背景
由于NR中系统带宽较大(FR1最高可达100MHz,FR2最高可达400MHz),若PDCCH此时仍如LTE那般在频域上占整个带宽,不仅浪费资源,且盲检复杂度较大。因此,NR将PDCCH在频域上占用的频段和在时域上占用的OFDM符号数等信息封装在CORESET中;将PDCCH起始的OFDM符号数索引以及PDCCH监听周期等信息封装在搜索空间中。PDCCH的配置为CORESET和搜索空间的组合。
扩展:LTE系统中,PDCCH在频域上占用整个带宽,时域上占用每个子帧的前1~3个OFDM符号。
CORESET
每个小区最多可配置4个BWP,每个BWP最多可配置3个CORESET,因此每个小区最多可配置12个CORESET,其索引为0~11,由高层参数ControlResourceSetld通知给UE,该参数在一个小区内的所有BWP中式唯一的,其中CORESET0为TYPE0 PDCCH公共搜索空间(Common Search Space,CSS)。
频域
CORESET在频域上占用
N
R
B
C
O
R
E
S
E
T
N^{CORESET}_{RB}
NRBCORESET 个PRB,在频域上的位置可以灵活配置,由高层参数frequencyDomainResources通知给UE,该参数为45bit,每个bit表示一组连续的6个PRB(共270 PRB),最高bit位对应BWP中最低频率的PRB组。若某个bit=1,则表示该对应的PRB组在CORESET内,=0则不在,因此CORESET在频域上占用的PRB数
N
R
B
C
O
R
E
S
E
T
N^{CORESET}_{RB}
NRBCORESET最大取值270。
