目录(点击可跳转)
- PaddleDetection挑战赛参赛心得分享
- 1 比赛介绍
- CVPR2020比赛:商超检测基线
- 基线方案介绍
- 2 比赛历史提交记录
- 3 推进心得
- 3.1 PD挑战赛_V1.0版本:Baseline基线代码测试
- 3.2 PD挑战赛_V2.1版本:PP-YOLO_r18vd模型测试
- 3.3 PD挑战赛_V2.3版本:6500iter恢复训练
- 3.4 PD挑战赛_V2.3.1版本:8000iter恢复训练
- 4 结语
PaddleDetection挑战赛参赛心得分享
飞桨开发者&百度飞桨官方帮帮团萌新:Kevin Pang
1 比赛介绍
CVPR2020比赛:商超检测基线
本项目基于深度学习平台飞桨(PaddlePaddle),利用一键式目标检测开发套件PaddleDetection进行开发,欢迎使用并star。
基线方案介绍
本基线用于检测密集场景中产品的位置。基于飞桨推出的端到端目标检测开发套件PaddleDetection进行二次开发,PaddleDetection提供了丰富的检测模型,包含目标检测、实例分割、人脸检测等100+个预训练模型,涵盖多种数据集竞赛冠军方案,同时还具备了高灵活度,通过模块化的设计解藕各个组建,基于配置文件即可轻松搭建各种检测模型。本基线对商超检测数据集进行读取和评估,采用faster_rcnn算法,ResNet50_vd作为主干网络,引入FPN模块,在测试集上检测的AP@.50:.05:.95达到0.382,AP@0.5达到0.599,AP@0.75达到0.440。可以选择PaddleDetection中提供的大量主干网络优化精度,也可以尝试PaddleDetection已具备的扩展特性进一步提升模型效果,例如group_norm, Modulated Deformable Convolution等,更多模型可以参考MODEL_ZOO文档。
| 基线方案 | 算法 | AP@.50:.05:.95 | AP@0.5 | AP@0.75 | 备注 |
|---|---|---|---|---|---|
| 检测 | faster_rcnn + ResNet50_vd + FPN | 0.332 | 0.574 | 0.352 | 基于PaddleDetection进行二次开发 |
2 比赛历史提交记录
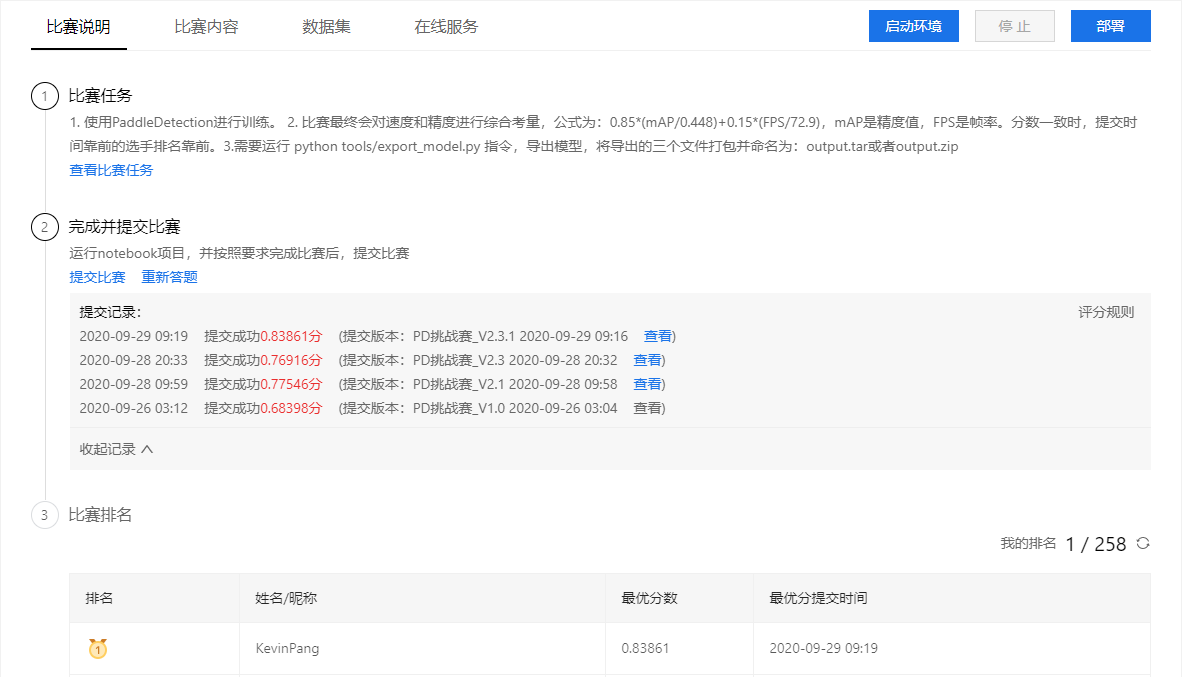
3 推进心得
这部分我就按我的版本推进时间轴来进行分享~
3.1 PD挑战赛_V1.0版本:Baseline基线代码测试
# 训练:“-c”选择你要使用的模型,此处是默认的“faster_rcnn_r50_1x.yml”
!python tools/train.py -c configs/faster_rcnn_r50_1x.yml
# 评估:model_final可按需更改模型文件
!python tools/eval.py -c configs/faster_rcnn_r50_1x.yml
-o weights=output/faster_rcnn_r50_1x/model_final
# 导出:按比赛要求使用“export_model.py”将模型导出
!python tools/export_model.py -c configs/faster_rcnn_r50_1x.yml
-o weights=output/faster_rcnn_r50_1x/model_final
# 压缩:将导出的模型文件按比赛要求进行压缩
%cd output/faster_rcnn_r50_1x/
!zip output.zip __model__ __params__ infer_cfg.yml
