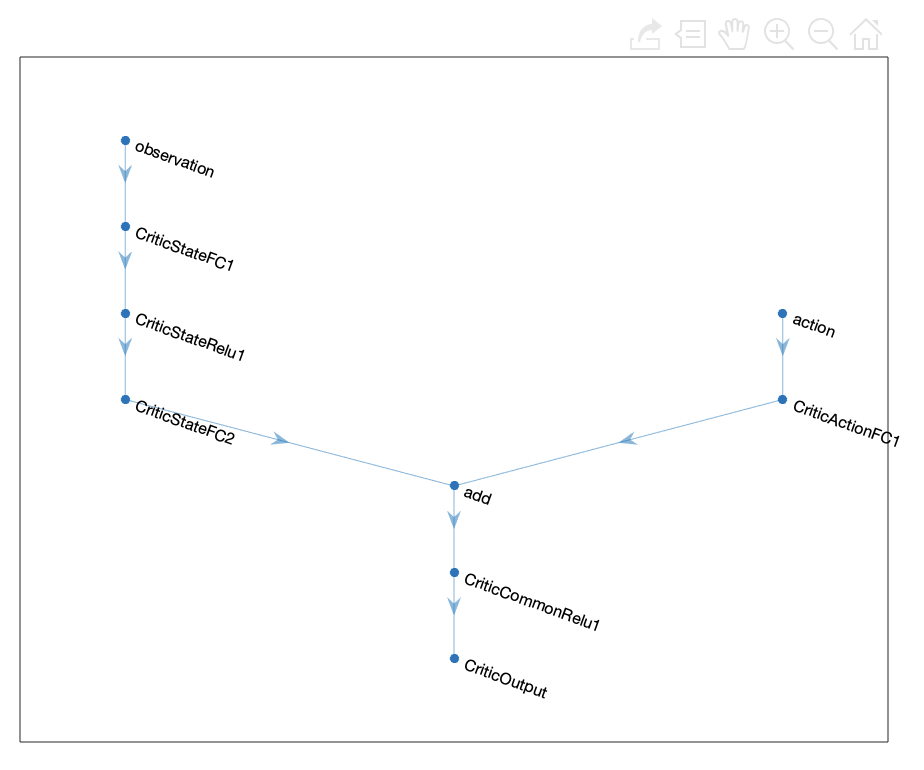
- 两套Actor与Critic网络,目标网络用于计算TD error;
- Critic作用预估Q而不是V;Actor输出确定动作非概率分布,该动作可获得最大Q;
- 目标网络软更新;
- offline policy;
2. 关于TD3(Twin-Delayed Deep Deterministic Policy Gradient Agents)
- 之于DDPG就像Double DQN之于DQN;
- 避免对于Q值得过高估计;
- 一共有6个网络,Criticx2, Actorx1, Target Criticx2, Target Actorx1;
两种agents都在具有相同模型参数的Biped机器人环境上进行训练,并有共同的初始条件策略、相同Actor和Critic的网络架构、相同的训练参数配置(采样时间、折扣因子、mini-batch尺寸、经验池buffer大小、exploration noise..)
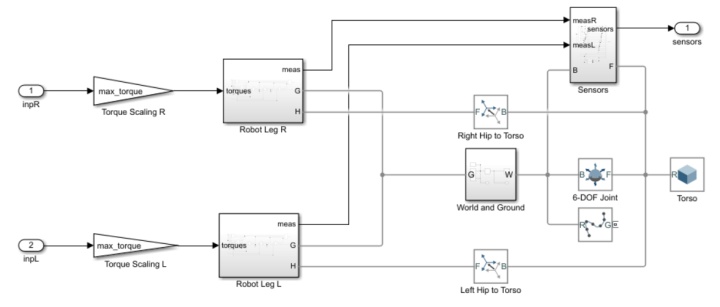
双足机器人如下:Hip joint大腿髋关节、Knee joint膝盖、Ankle joint 脚踝关节