CORESET配置支持连续和离散的频域资源分配,但是配置的CORESET必须在BWP的频率范围内。不同的CORESET在频域可能存在PRB重叠,重叠的PRB无法支持不同CORESET内PDCCH的同时传输,从而会导致PDCCH的相互阻塞,为减少被阻塞的PRB,除PBCH配置的CORESET外,其他RRC信令配置的CORESET在频域上的配置使用相同的参考点。
时域
CORESET在时域上占用
N
s
y
m
b
o
l
C
O
R
E
S
E
T
N^{CORESET}_{symbol}
NsymbolCORESET(取值1/2/3)个连续的OFDM符号,在时隙中开始的位置可以配置,只有当dmrs-TypeA-Position=pos3时,才会取3值,这是因为PDCCH和PDSCH的DMRS在时域上不能重叠。
NR的PDCCH由1个或多个CCE(Control Channel Element)聚合而成,CCE的个数即聚合等级,取值为{1,2,4,8,16}之一。一个CCE由6个REG组成,一个REG在频域上占用一个RB,在时域上占用一个OFDM符号。在CORESET内,REG以时间优先的方式,按照增序进行编号,CORESET内的第一个OFDM符号、最低索引的PRB为REG0。REG如果以频率优先的方式进行编号,则一个CCE的多个REG交织之后,可能在频率上还是相邻的,达不到频率分集的效果,所以REG以时间优先的方式进行编号。PDCCH的DMRS固定在一个PRB中子载波1,5,9上。
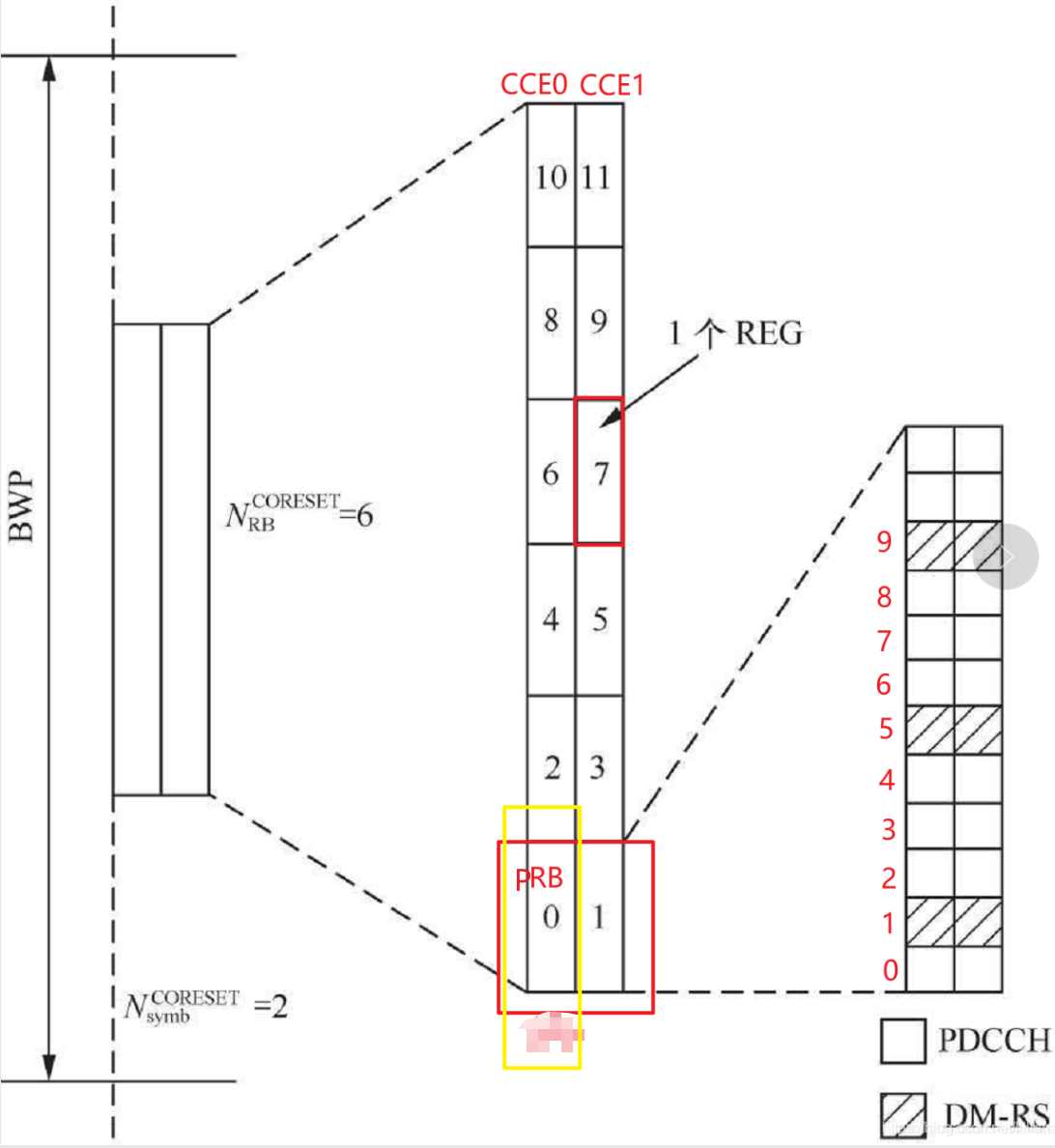
DMRS只有一个天线端口,因此PDCCH只能进行单层传输,1个PRB有12个RE,其中3个RE用于传输DMRS,剩余的9个RE用于PDCCH。由于PDCCH采用QPSK调制,所以一个REG可用的比特数是18个,1个CCE可用的比特数是18x6=108个。
NR的CORESET与LTE的PDCCH比较