系统评分:0.68398分
3.2 PD挑战赛_V2.1版本:PP-YOLO_r18vd模型测试
# 训练:“-c”选择你要使用的模型,此处已切换为“ppyolo_r18vd.yml”
!python tools/train.py -c configs/ppyolo/ppyolo_r18vd.yml
# 评估:model_final可按需更改模型文件
!python tools/eval.py -c configs/ppyolo/ppyolo_r18vd.yml
-o weights=output/ppyolo_r18vd/model_final
# 导出:按比赛要求使用“ppyolo_r18vd.py”将模型导出
!python tools/export_model.py -c configs/ppyolo/ppyolo_r18vd.yml
-o weights=output/ppyolo_r18vd/model_final
# 压缩:将导出的模型文件按比赛要求进行压缩
%cd output/ppyolo_r18vd/
!zip output.zip __model__ __params__ infer_cfg.yml
系统评分:0.77546分
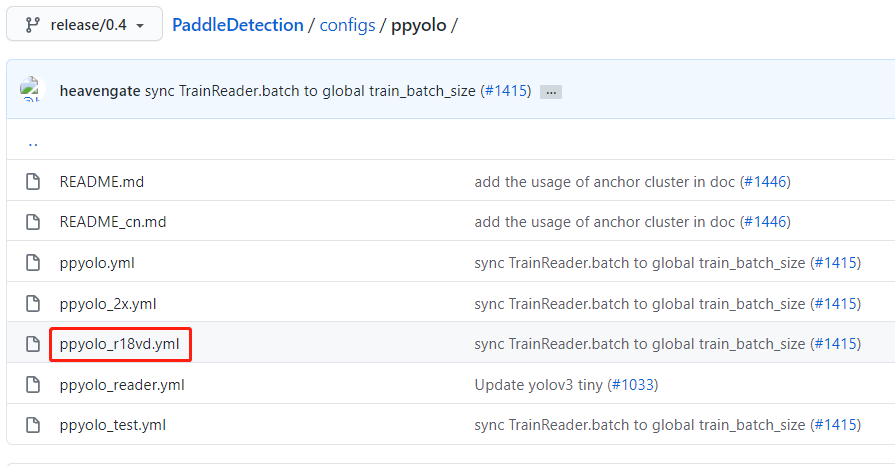
PaddleDetection中ppyolo的地址:https://github.com/PaddlePaddle/PaddleDetection/tree/release/0.4/configs/ppyolo
ppyolo的可选模型中,为什么我会选择“ppyolo_r18vd”而不是选择“ppyolo”来做此次比赛的模型呢?
主要原因就是比赛时间有限,而基于ResNet50的ppyolo的训练时长和训练配置的要求都比基于ResNet18的ppyolo_r18vd高,理论上从ResNet50虽然效果会比ResNet18更好,但相应的神经网络也更复杂。
ResNet参考论文:《Deep Residual Learning for Image Recognition》https://arxiv.org/abs/1512.03385v1
Add:
之前参加论文复现的时候,选读的3D ResNet论文的背景知识碰巧覆盖了ResNet网络,当时也顺带阅读了一些相关的paper,写了篇笔记,感兴趣的小伙伴欢迎前往考古,一起学习:https://blog.csdn.net/qq_41138197/article/details/107832207
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y5wgUf1w-1601366992621)(C:UsersKevin PangDocumentsMarkdownPaddleDetection挑战赛参赛心得.assetsimage-20200929144725064.png)]](https://www.shuijiaxian.com/files_image/2023052800/20200929161407405.png)
我也在GPU环境同参数下在ppyolo和ppyolo_r18vd各跑了20iter做测试,符合我的猜测,ResNet50训练需要的时间会更长。
综上所述,我就选择了ppyolo_r18vd这个优秀的模型~
此时,我修改的参数主要是:
milestones设置的两个节点是参考之前给出的“max_iters”的2/3和8/9。
# ppyolo_r18vd.yml
......
max_iters: 6624
snapshot_iter: 500
num_classes: 2
......