动作空间是6个关节扭矩;状态空间包括躯干位置(Y,Z)、速度(X,Y,Z)、姿态((Yaw,Pitch,Roll)、角速度(p,q,r)、两腿3个Joint的角位置与速度(12)、上一时刻扭矩指令(6)共29个状态;
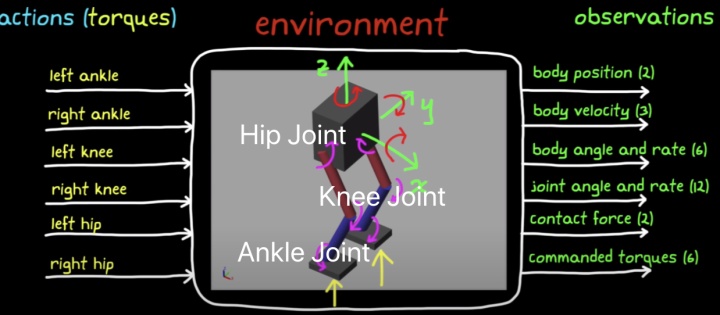
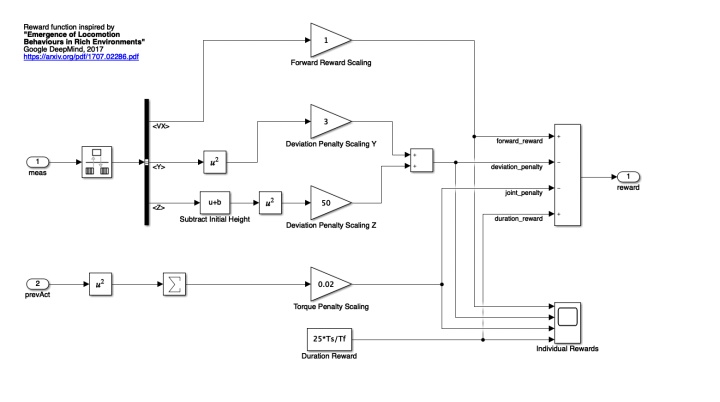
训练目标——让这个Biped Robot以最小的控制效果下学会走直线...为了完成目标,设置如下奖励函数:
其中:第一项是对于前进速度的奖励;第二项是对偏离x正方向的惩罚;第三项是防止机器人跳起;第四项是对每一时间步的微小奖励(总得给点...);第五项目的是尽量让输入最小。
看一下官方给的demo:
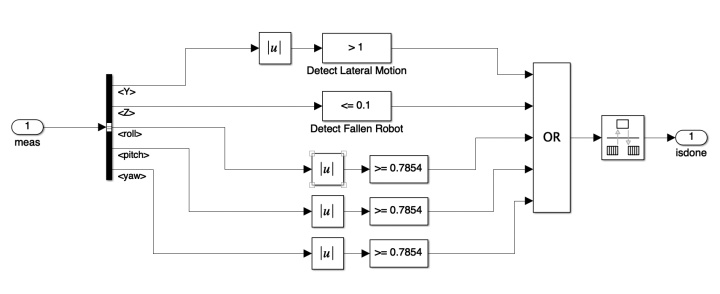
每个episode终止条件有以下几个:
- 机器人躯干质心在Z方向上小于0.1 m(摔倒了),在Y方向上大于1 m(跑偏了)。
- 滚动roll,俯仰pitch或偏航yaw的绝对值都大于0.7854弧度。
- 达到自然的终止点(episodes限置)