两者相较,有以下6点异同。
1、LTE的PDCCH需占用整个带宽,而CORESET在频域上的位置及其所占用的PRB数可半静态配置。这是因为UE仅在激活的BWP上收发消息,因此CORESET是BWP的子集。
2、LTE的PDCCH仅配置在一个子帧的前1~3个OFDM符号上,而CORESET可以配置在时隙的任意位置。
3、LTE的PDCCH占用的OFDM符号数是动态变化的,由PCFICH通知UE。而CORESET占用的OFDM符号数是半静态配置,有利于降低PDCCH的处理时延。
4、LTE使用CRS进行信道估计来解调PDCCH,由于CRS对所有的UE都是公共的,所以不能进行波束赋形。而NR解调PDCCH时,每个PDCCH都有专用的DMRS进行信道估计,因此可以使用波束赋形以提高性能。
5、LTE的数据信道不能使用控制区域的OFDM符号,而NR通过预留资源的机制使得CORESET的资源可以被数据信道使用。
6、LTE的一个CCE映射到36个RE上,而NR的一个CCE(不含DMRS)映射到54个RE上,因为NR PDCCH上DMRS资源少于LTE CRS的个数,导致信道估计性能下降,因此需要较多的RE。
交织映射和非交织映射
在一个CORESET内,CCE到REG的映射支持交织映射和非交织映射两种方式。如果基站有下行信道的详细信息,如对于静止或者低速移动的UE,则建议使用非交织映射方式;如果基站没有下行信道的详细信息,如对于高速移动的UE则建议使用交织的映射方式以获得频率分集增益,增加传输的可靠性。
一个CORESET内CCE到REG的映射方式是唯一的,由于UE可以配置多个CORESET,因此在不同的CORESET上配不同的交织方式,在传输效率和可靠性之间取得平衡。