YOLOv3Loss:
batch_size: 16
......
LearningRate:
base_lr: 0.0016
......
milestones:
- 4416
- 5888
......
.....
TrainReader:
dataset:
!COCODataSet
image_dir: images
anno_path: annotations/instances_train2017.json
dataset_dir: /home/aistudio/PaddleDetection/dataset/coco
batch_size: 16
shuffle: true
mixup_epoch: 50
drop_last: true
worker_num: 8
bufsize: 8
# ppyolo_reader.yml
TrainReader:
......
dataset:
!COCODataSet
image_dir: images
anno_path: annotations/instances_train2017.json
dataset_dir: /home/aistudio/PaddleDetection/dataset/coco
......
EvalReader:
......
dataset:
!COCODataSet
image_dir: images
anno_path: annotations/instances_val2017.json
dataset_dir: /home/aistudio/PaddleDetection/dataset/coco
......
TestReader:
dataset:
!ImageFolder
anno_path: /home/aistudio/PaddleDetection/dataset/coco/annotations/instances_val2017.json
3.3 PD挑战赛_V2.3版本:6500iter恢复训练
# 训练:“-c”选择你要使用的模型,“-r”选择你要恢复训练的模型(之前训练保存的模型)
!python tools/train.py -c configs/ppyolo/ppyolo_r18vd.yml
-r output/ppyolo_r18vd/6500
# 评估:model_final可按需更改模型文件,此处因为在8000iter处中断训练了,所以我直接选择8000iter这个模型
!python tools/eval.py -c configs/ppyolo/ppyolo_r18vd.yml
-o weights=output/ppyolo_r18vd/8000
# 导出:按比赛要求使用“ppyolo_r18vd.py”将模型导出
!python tools/export_model.py -c configs/ppyolo/ppyolo_r18vd.yml
-o weights=output/ppyolo_r18vd/8000
# 压缩:将导出的模型文件按比赛要求进行压缩
%cd output/ppyolo_r18vd/
!zip output.zip __model__ __params__ infer_cfg.yml
系统评分:0.76916分

通过观察训练的结果,不难发现,目前loss值还有明显的波动,增大batch_size或者继续训练就仍有一定的提升空间。此时距离比赛截止剩下的时间也不多了,要在一天内完成更复杂的训练,全部重新训练是不现实的,因为在V100单卡环境下继续增大batch_size对目前的我来说还做不到,那么剩下的最有效方案就是恢复训练。
恰巧之前在浏览PaddleDetection官方文档时,发现有“-r”恢复训练的功能,在此前完成作业时也测试过此功能,发现确实能从指定的保存点恢复训练中的模型。于是,我就计划在V2.1的6624iter基础上进行继续训练,V2.3是我做的一个尝试,因为我不确定这样是否能得到理想的结果。所以,在V2.3中我训练到8000iter就中止训练,直接提交系统。
# ppyolo_r18vd.yml
....
max_iters: 13248
snapshot_iter: 500
num_classes: 2
......
YOLOv3Loss:
batch_size: 16
......
LearningRate:
base_lr: 0.0016
......
milestones:
- 8832
- 11776
......
.....