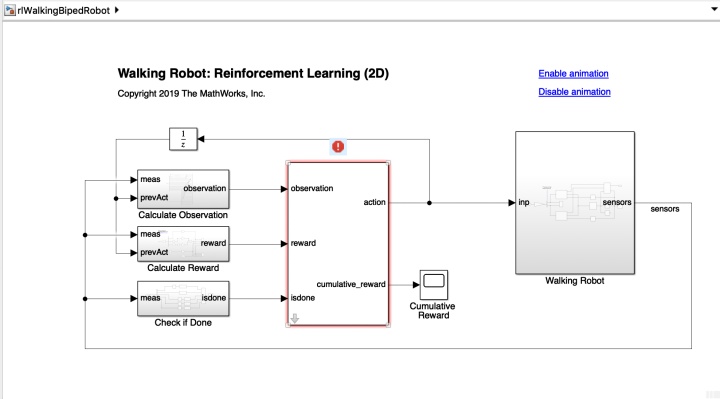
Simulink架构:
这个框架图非常舒服,更加直观的展示了使用tensorflow或者pytorch时智能体与环境交互的框架结构。
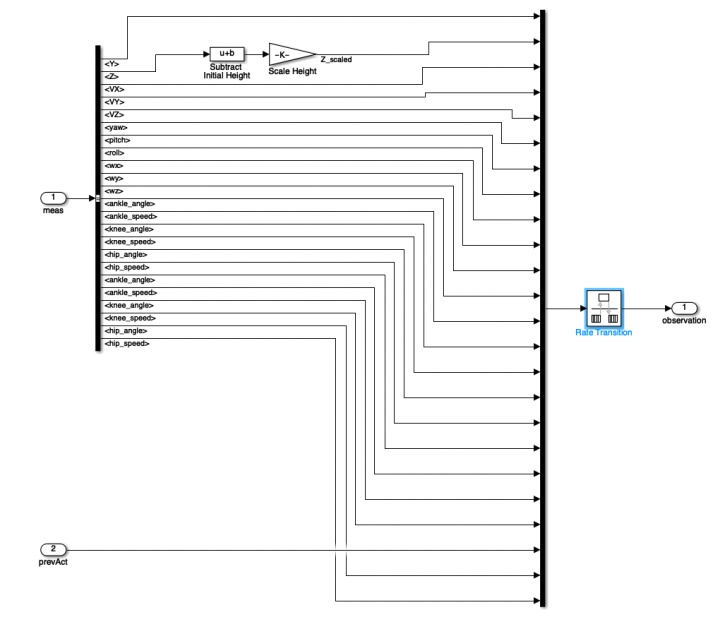
%% 状态配置
学习曲线:
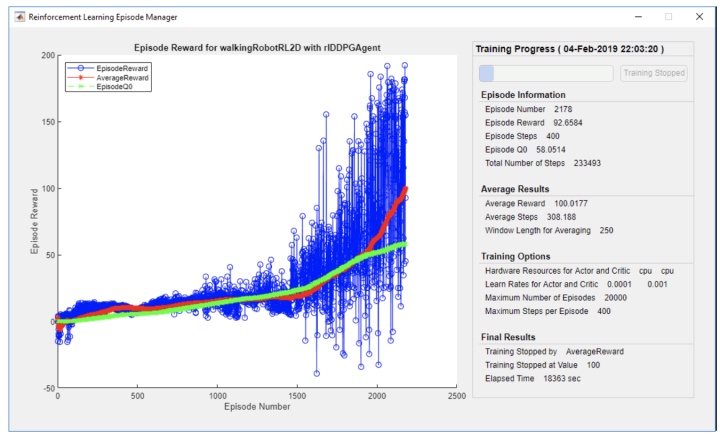
comparePerformance('DDPGAgent','TD3Agent')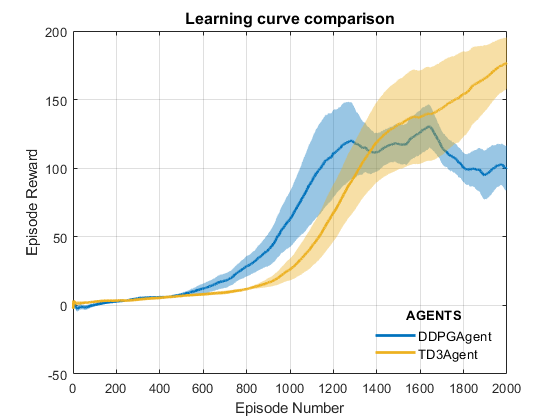
matlab虽好,但是指不定哪天就用不上了... 且用且珍惜啊...
REF
张斯俊:一文带你理清DDPG算法(附代码及代码解释)zhuanlan.zhihu.com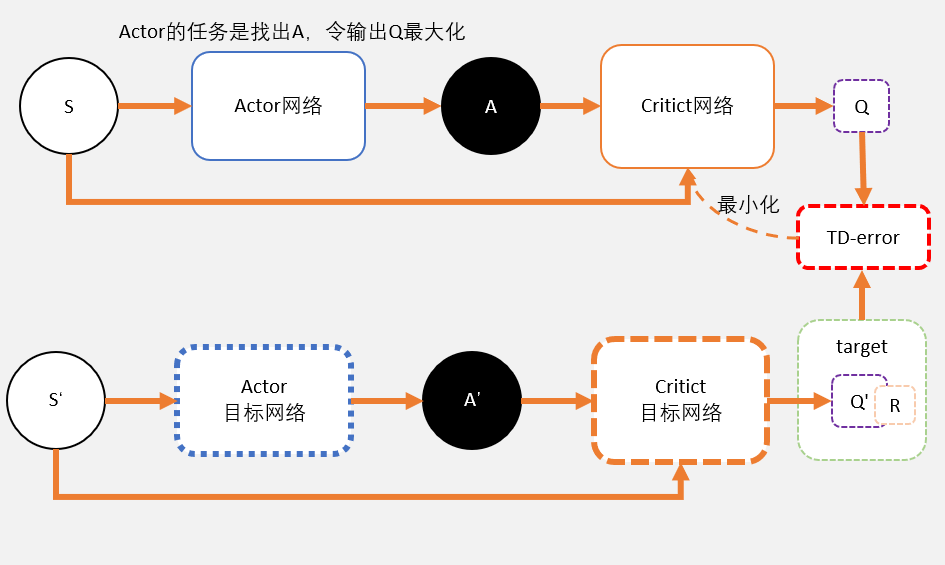
最后
以上就是开朗机器猫最近收集整理的关于matlab工具箱_MATLAB大法好---强化学习工具箱探索的全部内容,更多相关matlab工具箱_MATLAB大法好---强化学习工具箱探索内容请搜索靠谱客的其他文章。








发表评论 取消回复