L个REG组成1个REG bundle,通过一个多个REG bundle实现CCE到REG的映射。两种映射方式都有具体的公式来描述其实际映射规则,此处暂不列出公式,直接以示例的形式解释两种映射规则。
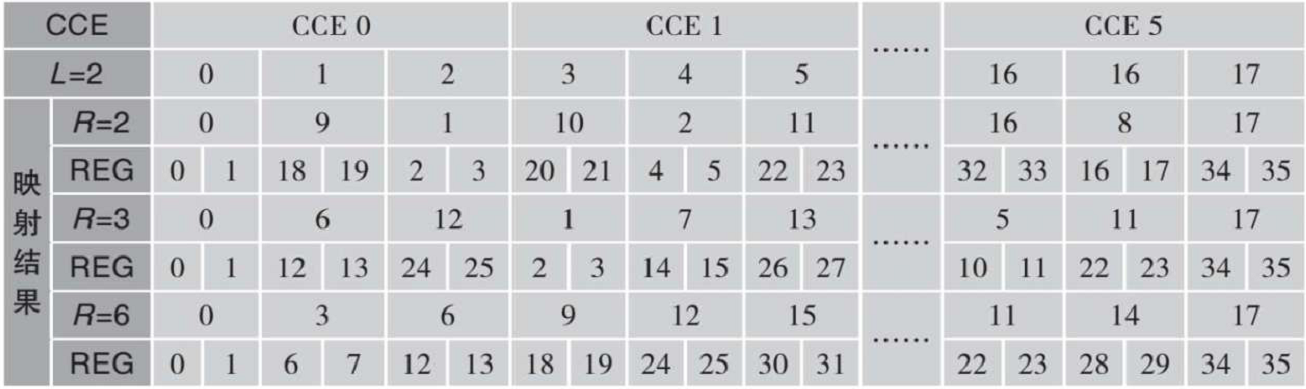
举个栗子:假设 N R B C O R E S E T N^{CORESET}_{RB} NRBCORESET=18, N s y m b o l C O R E S E T N^{CORESET}_{symbol} NsymbolCORESET=2, n s h i f t n^{}_{shift} nshift=0(映射时的偏移索引),则 N R E G C O R E S E T N^{CORESET}_{REG} NREGCORESET=18x2=36,REG的索引为0,1,…35,共有36/6=6个CCE,CCE的索引为0,1,…5。
对于非交织映射,CCE到REG的映射结果如下表所示。

交织映射
由于
N
s
y
m
b
o
l
C
O
R
E
S
E
T
N^{CORESET}_{symbol}
NsymbolCORESET=2,因此L={2,6},当L=2时,CCE到REG的交织映射结果如下表所示。R为交织深度,交织方法为行进列出。
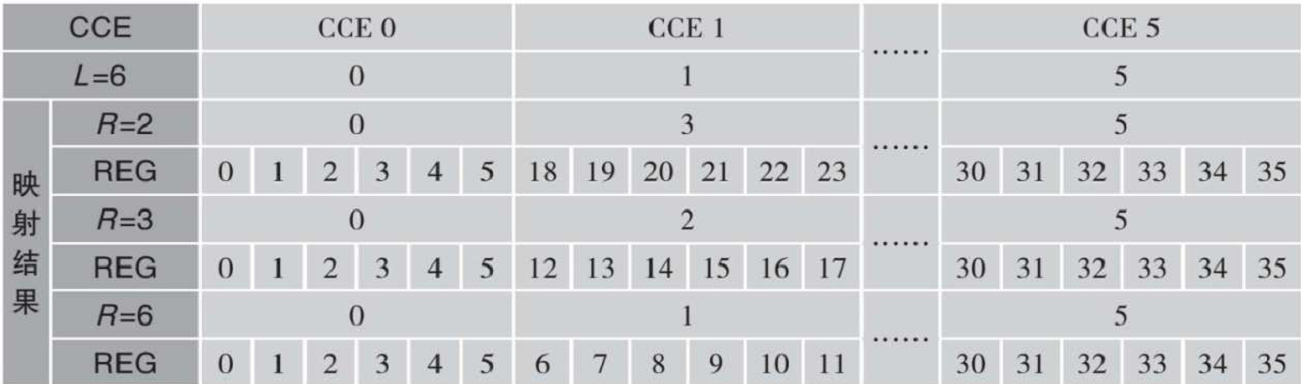
当L=6时,CCE到REG的交织映射结果如下表所示。R为交织深度,交织方法为行进列出。
下图给出L=2,不同交织深度下,CCE0/1分别映射到不同REG上的示意图。
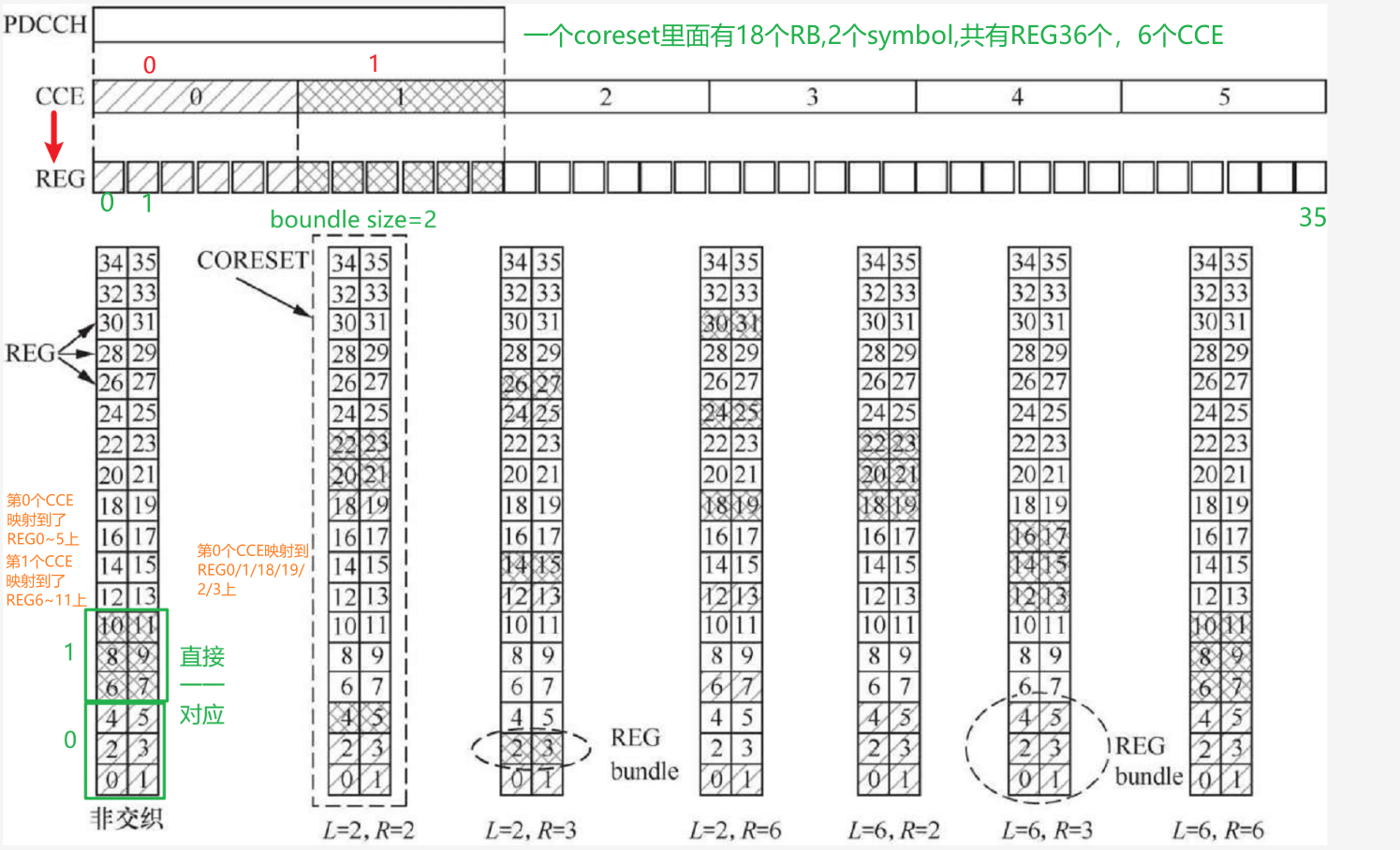
下图给出L=2,R=3的场景下,CCE到REG的交织映射详细过程示意图。