TrainReader:
dataset:
!COCODataSet
image_dir: images
anno_path: annotations/instances_train2017.json
dataset_dir: /home/aistudio/PaddleDetection/dataset/coco
batch_size: 16
shuffle: true
mixup_epoch: 50
drop_last: true
worker_num: 8
bufsize: 8
3.4 PD挑战赛_V2.3.1版本:8000iter恢复训练
# 训练:“-c”选择你要使用的模型,“-r”选择你要恢复训练的模型(之前训练保存的模型)
!python tools/train.py -c configs/ppyolo/ppyolo_r18vd.yml
-r output/ppyolo_r18vd/8000
# 评估:model_final可按需更改模型文件
!python tools/eval.py -c configs/ppyolo/ppyolo_r18vd.yml
-o weights=output/ppyolo_r18vd/model_final
# 导出:按比赛要求使用“ppyolo_r18vd.py”将模型导出
!python tools/export_model.py -c configs/ppyolo/ppyolo_r18vd.yml
-o weights=output/ppyolo_r18vd/model_final
# 压缩:将导出的模型文件按比赛要求进行压缩
%cd output/ppyolo_r18vd/
!zip output.zip __model__ __params__ infer_cfg.yml
系统评分:0.83861分
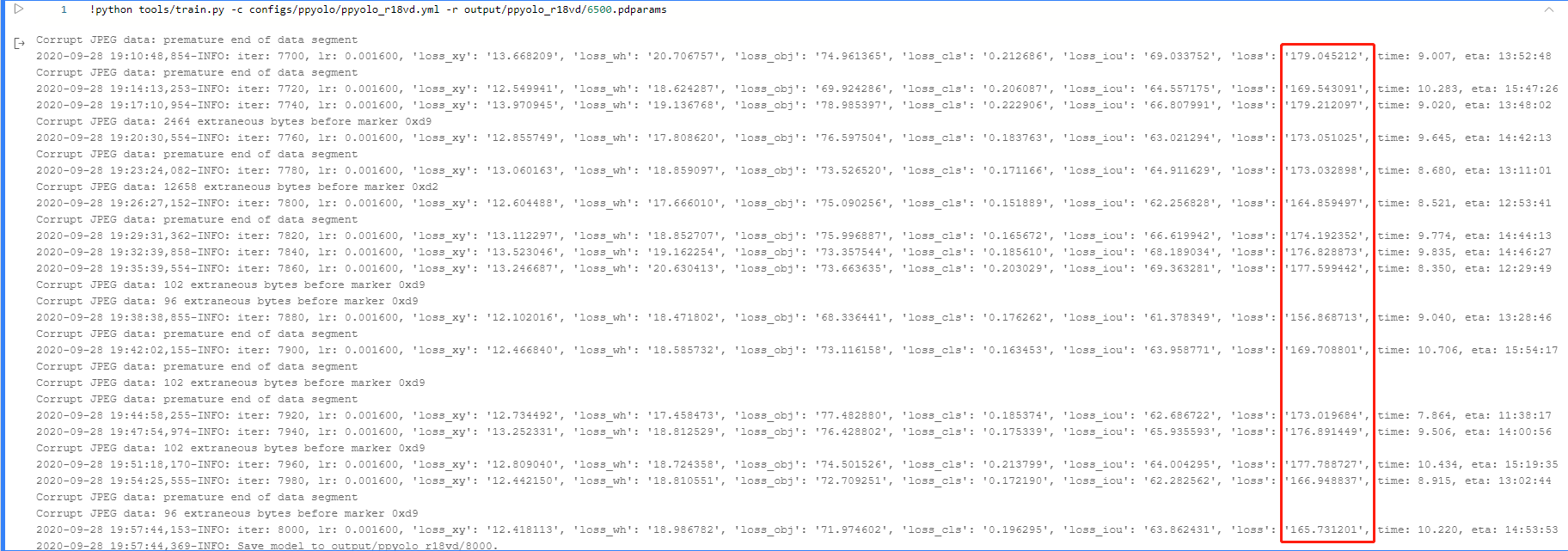
通过对V2.3的训练日志的观察,我们不难发现loss值的波动仍然存在,但有降低的趋势,这是一个好迹象,于是,提交完V2.3版本之后,我就从8000iter保存点开始恢复训练,完成13248iter中剩下的5248iter。经过一个晚上的训练,最终于9月29日上午9点06分完成中13248iter训练,得到了最终版的“model_final”模型。
需要注意的是,使用“-r”参数恢复训练时,batch_size大小是不能改动的。
4 结语
最后,十分感谢飞桨能在深度学习目标检测方向给我们免费提供这样一个宝贵的课程学习与实操训练的机会,感谢这次课程中每一位辛苦的老师与助教,还有一直以来都是如此认真负责、关心每一位同学的班班芮芮姐~
如果有小伙伴错过了此次课程,但又想回顾相关内容,可前往AI Studio平台直接查看录播,课程地址:https://aistudio.baidu.com/aistudio/education/group/info/1617
最后
以上就是优秀短靴最近收集整理的关于PaddleDetection挑战赛参赛心得分享PaddleDetection挑战赛参赛心得分享的全部内容,更多相关PaddleDetection挑战赛参赛心得分享PaddleDetection挑战赛参赛心得分享内容请搜索靠谱客的其他文章。








发表评论 取消回复