NR是以REG bundle为单位进行信道估计的。基站可以在不同的REG bundle之间使用不同的预编码,以提高PDCCH的传输效率。由于PBCH信道不传递CCE到REG映射的信息,因此通过PBCH配置的CORESET,UE默认REG bundle size L=6, 交织深度R=2,以便获得频率分集增益。
关于PDCCH CORESET上频域资源CCE到REG的交织与非交织映射的介绍就如文中所述。关于映射过程中的具体公式,文中并未列出,而是直接对结果加以图示说明,如有需要,可参考协议。如后续工作学习中遇到新发现,再继续更新。注:
n s h i f t n^{}_{shift} nshift的取值有两种情况:
1、由PBCH或者SIB1配置的CORESET, n s h i f t n^{}_{shift} nshift= N I D c e l l N^{cell}_{ID} NIDcell ;
2、其他情况下 n s h i f t n^{}_{shift} nshift由高层参数shiftidex通知给UE,取值{0,1,…274};
另,
1、CCE到REG的交织映射中,若 N s y m b o l C O R E S E T N^{CORESET}_{symbol} NsymbolCORESET=1,则L={2,6};
若 N s y m b o l C O R E S E T N^{CORESET}_{symbol} NsymbolCORESET={2,3},则L={ N s y m b o l C O R E S E T N^{CORESET}_{symbol} NsymbolCORESET,6}。
最后
以上就是安详小虾米最近收集整理的关于5G PDCCH时频资源之CORESET概要的全部内容,更多相关5G内容请搜索靠谱客的其他文章。








发表评论 取消回复